
PM2.5 Concentration Prediction Model: A CNN–RF Ensemble Framework

Abstract
:1. Introduction
2. Datasets and Methods
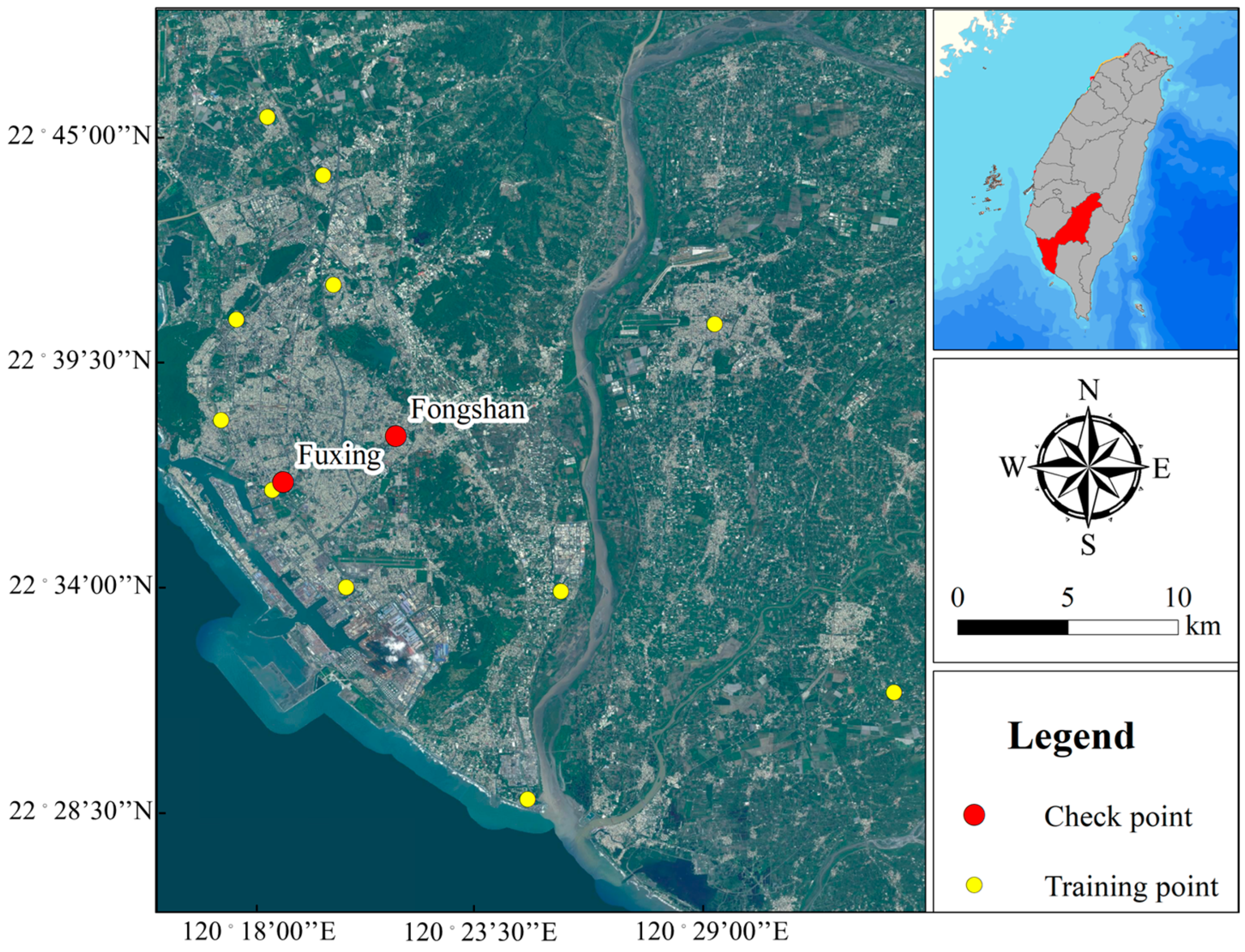
2.1. Datasets and Preprocessing
2.2. Proposed CNN–RF Framework
2.3. Experimental Equipment and Assessment Indicators
3. Results and Discussion
3.1. Model Evaluation
3.2. Model Validation
4. Conclusions
4.1. Model Evaluation
4.2. Model Validation
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Available online: https://www.who.int/health-topics/air-pollution#tab=tab_1 (accessed on 16 February 2023).
- Bailie, C.R.; Ghosh, J.K.C.; Kirk, M.D.; Sullivan, S.G. Effect of ambient PM2.5 on healthcare utilisation for acute respiratory illness, Melbourne, Victoria, 2014–2019. J. Air Waste Manag. Assoc. 2022, 73, 120–132. [Google Scholar] [CrossRef] [PubMed]
- Syuhada, G.; Akbar, A.; Hardiawan, D.; Pun, V.; Darmawan, A.; Heryati, H.A.; Siregar, A.Y.M.; Kusuma, R.R.; Driejana, R.; Ingole, V. Impacts of Air Pollution on Health and Cost of Illness in Jakarta, Indonesia. Int. J. Environ. Res. Public Health 2023, 20, 2916. [Google Scholar] [CrossRef]
- Cocârţă, D.; Prodana, M.; Demetrescu, I.; Lungu, P.; Didilescu, A. Indoor air pollution with fine particles and implications for workers’ health in dental offices: A brief review. Sustainability 2021, 13, 599. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, B. Air pollution and healthcare expenditure: Implication for the benefit of air pollution control in China. Environ. Int. 2018, 120, 443–455. [Google Scholar] [CrossRef] [PubMed]
- Kurwadkar, S.; Sankar, T.K.; Kumar, A.; Ambade, B.; Gautam, S.; Gautam, A.S.; Biswas, J.K.; Salam, M.A. Emissions of black carbon and polycyclic aromatic hydrocarbons: Potential implications of cultural practices during the COVID-19 pandemic. Gondwana Res. 2023, 114, 4–14. [Google Scholar] [CrossRef]
- Ambade, B.; Sethi, S.S.; Kurwadkar, S.; Mishra, P.; Tripathee, L. Accumulation of polycyclic aromatic hydrocarbons (PAHs) in surface sediment residues of Mahanadi River Estuary: Abundance, source, and risk assessment. Mar. Pollut. Bull. 2022, 183, 114073. [Google Scholar] [CrossRef] [PubMed]
- Ambade, B.; Sankar, T.K.; Kumar, A.; Gautam, A.S.; Gautam, S. COVID-19 lockdowns reduce the Black carbon and polycyclic aromatic hydrocarbons of the Asian atmosphere: Source apportionment and health hazard evaluation. Environ. Dev. Sustain. 2021, 23, 12252–12271. [Google Scholar] [CrossRef]
- Ambade, B.; Sankar, T.K.; Sahu, L.K.; Gautam, S.; Gautam, A.S. Comparison of emission profile of black carbon and carbon monoxide over Eastern India: Source apportionment and health risk impact. Environ. Sci. 2021. [Google Scholar] [CrossRef]
- Hinds, W.C.A.T. Introduction, 2nd ed.; John Wiley and Sons: New York, NY, USA, 1999. [Google Scholar]
- Zhang, M.; Mueller, N.T.; Wang, H.; Hong, X.; Appel, L.J.; Wang, X. Maternal exposure to ambient particulate matter≤ 2.5 µm during pregnancy and the risk for high blood pressure in childhood. Hypertension 2018, 72, 194–201. [Google Scholar] [CrossRef]
- Park, S.; Kim, M.; Kim, M.; Namgung, H.-G.; Kim, K.-T.; Cho, K.H.; Kwon, S.-B. Predicting PM10 concentration in Seoul metropolitan subway stations using artificial neural network (ANN). J. Hazard. Mater. 2018, 341, 75–82. [Google Scholar] [CrossRef]
- Djalalova, I.; Delle Monache, L.; Wilczak, J. PM2.5 analog forecast and Kalman filter post-processing for the Community Multiscale Air Quality (CMAQ) model. Atmos. Environ. 2015, 108, 76–87. [Google Scholar] [CrossRef]
- Woody, M.; Wong, H.-W.; West, J.; Arunachalam, S. Multiscale predictions of aviation-attributable PM2.5 for US airports modeled using CMAQ with plume-in-grid and an aircraft-specific 1-D emission model. Atmos. Environ. 2016, 147, 384–394. [Google Scholar] [CrossRef]
- Zhu, B.; Akimoto, H.; Wang, Z. The Preliminary Application of a Nested Air Quality Prediction Modeling System in Kanto Area, Japan. In Proceedings of the AGU Fall Meeting Abstracts, San Francisco, CA, USA, 5–9 December 2005; p. A33F-08. [Google Scholar]
- Geng, G.; Zhang, Q.; Martin, R.V.; van Donkelaar, A.; Huo, H.; Che, H.; Lin, J.; He, K. Estimating long-term PM2.5 concentrations in China using satellite-based aerosol optical depth and a chemical transport model. Remote Sens. Environ. 2015, 166, 262–270. [Google Scholar] [CrossRef]
- Saide, P.E.; Carmichael, G.R.; Spak, S.N.; Gallardo, L.; Osses, A.E.; Mena-Carrasco, M.A.; Pagowski, M. Forecasting urban PM10 and PM2.5 pollution episodes in very stable nocturnal conditions and complex terrain using WRF–Chem CO tracer model. Atmos. Environ. 2011, 45, 2769–2780. [Google Scholar] [CrossRef]
- Wang, P.; Qiao, X.; Zhang, H. Modeling PM2.5 and O3 with aerosol feedbacks using WRF/Chem over the Sichuan Basin, southwestern China. Chemosphere 2020, 254, 126735. [Google Scholar] [CrossRef]
- Mao, F.; Hong, J.; Min, Q.; Gong, W.; Zang, L.; Yin, J. Estimating hourly full-coverage PM2.5 over China based on TOA reflectance data from the Fengyun-4A satellite. Environ. Pollut. 2021, 270, 116119. [Google Scholar] [CrossRef]
- Wei, J.; Li, Z.; Lyapustin, A.; Sun, L.; Peng, Y.; Xue, W.; Su, T.; Cribb, M. Reconstructing 1-km-resolution high-quality PM2.5 data records from 2000 to 2018 in China: Spatiotemporal variations and policy implications. Remote Sens. Environ. 2021, 252, 112136. [Google Scholar] [CrossRef]
- Wei, N.; Jia, Z.; Men, Z.; Ren, C.; Zhang, Y.; Peng, J.; Wu, L.; Wang, T.; Zhang, Q.; Mao, H. Machine Learning Predicts Emissions of Brake Wear PM2.5: Model Construction and Interpretation. Environ. Sci. Technol. Lett. 2022, 9, 352–358. [Google Scholar] [CrossRef]
- Wang, Z.; Li, R.; Chen, Z.; Yao, Q.; Gao, B.; Xu, M.; Yang, L.; Li, M.; Zhou, C. The estimation of hourly PM2.5 concentrations across China based on a Spatial and Temporal Weighted Continuous Deep Neural Network (STWC-DNN). ISPRS J. Photogramm. Remote Sens. 2022, 190, 38–55. [Google Scholar] [CrossRef]
- Zou, G.; Zhang, B.; Yong, R.; Qin, D.; Zhao, Q. FDN-learning: Urban PM2.5-concentration Spatial Correlation Prediction Model Based on Fusion Deep Neural Network. Big Data Res. 2021, 26, 100269. [Google Scholar] [CrossRef]
- Rybarczyk, Y.; Zalakeviciute, R. Machine learning approach to forecasting urban pollution. In Proceedings of the 2016 IEEE Ecuador Technical Chapters Meeting (ETCM), Guayaquil, Ecuador, 12–14 October 2016; pp. 1–6. [Google Scholar]
- Gore, R.W.; Deshpande, D.S. An approach for classification of health risks based on air quality levels. In Proceedings of the 2017 1st International Conference on Intelligent Systems and Information Management (ICISIM), Aurangabad, India, 5–6 October 2017; pp. 58–61. [Google Scholar]
- Di, Q.; Amini, H.; Shi, L.; Kloog, I.; Silvern, R.; Kelly, J.; Sabath, M.B.; Choirat, C.; Koutrakis, P.; Lyapustin, A. An ensemble-based model of PM2.5 concentration across the contiguous United States with high spatiotemporal resolution. Environ. Int. 2019, 130, 104909. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Mishra, S.; Singh, S.K. A machine learning-based model to estimate PM2.5 concentration levels in Delhi’s atmosphere. Heliyon 2020, 6, e05618. [Google Scholar] [CrossRef] [PubMed]
- Feng, C.; Wang, W.; Tian, Y.; Que, X.; Gong, X. Estimate air quality based on mobile crowd sensing and big data. In Proceedings of the 2017 IEEE 18th International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM), Macao, China, 12–15 June 2017; pp. 1–9. [Google Scholar]
- Kleine Deters, J.; Zalakeviciute, R.; Gonzalez, M.; Rybarczyk, Y. Modeling PM2.5 urban pollution using machine learning and selected meteorological parameters. J. Electr. Comput. Eng. 2017, 2017, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Zhang, H.; Qin, Z.; Zhang, G. A novel hybrid-Garch model based on ARIMA and SVM for PM2.5 concentrations forecasting. Atmos. Pollut. Res. 2017, 8, 850–860. [Google Scholar] [CrossRef]
- Yarragunta, S.; Nabi, M.A. Prediction of air pollutants using supervised machine learning. In Proceedings of the 2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 6–8 May 2021; pp. 1633–1640. [Google Scholar]
- Goudarzi, G.; Hopke, P.K.; Yazdani, M. Forecasting PM2.5 concentration using artificial neural network and its health effects in Ahvaz, Iran. Chemosphere 2021, 283, 131285. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Choi, S.-M.; Choi, H. Artificial Neural Network Modeling on PM10, PM2.5, and NO2 Concentrations between Two Megacities without a Lockdown in Korea, for the COVID-19 Pandemic Period of 2020. Int. J. Environ. Res. Public Health 2022, 19, 16338. [Google Scholar] [CrossRef]
- Chae, S.; Shin, J.; Kwon, S.; Lee, S.; Kang, S.; Lee, D. PM10 and PM2.5 real-time prediction models using an interpolated convolutional neural network. Sci. Rep. 2021, 11, 11952. [Google Scholar] [CrossRef]
- Chakma, A.; Vizena, B.; Cao, T.; Lin, J.; Zhang, J. Image-based air quality analysis using deep convolutional neural network. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3949–3952. [Google Scholar]
- Li, J.; Jin, M.; Li, H. Exploring spatial influence of remotely sensed PM2.5 concentration using a developed deep convolutional neural network model. Int. J. Environ. Res. Public Health 2019, 16, 454. [Google Scholar] [CrossRef] [Green Version]
- Tong, W.; Li, L.; Zhou, X.; Hamilton, A.; Zhang, K. Deep learning PM2.5 concentrations with bidirectional LSTM RNN. Air Qual. Atmos. Health 2019, 12, 411–423. [Google Scholar] [CrossRef]
- Tsai, Y.-T.; Zeng, Y.-R.; Chang, Y.-S. Air pollution forecasting using RNN with LSTM. In Proceedings of the 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; pp. 1074–1079. [Google Scholar]
- Liu, B.; Yan, S.; Li, J.; Li, Y.; Lang, J.; Qu, G. A spatiotemporal recurrent neural network for prediction of atmospheric PM2.5: A case study of Beijing. IEEE Trans. Comput. Soc. Syst. 2021, 8, 578–588. [Google Scholar] [CrossRef]
- Gao, X.; Li, W. A graph-based LSTM model for PM2.5 forecasting. Atmos. Pollut. Res. 2021, 12, 101150. [Google Scholar] [CrossRef]
- Qadeer, K.; Rehman, W.U.; Sheri, A.M.; Park, I.; Kim, H.K.; Jeon, M. A long short-term memory (LSTM) network for hourly estimation of PM2.5 concentration in two cities of South Korea. Appl. Sci. 2020, 10, 3984. [Google Scholar] [CrossRef]
- Zhang, M.; Wu, D.; Xue, R. Hourly prediction of PM2.5 concentration in Beijing based on Bi-LSTM neural network. Multimed. Tools Appl. 2021, 80, 24455–24468. [Google Scholar] [CrossRef]
- Babu, S.; Thomas, B. A recurrent neural network forecasting technique for daily PM2.5 concentration level in Southern Kerala. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2021; p. 012012. [Google Scholar]
- Wei, P.; Xie, S.; Huang, L.; Zhu, G.; Tang, Y.; Zhang, Y. Prediction of PM2.5 concentration in Guangxi region, China based on MLR-ARIMA. J. Phys. Conf. Ser. 2021, 2006, 012023. [Google Scholar] [CrossRef]
- Teng, M.; Li, S.; Xing, J.; Song, G.; Yang, J.; Dong, J.; Zeng, X.; Qin, Y. 24-Hour prediction of PM2.5 concentrations by combining empirical mode decomposition and bidirectional long short-term memory neural network. Sci. Total Environ. 2022, 821, 153276. [Google Scholar] [CrossRef] [PubMed]
- Jin, X.-B.; Yang, N.-X.; Wang, X.-Y.; Bai, Y.-T.; Su, T.-L.; Kong, J.-L. Deep hybrid model based on EMD with classification by frequency characteristics for long-term air quality prediction. Mathematics 2020, 8, 214. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Deng, F.; Cai, Y.; Chen, J. Long short-term memory-Fully connected (LSTM-FC) neural network for PM2.5 concentration prediction. Chemosphere 2019, 220, 486–492. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.; Huang, G.; Zeng, H.; Yang, F. PM2.5 Concentration Prediction Based on Spatiotemporal Feature Selection Using XGBoost-MSCNN-GA-LSTM. Sustainability 2021, 13, 12071. [Google Scholar] [CrossRef]
- Li, T.; Hua, M.; Wu, X. A hybrid CNN-LSTM model for forecasting particulate matter (PM2.5). IEEE Access 2020, 8, 26933–26940. [Google Scholar] [CrossRef]
- Huang, C.-J.; Kuo, P.-H. A deep CNN-LSTM model for particulate matter (PM2.5) forecasting in smart cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef] [Green Version]
- Qin, D.; Yu, J.; Zou, G.; Yong, R.; Zhao, Q.; Zhang, B. A novel combined prediction scheme based on CNN and LSTM for urban PM 2.5 concentration. IEEE Access 2019, 7, 20050–20059. [Google Scholar] [CrossRef]
- Zhu, M.; Xie, J. Investigation of nearby monitoring station for hourly PM2.5 forecasting using parallel multi-input 1D-CNN-biLSTM. Expert Syst. Appl. 2023, 211, 118707. [Google Scholar] [CrossRef]
- Zhang, J.; Peng, Y.; Ren, B.; Li, T. PM2.5 Concentration Prediction Based on CNN-BiLSTM and Attention Mechanism. Algorithms 2021, 14, 208. [Google Scholar] [CrossRef]
- Chen, Y.; Ye, C.; Yang, P.; Miao, Z.; Chen, Y.; Li, H.; Liu, R.; Liu, B. Research on An Attention-based Hybrid CNN and BiLSTM Model for Air Pollutant Concentration Prediction. In Proceedings of the 2021 6th International Conference on Computational Intelligence and Applications (ICCIA), Xiamen, China, 11–13 June 2021; pp. 79–84. [Google Scholar]
- Wong, P.-Y.; Lee, H.-Y.; Chen, Y.-C.; Zeng, Y.-T.; Chern, Y.-R.; Chen, N.-T.; Lung, S.-C.C.; Su, H.-J.; Wu, C.-D. Using a land use regression model with machine learning to estimate ground level PM2.5. Environ. Pollut. 2021, 277, 116846. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Sun, W.; Zheng, K.; Ren, X.; Han, P. Estimating hourly PM2.5 concentrations using MODIS 3 km AOD and an improved spatiotemporal model over Beijing-Tianjin-Hebei, China. Atmos. Environ. 2020, 222, 117089. [Google Scholar] [CrossRef]
- Shen, J.; Valagolam, D.; McCalla, S. Prophet forecasting model: A machine learning approach to predict the concentration of air pollutants (PM2.5, PM10, O3, NO2, SO2, CO) in Seoul, South Korea. PeerJ 2020, 8, e9961. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Zhang, X. Predicting ground-level PM2.5 concentrations in the Beijing-Tianjin-Hebei region: A hybrid remote sensing and machine learning approach. Environ. Pollut. 2019, 249, 735–749. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ejohwomu, O.A.; Shamsideen Oshodi, O.; Oladokun, M.; Bukoye, O.T.; Emekwuru, N.; Sotunbo, A.; Adenuga, O. Modelling and forecasting temporal PM2.5 concentration using ensemble machine learning methods. Buildings 2022, 12, 46. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Observations | Training | Testing | |
|---|---|---|---|
| (CO, NO2, NO, NOX, SO2, O3, PM10, PM2.5, wind speed, wind direction, relative humidity, rainfall, ambient temperature, day of year, hour of day, latitude, longitude) | Fuxing | Fongshan | |
| 88,383 | 8018 | 7925 | |
| Parameters | Value |
|---|---|
| Convolution layer | 1 |
| Kernel size of CNN | 3 × 1 |
| Convolution layer channels | 16 |
| Max pooling layer | 1 |
| Pooling filter size, stride | 2 × 1, 2 |
| Fully connected layer | 1 |
| Fully connected nodes | 384 |
| Learning rate | 0.005 |
| Batch size | 16 |
| Epochs | 20 |
| Mini leaf size | 8 |
| Number of learners | 30 |
| Method | RMSE (μg/m3) | MSE (μg/m3)2 | MAE (μg/m3) | R2 |
|---|---|---|---|---|
| RF | 3.36 | 11.27 | 2.38 | 0.94 |
| CNN | 4.65 | 21.66 | 3.43 | 0.89 |
| CNN-RF | 3.67 | 13.44 | 2.66 | 0.93 |
| Method | RMSE(μg/m3) | MAE(μg/m3) | R2 | MA(%) | ||||
|---|---|---|---|---|---|---|---|---|
| Fuxing | Fongshan | Fuxing | Fongshan | Fuxing | Fongshan | Fuxing | Fongshan | |
| RF | 4.93 | 5.75 | 3.61 | 4.30 | 0.88 | 0.84 | 83.20 | 81.33 |
| CNN | 5.54 | 5.43 | 3.95 | 4.08 | 0.83 | 0.85 | 82.26 | 81.61 |
| CNN-RF | 4.69 | 5.06 | 3.47 | 3.79 | 0.89 | 0.88 | 83.81 | 83.50 |
| Method | RMSE (μg/m3) | MAE (μg/m3) | R2 | MA (%) | ||
|---|---|---|---|---|---|---|
| Average | CNN-RF Improvement Rate (%) | Average | CNN-RF Improvement Rate (%) | Average | ||
| RF | 5.34 | 8.61 | 3.95 | 8.10 | 0.86 | 82.26 |
| CNN | 5.49 | 11.11 | 4.01 | 9.48 | 0.84 | 81.94 |
| CNN-RF | 4.88 | --- | 3.63 | --- | 0.88 | 83.66 |
| Improvement Rate (%) = (Method − CNN − RF)/Method × 100 | ||||||
| Method | >10 | >20 | >30 (μg/m3) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Training | Fuxing | Fongshan | Training | Fuxing | Fongshan | Training | Fuxing | Fongshan | |
| RF | 1212 | 418 | 476 | 72 | 26 | 23 | 14 | 2 | 2 |
| CNN | 3501 | 583 | 536 | 213 | 52 | 36 | 33 | 9 | 1 |
| CNN-RF | 1595 | 344 | 423 | 76 | 14 | 21 | 15 | 0 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.-H.; Chen, Y.-C.; Chou, T.-Y.; Ning, F.-S. PM2.5 Concentration Prediction Model: A CNN–RF Ensemble Framework. Int. J. Environ. Res. Public Health 2023, 20, 4077. https://doi.org/10.3390/ijerph20054077
Chen M-H, Chen Y-C, Chou T-Y, Ning F-S. PM2.5 Concentration Prediction Model: A CNN–RF Ensemble Framework. International Journal of Environmental Research and Public Health. 2023; 20(5):4077. https://doi.org/10.3390/ijerph20054077
Chicago/Turabian StyleChen, Mei-Hsin, Yao-Chung Chen, Tien-Yin Chou, and Fang-Shii Ning. 2023. "PM2.5 Concentration Prediction Model: A CNN–RF Ensemble Framework" International Journal of Environmental Research and Public Health 20, no. 5: 4077. https://doi.org/10.3390/ijerph20054077