1. Introduction
The water supply is considered to be one of the critical infrastructure sectors whose assets, systems and networks play significant roles in modern society [
1]. Incapacitation or impairment of the water supply system will impose catastrophic effects on public health, economy, security, or any combination thereof. The water supply system must provide water to the customers in good quality, quantity, and continuity. The water distribution network (WDN) is crucial for ensuring a well-functioning centralized water supply system. Aging of the WDN has become one of the major issues that demand attention to uphold the objectives of drinking water provision [
2]. This issue requires a long-term rehabilitation strategy in which plans for maintaining or upgrading the WDN are systematically set. Water utility providers are often challenged to set their priorities correctly, e.g., due to budget and resource limitations. The implementation of infrastructure asset management (IAM) principles may help the water utility providers make better decisions under such constraints, avoid reactive approaches, and improve the process of WDN rehabilitation planning.
IAM applied to urban water systems consists of a multidisciplinary approach to guide a water utility in providing the set level of service in an efficient, effective, and economic way. In IAM, three decision levels are identified in an organization: a strategic level, driven by corporate and long-term views; a tactical level, where the intermediate managers in charge of the infrastructures need to select what the best medium-term intervention solutions are; and an operational level, where short-term actions are planned and implemented [
3]. At the tactical level, rehabilitation decisions are taken and involve some aspect of performance/cost/risk trade-off. Risk management is the process of identifying, quantifying, and managing the risks that an organization faces. ISO 31000 is a standard for risk management. In ISO 31000, the focus is on best practice principles for implementing, maintaining, and improving a framework for risk management. According to ISO 31000, a risk management process starts with the establishment of a team, and it covers the following steps: (i) establishing the context; (ii) risk assessment; (iii) risk treatment; and (iv) monitoring and review. The risk assessment step involves risk identification to identify risk events preventing an organization from achieving a set goal; risk analysis aims to understand the sources and causes of the identified risks by studying probabilities and consequences to assess the level of risk and conducting a risk evaluation to compare risk analysis results with risk criteria to determine if the computed risk is tolerable.
The result of the risk assessment step consists of a categorization of the risk events that are tolerable and those for which immediate actions must be taken. At a tactical level, the water operator must assess what risk is tolerable by balancing the risk with the system performances and the available resources to treat the risk, and thereby define the priorities of intervention. Risk assessment is a process that in many cases is not (at least not adequately) performed, even if risk management is implemented by water utility providers. One of the main objectives of this paper is to facilitate the use of risk assessment by providing a practical example of its applications in a real case study.
The assessment approach adopted for quantifying risk needs to be selected with respect to the specific scope of the risk analysis, i.e., with consideration of qualitative, semi-quantitative, or quantitative measures of risk and determination of whether the risk analysis comprises the complete water utility system or some subsystem(s) of it. Risk is traditionally expressed by the combination of the severity of the consequences induced by unwanted events (C) and the likelihood (i.e., probability, P, or frequency, f) of the event to happen. In this study, the risk event addressed is the “inability to supply water due to pipe break”. Therefore, on the probability side, the probability of pipes breaking (structural reliability) is assessed, and on the consequence side, the number of nodes disconnected and the corresponding unsupplied flow owing to a pipe break event are computed.
The success of the rehabilitation strategy is greatly dependent on the accuracy of the pipe failure forecasting model in use. Thus, a number of physically and statistically based water main prediction models have been developed in the last 40 years. The review of Kleiner and Rajani [
4] presents an overview of the statistical models developed prior to 2001. Since the review of Kleiner and Rajani [
4], the knowledge about machine learning techniques has become popularized in the water sector and has been adopted in pipe failure forecasting modelling. These modelling techniques include, but are not limited to, genetic algorithms [
5], artificial neural networks [
6], Random Forest analysis [
7], boosted decision trees [
8], fuzzy logic, support vector machines, etc. Machine learning and statistical methods have become an invaluable tool for forecasting [
9] and lifetime analysis [
10]. The applications include financial markets [
11], modelling of dynamical systems [
12], and predictive maintenance [
13]. Predicting the remaining service life of a physical component provides a useful decision support regarding whether to rehabilitate or to replace the component. This has an obvious economic benefit while also ensuring the safety and productivity of the system. Powered by increased data collection and the integration of physical and digital systems in industrial applications, data-driven methods are valuable, for instance, in production facilities, electricity grids, and offshore activities [
13]. Recent trends show that the use of data-driven models is becoming more common for water resource management [
14].
Traditionally, physical models are used to capture the dynamics of a system in the form of differential equations. However, as in the case of breakage of water pipes [
15], the physical models are not able to capture the underlying physics. This may be due to complex interactions and unmodeled effects. In the case of highly accurate calibration of the hydraulic models, physical-based simulation analysis can be adopted to identify pipelines that require rehabilitation [
16]. The advantage of physical models is that they are highly interpretable and they do not require a direct observation of a system, i.e., they can be extrapolated to unseen areas of the data domain. On the other hand, machine learning models provide a flexible framework that can adapt to the data and often yield excellent predictive performance. Such models require little prior knowledge about the system, but they can be harder to interpret. Deep learning models [
17] have, in recent years, achieved unprecedented results, but they act as a “black-box” for the practitioner. This makes it difficult to adopt such methods in industrial applications where the predictions leading to decisions must be held accountable. Efforts have been made in combining the physical and data-driven models [
18].
An alternative to cope with the lack of transparency of flexible data-driven models would be to use a simple model that is inherently interpretable. For instance, this could be a linear model or a decision tree. However, the interpretability comes at the cost of worse predictive performance. Random Forest (RF) analysis can be used as a tradeoff between interpretability and flexibility [
17]. RF is an ensemble method that deploys a multitude of decisions trees in training and aggregates their predictions [
19]. RF has become a popular model that achieves reasonable predictions with very little requirements for configuration and has also been previously used to model water distribution networks (WDN) [
8].
Among the many elements in a WDN, pipes are the primary components for conveying water to customers. Each of these pipes can suffer failure (e.g., intentional due to maintenance or unintentional due to breakage) that decreases network functionality depending on the importance of the pipe, as well as impacting the provision of water supply for the customers [
20]. The criticality of a pipe is usually assessed by quantifying the decrease in the network functionality in a WDN reliability analysis. The reliability concept has been a central concept in WDN design, operation, and maintenance, and was developed as a continuation of the classical reliability concept that divides reliability into mechanical and hydraulic reliability [
21,
22] and uses various indices and methods of assessment. In general, the mechanical reliability puts emphasis on the network topology by evaluating system connectivity under given failure conditions. Pipe failure statistics [
23] and probability [
24] are later incorporated into the mechanical reliability analysis to better indicate the criticality of pipes in a WDN, and some studies include the water availability aspect in their simulation of pipe failure and repair events [
25]. On the other hand, hydraulic reliability refers to the ability of a system to meet the requirements of water flow and pressure. Quantification of the hydraulic reliability involves results from hydraulic simulation through the use of nodal pressure [
26] or even more complex approaches, e.g., unsupplied demand, economic loss, pressure deficiency, water quality [
27], and energy [
28].
The objective of this study is to develop a risk-based approach for prioritizing pipe rehabilitation. The paper discusses, in detail, the steps involved in the approach, which include: (1) identification of risk event for the risk analysis, i.e., inability to supply water due to pipe breaks; (2) assessment of the probability of a pipe break (P) by means of a machine learning method (RF); (3) Consequence (C) assessment conducted with the use of the Asset Vulnerability Analysis Toolkit (AVAT) that evaluates the topological importance of each pipe in a water distribution network and estimates the hydraulic reliability of each pipe with the support of complex network theory; (4) risk evaluation at pipe level using a risk matrix approach. A risk matrix is a method that provides an approximation to a quantitative relation between Consequence (C) and Probability (P). The risk matrix enables:
Estimation of a risk level of identified risk events;
Setting of the risk criteria: the levels of acceptable risk;
Discrimination between three levels of risk associated with acceptance criteria:
- ○
Low (acceptable);
- ○
Medium (tolerable);
- ○
High (not acceptable).
Subsequently, (5) ranking of risk events takes place according to their severity/level in the risk matrix, thereby enabling prioritization for the pipe rehabilitation plan.
The paper is structured in sections. First, the risk assessment methodology is described, including the information on the case study, and how the probability and consequences are calculated. Secondly, the results of probability, consequence, and risk assessment, as well as the pipe ranking, are presented. Finally, the results are discussed and compared with other studies, including limitations and potential improvements of the proposed method, followed by the main conclusions and future perspectives of the study.
4. Discussion
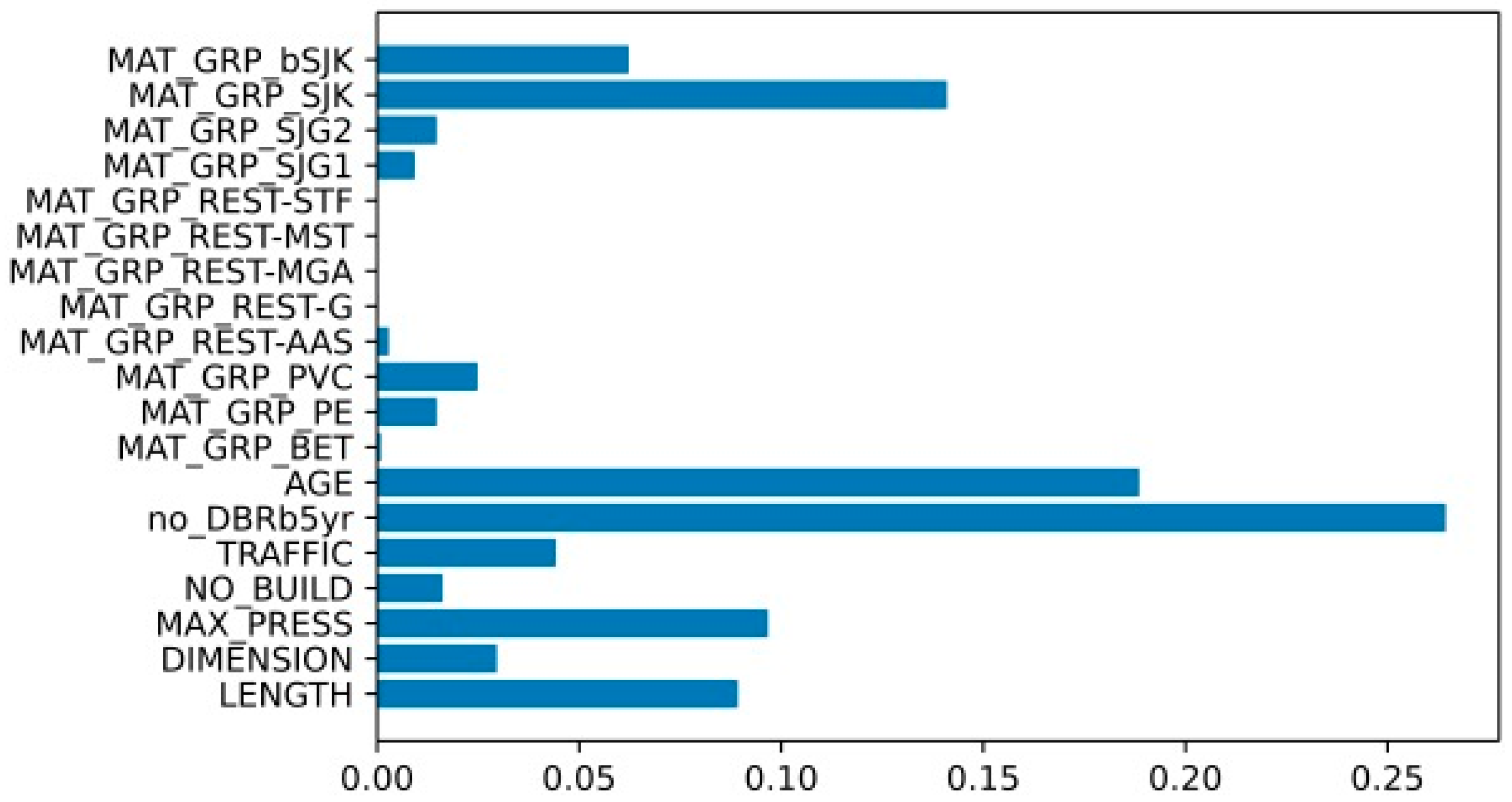
Pipe failure statistics and probability assessment play a central role in a reliability analysis. It is, therefore, important to be able to test and verify the models that are used for probability assessment. In the study, the model was trained by 70% of the dataset verified with 30% of the data. This enabled the possibility to verify how accurately the model was able to predict failures on pipes that had real failures and predict no failures on pipes that had no real failures. The municipality experiences about 140 breaks per year. Over a period of the next five years (i.e., the estimation period in this study), this amounts to about 700 breaks, which means that the BA model predicts more (it predicted 927 failures) than the actual observed number of breaks. There is, therefore, a possibility that the BA model is over-estimating the number of failures. However, there is another more plausible explanation for the overestimation of failures. Even though the municipality have not registered a failure on a pipe, it does not mean that the pipe has a smaller or several smaller failures that the municipality is yet to discover. For a failure to be registered, it must be observed. Therein lies a bias in the numbers. Many of the pipes that were predicted to fail by Random Forest analysis, but for which failure was not observed reality (True label = 0 + Predicted label = 1), may have smaller leakages that are yet to be discovered, e.g., background leakages. Our interpretation of the results is that the BA model identified pipes with leakages that are yet to be discovered by the municipality. This means that there may be failures that are not yet observed. In the testing of the BA model, where the model was tested on the verification dataset, it showed an accuracy of 68% in terms of estimating failures on pipes that have actual failures in real life. This is important because it conveys something about the probability of estimating failures on pipes that will experience real failures in the next five years. The model was able to estimate 2 out of 3 failures that occurred on the validation dataset.
It is also important to note that the study found pipe failure history to be an important predictor, as was also found by other researchers [
32,
33], ahead of other predictors, e.g., age, material, length, and pressure [
8,
34,
35,
36]. Such a ‘clustering’ pipe failure phenomenon is well known and can be a result of, e.g., an inadequate repair of the previous failure [
37,
38].
In this study, the mechanical reliability analysis was represented by AVAT simulations that quantified the number of disconnected nodes as a function of pipe failure events. The application of AVAT in a large, real-life WDN comprising loop and branch pipes showed that AVAT has a tendency of giving away higher LCI scores for branch pipes and often undermines the centrality of pipes in complex pipe loops (see
Figure 6). This highlights another common tendency for most of the reliability index methods besides, e.g., a greater criticality index of large pipes or pipes serving high-demand nodes [
27]. Hence, one needs to include other parameter(s) to be able to improve the pipe criticality analysis. From the perspective of water utility providers, the objective is to supply water of adequate quantity and pressure. Hence, the number of unsupplied customers and/or pressure sufficiency can be an important factor. From AVAT simulation, one can obtain the number of disconnected nodes, which is quite straightforward for a branch system. For a loop system, the calculation of disconnected nodes will not be as straightforward as in a branch system. The unsupplied flow to a node due to disconnection of a pipe can be compensated by the node’s connection with other pipes in the WDN, i.e., by the rerouting of flow with a higher energy dissipation/headloss as compensation. To account for this issue, the study combined the hydraulic–topological reliability in a simple way through the inclusion of unsupplied flow if a particular pipe was out of service. This approach was shown generically to provide indication of the critical pipes; however, the unsupplied flow did not necessarily/directly reflect the true value of unsupplied demand for customers. One can argue that pressure-driven modelling may help in calculating flow and pressure with much greater flow accuracy but given that AVAT involves a steady-state hydraulic analysis, this may not amount to a huge difference. The difference, however, can be significant if one can evaluate the background leakage and decouple it from the real customer demand at nodes and, consequently, the leakage flow contribution to the total flow of water in a pipe, e.g., by means of using a well-calibrated hydraulic model coupled with a leakage algorithm [
39,
40] or by observing customer demand records [
41]. A simpler solution may involve developing a separate disconnected nodes list and quantifying the customer demands attached to those nodes. Hence, the problem of the indirect representation of unsupplied demand by flow in pipes can be resolved.
As described in
Section 2.4, the C assessment involved a hydraulic simulation at 17.00. To make sure the chosen time of simulation was representative, another sensitivity test was conducted using flow data at 00.00 and the result is presented in
Table A6 (
Appendix C). One can again observe that the ‘sum row’ is constant irrespective of the hydraulic simulation owing to the single set of
p values used in the test. In addition, one may see that the ‘sum column’ is different if compared to that of 17.00. There is an increase in number of pipes in C0–C1 and a decrease in C2–C3, while the numbers in C4–C5 are constant. Indeed, some of the pipes in C2–C3 conveying lower flows at 00.00 compared to at 17.00 render lower C values and are demoted to the lower C classes. This does not, however, impact the number of pipes in the red risk group as the total pipe number belonging to the group is merely the same and still refers to the same critical pipe IDs as listed in
Table A5.
The risk matrix approach applied in this study was found to help in improving the visualization of the risk events investigated. Nonetheless, the straightforward classification of risk levels in this study can be refined in many ways. Some of the criticisms of the application of risk matrices in decision making were addressed in this study. For example, the P and C assessment involves objective data that quantifies the two factors and, hence, minimizes cognitive/subjective biases that lead to off-target analysis [
42]. A sensitivity analysis was also performed to assess how some specific model variables impact the output of the method applied. Only after an objective quantification or the risk levels can real life factors be considered deeply to better alleviate a false sense of security of the risk levels and ensure the effectiveness of risk treatment (e.g., setting up a pipe rehabilitation plan). For example, the water utility provider may perceive P and C differently; hence, the finalization of the risk matrix should be conducted in close interaction with the stakeholders. External data, e.g., data from other infrastructures that are directly or indirectly connected to the operational aspects of WDN, such as railways, wastewater pipes, and so on, can help assist better decision making. Some of these pieces of data were included in the RF analysis (e.g., the number of buildings and the traffic load above or near the pipe), but not, in a sense, evaluated when it came to the consequence analysis.
Traditionally, pipe rehabilitation plans in Norway are mostly based on pipe breakage probability assessment. This study took risk into consideration by combining the probability of a failure with the consequence if it happens. The main advantage with this approach is that pipes with high probability of failure are not necessarily prioritized if their failure does not involve a significant consequence. This allows the municipality to focus on high-risk pipes in the rehabilitation planning process.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














