
Powering Research through Innovative Methods for Mixtures in Epidemiology (PRIME) Program: Novel and Expanded Statistical Methods

 , , , , ,
, , , , ,
Abstract
:1. Introduction
2. Powering Research through Innovative Methods for Mixtures in Epidemiology (PRIME) Initiative
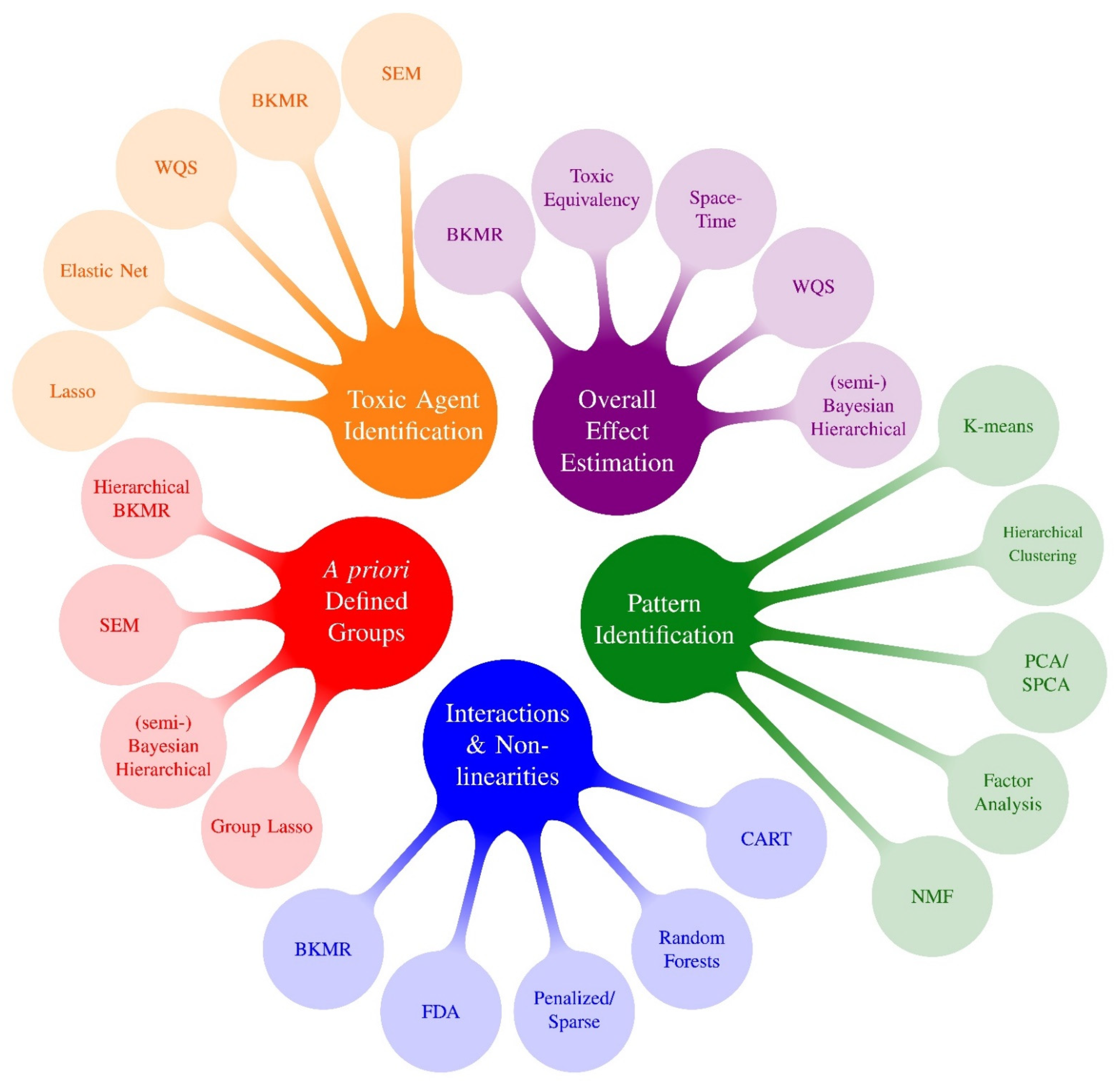
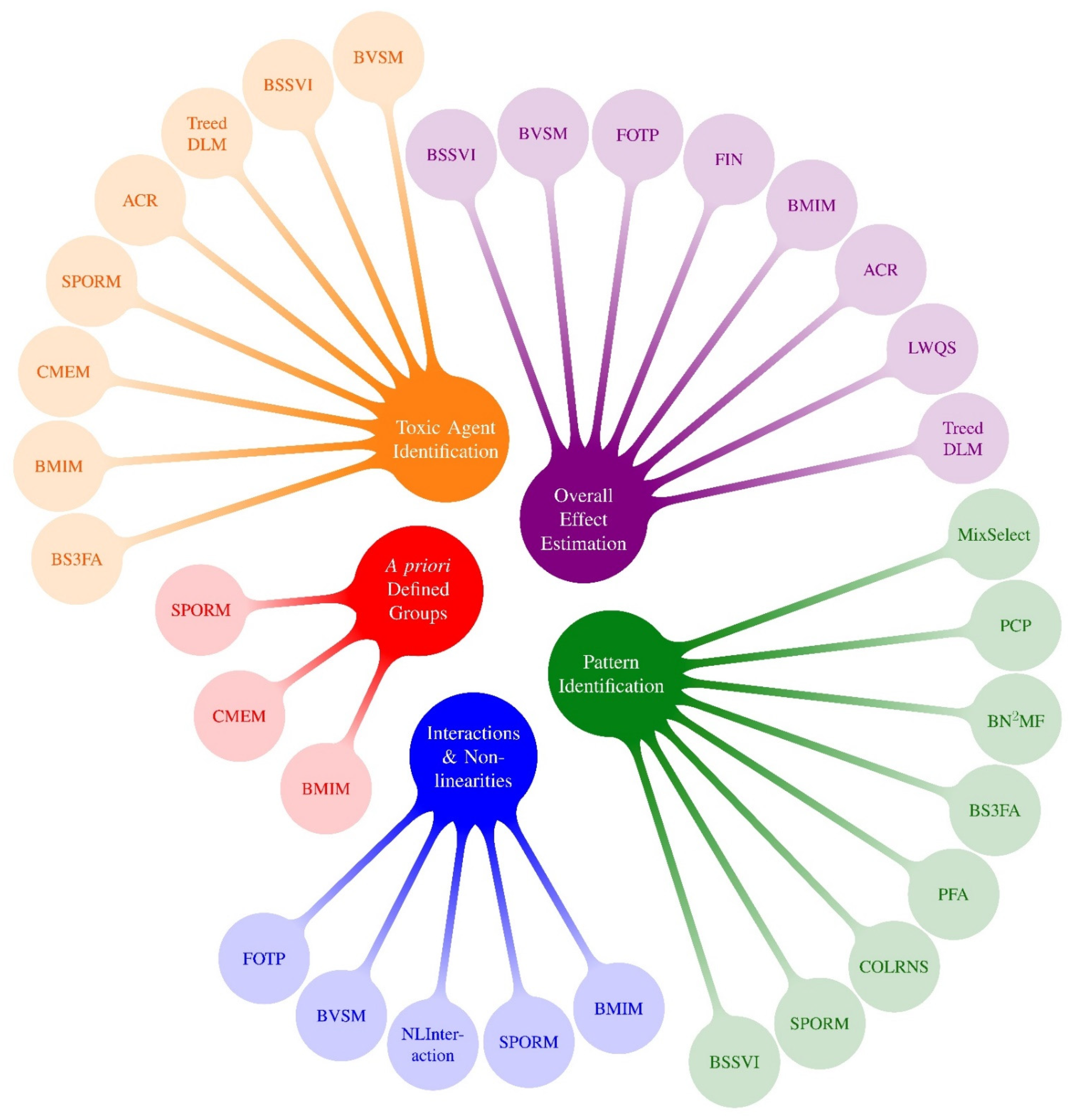
3. Results: Key Advancements Offered by New and Expanded Methods
3.1. Overall Effect Estimation
3.2. Toxic AGENT Identification (Variable Selection)
3.3. Pattern Identification
3.4. A Priori Defined Groups
3.5. Interactions and Non-Linearities
4. Other Statistical Advancements for Mixtures
4.1. Data Science and Data Preparation Strategies
4.2. Estimation of the Exposure-Response Surface
4.3. Timing of Exposures and Periods of Susceptibility
4.4. Epidemiological Methods and Causal Models
4.5. Toxicity and Related Chemical Information
4.6. Spatiotemporal Methods
4.7. Risk Assessment and Regulatory Relevance
4.8. Model Performance, Efficiency, and Interpretation
5. Software
6. Discussion
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Taylor, K.W.; Joubert, B.R.; Braun, J.M.; Dilworth, C.; Gennings, C.; Hauser, R.; Heindel, J.J.; Rider, C.V.; Webster, T.F.; Carlin, D.J. Statistical Approaches for Assessing Health Effects of Environmental Chemical Mixtures in Epidemiology: Lessons from an Innovative Workshop. Environ. Health Perspect. 2016, 124, A227–A229. [Google Scholar] [CrossRef]
- Carlin, D.J.; Rider, C.V.; Woychik, R.; Birnbaum, L.S. Unraveling the health effects of environmental mixtures: An NIEHS priority. Environ. Health Perspect. 2013, 121, A6–A8. [Google Scholar] [CrossRef] [PubMed]
- NIEHS. Powering Research through Innovative Methods for Mixtures in Epidemiology (PRIME). Available online: https://grants.nih.gov/grants/guide/rfa-files/RFA-ES-17-001.html (accessed on 16 November 2021).
- Devick, K.L.; Bobb, J.F.; Mazumdar, M.; Henn, B.C.; Bellinger, D.C.; Christiani, D.C.; Wright, R.O.; Williams, P.L.; Coull, B.A.; Valeri, L. Bayesian kernel machine regression-causal mediation analysis. arXiv 2018, arXiv:1811.10453. [Google Scholar] [CrossRef]
- McGee, G.; Wilson, A.; Webster, T.F.; Coull, B.A. Bayesian Multiple Index Models for Environmental Mixtures. arXiv 2021, arXiv:2101.05352. [Google Scholar] [CrossRef]
- Weisskopf, M.G.; Seals, R.M.; Webster, T.F. Bias Amplification in Epidemiologic Analysis of Exposure to Mixtures. Environ. Health Perspect. 2018, 126, 047003. [Google Scholar] [CrossRef]
- Gibson, E.A.; Rowland, S.T.; Goldsmith, J.; Paisley, J.; Herbstman, J.B.; Kiourmourtzoglou, M.-A. Bayesian non-parametric non-negative matrix factorization for pattern identification in environmental mixtures. arXiv 2021, arXiv:2109.12164. [Google Scholar]
- Gibson, E.A.; Zhang, J.; Yan, J.; Chillrud, L.; Benavides, J.; Nunez, Y.; Herbstman, J.B.; Goldsmith, J.; Wright, J.; Kioumourtzoglou, M.-A. Principal Component Pursuit for Pattern Identification in Environmental Mixtures. arXiv 2021, arXiv:2111.00104. [Google Scholar]
- Jin, B.; Peruzzi, M.; Dunson, D.B. Bag of DAGs: Flexible & Scalable Modeling of Spatiotemporal Dependence. arXiv 2021, arXiv:2112.11870. [Google Scholar]
- Jin, B.; Dunson, D.B.; Rager, J.E.; Reif, D.; Engel, S.M.; Herring, A.H. Bayesian Matrix Completion for Hypothesis Testing. arXiv 2020, arXiv:2009.08405. [Google Scholar]
- Moran, K.R.; Dunson, D.; Wheeler, M.W.; Herring, A.H. Bayesian joint modeling of chemical structure and dose response curves. Ann. Appl. Stat. 2021, 15, 1405–1430. [Google Scholar] [CrossRef]
- Ferrari, F.; Dunson, D.B. Bayesian factor analysis for inference on interactions. J. Am. Stat. Assoc. 2020, 116, 1521–1532. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schiavon, L.; Canale, A.; Dunson, D.B. Generalized infinite factorization models. arXiv 2021, arXiv:2103.10333. [Google Scholar] [CrossRef]
- Dunson, D.B.; Wu, H.-T.; Wu, N. Diffusion based gaussian processes on restricted domains. arXiv 2020, arXiv:2010.07242. [Google Scholar]
- Peruzzi, M.; Banerjee, S.; Dunson, D.B.; Finley, A.O. Grid-Parametrize-Split (GriPS) for improved scalable inference in spatial big data analysis. arXiv 2021, arXiv:2101.03579. [Google Scholar]
- Ferrari, F.; Dunson, D.B. Identifying main effects and interactions among exposures using Gaussian processes. Ann. Appl. Stat. 2020, 14, 1743–1758. [Google Scholar] [CrossRef]
- Dunson, D.B.; Wu, N. Inferring Manifolds From Noisy Data Using Gaussian Processes. arXiv 2021, arXiv:2110.07478. [Google Scholar]
- Roy, A.; Lavine, I.; Herring, A.H.; Dunson, D.B. Perturbed factor analysis: Accounting for group differences in exposure profiles. Ann. Appl. Stat. 2021, 15, 1386–1404. [Google Scholar] [CrossRef]
- Poworoznek, E.; Ferrari, F.; Dunson, D. Efficiently resolving rotational ambiguity in Bayesian matrix sampling with matching. arXiv 2021, arXiv:2107.13783. [Google Scholar]
- Peruzzi, M.; Dunson, D.B. Spatial multivariate trees for big data Bayesian regression. arXiv 2020, arXiv:2012.00943. [Google Scholar]
- Gennings, C.; Shu, H.; Rudén, C.; Öberg, M.; Lindh, C.; Kiviranta, H.; Bornehag, C.-G. Incorporating regulatory guideline values in analysis of epidemiology data. Environ. Int. 2018, 120, 535–543. [Google Scholar] [CrossRef]
- Antonelli, J.; Wilson, A.; Coull, B. Multiple exposure distributed lag models with variable selection. arXiv 2021, arXiv:2107.14567. [Google Scholar]
- Wilson, A.; Hsu, H.H.L.; Chiu, Y.H.M.; Wright, R.O.; Wright, R.J.; Coull, B.A. Kernel Machine and Distributed Lag Models for Assessing Windows of Susceptibility to Environmental Mixtures in Children’s Health Studies. Ann. Appl. Stat. 2021, in press.
- Liu, J.Z.; Lee, J.; Lin, P.I.D.; Valeri, L.; Christiani, D.C.; Bellinger, D.C.; Wright, R.O.; Mazumdar, M.M.; Coull, B.A. A Cross-validated Ensemble Approach to Robust Hypothesis Testing of Continuous Nonlinear Interactions: Application to Nutrition-Environment Studies. arXiv 2019, arXiv:1904.10918. [Google Scholar] [CrossRef]
- Mork, D.; Wilson, A. Estimating perinatal critical windows of susceptibility to environmental mixtures via structured Bayesian regression tree pairs. arXiv 2021, arXiv:2102.09071. [Google Scholar] [CrossRef] [PubMed]
- Mork, D.; Wilson, A. Treed distributed lag nonlinear models. arXiv 2021, arXiv:2010.06147. [Google Scholar] [CrossRef] [PubMed]
- Mork, D.; Kioumourtzoglou, M.-A.; Weisskopf, M.; Coull, B.A.; Wilson, A. Heterogeneous Distributed Lag Models to Estimate Personalized Effects of Maternal Exposures to Air Pollution. arXiv 2021, arXiv:2109.13763. [Google Scholar]
- Gennings, C.; Curtin, P.; Bello, G.; Wright, R.; Arora, M.; Austin, C. Lagged WQS regression for mixtures with many components. Environ. Res. 2020, 186, 109529. [Google Scholar] [CrossRef]
- Antonelli, J.; Mazumdar, M.; Bellinger, D.; Christiani, D.; Wright, R.; Coull, B. Estimating the health effects of environmental mixtures using Bayesian semiparametric regression and sparsity inducing priors. Ann. Appl. Stat. 2020, 14, 257–275. [Google Scholar] [CrossRef] [Green Version]
- Tanner, E.M.; Bornehag, C.-G.; Gennings, C. Repeated holdout validation for weighted quantile sum regression. MethodsX 2019, 6, 2855–2860. [Google Scholar] [CrossRef]
- Sonabend, A.; Zhang, J.; Schwartz, J.; Coull, B.A.; Lu, J. Scalable Gaussian Process Regression Via Median Posterior Inference for Estimating Multi-Pollutant Mixture Health Effects. Available online: https://slideslive.com/38940890/scalable-gaussian-process-regression-via-median-posterior-inference-for-estimating-multipollutant-mixture-health-effects (accessed on 16 November 2021).
- Feldman, J.; Kowal, D. A Bayesian Framework for Generation of Fully Synthetic Mixed Datasets. arXiv 2021, arXiv:2102.08255. [Google Scholar]
- Kowal, D. Bayesian subset selection and variable importance for interpretable prediction and classification. arXiv 2021, arXiv:2104.10150. [Google Scholar]
- Kowal, D.R.; Bravo, M.; Leong, H.; Bui, A.; Griffin, R.J.; Ensor, K.B.; Miranda, M.L. Bayesian variable selection for understanding mixtures in environmental exposures. Stat. Med. 2021, 40, 4850–4871. [Google Scholar] [CrossRef] [PubMed]
- Kowal, D.R. Fast, Optimal, and Targeted Predictions Using Parameterized Decision Analysis. J. Am. Stat. Assoc. 2021, 1–12. [Google Scholar] [CrossRef]
- Schedler, J.C.; Ensor, K.B. A spatiotemporal case-crossover model of asthma exacerbation in the City of Houston. Stat 2021, 10, e357. [Google Scholar] [CrossRef]
- Actkinson, B.; Ensor, K.; Griffin, R.J. SIBaR: A new method for background quantification and removal from mobile air pollution measurements. Atmos. Meas. Tech. 2021, 14, 5809–5821. [Google Scholar] [CrossRef]
- Li, H. Mvnimpute. Available online: https://github.com/hli226/mvnimpute (accessed on 16 November 2021).
- Chen, H.Y. Statistical inference on explained variation in high-dimensional linear model with dense effects. arXiv 2022, arXiv:2201.08723. [Google Scholar]
- Chen, H.Y. Semiparametric Odds Ratio Model and Its Applications; Chapman and Hall/CRC: Boca Raton, FL, USA, 2022. [Google Scholar]
- Chen, H.Y.; Li, H.; Argos, M.; Persky, V.; Turyk, M. Statistical methods for assessing explained variations of a health outcome by mixtures of exposures. Prep. Spec. Issue Int. J. Environ. Res. Public Health 2022. [Google Scholar]
- Tanner, E.; Lee, A.; Colicino, E. Environmental mixtures and children’s health: Identifying appropriate statistical approaches. Curr. Opin. Pediatr. 2020, 32, 315–320. [Google Scholar] [CrossRef]
- Hamra, G.B.; Buckley, J.P. Environmental exposure mixtures: Questions and methods to address them. Curr. Epidemiol. Rep. 2018, 5, 160–165. [Google Scholar] [CrossRef]
- Gibson, E.A.; Nunez, Y.; Abuawad, A.; Zota, A.R.; Renzetti, S.; Devick, K.L.; Gennings, C.; Goldsmith, J.; Coull, B.A.; Kioumourtzoglou, M.A. An overview of methods to address distinct research questions on environmental mixtures: An application to persistent organic pollutants and leukocyte telomere length. Environ. Health 2019, 18, 76. [Google Scholar] [CrossRef] [Green Version]
- Davalos, A.D.; Luben, T.J.; Herring, A.H.; Sacks, J.D. Current approaches used in epidemiologic studies to examine short-term multipollutant air pollution exposures. Ann. Epidemiol. 2017, 27, 145–153.e1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carrico, C.; Gennings, C.; Wheeler, D.C.; Factor-Litvak, P. Characterization of Weighted Quantile Sum Regression for Highly Correlated Data in a Risk Analysis Setting. J. Agric. Biol. Environ. Stat. 2015, 20, 100–120. [Google Scholar] [CrossRef] [PubMed]
- Keil, A.P.; Buckley, J.P.; O’Brien, K.M.; Ferguson, K.K.; Zhao, S.; White, A.J. A Quantile-Based g-Computation Approach to Addressing the Effects of Exposure Mixtures. Environ. Health Perspect. 2020, 128, 47004. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bobb, J.F.; Valeri, L.; Claus Henn, B.; Christiani, D.C.; Wright, R.O.; Mazumdar, M.; Godleski, J.J.; Coull, B.A. Bayesian kernel machine regression for estimating the health effects of multi-pollutant mixtures. Biostatistics 2015, 16, 493–508. [Google Scholar] [CrossRef]
- Wood, S. Generalized Additive Models: An Introduction with R; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Yang, J.; Benyamin, B.; McEvoy, B.P.; Gordon, S.; Henders, A.K.; Nyholt, D.R.; Madden, P.A.; Heath, A.C.; Martin, N.G.; Montgomery, G.W.; et al. Common SNPs explain a large proportion of the heritability for human height. Nat. Genet. 2010, 42, 565–569. [Google Scholar] [CrossRef] [Green Version]
- Janson, L.; Barber, R.F.; Candes, E. EigenPrism: Inference for high dimensional signal-to-noise ratios. J. R. Stat. Soc. Ser. B Stat. Methodol. 2017, 79, 1037–1065. [Google Scholar] [CrossRef] [Green Version]
- De Vito, R.; Bellio, R.; Trippa, L.; Parmigiani, G. Bayesian multi-study factor analysis for high-throughput biological data. arXiv 2018, arXiv:1806.09896. [Google Scholar]
- De Vito, R.; Bellio, R. Multi-Study Factor Analysis (MSFA). Biometrics 2019, 75, 337–346. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharya, A.; Dunson, D.B. Sparse Bayesian infinite factor models. Biometrika 2011, 98, 291–306. [Google Scholar] [CrossRef]
- Tikhonov, G.; Opedal, O.H.; Abrego, N.; Lehikoinen, A.; de Jonge, M.M.J.; Oksanen, J.; Ovaskainen, O. Joint species distribution modelling with the r-package Hmsc. Methods Ecol. Evol. 2020, 11, 442–447. [Google Scholar] [CrossRef]
- Papastamoulis, P.; Ntzoufras, I. On the identifiability of Bayesian factor analytic models. arXiv 2020, arXiv:2004.05105. [Google Scholar]
- Mardia, K.V.; Kent, J.T.; Bibby, J.M. Multivariate Analysis; Academic Press: San Diego, CA, USA, 1979. [Google Scholar]
- Wang, C.; Jiang, B.; Zhu, L. Penalized interaction estimation for ultrahigh dimensional quadratic regression. arXiv 2019, arXiv:1901.07147. [Google Scholar] [CrossRef]
- Hao, N.; Feng, Y.; Zhang, H.H. Model Selection for High-Dimensional Quadratic Regression via Regularization. J. Am. Stat. Assoc. 2018, 113, 615–625. [Google Scholar] [CrossRef] [Green Version]
- Haris, A.; Witten, D.; Simon, N. Convex Modeling of Interactions with Strong Heredity. J. Comput. Graph. Stat. 2016, 25, 981–1004. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bien, J.; Taylor, J.; Tibshirani, R. A Lasso for Hierarchical Interactions. Ann. Stat. 2013, 41, 1111–1141. [Google Scholar] [CrossRef]
- Bravo, M.A.; Miranda, M.L. Effects of accumulated environmental, social and host exposures on early childhood educational outcomes. Environ. Res. 2021, 198, 111241. [Google Scholar] [CrossRef]
- McGee, G.; Wilson, A.; Coull, B.A.; Webster, T.F. Incorporating biological knowledge in analyses of environmental mixtures. arXiv 2022. forthcoming. [Google Scholar]
- Buckley, J.P.; Hamra, G.B.; Braun, J.M. Statistical Approaches for Investigating Periods of Susceptibility in Children’s Environmental Health Research. Curr. Environ. Health Rep. 2019, 6, 1–7. [Google Scholar] [CrossRef]
- Gasparrini, A. Distributed Lag Linear and Non-Linear Models in R: The Package dlnm. J. Stat. Softw. 2011, 43, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Sanchez, B.N.; Hu, H.; Litman, H.J.; Tellez-Rojo, M.M. Statistical methods to study timing of vulnerability with sparsely sampled data on environmental toxicants. Environ. Health Perspect. 2011, 119, 409–415. [Google Scholar] [CrossRef]
- Bello, G.A.; Arora, M.; Austin, C.; Horton, M.K.; Wright, R.O.; Gennings, C. Extending the Distributed Lag Model framework to handle chemical mixtures. Environ. Res. 2017, 156, 253–264. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.H.; Bobb, J.F.; Lee, K.H.; Gennings, C.; Claus Henn, B.; Bellinger, D.; Austin, C.; Schnaas, L.; Tellez-Rojo, M.M.; Hu, H.; et al. Lagged kernel machine regression for identifying time windows of susceptibility to exposures of complex mixtures. Biostatistics 2018, 19, 325–341. [Google Scholar] [CrossRef] [PubMed]
- Webster, T.F.; Weisskopf, M.G. Epidemiology of exposure to mixtures: We can’t be casual about causail;ty when using or testing methods. arXiv 2020, arXiv:2007.01370. [Google Scholar]
- Bobb, J.F.; Claus Henn, B.; Valeri, L.; Coull, B.A. Statistical software for analyzing the health effects of multiple concurrent exposures via Bayesian kernel machine regression. Environ. Health 2018, 17, 67. [Google Scholar] [CrossRef] [Green Version]
- Peruzzi, M. Multi-Outcome Meshed Gaussian Processes on Projected Inputs for Scalable Inference with Exposome Data. Available online: https://www.isglobal.org/documents/10179/9117539/1_Topic5_Michele_Peruzzi.pdf/30c5e893-f2da-4452-b2c4-a3e075425b77 (accessed on 16 December 2021).
- Environmental Mixtures Workshop: Applications in Environmental Health Studies. Available online: http://www.publichealth.columbia.edu/research/precision-prevention/workshop-analyzing-mixtures-environmental-health-studies (accessed on 16 November 2021).



{kind=link}
{kind=link}
| Project (Institutions(s)) 1 | Summary | Exposures 2 | Study Populations 3 |
|---|---|---|---|
| Development and testing of response surface methods for investigating the epidemiology of exposure to mixtures (BU/Harvard) | Combines aspects of response surface modeling with index methods into the Bayesian Multiple Index Method (BMIM) and incorporates toxicological information. Special cases are a single index model and a full response surface of all exposures as in BKMR. | Dioxin-like compounds, PCBs, phthalates, parabens, bisphenols triclosan, UV filters, BFRs, PBDEs | RCC, EARTH |
| Principal Component Pursuit to assess exposure to environmental mixtures in epidemiologic studies (Columbia) | Adapts the method Principal Component Pursuit (PCP), used in computer vision applications, to the epidemiologic setting of mixtures of environmental pollutants. | PCBs, metals, air pollution | CHDS, CCCEH, SHS, SPARCS |
| Structured nonparametric methods for mixtures of exposures (Duke) | Incorporates chemical structure data and mechanistic constraints into nonparametric Bayesian regression methods to improve stability, performance, and interpretation in estimating dose response. Supplemental funding develops Bayesian modeling frameworks for including exposures in epidemiological models of infectious disease spread, as well as flexible spatiotemporal modeling with applications to study exposure effects on COVID-19 hospitalizations. | Phenols, OPs, perchlorate, PFCs, phthalates, BFRs, PAHs, pyrethroids, air pollutants | MSSM, NHANES, CHAMACOS, CLEAR, CDC COVID Data Tracker, NYTimes COVID Data, State Population by Characteristics |
| Methods for data integration and risk assessment for environmental mixtures (MSSM/Harvard) | Integrates temporally resolved exposure into models, evaluates how early (“priming” or “protective”) exposures can impact susceptibility to later exposures, and estimates regulatory guideline values for mixtures. | Tooth metal biomarkers; EDCs, dietary data | Colorado birth data; SELMA |
| Bringing Modern Data Science Tools to Bear on Environmental Mixtures (Notre Dame/Rice) | Develops data architecture to capture complex spatial location data for families, environmental exposures, and social stressors that vary over time. Leverages modern data science by applying rapidly evolving techniques for architecting data combined with hierarchical Bayesian models with variable selection, spatial models, and machine learning algorithms to large-scale environmental mixture and social exposure datasets of direct importance to child outcomes. | Air pollution, lead, social stressors | Aggregate North Carolina birth records, blood lead surveillance data, and educational system data to social and environmental exposures |
| Innovative Methodologic Advances for Mixtures Research in Epidemiology (UI Chicago) | Adapts genomics approaches to evaluate the total main effects and interactions of chemical exposures. Applies novel multivariate models for analyzing the complex relationship between health outcomes, biological intermediates, and environmental pollutants. | POPs, PCBs, OCPs, BFRs, PFCs, dioxins, heavy metals | NHANES, GLFCS, HCHS/SOL |
| Project 1 | Method Acronym | Method Title | Summary | Reference |
|---|---|---|---|---|
| BU/ Harvard | BKMR-CMA | Bayesian Kernel Machine Regression-Causal Mediation Analysis | Performs a causal mediation analysis when exposure within the mediation framework is a mixture. Estimates a multivariate exposure response surface in a model for the mediator given exposure, and another for the outcome given the mediator and the outcome, both using BKMR. | [4] |
| BU/ Harvard | BMIM | Bayesian Multiple Index Model | Unifies exposure index models with the response surface method BKMR, allowing a spectrum of intermediate models of multiple indices. Models non-linear, non-additive relationships between indices and an outcome. Special cases are a single exposure index and a response surface of all exposures. | [5] |
| BU/ Harvard | DAG analysis | Use of causal methods for determining which exposures to include in a model | Applies directed acyclic graphs (DAGs) to determine inclusion of exposure variables. In some circumstances, including an exposure variable can increase bias. Determines causal relationships between exposures (or groups of exposures) and a health outcome. | [6] |
| Columbia | BN2MF | Bayesian Non-parametric non-negative Matrix Factorization | Matrix factorization that provides non-negative (and more interpretable) solutions for factors and loadings and uncertainty estimates for the estimated parameters. Used for exposure pattern identification, similar to PCP. | [7] |
| Columbia | PCP | Principal Component Pursuit | Unsupervised robust exposure pattern identification. Decomposes exposure matrix into a low-rank matrix (consistent patterns) and a sparse matrix (unique exposure events). Robust exposure pattern identification. | [8] |
| Duke | BAG | Bag of DAGs | A computationally efficient method to construct a class of non-stationary spatiotemporal processes in point-referenced geostatistical models. Accounts for uncertainty in directions of association over space and time by considering a mixture of direct acyclic graphs (DAGs) | [9] |
| Duke | BMC | Bayesian Matrix Completion for hypothesis testing | Bayesian inference about chemical activity on mean and variance of dose-response measurements accounting for sparsity of data. Used to characterize chemical activity and its uncertainty. | [10] |
| Duke | BS3FA | Bayesian partially supervised sparse and smooth factor analysis | Bayesian inference on how chemical structure relates to variation in dose-response measurements. Addresses how to jointly model structural variability in molecular features of a chemical and its dose-response profile. | [11] |
| Duke | FIN | Factor analysis for interactions | Bayesian factor analysis for inference on interactions. Estimates interactions between highly correlated chemical exposures and effect on health outcomes. | [12] |
| Duke | GIF-SIS | Generalized infinite factor model | Shrinkage prior to the loadings matrix of infinite factor models that incorporate meta covariates to inform the sparsity structure and has desirable shrinkage properties. Addresses how to incorporate a priori known structure among variables when fitting a member of the broad class of factorization models. | [13] |
| Duke | GL-GPs | Graph Laplacian based Gaussian Process | Gaussian process model with a covariance function that respects the geometry of highly restricted or nonlinear domains. Develops a covariance function for nonparametric regression that respects the intrinsic geometry of the domain without sacrificing computational tractability. | [14] |
| Duke | GriPS | Computational improvements for Bayesian multivariate regression models based on latent meshed gaussian processes | Computational improvements for Bayesian multivariate regression models based on latent Meshed Gaussian Processes. Addresses how to efficiently solve the big-n problem for GPs when the number of outcomes is large. | [15] |
| Duke | MixSelect | Identifying main effects and interactions among exposures using Gaussian processes | Identifies main effects and interactions among exposures using Gaussian processes. Addresses how to model potentially non-linear effects and high-order interactions of chemical exposures on health outcomes. | [16] |
| Duke | MrGap | Manifold Reconstruction via Gaussian Process | Local covariance Gaussian process model for estimating a manifold in high dimensional space from noisy data. Conducts inference on a low-dimensional, nonlinear manifold in high dimensional space when data are subject to measurement error. | [17] |
| Duke | PFA | Perturbed factor analysis | Factor analysis that captures common structure among groups of related observations. Distinguishes shared and group-specific covariance structure and expresses shared structure via a set of shared factors. | [18] |
| Duke | MatchAlign | Resolving rotational ambiguity in matrix sampling | Efficiently resolving rotational ambiguity in Bayesian matrix sampling with matching. Does inference on unidentifiable random matrices. | [19] |
| Duke | SPAMTREE | Spatial Multivariate Trees | Bayesian multivariate regression methods for big data using sparse treed Gaussian processes. Jointly models several imbalanced variables flexibly and scalably via GPs | [20] |
| MSSM/ Harvard | ACR | Acceptable Concentration Range model | New class of nonlinear statistical models for human data that incorporates and evaluates regulatory guideline values into analyses of health effects of exposure to chemical mixtures. Allows for human data to suggest points of departure for comparison to in vivo estimates from single chemicals. | [21] |
| MSSM/ Harvard | Mult DLAG | Multiple exposure distributed lag models with variable selection | A method to identify the presence of time-dependent interactions (interactions among chemical exposures experienced during different exposure windows) in a critical windows analysis. Identifies critical windows of exposure to multiple chemicals, and whether exposures experienced at different developmental windows interact with one another on a health outcome. | [22] |
| MSSM/ Harvard | BKMR-DLM | Bayesian Kernel Machine Regression-Distributed Lag Model | Develops distributed lag models for assessing critical windows of exposure associated with a mixture. The model simultaneously estimates a time-weighted combination of each exposure and estimates a multivariate exposures-response surface of these time-weighted exposures using BKMR. | [23] |
| MSSM/ Harvard | CVEK | Cross-validated kernel ensemble | Performs tests of interaction between two sets of exposures (i.e., two mixtures) while placing minimal assumptions on the main effects of each mixture. Asks whether one mixture (e.g., a collection of nutrients) modifies the effect of another (e.g., a metal mixture) as a whole. | [24] |
| MSSM/ Harvard | Bayes Tree Pairs | Bayesian Regression Tree Pairs | Estimates critical windows of susceptibility to an environmental mixture. Uses an additive ensemble of tree pairs to estimate main effects and interactions between time-resolved predictors with variable selection. | [25] |
| MSSM/ Harvard | DLMtree | Bayesian Treed Distributed Lab Models | Distributed lag linear and non-linear models. Method to improve the precision of critical window identification compared to methods that use spline or penalized spline basis functions. Interest focuses on identifying critical windows of exposure using data on a single exposure measured over time. | [26] |
| MSSM/ Harvard | Het-DLM | Heterogeneous distributed lag models | Methods for precision children’s environmental health—that is, methods to identify subject characteristics (child sex, maternal age, etc.) that modify distributed lag effects of exposure. Addresses which subjects exhibit the strongest associations with an exposure measured over multiple developmental windows, and whether the critical windows of exposure vary among subgroups. | [27] |
| MSSM/ Harvard | LWQS | Lagged Weighted Quantile Sum (WQS) regression | Uses a reverse distributed lag model for assessing critical windows of exposure associated with a mixture when the exposure temporal pattern differs across subjects. Can also incorporate strata-specific associations. Useful for identifying time-varying associations of a mixture effect and later life health/developmental outcomes. | [28] |
| MSSM/ Harvard | NLinteraction | Bayesian semiparametric regression with sparsity inducing priors | Estimates effects of environmental mixtures to allow for interactions of any order. Provides variable importance measures for both main effects and interactions among exposures within a mixture, while making minimal assumptions on the forms of those effects. | [29] |
| MSSM/ Harvard | RH-WQS | Repeated holdout Weighted Quantile Sum (WQS) regression | Generalizes WQS regression to include repeated holdout random data splits. Estimates a mixture effect using an empirically estimated weighted index. | [30] |
| MSSM/ Harvard | SGP-MPI | Scalable Gaussian Process regression via Median Posterior Inference | Takes a split-and-conquer strategy to fitting BKMR to big data. Yields summaries of the multivariate exposure-response surface, as well as variable importance measures of each individual exposure. | [31] |
| ND/Rice | BDS | Bayesian Data Synthesis | A Bayesian framework used to simulate fully synthetic datasets of mixed data types. The dataset may be comprised of mixed categorical, binary, count, and continuous datatypes. Can handle missing data and has customized metrics for attributing risk disclosure and other privacy concerns. | [32] |
| ND/Rice | BSSVI | Bayesian subset selection and variable importance for interpretable prediction and classification | Used to collect and summarize all near-optimal subset models to provide a complete predictive picture. Useful in the presence of correlated covariates, weak signals, and/or small sample sizes, where different subsets may be indistinguishable in their predictive accuracy. | [33] |
| ND/Rice | BVSM | Bayesian variable selection for understanding mixtures in environmental exposures | Variable selection via sparse summaries of a linear regression model. Given a Bayesian regression model with social and environmental covariates, addresses which variables matter most for predicting educational outcomes. | [34] |
| ND/Rice | FOTP | Fast, optimal, and targeted predictions using parameterized decision analysis | Computes targeted summaries and prediction for specific decision tasks. Given a target (or functional) of interest and a Bayesian model, constructs accurate, simple, and efficient predictions of future values or functionals of future values. Model summaries can be customized for each functionality. | [35] |
| ND/Rice | SCC | Spatiotemporal case-crossover | Presents a strategy for the case-crossover study design in a spatial-temporal setting. Incorporates a temporal case-crossover and a geometrically aware spatial random effect based on the Hausdorff distance. | [36] |
| ND/Rice | SiBAR | State Informed Background Removal | Computational technique to quantify ‘background’ versus ‘source influenced’ contributions to air pollutant time series. Addresses whether a hidden Markov model can be used and what the ‘background’ levels of pollutants are measured across an urban area. | [37] |
| UI Chicago | MVNimpute | Imputation of multivariate data by normal model | Implements multiple imputation to the data when there are missing and/or censored values. | [38] |
| UI Chicago | SPORM | Semi-Parametric Odds Ratio Model | Flexible semiparametric model for estimating complex relationship among multiple variables. Associations are modeled by odds ratio functions. | [14,39] |
| UI Chicago | TEV | Estimation and inference on the explained variation parameter | Estimates the explained variation of an outcome by a set of mixture pollutants. | [40,41] |
| Method Acronym 2 | Overall Effect Estimation | Toxic Agent Identification (Variable Selection) | Pattern Identification | A Priori Defined Groups | Interactions and Non-Linearities |
|---|---|---|---|---|---|
| FIN | X | X | X | X | |
| BSSVI | X | X | X | X | |
| SGP-MPI | X | X | X | ||
| RH-WQS | x | X | |||
| Mult DLAG | X | X | X | ||
| MatchAlign | X | X | X | ||
| LWQS | x | X | |||
| GriPS | X | X | X | ||
| DLMtree | X | X | X | ||
| DAG analysis | X | X | |||
| BVSM | X | X | X | ||
| BMIM | X | X | X | X | |
| BKMR-DLM | X | X | X | ||
| BKMR-CMA | X | X | X | X | |
| Bayes Tree Pairs | X | X | X | ||
| ACR | X | X | |||
| SPAMTREE | X | X | X | ||
| FOTP | X | X | X | ||
| BAG | X | X | X | ||
| TEV | X | X | |||
| SCC | X | ||||
| GL-GPs | X | X | |||
| BDS | X | X | |||
| SPORM | X | X | X | X | |
| SiBAR | X | X | |||
| BS3FA | X | X | |||
| NLinteraction | X | X | |||
| Het-DLM | X | ||||
| BMC | X | ||||
| PFA | X | ||||
| PCP | X | ||||
| MrGap | X | ||||
| MixSelect | X | ||||
| GIF-SIS | X | X | |||
| BN2MF | X | ||||
| CVEK | X | X |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joubert, B.R.; Kioumourtzoglou, M.-A.; Chamberlain, T.; Chen, H.Y.; Gennings, C.; Turyk, M.E.; Miranda, M.L.; Webster, T.F.; Ensor, K.B.; Dunson, D.B.; et al. Powering Research through Innovative Methods for Mixtures in Epidemiology (PRIME) Program: Novel and Expanded Statistical Methods. Int. J. Environ. Res. Public Health 2022, 19, 1378. https://doi.org/10.3390/ijerph19031378
Joubert BR, Kioumourtzoglou M-A, Chamberlain T, Chen HY, Gennings C, Turyk ME, Miranda ML, Webster TF, Ensor KB, Dunson DB, et al. Powering Research through Innovative Methods for Mixtures in Epidemiology (PRIME) Program: Novel and Expanded Statistical Methods. International Journal of Environmental Research and Public Health. 2022; 19(3):1378. https://doi.org/10.3390/ijerph19031378
Chicago/Turabian StyleJoubert, Bonnie R., Marianthi-Anna Kioumourtzoglou, Toccara Chamberlain, Hua Yun Chen, Chris Gennings, Mary E. Turyk, Marie Lynn Miranda, Thomas F. Webster, Katherine B. Ensor, David B. Dunson, and et al. 2022. "Powering Research through Innovative Methods for Mixtures in Epidemiology (PRIME) Program: Novel and Expanded Statistical Methods" International Journal of Environmental Research and Public Health 19, no. 3: 1378. https://doi.org/10.3390/ijerph19031378