
Assessment of Glucose Lowering Medications’ Effectiveness for Cardiovascular Clinical Risk Management of Real-World Patients with Type 2 Diabetes: Targeted Maximum Likelihood Estimation under Model Misspecification and Missing Outcomes
 , ,
, ,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Case Study with Real-World Data
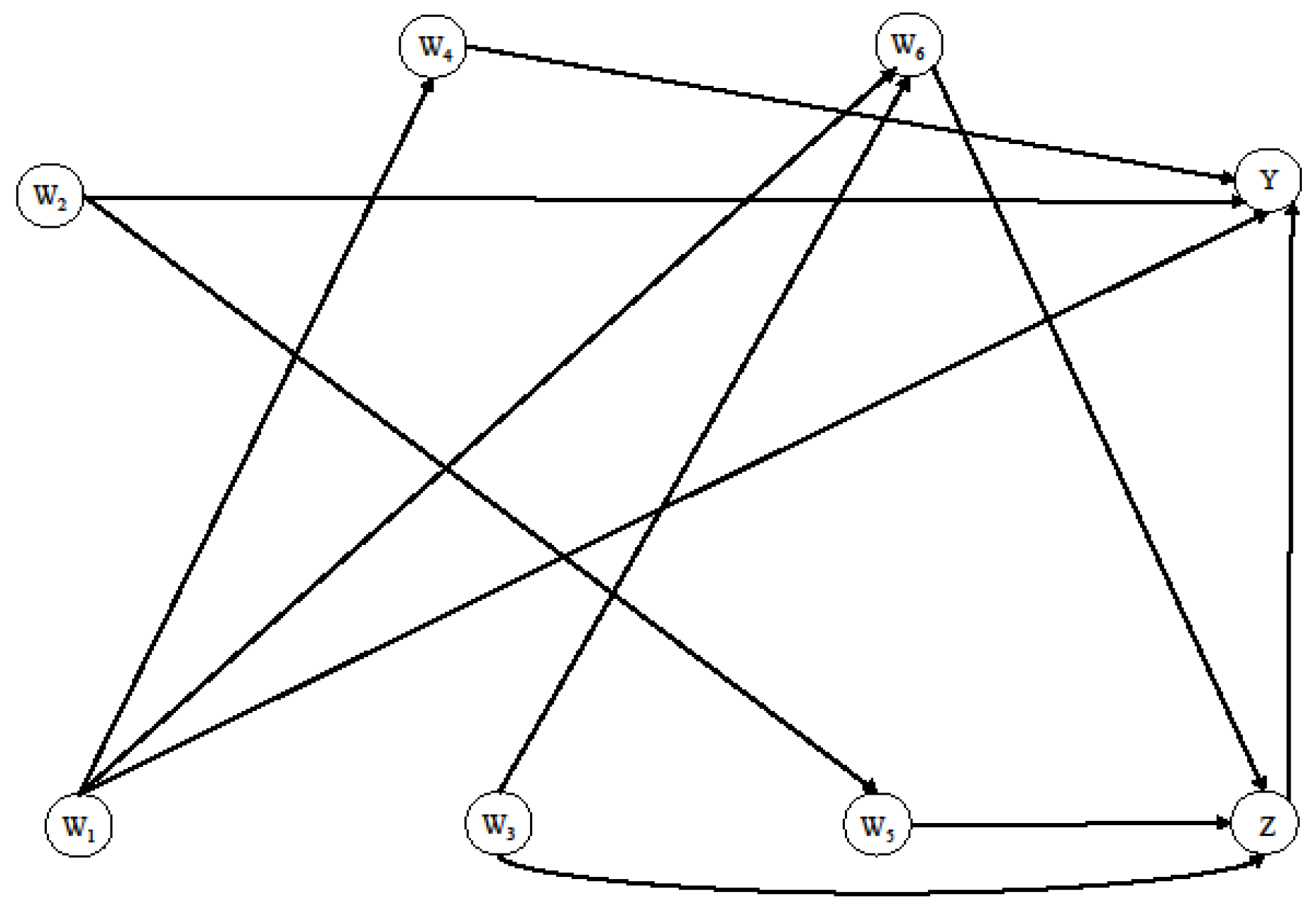
2.2. Simulation Study
- W1 ~ Bernoulli (0.6);
- W2 ~ Gaussian (mean = 60, sd = 8);
- W3 ~ Gaussian (mean = 35, sd = 6);
- W4 ~ Gaussian (mean = 90 if W1 = 1 and mean = 97 if W1 = 0, sd = 30),
- W5 ~ Bernoulli (plogis (−2 + 0.05 × W2));
- W6 ~ Bernoulli (plogis (−12 + 0.50 × W3 − W1));
- Z ~ Bernoulli (plogis (−2 + 0.05 × W3 − 0.20 × W5 + 0.10 × W6));
- Y ~ Bernoulli (plogis (−3 + Z − 0.05 × W2 + 0.05 × W4 − 0.80 × W1 − 0.20 × W1 × W2)), where plogis is the inverse logit function: 1/log[p/(1 − p)].
2.3. Statistical Methods
2.3.1. Logistic Regression for Covariate Adjustment (LR)
2.3.2. Propensity Score Based Methods: Adjustment, Matching, IPTW
2.3.3. Targeted Maximum Likelihood Estimator (TMLE)
3. Results
3.1. Case Study with Real-World Data
3.2. Simulation Study
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- American Diabetes Association. 10. Cardiovascular disease and risk management: Standards of Medical Care in Diabetes—2020. Diabetes Care 2020, 43 (Suppl. S1), S111–S134. [Google Scholar] [CrossRef] [Green Version]
- American Diabetes Association. Economic costs of diabetes in the US in 2017. Diabetes Care 2018, 41, 917–928. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wiviott, S.D.; Raz, I.; Bonaca, M.P.; Mosenzon, O.; Kato, E.T.; Cahn, A.; Silverman, M.G.; Zelniker, T.A.; Kuder, J.F.; Murphy, S.A.; et al. Dapagliflozin and cardiovascular outcomes in type 2 diabetes. N. Engl. J. Med. 2019, 380, 347–357. [Google Scholar] [CrossRef] [PubMed]
- Neal, B.; Perkovic, V.; Mahaffey, K.W.; de Zeeuw, D.; Fulcher, G.; Erondu, N.; Shaw, W.; Law, G.; Desai, M.; Matthews, D.R.; et al. Canagliflozin and Cardiovascular and Renal Events in Type 2 Diabetes. N. Engl. J. Med. 2017, 377, 644–657. [Google Scholar] [CrossRef] [PubMed]
- Holman, R.R.; Bethel, M.A.; Mentz, R.J.; Thompson, V.P.; Lokhnygina, Y.; Buse, J.B.; Chan, J.C.; Choi, J.; Gustavson, S.M.; Iqbal, N.; et al. Effects of Once-Weekly Exenatide on Cardiovascular Outcomes in Type 2 Diabetes. N. Engl. J. Med. 2017, 377, 1228–1239. [Google Scholar] [CrossRef] [PubMed]
- Marso, S.P.; Bain, S.C.; Consoli, A.; Eliaschewitz, F.G.; Jódar, E.; Leiter, L.A.; Lingvay, I.; Rosenstock, J.; Seufert, J.; Warren, M.L.; et al. Semaglutide and Cardiovascular Outcomes in Patients with Type 2 Diabetes. N. Engl. J. Med. 2016, 375, 1834–1844. [Google Scholar] [CrossRef] [Green Version]
- Marso, S.P.; Daniels, G.H.; Brown-Frandsen, K.; Kristensen, P.; Mann, J.F.E.; Nauck, M.A.; Nissen, S.E.; Pocock, S.; Poulter, N.R.; Ravn, L.S.; et al. Liraglutide and Cardiovascular Outcomes in Type 2 Diabetes. N. Engl. J. Med. 2016, 375, 311–322. [Google Scholar] [CrossRef] [Green Version]
- Zaccardi, F.; Dhalwani, N.N.; Dales, J.; Mani, H.; Khunti, K.; Davies, M.J.; Webb, D.R. Comparison of glucose-lowering agents after dual therapy failure in type 2 diabetes: A systematic review and network meta-analysis of randomized controlled trials. Diabetes Obes. Metab. 2018, 20, 985–997. [Google Scholar] [CrossRef]
- Campbell, J.E.; Drucker, D.J. Pharmacology, Physiology, and Mechanisms of Incretin Hormone Action. Cell Metab. 2013, 17, 819–837. [Google Scholar] [CrossRef] [Green Version]
- Vasilakou, D.; Karagiannis, T.; Athanasiadou, E.; Mainou, M.; Liakos, A.; Bekiari, E.; Sarigianni, M.; Matthews, D.R.; Tsapas, A. Sodium–glucose cotransporter 2 inhibitors for type 2 diabetes: A systematic review and meta-analysis. Ann. Intern. Med. 2013, 159, 262–274. [Google Scholar] [CrossRef] [Green Version]
- Fadini, G.P.; Simioni, N.; Frison, V.; Pos, M.D.; Bettio, M.; Rocchini, P.; Avogaro, A. Independent glucose and weight-reducing effects of Liraglutide in a real-world population of type 2 diabetic outpatients. Geol. Rundsch. 2013, 50, 943–949. [Google Scholar] [CrossRef]
- Fadini, G.P.; Sciannameo, V.; Franzetti, I.; Bottigliengo, D.; D’Angelo, P.; Vinci, C.; Berchialla, P.; Arena, S.; Buzzetti, R.; Avogaro, A.; et al. Similar effectiveness of dapagliflozin and GLP-1 receptor agonists concerning combined endpoints in routine clinical practice: A multicentre retrospective study. Diabetes Obes. Metab. 2019, 21, 1886–1894. [Google Scholar] [CrossRef] [PubMed]
- Sciannameo, V.; Berchialla, P.; Orsi, E.; Lamacchia, O.; Morano, S.; Querci, F.; Consoli, A.; Avogaro, A.; Fadini, G.P.; the DARWIN-T2D study. Enrolment criteria for diabetes cardiovascular outcome trials do not inform on generalizability to clinical practice: The case of glucagon-like peptide-1 receptor agonists. Diabetes, Obes. Metab. 2020, 22, 817–827. [Google Scholar] [CrossRef] [PubMed]
- Galimard, J.-E.; Chevret, S.; Curis, E.; Resche-Rigon, M. Heckman imputation models for binary or continuous MNAR outcomes and MAR predictors. BMC Med. Res. Methodol. 2018, 18, 90. [Google Scholar] [CrossRef]
- Fadini, G.P.; Zatti, G.; Consoli, A.; Bonora, E.; Sesti, G.; Avogaro, A.; DARWIN-T2D Network. Rationale and design of the DARWIN-T2D (DApagliflozin Real World evIdeNce in Type 2 Diabetes): A multicenter retrospective nationwide Italian study and crowdsourcing opportunity. Nutr. Metab. Cardiovasc. Dis. 2017, 27, 1089–1097. [Google Scholar] [CrossRef]
- Van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate imputation by chained equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef] [Green Version]
- Moons, K.G.; Donders, R.A.; Stijnen, T.; Harrell, F.E. Using the outcome for imputation of missing predictor values was preferred. J. Clin. Epidemiol. 2006, 59, 1092–1101. [Google Scholar] [CrossRef]
- Dong, Y.; Peng, C.-Y.J. Principled missing data methods for researchers. SpringerPlus 2013, 2, 222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jakobsen, J.C.; Gluud, C.; Wetterslev, J.; Winkel, P. When and how should multiple imputation be used for handling missing data in randomised clinical trials—A practical guide with flowcharts. BMC Med. Res. Methodol. 2017, 17, 162. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Buuren, S. Flexible Imputation of Missing Data; Chapman & Hall/CRC: Boca Raton, FL, USA, 2012. [Google Scholar]
- Sterne, J.A.C.; White, I.R.; Carlin, J.B.; Spratt, M.; Royston, P.; Kenward, M.G.; Wood, A.M.; Carpenter, J.R. Multiple imputation for missing data in epidemiological and clinical research: Potential and pitfalls. BMJ 2009, 338, b2393. [Google Scholar] [CrossRef] [PubMed]
- Groenwold, R.H.H.; Donders, A.R.T.; Roes, K.C.B.; Harrell, F.E.; Moons, K.G.M. Dealing With Missing Outcome Data in Randomized Trials and Observational Studies. Am. J. Epidemiol. 2011, 175, 210–217. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lewin, A.; Brondeel, R.; Benmarhnia, T.; Thomas, F.; Chaix, B. Attrition Bias Related to Missing Outcome Data: A Longitudinal Simulation Study. Epidemiology 2018, 29, 87–95. [Google Scholar] [CrossRef] [PubMed]
- Austin, P.C. An Introduction to Propensity Score Methods for Reducing the Effects of Confounding in Observational Studies. Multivar. Behav. Res. 2011, 46, 399–424. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rubin, D. Multiple Imputation for Nonresponse in Surveys; John Wiley and Sons: New York, NY, USA, 1987. [Google Scholar]
- De Vries, B.B.L.P.; Groenwold, R.H.H. A comparison of two approaches to implementing propensity score methods following multiple imputation. Epidemiol. Biostat. Public Health 2017, 14, e12630. [Google Scholar]
- Sofrygin, O.; van der Laan, M.J.; Neugebauer, R. Simcausal Package: Technical Details and Extended Examples of Simulations with Complex Longitudinal Data. Available online: http://cran.nexr.com/web/packages/simcausal/vignettes/simcausal_vignette.pdf (accessed on 19 March 2019).
- Luque-Fernandez, M.A.; Schomaker, M.; Rachet, B.; Schnitzer, M.E. Targeted maximum likelihood estimation for a binary treatment: A tutorial. Stat. Med. 2018, 37, 2530–2546. [Google Scholar] [CrossRef]
- Colombo, D.; Maathuis, M.H. Order-independent constraint-based causal structure learning. J. Mach. Learn. Res. 2014, 15, 3921–3962. [Google Scholar]
- Broom, B.M.; Do, K.-A.; Subramanian, D. Model averaging strategies for structure learning in Bayesian networks with limited data. BMC Bioinform. 2012, 13, S10. [Google Scholar] [CrossRef] [Green Version]
- Schouten, R.M.; Lugtig, P.; Vink, G. Generating missing values for simulation purposes: A multivariate amputation procedure. J. Stat. Comput. Simul. 2018, 88, 2909–2930. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 19 March 2019).
- Pang, M.; Schuster, T.; Filion, K.B.; Schnitzer, M.E.; Eberg, M.; Platt, R.W. Effect estimation in point-exposure studies with binary outcomes and high-dimensional covariate data–a comparison of targeted maximum likelihood estimation and inverse probability of treatment weighting. Int. J. Biostat. 2016, 12, 20150034. [Google Scholar] [CrossRef]
- Xie, Y.; Brand, J.E.; Jann, B. Estimating Heterogeneous Treatment Effects with Observational Data. Sociol. Methodol. 2012, 42, 314–347. [Google Scholar] [CrossRef]
- Greenland, S.; Pearl, J.; Robins, J.M. Confounding and collapsibility in causal inference. Stat. Sci. 1999, 14, 29–46. [Google Scholar] [CrossRef]
- Rubin, D.B. Estimating causal effects of treatments in randomized and nonrandomized studies. J. Educ. Psychol. 1974, 66, 688. [Google Scholar] [CrossRef]
- Rosenbaum, P.R.; Rubin, D.B. The Central Role of the Propensity Score in Observational Studies For Causal Effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Guo, S.; Fraser, M.W. Propensity Score Analysis: Statistical Methods and Applications, 2nd ed.; SAGE: Los Angeles, CA, USA, 2015. [Google Scholar]
- Lunceford, J.K.; Davidian, M. Stratification and weighting via the propensity score in estimation of causal treatment effects: A comparative study. Stat. Med. 2004, 23, 2937–2960. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar]
- Mallinckrodt, C.H.; Lane, P.; Schnell, D.; Peng, Y.; Mancuso, J.P. Recommendations for the Primary Analysis of Continuous Endpoints in Longitudinal Clinical Trials. Ther. Innov. Regul. Sci. 2008, 42, 303–319. [Google Scholar] [CrossRef]
- Ten Have, T.R.; Kunselman, A.R.; Pulkstenis, E.P.; Landis, J.R. Mixed effects logistic regression models. Biometrics 1998, 54, 367–383. [Google Scholar] [CrossRef]
- Van Der Laan, M.; Rose, S. Targeted Learning: Causal Inference for Observational and Experimental Data; Springer: New York, NY, USA, 2011. [Google Scholar]
- Neugebauer, R.; van der Laan, M. Why prefer double robust estimators in causal inference? J. Stat. Plan. Inference 2005, 129, 405–426. [Google Scholar] [CrossRef]
- Van der Laan, M.J.; Dudoit, S. Unified Cross-Validation Methodology for Selection among Estimators and a General Cross-Validated Adaptive Epsilon-Net Estimator: Finite Sample Oracle Inequalities and Examples; Technical report; Division of Biostatistics, University of California: Berkeley, CA, USA, 2003. [Google Scholar]
- Gruber, S.; van der Laan, M. tmle: An R package for targeted maximum likelihood estimation. J. Stat. Softw. 2012, 51, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Berchialla, P.; Lanera, C.; Sciannameo, V.; Gregori, D.; Baldi, I. Prediction of treatment outcome in clinical trials under a personalized medicine perspective. Sci. Rep. 2022, 12, 4115. [Google Scholar] [CrossRef]
- Van Der Laan, M.J.; Rubin, D. Targeted maximum likelihood learning. Int. J. Biostat. 2006, 2, 213. [Google Scholar] [CrossRef] [Green Version]
- Hernán, M.A. Causal analyses of existing databases: No power calculations required. J. Clin. Epidemiol. 2022, 144, 203–205. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Chi, G.Y.H. A method for testing a prespecified subgroup in clinical trials. Stat. Med. 2007, 26, 3535–3549. [Google Scholar] [CrossRef] [PubMed]
- Austin, P.C.; Grootendorst, P.; Normand, S.T.; Anderson, G.M. Conditioning on the propensity score can result in biased estimation of common measures of treatment effect: A Monte Carlo study. Stat. Med. 2007, 26, 754–768. [Google Scholar] [CrossRef] [PubMed]
- Gail, M.H.; Wieand, S.; Piantadosi, S. Biased estimates of treatment effect in randomized experiments with nonlinear regressions and omitted covariates. Biometrika 1984, 71, 431–444. [Google Scholar] [CrossRef]
- Schuler, M.S.; Rose, S. Targeted Maximum Likelihood Estimation for Causal Inference in Observational Studies. Am. J. Epidemiol. 2016, 185, 65–73. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rubin, D.B. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Kreif, N.; Gruber, S.; Radice, R.; Grieve, R.; Sekhon, J.S. Evaluating treatment effectiveness under model misspecification: A comparison of targeted maximum likelihood estimation with bias-corrected matching. Stat. Methods Med. Res. 2016, 25, 2315–2336. [Google Scholar] [CrossRef] [Green Version]
- Lendle, S.D.; Fireman, B.; Van Der Laan, M.J. Targeted maximum likelihood estimation in safety analysis. J. Clin. Epidemiol. 2013, 66, S91–S98. [Google Scholar] [CrossRef]
- Rombach, I.; Jenkinson, C.; Gray, A.M.; Murray, D.W.; Rivero-Arias, O. Comparison of statistical approaches for analyzing incomplete longitudinal patient-reported outcome data in randomized controlled trials. Patient Relat. Outcome Meas. 2018, 9, 197–209. [Google Scholar] [CrossRef]


{kind=link}
| Method | OR (95% CI) |
|---|---|
| LR | 0.82 (0.53−1.27) |
| PS matching | 0.86 (0.53−1.41) |
| PS covariate | 0.81 (0.52−1.26) |
| IPTW | 0.85 (0.54−1.34) |
| TMLE 1 (CC) | 1.33 (0.91−1.96) |
| TMLE 2 (CC) | 1.53 (1.09−2.14) |
| TMLE 1 (IPW) | 1.34 (0.95−1.91) |
| TMLE 2 (IPW) | 1.35 (1.04−1.73) |
| Model | |||
|---|---|---|---|
| Outcome (Y) | Treatment (Z) | ||
| Super Learner algorithms | |||
| LR | 0 | 0 | 0.09 |
| Step | 0.51 | 0.19 | 0 |
| Step + interaction terms | 0.12 | 0.10 | 0 |
| LR + interaction terms | 0 | 0 | 0 |
| GAM | 0.31 | 0 | 0.21 |
| RF | 0.03 | 0.53 | 0 |
| RPART | 0.03 | 0.18 | 0.70 |
| LR | PS Matching | PS Covariate | IPTW | TMLE1 (CC) | TMLE2 (CC) | TMLE1 (IPW) | TMLE2 (IPW) | |
|---|---|---|---|---|---|---|---|---|
| SCENARIO 1: 20% MNAR on Y, n = 1000 | ||||||||
| OR | 1.89 | 1.90 | 1.88 | 1.84 | 1.79 | 1.79 | 1.75 | 1.75 |
| Bias | 0.23 | 0.25 | 0.23 | 0.18 | 0.13 | 0.13 | 0.09 | 0.09 |
| SE | 0.67 | 0.84 | 0.68 | 0.66 | 0.58 | 0.58 | 0.58 | 0.57 |
| 95% NCI | 94.5 | 93.9 | 94.0 | 94.5 | 94.5 | 92.4 | 93.9 | 91.6 |
| SCENARIO 2: 40% MNAR on Y, n = 1000 | ||||||||
| OR | 2.06 | 2.07 | 2.05 | 2.00 | 1.97 | 1.98 | 1.92 | 1.94 |
| Bias | 0.40 | 0.41 | 0.39 | 0.34 | 0.31 | 0.32 | 0.26 | 0.28 |
| SE | 1.30 | 1.31 | 1.30 | 1.23 | 1.20 | 1.18 | 1.15 | 1.17 |
| 95% NCI | 94.2 | 96.0 | 94.6 | 95.5 | 94.9 | 92.4 | 94.2 | 91.2 |
| SCENARIO 3: 20% MNAR on Y, n = 5000 | ||||||||
| OR | 1.78 | 1.77 | 1.77 | 1.74 | 1.70 | 1.70 | 1.66 | 1.66 |
| Bias | 0.12 | 0.11 | 0.11 | 0.08 | 0.04 | 0.04 | 0.002 | 0.006 |
| SE | 0.25 | 0.28 | 0.25 | 0.25 | 0.22 | 0.22 | 0.22 | 0.22 |
| 95% NCI | 92.0 | 93.5 | 92.7 | 94.6 | 95.6 | 94.2 | 94.6 | 93.4 |
| SCENARIO 4: 40% MNAR on Y, n = 5000 | ||||||||
| OR | 1.78 | 1.79 | 1.78 | 1.74 | 1.73 | 1.73 | 1.68 | 1.68 |
| Bias | 0.12 | 0.13 | 0.12 | 0.08 | 0.07 | 0.07 | 0.02 | 0.02 |
| SE | 0.37 | 0.43 | 0.37 | 0.36 | 0.35 | 0.35 | 0.35 | 0.35 |
| 95% NCI | 95.2 | 95.6 | 95.1 | 95.7 | 95.8 | 94.8 | 96.1 | 95.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sciannameo, V.; Fadini, G.P.; Bottigliengo, D.; Avogaro, A.; Baldi, I.; Gregori, D.; Berchialla, P. Assessment of Glucose Lowering Medications’ Effectiveness for Cardiovascular Clinical Risk Management of Real-World Patients with Type 2 Diabetes: Targeted Maximum Likelihood Estimation under Model Misspecification and Missing Outcomes. Int. J. Environ. Res. Public Health 2022, 19, 14825. https://doi.org/10.3390/ijerph192214825
Sciannameo V, Fadini GP, Bottigliengo D, Avogaro A, Baldi I, Gregori D, Berchialla P. Assessment of Glucose Lowering Medications’ Effectiveness for Cardiovascular Clinical Risk Management of Real-World Patients with Type 2 Diabetes: Targeted Maximum Likelihood Estimation under Model Misspecification and Missing Outcomes. International Journal of Environmental Research and Public Health. 2022; 19(22):14825. https://doi.org/10.3390/ijerph192214825
Chicago/Turabian StyleSciannameo, Veronica, Gian Paolo Fadini, Daniele Bottigliengo, Angelo Avogaro, Ileana Baldi, Dario Gregori, and Paola Berchialla. 2022. "Assessment of Glucose Lowering Medications’ Effectiveness for Cardiovascular Clinical Risk Management of Real-World Patients with Type 2 Diabetes: Targeted Maximum Likelihood Estimation under Model Misspecification and Missing Outcomes" International Journal of Environmental Research and Public Health 19, no. 22: 14825. https://doi.org/10.3390/ijerph192214825