

PM2.5 Concentrations Variability in North China Explored with a Multi-Scale Spatial Random Effect Model


Abstract
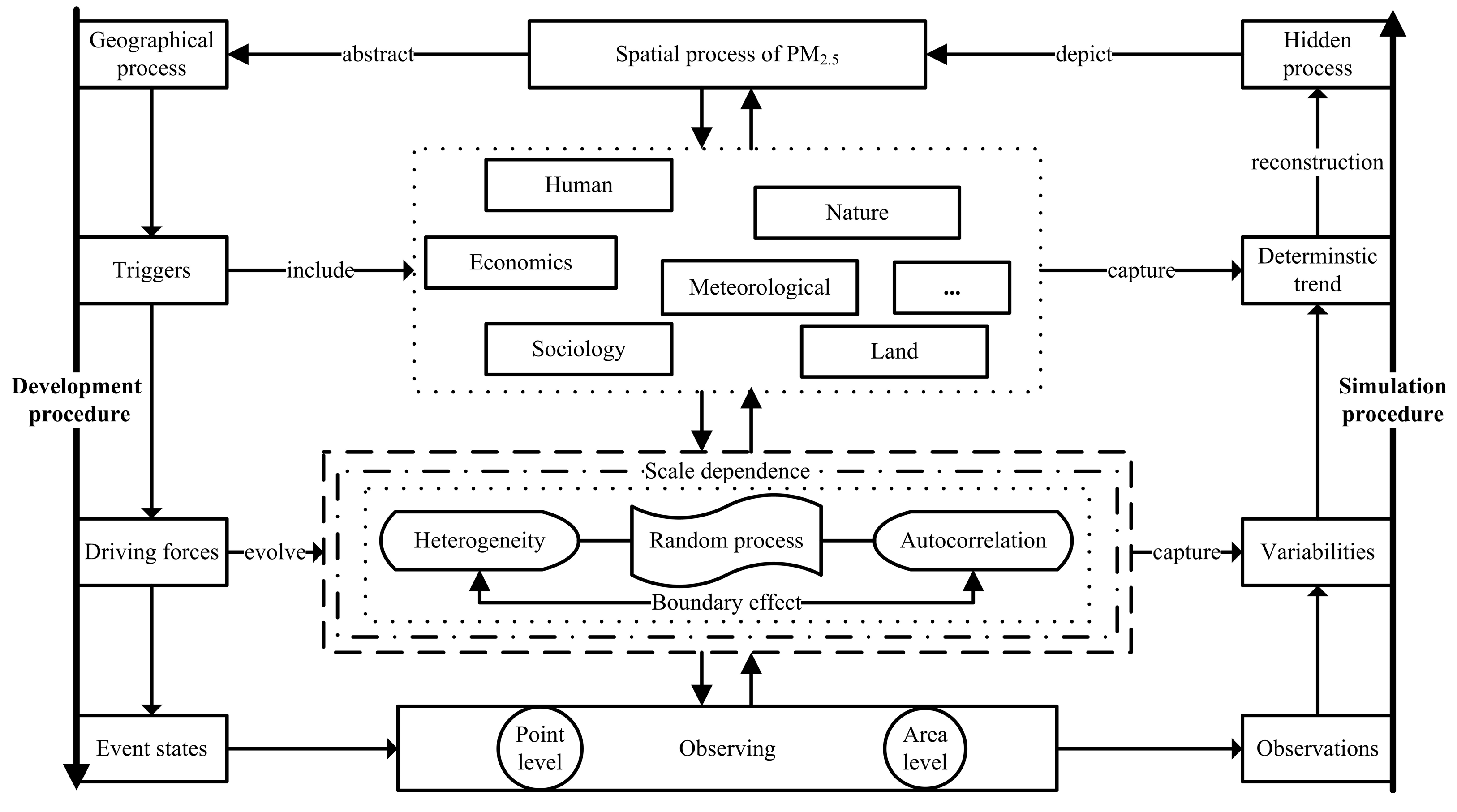
:1. Introduction
1.1. Classic Methods for Ground PM2.5 Concentrations
1.2. Scale-Dependent Variabilitie, and Spatial Correlation in an Integrated Model
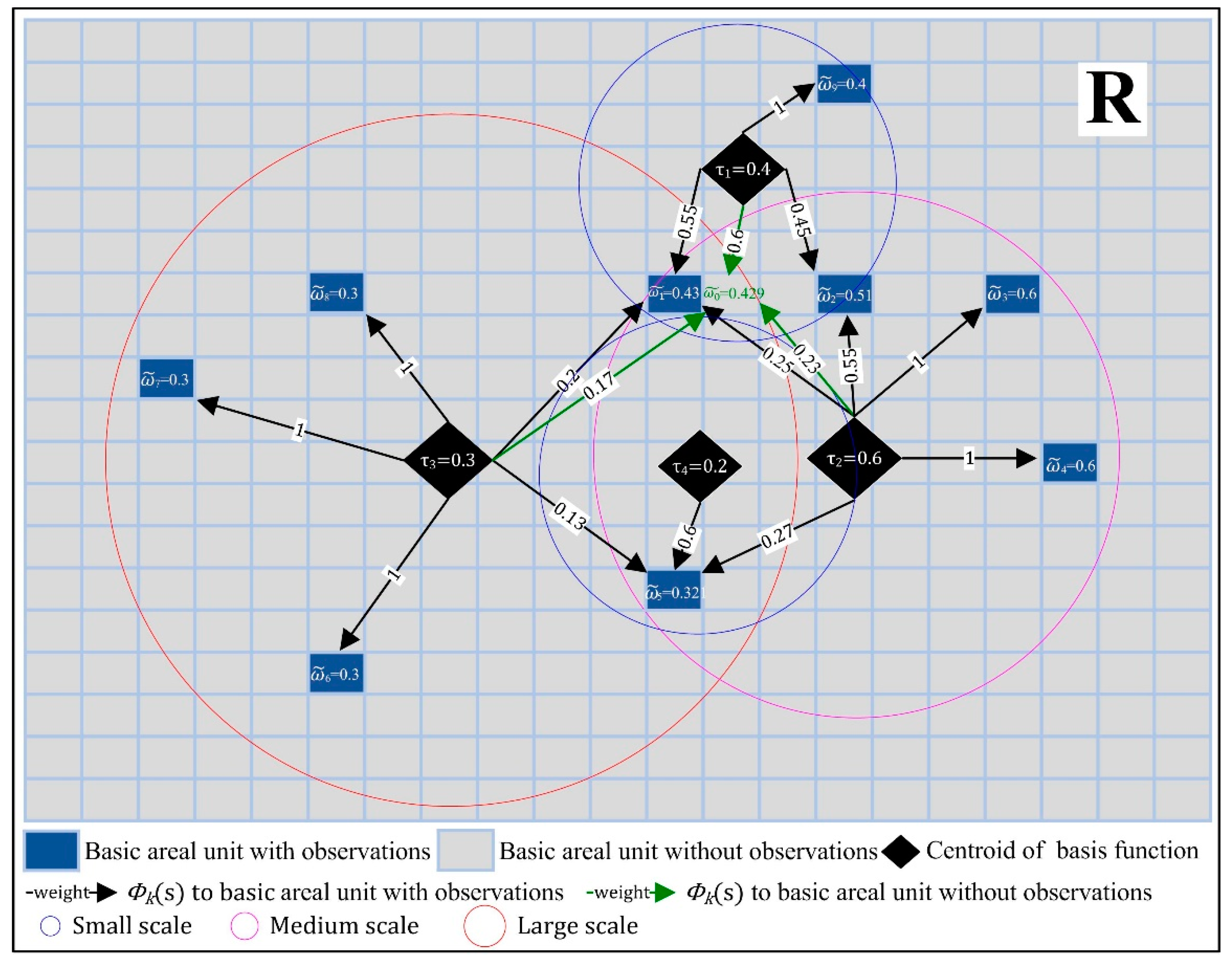
2. Statistical Modelling
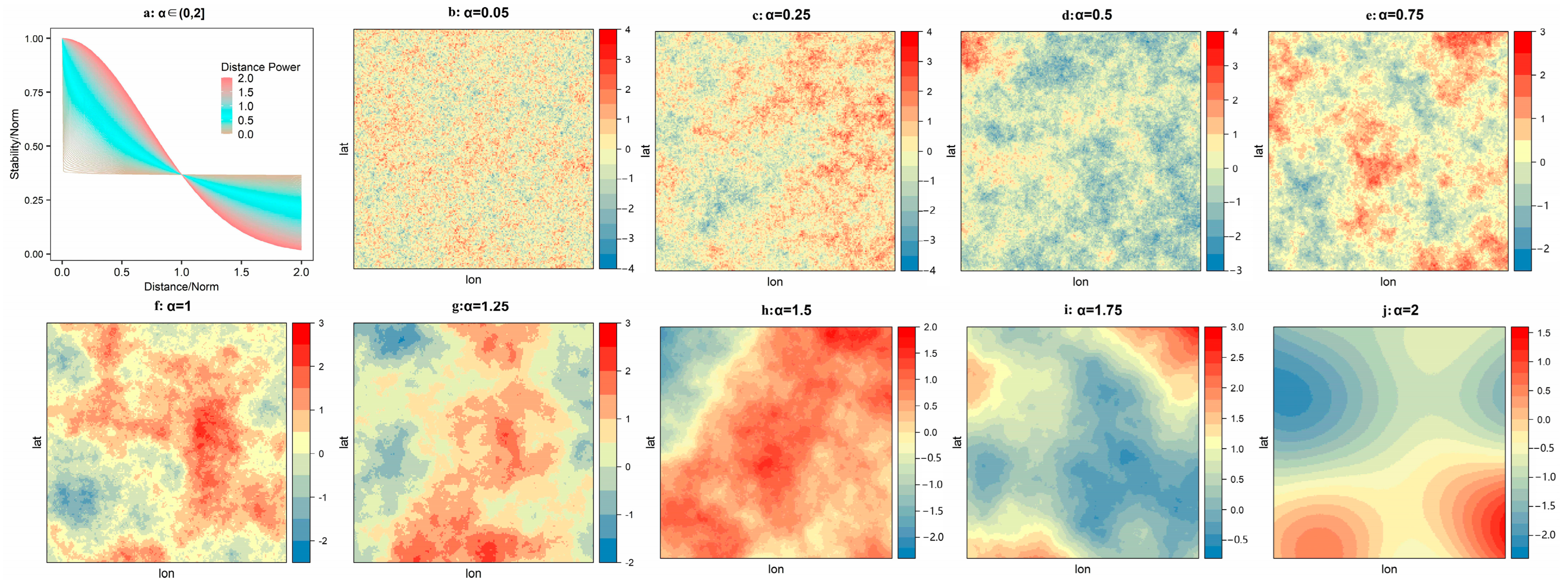
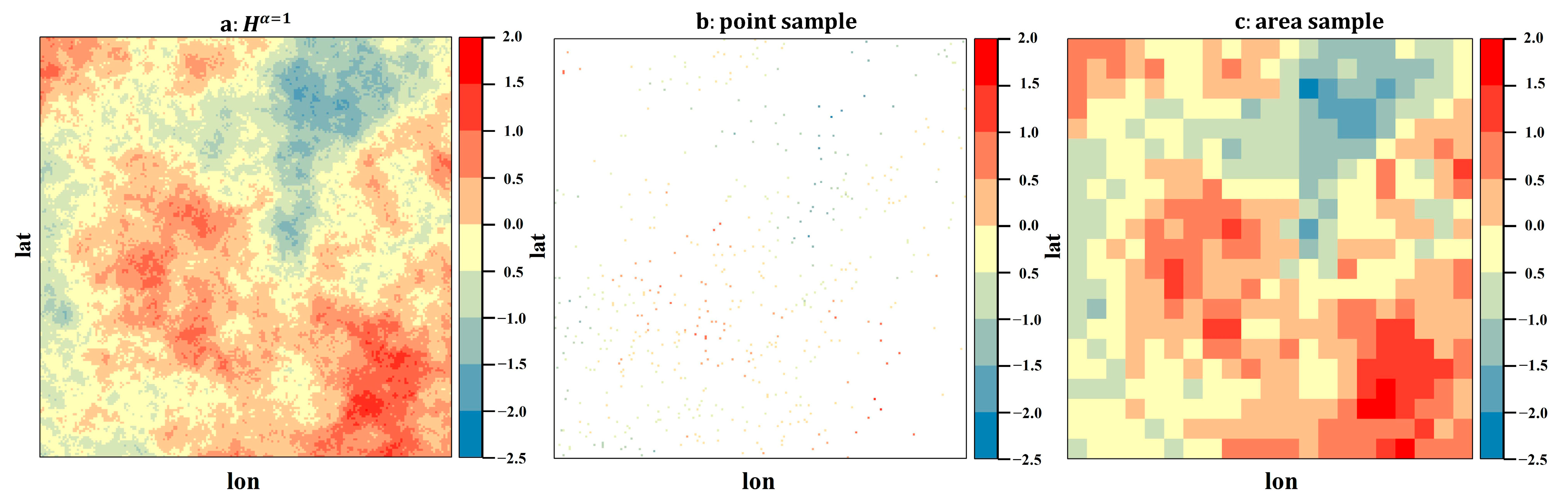
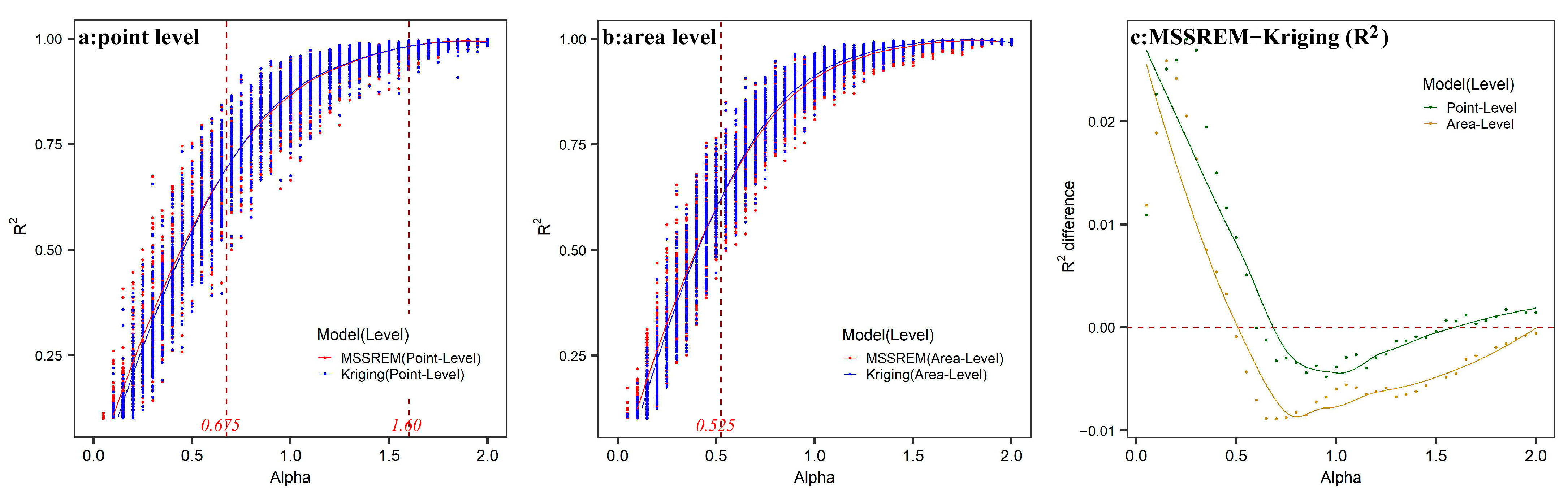
3. A Monte Carlo Simulation Experiment
4. Empirical Study
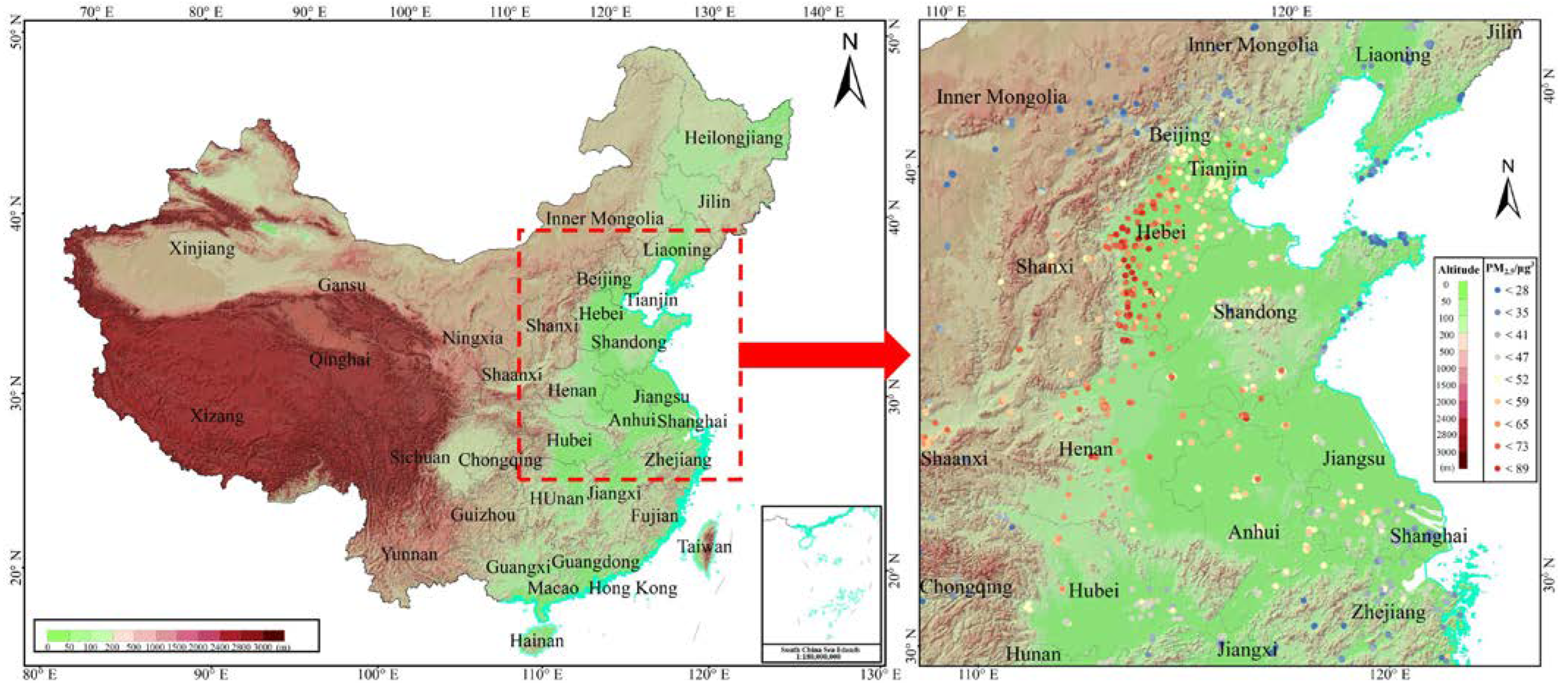
4.1. Study Area, Data Sources, and Variables
4.1.1. Study Area
4.1.2. Ground PM2.5 Concentrations
4.1.3. Independent Variables
4.2. Empirical Model Specification
4.3. Covariate Effects
4.4. Prediction Accuracy
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Masiol, M.; Hopke, P.; Felton, H.; Frank, B.; Rattigan, O.; Wurth, M.; LaDuke, G. Source apportionment of PM2.5 chemically speciated mass and particle number concentrations in New York City. Atmospheric Environ. 2017, 148, 215–229. [Google Scholar] [CrossRef]
- Gao, A.; Wang, J.; Luo, J.; Wang, P.; Chen, K.; Wang, Y.; Li, J.; Hu, J.; Kota, S.H.; Zhang, H. Health and economic losses attributable to PM2.5 and ozone exposure in Handan, China. Air Qual. Atmosphere Health 2021, 14, 605–615. [Google Scholar] [CrossRef]
- Yerramilli, A.; Dodla, V.B.R.; Challa, V.S.; Myles, L.; Pendergrass, W.R.; Vogel, C.A.; Dasari, H.P.; Tuluri, F.; Baham, J.M.; Hughes, R.L.; et al. An integrated WRF/HYSPLIT modeling approach for the assessment of PM2.5 source regions over the Mississippi Gulf Coast region. Air Qual. Atmosphere Health 2012, 5, 401–412. [Google Scholar] [CrossRef]
- Song, Y.; Huang, B.; He, Q.; Chen, B.; Wei, J.; Mahmood, R. Dynamic assessment of PM2.5 exposure and health risk using remote sensing and geo-spatial big data. Environ. Pollut. 2019, 253, 288–296. [Google Scholar] [CrossRef] [PubMed]
- de A. Albuquerque, T.T.D.A.; West, J.; Andrade, M.D.F.; Ynoue, R.Y.; Andreão, W.L.; dos Santos, F.S.; Maciel, F.M.; Pedruzzi, R.; Mateus, V.D.O.; Martins, J.A.; et al. Analysis of PM2.5 concentrations under pollutant emission control strategies in the metropolitan area of São Paulo, Brazil. Environ. Sci. Pollut. Res. 2019, 26, 33216–33227. [Google Scholar] [CrossRef]
- He, Q.; Huang, B. Satellite-based high-resolution PM2.5 estimation over the Beijing-Tianjin-Hebei region of China using an improved geographically and temporally weighted regression model. Environ. Pollut. 2018, 236, 1027–1037. [Google Scholar] [CrossRef] [PubMed]
- Dhakal, S.; Gautam, Y.; Bhattarai, A. Exploring a deep LSTM neural network to forecast daily PM2.5 concentration using meteorological parameters in Kathmandu Valley, Nepal. Air Qual. Atmosphere Health 2021, 14, 83–96. [Google Scholar] [CrossRef]
- Woody, M.; Wong, H.-W.; West, J.; Arunachalam, S. Multiscale predictions of aviation-attributable PM2.5 for U.S. airports modeled using CMAQ with plume-in-grid and an aircraft-specific 1-D emission model. Atmospheric Environ. 2016, 147, 384–394. [Google Scholar] [CrossRef]
- Yuan, W.; Wang, K.; Bo, X.; Tang, L.; Wu, J. A novel multi-factor & multi-scale method for PM2.5 concentration forecasting. Environ. Pollut. 2019, 255, 113187. [Google Scholar] [CrossRef]
- Trapp, S.; Matthies, M. Atmospheric Transport Models. In Chemodynamics and Environmental Modeling; Trapp, S., Matthies, M., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 107–114. [Google Scholar] [CrossRef]
- LeDuc, S.; Fine, S. Models-3/Community Multiscale Air Quality (CMAQ) Modeling System. In Air Pollution Modeling and Its Application XV; Borrego, C., Schayes, G., Eds.; Springer: Boston, MA, USA, 2004; pp. 307–310. [Google Scholar] [CrossRef]
- Skamarock, W.C.; Klemp, J.B. A time-split nonhydrostatic atmospheric model for weather research and forecasting applications. J. Comput. Phys. 2008, 227, 3465–3485. [Google Scholar] [CrossRef]
- Berrocal, V.J.; Gelfand, A.E.; Holland, D.M. Space-Time Data fusion Under Error in Computer Model Output: An Application to Modeling Air Quality. Biometrics 2012, 68, 837–848. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.; Katzfuss, M.; Cressie, N.; Braverman, A. Spatio-Temporal Data Fusion for Very Large Remote Sensing Datasets. Technometrics 2014, 56, 174–185. [Google Scholar] [CrossRef]
- Xing, J.; Mathur, R.; Pleim, J.; Hogrefe, C.; Gan, C.-M.; Wong, D.C.; Wei, C. Can a coupled meteorology–chemistry model reproduce the historical trend in aerosol direct radiative effects over the Northern Hemisphere? Atmospheric Chem. Phys. 2015, 15, 9997–10018. [Google Scholar] [CrossRef]
- Cressie, N. Mission CO2ntrol: A Statistical Scientist’s Role in Remote Sensing of Atmospheric Carbon Dioxide. J. Am. Stat. Assoc. 2018, 113, 152–168. [Google Scholar] [CrossRef]
- Banerjee, S.; Carlin, B.P.; Gelfand, A.E. Hierarchical Modeling and Analysis for Spatial Data; Chapman and Hall: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Wikle, C.K.; Zammit-Mangion, A.; Cressie, N. Spatio-Temporal Statistics with R; Chapman and Hall/CRC: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Yang, D.; Lu, D.; Xu, J.; Ye, C.; Zhao, J.; Tian, G.; Wang, X.; Zhu, N. Predicting spatio-temporal concentrations of PM2.5 using land use and meteorological data in Yangtze River Delta, China. Stoch. Hydrol. Hydraul. 2018, 32, 2445–2456. [Google Scholar] [CrossRef]
- Banks, A.; Kooperman, G.J.; Xu, Y. Meteorological Influences on Anthropogenic PM2.5 in Future Climates: Species Level Analysis in the Community Earth System Model v2. Earth’s Futur. 2022, 10, e2021EF002298. [Google Scholar] [CrossRef]
- Ji, X.; Yao, Y.; Long, X. What causes PM2.5 pollution? Cross-economy empirical analysis from socioeconomic perspective. Energy Policy 2018, 119, 458–472. [Google Scholar] [CrossRef]
- Ashayeri, M.; Abbasabadi, N.; Heidarinejad, M.; Stephens, B. Predicting intraurban PM2.5 concentrations using enhanced machine learning approaches and incorporating human activity patterns. Environ. Res. 2021, 196, 110423. [Google Scholar] [CrossRef]
- Mirzaei, M.; Bertazzon, S.; Couloigner, I.; Farjad, B.; Ngom, R. Estimation of local daily PM2.5 concentration during wildfire episodes: Integrating MODIS AOD with multivariate linear mixed effect (LME) models. Air Qual. Atmosphere Health 2020, 13, 173–185. [Google Scholar] [CrossRef]
- Gogikar, P.; Tripathy, M.R.; Rajagopal, M.; Paul, K.K.; Tyagi, B. PM2.5 estimation using multiple linear regression approach over industrial and non-industrial stations of India. J. Ambient Intell. Humaniz. Comput. 2021, 12, 2975–2991. [Google Scholar] [CrossRef]
- Wu, X.; He, S.; Guo, J.; Sun, W. A multi-scale periodic study of PM2.5 concentration in the Yangtze River Delta of China based on Empirical Mode Decomposition-Wavelet Analysis. J. Clean. Prod. 2021, 281, 124853. [Google Scholar] [CrossRef]
- Fotheringham, A.; Brunsdon, C.; Charlton, M. Geographically Weighted Regression: The Analysis of Spatially Varying Relationships; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Huang, B.; Wu, B.; Barry, M. Geographically and temporally weighted regression for modeling spatio-temporal variation in house prices. Int. J. Geogr. Inf. Sci. 2010, 24, 383–401. [Google Scholar] [CrossRef]
- Lu, B.; Brunsdon, C.; Charlton, M.; Harris, P. Geographically weighted regression with parameter-specific distance metrics. Int. J. Geogr. Inf. Sci. 2017, 31, 982–998. [Google Scholar] [CrossRef]
- Lu, B.; Yang, W.; Ge, Y.; Harris, P. Improvements to the calibration of a geographically weighted regression with parameter-specific distance metrics and bandwidths. Comput. Environ. Urban Syst. 2018, 71, 41–57. [Google Scholar] [CrossRef]
- Cressie, N.A.C. Statistics for Spatial Data; John Wiley & Sons: Hoboken, NJ, USA, 1993. [Google Scholar] [CrossRef]
- Dong, G.; Harris, R. Spatial Autoregressive Models for Geographically Hierarchical Data Structures. Geogr. Anal. 2015, 47, 173–191. [Google Scholar] [CrossRef]
- Diggle, P.J.; Tawn, J.A.; Moyeed, R.A. Model-based geostatistics. J. R. Stat. Soc. Ser. C 1998, 47, 299–350. [Google Scholar] [CrossRef]
- Paatero, P.; Hopke, P.K.; Hoppenstock, J.; Eberly, S.I. Advanced Factor Analysis of Spatial Distributions of PM2.5 in the Eastern United States. Environ. Sci. Technol. 2003, 37, 2460–2476. [Google Scholar] [CrossRef]
- Hajiloo, F.; Hamzeh, S.; Gheysari, M. Impact assessment of meteorological and environmental parameters on PM2.5 concentrations using remote sensing data and GWR analysis (case study of Tehran). Environ. Sci. Pollut. Res. 2019, 26, 24331–24345. [Google Scholar] [CrossRef]
- van Donkelaar, A.; Martin, R.V.; Spurr, R.J.D.; Burnett, R.T. High-Resolution Satellite-Derived PM2.5 from Optimal Estimation and Geographically Weighted Regression over North America. Environ. Sci. Technol. 2015, 49, 10482–10491. [Google Scholar] [CrossRef]
- Stafoggia, M.; Bellander, T.; Bucci, S.; Davoli, M.; de Hoogh, K.; Donato, F.D.; Gariazzo, C.; Lyapustin, A.; Michelozzi, P.; Renzi, M.; et al. Estimation of daily PM10 and PM2.5 concentrations in Italy, 2013–2015, using a spatiotemporal land-use random-forest model. Environ. Int. 2019, 124, 170–179. [Google Scholar] [CrossRef]
- Wei, J.; Li, Z.; Cribb, M.; Huang, W.; Xue, W.; Sun, L.; Guo, J.; Peng, Y.; Li, J.; Lyapustin, A.; et al. Improved 1 km resolution PM2.5 estimates across China using enhanced space–time extremely randomized trees. Atmospheric Chem. Phys. 2020, 20, 3273–3289. [Google Scholar] [CrossRef]
- Schneider, R.; Vicedo-Cabrera, A.M.; Sera, F.; Masselot, P.; Stafoggia, M.; de Hoogh, K.; Kloog, I.; Reis, S.; Vieno, M.; Gasparrini, A. A Satellite-Based Spatio-Temporal Machine Learning Model to Reconstruct Daily PM2.5 Concentrations across Great Britain. Remote Sens. 2020, 12, 3803. [Google Scholar] [CrossRef]
- Dong, G.; Ma, J.; Lee, D.; Chen, M.; Pryce, G.; Chen, Y. Developing a Locally Adaptive Spatial Multilevel Logistic Model to Analyze Ecological Effects on Health Using Individual Census Records. Ann. Am. Assoc. Geogr. 2020, 110, 739–757. [Google Scholar] [CrossRef]
- Cressie, N.; Johannesson, G. Fixed rank kriging for very large spatial data sets. J. R. Stat. Soc. Ser. B 2008, 70, 209–226. [Google Scholar] [CrossRef]
- Nguyen, H.; Cressie, N.; Braverman, A. Spatial Statistical Data Fusion for Remote Sensing Applications. J. Am. Stat. Assoc. 2012, 107, 1004–1018. [Google Scholar] [CrossRef]
- Kang, E.L.; Liu, D.; Cressie, N. Statistical analysis of small-area data based on independence, spatial, non-hierarchical, and hierarchical models. Comput. Stat. Data Anal. 2009, 53, 3016–3032. [Google Scholar] [CrossRef]
- Kang, E.L.; Cressie, N. Bayesian Inference for the Spatial Random Effects Model. J. Am. Stat. Assoc. 2011, 106, 972–983. [Google Scholar] [CrossRef]
- Sengupta, A.; Cressie, N. Hierarchical statistical modeling of big spatial datasets using the exponential family of distributions. Spat. Stat. 2013, 4, 14–44. [Google Scholar] [CrossRef]
- Vali, M.; Hassanzadeh, J.; Mirahmadizadeh, A.; Hoseini, M.; Dehghani, S.; Maleki, Z.; Méndez-Arriaga, F.; Ghaem, H. Effect of meteorological factors and Air Quality Index on the COVID-19 epidemiological characteristics: An ecological study among 210 countries. Environ. Sci. Pollut. Res. 2021, 28, 53116–53126. [Google Scholar] [CrossRef]
- Zhou, H.; Jiang, M.; Huang, Y.; Wang, Q. Directional spatial spillover effects and driving factors of haze pollution in North China Plain. Resour. Conserv. Recycl. 2021, 169, 105475. [Google Scholar] [CrossRef]
- Zammit-Mangion, A.; Cressie, N. FRK: An R Package for Spatial and Spatio-Temporal Prediction with Large Datasets. J. Stat. Softw. 2021, 98, 1–48. [Google Scholar] [CrossRef]
- Kirk-Davidoff, D. The Greenhouse Effect, Aerosols, and Climate Change. In Green Chemistry; Török, B., Dransfield, T., Eds.; Elsevier: Amsterdam, The Netherlands, 2018; pp. 211–234. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Domain | Variable | Content | Unit | Spatial Resolution | Data Source | Computing Method |
|---|---|---|---|---|---|---|
| PM2.5 | P | Particulate Matter ≤ 2.5 µm | µg m−3 | In Situ | AQICN | Denoising |
| Meteorology | TEM | 2 m air temperature | K | 0.1° × 0.1° | CMA | Interpolation |
| RLH | Relative humidity | % | 0.1° × 0.1° | CMA | Interpolation | |
| CPP | Cumulative precipitation | Mm | 0.1° × 0.1° | CMA | Interpolation | |
| WDS | 10 m wind speed | m s−1 | 0.1° × 0.1° | CMA | Interpolation | |
| Land use | WGD | Woodland–grassland density | % | 0.1° × 0.1° | CNLUCC | Kernel Density |
| CSD | Construction land density | % | 0.1° × 0.1° | CNLUCC | Kernel Density | |
| UUD | Unused land density | % | 0.1° × 0.1° | CNLUCC | Kernel Density | |
| CTD | Cultivated land density | % | 0.1° × 0.1° | CNLUCC | Kernel Density | |
| Altitude | DEM | DEM | M | 0.1° × 0.1° | SRTM-V4.1 | Denoising |
| Human activity | IED | Industry–enterprise density | % | 0.1° × 0.1° | Amap | Kernel Density |
| RND | Road network density | % | 0.1° × 0.1° | Amap | Quadrat Sample | |
| NTL | Night-time lights | W cm−2 sr−1 | 0.1° × 0.1° | NPP-VIIRS | Denoising |
| DataDomain | Variables | Coefficients | Standard Error | t-Value * | p-Value |
|---|---|---|---|---|---|
| Meteorology | TEM | 0.287 | 0.011 | 26.534 | 0.000 |
| RLH | −0.411 | 0.046 | 8.846 | 0.000 | |
| CPP | −1.947 | 0.069 | 28.159 | 0.000 | |
| WDS | −0.988 | 0.056 | 17.497 | 0.000 | |
| Landuse | WGD | −10.840 | 1.854 | 5.846 | 0.000 |
| CSD | −0.709 | 1.667 | 0.425 | 0.671 | |
| UUD | −25.117 | 10.037 | 2.502 | 0.012 | |
| CTD | −2.698 | 1.711 | 1.577 | 0.115 | |
| Altitude | DEM | −0.010 | 0.001 | 17.001 | 0.000 |
| Humanactivity | IED | −2.800 | 2.532 | 1.106 | 0.269 |
| RND | 0.013 | 0.006 | 2.288 | 0.022 | |
| NTL | −0.004 | 0.012 | 0.338 | 0.736 | |
| Others | Intercept | 85.617 | 3.057 | 28.004 | 0.000 |
| R2 | 0.855 | ||||
| RMSE | 5.137 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Liu, Y.; Yang, D.; Dong, G. PM2.5 Concentrations Variability in North China Explored with a Multi-Scale Spatial Random Effect Model. Int. J. Environ. Res. Public Health 2022, 19, 10811. https://doi.org/10.3390/ijerph191710811
Zhang H, Liu Y, Yang D, Dong G. PM2.5 Concentrations Variability in North China Explored with a Multi-Scale Spatial Random Effect Model. International Journal of Environmental Research and Public Health. 2022; 19(17):10811. https://doi.org/10.3390/ijerph191710811
Chicago/Turabian StyleZhang, Hang, Yong Liu, Dongyang Yang, and Guanpeng Dong. 2022. "PM2.5 Concentrations Variability in North China Explored with a Multi-Scale Spatial Random Effect Model" International Journal of Environmental Research and Public Health 19, no. 17: 10811. https://doi.org/10.3390/ijerph191710811