
Determinants and Prediction of Injury Severities in Multi-Vehicle-Involved Crashes

 ,
,
Abstract
:1. Introduction
2. Methodology
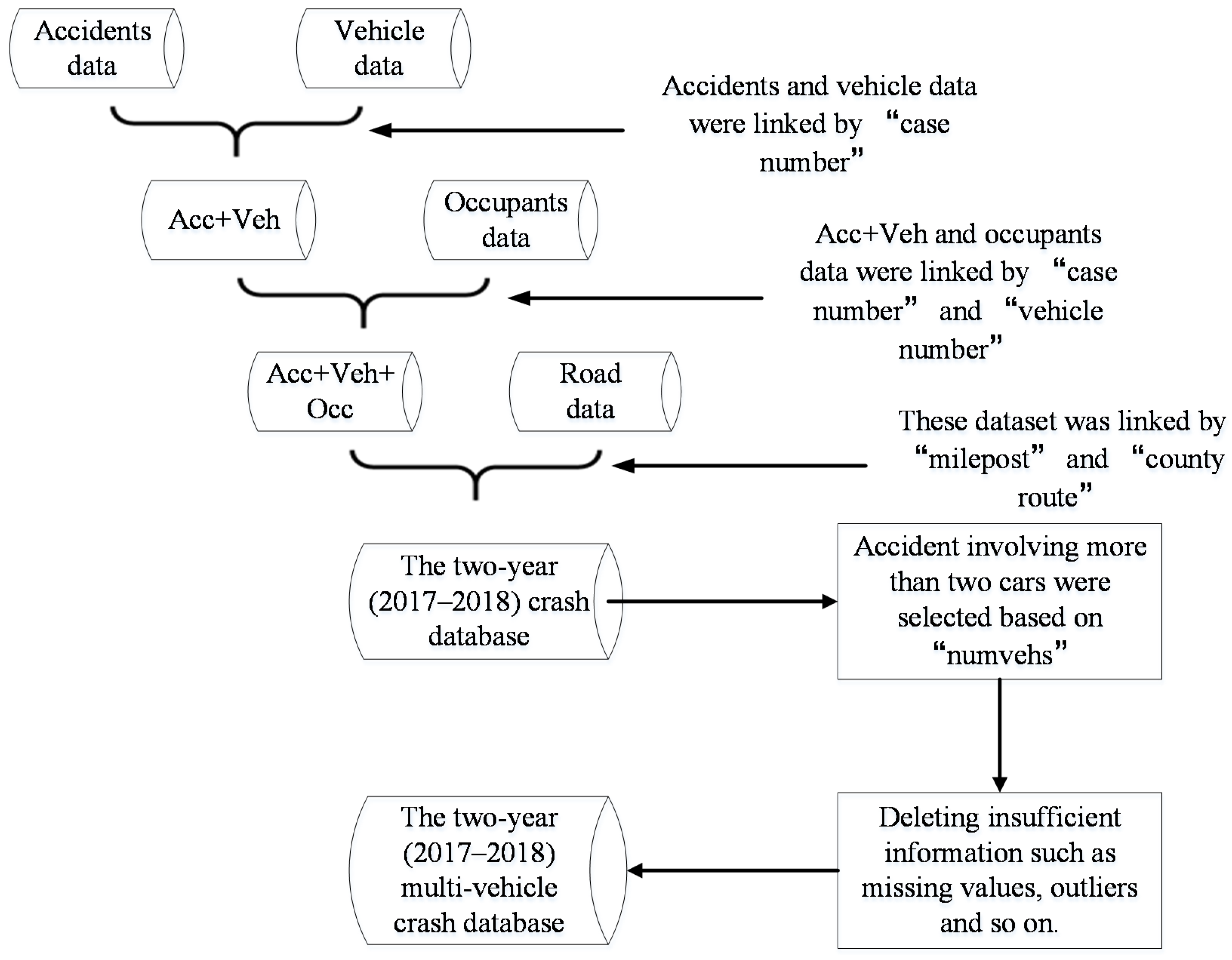
2.1. Data Processing
2.2. Random Parameters Logit Model (RPL)
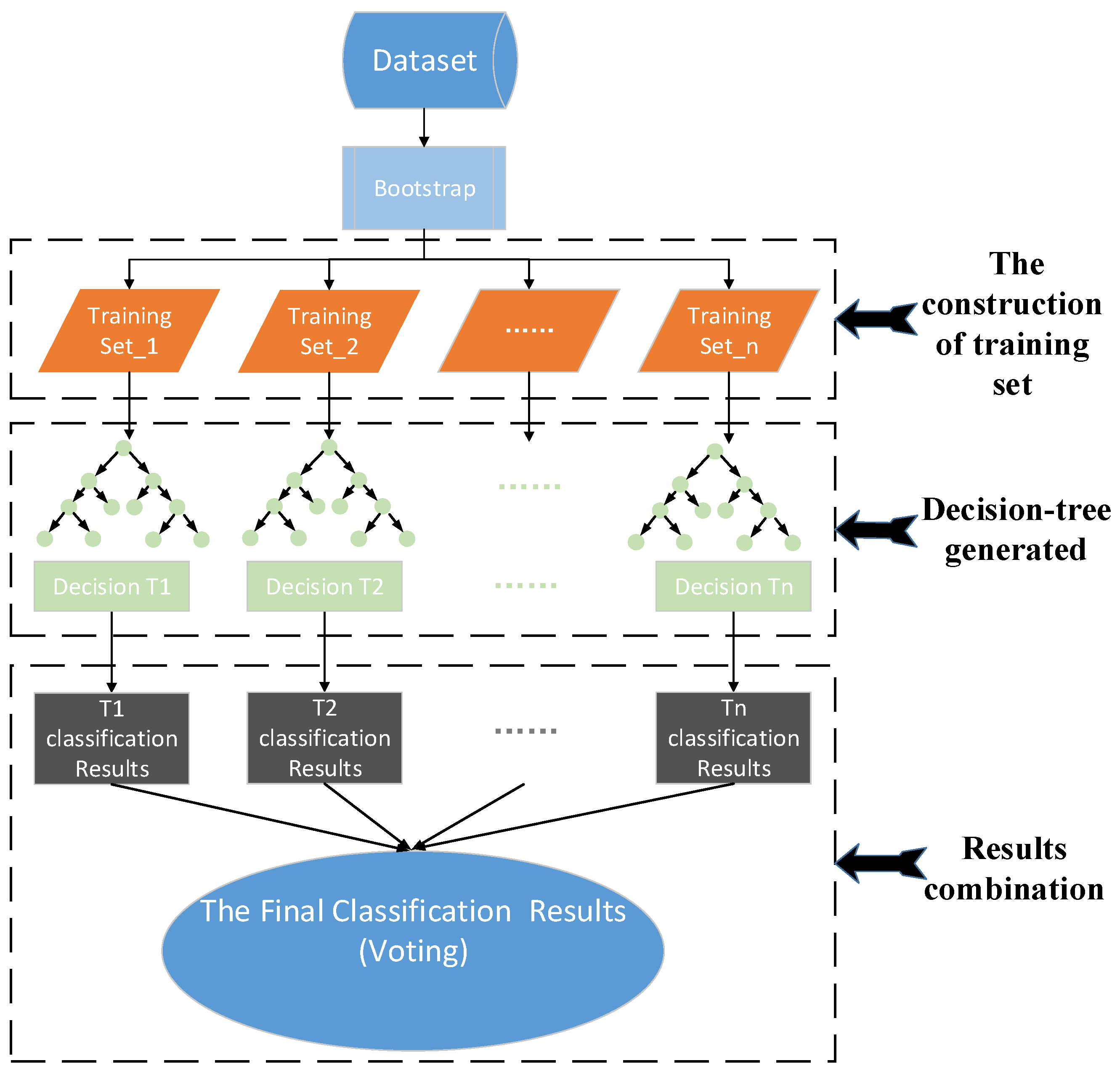
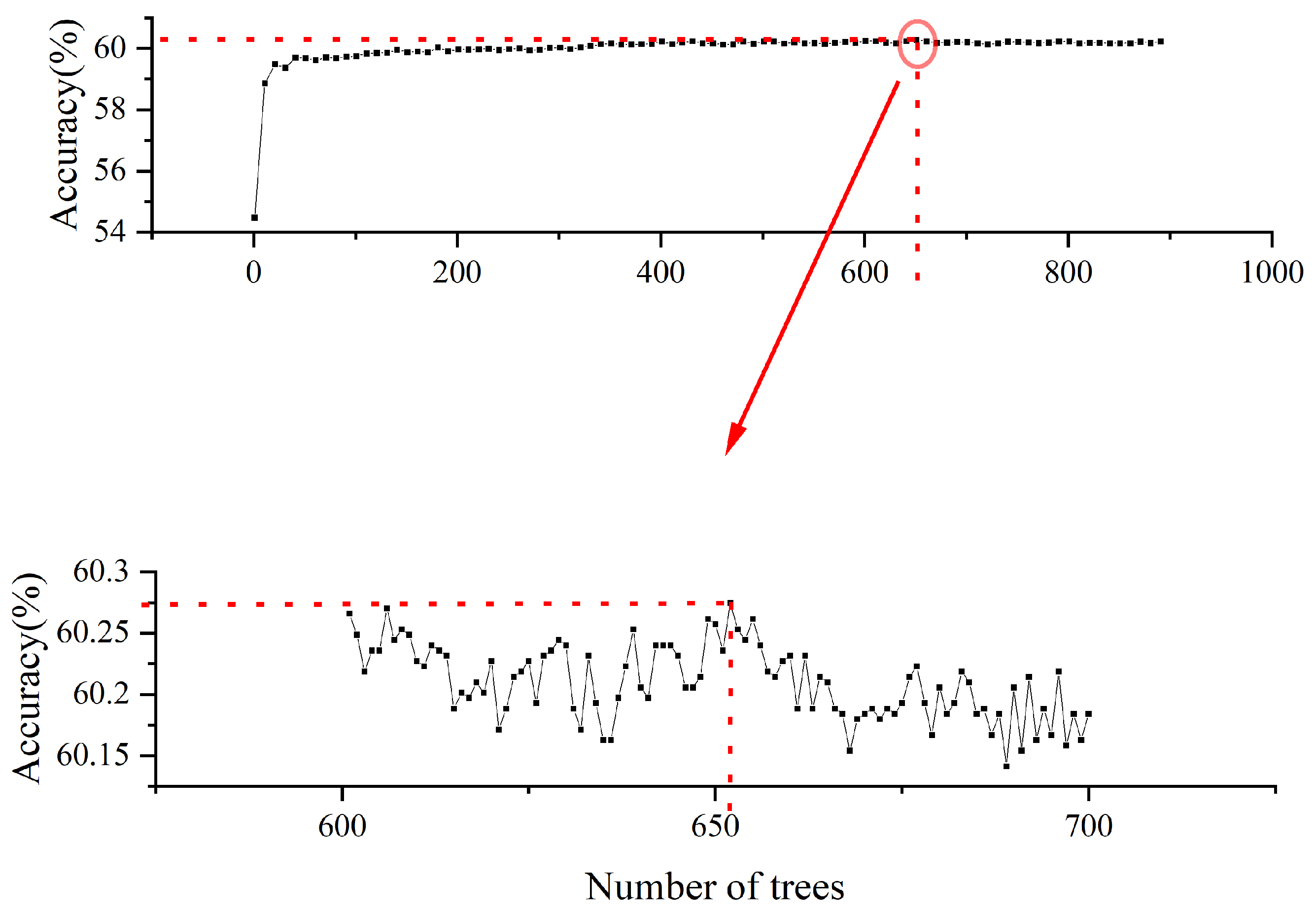
2.3. Random Forest
2.4. Model Evaluation
3. Results and Discussion
3.1. Likelihood Ratio Tests
3.2. Model Estimation
3.3. Model Prediction and Discussion
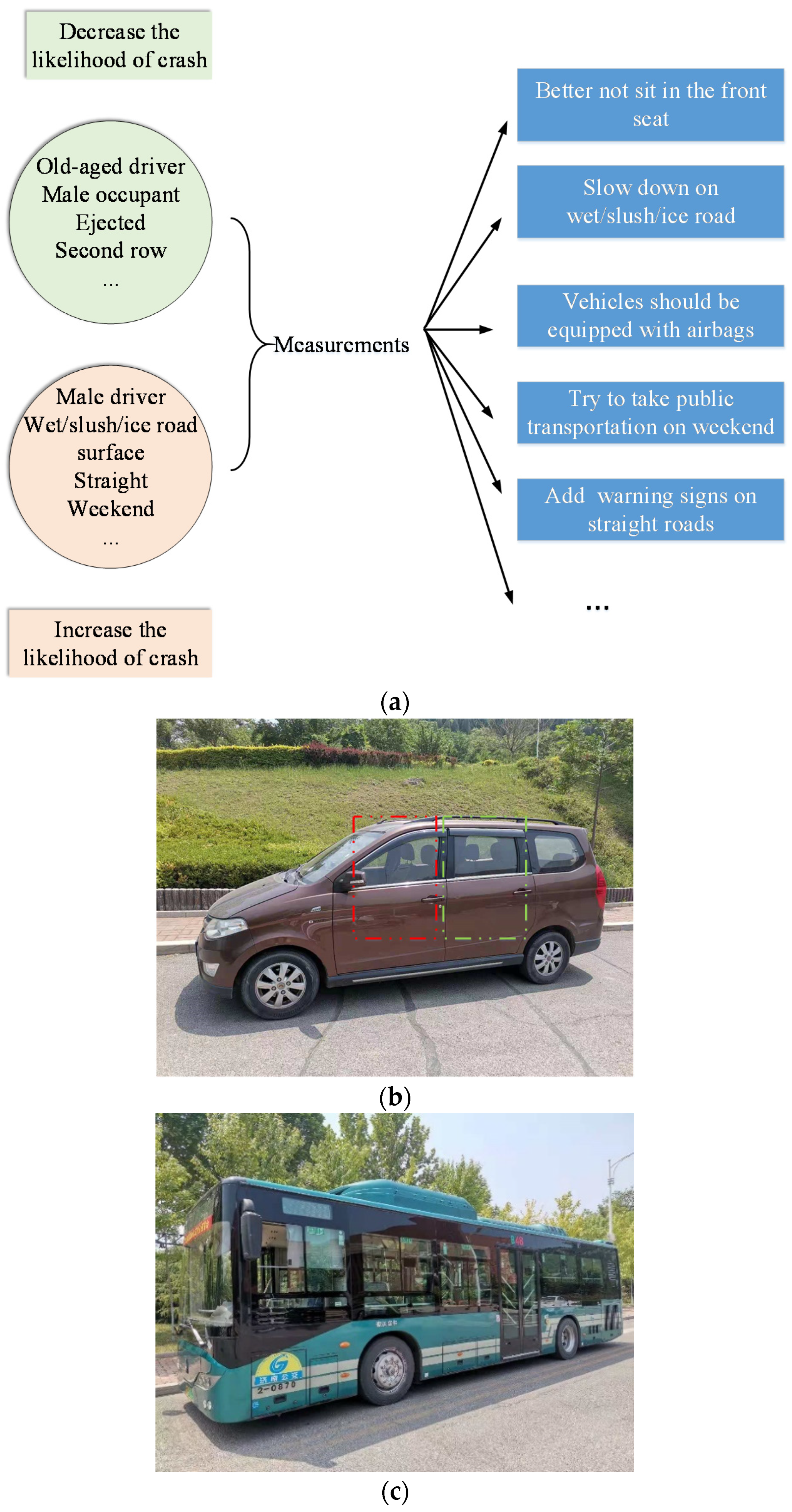
3.4. Effect of Significant Factors
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Explanatory Variable | PDO | Injury | Fatal | Total | ||||
|---|---|---|---|---|---|---|---|---|
| Total crashes | 9287 | 68.90% | 4180 | 31.01% | 11 | 0.08% | 13,478 | |
| Driver characteristics | ||||||||
| Driver gender | ||||||||
| Male driver | 5512 | 40.90% | 2280 | 16.92% | 5 | 0.04% | 7797 | 57.85% |
| Female driver | 3775 | 28.01% | 1900 | 14.10% | 6 | 0.04% | 5681 | 42.15% |
| Driver age | ||||||||
| Young driver | 1458 | 10.82% | 628 | 4.66% | 3 | 0.02% | 2089 | 15.50% |
| Middle-aged driver | 6718 | 49.84% | 2951 | 21.89% | 5 | 0.04% | 9674 | 71.78% |
| Elder driver | 1111 | 8.24% | 601 | 4.46% | 3 | 0.02% | 1715 | 12.72% |
| Driver restraint | ||||||||
| No restraints used | 33 | 0.24% | 19 | 0.14% | 3 | 0.02% | 55 | 0.41% |
| Lap belt/shoulder or other restraints used | 9254 | 68.66% | 4161 | 30.87% | 8 | 0.06% | 13,423 | 99.59% |
| Driver mistake action | ||||||||
| Skidding involved | 175 | 1.30% | 60 | 0.45% | 2 | 0.01% | 237 | 1.76% |
| Avoiding maneuvers | 156 | 1.16% | 47 | 0.35% | 0 | 0.00% | 203 | 1.51% |
| Sudden slowing maneuvers | 4089 | 30.34% | 1505 | 11.17% | 1 | 0.01% | 5595 | 41.51% |
| Stopped vehicle | 4145 | 30.75% | 2061 | 15.29% | 2 | 0.01% | 6208 | 46.06% |
| Vehicle characteristics | ||||||||
| Carry hazardous material | ||||||||
| Yes | 0 | 0.01% | 2 | 0.04% | 4 | 0.00% | 6 | 0.04% |
| No | 5417 | 40.21% | 8055 | 59.79% | 0 | 0.00% | 13,472 | 99.96% |
| Road characteristics | ||||||||
| Roadway classification | ||||||||
| Urban freeways | 5463 | 40.53% | 2337 | 17.34% | 3 | 0.02% | 7803 | 57.89% |
| Urban multilane roads | 2607 | 19.34% | 1272 | 9.44% | 0 | 0.00% | 3879 | 28.78% |
| Rural freeways | 562 | 4.17% | 232 | 1.72% | 3 | 0.02% | 797 | 5.91% |
| Rural multilane roads | 655 | 4.86% | 339 | 2.52% | 5 | 0.04% | 999 | 7.41% |
| Road characteristics | ||||||||
| Straight | 8589 | 63.73% | 3845 | 28.53% | 10 | 0.07% | 12,444 | 92.33% |
| Curve | 698 | 5.18% | 335 | 2.49% | 1 | 0.01% | 1034 | 7.67% |
| Federal function class | ||||||||
| Rural collector | 1221 | 9.06% | 573 | 4.25% | 8 | 0.06% | 1802 | 13.37% |
| Urban collector | 8066 | 59.85% | 3607 | 26.76% | 3 | 0.02% | 11,676 | 86.63% |
| Road surface type | ||||||||
| Portland concrete cement | 2440 | 18.10% | 1006 | 7.46% | 0 | 0.00% | 3446 | 25.57% |
| Asphalt concrete | 6847 | 50.80% | 3171 | 23.53% | 11 | 0.08% | 10,029 | 74.41% |
| Brick/gravel/dirt | 0 | 0.00% | 3 | 0.02% | 0 | 0.00% | 3 | 0.02% |
| Crash characteristics | ||||||||
| Day of week | ||||||||
| Non-weekend | 6038 | 44.80% | 2796 | 20.74% | 8 | 0.06% | 8842 | 65.60% |
| Weekend | 3249 | 24.11% | 1384 | 10.27% | 3 | 0.02% | 4636 | 34.40% |
| Location of the crash | ||||||||
| Intersection-related | 2316 | 17.18% | 1135 | 8.42% | 3 | 0.02% | 3454 | 25.63% |
| Driveway-related | 279 | 2.07% | 177 | 1.31% | 1 | 0.01% | 457 | 3.39% |
| Not at intersection or driveway | 6692 | 49.65% | 2868 | 21.28% | 7 | 0.05% | 9567 | 70.98% |
| Weather | ||||||||
| Clear | 7354 | 54.56% | 3410 | 25.30% | 5 | 0.04% | 10,769 | 79.90% |
| Cloudy | 1689 | 12.53% | 657 | 4.87% | 4 | 0.03% | 2350 | 17.44% |
| Raining/snowing | 154 | 1.14% | 69 | 0.51% | 0 | 0.00% | 223 | 1.65% |
| Fog/wind/other | 90 | 0.67% | 44 | 0.33% | 2 | 0.01% | 136 | 1.00% |
| Light condition | ||||||||
| Daylight | 7233 | 53.67% | 3261 | 24.19% | 7 | 0.05% | 10,501 | 77.91% |
| Dusk-dawn | 319 | 2.37% | 137 | 1.02% | 0 | 0.00% | 456 | 3.38% |
| Dark, light on | 1274 | 9.45% | 594 | 4.41% | 2 | 0.01% | 1870 | 13.87% |
| Dark, light off | 461 | 3.42% | 188 | 1.39% | 2 | 0.01% | 651 | 4.83% |
| Roadway surface | ||||||||
| Dry | 6722 | 49.87% | 3104 | 23.03% | 4 | 0.03% | 9830 | 72.93% |
| Wet/snow/slush/ice | 2538 | 18.83% | 1060 | 7.86% | 7 | 0.05% | 3605 | 26.75% |
| Other | 27 | 0.20% | 16 | 0.12% | 0 | 0.00% | 43 | 0.32% |
| Occupant characteristics | ||||||||
| Age | ||||||||
| Young passenger | 5019 | 37.24% | 1951 | 14.48% | 4 | 0.03% | 6974 | 51.74% |
| Middle-aged passenger | 3352 | 24.87% | 1654 | 12.27% | 5 | 0.04% | 5011 | 37.18% |
| Elder passenger | 916 | 6.80% | 575 | 4.27% | 2 | 0.01% | 1493 | 11.08% |
| Gender | ||||||||
| Male | 4115 | 30.53% | 1572 | 11.66% | 5 | 0.04% | 5692 | 42.23% |
| Female | 5172 | 38.37% | 2608 | 19.35% | 6 | 0.04% | 7786 | 57.77% |
| Seat position | ||||||||
| First row | 4934 | 36.61% | 2499 | 18.54% | 6 | 0.04% | 7439 | 55.19% |
| Second row | 1237 | 9.18% | 446 | 3.31% | 0 | 0.00% | 1683 | 12.49% |
| Third row | 3116 | 23.12% | 1235 | 9.16% | 5 | 0.04% | 4356 | 32.32% |
| Eject | ||||||||
| Not ejected | 9281 | 68.86% | 4175 | 30.98% | 7 | 0.05% | 13,463 | 99.89% |
| Ejected | 6 | 0.04% | 5 | 0.04% | 4 | 0.03% | 15 | 0.11% |
| Occupant Restraint | ||||||||
| No restraints used | 34 | 0.25% | 33 | 0.24% | 3 | 0.02% | 70 | 0.52% |
| Lap belt/shoulder or other used | 9253 | 68.65% | 4147 | 30.77% | 8 | 0.06% | 13,408 | 99.48% |
Appendix B
| Variable | Random Parameters Logit Model (with Heterogeneity in Means and Variances) | |
|---|---|---|
| Parameters Estimate | z-Stat | |
| Constant (PDO) | 7.0652 | 15.68 |
| Constant (I) | 5.4921 | 11.68 |
| Driver characteristics | ||
| Old-aged driver (1 if driver is older than 60 years old; 0 otherwise) (PDO) | −1.3907 | −3.66 |
| Middle-aged driver (1 if driver is between 25 and 60 years old; 0 otherwise) (PDO) | 1.4329 | 3.34 |
| Male driver (1 if the gender of driver is male; 0 otherwise) (PDO) | 0.7133 | −3.44 |
| Sudden slowing maneuvers (1 if the Driver mistake action is Sudden slowing maneuvers; 0 otherwise) (FI) | −2.0871 | −1.68 |
| Road characteristics | ||
| Wet/snow/slush/ice road surface (1 if the road surface is wet/snow/slush/ice; 0 otherwise) (PDO) | 0.2841 | 2.09 |
| Rural freeways (1 if the road classification is rural freeways; 0 otherwise) (F) | 1.8023 | 2.21 |
| Crash characteristics | ||
| Not at intersection or driveway (1 if the crash occurred not at intersection or driveway; 0 otherwise) (PDO) | 0.2232 | 1.73 |
| Weekend (1 if weekend; 0 otherwise) (I) | −0.1791 | −1.56 |
| Occupant characteristics | ||
| Male occupant (1 if the gender of occupant is male; 0 otherwise) (PDO) | −0.5782 | −2.39 |
| Old-aged occupant (1 if occupant is older than 60 years old; 0 otherwise) (PDO) | −0.8212 | −2.30 |
| Ejected (1 if occupant is ejected; 0 otherwise) (PDO) | −4.2151 | −4.30 |
| Second row (1 if the occupant seated in second row; 0 otherwise) (I) | −0.4940 | −2.29 |
| Random parameters | ||
| Occupant restraints (1 if occupant’s safety equipment is used; 0 otherwise) (I) | −1.5017 | −2.56 |
| Standard deviation of “Occupant restraints” (I) | 4.5840 | 3.45 |
| Male driver (1 if the gender of driver male; 0 otherwise) (I) | 0.6905 | 2.38 |
| Standard deviation of “Male driver” (I) | 3.1585 | 2.66 |
| Heterogeneity in the mean of the random parameters | ||
| Occupant restraints (I): Sudden slowing maneuvers | −0.5543 | −2.83 |
| Male driver (I): Sudden slowing maneuvers | −0.8786 | −2.54 |
| Heterogeneity in the variances of the random parameters | ||
| Occupant restraints (I): Middle-aged driver | −0.4272 | −2.19 |
| Model statistics | - | - |
| Number of observations | 13,478 | - |
| AIC | 16,593 | - |
| BIC | 16,743 | - |
| McFadden | 0.44 | - |
References
- World Health Organization. Global Status Report on Road Safety 2018: Summary (No. WHO/NMH/NVI/18.20); World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Hong, J.; Tamakloe, R.; Park, D. A Comprehensive Analysis of Multi-Vehicle Crashes on Expressways: A Double Hurdle Approach. Sustainability 2019, 11, 2782. [Google Scholar] [CrossRef] [Green Version]
- Ahn, J.Y.; Ryoo, H.W.; Park, J.B.; Kim, J.K.; Lee, M.J.; Lee, D.E.; Seo, K.S.; Kim, Y.J.; Moon, S. Comparison of traffic collision victims between older and younger drivers in South Korea: Epidemiologic characteristics, risk factors and types of collisions. PLoS ONE 2019, 14, e0214205. [Google Scholar] [CrossRef] [Green Version]
- Venkataraman, N.; Ulfarsson, G.F.; Shankar, V.N. Random parameter models of interstate crash frequencies by severity, number of vehicles involved, collision and location type. Accid. Anal. Prev. 2013, 59, 309–318. [Google Scholar] [CrossRef] [PubMed]
- Seraneeprakarn, P.; Huang, S.; Shankar, V.; Mannering, F.; Venkataraman, N.; Milton, J. Occupant injury severities in hybrid-vehicle involved crashes: A random parameters approach with heterogeneity in means and variances. Anal. Methods Accid. Res. 2017, 15, 41–55. [Google Scholar] [CrossRef]
- Rahimi, E.; Shamshiripour, A.; Samimi, A.; Mohammadian, A.K. Investigating the injury severity of single-vehicle truck crashes in a developing country. Accid. Anal. Prev. 2020, 137, 105444. [Google Scholar] [CrossRef] [PubMed]
- Shao, X.; Ma, X.; Chen, F.; Song, M.; Pan, X.; Pan, K. A Random Parameters Ordered Probit Analysis of Injury Severity in Truck Involved Rear-End Collisions. Int. J. Environ. Res. Public Health 2020, 17, 395. [Google Scholar] [CrossRef] [Green Version]
- Rezapour, M.; Moomen, M.; Ksaibati, K. Ordered logistic models of influencing factors on crash injury severity of single and multiple-vehicle downgrade crashes: A case study in Wyoming. J. Saf. Res. 2019, 68, 107–118. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Lord, D.; Zhang, Y.; Xie, Y. Predicting motor vehicle crashes using Support Vector Machine models. Accid. Anal. Prev. 2008, 40, 1611–1618. [Google Scholar] [CrossRef] [PubMed]
- Mokhtarimousavi, S.; Anderson, J.C.; Azizinamini, A.; Hadi, M. Improved Support Vector Machine Models for Work Zone Crash Injury Severity Prediction and Analysis. Transp. Res. Rec. 2019, 2673, 680–692. [Google Scholar] [CrossRef]
- Li, Z.; Liu, P.; Wang, W.; Xu, C. Using support vector machine models for crash injury severity analysis. Accid. Anal. Prev. 2012, 45, 478–486. [Google Scholar] [CrossRef]
- Harb, R.; Yan, X.; Radwan, E.; Su, X. Exploring precrash maneuvers using classification trees and random forests. Accid. Anal. Prev. 2009, 41, 98–107. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B. Severity Prediction of Traffic Accidents with Recurrent Neural Networks. Appl. Sci. 2017, 7, 476. [Google Scholar] [CrossRef] [Green Version]
- Iranitalab, A.; Khattak, A. Comparison of four statistical and machine learning methods for crash severity prediction. Accid. Anal. Prev. 2017, 108, 27–36. [Google Scholar] [CrossRef]
- Wang, J.; Boya, L.; Lanfang, Z.; Ragland, D.R. Modeling when and where a secondary accident occurs. Accid. Anal. Prev. 2019, 130, 160–166. [Google Scholar] [CrossRef]
- Pervez, A.; Lee, J.; Huang, H. Identifying Factors Contributing to the Motorcycle Crash Severity in Pakistan. J. Adv. Transp. 2021, 2021. [Google Scholar] [CrossRef]
- Adanu, E.K.; Lidbe, A.; Tedla, E.; Jones, S. Injury-severity analysis of lane change crashes involving commercial motor vehicles on interstate highways. J. Saf. Res. 2021, 76, 30–35. [Google Scholar] [CrossRef] [PubMed]
- Meng, F.; Xu, P.; Song, C.; Gao, K.; Zhou, Z.; Yang, L. Influential Factors Associated with Consecutive Crash Severity: A Two-Level Logistic Modeling Approach. Int. J. Environ. Res. Public Health 2020, 17, 5623. [Google Scholar] [CrossRef]
- Zhou, H.; Yuan, C.; Dong, N.; Wong, S.C.; Xu, P. Severity of passenger injuries on public buses: A comparative analysis of collision injuries and non-collision injuries. J. Saf. Res. 2020, 74, 55–69. [Google Scholar] [CrossRef]
- Huo, X.; Leng, J.; Hou, Q.; Yang, H. A correlated random parameters model with heterogeneity in means to account for unobserved heterogeneity in crash frequency analysis. Transp. Res. Rec. 2020, 2674, 312–322. [Google Scholar] [CrossRef]
- Hou, Q.; Huo, X.; Leng, J.; Cheng, Y. Examination of driver injury severity in freeway single-vehicle crashes using a mixed logit model with heterogeneity-in-means. Phys. A Stat. Mech. Appl. 2019, 531, 121760. [Google Scholar] [CrossRef]
- Waseem, M.; Ahmed, A.; Saeed, T.U. Factors affecting motorcyclists’ injury severities: An empirical assessment using random parameters logit model with heterogeneity in means and variances. Accid. Anal. Prev. 2019, 123, 12–19. [Google Scholar] [CrossRef]
- Yu, M.; Zheng, C.; Ma, C. Analysis of injury severity of rear-end crashes in work zones: A random parameters approach with heterogeneity in means and variances. Anal. Methods Accid. Res. 2020, 100126. [Google Scholar] [CrossRef]
- McFadden, D.; Train, K. Mixed MNL models for discrete response. J. Appl. Econom. 2000, 15, 447–470. [Google Scholar] [CrossRef]
- Ahmadi, A.; Jahangiri, A.; Berardi, V.; Machiani, S.G. Crash severity analysis of rear-end crashes in California using statistical and machine learning classification methods. J. Transp. Saf. Secur. 2020, 12, 522–546. [Google Scholar] [CrossRef]
- Zhou, X.Y.; Lu, P.; Zheng, Z.; Tolliver, D.; Keramati, A. Accident Prediction Accuracy Assessment for Highway-Rail Grade Crossings Using Random Forest Algorithm Compared with Decision Tree. Reliab. Eng. Syst. Saf. 2020, 200, 9. [Google Scholar] [CrossRef]
- Kitali, A.E.; Mokhtarimousavi, S.; Kadeha, C.; Alluri, P. Severity analysis of crashes on express lane facilities using support vector machine model trained by firefly algorithm. Traffic Inj. Prev. 2021, 22, 79–84. [Google Scholar] [CrossRef]
- Song, X.; Wu, J.; Zhang, H.; Pi, R. Analysis of Crash Severity for Hazard Material Transportation Using Highway Safety Information System Data. SAGE Open 2020, 10, 2158244020939924. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Zhao, S.; Khattak, A. Motor vehicle drivers’ injuries in train–motor vehicle crashes. Accid. Anal. Prev. 2015, 74, 162–168. [Google Scholar] [CrossRef]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Huo, X.; Leng, J.; Hou, Q.; Zheng, L.; Zhao, L. Assessing the explanatory and predictive performance of a random parameters count model with heterogeneity in means and variances. Accid. Anal. Prev. 2020, 147, 105759. [Google Scholar] [CrossRef] [PubMed]
- Harmon, T.; Bahar, G.B.; Gross, F.B. Crash Costs for Highway Safety Analysis; National Transportation Library: Washington, DC, USA, 2018.
- Hezaveh, A.M.; Arvin, R.; Cherry, C.R. A geographically weighted regression to estimate the comprehensive cost of traffic crashes at a zonal level. Accid. Anal. Prev. 2019, 131, 15–24. [Google Scholar] [CrossRef] [PubMed]
- Washington, S.P.; Karlaftis, M.G.; Mannering, F.L. Statistical and Econometric Methods for Transportation Data Analysis; CRC Press: Boca Raton, FL, USA, 2003. [Google Scholar]
- Yan, X.; He, J.; Zhang, C.; Liu, Z.; Wang, C.; Qiao, B. Temporal analysis of crash severities involving male and female drivers: A random parameters approach with heterogeneity in means and variances. Anal. Methods Accid. Res. 2021, 30, 100161. [Google Scholar]




| Predicted | Injury-Severity Level | Actual Number of Crashes | |||
|---|---|---|---|---|---|
| Actual | Property Damage Only (PDO) | Injury (I) | Fatal Injury (FI) | ||
| Injury-Severity Level | Property Damage Only (PDO) | P11 | P12 | P13 | N1 |
| R11 | R12 | R13 | |||
| Injury (I) | P21 | P22 | P23 | N2 | |
| R21 | R22 | R23 | |||
| Fatal Injury (FI) | P31 | P32 | P33 | N3 | |
| R31 | R32 | R33 | |||
| Injury-Severity Level | Economic Crash Costs | QALY Crash Unit Costs | Comprehensive Crash Unit Cost |
|---|---|---|---|
| Property Damage Only (PDO) | 12,456 | 0 | 12,456 |
| Injury (I) | 46,132 | 97,535 | 143,667 |
| Fatal Injury (FI) | 588,738 | 3,173,900 | 3,762,638 |
| 2016 | 2017 | 2018 | |
|---|---|---|---|
| 2016 | - | 35.06 (9) [>99.99%] | 32.02 (10) [>99.96%] |
| 2017 | 7.48 (13) [12.42%] | - | 3.56 (10) [3.49%] |
| 2018 | 8.94 (13) [22.25%] | 2.84 (9) [2.97%] | - |
| Methods | Statistical Methods | Machine Learning Methods |
|---|---|---|
| RPL | RF | |
| Roverall | 56.59% | 67.16% |
| OPMAE | 2143 | 14,076 |
| OPAPE | 3.61% | 27.12% |
| OPRMSE (USD millions) | 137 | 895 |
| POCC (USD millions) | 252 | 153 |
| AOCC (USD millions) | 243 | 209 |
| Injury-Severity Level | Method | Property Damage Only (PDO) | Injury (I) | Fatal (F) |
|---|---|---|---|---|
| Property Damage Only (PDO) | RPL | 1881 | 918 | 3 |
| 67.13% | 32.76% | 0.11% | ||
| RF | 2408 | 419 | 1 | |
| 85.14% | 14.81% | 0.03% | ||
| Injury (I) | RPL | 850 | 440 | 3 |
| 65.74% | 34.03% | 0.23% | ||
| RF | 909 | 306 | 1 | |
| 74.75% | 25.16% | 0.08% | ||
| Fatal (F) | RPL | 4 | 2 | 0 |
| 66.67% | 33.33% | 0% | ||
| RF | 0 | 0 | 0 | |
| 0% | 0% | 0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, X.; Pi, R.; Zhang, Y.; Wu, J.; Dong, Y.; Zhang, H.; Zhu, X. Determinants and Prediction of Injury Severities in Multi-Vehicle-Involved Crashes. Int. J. Environ. Res. Public Health 2021, 18, 5271. https://doi.org/10.3390/ijerph18105271
Song X, Pi R, Zhang Y, Wu J, Dong Y, Zhang H, Zhu X. Determinants and Prediction of Injury Severities in Multi-Vehicle-Involved Crashes. International Journal of Environmental Research and Public Health. 2021; 18(10):5271. https://doi.org/10.3390/ijerph18105271
Chicago/Turabian StyleSong, Xiuguang, Rendong Pi, Yu Zhang, Jianqing Wu, Yuhuan Dong, Han Zhang, and Xinyuan Zhu. 2021. "Determinants and Prediction of Injury Severities in Multi-Vehicle-Involved Crashes" International Journal of Environmental Research and Public Health 18, no. 10: 5271. https://doi.org/10.3390/ijerph18105271