Time Series Analysis and Forecasting with Automated Machine Learning on a National ICD-10 Database


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Selection
2.2. Data Preparation and Extraction
2.3. Experimental Setup
2.4. Model Selection
2.5. Forecasting
2.6. Ethics Statement
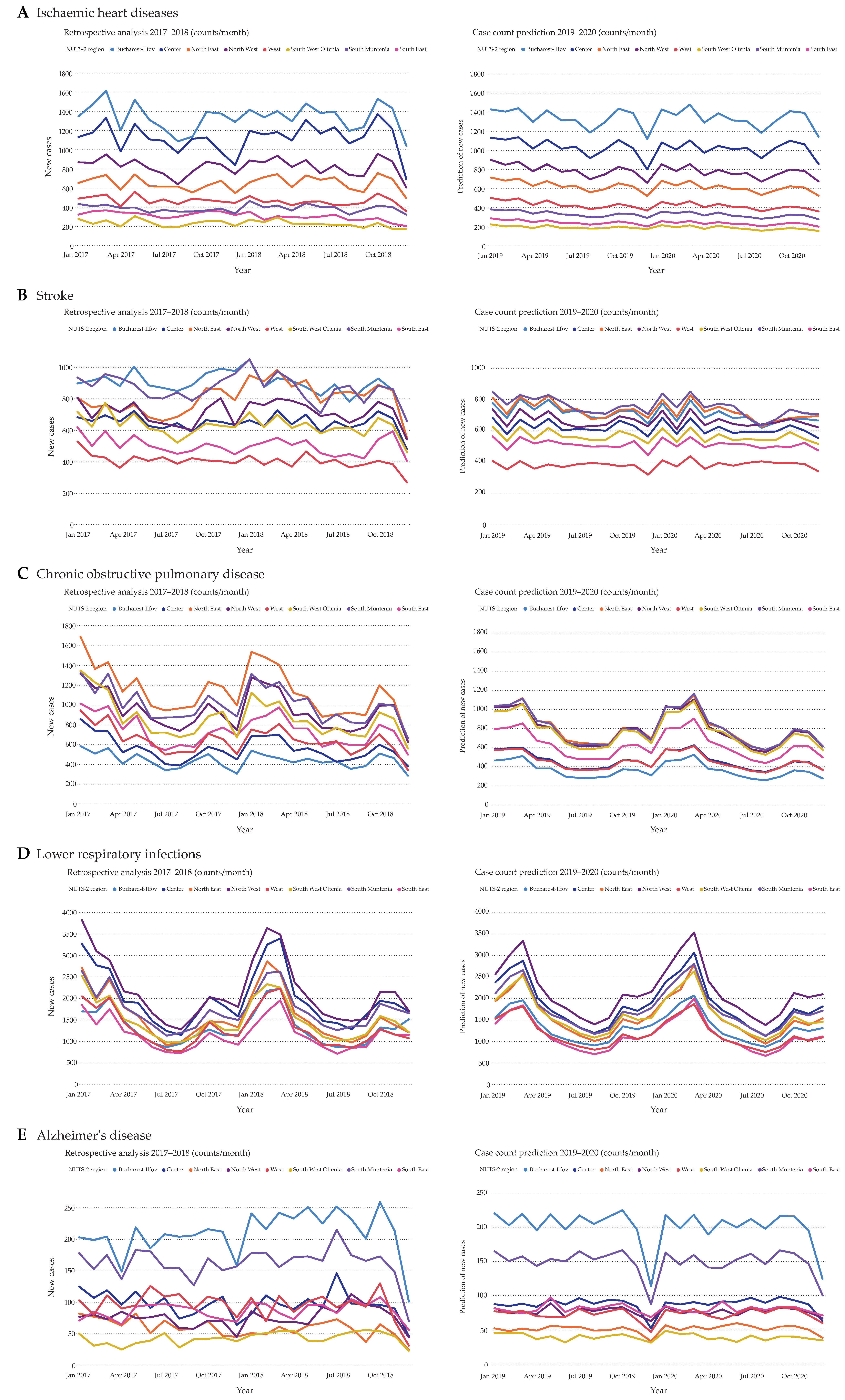
3. Results
3.1. Retrospective Analysis of the Ten Leading Causes of Death in Romania over the Period 2008–2018
3.2. Employment of Automated Machine Learning on the Time Series Datasets and Selection of the Most Accurate Forecasting Models
3.3. Time Series Forecasting for the Years 2019 and 2020
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AML | Automated machine learning |
| AVG | Average |
| ICD-10 | International Classification of Diseases, Tenth Revision |
| LightGBM | Light Gradient Boosting Machine |
| NUTS | Nomenclature of Territorial Units for Statistics |
| SARIMA | Seasonal Autoregressive Integrated Moving Average |
| WHO | World Health Organization |
| XGBoost | Extreme Gradient Boosting |
References
- Chen, P.C.; Liu, Y.; Peng, L. How to develop machine learning models for healthcare. Nat. Mater. 2019, 18, 410–414. [Google Scholar] [CrossRef] [PubMed]
- Big hopes for big data. Nat. Med. 2020, 26, 1. [CrossRef] [PubMed]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef] [Green Version]
- Alaa, A.M.; Bolton, T.; Di Angelantonio, E.; Rudd, J.H.F.; van der Schaar, M. Cardiovascular disease risk prediction using automated machine learning: A prospective study of 423,604 UK Biobank participants. PLoS ONE 2019, 14, e0213653. [Google Scholar] [CrossRef]
- Artzi, N.S.; Shilo, S.; Hadar, E.; Rossman, H.; Barbash-Hazan, S.; Ben-Haroush, A.; Balicer, R.D.; Feldman, B.; Wiznitzer, A.; Segal, E. Prediction of gestational diabetes based on nationwide electronic health records. Nat. Med. 2020, 26, 71–76. [Google Scholar] [CrossRef]
- Gupta, P.; Chiang, S.F.; Sahoo, P.K.; Mohapatra, S.K.; You, J.F.; Onthoni, D.D.; Hung, H.Y.; Chiang, J.M.; Huang, Y.; Tsai, W.S. Prediction of Colon Cancer Stages and Survival Period with Machine Learning Approach. Cancers 2019, 11, 2007. [Google Scholar] [CrossRef] [Green Version]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-Level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Klang, E. Deep learning and medical imaging. J. Thorac. Dis. 2018, 10, 1325–1328. [Google Scholar] [CrossRef]
- Bychkov, D.; Linder, N.; Turkki, R.; Nordling, S.; Kovanen, P.E.; Verrill, C.; Walliander, M.; Lundin, M.; Haglund, C.; Lundin, J. Deep learning based tissue analysis predicts outcome in colorectal cancer. Sci. Rep. 2018, 8, 1–11. [Google Scholar] [CrossRef]
- Janowczyk, A.; Madabhushi, A. Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases. J. Pathol. Inform. 2016, 7, 29. [Google Scholar] [CrossRef] [PubMed]
- Chae, S.; Kwon, S.; Lee, D. Predicting Infectious Disease Using Deep Learning and Big Data. Int. J. Environ. Res. Public Health 2018, 15, 1596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brower, V. Health is a global issue. EMBO Rep. 2003, 4, 649–651. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Contini, C.; Di Nuzzo, M.; Barp, N.; Bonazza, A.; De Giorgio, R.; Tognon, M.; Rubino, S. The novel zoonotic COVID-19 pandemic: An expected global health concern. J. Infect. Dev. Ctries. 2020, 14, 254–264. [Google Scholar] [CrossRef] [Green Version]
- Fan, V.Y.; Jamison, D.T.; Summers, L.H. Pandemic risk: How large are the expected losses? Bull. World Health Organ. 2018, 96, 129–134. [Google Scholar] [CrossRef] [PubMed]
- Brooks, L.C.; Farrow, D.C.; Hyun, S.; Tibshirani, R.J.; Rosenfeld, R. Nonmechanistic forecasts of seasonal influenza with iterative one-week-ahead distributions. PLoS Comput. Biol. 2018, 14, e1006134. [Google Scholar] [CrossRef] [Green Version]
- Tian, C.W.; Wang, H.; Luo, X.M. Time-Series modelling and forecasting of hand, foot and mouth disease cases in China from 2008 to 2018. Epidemiol. Infect. 2019, 147, e82. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Tian, C.W.; Wang, W.M.; Luo, X.M. Time-Series analysis of tuberculosis from 2005 to 2017 in China. Epidemiol. Infect. 2018, 146, 935–939. [Google Scholar] [CrossRef] [Green Version]
- Dugas, A.F.; Jalalpour, M.; Gel, Y.; Levin, S.; Torcaso, F.; Igusa, T.; Rothman, R.E. Influenza forecasting with Google Flu Trends. PLoS ONE 2013, 8, e56176. [Google Scholar] [CrossRef]
- He, F.; Hu, Z.J.; Zhang, W.C.; Cai, L.; Cai, G.X.; Aoyagi, K. Construction and evaluation of two computational models for predicting the incidence of influenza in Nagasaki Prefecture, Japan. Sci. Rep. 2017, 7, 1–9. [Google Scholar] [CrossRef]
- Lampos, V.; Miller, A.C.; Crossan, S.; Stefansen, C. Advances in nowcasting influenza-like illness rates using search query logs. Sci. Rep. 2015, 5, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Volkova, S.; Ayton, E.; Porterfield, K.; Corley, C.D. Forecasting influenza-like illness dynamics for military populations using neural networks and social media. PLoS ONE 2017, 12, e0188941. [Google Scholar] [CrossRef] [Green Version]
- Xu, Q.; Gel, Y.R.; Ramirez Ramirez, L.L.; Nezafati, K.; Zhang, Q.; Tsui, K.L. Forecasting influenza in Hong Kong with Google search queries and statistical model fusion. PLoS ONE 2017, 12, e0176690. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hii, Y.L.; Rocklov, J.; Ng, N. Short term effects of weather on hand, foot and mouth disease. PLoS ONE 2011, 6, e16796. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.C.; Wang, J.F. Monitoring hand, foot and mouth disease by combining search engine query data and meteorological factors. Sci. Total Environ. 2018, 612, 1293–1299. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Wang, F.; Wang, B.; Tao, S.; Zhang, H.; Liu, S.; Ramirez, O.; Zeng, Q. Time series analyses of hand, foot and mouth disease integrating weather variables. PLoS ONE 2015, 10, e0117296. [Google Scholar] [CrossRef]
- Moosazadeh, M.; Khanjani, N.; Bahrampour, A. Seasonality and temporal variations of tuberculosis in the north of iran. Tanaffos 2013, 12, 35–41. [Google Scholar] [PubMed]
- Willis, M.D.; Winston, C.A.; Heilig, C.M.; Cain, K.P.; Walter, N.D.; Mac Kenzie, W.R. Seasonality of tuberculosis in the United States, 1993–2008. Clin. Infect. Dis. 2012, 54, 1553–1560. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Teng, Y.; Bi, D.; Xie, G.; Jin, Y.; Huang, Y.; Lin, B.; An, X.; Feng, D.; Tong, Y. Dynamic Forecasting of Zika Epidemics Using Google Trends. PLoS ONE 2017, 12, e0165085. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Milinovich, G.; Xu, Z.; Bambrick, H.; Mengersen, K.; Tong, S.; Hu, W. Monitoring Pertussis Infections Using Internet Search Queries. Sci. Rep. 2017, 7, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Allen, C.; Tsou, M.H.; Aslam, A.; Nagel, A.; Gawron, J.M. Applying GIS and Machine Learning Methods to Twitter Data for Multiscale Surveillance of Influenza. PLoS ONE 2016, 11, e0157734. [Google Scholar] [CrossRef] [PubMed]
- Butler, D. When Google got flu wrong. Nature 2013, 494, 155–156. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cho, S.; Sohn, C.H.; Jo, M.W.; Shin, S.Y.; Lee, J.H.; Ryoo, S.M.; Kim, W.Y.; Seo, D.W. Correlation between national influenza surveillance data and google trends in South Korea. PLoS ONE 2013, 8, e81422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lopman, B.; Armstrong, B.; Atchison, C.; Gray, J.J. Host, weather and virological factors drive norovirus epidemiology: Time-Series analysis of laboratory surveillance data in England and Wales. PLoS ONE 2009, 4, e6671. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Zhao, P.; Wu, D.; Cheng, C.; Huang, H. Time series model for forecasting the number of new admission inpatients. BMC Med. Inform. Decis. Mak. 2018, 18, 39. [Google Scholar] [CrossRef] [Green Version]
- Rohart, F.; Milinovich, G.J.; Avril, S.M.; Le Cao, K.A.; Tong, S.; Hu, W. Disease surveillance based on Internet-based linear models: An Australian case study of previously unmodeled infection diseases. Sci. Rep. 2016, 6, 38522. [Google Scholar] [CrossRef] [Green Version]
- Khoshdel, A.R.; Alimohamadi, Y.; Ziaei, M.; Ghaffari, H.R.; Azadi, S.; Sepandi, M. The prediction incidence of the three most common cancers among Iranian military community during 2007–2019: A time series analysis. J. Prev. Med. Hyg. 2019, 60, E256–E261. [Google Scholar] [CrossRef]
- Bi, Q.; Goodman, K.E.; Kaminsky, J.; Lessler, J. What Is Machine Learning: A Primer for the Epidemiologist. Am. J. Epidemiol. 2019, 188, 2222–2239. [Google Scholar] [CrossRef]
- Schmidt, M. Automated Feature Engineering for Time Series Data. Available online: https://www.kdnuggets.com/2017/11/automated-feature-engineering-time-series-data.html (accessed on 29 May 2020).
- Suzuki, S.; Yamashita, T.; Sakama, T.; Arita, T.; Yagi, N.; Otsuka, T.; Semba, H.; Kano, H.; Matsuno, S.; Kato, Y.; et al. Comparison of risk models for mortality and cardiovascular events between machine learning and conventional logistic regression analysis. PLoS ONE 2019, 14, e0221911. [Google Scholar] [CrossRef]
- WHO. The Top 10 Causes of Death. Available online: https://www.who.int/en/news-room/fact-sheets/detail/the-top-10-causes-of-death (accessed on 6 May 2020).
- SIMAP. The Nomenclature of Territorial Units for Statistics (NUTS). Available online: https://simap.ted.europa.eu/web/simap/nuts (accessed on 6 May 2020).
- Radu, C.P.; Chiriac, D.N.; Vladescu, C. Changing patient classification system for hospital reimbursement in Romania. Croat. Med. J. 2010, 51, 250–258. [Google Scholar] [CrossRef]
- Vlǎdescu, C.; Astǎrǎstoae, V.; Scintee, S.G. A health system focused on citizen’s needs. Romania. Hospital services, primary health care and human resources. Solutions (III). Rev. Romana Bioet. 2010, 8, 89–99. [Google Scholar]
- Judith, M. Diagnosis Related Groups (DRGs); Bioethics Research Library, Kennedy Institute of Ethics, Georgetown University: Washington, DC, USA, 1984. [Google Scholar]
- Vlǎdescu, C.; Astǎrǎstoae, V.; Scintee, S.G. A health system focused on citizen’s needs. Romania. Financing, organization and drug policy. Solutions (II). Rev. Romana Bioet. 2010, 8, 106–115. [Google Scholar]
- Paxata. Available online: https://www.paxata.com/ (accessed on 13 May 2020).
- WHO. ICD-10 Version: 2016. Available online: https://icd.who.int/browse10/2016/en#/I20.0 (accessed on 21 June 2020).
- DataRobot. Available online: https://www.datarobot.com/ (accessed on 31 May 2020).
- Wiecki, T.; Campbell, A.; Lent, J.; Stauth, J. All That Glitters Is Not Gold: Comparing Backtest and Out-of-Sample Performance on a Large Cohort of Trading Algorithms. J. Invest. 2016, 25, 69–80. [Google Scholar] [CrossRef]
- Kaspar, M.; Fette, G.; Guder, G.; Seidlmayer, L.; Ertl, M.; Dietrich, G.; Greger, H.; Puppe, F.; Stork, S. Underestimated prevalence of heart failure in hospital inpatients: A comparison of ICD codes and discharge letter information. Clin. Res. Cardiol. 2018, 107, 778–787. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A desicion-theoretic generalization of on-line learning and an application to boosting. In European Conference on Computational Learning Theory; Springer: Berlin/Heidelberg, Germany, 1995; pp. 23–37. [Google Scholar]
- Simionescu, M.; Bilan, S.; Gavurova, B.; Bordea, E.N. Health Policies in Romania to Reduce the Mortality Caused by Cardiovascular Diseases. Int J. Environ. Res. Public Health 2019, 16, 3080. [Google Scholar] [CrossRef] [Green Version]
- Nowbar, A.N.; Gitto, M.; Howard, J.P.; Francis, D.P.; Al-Lamee, R. Mortality From Ischemic Heart Disease. Circ. Cardiovasc. Qual. Outcomes 2019, 12, e005375. [Google Scholar] [CrossRef]
- GBD; Feigin, V.L.; Nguyen, G.; Cercy, K.; Johnson, C.O.; Alam, T.; Parmar, P.G.; Abajobir, A.A.; Abate, K.H.; Abd-Allah, F.; et al. Global, Regional, and Country-Specific Lifetime Risks of Stroke, 1990 and 2016. N. Engl. J. Med. 2018, 379, 2429–2437. [Google Scholar] [CrossRef]
- Ceornodolea, A.D.; Bal, R.; Severens, J.L. Epidemiology and Management of Atrial Fibrillation and Stroke: Review of Data from Four European Countries. Stroke Res. Treat. 2017, 2017, 8593207. [Google Scholar] [CrossRef]
- Soriano, J.B.; Abajobir, A.A.; Abate, K.H.; Abera, S.F.; Agrawal, A.; Ahmed, M.B.; Aichour, A.N.; Aichour, I.; Aichour, M.T.E.; Alam, K.; et al. Global, regional, and national deaths, prevalence, disability-adjusted life years, and years lived with disability for chronic obstructive pulmonary disease and asthma, 1990–2015: A systematic analysis for the Global Burden of Disease Study 2015. Lancet Respir. Med. 2017, 5, 691–706. [Google Scholar] [CrossRef] [Green Version]
- Blanco, I.; Diego, I.; Bueno, P.; Fernandez, E.; Casas-Maldonado, F.; Esquinas, C.; Soriano, J.B.; Miravitlles, M. Geographical distribution of COPD prevalence in Europe, estimated by an inverse distance weighting interpolation technique. Int. J. Chron Obstruct. Pulmon. Dis. 2018, 13, 57–67. [Google Scholar] [CrossRef] [Green Version]
- Mihaltan, F.; Nemes, R.; Daramus, I.; Farcasanu, D.; Paunescu, B. Prevalence of Chronic Obstructive Pulmonary Disease (COPD) in Romania. Chest 2012, 142, 658A. [Google Scholar] [CrossRef]
- Gefenaite, G.; Pistol, A.; Popescu, R.; Popovici, O.; Ciurea, D.; Dolk, C.; Jit, M.; Gross, D. Estimating burden of influenza-associated influenza-like illness and severe acute respiratory infection at public healthcare facilities in Romania during the 2011/12-2015/16 influenza seasons. Influenza Other Respir Viruses 2018, 12, 183–192. [Google Scholar] [CrossRef] [PubMed]
- Troeger, C.; Blacker, B.; Khalil, I.A.; Rao, P.C.; Cao, J.; Zimsen, S.R.M.; Albertson, S.B.; Deshpande, A.; Farag, T.; Abebe, Z.; et al. Estimates of the global, regional, and national morbidity, mortality, and aetiologies of lower respiratory infections in 195 countries, 1990–2016: A systematic analysis for the Global Burden of Disease Study 2016. Lancet Infect. Dis. 2018, 18, 1191–1210. [Google Scholar] [CrossRef] [Green Version]
- Cornutiu, G. The incidence and prevalence of Alzheimer’s disease. Neurodegener. Dis 2011, 8, 9–14. [Google Scholar] [CrossRef] [PubMed]
- Ciuleanu, T.E. Research and standard of care: Lung cancer in romania. Am. Soc. Clin. Oncol. Educ. Book 2012, 437, 437–441. [Google Scholar] [CrossRef] [PubMed]
- Tereanu, C.; Baili, P.; Berrino, F.; Micheli, A.; Furtunescu, F.L.; Minca, D.G.; Sant, M. Recent trends of cancer mortality in Romanian adults: Mortality is still increasing, although young adults do better than the middle-aged and elderly population. Eur. J. Cancer Prev. 2013, 22, 199–209. [Google Scholar] [CrossRef]
- Guariguata, L.; Whiting, D.R.; Hambleton, I.; Beagley, J.; Linnenkamp, U.; Shaw, J.E. Global estimates of diabetes prevalence for 2013 and projections for 2035. Diabetes Res. Clin. Pract. 2014, 103, 137–149. [Google Scholar] [CrossRef]
- Dulf, D.; Peek-Asa, C.; Baragan, E.; Cherecheş, R.; Mocean, F. Epidemiology of Road Traffic Injuries Treated in a Large Romanian Emergency Department in Tîrgu-Mureş Between 2009 and 2010. Traffic Inj. Prev. 2015, 16, 835–841. [Google Scholar] [CrossRef] [Green Version]
- Graziella, J.; Richard, A.; Mircea, S.; Marco, P. Road Safety Target Outcome: 100,000 Fewer Deaths since 2001; European Transport Safety Council: Etterbeek, Belgium, 2011. [Google Scholar]
- Hamann, C.; Dulf, D.; Baragan-Andrada, E.; Price, M.; Peek-Asa, C. Contributors to pedestrian distraction and risky behaviours during road crossings in Romania. Inj. Prev. 2017, 23, 370–376. [Google Scholar] [CrossRef]
- Troeger, C.; Forouzanfar, M.; Rao, P.C.; Khalil, I.; Brown, A.; Reiner, R.C.; Fullman, N.; Thompson, R.L.; Abajobir, A.; Ahmed, M.; et al. Estimates of global, regional, and national morbidity, mortality, and aetiologies of diarrhoeal diseases: A systematic analysis for the Global Burden of Disease Study 2015. Lancet Infect. Dis. 2017, 17, 909–948. [Google Scholar] [CrossRef] [Green Version]
- Troeger, C.E.; Khalil, I.A.; Blacker, B.F.; Biehl, M.H.; Albertson, S.B.; Zimsen, S.R.M.; Rao, P.C.; Abate, D.; Ahmadi, A.; Ahmed, M.L.C.b.; et al. Quantifying risks and interventions that have affected the burden of diarrhoea among children younger than 5 years: An analysis of the Global Burden of Disease Study 2017. Lancet Infect. Dis. 2020, 20, 37–59. [Google Scholar] [CrossRef] [Green Version]
- European Centre for Disease Prevention and Control. Tuberculosis Surveillance and Monitoring in Europe; ECDC: Copenhagen, Denmark, 2017.
- Golli, A.L.; Nitu, M.F.; Turcu, F.; Popescu, M.; Ciobanu-Mitrache, L.; Olteanu, M. Tuberculosis remains a public health problem in Romania. Int. J. Tuberc. Lung Dis. 2019, 23, 226–231. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease | Years | Compared Models | Selected Model | Gamma Deviance | RMSE | R-Squared | MAE | MAPE |
|---|---|---|---|---|---|---|---|---|
| Ischemic heart disease | DW = 6 FD = 24 | 25 | AVG Blender | 0.0110 | 65.6272 | 0.9725 | 48.5973 | 8.3663 |
| Stroke | DW = 6 FD = 24 | 29 | eXtreme Gradient Boosting on ElasticNet Predictions | 0.0140 | 82.1981 | 0.8000 | 57.5654 | 8.8361 |
| Chronic obstructive pulmonary disease | DW = 12 FD = 24 | 35 | AVG Blender | 0.0117 | 79.8697 | 0.9126 | 61.3592 | 8.7560 |
| Lower respiratory infections | DW = 8 FD = 24 | 25 | AVG Blender | 0.0108 | 192.8462 | 0.9045 | 127.5683 | 7.4239 |
| Alzheimer’s disease | DW = 8 FD = 24 | 28 | AVG Blender | 0.0579 | 21.7291 | 0.8688 | 16.0741 | 19.9726 |
| Lung cancer | DW = 12 FD = 24 | 35 | eXtreme Gradient Boosted Trees Regressor with Early Stopping (Gamma Loss) | 0.0115 | 32.7293 | 0.9372 | 24.7214 | 8.5870 |
| Diabetes mellitus | DW = 6 FD = 24 | 26 | AVG Blender | 0.0053 | 50.9413 | 0.9499 | 37.2955 | 5.5817 |
| Road injuries | DW = 6 FD = 24 | 25 | Elastic-Net Regressor (L2/Gamma Deviance) with Forecast Distance Modeling | 0.0338 | 25.7580 | 0.8410 | 19.6105 | 15.1879 |
| Diarrheal Disease | DW = 10 FD = 24 | 25 | AVG Blender | 0.0175 | 108.7063 | 0.8274 | 74.4832 | 10.7970 |
| Tuberculosis | DW = 12 FD = 24 | 41 | eXtreme Gradient Boosted Trees Regressor with Early Stopping | 0.0674 | 54.8689 | 0.7771 | 36.5015 | 21.7094 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olsavszky, V.; Dosius, M.; Vladescu, C.; Benecke, J. Time Series Analysis and Forecasting with Automated Machine Learning on a National ICD-10 Database. Int. J. Environ. Res. Public Health 2020, 17, 4979. https://doi.org/10.3390/ijerph17144979
Olsavszky V, Dosius M, Vladescu C, Benecke J. Time Series Analysis and Forecasting with Automated Machine Learning on a National ICD-10 Database. International Journal of Environmental Research and Public Health. 2020; 17(14):4979. https://doi.org/10.3390/ijerph17144979
Chicago/Turabian StyleOlsavszky, Victor, Mihnea Dosius, Cristian Vladescu, and Johannes Benecke. 2020. "Time Series Analysis and Forecasting with Automated Machine Learning on a National ICD-10 Database" International Journal of Environmental Research and Public Health 17, no. 14: 4979. https://doi.org/10.3390/ijerph17144979