Respiratory Diseases, Malaria and Leishmaniasis: Temporal and Spatial Association with Fire Occurrences from Knowledge Discovery and Data Mining

 , , ,
, , ,  and
and
Abstract
:1. Introduction
2. Malaria, Leishmaniasis and Respiratory Diseases
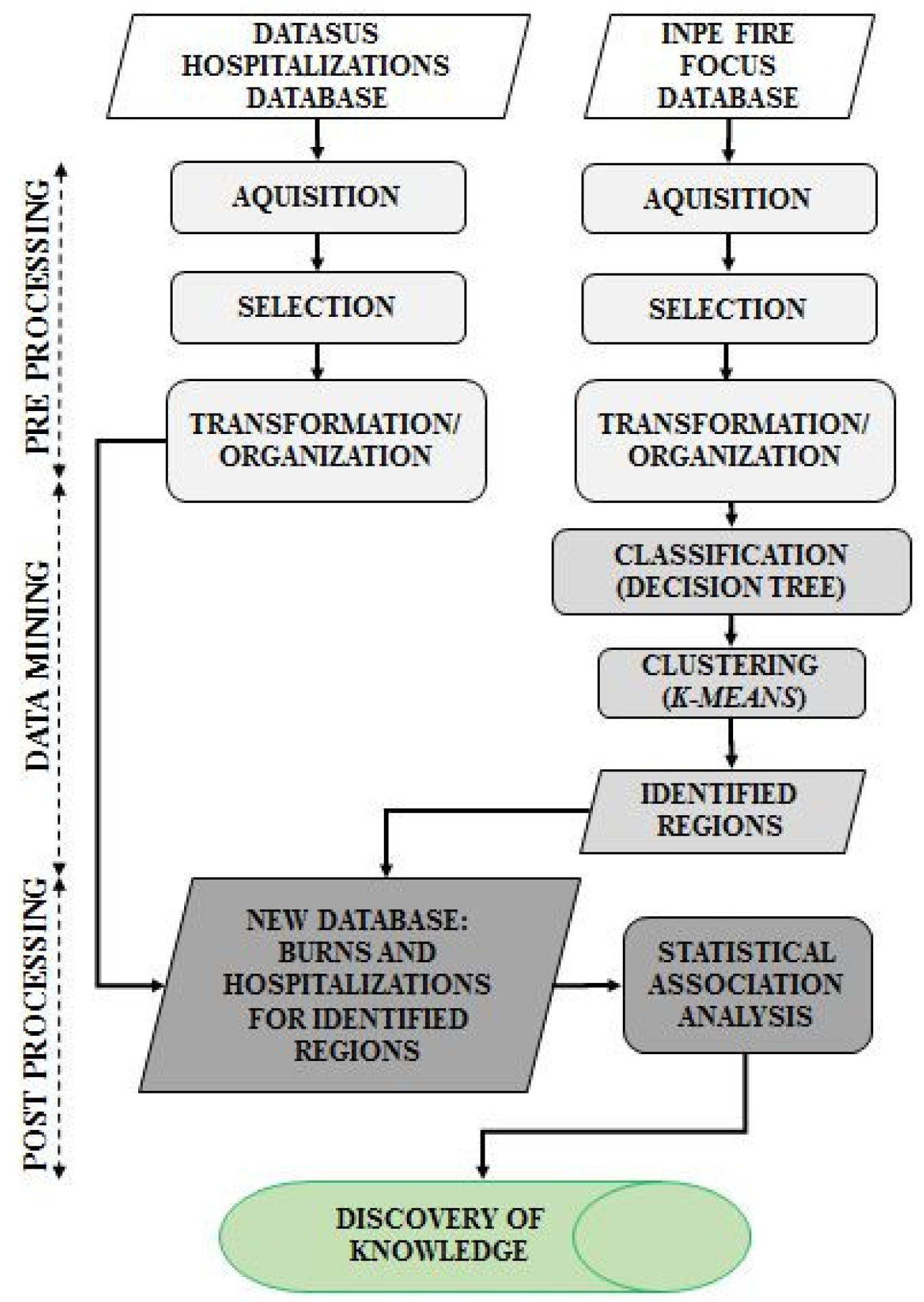
3. Material and Methods
3.1. Pre-processing
3.1.1. Forest fires Database
3.1.2. Health Database: Malaria, Leishmaniasis and Respiratory Disease Hospitalizations
3.2. Data Mining
3.2.1. (a) Classification: Decision Trees
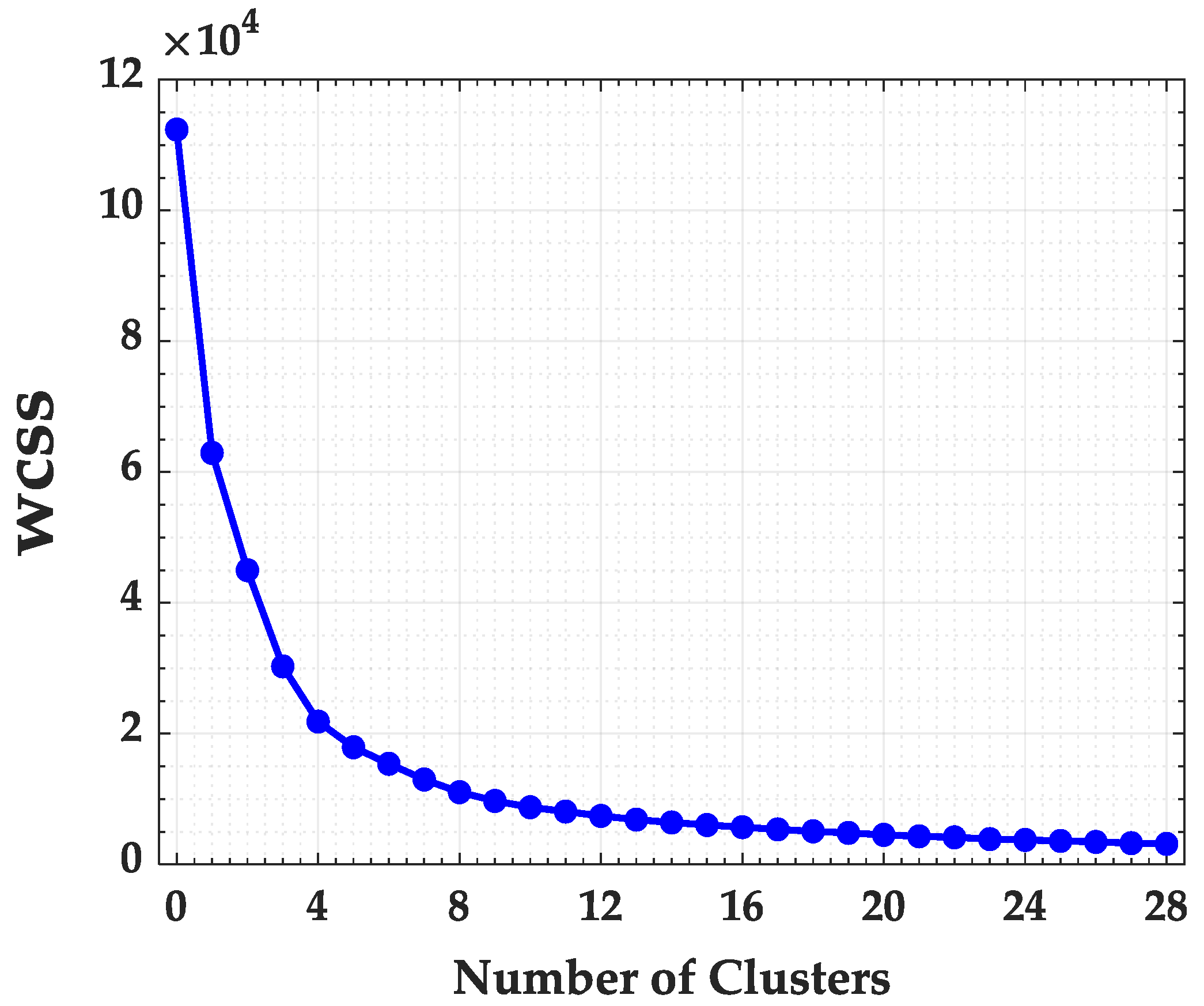
3.2.2. (b) Clustering
- determine the number of k, that is, the number of centroids and clusters that will be created;
- calculate the distance of each sample observation to the centroid;
- reposition the sample observation for the group whose distance to the centroid is smaller;
- recalculate the new position of the centroid within its group;
- repeat the iterations until the centroid does not change its position;
3.3. Post-Processing
4. Results and Discussion
4.1. Classification
4.1.1. Biome
4.1.2. State
4.1.3. Months, Climatic Conditions and Period of the Year
- (1)
- if the number of days without rainfall is less than or equal to 36 and if the fire risk is greater than 0.8 then a total of 55,538 fire outbreaks are correctly classified;
- (2)
- if the number of days without rain is greater than 36, and if the fire risk is greater than 0.2 then a total of 30,026 fire outbreaks are correctly classified.
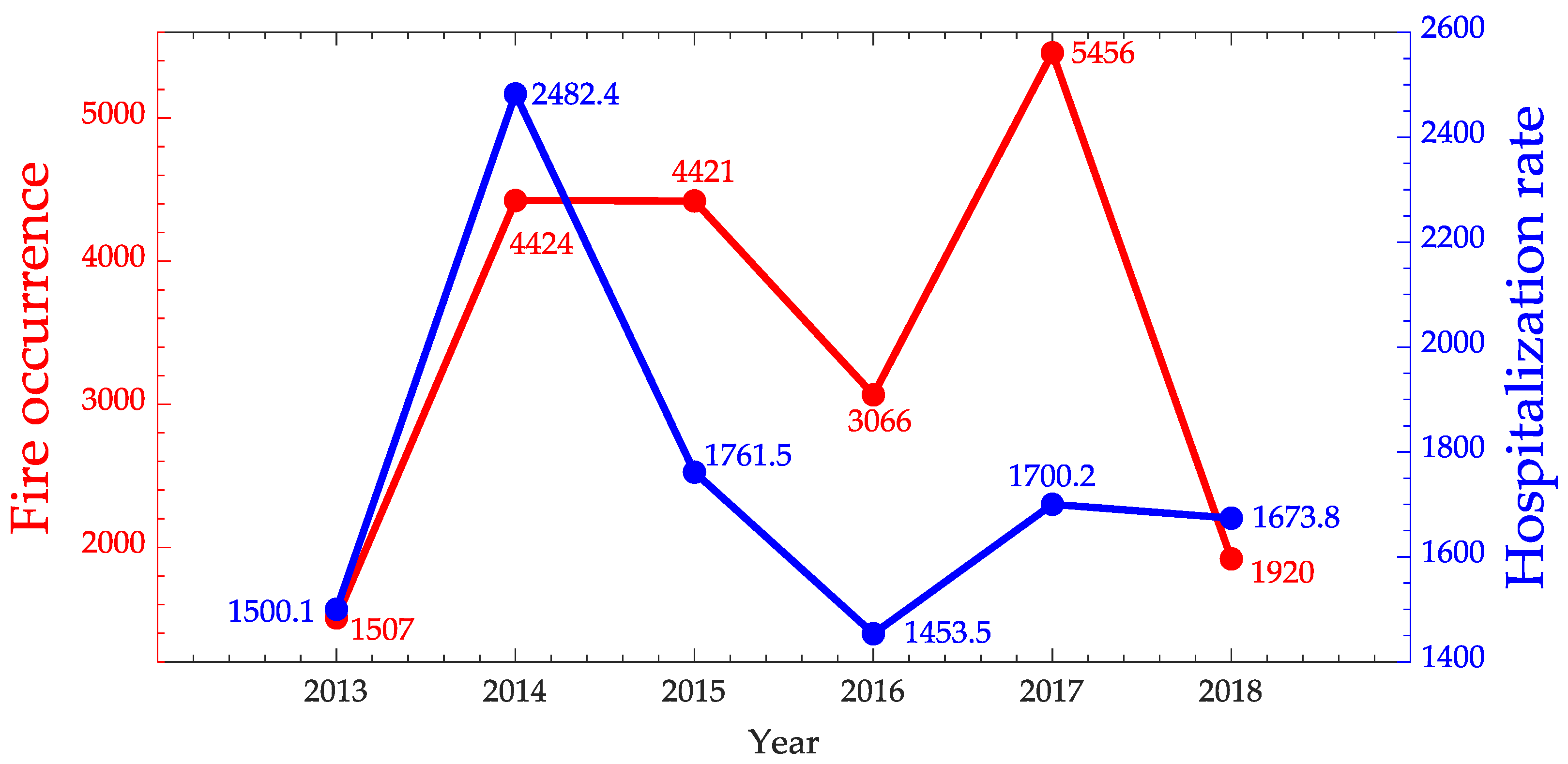
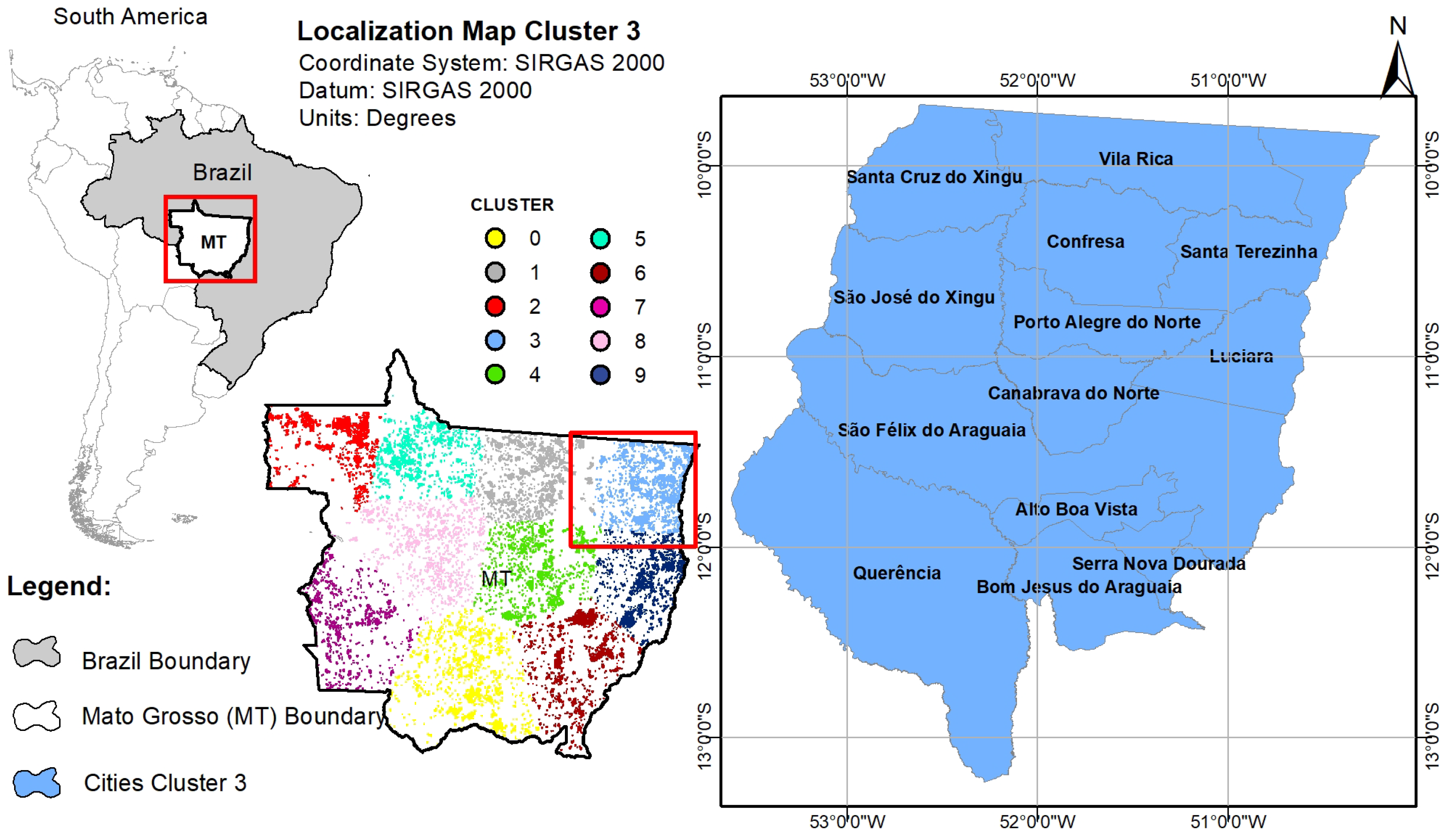
4.2. Clustering
4.3. Maranhão
4.4. Pará
4.5. Mato Grosso
5. Final Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Van der Werf, G.R.; Randerson, J.T.; Giglio, L.; Collatz, G.J.; Mu, M.; Kasibhatla, P.S.; Morton, D.C.; DeFries, R.S.; Jin, Y.; van Leeuwen, T.T. Global fire emissions and the contribution of deforestation, savanna, forest, agricultural, and peat fires (1997–2009). Atmos. Chem. Phys. 2010, 10, 11707–11735. [Google Scholar] [CrossRef] [Green Version]
- Morton, D.C.; Defries, R.S.; Randerson, J.T.; Giglio, L.; Schroeder, W.; Van Der Werf, G.R. Agricultural intensification increases deforestation fire activity in Amazonia. Glob. Chang. Biol. 2008, 14, 2262–2275. [Google Scholar] [CrossRef] [Green Version]
- Van Lierop, P.; Lindquist, E.; Sathyapala, S.; Franceschini, G. Global forest area disturbance from fire, insect pests, diseases and severe weather events. For. Ecol. Manag. 2015, 352, 78–88. [Google Scholar] [CrossRef] [Green Version]
- Cruz Marques, A.C. Human migration and the spread of malaria in Brazil. Parasitol. Today 1987, 3, 166–170. [Google Scholar] [CrossRef]
- Bauch, S.C.; Birkenbach, A.M.; Pattanayak, S.K.; Sills, E.O. Public health impacts of ecosystem change in the Brazilian Amazon. Proc. Natl. Acad. Sci. USA 2015, 112, 7414–7419. [Google Scholar] [CrossRef] [Green Version]
- Patz, J.A.; Graczyk, T.K.; Geller, N.; Vittor, A.Y. Effects of environmental change on emerging parasitic diseases. Int. J. Parasitol. 2000, 30, 1395–1405. [Google Scholar] [CrossRef] [Green Version]
- Yanoviak, S.P.; Paredes, J.E.R.; Lounibos, L.P.; Weaver, S.C. Deforestation Alters Phytotelm Habitat Availability and Mosquito Production in the Peruvian Amazon. Ecol. Appl. 2006, 16, 1854–1864. [Google Scholar] [CrossRef]
- Smith, L.T.; Aragão, L.E.O.C.; Sabel, C.E.; Nakaya, T. Drought impacts on children’s respiratory health in the Brazilian Amazon. Sci. Rep. 2014, 4, 3726. [Google Scholar] [CrossRef] [Green Version]
- Foley, J.A.; Asner, G.P.; Costa, M.H.; Coe, M.T.; DeFries, R.; Gibbs, H.K.; Howard, E.A.; Olson, S.; Patz, J.; Ramankutty, N.; et al. Amazonia revealed: Forest degradation and loss of ecosystem goods and services in the Amazon Basin. Front. Ecol. Environ. 2007, 5, 25–32. [Google Scholar] [CrossRef]
- Nepstad, D.C.; Verssimo, A.; Alencar, A.; Nobre, C.; Lima, E.; Lefebvre, P.; Schlesinger, P.; Potter, C.; Moutinho, P.; Mendoza, E.; et al. Large-scale impoverishment of Amazonian forests by logging and fire. Nature 1999, 398, 505–508. [Google Scholar] [CrossRef]
- Pereira, A.A.; Alves Pereira, J.A.; Morelli, F.; de Barros, D.A.; Acerbi, F.W.; Scolforo, J.R.S. Validação de focos de calor utilizados no monitoramento orbital de queimadas por meio de imagens TM. Cerne 2012, 18, 335–343. [Google Scholar] [CrossRef] [Green Version]
- Boquett, J.A.; Zagonel-Oliveira, M.; Jobim, L.F.; Jobim, M.; Gonzaga, L., Jr.; Veronez, M.R.; Rosa Fagundes, N.J.; Schüler-Faccini, L. Spatial analyzes of HLA data in Rio Grande do Sul, South Brazil: Genetic structure and possible correlation with autoimune diseases. Int. J. Health Geogr. 2018. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Miler, H.J. Geographic Data Mining and Knowledge Discovery, 1st ed.; Taylor e Francis: London, UK, 2001. [Google Scholar]
- Guo, D.; Mennis, J. Spatial data mining and geographic knowledge discovery—An introduction. Comput. Environ. Urban Syst. 2009, 33, 403–408. [Google Scholar] [CrossRef]
- Carvalho, O., Jr.; Nepstad, D. Forest fire: Impacts on plant biomass and mammals populations in eastern Amazon. In Proceedings of the First LBA Scientific Conference, Belém, PA, Brazil, 25–30 June 2000. [Google Scholar]
- Fonseca-Morello, T.; Ramos, R.; Steil, L.; Parry, L.; Barlow, K.; Markusson, N.; Ferreira, A. Queimadas e IncêNdios Florestais na AmazôNia Brasileira: Porque as PolíTicas PúBlicas têM Efeito Limitado? Ambiente Soc. 2017, 20, 19–38. [Google Scholar] [CrossRef]
- Stefani, A.; Roux, E.; Fotsing, J.-M.; Carme, B. Studying relationships between environment and malaria incidence in Camopi (French Guiana) through the objective selection of buffer-based landscape characterisations. Int. J. Health Geogr. 2011, 10, 65. [Google Scholar] [CrossRef] [PubMed]
- Hahn, M.B.; Gangnon, R.E.; Barcellos, C.; Asner, G.P.; Patz, J.A. Influence of Deforestation, Logging, and Fire on Malaria in the Brazilian Amazon. PLoS ONE 2014, 9, e85725. [Google Scholar] [CrossRef] [Green Version]
- Da Camara, C.C.; Calado, T.J.; Ermida, S.L.; Trigo, I.F. Calibration of the Fire Weather Index over Mediterranean Europe based on fire activity retrieved from MSG satellite imagery. Int. J. Wildland Fire 2014, 23, 945–958. [Google Scholar] [CrossRef]
- Brasil. Manual of Surveillance and Control of Visceral Leishmaniasis, 1st ed.; Ministério da Saúde: Brasília, Brasil, 2014. [Google Scholar]
- de A Marzochi, M.C.; Marzochi, K.B.F. Tegumentary and Visceral Leishmaniases in Brazil—Emerging Anthropozoonosis and Possibilities for Their Control. Cad. SaúDe PúBl. 1994, 10, 359–375. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, M.U.; Da Silva-Nunes, M. Evidence-based public health and prospects for malaria control in Brazil. J. Infect. Dev. Ctries 2010, 4, 533–545. [Google Scholar] [CrossRef] [Green Version]
- Parente, A.T.; De Souza, E.B.; Miranda Ribeiro, J.B. Occurrence of malaria in four cities in the state of Pará during 1988 to 2005 and its relationships with deforestation. Acta Amaz. 2012, 42, 41–48. [Google Scholar] [CrossRef]
- Peterson, A.T. Ecological niche modelling and understanding the geography of disease transmission. Itália Veterinária Italiana 2007, 43, 393–400. [Google Scholar]
- Youssouf, H.; Liousse, C.; Roblou, L.; Assamoi, E.-M.; Salonen, R.O.; Maesano, C.; Banerjee, S.; Annesi-Maesano, I. Non-accidental health impacts of wildfire smoke. Int. J. Environ. Res. Public Health 2014, 11, 11772–11804. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Do Carmo, C.N.; Hacon, S.; de Freitas, K.M.L.; Freitas, S.R. Associação entre material particulado de queimadas e doenças respiratórias na região sul da Amazônia brasileira. Rev. Panam. Salud Publica 2010, 27, 10–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, J.; Kamber, M. Data Mining: Concepts and Techniques, 2nd ed.; Elsevier: San Francisco, CA, USA, 2006. [Google Scholar]
- Linonati, R.; Da Camara, C.C.; Pereira, J.M.C.; Peres, L.F. On a new coordinate system for improved discrimination of vegetation and burned áreas using MIR/NIR information. Remote. Sens. Environ. 2011, 115, 1464–1477. [Google Scholar] [CrossRef]
- Linonati, R.; Da Camara, C.C.; Setzer, A.W.; Morelli, F.; Melchiori, A.E. An Algorithm for Burned Area Detection in the Brazilian Cerrado Using 4 μm MODIS Imagery. Remote Sens. 2015, 7, 15782–15803. [Google Scholar] [CrossRef] [Green Version]
- National Institute for Space Research Burns—INPE Queimadas. Available online: http://www.inpe.br/queimadas/bdqueimada (accessed on 10 October 2018).
- Adriaans, P.; Zantinge, D. Data Mining, 1st ed.; Addison-Wesley Professional: Harlow, UK, 1996. [Google Scholar]
- Kumar, V.; Steinbach, M.; Tan, P.N. Introduction to Data Mining, 1st ed.; Addison Wesley: Boston, MA, USA, 2005. [Google Scholar]
- Han, J.; Kamber, M.P.J. Data Mining: Concepts and Techniques, 3rd ed.; Elsevier: Waltham, MA, USA, 2011. [Google Scholar]
- Cortês, S.; Da, C.; Porcaro, R.M.L.S. Mineração de Dados Funcionalidades, técnicas e abordagens; Pontifícia Universidade Católica do Rio de Janeiro: Rio de Janeiro, Brazil, 2002; pp. 1–35. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Yale University Press: New York, NY, USA, 2009. [Google Scholar]
- Giasson, E.; Hartemink, A.E.; Tornquist, C.G.; Teske, R.; Bagatini, T. Avaliação de cinco algoritmos de árvores de decisão e três tipos de modelos digitais de elevação para mapeamento digital de solos a nível semidetalhado na Bacia do Lageado Grande, RS, Brasil. Ciência Rural 2013, 43, 1967–1973. [Google Scholar] [CrossRef] [Green Version]
- Cios, K.J.; Kurgan, L.A.; Pedrycz, W.; Swiniarski, R.W. Data Mining: A Knowledge Dicovery Approach; Springer: New York, NY, USA, 2007. [Google Scholar]
- Franck, E.; Witten, I.H. DATA MINING Practical Machine Learning Tools and Techniques, 2nd ed.; Elsevier: San Francisco, CA, USA, 2005. [Google Scholar]
- Korting, T.S. C4. 5 Algorithm and Multivariate Decision Trees; Image Processing Division, National Institute for Space Research-INPE: São José dos Campos, Brazil, 2007. [Google Scholar]
- Kaur, G.; Chhabra, A. Improved J48 Classification Algorithm for the Prediction of Diabetes. Int. J. Comput. Appl. 2014, 98. [Google Scholar] [CrossRef]
- Watzlawick, L.F.; Kirchner, F.F.; de Azambuja Madruga, P.R. Avaliação de classificação digital em imagens de vídeo multiespectral utilizando matriz confusão. Revista de Ciências Exatas e Naturais 2003, 5, 47–57. [Google Scholar]
- Landis, R.J.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Int. Biom. Soc. 1977, 33, 159–174. [Google Scholar] [CrossRef] [Green Version]
- Groth, R. Data Mining: Building Competitive Advantage; Prentice Hall PTR: New Jersey, NJ, USA, 2000. [Google Scholar]
- De Souza, J.A. Optimizing metric access methods for querying and mining complex data types. J. Braz. Comput. Soc. 2014, 20. [Google Scholar] [CrossRef] [Green Version]
- Souza, B.F.S.; Teixeira, A.d.S.; Francisco, d.A.T.F.; de Andrde, E.M.; Arthur, P.d.S. Evaluation of Classifiers Based on Machines Learning to Land Use and Cover Classification on Caatinga Biome. Revista Brasileira de Cartografia 2010, 20, 385–399. [Google Scholar]
- Koua, E.L.; Kraak, M.J. Geovisualization to support the exploration of large health and demographic survey data. Int. J. Health Geogr. 2004. [Google Scholar] [CrossRef] [Green Version]
- Evans, J. Straightforward Statistics for the Behavioral Sciences; Brooks/Cole Publishing Company: Pacific Grove, CA, USA, 1996. [Google Scholar]
- Panda Data Anaysis Library. Available online: https://pandas.pydata.org/ (accessed on 10 October 2018).
- Brakto, I.; Kubat, M.; Michalski, R.S. Machine Learning and Data Mining: Methods and Applications; John Wiley & Sons Ltda: New York, NY, USA, 1998. [Google Scholar]
- Araújo, F.; Ferreira, L.G.; Arantes, A.E. Distribution Patterns of Burned Areas in the Brazilian Biomes: An Analysis Based on Satellite Data for the 2002–2010 Period. Remote Sens. 2012, 4, 1929–1946. [Google Scholar] [CrossRef] [Green Version]
- Schroeder, W.; Alencar, A.; Arima, E.; Setzer, A. A Distribuição Espacial e Variabilidade Interanual do Fogo na Amazônia. Geophys. Monogr. Ser. 2009, 186, 43–60. [Google Scholar]
- De Oliveira-Júnior, J.F.; Teodoro, P.E.; da Silva Junior, C.A.; Baio, F.H.R.; Gava, R.; Capristo-Silva, G.F.; de Gois, G.; Filho, W.L.F.C.; Lima, M.; de Barros Santiago, D.; et al. Fire foci related to rainfall and biomes of the state of Mato Grosso do Sul, Brazil. Agric. For. Meteorol. 2020, 282–283, 107861. [Google Scholar] [CrossRef]
- Silva, A.M.C.; Mattos, I.E.; Ignotti, E.; Hacon, S.d.S. Material particulado originário de queimadas e doenças respiratórias. Rev Saúde Pública 2013, 47, 345–352. [Google Scholar] [CrossRef] [Green Version]
- Melo, A.S.; Justino, F.; Lemos, C.F.; Sediyama, G.; Ribeiro, G. Suscetibilidade do Ambiente a OcorrêNcias de Queimadas sob CondiçõEs ClimáTicas Atuais e de Futuro Aquecimento Global. Rev. Bras. Meteorol. 2011, 26, 401–418. [Google Scholar] [CrossRef] [Green Version]
- Santos, T.O.D.; Filho, V.S.A.; Rocha, V.M.; Menezes, J.S. The impacts of deforestation and burning of anthropogenic climate of the brazilian amazon: A review. Rev. Geogr. AcadêMica 2017, 11, 157–181. [Google Scholar]
- Viera, A.J.; Garrett, J.M. Understanding Interobserver Agreement: The Kappa Statistic. Fam. Med. Res. Ser. 2005, 37, 360–363. [Google Scholar]
- Leygonie, C.A.; Michel, B.S.; Mathian, H.; Sanders, L. Gaining a better understanding of respiratory health inequalities among cities: An ecological case study on elderly males in the larger French cities. Int. J. Health Geogr. 2013, 12, 19. [Google Scholar] [CrossRef] [Green Version]
- Almeida, A.S.; Werneck, G.L. Prediction of high-risk áreas for visceral leishmaniasis using socioeconomic indicators and remote sensing data. Int. J. Health Geogr. 2014, 13, 13. [Google Scholar] [CrossRef] [Green Version]
- MacDonald, A.J.; Mordecai, E.A. Amazon deforestation drives malaria transmission, and malaria burden reduces forest clearing. Proc. Natl. Acad. Sci. USA 2019, 116, 22212–22218. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Hao, Y.; Hwang, K.; Wang, L. Disease Prediction by Machine Learning Over Big Data From Healthcare Communities. IEEE Access Spec. Sect. Healthc. Big Data 2017, 5, 8869–8879. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| a | b | c | d | e | f | ← Classified as: |
|---|---|---|---|---|---|---|
| 304 | 0 | 0 | 0 | 0 | 0 | a = Pampa |
| 0 | 3732 | 0 | 105 | 22 | 0 | b = Caatinga |
| 0 | 0 | 39,641 | 117 | 0 | 0 | c = Amazônia |
| 0 | 121 | 202 | 25,637 | 110 | 30 | d = Cerrado |
| 15 | 26 | 0 | 119 | 5662 | 0 | e = Mata Atlântica |
| 0 | 0 | 3 | 10 | 0 | 2176 | f = Pantanal |
| Correctly Classified Instances | 77,152 | |||||
| Incorrectly Classified Instances | 889 | |||||
| Kappa statistic | ||||||
| Mean absolute error | ||||||
| Root mean squared error | ||||||
| Relative absolute error | ||||||
| Root relative squared error | ||||||
| Total Number of Instances | 78041 | |||||
| a | b | c | d | e | f | g | ← Classified as: |
|---|---|---|---|---|---|---|---|
| 737 | 0 | 0 | 0 | 0 | 0 | 21 | a = Rio Grande do Sul |
| 0 | 2497 | 0 | 0 | 0 | 0 | 18 | b = Bahia |
| 0 | 0 | 1102 | 0 | 0 | 0 | 0 | c = Ceara |
| 0 | 0 | 0 | 18,514 | 4 | 26 | 0 | d = Pará |
| 0 | 0 | 0 | 0 | 12,118 | 0 | 0 | e = Mato Grosso |
| 0 | 0 | 0 | 6 | 0 | 9446 | 0 | f = Maranhão |
| 0 | 11 | 0 | 0 | 0 | 0 | 3184 | g = Minas Gerais |
| ... | ... | ... | ... | ... | ... | ... | n =... |
| Correctly Classified Instances | 77,563 | ||||||
| Incorrectly Classified Instances | 478 | ||||||
| Kappa statistic | |||||||
| Mean absolute error | |||||||
| Root mean squared error | |||||||
| Relative absolute error | |||||||
| Root relative squared error | |||||||
| Total Number of Instances | 78041 | ||||||
| a | b | c | d | e | f | g | h | i | j | k | l | ← Classified as: |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 86 | 23 | 29 | 8 | 5 | 3 | 3 | 2 | 12 | 29 | 43 | 24 | a = Jan |
| 11 | 39 | 26 | 7 | 4 | 5 | 1 | 1 | 0 | 15 | 20 | 9 | b = Feb |
| 17 | 23 | 87 | 28 | 2 | 0 | 0 | 5 | 1 | 35 | 17 | 6 | c = Mar |
| 15 | 12 | 34 | 86 | 16 | 2 | 0 | 5 | 15 | 29 | 24 | 4 | d = Apr |
| 16 | 3 | 10 | 20 | 150 | 33 | 11 | 10 | 27 | 63 | 19 | 9 | e = May |
| 11 | 0 | 1 | 0 | 41 | 751 | 60 | 49 | 88 | 58 | 22 | 14 | f = Jun |
| 2 | 4 | 1 | 0 | 2 | 53 | 2486 | 186 | 140 | 55 | 106 | 37 | g = Jul |
| 4 | 0 | 2 | 2 | 7 | 20 | 206 | 5499 | 519 | 179 | 132 | 50 | h = Aug |
| 2 | 1 | 1 | 4 | 11 | 48 | 121 | 468 | 14956 | 354 | 174 | 64 | i = Sep |
| 19 | 8 | 33 | 24 | 17 | 56 | 45 | 205 | 612 | 3984 | 398 | 117 | j = Oct |
| 25 | 15 | 19 | 20 | 6 | 16 | 91 | 128 | 146 | 429 | 2871 | 268 | k = Nov |
| 21 | 5 | 15 | 9 | 6 | 11 | 27 | 56 | 87 | 169 | 363 | 1662 | l = Dec |
| Correctly Classified Instances | 32,657 | |||||||||||
| Incorrectly Classified Instances | 7556 | |||||||||||
| Kappa statistic | ||||||||||||
| Mean absolute error | ||||||||||||
| Root mean squared error | ||||||||||||
| Relative absolute error | ||||||||||||
| Root relative squared error | ||||||||||||
| Total Number of Instances | 40213 | |||||||||||
| a | b | ← Classified as: | |
|---|---|---|---|
| 58 | 2276 | a = RAINY | |
| 39 | 37,840 | b = DRY | |
| Correctly Classified Instances | 37,898 | ||
| Incorrectly Classified Instances | 2315 | ||
| Kappa statistic | |||
| Mean absolute error | |||
| Root mean squared error | |||
| Relative absolute error | |||
| Root relative squared error | |||
| Total Number of Instances | 40213 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schroeder, L.; Roberto Veronez, M.; Menezes de Souza, E.; Brum, D.; Gonzaga, L., Jr.; Rofatto, V.F. Respiratory Diseases, Malaria and Leishmaniasis: Temporal and Spatial Association with Fire Occurrences from Knowledge Discovery and Data Mining. Int. J. Environ. Res. Public Health 2020, 17, 3718. https://doi.org/10.3390/ijerph17103718
Schroeder L, Roberto Veronez M, Menezes de Souza E, Brum D, Gonzaga L Jr., Rofatto VF. Respiratory Diseases, Malaria and Leishmaniasis: Temporal and Spatial Association with Fire Occurrences from Knowledge Discovery and Data Mining. International Journal of Environmental Research and Public Health. 2020; 17(10):3718. https://doi.org/10.3390/ijerph17103718
Chicago/Turabian StyleSchroeder, Lucas, Mauricio Roberto Veronez, Eniuce Menezes de Souza, Diego Brum, Luiz Gonzaga, Jr., and Vinicius Francisco Rofatto. 2020. "Respiratory Diseases, Malaria and Leishmaniasis: Temporal and Spatial Association with Fire Occurrences from Knowledge Discovery and Data Mining" International Journal of Environmental Research and Public Health 17, no. 10: 3718. https://doi.org/10.3390/ijerph17103718