
Application of Deep Learning System Technology in Identification of Women’s Breast Cancer
Abstract
:1. Introduction
1.1. Literature Review
- *
- The top cause of mortality for women globally is breast cancer. Breast tissue samples from biopsies that have been stained with hematoxylin and eosin (H&E) are examined using microscopes to make the first diagnosis of breast cancer. Images of breast tissue are categorized into four groups using Inception-v3 convolutional neural network (CNN) fine tuning: (1) normal histology, (2) benign lesion, (3) localized carcinoma, and (4) invasive carcinomas [16].
- *
- While crowdsourcing has made it possible to annotate huge datasets of real-world photos, their use for biological applications necessitates a better understanding and, thus, a more specific description of the annotation job itself. Conventional machine learning techniques may struggle to cope with noisy annotations during training, despite being a significant resource for crowdsourcing annotation model learning. In this article, we provide a novel idea for learning from crowds that directly handles data aggregation as a part of the convolutional neural network’s (CNN’s) learning process through an extra crowdsourcing layer (AggNet) [17].
- *
- Breast cancer histology photos stained with hematoxylin and eosin are difficult to diagnose, labor-intensive, and often cause conflict amongst pathologists. Systems for computer-assisted diagnostics help pathologists increase the accuracy and consistency of their diagnoses. For the analysis of histology pictures, convolutional neural networks (CNNs) have been employed effectively. Breast cancer histology photos are divided into normal, benign, and malignant subclasses based on the density, variability, and arrangement of the cells as well as the overall structure and shape of the tissue [18].
- *
- A technique used to diagnose breast cancer is histopathology. In the medical field, supervised learning tasks have been successfully completed using machine learning (ML) techniques. Picture preprocessing, feature extraction, classification, and performance analysis are all steps in the cancer diagnostic process that determine if a given image contains cancer [19].
- *
- The mortality rate of breast cancer (BC) is significantly decreased by early identification. Computer-aided diagnosis (CAD) systems have been established in this research sector and are an efficient cost- and time-saving tool that supports physicians’ and radiologists’ decision making by providing highly accurate information [20].
- *
- Pathologists must manually diagnose breast cancer from biopsy tissue pictures, which is expensive, time-consuming, and fraught with difficulty. The development of the computer-aided diagnosis (CAD) system has made it possible for pathologists to recognize breast cancer more rapidly and accurately. This has led to a major increase in interest in deep learning models based on CAD. The framework “MultiNet” was created. In the suggested framework, three well-known pretrained models—DenseNet-201, NasNetMobile, and VGG16—are used to extract features from microscope pictures [21].
- *
- Early cancer diagnosis is essential for cancer research in cancer detection. These issues connect biomedicine and bioinformatics with methodologies from the area of computational intelligence to arrive at a solution. The use of computational intelligence technologies enables the identification of key indicators of the existence of malignant cells in cancer patients, such as the degree of risk (high or low) [22].
1.2. The Recent Works on Data Augmentation and GAN
- This article was a survey of different data augmentation techniques used on mammogram images in the field of medical imaging and deep learning. Its purpose was to provide an overview of basic and deep-learning-based augmentation techniques. The article discussed the challenges faced by DL models when processing radiological images, including overfitting and class imbalance. It explained that data augmentation can increase the training set size and help the model avoid overfitting. The article also mentioned other techniques to overcome overfitting, such as batch normalization, dropout, transfer learning, and early stopping. The article concluded by emphasizing the importance of data augmentation in improving the performance of DL models on mammogram images [25].
- 2.
- This paper surveyed recent works on image data augmentation for deep learning. It focused on techniques that enhanced the size and quality of training datasets to improve deep learning models. The paper covered various image augmentation methods, such as geometric transformations, color space augmentations, kernel filters, mixing images, random erasing, feature space augmentation, adversarial training, generative adversarial networks, neural style transfer, and meta-learning. It also briefly discussed other aspects of data augmentation, such as test-time augmentation, resolution impact, final dataset size, and curriculum learning. The paper explained how data augmentation helps reduce overfitting and improve model performance. The paper also mentioned other overfitting solutions in deep learning, such as architecture complexity, dropout regularization, batch normalization, transfer learning, and pretraining [26].
- 3.
- The recent works in data augmentation have focused on techniques for inflating the sizes of training datasets, such as translation, cropping, padding, rotation, and flipping. These techniques enable regularization in deep neural networks and reduce the chance of overfitting. However, there is no consensus on the best combination of these techniques, and more advanced methods, such as mixing images, require expert knowledge for validation and labeling. Data augmentation based on random erasing is frequently used, but not guaranteed to be advantageous in all conditions. In the context of computer vision tasks, imbalance problems in image datasets can lead to poor performance of algorithms. GANs have gained attention for their ability to model complex real-world data and their potential to restore balance in imbalanced datasets through adversarial learning [27].
- 4.
- This paper surveyed the applications of AI in breast cancer imaging, with a focus on data augmentation techniques. The study analyzed traditional machine learning and deep learning methods for lesion detection and classification and reviewed research on breast cancer risk prediction using mammograms. Data augmentation techniques, such as generative adversarial networks (GANs), were analyzed as a solution to the lack of labeled data. Self-supervised learning was also studied as a solution to the absence of large datasets. Despite challenges in developing AI techniques, it has great potential for improving accuracy and reducing workload for healthcare professionals. Data augmentation techniques aim to create high-quality datasets by generating synthetic mammograms, but further development is needed to accurately reproduce the specific characteristics of lesions. This study emphasized the need for further testing in real-world environments to ensure the safety of AI systems [28].
2. Methods
2.1. Database
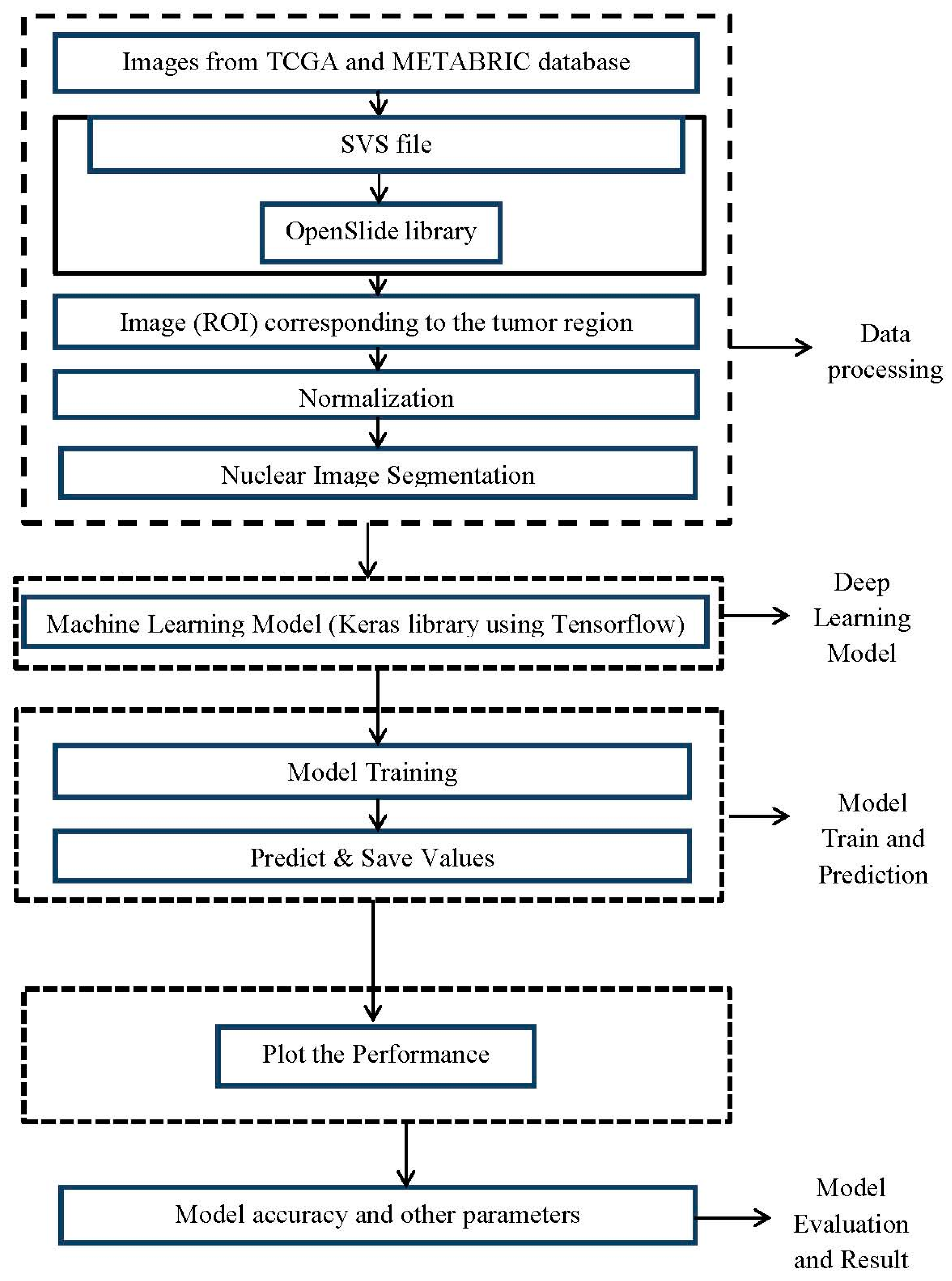
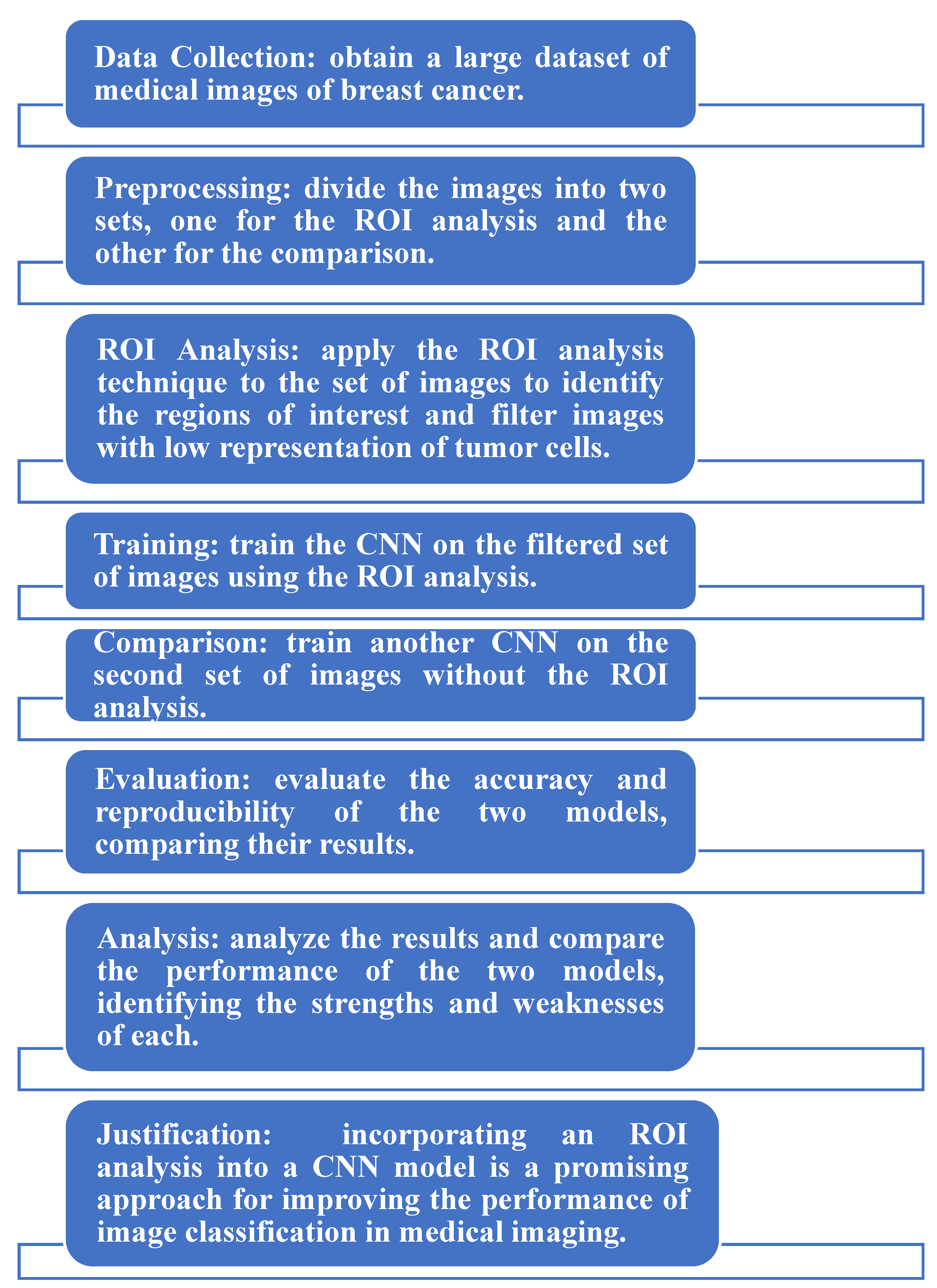
2.2. Development of the Proposed System
- (1)
- A digital image reading module.
- (2)
- A preprocessing, normalization, and image selection module.
- (3)
- A nuclear segmentation module.
- (4)
- A machine training module.
- (i)
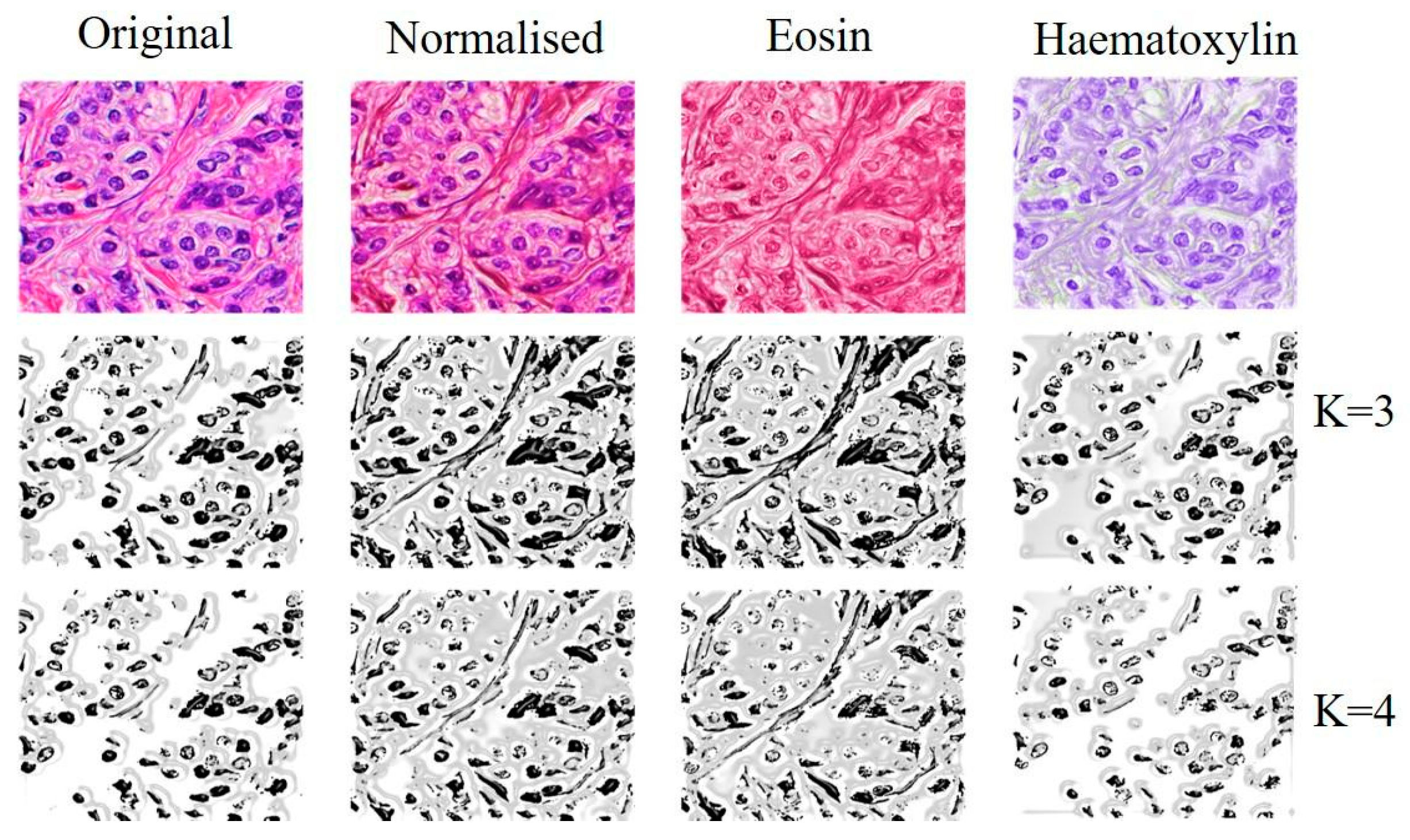
- Digital image reading module: The images from the TCGA and METABRIC databases were acquired with the Aperio® scanner, which generated an SVS file that contained four images in TIFF format with different sizes. The system used the OpenSlide library to read the images, and the OpenCV library was used to visualize the image (ROI) corresponding to the tumor ROI. The preprocessing and normalization system reads the PNG images from the database, allowing the user to determine changes in the image dimension. An image normalization module was implemented. We will use a tool developed by Macenko M et al., (2009) [32] that normalizes the staining intensity of the slides.
- (ii)
- Nuclear segmentation module: the nuclear segmentation strategies were implemented using Mask R-CNN after the construction of the definitive image bank, with the exclusion of low-quality images.
- (iii)
- Machine training module: This module is the foundation of machine learning. It was implemented after nuclear targeting. We intend to test different classic architectures, including AlexNet, VGGnet, Lenet, and GoogLeNet. The entire CNN will be developed with the Keras library, using Tensorflow as a learning tool.
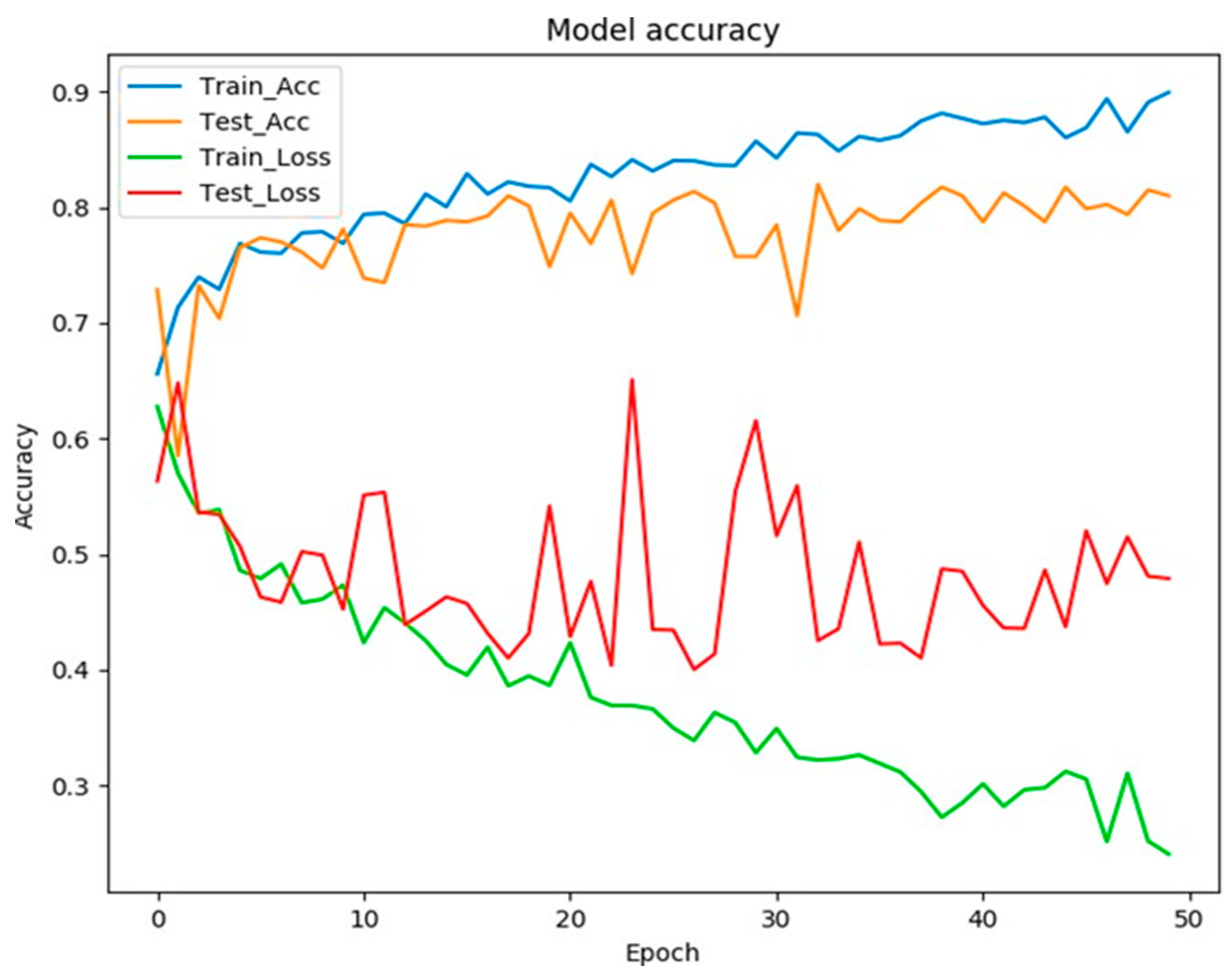
3. Results
4. Discussion
5. Conclusions
- Further testing and validation of the proposed method using a larger dataset of medical images to improve the robustness and generalizability of the results.
- Investigating the use of other deep learning techniques, such as deep neural networks (DNNs) or recurrent neural networks (RNNs), in combination with the CNNs for improved performance in identifying ROIs and classifying histological breast cancer subtypes.
- Developing a more efficient and automated method for selecting and preprocessing the medical images to be used in the CNNs in order to reduce the need for manual input and improve the speed and accuracy of the system.
- Investigating the use of different image normalization and clustering segmentation techniques to improve the performance of the system in identifying ROIs and filtering images with low representation of tumor cells.
- Developing a user-friendly and low-cost AI model that can be used by healthcare professionals in remote areas, with the goal of improving access to accurate and reliable breast cancer screening and diagnosis.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Momenimovahed, Z.; Salehiniya, H. Epidemiological characteristics of and risk factors for breast cancer in the world. Breast Cancer Targets Ther. 2019, 11, 151–164. [Google Scholar] [CrossRef] [Green Version]
- Alwan, N. Breast Cancer Among Iraqi Women: Preliminary Findings From a Regional Comparative Breast Cancer Research Project. J. Glob. Oncol. 2016, 2, 255–258. [Google Scholar] [CrossRef] [PubMed]
- Hussain, A.; Lafta, R. Cancer Trends in Iraq 2000–2016. Oman Med. J. 2021, 36, e219. [Google Scholar] [CrossRef] [PubMed]
- Feng, Y.; Spezia, M.; Huang, S.; Yuan, C.; Zeng, Z.; Zhang, L.; Ji, X.; Liu, W.; Huang, B.; Luo, W.; et al. Breast cancer development and progression: Risk factors, cancer stem cells, signaling pathways, genomics, and molecular pathogenesis. Genes Dis. 2018, 5, 77–106. [Google Scholar] [CrossRef] [PubMed]
- Pucci, C.; Martinelli, C.; Ciofani, G. Innovative approaches for cancer treatment: Current perspectives and new challenges. Ecancermedicalscience 2019, 13, 961. [Google Scholar] [CrossRef] [PubMed]
- Rakha, E.; Reis-Filho, J.S.; Baehner, F.; Dabbs, D.; Decker, T.; Eusebi, V.; Fox, S.B.; Ichihara, S.; Jacquemier, J.; Lakhani, S.; et al. Breast cancer prognostic classification in the molecular era: The role of histological grade. Breast Cancer Res. 2010, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Longacre, T.; Ennis, M.; Quenneville, L. Interobserver agreement and reproducibility in classification of invasive breast carcinoma: An NCI breast cancer family registry study. Mod. Pathol. 2006, 19, 195–207. [Google Scholar] [CrossRef] [Green Version]
- Zelic, R.; Giunchi, F.; Lianas, L.; Mascia, C.; Zanetti, G.; Andrén, O.; Fridfeldt, J.; Carlsson, J.; Davidsson, S.; Molinaro, L.; et al. Interchangeability of light and virtual microscopy for histopathological evaluation of prostate cancer. Sci. Rep. 2021, 11, 3257. [Google Scholar] [CrossRef]
- Shariat, S.F.; Karakiewicz, P.; Godoy, G.; Lerner, S. Use of nomograms for predictions of outcome in patients with advanced bladder cancer. Ther. Adv. Urol. 2009, 1, 13–26. [Google Scholar] [CrossRef] [Green Version]
- Taleghamar, H.; Moghadas-Dastjerdi, H.; Czarnota, G.J.; Sadeghi-Naini, A. Characterizing intra-tumor regions on quantitative ultrasound parametric images to predict breast cancer response to chemotherapy at pre-treatment. Sci. Rep. 2021, 11, 14865. [Google Scholar] [CrossRef]
- Zhang, Z.; Sejdić, E. Radiological images and machine learning: Trends, perspectives, and prospects. Comput. Biol. Med. 2019, 108, 354–370. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hosny, A.; Parmar, C.; Quackenbush, J.; Schwartz, L.; Aerts, H. Artificial intelligence in radiology. Nat. Rev. Cancer 2018, 18, 500–510. [Google Scholar] [CrossRef] [PubMed]
- Sultana, F.; Sufian, A.; Dutta, P. Advancements in Image Classification using Convolutional Neural Network. In Proceedings of the 2018 Fourth International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN), Kolkata, India, 22–23 November 2018; pp. 122–129. [Google Scholar] [CrossRef] [Green Version]
- Palle, R.; Boda, R. Automated image and video object detection based on hybrid heuristic-based U-net segmentation and faster region-convolutional neural network-enabled learning. Multimed. Tools Appl. 2022, 82, 3459–3484. [Google Scholar] [CrossRef]
- Lee, D.; Yoon, S. Application of Artificial Intelligence-Based Technologies in the Healthcare Industry: Opportunities and Challenges. Int. J. Environ. Res. Public Health 2021, 18, 271. [Google Scholar] [CrossRef] [PubMed]
- Golatkar, A.; Anand, D.; Sethi, A. Classification of breast cancer histology using deep learning. In International Conference Image Analysis and Recognition; Springer: Cham, Switzerland, 2018; pp. 837–844. [Google Scholar]
- Albarqouni, S.; Baur, C.; Achilles, F.; Belagiannis, V.; Demirci, S.; Navab, N. Aggnet: Deep learning from crowds for mitosis detection in breast cancer histology images. IEEE Trans. Med. Imaging 2016, 35, 1313–1321. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Wu, J.; Wu, Q. Classification of breast cancer histology images using multi-size and discriminative patches based on deep learning. IEEE Access 2019, 7, 21400–21408. [Google Scholar] [CrossRef]
- Saxena, S.; Gyanchandani, M. Machine learning methods for computer-aided breast cancer diagnosis using histopathology: A narrative review. J. Med. Imaging Radiat. Sci. 2020, 51, 182–193. [Google Scholar] [CrossRef]
- Alshayeji, M.H.; Ellethy, H.; Gupta, R. Computer-aided detection of breast cancer on the Wisconsin dataset: An artificial neural networks approach. Biomed. Signal Process. Control 2022, 71, 103141. [Google Scholar] [CrossRef]
- Khan, S.I.; Shahrior, A.; Karim, R.; Hasan, M.; Rahman, A. MultiNet: A deep neural network approach for detecting breast cancer through multi-scale feature fusion. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 6217–6228. [Google Scholar] [CrossRef]
- Dash, R.; Dash, R.; Rautray, R. A Computational Intelligence Approach for Cancer Detection Using Artificial Neural Network. In Intelligent and Cloud Computing; Springer: Singapore, 2022; pp. 565–570. [Google Scholar]
- Abe, J. Paraconsistent Artificial Neural Networks: An Introduction. In Proceedings of the Knowledge-Based Intelligent Information and Engineering Systems: 8th International Conference, KES 2004, Wellington, New Zealand, 20–25 September 2004; pp. 942–948. [Google Scholar] [CrossRef]
- Ahmed, O.; Lindblad, O. A Comparative Study on the Effect of Different Hyperparameters on the Performance of VGGNet-16 for Detection of Cardiomegaly in Chest X-ray Images. Master’s Thesis, School of Electrical Engineering and Computer Science, Stockholm, Sweden, 2022. [Google Scholar]
- Oza, P.; Sharma, P.; Patel, S.; Adedoyin, F.; Bruno, A. Image augmentation techniques for mammogram analysis. J. Imaging 2022, 8, 141. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Sampath, V.; Maurtua, I.; Aguilar Martin, J.J.; Gutierrez, A. A survey on generative adversarial networks for imbalance problems in computer vision tasks. J. Big Data 2021, 8, 27. [Google Scholar] [CrossRef] [PubMed]
- Mendes, J.; Domingues, J.; Aidos, H.; Garcia, N.; Matela, N. AI in Breast Cancer Imaging: A Survey of Different Applications. J. Imaging 2022, 8, 228. [Google Scholar] [CrossRef] [PubMed]
- Albuquerque, V.; Alexandria, A.; Cortez, P.; Tavares, J. Evaluation of multilayer perceptron and self-organizing map neural network topologies applied on microstructure segmentation from metallographic images. NDT E Int. 2009, 42, 644–651. [Google Scholar] [CrossRef]
- Bre, F.; Gimenez, J.; Fachinotti, V. Prediction of wind pressure coefficients on building surfaces using Artificial Neural Networks. Energy Build. 2017, 158, 1429–1441. [Google Scholar] [CrossRef]
- Bismeijer, T.; Canisius, S.; Wessels, L. Molecular characterization of breast and lung tumors by integration of multiple data types with functional sparse-factor analysis. PLoS Comput. Biol. 2018, 14, e1006520. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Macenko, M.; Niethammer, M.; Marron, J.; Borland, D.; Woosley, J.; Xiaojun, G.; Schmitt, C.; Thomas, N. A method for normalizing histology slides for quantitative analysis. In Proceedings of the 2009 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Boston, MA, USA, 28 June –1 July 2009; pp. 1107–1110. [Google Scholar]
- Vang, Y.S.; Chen, Z.; Xie, X. Deep learning framework for multi-class breast cancer histology image classification. In International Conference Image Analysis and Recognition; Springer: Cham, Switzerland, 2018; pp. 914–922. [Google Scholar]
- Jebarani, P.E.; Umadevi, N.; Dang, H.; Pomplun, M. A Novel Hybrid K-Means and GMM Machine Learning Model for Breast Cancer Detection. IEEE Access 2021, 9, 146153–146162. [Google Scholar] [CrossRef]
- Nomani, A.; Ansari, Y.; Nasirpour, M.H.; Masoumian, A.; Pour, E.S.; Valizadeh, A. PSOWNNs-CNN: A Computational Radiology for Breast Cancer Diagnosis Improvement Based on Image Processing Using Machine Learning Methods. Comput. Intell. Neurosci. 2022, 2022, 5667264. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article Citation | Sample and Methodology | Results | Contribution of Study |
|---|---|---|---|
| S Albarqouni. et al., (2016) [23] | S: They provided an experimental investigation on crowdsourcing learning. Annot8, a self-implemented web platform based on the Crowdflower API, was used in the experimental setting to realize picture annotation tasks for a publicly accessible biomedical image database. M: 1. Multi-scale CNN model; 2. Layer of aggregation (AG). | The findings demonstrated the importance of data aggregation integration and provided useful insights into how deep CNN learning using crowd annotations works. | They developed a fresh idea for crowdsourcing learning in this study. Through an extra crowdsourcing layer, the novel multi-scale CNN AggNet was made to handle data aggregation directly as part of the learning process. |
| Y Li et al., (2019) [24] | S: The diagnosis of breast cancer histology images with hematoxylin and eosin staining was non-trivial. Two pathologists labeled images as normal, benign, in situ carcinoma, or invasive carcinoma according to the predominant cancer type in each image, without specifying the area of interest. M: 1. The framework; 2. Sampling patches; 3. Feature extractor; 4. Screening patches; 5. Image-wise classification. | As a consequence, when the method described in this study was used to categorize breast cancer histology photos into four classes, it achieved 95% accuracy on the first test set and 88.89% accuracy on the whole test set. | For the classification of breast cancer histology images, they suggested patch sampling utilizing the multi-Size and discriminative patches approach. Two types of patches of various sizes were extracted, each of which included characteristics at the cellular and tissue levels. They created a classification framework that extracted features from the patches using feature extractors and computed the final feature of each whole image for classification through a classifier. They designed a patch selecting method to select more discriminative patches based on the CNN and K-means. |
| YS Vang et al., (2018) [33] | S: scanning the breast using an X-ray to check for changes in the United States M: In order to categorize patches, they first proposed utilizing Inception V3 to classify patches at the patch level. These extracted features were then transferred to a second layer of ensemble prediction fusion using GBM, logistic regression, and a support vector machine (SVM) to improve the predictions. The forecasts were made at the patch level. | The framework achieved an accuracy score of 87.5%, a 12.5% improvement over the baseline score. In spite of the refinement model, the model gave a 6% improvement over the standard model. For the normal, benign, in situ, and invasive classifications, each attained sensitivities of 77.8%, 66.7%, 88.9%, and 88.9%. This supports the inclusion of a binary class refinement step only for the benign and normal classes. | The experimental findings revealed that the approach outperformed the leading model by 12.5%. |
| Jebarani, et al., (2021) [34] | S: A digital dataset for screening mammography (DDSM) was received from the University of South Florida. M: An adaptive median filter was used for noise reduction, picture quality improvement, edge preservation, and smoothing. The multi-variant analysis and prediction rate for the suggested technique were determined using the ANOVA test. A hybrid mix of segmentation and detection was used on breast cancer. | The suggested approach enabled binary outcomes to indicate whether the tissue was benign, normal, or malignant when a mammographic picture included microcalcifications. | Early diagnosis improves treatment choices and saves lives. The versatile methodology combining modern segmentation methodologies with machine learning techniques achieved this goal by suggesting a new parameter for assessing the performance of K-means and a Gaussian mixture model (GMM). |
| Nomani. et al., (2022) [35] | S: In this study, 64 samples from the benign class and 51 samples from the malignant class from the MIAS dataset were evaluated. M: artificial intelligence, image processing, and CNN | 1. In 98.8% of the instances, 905 pictures with various diseases were appropriately identified. 2. The specificity of PSOWNNs was 98.8%. 3. Since PSOWNNs had a 98.6% accuracy rate, 830 people were appropriately identified as having breast cancer. 4. The results demonstrated that a CNN can gain additional functionalities that are more beneficial than methods that do not account for this. 5. The CNN showed that 799 people (94.9%) correctly identified 905 breast cancer patients. 6. In total, 106 pictures had incorrect diagnoses. | This article’s goal was to examine several methods for spotting breast cancer using artificial intelligence and image processing. The findings showed that the strategy described in this study may provide an excellent fusion picture that is superior to that produced by certain advanced image fusion algorithms in terms of both visual and objective evaluations. |
| Architecture | Salient Feature | Number of Parameters | Top-5 Accuracy | Top-1 Accuracy |
|---|---|---|---|---|
| AlexNet | Deeper | 62,378,344 | 84.60 | 63.30 |
| VGG16 | Fixed-size kernels | 138,357,544 | 91.90 | 74.40 |
| GoogLeNet | Fixed-size kernels | 23,000,000 | 92.20 | 74.80 |
| LetNet | Shortcut connections | 8,062,504 | 93.34 | 76.39 |
| Proposed method | Wider parallel kernels | 22,910,480 | 94.50 | 79.00 |
| Proposed Network | Accuracy (Epoch) | Training Time |
|---|---|---|
| Pretrain (160 × 160) | 69.05 (45) | 70.19 h |
| Target (224 × 224) | 72.61 (49) | 178.45 h |
| Resized Epoch 10 | 72.91 (46) | 146.72 h |
| Resized Epoch 30 | 72.79 (46) | 114.23 h |
| Resized Epoch 50 | 71.36 (45) | 109.81 h |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Fryan, L.H.; Shomo, M.I.; Alazzam, M.B. Application of Deep Learning System Technology in Identification of Women’s Breast Cancer. Medicina 2023, 59, 487. https://doi.org/10.3390/medicina59030487
Al Fryan LH, Shomo MI, Alazzam MB. Application of Deep Learning System Technology in Identification of Women’s Breast Cancer. Medicina. 2023; 59(3):487. https://doi.org/10.3390/medicina59030487
Chicago/Turabian StyleAl Fryan, Latefa Hamad, Mahasin Ibrahim Shomo, and Malik Bader Alazzam. 2023. "Application of Deep Learning System Technology in Identification of Women’s Breast Cancer" Medicina 59, no. 3: 487. https://doi.org/10.3390/medicina59030487