1. Introduction
The present worldwide pandemic caused by the SARS-CoV-2 strain of SARS coronavirus requires conventional and non-conventional methods of curing it. The COVID-19 virus is largely intractable to currently available antivirals. Nonetheless, the effective life span of most antivirals is limited. The application of alternative drugs, e.g., phytocompounds, can provide an auxiliary treatment plan, owing to their abundance, ease of accessibility, and low toxicity. Phytochemicals are secondary metabolites produced by plants for their survival and propagation. Various phytocompounds have been validated for their antiviral activity. Usually, the information about the healing ability of ethnomedicines is largely observational rather than strictly scientific. Phyto-therapeutic agents have gathered increased attention from the scientific community to deal with the current pandemic. In a recent article by Swain et al. [
1], a long list of potential anti-Covid phytochemicals was published along with the plant source and the inhibition effects.
The process of developing new drugs is a long-lasting and costly effort. The chemical diversity, unique properties, and wide structural variety make the natural compounds an excellent initial point serving as a good template for new drug discovery. Natural products with antiviral activity may provide an auxiliary way for tackling SARS-CoV-2 infections. In this study, we investigated the antiviral activity of flavonoids against SARS-CoV-2 [
2].
The aid of computational drug design methods opens the possibilities of transforming natural products for many health issues. The development and comprehension of antiviral drugs have led to a wide range of natural compound studies as an efficient and effective strategy, even with the aid of nanotechnology approaches [
3,
4], for identifying effective COVID-19 medication. To explore novel and potent therapies, a fundamental understanding of the interplay of molecular forces involving the spike protein and potential inhibitors in an aqueous medium is critical. The class of flavonoids, terpenes, terpenoids, alkaloids, quinone derivatives, and esters was less studied for drug interactions, and this class consists of hydrophobic and hydrophilic constituents. Among natural compounds, flavonoids constitute a possible target for antiviral drugs due to their large spectrum of medicinal properties (antioxidant, anti-inflammatory, and antiviral). Some flavonoids with substantial antiviral activity against SARS-CoV-2 are kaempferol, quercetin, myricetin, fisetin, and derivatives. The efficacy of many dietary flavanols as potential antiviral drugs for SARS-CoV-2 enzymes was performed by Patel et al. using in silico assays and machine learning techniques [
5]. Several other articles have studied the effectiveness of natural compounds in blocking the binding of the spike protein with the angiotensin-converting enzyme 2 (ACE2) receptor present on human cells [
6,
7,
8,
9,
10,
11]. Recent advances in machine learning (ML) methods have created the ability to identify new natural compounds for a given target [
12,
13]. A variety of machine learning algorithms was applied recently to resolve these problems to boost and reveal the treatment capabilities of natural compounds [
14,
15,
16,
17]. A recent paper by Barazorda-Ccahuana et al. [
18] showed significant effort in implementing computational methods to determine the efficacy of molecular inhibitors in different protonation states at different pHs and their applications in therapeutics.
In the recently published paper by Qiang et al. [
19], the ML model was developed on a natural product dataset obtained using the ChEMBL dataset. The transfer learning algorithm, data balancing technique, and model diagnostics applied in their work show a promising result in determining the lead compound. Glycyrrhizin and Nafamostat mesilate were selected as candidates for drug delivery. These compounds were transferred into micelle nanoparticles to improve the stability and availability of drugs in the cells to treat COVID-19. Such a target prediction model can be applied in natural product-based drug discovery to find more lead compounds and assist in drug repurposing. The free energy evaluations predict the missing experimental data for those receptor–ligand complexes with the absent experimental study [
20]. The data thus obtained can be adapted for building a training algorithm. The computationally obtained data could indeed decrease the reliability level of the training data set. However, the new prediction algorithms have a higher threshold for minimizing errors.
Last year, all available resources and ML were forced to narrow down the drug candidates and minimize clinical trial failure. Kowalewski and Ray developed models to help identify effective drugs against SARS-CoV-2 proteins. They collected 14 million chemicals from ZINC databases. A partitioning algorithm that follows the proper descriptor space was also explored [
21]. In silico modeling has been recognized as a path for applying natural products as potential disruptors of the initial infection. Experimental findings also exist in conjunction with in silico studies, which show the potential of plant-originated therapeutics for the treatment of COVID-19 [
22].
The literature still lacks binding abilities and the dynamic behavior of many natural compounds. This study presented an in silico drug design strategy based on docking, MD simulations and combined with ML methods with a broad descriptors database generated by [
23] to examine readily available natural-based combinations. The spike protein is responsible for invading the virion into the host cell by binding to the cell surface via the ACE2 receptor. Salt bridges and hydrogen bonding stabilize this interaction between the receptor–binding domain in the S1 subunit of the spike protein (S1-RBD) of SARS-CoV-2 and the ACE2. In this paper, 40 prevalent phytochemicals were studied for their binding affinity. The database of natural ligands was targeted to the available X-ray crystal structure of the SARS-CoV-2 S1-RBD bound to ACE2 (PDB ID: 6M0J) for docking. Their derivatives are polyphenols, flavonoids, alkaloids, terpenes, diarylheptanoids, and lectins. These compounds are polyphenols and flavonoids, alkaloids, anthraquinones, saponins, terpenes, coumarins, diarylheptanoids, and lectins. Some of the selected candidates from natural products targeted to the viral RBD of the SARS-CoV-2 spike protein have previously been studied using isothermal titration calorimetry ITC binding assay [
24], viz. celastrol, saikosaponin C, and amentoflavone. The dual computational approach and classification (supervised and unsupervised) methods applied in this work indicate that amentoflavone and glyrimizine may disrupt the interaction between ACE2 receptors and the spike protein of SARS-CoV-2. These natural products may bind to the viral spike protein, preventing SARS-CoV-2 from entering cells.
A sequence of methodologies was employed to establish the nature of the spike protein, stability of ligand-binding to spike protein, and the dominant characteristics required for antagonistic behavior of ligands. The best candidates’ ranking is based on a binding score and is proven by molecular dynamics simulations, followed by a classification algorithm and dimensionality reduction approach as principal component analysis (PCA) and a self-organizing map (SOM). The docking energies and geometrical properties between a ligand–receptor complex of a 40-natural-compound library are shown in
Supporting Information (
Supporting Information Table S1 Dataset of 40 natural compounds with docking scores).
2. Results and Discussion
2.1. Molecular Docking Results
The primary approach in structure-based drug design is to use in silico virtual screening methods to screen databases of small molecule compounds against targets of interest. In the current article, molecular docking software, Auto Dock Vina was employed to identify potential phytotherapeutic binders toward the receptor-binding domain (RBD) (PBD: 6M0J) of the SARS-CoV-2 spike protein. AutoDockVina software is now integrated into the SAMSON molecular design platform (
https://www.samson-connect.net, accessed on 21 November 2021) as a SAMSON extension. The extension provides additional functionality to easily prepare receptors and ligands, dock ligand libraries, analyses and export docking results. We used SAMSON and the Vina extension to configure calculations, export input files, run docking calculations in the cloud, and import results for visualization and analysis. The search space was defined by a docking box wrapper, the space around the receptor that will be searched according to the selected pocket for the RBD. The size of the grid box was set to 44.4, 21.3, 55.3Å for each axis. The number of modes was set to 200 and the exhaustiveness was set to 10. The active pocket amino acid residues were predicted by the webserver CASTp [
23] and summarized in
Table 1 and depicted in
Figure 1. A total of 40 molecules with 25 flexible chains for docking calculations was performed. Binding energy and the constant inhibition were obtained for 200 poses for each molecule. A novel protein–ligand interaction analyzer tool available with SAMSON software was used to understand the stability of the protein–ligand complexes interaction based on hydrogen bond analyses, amino acids environment, histogram distribution of the amino acids, SASA (solvent accessible surface area), radius of gyration, and contact area receptor–ligand.
2.2. Molecular Dynamics Simulation Protocol
The additive forcefield parameters for the ligands were obtained using CHARMM General Force Field (CGenFF) online web server (
https://cgenff.umaryland.edu, accessed on 21 November 2021) and were later converted to GROMACS force field format. The structure of the receptor-binding domain (6M0J) of the SARS-CoV-2 spike protein was obtained from the Protein Data Bank (PDB), and topology was prepared using CHARMM36 force field. We used the docked conformation to generate the coordinates of protein-drug complex. The combined protein and drug (system obtained from the autodocking studies as an initial guess) was kept in a box of dimension 90 × 90 × 90 Å
3 and solvated with the SPC/E water molecule. Physiological ion concentrations of Na
+ and Cl
− were used to neutralize the system.
Initially, each system was energy minimized using the steepest descent method for 10,000 steps, followed by heating it to 300 K in 1 ns using a Berendsen thermostat with a coupling constant of 0.6 ps. We applied restraints of 25 kcal/mol/Å2 on heavy atoms of proteins during the heating process. Thereafter, equilibration was carried out for 10 ns at constant temperature (300 K) and pressure (1 bar) without any restraints using the same Berenson thermostat and barostat with coupling constants of 0.6 ps each. Finally, we performed 300 ns unrestrained NPT equilibration using the Nosé-Hoover thermostat with a coupling constant of 0.6 ps. During the simulation, all atoms were constrained using Linear Constraint Solver (LINCS), and Particle Mesh Ewald (PME) method was used for electrostatics with long-range cut-off of 10 Å. The distance cut-offs for the van der Waals (vdW) were kept at 10 Å. The time step for each simulation was taken to be 2 fs.
2.3. Docking Results
Structure-based drug discovery efforts require knowledge of drug-binding sites on target proteins. The above procedure generates a set of residues that are part of the three identified pockets. To investigate which predicted sites are likely to be druggable, molecular docking is performed on each site using 40 molecules. The dock score (presented in the tables in
Supporting Information) is used here to verify and expand upon the ML predictions based on a combination of a descriptors obtained using AlvaDesc v.2 software (Milano, Italy
https://www.alvascience.com/alvadesc/, accessed on 15 October 2020). It is expected that predictions are more likely to be accurate when the residues with high binding scores are in the same region as residues with high dock scores. The residues were further classified using ML methods to bring out broad set of features that are helpful to identify druggable quality of natural compounds (complete dataset with a full list with descriptors is mentioned in the
SI).
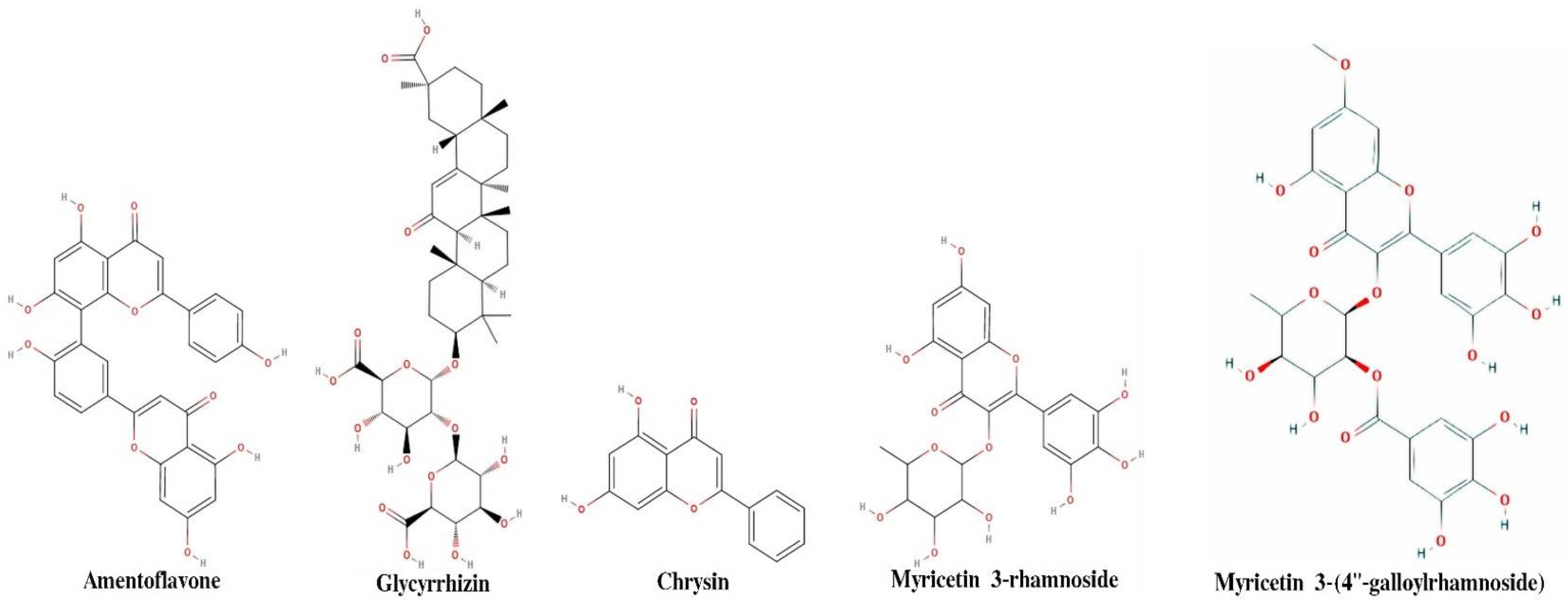
Figure 2 shows two-dimensional structure of five compounds, which shows maximum binding affinity in molecular docking. Drug-like properties of top five compounds are shown in
Table 2. According to Lipinski’s rule, a compound is labeled as drug-like when it meets the following criteria: molecular weight < 500 Da, H bond donor ≤ 5, H bond acceptor ≤ 10, Log
p ≤ 5, and TPSA > 140 Å
2.
Table 3 shows analysis of molecular docking results of these top five compounds.
The first five candidate molecules from the docking study are depicted in
Table 3 for inhibition candidates of the spike RBD protein with binding energies ranging from −9 to −8.3 kcal/mol. In
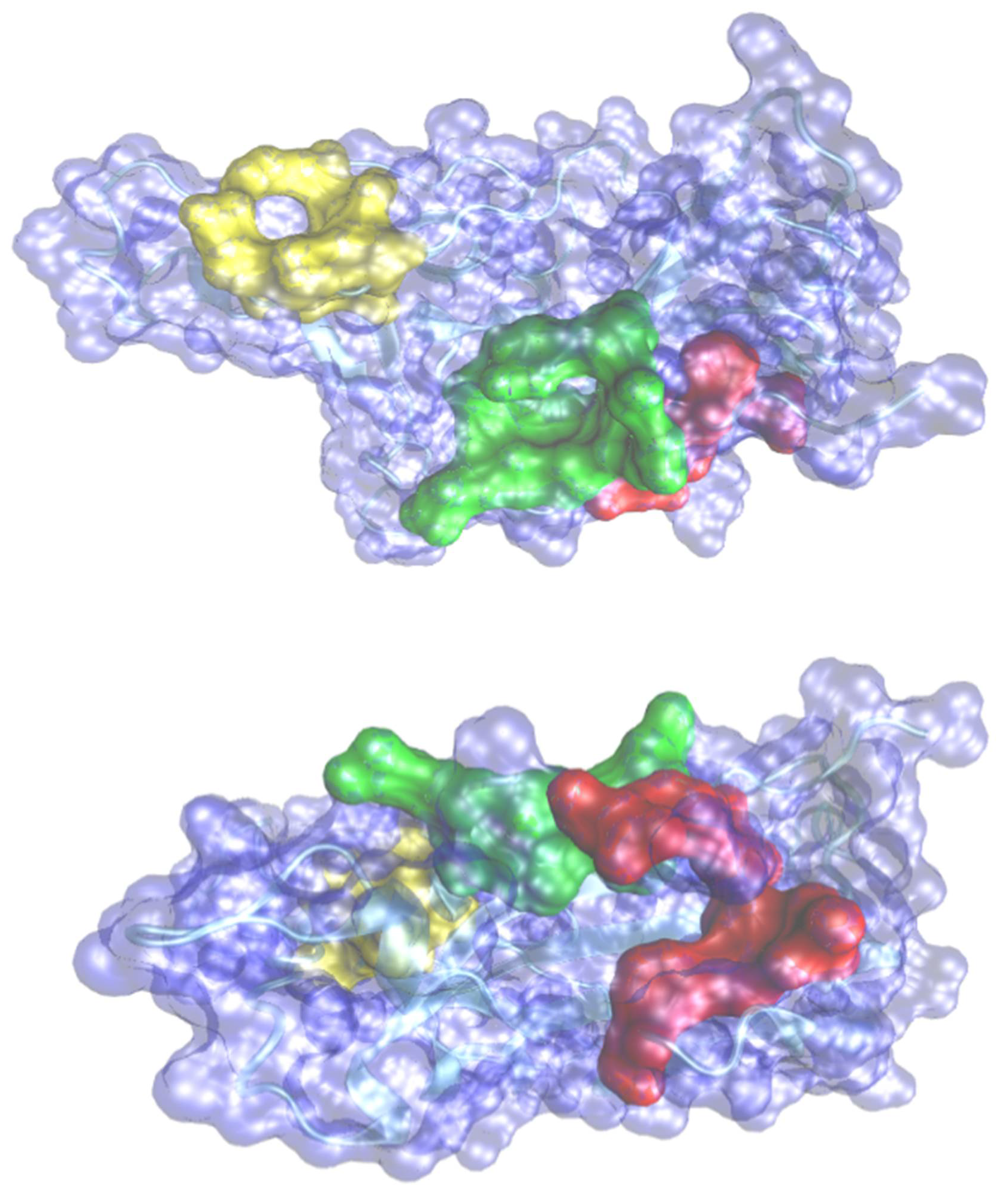
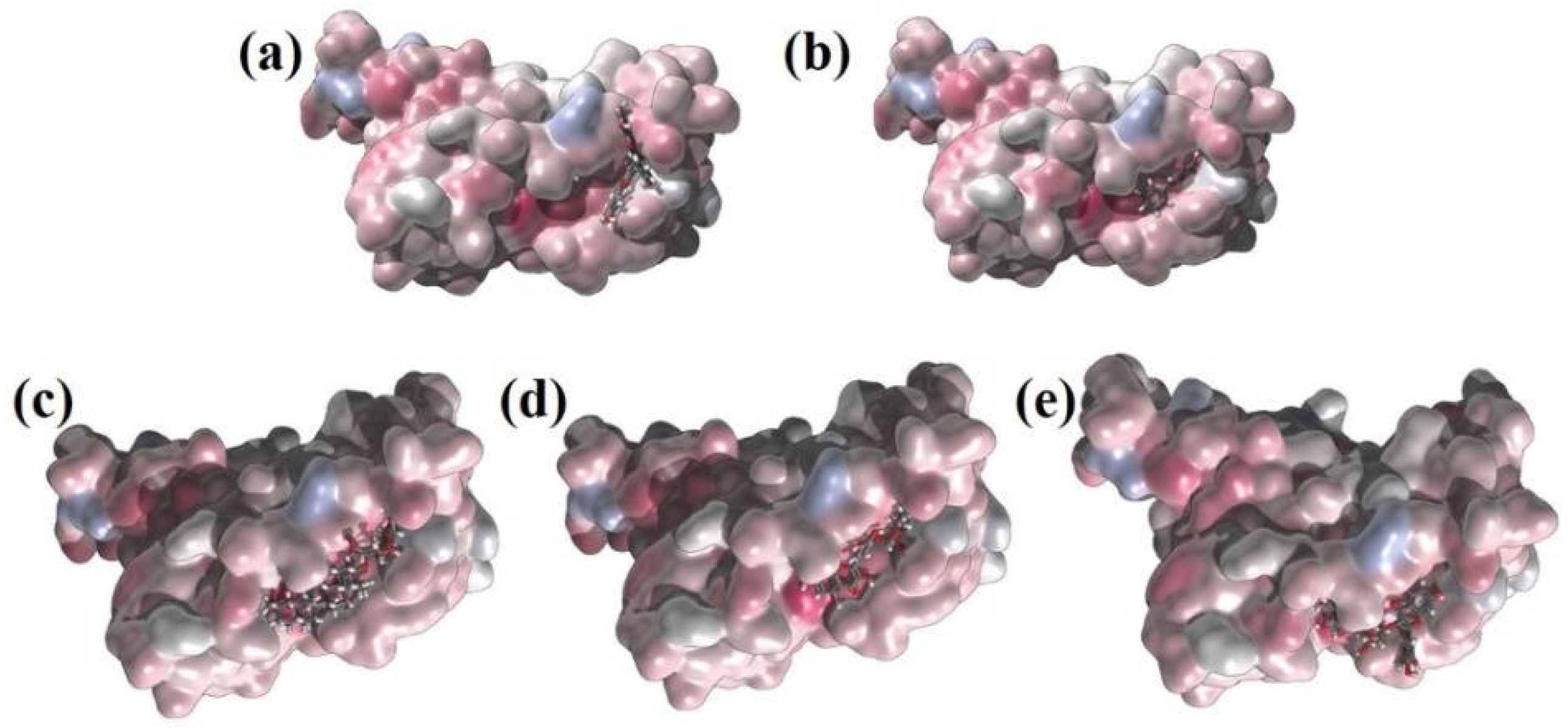
Figure 3, each of the five residues bound to the protein are shown. Hydrophobic Gaussian surface was used for graphical representation of the protein. The 40 phytocompounds were analyzed for the binding affinity.
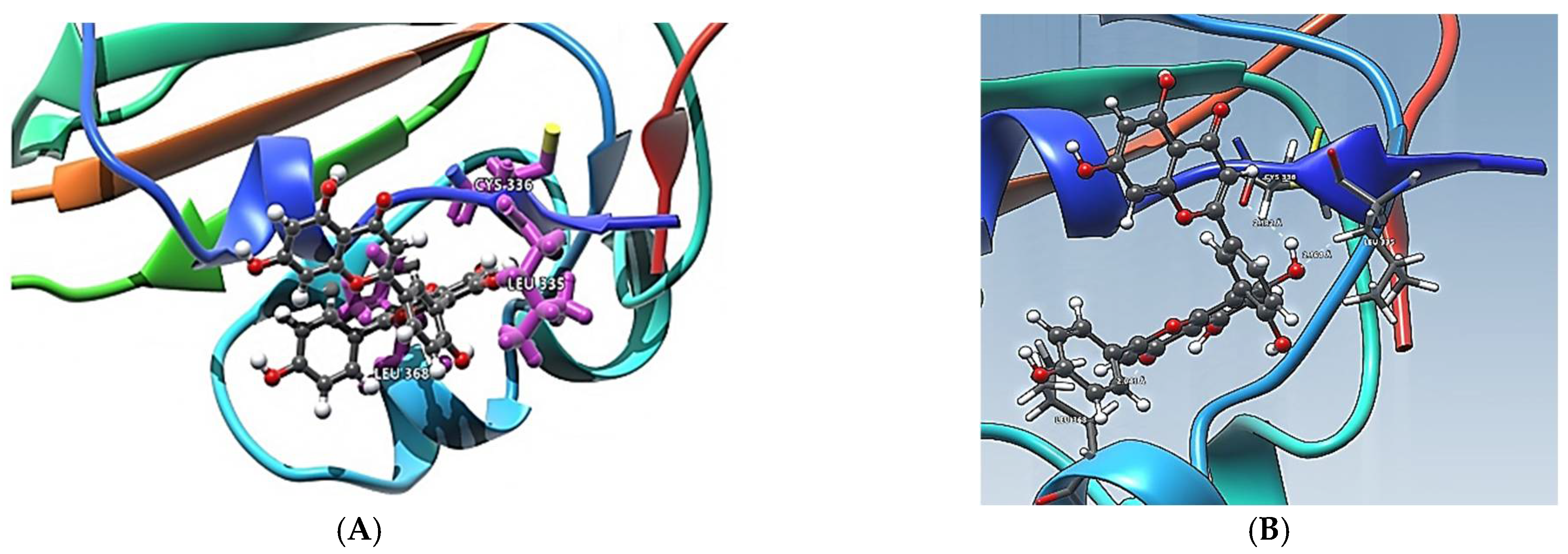
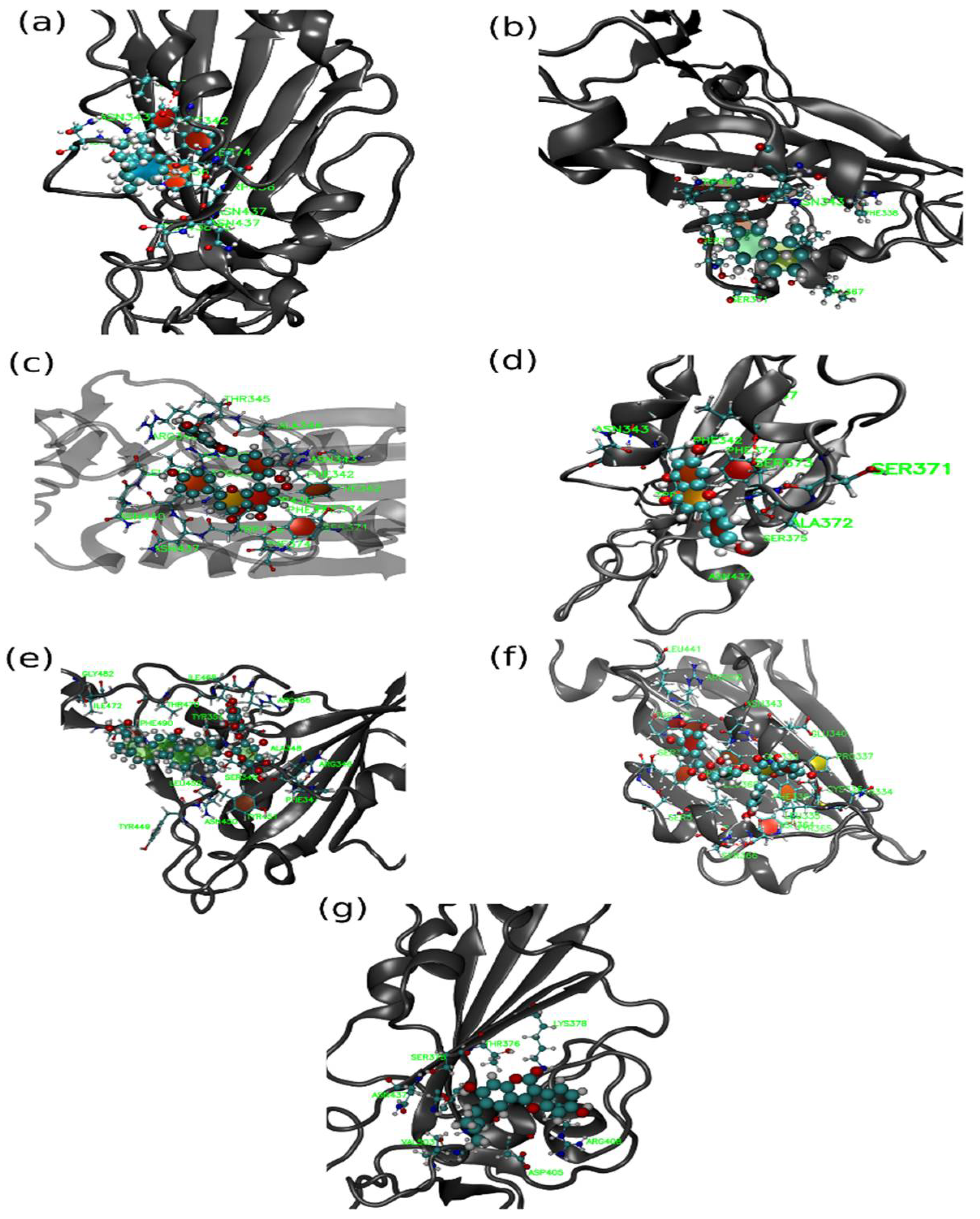
Figure 4 shows interactions of Amentoflavone and S-protein as obtained using molecular docking. The amino acid residues environment for the Amentoflavone shows effective hydrogen bond formation with LEU 335, CYS 336, and LEU 368. The obtained data for the hydrogen bonds based on the docking suggested that the interactions of the specific residues (amino acids residues) of RBD of SARS-CoV-2 S-protein and the corresponding ligand are capable of forming a stabilized hydrogen bond. LEU 335 is a part of a coil structure of the RDB, and LEU 368 is a part of a helix structure. Out of the 13 ligand-interacting residues, six are strongly hydrophilic, and the remaining seven are hydrophobic. These amino acids formed H bond with the ligand. The hydrophilic residues around the ligand create a hydrophobic environment and facilitate the binding to the hydrophobic pocket.
The radius of gyration is used to analyze the effect ligand on the distortion of the conformation of RBD upon binding. It could be seen that the RBD does not change significantly in terms of Rg for any of the shown ligands. This depicts no significant change in the protein conformation before and after ligand docking. SASA is another metric that allows us to determine the protein’s flexibility, stability, and folding in the presence and absence of ligands. With this property, we have a clearer picture of the immediate changes in the protein conformation. Since the values obtained for SASA between the complex RBD and the inhibitor candidates were without a significant deviation, we can conclude that the globally available surface area is preserved before and after the docking.
2.4. Molecular Dynamics Simulations
In order to prove the obtained docking scores and bring out the interaction between the class of flavonoids, terpenes and terpenoids with the spike protein, we performed all atom MD simulations on protein–ligand elected conformations. Four of the complexes exhibiting best docking energies and three of low binding energies complexes were chosen to figure out the key to successful binding. Preliminary simulations over 300 ns time were performed on the apo protein system and then compared our results with the seven selected protein–ligand complexes. Last 250 ns are considered for all the analysis. During the protein–ligand simulations, a new pocket was identified adjacent to pocket 1 (pocket 1A), showing greater affinity toward some of the ligands (see
Table 1).
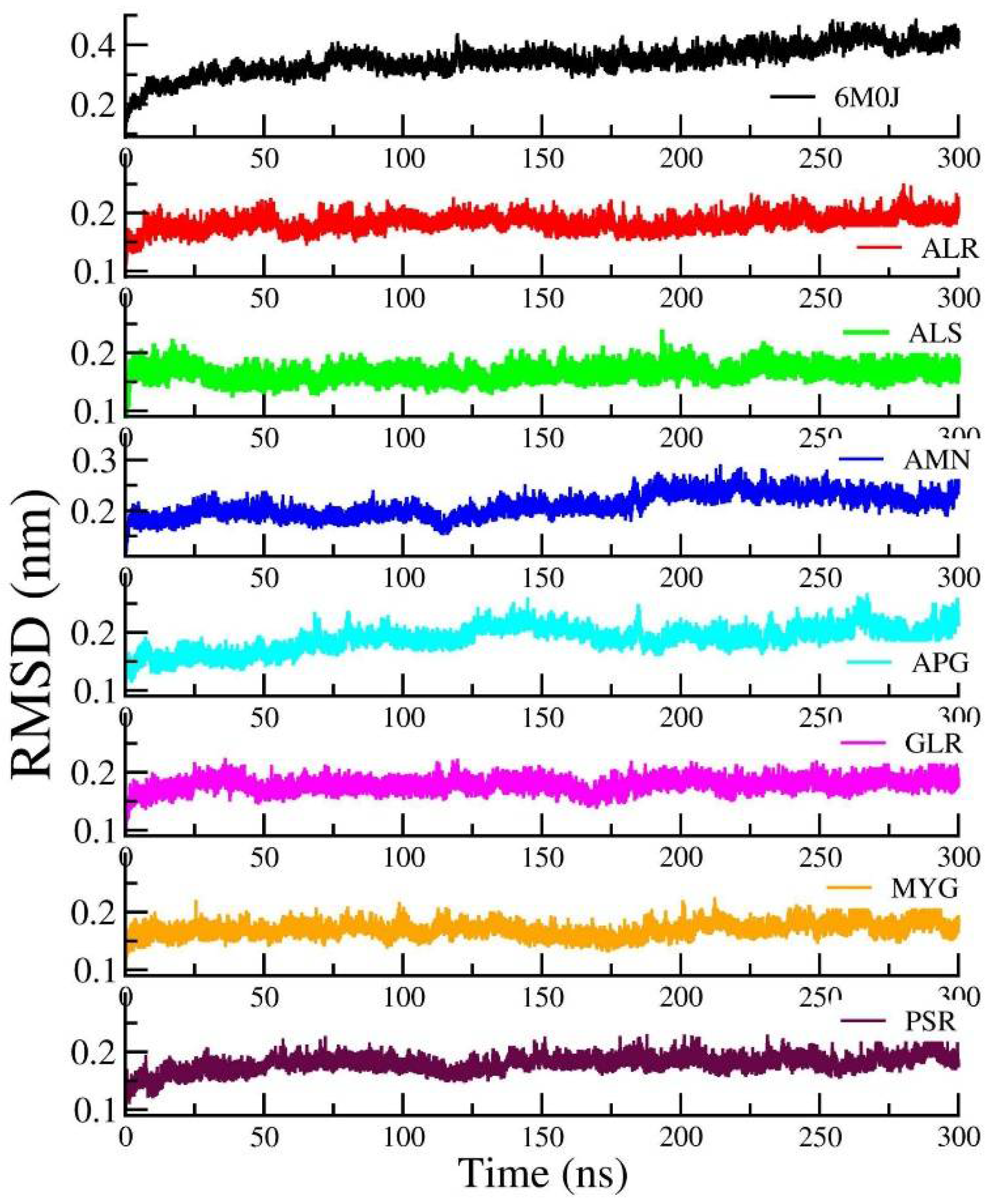
Figure 5 shows the RMSD of the RBD protein in water and compared with protein in all other seven protein–drug complexes. We observed that the protein–water and protein–ligand systems are stable throughout the production run. The RMSD of the protein in the protein–water complex is 0.377 nm. The RMSD of the protein in the protein–Amentoflavone is closer to the protein–water complex. To monitor the change in the structure of SARS-CoV-2 RBD resulting from its interaction with the seven drug molecules, we measured the radius of gyration of the backbone of the RBD as a function of time.
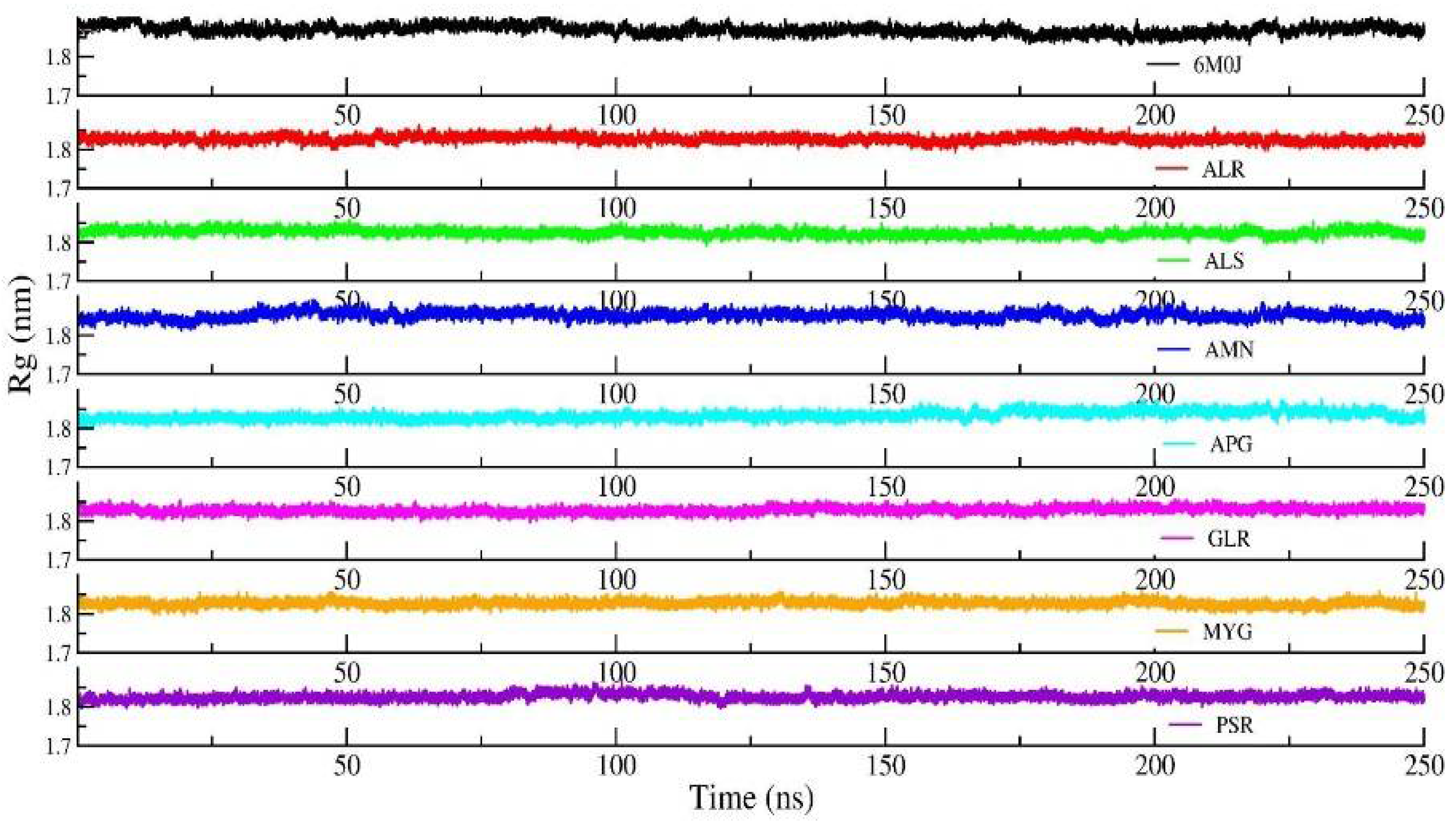
Figure 6 shows the Rg of the backbone (BB) of the RBD protein. Furthermore, the average value of Rg of the BB-RBD shows 1.869 nm. It shows that the Rg of the BB-RDB in the protein-Amentoflavone complex is perturbed from the other average Rg values of the protein–ligand complexes. The average SASA of the protein in the protein–ligand complex is 108 nm
2. However, in case of protein–Amentoflavone complex, average SASA is higher by 2 nm
2 (see
Figure 7).
2.5. Hydrogen Bond Interactions between Ligands and SARS-CoV-2
The H bonded interactions were assessed between polar groups of the drugs and amino acids of the protein. Ligand ALS and ALR did not show any significant H bond contacts.
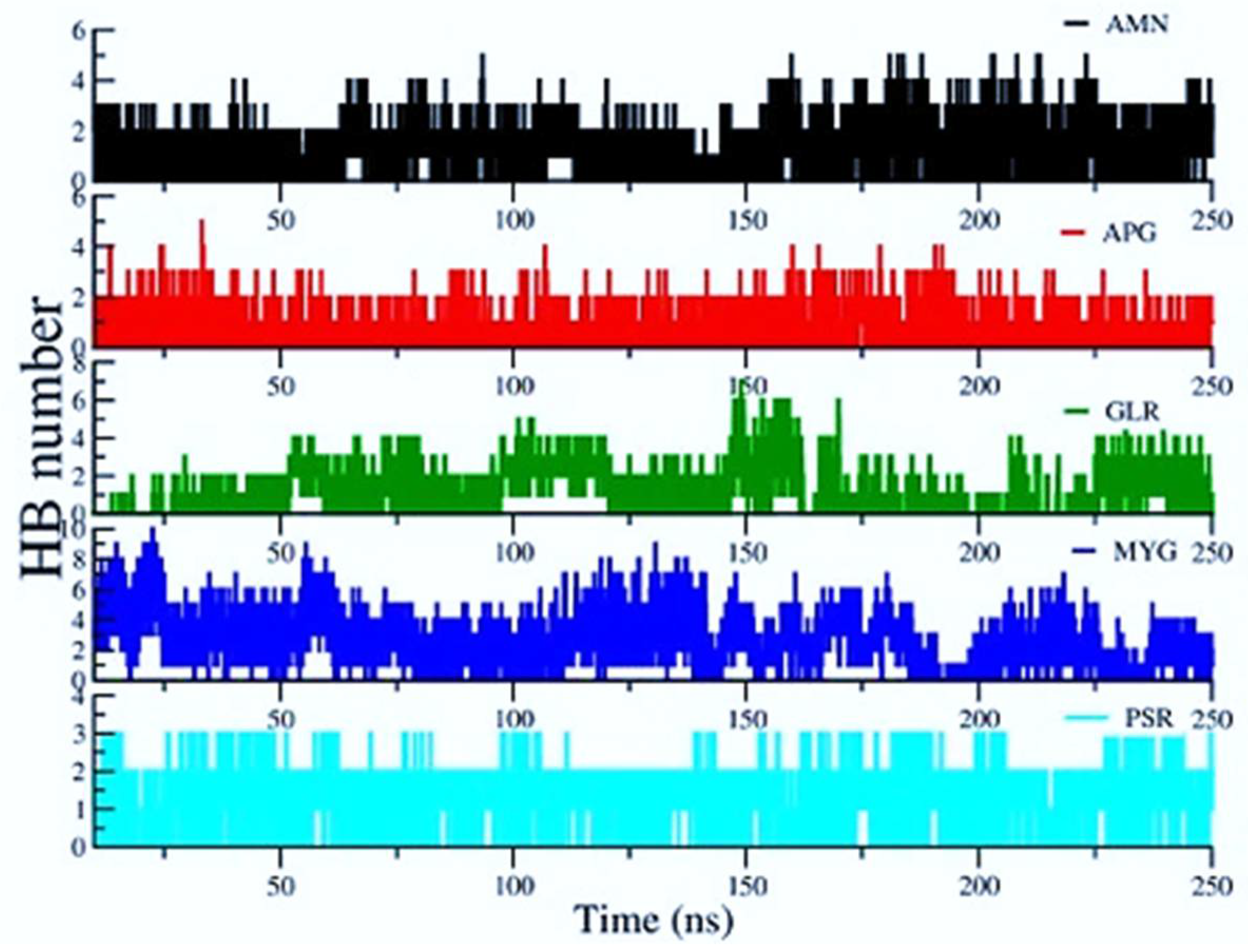
Figure 8 shows the average number of H Bonds between the protein and ligands. We observed that Myricetin-3-(4″-Galloylrhamnoside) creates the highest average number of H Bonds (2.473) with the RBD protein over the entire simulation followed by Amentoflavone and Glycyrrhizin.
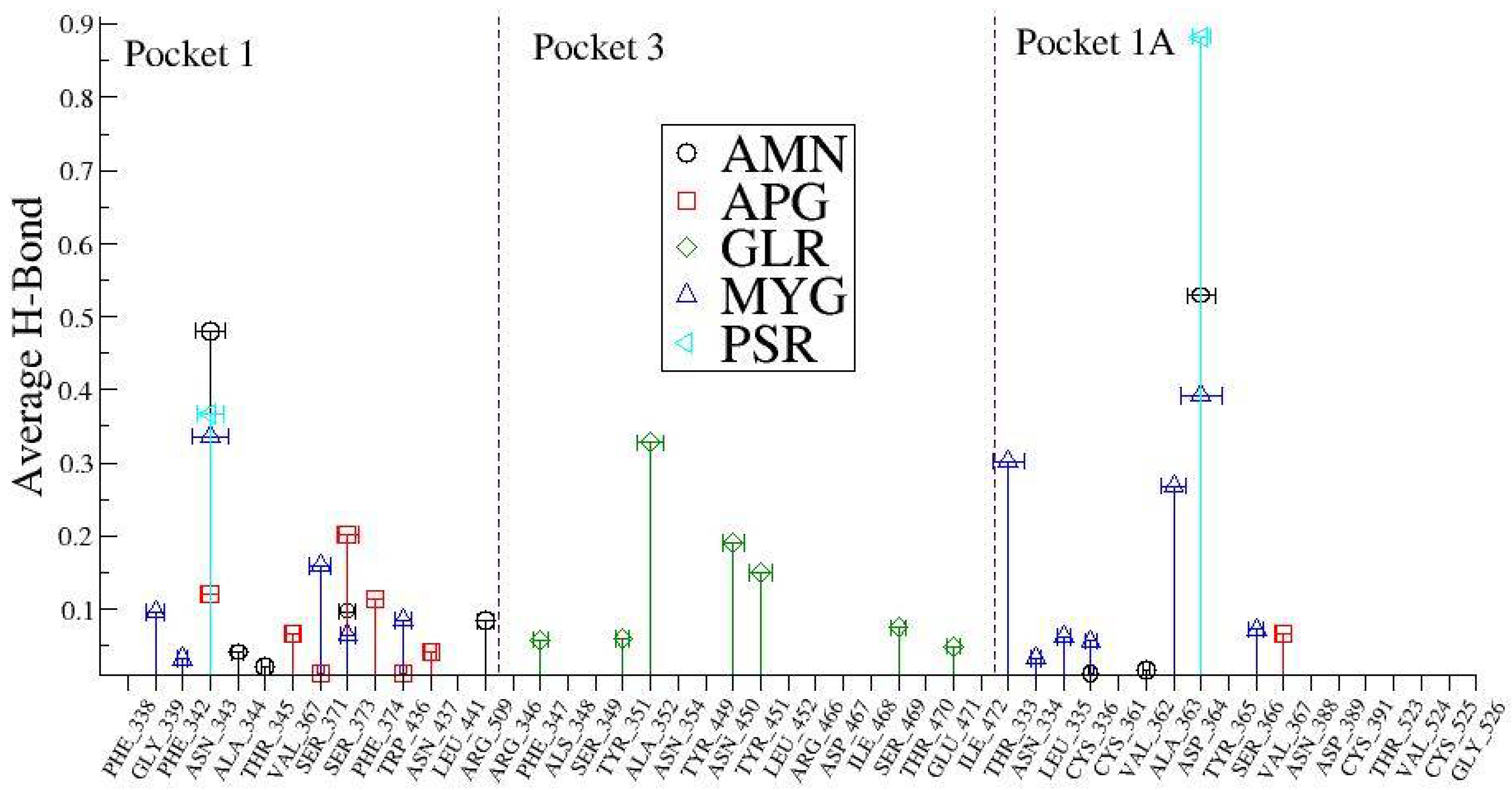
In order to understand these interactions with the natural compounds (
Figure 9), we plotted the average hydrogen bonding interactions in pocket 1, pocket 3, and pocket 1A (see
Figure 10). We found that asparagine (ASN_343) amino acid makes a strong H bond with the ligand molecules like AMN, PSR, MYG, and APG in the pocket 1. Similarly, other amino acid residues that have hydrogen bonding with the ligands were found to be SER_373, PHE_374, SER_371, VAL_367, GLY_339, ASN_437, ARG_509, ALA_344, THR_345 and PHE_342. Further, in pocket 3, the ligand molecule GLR showed hydrogen bonding with the amino acids at TYR_353, TYR_449, ASN_459, ILE_468, THR_470, SER_349 and ARG_346.
2.6. Retention Time of Ligands in Different Binding Pockets of SARS-CoV-2
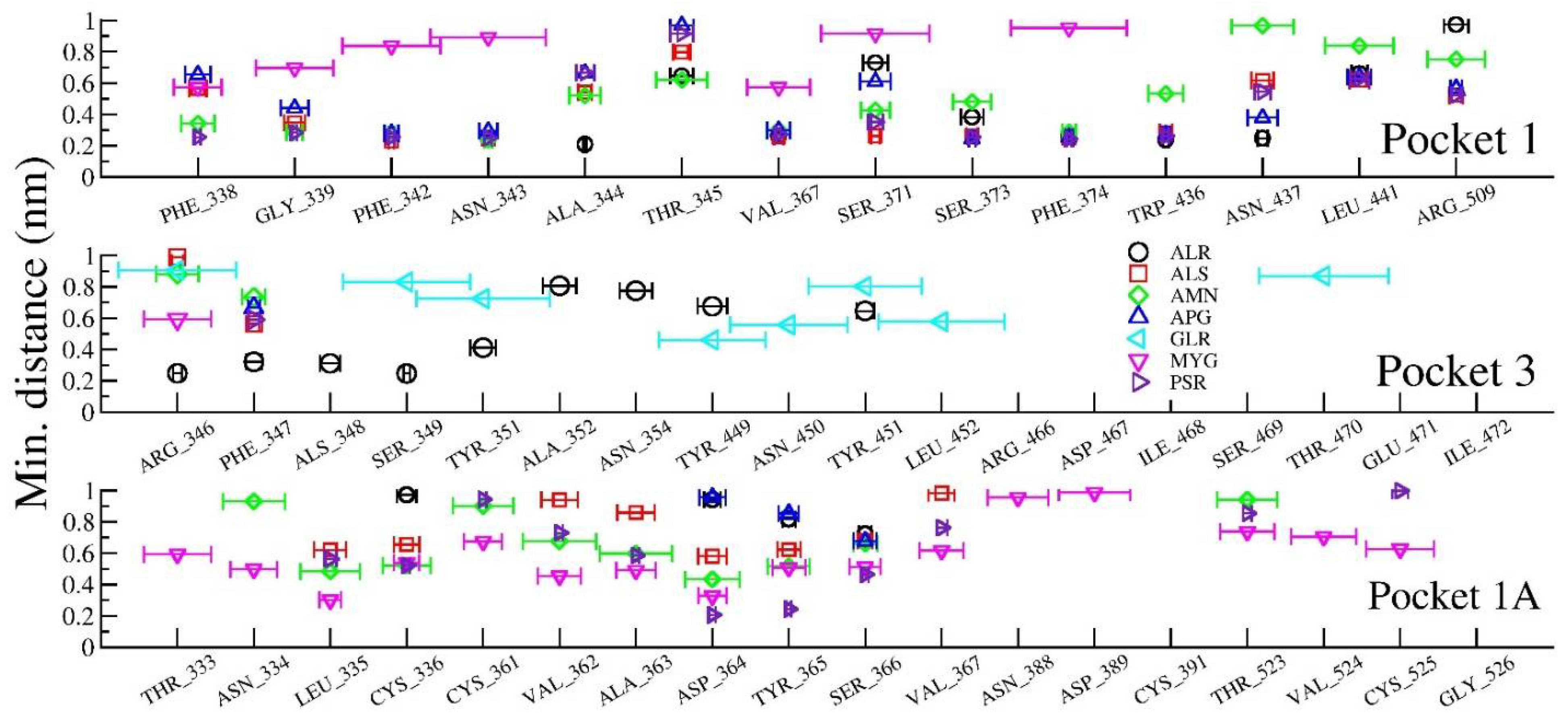
We investigated the interatomic contacts between ligands and the closest amino acids in the protein across the MD trajectories. We found three important pockets based on the closest distance criteria of the dynamic motion of the ligand. These pockets are similar to the results obtained from molecular docking. We found that pocket 1 and pocket 3 play a crucial role for the selected ligands. Furthermore, we investigated pocket 1A, which is adjacent (and within 1–2 nm) to pocket 1, also playing an important role in our MD simulations.
To bring out the retention time of ligand in the pockets, the distance between ligands and closest amino acids of the three pockets (viz, in between spiral α-helices, loop dominant region, and at N- or C- terminal of the protein) is plotted in
Figure 11.
Figure 11 shows the interaction distances and retention time of seven drugs in pocket 1, pocket 1-A and pocket 3. Consistent with our docking results, we found that ALS (Allo-Aromadendrene), AMN (Amentophlavone), APG (Apigenin) and PSR (Psoralidin) majorly stay in pocket 1, while GLR majorly occupies pocket 3 and MYG stays in pocket 1A. Ligand ALR binds in both pocket 1 and pocket 3. However, we noticed that none of the seven ligands are close to the pocket 2, consistent with molecular docking results.
The ligand molecules such as ALR, PSR, ALS, AMN lie within 5Å from the residue in pocket 1, and the ligand molecules such as ALR and GLR bind to the residue within 5Å from pocket 3. Here, ligand molecule PSR is found within a distance of 5Å, indicating the strength of binding of those with the protein. The ligand GLR is found to be away from both pocket 1 and pocket 1A, resulting in its unbound character with the protein active sites.
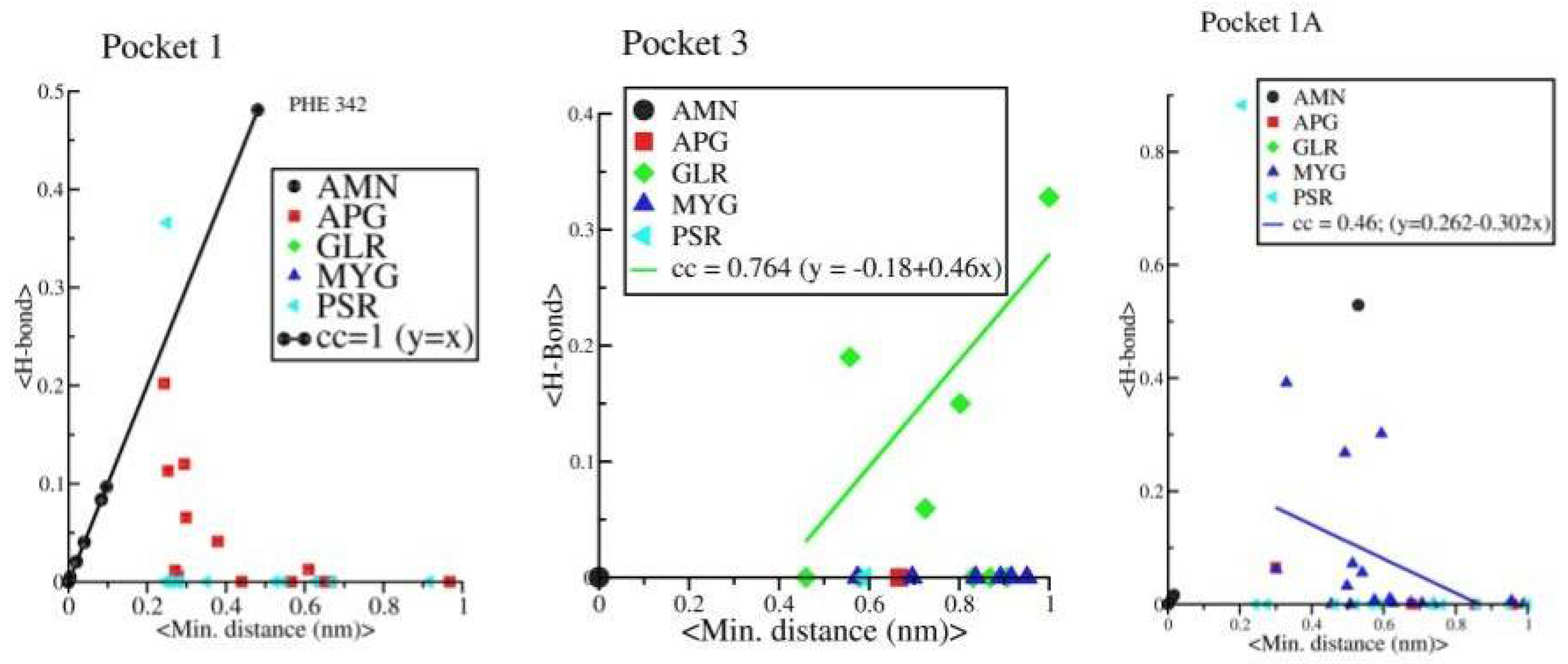
Further, we observed a linear correlation between minimum distance and average H bonds in protein-AMN complex which indicates that complexation is mainly driven by H bond formations. However, protein-GLR and protein-MYG complexes show poor correlation (see
Figure 12). Other four complexes are not showing any such linear correlations. The strength of H bond, strong correlation with minimum distance and long retention time in pocket 1 shows that AMN is the best ligand among all other seven selected ligands that can show antagonistic activity against spike protein, followed by GLR and MYG. The major binding site of AMN, GLR, and MYG are pocket 1, pocket 3, and pocket 1A, respectively.
2.7. Hierarchical Clustering
After identification of best ligands that could potentially block the binding of spike protein, we applied ML techniques to identify the features responsible for better binding of these ligands. This can be helpful to identify new molecules with similar features which can show binding with spike protein. All 40 ligands were used for this study. It was of substantial interest to check if the previous partitioning results (partitioning by the use of three different groups of descriptors, namely drug-likeness descriptors, topological and geometric descriptors, and WHIM descriptors) could be confirmed by a coarser scheme of separation (partitioning) offered by hierarchical or non-hierarchical (K-means) cluster analysis. This study has shown that they could be reliably used for this goal. The scheme using PCA and K-means partitioning has led to the following general outputs:
Drug-likeness descriptors: 10 clusters were identified based on drug-likeness descriptors, wherein GLR and one of the myrecitin ligand fall in one cluster; AMN falls in cluster 8, and the other three myrecitin ligands are distributed in cluster 6 (one ligand) and cluster 9 (2 ligands).
WHIM descriptors: seven clusters were identified where GLR is in cluster 2; AMN and all myrecitin ligands are in cluster 5;
Topological and geometrical descriptors: three clusters were identified where GLR and all myrecitin ligands are in cluster 1; AMN is in cluster 2.
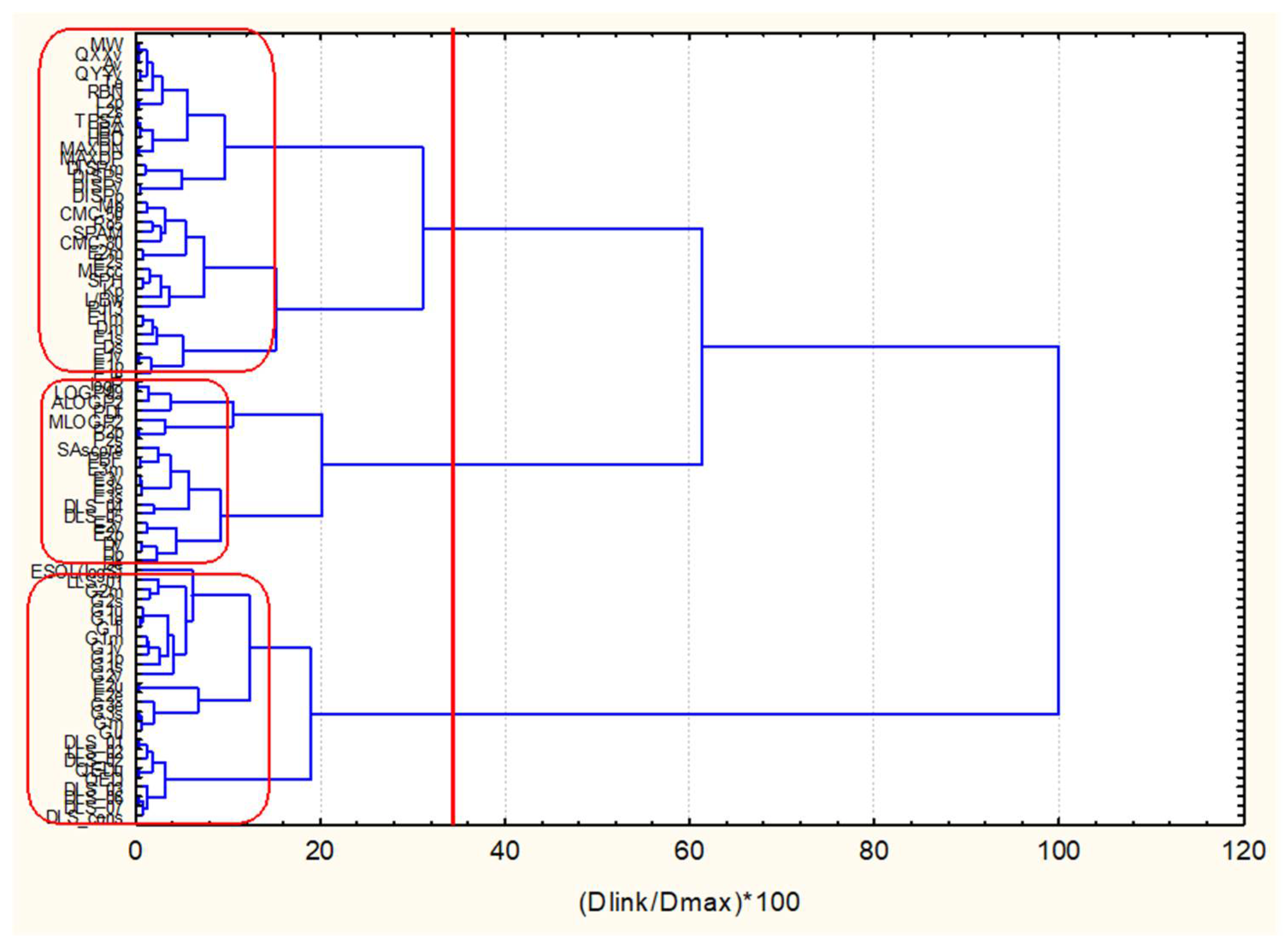
In
Figure 13, the hierarchical dendrogram for clustering of 83 descriptors is shown. Three clusters are identified at significance level 1/3Dmax, i.e., cluster with GLR, cluster with all four myricetins, cluster with AMN. Thus, complete separation is achieved. Considering features of five ligands identified above (see
Table 2) to be important for binding activity, the most important descriptors are: Mp, logP and SPAM descriptors (two drug-likeness and one topological descriptor). The results of the graphical representation of the clustering are shown in
SI—Hierarchical clustering of 40 ligands.
2.8. Hierarchical Clustering of Drug Candidates
The clustering by hierarchical mode and K-means (
Figure 14 and
Figure 15) gave the same results (the only difference is the numbering of the clusters if in the dendrogram one starts numbering from down to the top as C1, C2, C3, C4, the K-means clustering is C1, C2, C4, C3 with the same members.
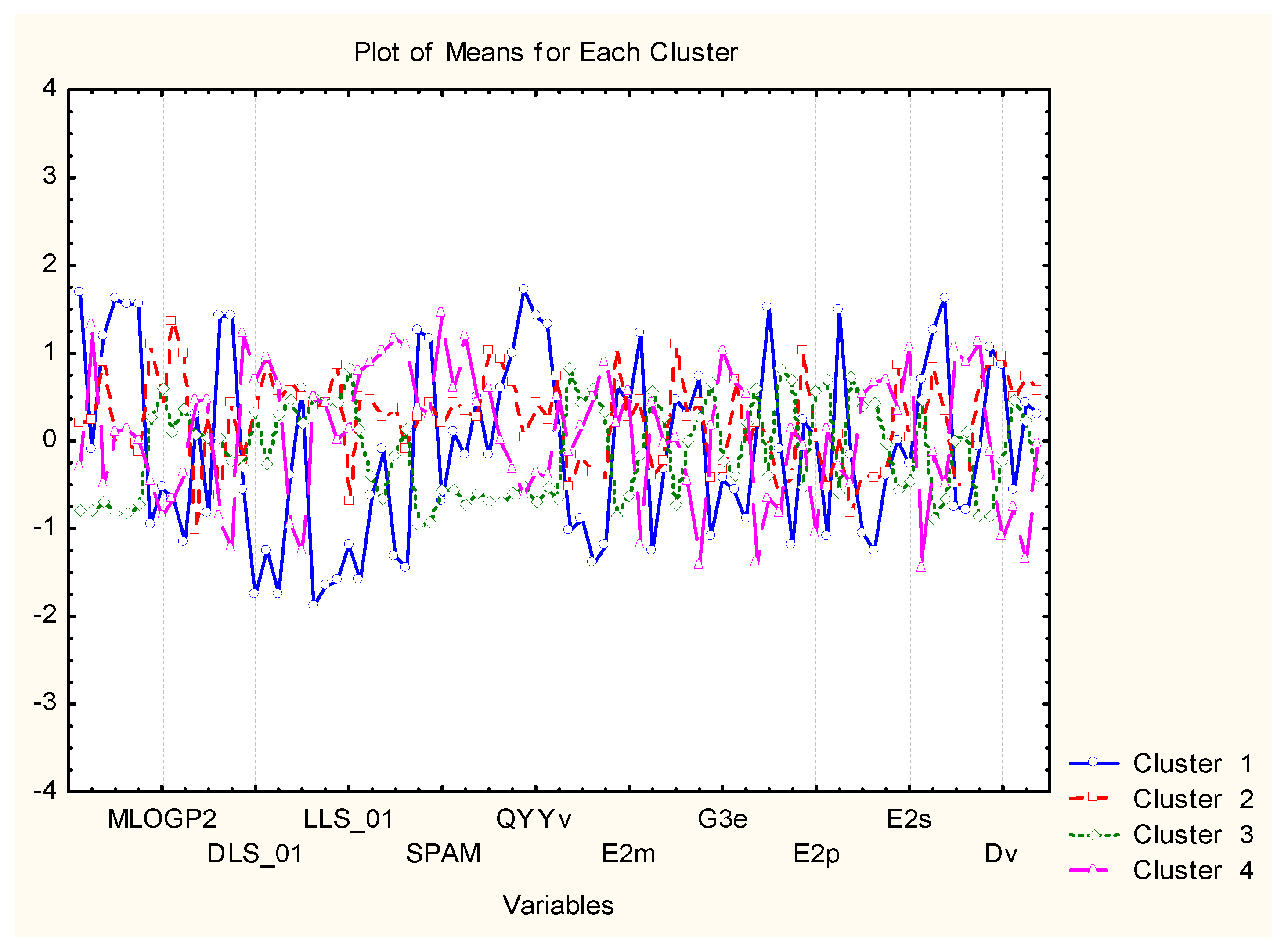
Cluster 1 (different from the other three similarity patterns) is characterized most typically by the highest values for MW, RBN, TPSA, HBA, HBD, QXXv, QYYv, L2p, P2s, and lowest values for DLS_01, DLS_02, DLS_03, DLS_06, DLS_07, DLS_conc, LLS_01, LLS_02, CMC_50, CMC_80.
C2 is marked mainly by the highest values of ALOGP2 and LOGP99 but, in general, is in the intermediate position. The same holds true for C3, and the most specific feature for it is the lowest levels of MW, Mp, RBN, TPSA, HBA, HBD, MEcc, SPH, PJI3, L/Bw, DISPm, DISPv.
C4 is, to some extent, opposite in relation to descriptor values to C1. For instance, it is characterized by the highest levels of LLS_02, CMC_50, CMC_80, QED, QEDu, OXXv, OYYv.
Therefore, it is possible to obtain initial information about the clustering of objects, descriptors, and the mutual relationships between them. This preliminary step in the classification helps in future better interpretation of the classes of objects and variables formed.
2.9. Comparisons of Both Classification Results
Although the classification by the traditional classification methods offers 12 classes and four clusters analyses, there is a good coincidence between both approaches. In the hierarchical cluster, C1 includes classes 1, 3, 6, 11, in C2–2, 9, in C3–4, 7, 10, 12, and C4–7, 8. The finer partitioning in
Table 3 is based on the mean docking score, but, in general, the partitioning is the same as the descriptors used in cluster analysis.
The comparison with the descriptor ranks (loadings) grouped in latent factors PC1 and PC2 shows that the grouping with respect to the rank is related to the partitioning of the descriptors into three clusters by cluster analysis: in PC1, there are members of the clusters 1 and 3 (cluster analysis), and in PC2, members of cluster 2 (except for the members of C1 MAXDN and MAXDP).
This relationship of both classification approaches allows using the patterns (class) formation results to solve other problems like docking operations. This classification technique could be used to identify another type of inhibitors. These classification techniques could accelerate the process of extensive screening making a preselection of suitable candidates.
2.10. Principle Component Analysis Self-Organizing Map Results
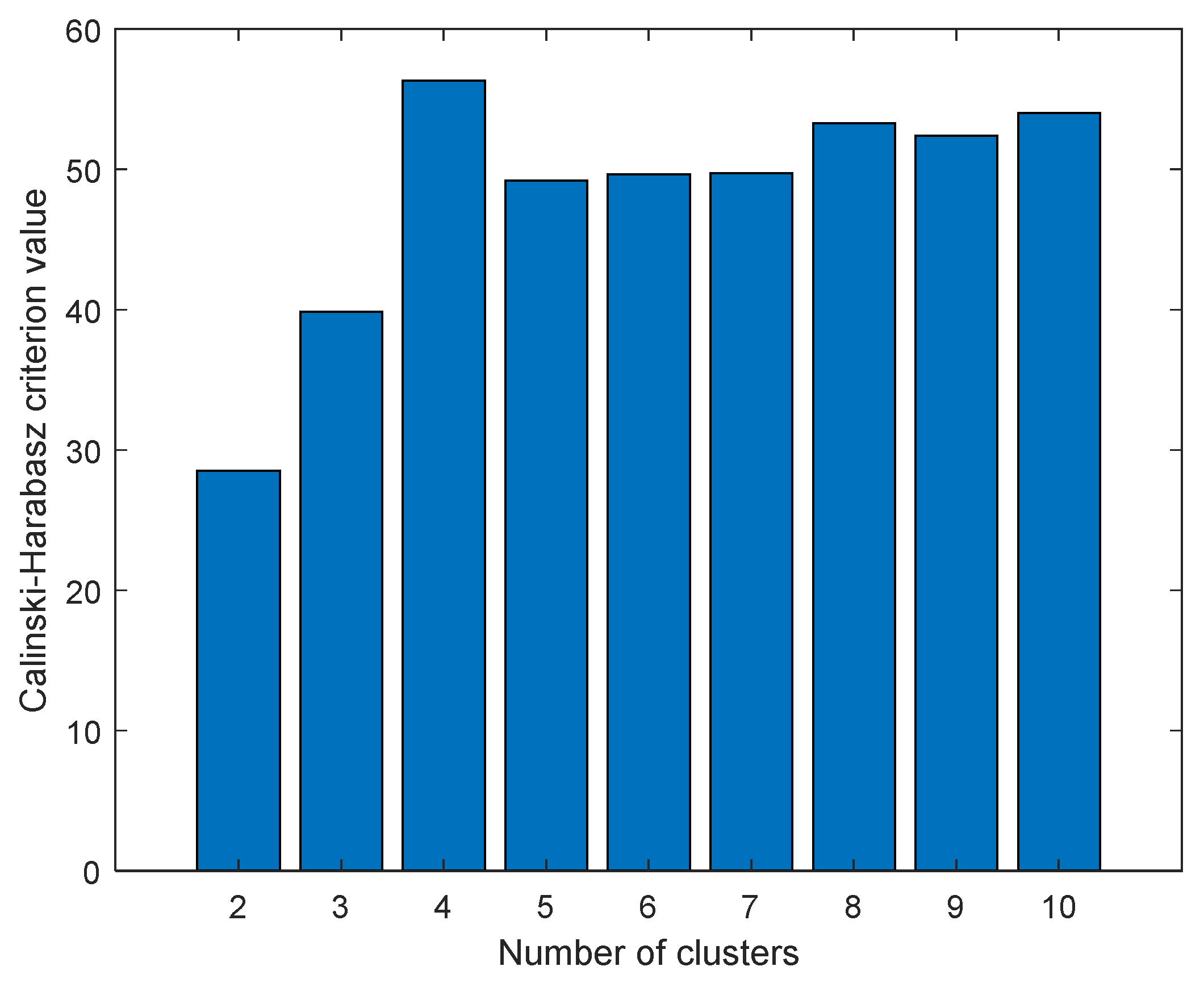
The data were first scaled to centered on origin and have unit variance for all variables to investigate any possible similarity between compounds and find distant patterns. Next, PCA was applied to reduce the dimensionality of data, and K-means clustering method was then applied on the abstracted sample space. The number of latent factors in PCA can control the amount of variation which PCA can model. We used the first three components of PCA which explain almost 65 percentage of variance in data. The best number of clusters for K-means was based on Calinski–Harabasz (CH) criteria, which is the ratio of the sum of between-clusters and inter-cluster scatter for all clusters. Higher values for this criterion mean the clusters are well separated and dense. Hence, the higher the score, the better the performance. The CH criterion values were checked at different clusters (K) and the best value was K = 4 (
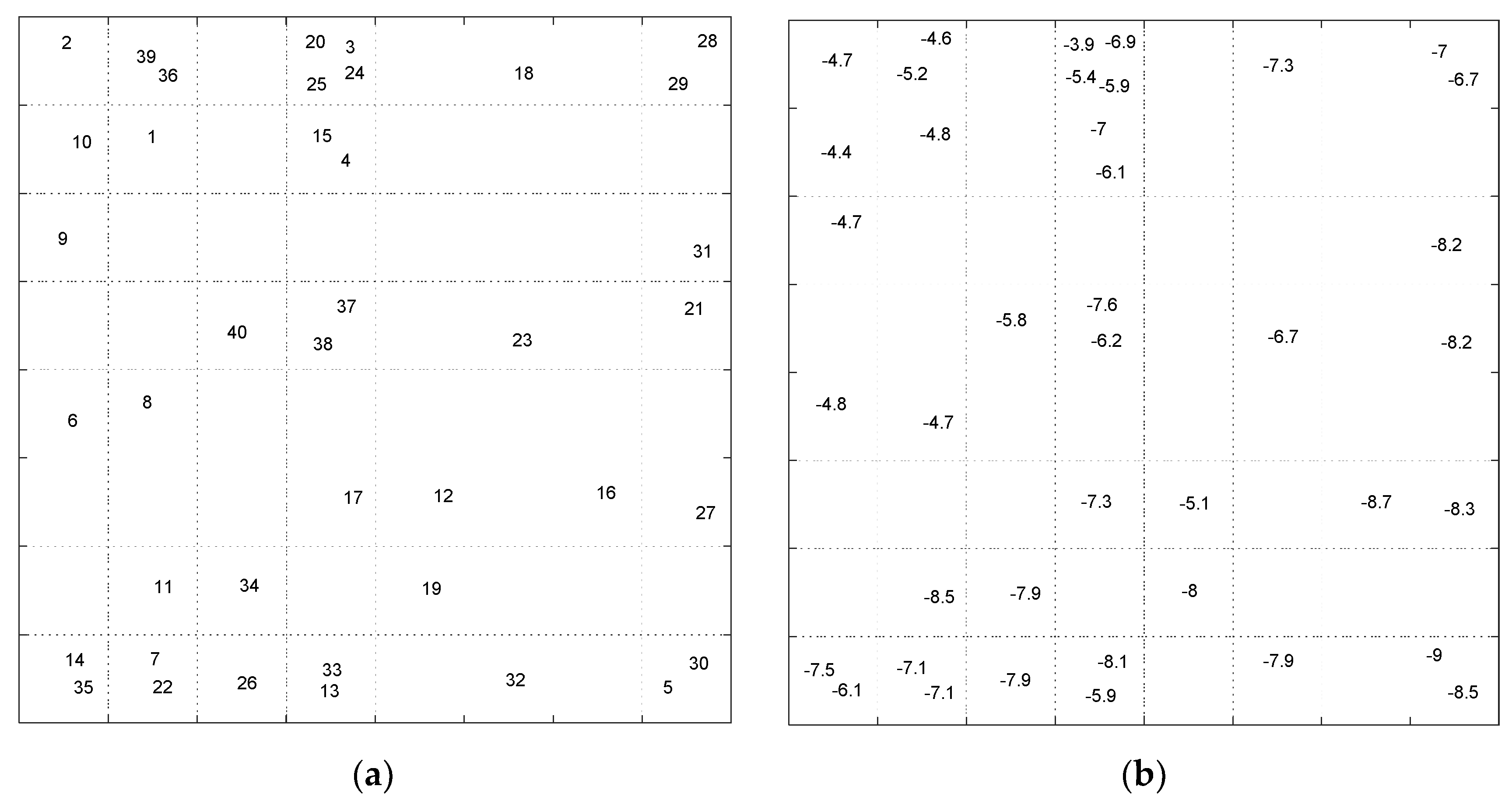
Figure 16). Each compound in the score plot was depicted as a circle labeled with corresponding docking score in three-dimensional space.
Figure 16 shows the PCA score plot for first three components. Different colors also specify the four clusters found by K-means clustering. To inspect the possible relation between compounds’ pattern and docking scores, each sample on the score plot is also labeled with a corresponding docking score value.
According to the clustering result and the pattern of compounds in the 3D score plot (
Figure 17), members of each cluster have nearly similar docking score values, and the groups are well separated. Furthermore, most of the compounds with different docking score (high/low) are discriminated along the first PC direction.
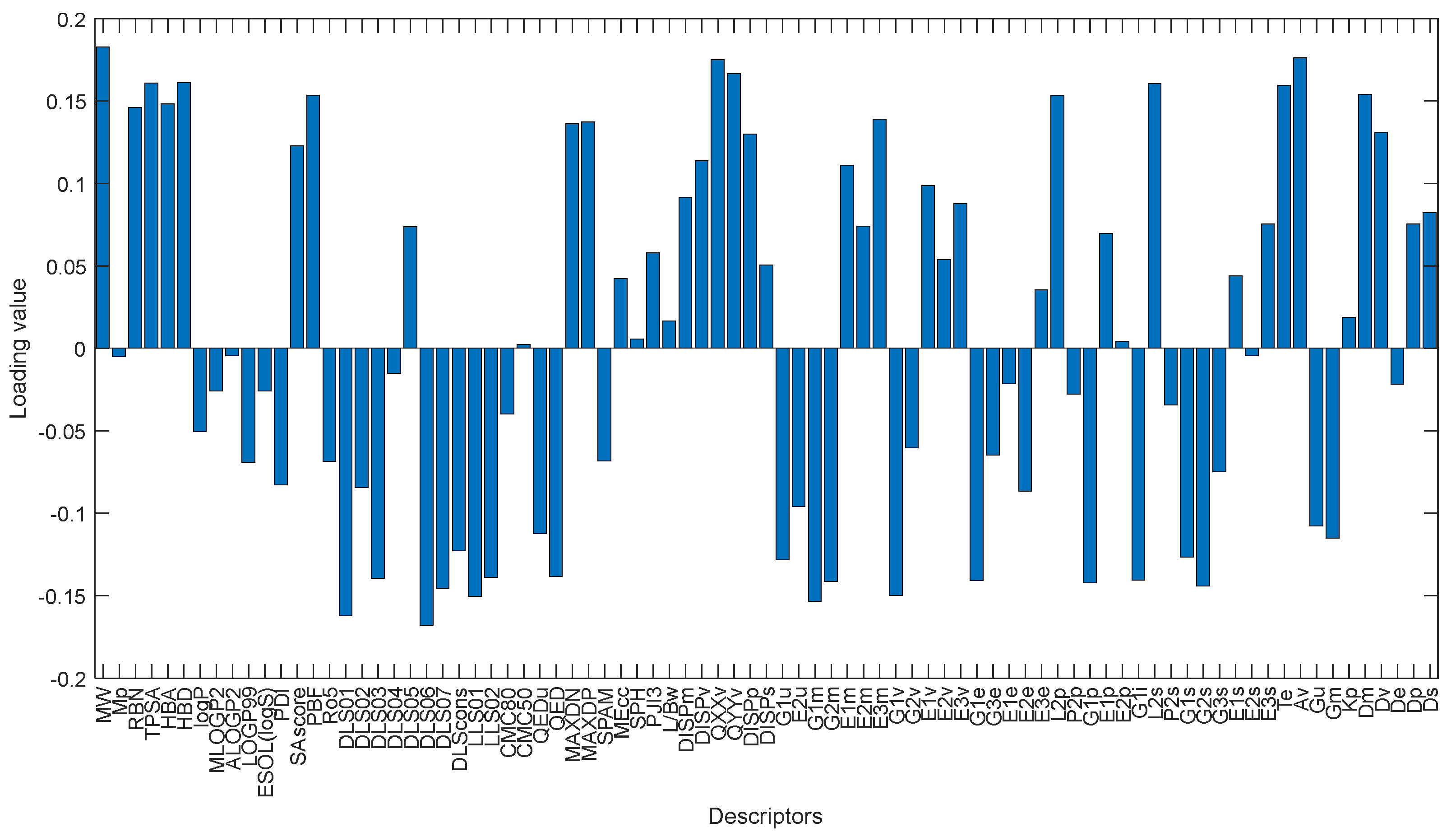
The first loading values defined by PCA can show the contribution of each variable to determine the first latent feature. As stated before, compounds with high and low docking score are well discriminated along first PC direction. Considering only the first loading, we can find the molecular descriptors that play an essential role in binding score of the compounds.
Figure 18 shows the loading values for first PC. The molecular weight (MW) descriptor, quadrupole x-component value (QXXv), A total size index (Av) and modified drug-like score from Rishton (DLS_06) and quadrupole y-component value (QYYv) are the top five descriptors that contribute to define the first PC and discriminate cluster 1 (dark blue) from the others. These descriptors have a reasonable correlation with the reported docking score values. The MW, QXXv, QYYv and Av mean values for the cluster 1 are more significant than other groups and are positively correlated with the docking score. The mean value of the DLS_06 descriptors is negatively correlated with the mean docking score values of the clusters.
2.11. Self-Organizing Map Results
Exploring the data topology in mapped feature space was also performed using Self-Organizing Map as a nonlinear dimensionality reduction method. The resulted maps from SOM can investigate the similarity between the compounds in feature space and any possible relation between the patterns and molecular descriptors. In this way, the scaled data matrix (40 × 83) was introduced to an 8 × 8 SOM row-wise. At the end of the training phase, molecules are mapped on the neurons such that similar molecules map on adjacent or the same neurons. The map was labeled using additional information such as row number or the docking. The resulted Top-Map of the trained 8 × 8 SOM labeled with sample number and binding score values are shown in
Figure 19.
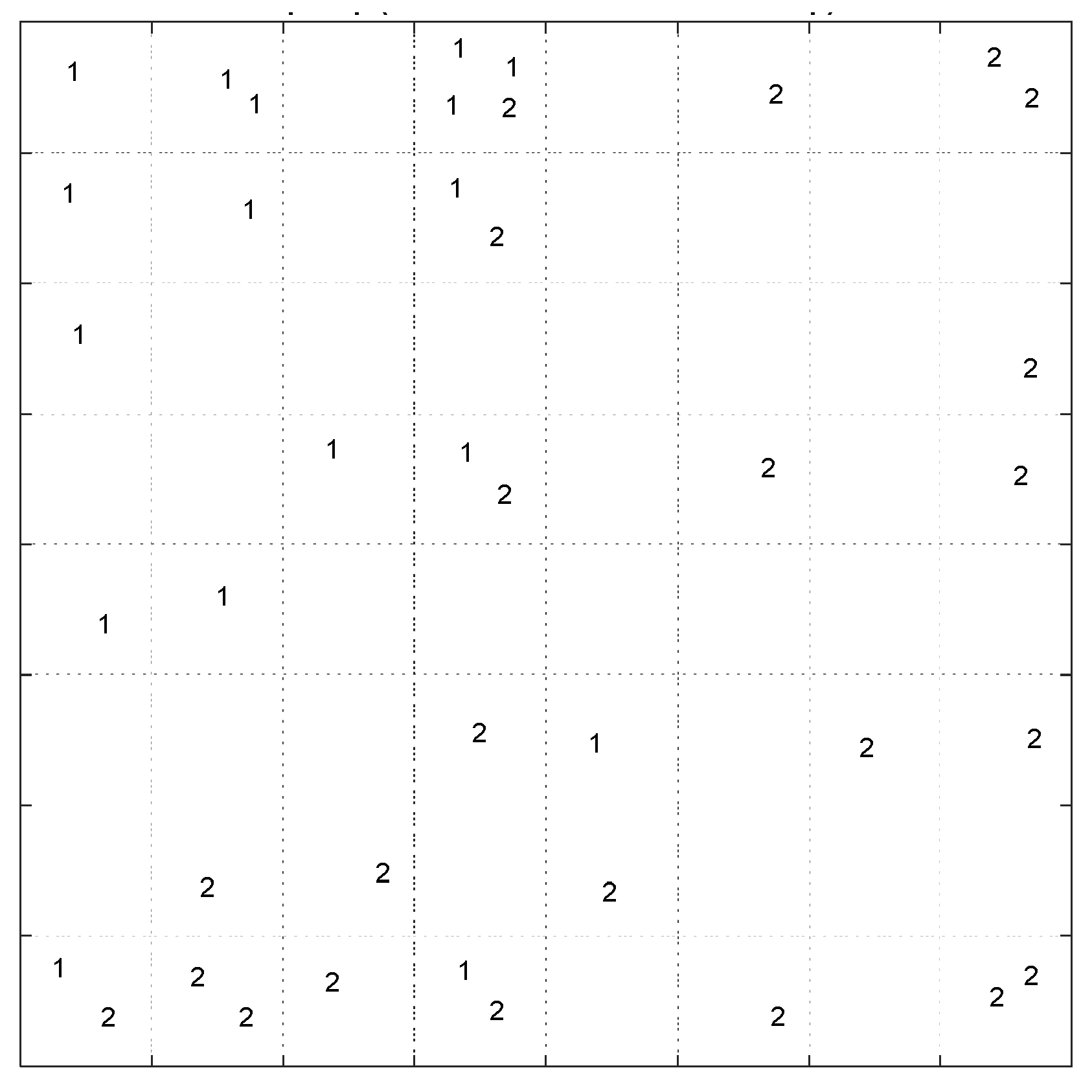
The pattern of samples on the Top-Map (
Figure 19a) shows similarities between compounds. Based on the molecular descriptors used to represent the compounds, highly similar molecules are mapped on the same or adjacent neurons. In addition, by considering the docking score of the molecules to label the sample (
Figure 19b), we can conclude that most of the compounds mapped on the same or adjacent neurons have almost similar binding affinity. More precisely, the compounds mapped on the top-left side have less binding affinity than other map parts. The SOM algorithm can distinguish the molecules with different binding affinities. Considering the range of binding scores for all of the molecules, we divided the molecules into two groups: low binding score (>−6.45) specified with label ‘1’, and high binding score (≤−6.45) which specified by label ‘2’ on the following Top-Map (
Figure 20).
Considering the low/high docking score as a class membership label makes it possible to use the supervised version of SOM, the counter-propagation artificial neural network (CPANN). CPANN can produce a Top-Map similar to a classical SOM and assign a class to each neuron that can be used to predict labels for unknown samples classification purposes. The size of the map was decided based on a Genetic Algorithm-based optimization method included in the Kohonen and Counter Propagation Toolbox for MATLAB. The best architecture and setting for the network is an 8 × 8 grid and 250 training epochs.
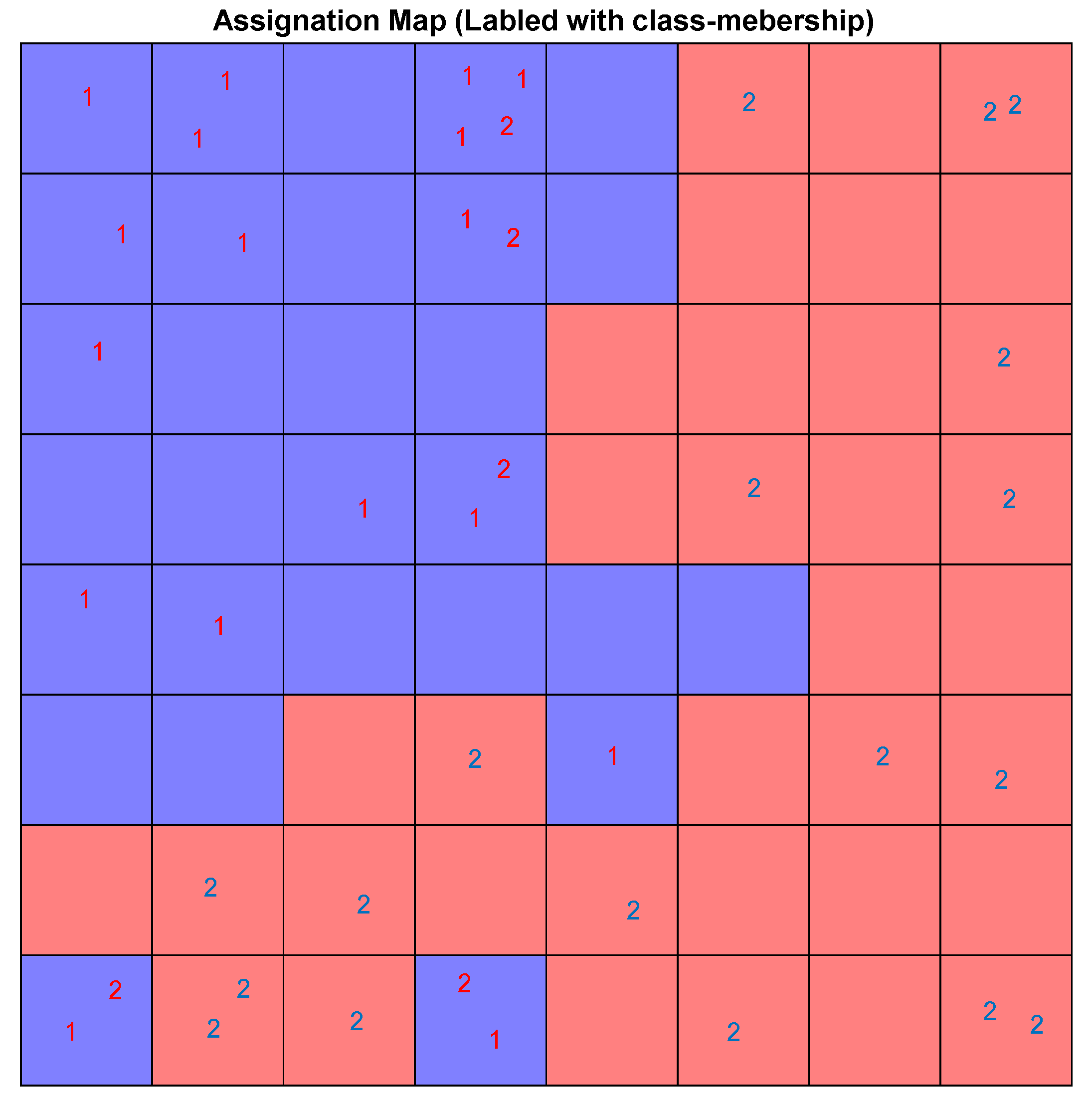
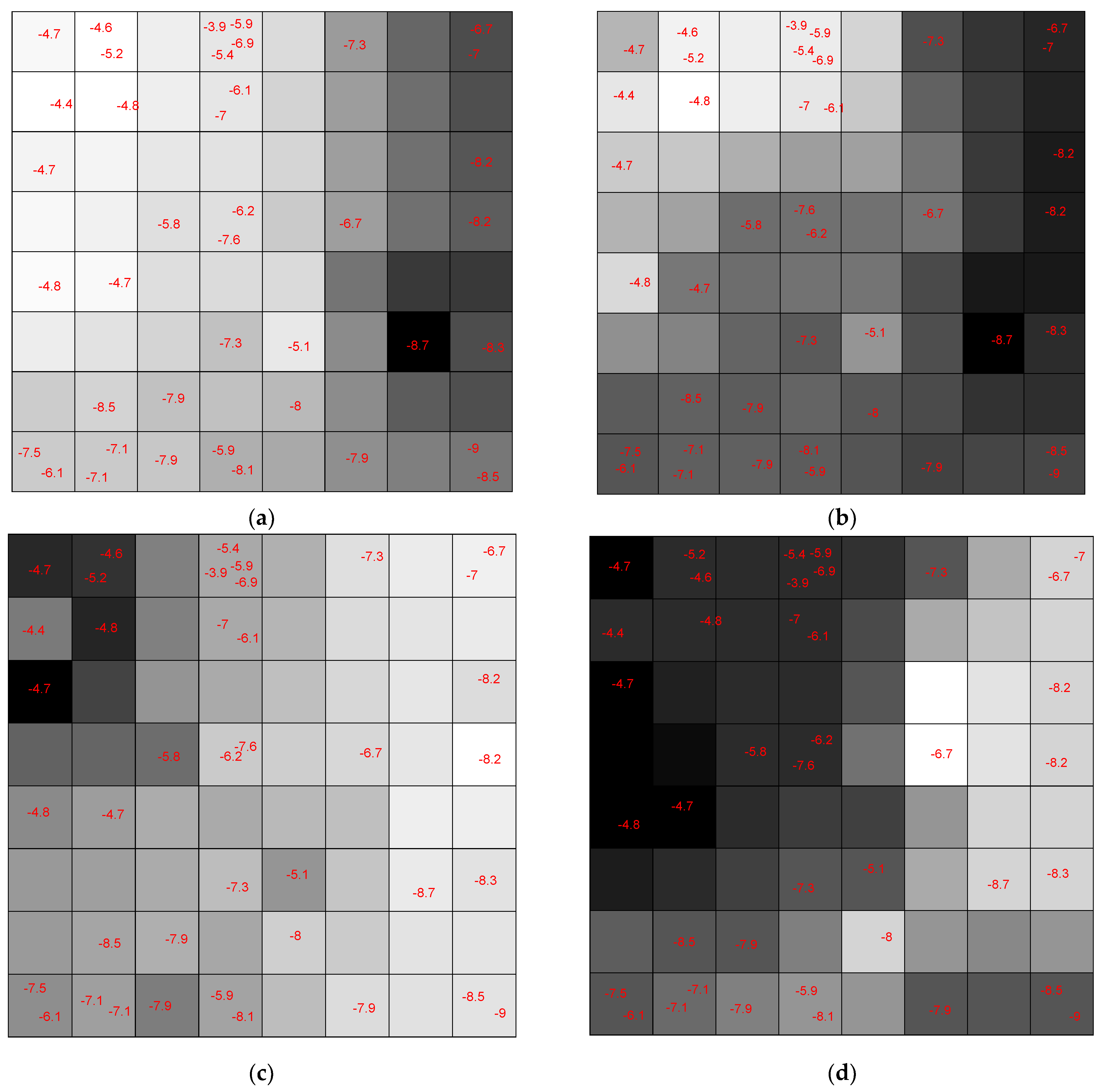
Figure 21 shows the assignation map obtained using an 8 × 8 CPANN trained with the data and class information.
Each neuron has an input weight vector that was updated during the training phase of the CPANN. Considering only the
ith weight vector elements of all neurons,
ith weight map can be obtained by shading the neurons. Comparing these weight maps to the pattern of the assignation map, we investigated the correlation of each variable with the assignation map. We found the most influential variables in the mapping process. The weight maps of several descriptors are shown in
Figure 22. The darker shade means a higher value for the corresponding weight element and vice versa.
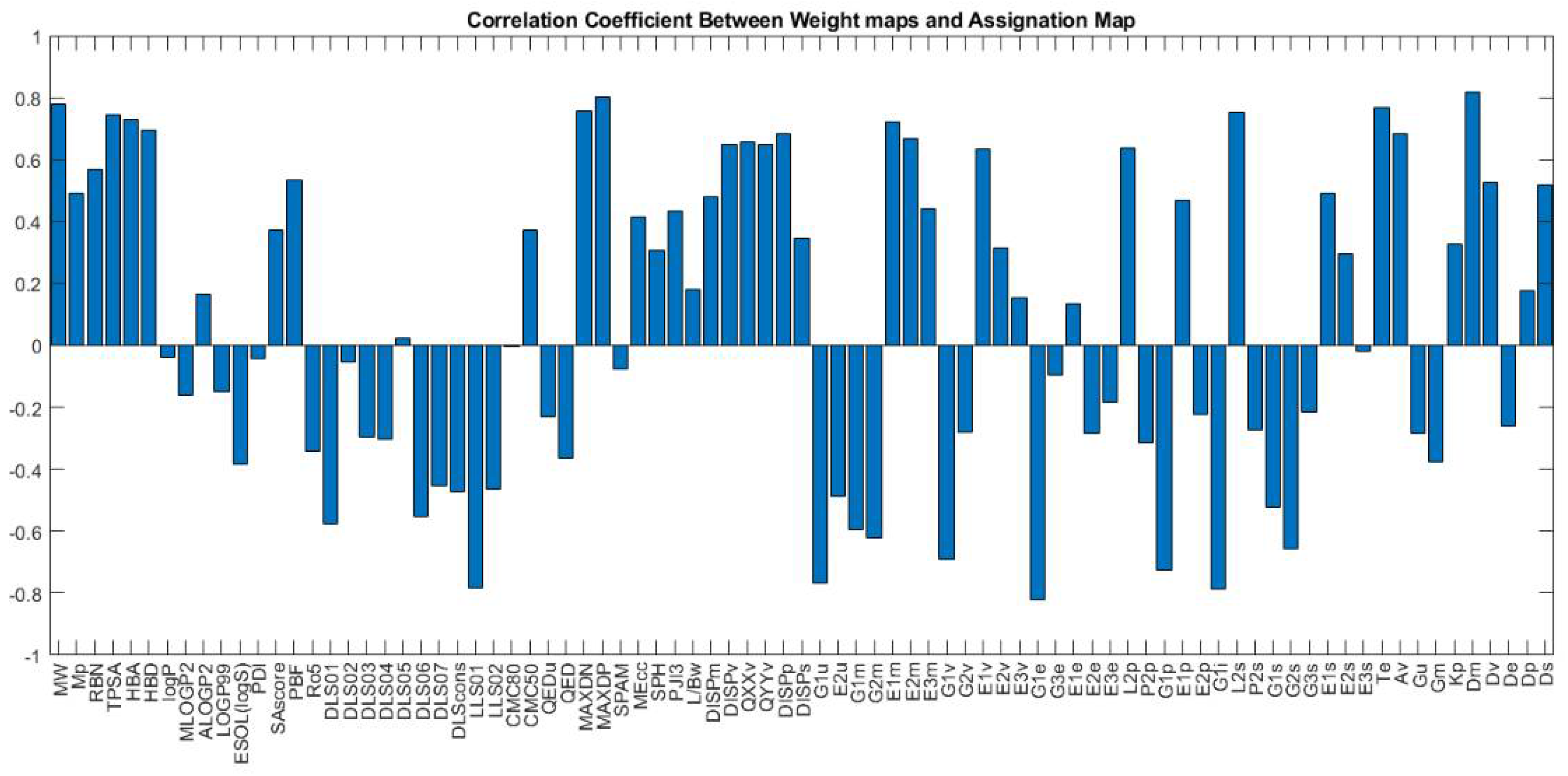
Figure 23 shows the weight maps of some important variables. It is apparent that the pattern of the weight map for the MW descriptor is positively correlated with the pattern of classes in the assignation map, and we can conclude that the molecular weight is an important descriptor related to the docking score and the molecules with higher molecular weight have a higher binding score. The maximal electro-topological positive variation (MAXDP) descriptor is also another variable that is highly correlated with the pattern of the docking score in the assignation map. In order to have better insight into the importance of variables, the Pearson correlation coefficient between the weight map of each variable and the assignation map is calculated and summarized in
Figure 23.
As shown in the figure, MW, TPSA, HBA, HBD, MAXDN, MAXDP, and DM are the most important descriptors, with a positive correlation with binding scores. Among the descriptors with the negative correlation, the most correlated ones are G1e, LLS01, G1u, G1i, and G1p. The weight maps of G1e and LLS01 are also shown.
4. Conclusions
A combination of molecular docking, MD simulations and ML techniques have been applied to identify natural compounds and their features that could substantially bind to the spike protein of SARS-CoV-2 and disrupt its interaction with ACE2 receptor. Binding affinity and dynamic behavior of 40 phytochemicals were examined against the X-ray crystal structure of the SARS-CoV-2 S1-RBD (PDB ID: 6M0J). We identified four potential binding sites in the protein structure. Molecular docking of the ligands to these sites show high binding affinity for amentoflavone, glycyrrhizin, chrysin, myricetin_3’-Rhamnoside and myricetin_3-(4″-Galloylrhamnoside). Molecular dynamic simulation of selected protein–ligand complexes shows a long retention time of Amentoflavone in pocket 1 of the spike protein, and the interaction is mainly driven by H bond interactions. Ligand Glyrimizine mainly binds at pocket 3 and MYG binds at pocket 1A. Based on binding affinity results and retention time, we conclude that Amentoflavone and Glyrimizine can potentially disrupt the interaction between ACE2 receptors and the spike protein of SARS-CoV-2.
The features of best binding drugs were further identified based on classification schemes. Based on Self-Organizing Map analysis, the primary descriptors are MW, TPSA, HBA, HBD, MAXDN, MAXDP, and DM as essential descriptors for better binding with spike protein. The machine-learning model, docking and molecular dynamics studies can predict the new inhibitors based on a set of obtained molecular descriptors. The current workflow can be used for the identifying descriptors, followed by identification of features that are important for drug development against the spike protein of SARS-CoV-2.


 ,
, 
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}