1. Introduction
With the rapid development of modern industry and science and technology, highly precise and integrated industrial equipment has been widely adopted across various fields. This trend has led to an increased risk of mechanical failures, particularly in rotating components such as bearings [
1,
2]. However, detecting abnormal noises or subtle faults in bearings can be challenging, making it difficult to mitigate potential risks [
3,
4]. Minor issues may lead to equipment malfunction or downtime, resulting in economic losses, while more serious failures can pose catastrophic safety hazards [
5].
With the rise of deep learning and revolutionary breakthroughs in computer hardware, deep learning-based fault diagnosis algorithms have gained popularity, fueled by the availability of massive datasets [
6]. Convolutional neural networks (CNNs) are the most commonly used network in deep learning, achieving excellent results in feature recognition [
7]. The local receptive field and weight sharing improve the training speed of CNNs. Deep convolutional networks exhibit outstanding classification performance and have been widely applied in rolling bearing fault diagnosis. Wang et al. [
8] proposed an intelligent fault diagnosis method for bearings based on the combination of symmetrical dot pattern representation and a squeeze-excitation convolutional neural network model. Li et al. [
9] introduced a novel bearing fault diagnosis model based on ensemble deep neural networks and CNN, where each local network is trained with different datasets to extract diverse features, thereby integrating features with different resolutions for fault identification. Shenfield et al. [
10] introduced a new dual-path recurrent neural network (RNN-WDCNN) with a wide one-step kernel and deep CNN path, capable of operating on raw time signals (e.g., vibration data) to diagnose bearing fault data collected from electromechanical drive systems.
However, applying deep learning strategies to rolling bearing fault diagnosis often encounters challenges such as imbalanced data distribution leading to poor generalization of deep diagnostic networks, high memory consumption, and large computational resource utilization by deep models [
11,
12,
13,
14]. The emergence of transfer learning provides a fresh and effective approach to address such practical issues, leveraging previously acquired knowledge to assist in learning new knowledge [
15]. Shen et al. [
16] adjusted the weights between selectively assisted data in the TrAdaBoost algorithm to enhance diagnostic capability, while avoiding negative transfer by judging similarity, thus improving the algorithm accuracy and reducing the computational burden. Liao [
17] proposed a transfer network based on dynamic distribution adaptation for cross-domain bearing fault diagnosis. Zhang et al. [
18] first extracted features from source and target domain data using CNN, then minimized the probability distribution distance of multi-kernel maximum mean difference and maximized the domain recognition error of the domain classifier to reduce domain distribution differences. Zhou et al. [
19] introduced a domain adaptation method, utilizing mixed distance measures to minimize distribution differences between source and target domains, applied to bearing fault diagnosis under different operating conditions. Zhao et al. [
20] designed a deep transfer diagnostic method, achieving comprehensive optimization of sample probability distribution distance, model classification error, and domain classification error. Tong et al. [
21] proposed a feature transfer learning-based domain adaptation method to address the performance degradation of fault diagnosis models in varying operating condition environments. These transfer methods have demonstrated excellent diagnostic performance under cross-condition scenarios but are challenging to apply to fault diagnosis problems under cross-device scenarios [
22,
23]. Cross-device scenarios not only involve different operating scenes and environmental changes but also encompass devices of different types with distinct materials, sizes, configurations, or installation methods [
24]. These varying factors inevitably lead to more significant distribution differences between the source and target domain data, necessitating research into fault diagnosis methods with better generalization capabilities [
25,
26].
Knowledge distillation, proposed and popularized by Geoffrey Hinton et al. in 2015 [
27], is a technique that can be viewed as a special case of transfer learning. It transfers knowledge from a complete large network (teacher model) to a smaller network (student model) in the form of soft labels, thereby enhancing the accuracy of the network [
28,
29]. Therefore, this paper proposes a domain-adaptive residual network model based on the knowledge distillation framework. To prevent gradient vanishing as CNNs deepen, a variable-scale residual network is employed to extract domain-invariant fault features from both the source and target domain data. Based on the variable-scale residual network, a knowledge distillation framework is constructed, enabling the student model in the framework to reference soft label information from the teacher model while reducing the model’s size for ease of deployment in industrial scenarios. Domain adaptation is achieved by measuring the difference between the source and target domain data in the feature space using maximum mean discrepancy (MMD), enabling cross-device invariant feature learning.
The main contents of each section of this paper are described as follows:
Section 2 introduces the theoretical foundation of the paper,
Section 3 details the designed lightweight distillation transfer learning diagnostic model,
Section 4 conducts engineering case verification and analysis, and
Section 5 provides the conclusions of the paper.
3. Lightweight Distillation Transfer Learning Diagnostic Model
This paper fully considers the advantages and limitations of deep and shallow deep learning networks. Based on the techniques of knowledge distillation lightweight models and feature-level domain adaptation transfer, it investigates model compression while ensuring the performance of deep learning models. Addressing the task of fault diagnosis across devices with incomplete inter-class data, this paper proposes a knowledge distillation-based residual network with domain adaptation (KD-ResNet-DA). This method utilizes a variable-scale ResNet model to extract domain-invariant features from the source domain data. Employing the framework of knowledge distillation, it transfers the fault features extracted by the deep teacher model from the source domain to the smaller-volume student model, achieving the extraction of fault features in the target domain. Furthermore, it minimizes the probability distribution distance of fault features between the source and target domains, facilitating domain-invariant feature learning across devices. The structure of the KD-ResNet-DA network model is illustrated in
Figure 3, comprising primarily the knowledge distillation framework and feature-level domain adaptation transfer. The knowledge distillation framework enables the student model to reference the internally invariant features learned by the teacher model during training. Meanwhile, domain adaptation transfer learns mutually invariant features of probability distribution between the source and target domain data from the feature level. The overall objective function of the model consists of three parts: the distillation error
from the knowledge distillation framework, the classification error
of the student model, and the probability distribution distance loss
at the feature level. The specific methods for obtaining each loss will be discussed in the following two sections.
3.1. Acquisition of Knowledge Distillation Framework Error
The knowledge distillation framework considering soft labels mainly consists of a deep variable-scale ResNet teacher model and a shallow ResNet student model. This framework relies on the teacher model to extract domain-invariant features relevant to fault classification tasks from the source domain data and transfer the learned fault classification information to the smaller-volume student model at the classification layer. The specific steps are as follows:
- (1)
Input source domain data into the deep variable-scale ResNet teacher model: The source domain dataset is input into the deep variable-scale ResNet teacher model. Initially, convolutional layers with larger kernel sizes capture coarse-grained features in a wide frequency band of the frequency domain signals. Then, the variable-scale ResNet progressively converts coarse-grained features into fine-grained fault features, with each residual unit adding a convolutional layer with a kernel size of 1 to reduce the depth of intermediate feature matrices and decrease model parameters. This process yields domain-invariant features for the source domain data.
- (2)
Pretrain the teacher model and infer with Softmax classifier: The teacher model is pretrained via backpropagation, and the pretrained variable-scale ResNet teacher model performs inference. By introducing the temperature factor T in the Softmax classifier as in Equation (5), the probabilities of each sample belonging to each fault class in the classification layer are obtained, i.e., soft labels .
- (3)
Input target domain data into the shallow student model: The target domain dataset is input into the shallow student model with fewer parameters, and the features of the target domain data are obtained.
- (4)
Calculate distillation error between student model’s soft predictions and soft labels: The distillation error between the soft predictions of the student model and the soft labels is computed using Equation (6).
- (5)
Calculate classification error between student model’s hard predictions and true sample labels: The classification error between the hard predictions of the student model and the true sample labels is calculated using Equation (7).
- (6)
Utilize overall knowledge distillation framework loss as training objective for student model: The overall loss, composed of distillation error and classification error , serves as the training objective for the student model, enabling it to gradually approach the outstanding fault classification performance of the teacher model.
3.2. Domain Adaptation Loss Acquisition Based on MMD
In the aforementioned knowledge distillation framework, domain-invariant features of the source domain data and features of the target domain data are extracted at the feature level. The probability distribution distance between the two is then computed in the RKHS using Equation (11). This distance is learned as more diverse domain-invariant features are encouraged through regularization. In Equation (11), the value in the Gaussian kernel function represents the width of the kernel function, controlling the range of influence of and on the kernel function, i.e., the smoothness of the Gaussian kernel function. Considering the potential variation in feature distributions across different cross-device fault diagnosis tasks, this study selects multiple values of to enhance the flexibility of domain adaptation. By selecting multiple different values of , the model can adapt to the diverse data features present in different cross-device scenarios, thus making it more suitable for a variety of fault classification tasks.
3.3. Training Procedure of KD-ResNet-DA
The proposed method represents a novel integration of the knowledge distillation framework with domain adaptation at the feature level, offering a comprehensive approach to address the challenges posed by cross-domain data incompleteness. By leveraging the strengths of both techniques, the proposed approach facilitates the seamless transfer of domain-invariant features gleaned from the teacher model trained on the source domain data to the student model. This transfer ensures that the student model can effectively capture and utilize essential information without being hindered by domain discrepancies. Moreover, our method goes beyond traditional knowledge distillation by incorporating domain adaptation mechanisms to bridge the gap between the source and target domains. Specifically, it exploits multi-kernel MMD to discern domain-invariant features between the source and target domain data. This process enhances the adaptability of the model to diverse data distributions encountered in real-world scenarios, thereby improving its robustness and generalization capability. The ultimate objective function of the proposed KD-ResNet-DA method encapsulates the essence of these strategies, aiming to minimize the distillation error, classification error, and probability distribution distance simultaneously. The distillation error quantifies the discrepancy between the soft predictions of the student model and the soft labels provided by the teacher model, facilitating the transfer of knowledge effectively. The classification error measures the disparity between the hard predictions of the student model and the ground truth labels, ensuring accurate diagnostic outcomes. Additionally, the probability distribution distance captures the dissimilarity between the probability distributions of the source and target domain data, guiding the model towards learning domain-invariant representations.
In essence, the proposed KD-ResNet-DA method offers a synergistic fusion of knowledge distillation and domain adaptation techniques, underpinned by a comprehensive objective function that optimizes model performance across domains. This holistic approach not only enhances the diagnostic accuracy and efficiency but also lays the groundwork for advancing intelligent fault diagnosis in diverse industrial settings. The ultimate objective function
of the proposed KD-ResNet-DA method consists of distillation error
, classification error
, and probability distribution distance
, which can be defined as follows:
where
represents the relative weight balancing between the distillation error of the teacher model and the classification error of the student model.
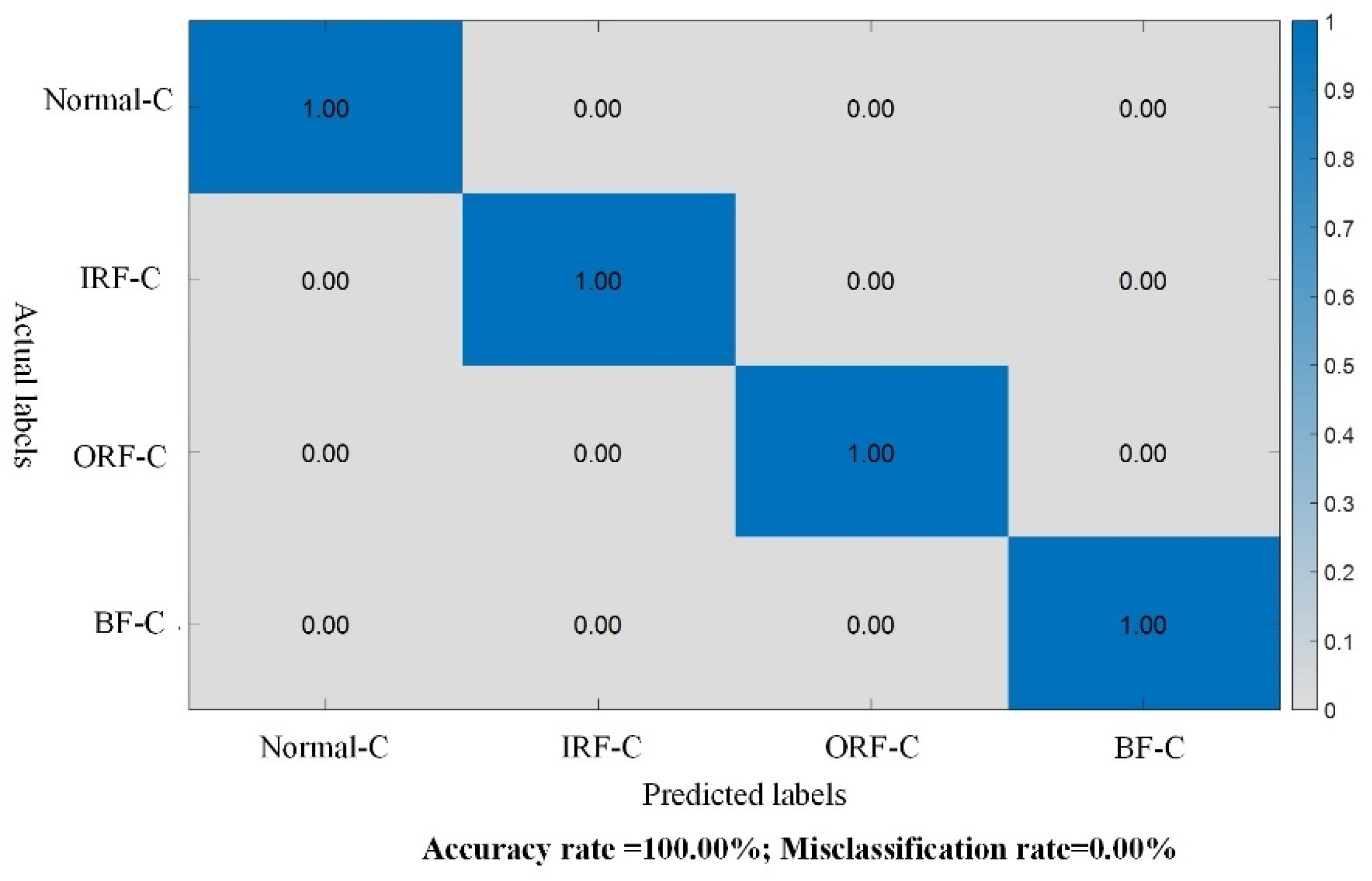
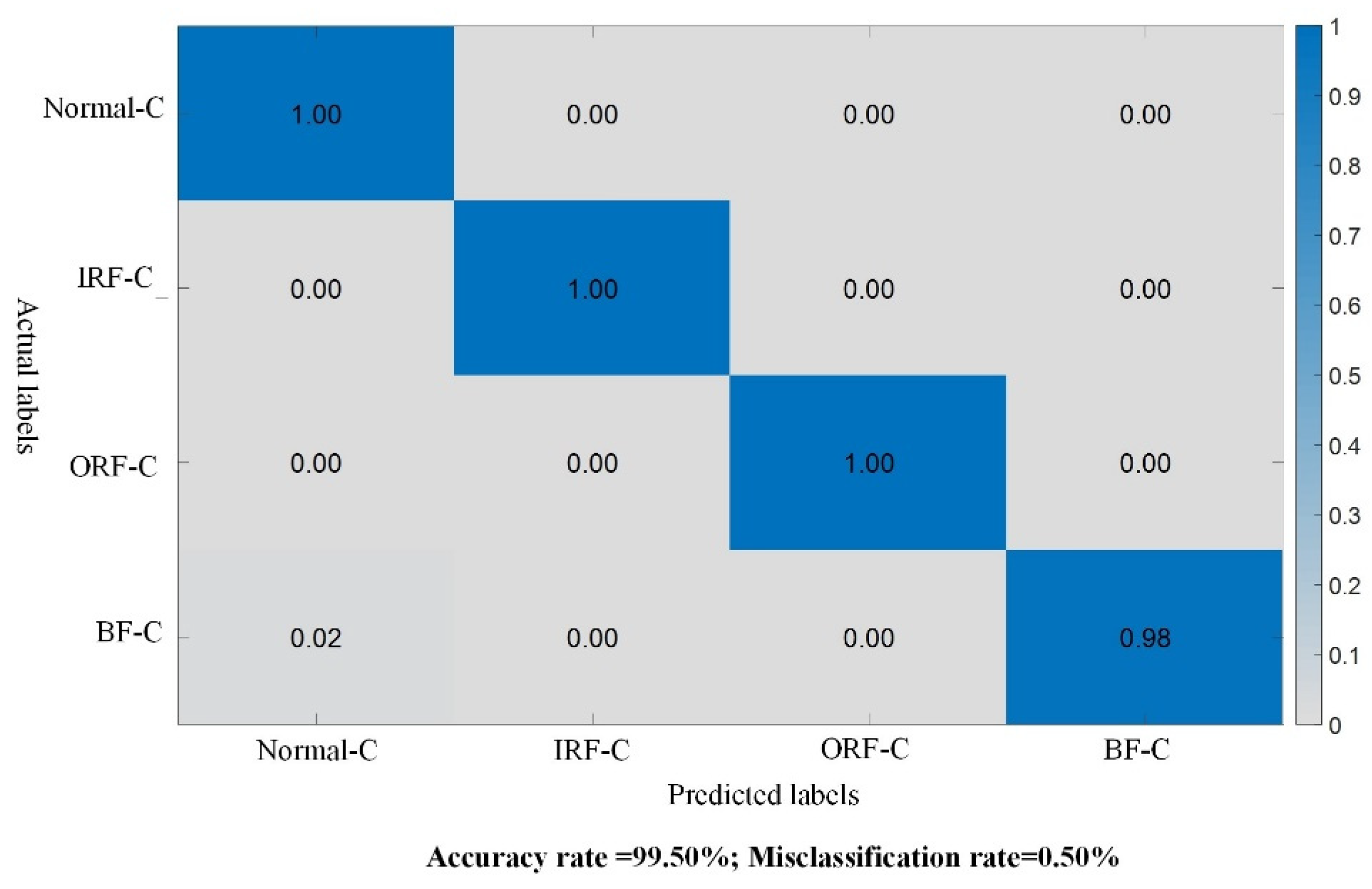
5. Conclusions
The intelligent fault diagnosis method proposed in this study, based on knowledge distillation and domain adaptation residual networks, demonstrates a scientific rationale and practical utility. By addressing the issue of incomplete inter-class data in cross-device scenarios, it overcomes the contradiction between diagnostic accuracy and computational resources during model deployment. Training the teacher model using frequency domain data and introducing soft labels with a temperature factor enables the extraction of domain-invariant features from the source domain data, providing valuable information for the model. Subsequently, by computing the distillation error and classification error, along with measuring the probability distribution distance loss using a multi-kernel Gaussian kernel function, high-performance fault diagnosis can be achieved while maintaining a smaller model size.
Although this study operates under the premise of identical sample labels between the source and target domains, this assumption does not hinder the effectiveness of the proposed method in practical applications. In future research, the team will further focus on addressing open-set fault diagnosis issues to enhance the applicability and generality of the method, thereby contributing significant scientific value to the advancement of intelligent fault diagnosis across devices.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}