

A Generative Approach to Person Reidentification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
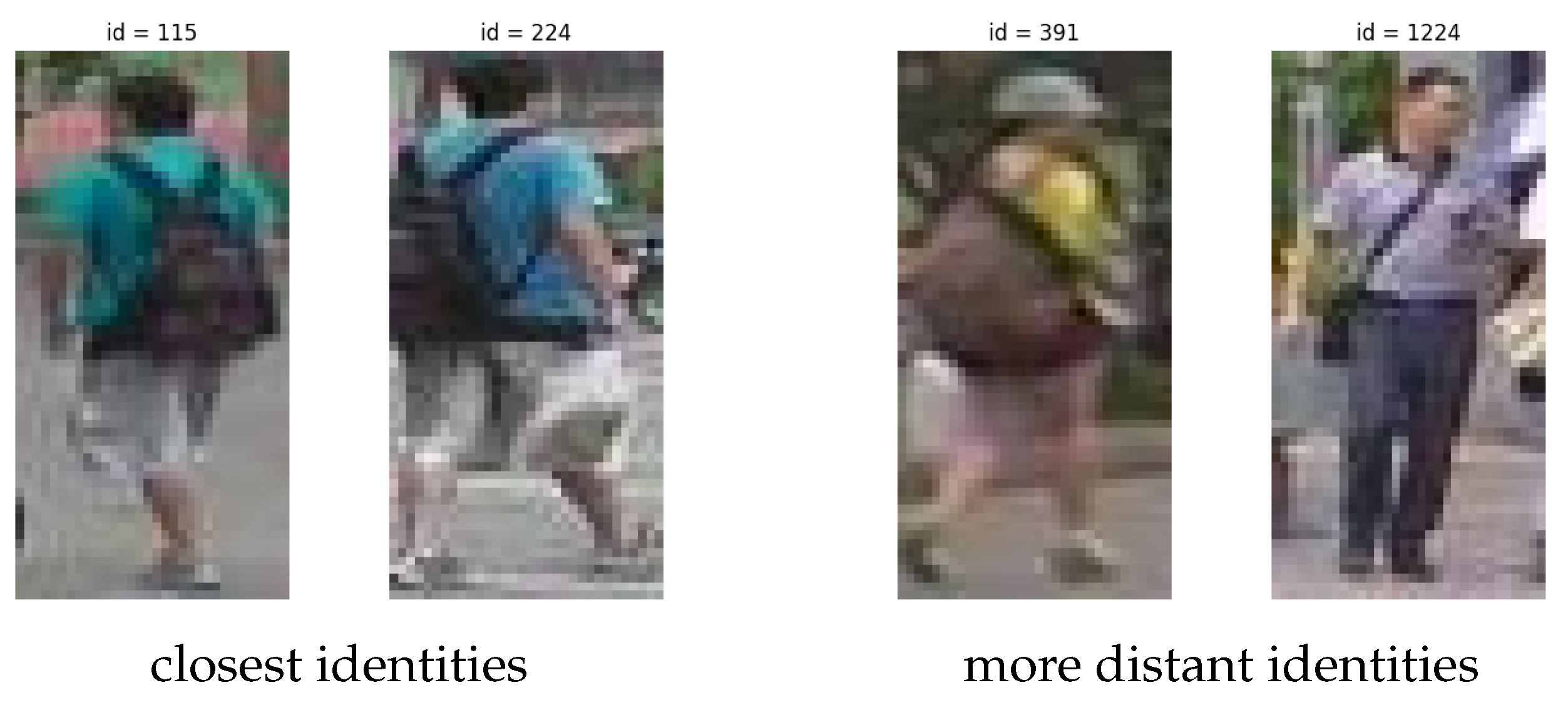{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Achievements
- Is it possible to characterize a person’s identity (from the person re-ID perspective) as the conditional information required to generate a diversified set of images relative to the given person?
- In that case, is it possible to compute a right inverse to the generator, extracting from an image of a person their conditioning identity?
1.2. Structure of the Work
2. Related Work
3. Denoising Diffusion Models
3.1. The Denoising Network
- pick a random image from the train set, coherent with the condition c;
- select a random step t of the process; to each step t is associated a signal rate defined by a suitable noise scheduling (more in the sampling section);
- sample a random Gaussian noise ;
- create a corrupted image as a weighted combination of and :
- train the network to properly guess the amount of noise present in , by minimizing the distance between and .
| Algorithm 1 Training |
| 1: repeat |
| 2: ▹ take a sample coherent with c |
| 3: Uniform(1,…,T) ▹ choose a timestep |
| 4: ▹ create random Gaussian noise |
| 5: ▹ corrupt the sample with signal rate |
| 6: Take a gradient descent step on ▹ backpropagate the loss |
| 7: until converged |
3.2. Sampling
| Algorithm 2 Sampling |
| 1: |
| 2: for do |
| 3: ▹ predict noise |
| 4: ▹ compute denoised result |
| 5: ▹ re-inject noise at rate |
| 6: end for |
4. Methodology
5. Neural Network Architectures
6. Evaluation
7. Latent Space Exploration
8. Ablation and Alternatives
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bukhari, M.; Yasmin, S.; Naz, S.; Maqsood, M.; Rew, J.; Rho, S. Language and vision based person re-identification for surveillance systems using deep learning with LIP layers. Image Vis. Comput. 2023, 132, 104658. [Google Scholar] [CrossRef]
- Kim, K.; Kim, M.J.; Kim, H.; Park, S.; Paik, J. Person Re-identification Method Using Text Description Through CLIP. In Proceedings of the 2023 International Conference on Electronics, Information, and Communication (ICEIC), Singapore, 5–8 February 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Ming, Z.; Zhu, M.; Wang, X.; Zhu, J.; Cheng, J.; Gao, C.; Yang, Y.; Wei, X. Deep learning-based person re-identification methods: A survey and outlook of recent works. Image Vis. Comput. 2022, 119, 104394. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Y.; Tang, Y.Y. Person Re-identification by Exploiting Spatio-Temporal Cues and Multi-view Metric Learning. IEEE Signal Process. Lett. 2016, 23, 998–1002. [Google Scholar] [CrossRef]
- Chung, D.; Tahboub, K.; Delp, E.J. A Two Stream Siamese Convolutional Neural Network for Person Re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1992–2000. [Google Scholar] [CrossRef]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification 2018. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar] [CrossRef]
- Liu, X.; Tan, H.; Tong, X.; Cao, J.; Zhou, J. Feature preserving GAN and multi-scale feature enhancement for domain adaption person Re-identification. Neurocomputing 2019, 364, 108–118. [Google Scholar] [CrossRef]
- Li, Y.; Chen, S.; Qi, G.; Zhu, Z.; Haner, M.; Cai, R. A GAN-Based Self-Training Framework for Unsupervised Domain Adaptive Person Re-Identification. J. Imaging 2021, 7, 62. [Google Scholar] [CrossRef] [PubMed]
- Tang, G.; Gao, X.; Chen, Z.; Zhong, H. Unsupervised adversarial domain adaptation with similarity diffusion for person re-identification. Neurocomputing 2021, 442, 337–347. [Google Scholar] [CrossRef]
- Li, Y.; He, J.; Zhang, T.; Liu, X.; Zhang, Y.; Wu, F. Diverse part discovery: Occluded person re-identification with part-aware transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2898–2907. [Google Scholar]
- Cao, G.; Jo, K.H. Unsupervised Person Re-Identification with Transformer-based Network for Intelligent Surveillance Systems. In Proceedings of the 2021 IEEE 30th International Symposium on Industrial Electronics (ISIE), Kyoto, Japan, 20–23 June 2021; pp. 1–6. [Google Scholar]
- Chen, Y.; Xia, S.; Zhao, J.; Zhou, Y.; Niu, Q.; Yao, R.; Zhu, D.; Liu, D. ResT-ReID: Transformer block-based residual learning for person re-identification. Pattern Recognit. Lett. 2022, 157, 90–96. [Google Scholar] [CrossRef]
- Chen, X.; Xie, S.; He, K. An empirical study of training self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9620–9629. [Google Scholar]
- Perwaiz, N.; Shahzad, M.; Fraz, M. Ubiquitous vision of transformers for person re-identification. Mach. Vis. Appl. 2023, 34, 27. [Google Scholar] [CrossRef]
- Zhou, S.; Wang, F.; Huang, Z.; Wang, J. Discriminative Feature Learning With Consistent Attention Regularization for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8039–8048. [Google Scholar] [CrossRef]
- Huang, Y.; Lian, S.; Hu, H.; Chen, D.; Su, T. Multiscale Omnibearing Attention Networks for Person Re-Identification. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1790–1803. [Google Scholar] [CrossRef]
- Huang, Y.; Peng, P.; Jin, Y.; Li, Y.; Xing, J. Domain Adaptive Attention Learning for Unsupervised Person Re-Identification. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11069–11076. [Google Scholar] [CrossRef]
- Saber, S.; Meshoul, S.; Amin, K.; Pławiak, P.; Hammad, M. A Multi-Attention Approach for Person Re-Identification Using Deep Learning. Sensors 2023, 23, 3678. [Google Scholar] [CrossRef]
- Somers, V.; De Vleeschouwer, C.; Alahi, A. Body Part-Based Representation Learning for Occluded Person Re-Identification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 1613–1623. [Google Scholar]
- Wu, J.J.; Chang, K.H.; Lin, I.C. Generalizable person re-identification with part-based multi-scale network. Multimed. Tools Appl. 2023, 82, 38639–38666. [Google Scholar] [CrossRef]
- Fu, D.; Chen, D.; Bao, J.; Yang, H.; Yuan, L.; Zhang, L.; Li, H.; Chen, D. Unsupervised Pre-Training for Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 14750–14759. [Google Scholar] [CrossRef]
- Yang, Z.; Jin, X.; Zheng, K.; Zhao, F. Unleashing Potential of Unsupervised Pre-Training with Intra-Identity Regularization for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 14278–14287. [Google Scholar] [CrossRef]
- Chen, W.; Xu, X.; Jia, J.; Luo, H.; Wang, Y.; Wang, F.; Jin, R.; Sun, X. Beyond Appearance: A Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks 2023. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 15050–15061. [Google Scholar] [CrossRef]
- Le-Khac, P.H.; Healy, G.; Smeaton, A.F. Contrastive Representation Learning: A Framework and Review. IEEE Access 2020, 8, 193907–193934. [Google Scholar] [CrossRef]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality Reduction by Learning an Invariant Mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar] [CrossRef]
- Wang, M.; Lai, B.; Huang, J.; Gong, X.; Hua, X.S. Graph-Induced Contrastive Learning for Intra-Camera Supervised Person Re-Identification. IEEE Access 2021, 9, 20850–20860. [Google Scholar] [CrossRef]
- Hu, S.; Zhang, X.; Xie, X. Decoupled Contrastive Learning for Intra-Camera Supervised Person Re-identification. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 2628–2665. [Google Scholar] [CrossRef]
- Shi, X.; Liu, H.; Shi, W.; Zhou, Z.; Li, Y. Boosting Person Re-Identification with Viewpoint Contrastive Learning and Adversarial Training. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning Fine-Grained Image Similarity with Deep Ranking. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1386–1393. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Yuan, Y.; Chen, W.; Yang, Y.; Wang, Z. In Defense of the Triplet Loss Again: Learning Robust Person Re-Identification with Fast Approximated Triplet Loss and Label Distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhang, S.; Zhang, Q.; Wei, X.; Zhang, Y.; Xia, Y. Person Re-Identification With Triplet Focal Loss. IEEE Access 2018, 6, 78092–78099. [Google Scholar] [CrossRef]
- Si, T.; Zhang, Z.; Liu, S. Compact Triplet Loss for person re-identification in camera sensor networks. Ad Hoc Netw. 2019, 95, 101984. [Google Scholar] [CrossRef]
- Wieczorek, M.; Rychalska, B.; Dąbrowski, J. On the unreasonable effectiveness of centroids in image retrieval. In Proceedings of the 28th International Conference on Neural Information Processing, ICONIP 2021, Sanur, Bali, Indonesia, 8–12 December 2021; pp. 212–223. [Google Scholar]
- Zhao, D.; Chen, C.; Li, D. Multi-stage attention and center triplet loss for person re-identication. Appl. Intell. 2022, 52, 3077–3089. [Google Scholar] [CrossRef]
- Alnissany, A.; Dayoub, Y. Modified centroid triplet loss for person re-identification. J. Big Data 2023, 10, 74. [Google Scholar] [CrossRef]
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. Beyond Triplet Loss: A Deep Quadruplet Network for Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1320–1329. [Google Scholar] [CrossRef]
- Sohn, K. Improved deep metric learning with multi-class n-pair loss objective. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Horiguchi, S.; Ikami, D.; Aizawa, K. Significance of Softmax-based Features in Comparison to Distance Metric Learning-based Features. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1279–1285. [Google Scholar] [CrossRef]
- Zhai, Y.; Guo, X.; Lu, Y.; Li, H. In Defense of the Classification Loss for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Ni, X.; Rahtu, E. Flipreid: Closing the gap between training and inference in person re-identification. In Proceedings of the 9th European Workshop on Visual Information Processing, EUVIP, Paris, France, 23–25 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Lagadec, B.; Dantcheva, A.; Bremond, F. Joint generative and contrastive learning for unsupervised person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2004–2013. [Google Scholar]
- Varga, D.; Szirányi, T. Person re-identification based on deep multi-instance learning. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 1559–1563. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1179–1188. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising Diffusion Implicit Models. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 994–1003. [Google Scholar] [CrossRef]
- Yanbei, C.; Zhu, X.; Gong, S. Instance-Guided Context Rendering for Cross-Domain Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Verma, A.; Subramanyam, A.; Wang, Z.; Satoh, S.; Shah, R.R. Unsupervised Domain Adaptation for Person Re-Identification Via Individual-Preserving and Environmental-Switching Cyclic Generation. IEEE Trans. Multimed. 2021, 25, 364–377. [Google Scholar] [CrossRef]
- Zhu, Y.; Deng, C.; Cao, H.; Wang, H. Object and background disentanglement for unsupervised cross-domain person re-identification. Neurocomputing 2020, 403, 88–97. [Google Scholar] [CrossRef]
- Dhariwal, P.; Nichol, A.Q. Diffusion Models Beat GANs on Image Synthesis. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 8780–8794. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.; Ghasemipour, S.K.S.; Ayan, B.K.; Mahdavi, S.S.; Lopes, R.G.; et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, 28 November–9 December 2022; Available online: http://papers.nips.cc/paper_files/paper/2022/hash/ec795aeadae0b7d230fa35cbaf04c041-Abstract-Conference.html (accessed on 20 December 2023).
- Ho, J.; Salimans, T.; Gritsenko, A.; Chan, W.; Norouzi, M.; Fleet, D.J. Video diffusion models. arXiv 2022, arXiv:2204.03458. [Google Scholar]
- Asperti, A.; Merizzi, F.; Paparella, A.; Pedrazzi, G.; Angelinelli, M.; Colamonaco, S. Precipitation nowcasting with generative diffusion models. arXiv 2023, arXiv:2308.06733. [Google Scholar]
- Asperti, A.; Evangelista, D.; Marro, S.; Merizzi, F. Image Embedding for Denoising Generative Models. arXiv 2022, arXiv:2301.07485. [Google Scholar] [CrossRef]
- Asperti, A.; Colasuonno, G.; Guerra, A. Portrait Reification with Generative Diffusion Models. Appl. Sci. 2023, 13, 6487. [Google Scholar] [CrossRef]
- Asperti, A.; Colasuonno, G.; Guerra, A. Head Rotation in Denoising Diffusion Models. arXiv 2023, arXiv:2308.06057. [Google Scholar]
- Ho, J.; Salimans, T. Classifier-Free Diffusion Guidance. arXiv 2022, arXiv:2207.12598. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 2642–2651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Kingma, D.; Salimans, T.; Poole, B.; Ho, J. Variational diffusion models. Adv. Neural Inf. Process. Syst. 2021, 34, 21696–21707. [Google Scholar]
- Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8162–8171. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar] [CrossRef]
- Chen, M.; Wang, Z.; Zheng, F. Benchmarks for Corruption Invariant Person Re-identification. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, Virtual, 6–14 December 2021; Available online: https://datasets-benchmarks-proceedings.neurips.cc/paper_files/paper/2021/file/f457c545a9ded88f18ecee47145a72c0-Paper-round2.pdf (accessed on 20 December 2023).
- Asperti, A.; Trentin, M. Balancing Reconstruction Error and Kullback-Leibler Divergence in Variational Autoencoders. IEEE Access 2020, 8, 199440–199448. [Google Scholar] [CrossRef]
- Asperti, A.; Evangelista, D.; Piccolomini, E.L. A Survey on Variational Autoencoders from a Green AI Perspective. SN Comput. Sci. 2021, 2, 301. [Google Scholar] [CrossRef]
- Dai, B.; Wipf, D.P. Diagnosing and enhancing VAE models. In Proceedings of the Seventh International Conference on Learning Representations (ICLR 2019), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Asperti, A. Variance Loss in Variational Autoencoders. In Proceedings of the Machine Learning, Optimization, and Data Science—6th International Conference, LOD 2020, Siena, Italy, 19–23 July 2020. [Google Scholar]
- Fan, H.; Zheng, L.; Yang, Y. Unsupervised Person Re-identification: Clustering and Fine-tuning. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2017, 14, 1–18. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, L.; Chen, W.; Wang, F.; Li, H. Refining pseudo labels for unsupervised Domain Adaptive Re-Identification. Knowl.-Based Syst. 2021, 242, 108336. [Google Scholar] [CrossRef]
- Yan, T.; Zhu, K.; Guo, H.; Zhu, G.; Tang, M.; Wang, J. Plug-and-Play Pseudo Label Correction Network for Unsupervised Person Re-identification. arXiv 2022, arXiv:2206.06607. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asperti, A.; Fiorilla, S.; Orsini, L. A Generative Approach to Person Reidentification. Sensors 2024, 24, 1240. https://doi.org/10.3390/s24041240
Asperti A, Fiorilla S, Orsini L. A Generative Approach to Person Reidentification. Sensors. 2024; 24(4):1240. https://doi.org/10.3390/s24041240
Chicago/Turabian StyleAsperti, Andrea, Salvatore Fiorilla, and Lorenzo Orsini. 2024. "A Generative Approach to Person Reidentification" Sensors 24, no. 4: 1240. https://doi.org/10.3390/s24041240