
SLMSF-Net: A Semantic Localization and Multi-Scale Fusion Network for RGB-D Salient Object Detection
Abstract
:1. Introduction
- The Modality Fusion Problem: Undoubtedly, depth information opens up significant possibilities for enhancing detection performance. The distance information it provides between objects aids in clearly distinguishing the foreground from the background, thereby endowing the algorithm with robustness when dealing with complex scenarios. However, an urgent challenge that remains to be solved is how to fully exploit this depth information and effectively integrate it with the color, texture, and other features of RGB images to extract richer and more discriminative features. This challenge becomes particularly pressing when dealing with issues of incomplete depth information and noise interference, which necessitate further exploration and research.
- The Multi-level Feature Integration Problem: To more effectively integrate multi-level features, it’s vital to fully consider the characteristics of both high-level and low-level features. High-level features contain discriminative semantic information, which aids in the localization of salient objects, while low-level features are rich in detailed information, beneficial for optimizing object edges. Traditional RGB-D salient object detection methods often fuse features from different levels directly, disregarding their inherent differences. This approach can lead to semantic information loss and make the method vulnerable to noise and background interference. Therefore, there is a need to explore more refined feature fusion techniques that fully take into account the characteristics of different levels of features, aiming to boost the performance of salient object detection.
- We propose a depth attention module that leverages channel and spatial attention mechanisms to fully explore the effective information of depth images and enhance the matching ability between RGB and depth feature maps.
- We propose a semantic localization module that constructs a global view for the precise localization of salient objects.
- We propose a reverse decoding network based on multi-scale fusion, which implements reverse decoding on modal fusion features and generates detailed information on salient objects through multi-scale feature fusion.
2. Related Works
2.1. Salient Object Detection Based on RGB Images
2.2. Salient Object Detection Based on RGB-D Images
3. Proposed Method
3.1. Overview of SLMSF-Net
- Modal Feature Fusion: As shown in Figure 1, we proposed a Depth Attention Module. This module performs a modal fusion of RGB image features and depth image features, forming the modal fusion features , , , and .
- Semantic Localization: We proposed a Semantic Localization Module. This module first downsamples the top-level modal fusion feature to compute a global view. It then performs coordinate localization on the global view and ultimately fuses the localization information with the global view, thereby precisely locating the salient object. Assuming the semantic localization module is represented as the SLM function, its output result can be written as: .
- Multi-Scale Fusion Decoding: After performing semantic localization, we predicted the clear boundaries of the salient object through reverse multi-level feature integration from front to back. To accomplish this multi-level feature integration, we constructed a Multi-Scale Fusion Module, which effectively fuses features at all levels.
3.2. Depth Attention Module
3.3. Semantic Localization Module
3.4. Multi-Scale Fusion Module and the Reverse Decoding Process
3.5. Loss Function
4. Experiments
4.1. Implementation Details
4.2. Datasets
4.3. Evaluation Metrics
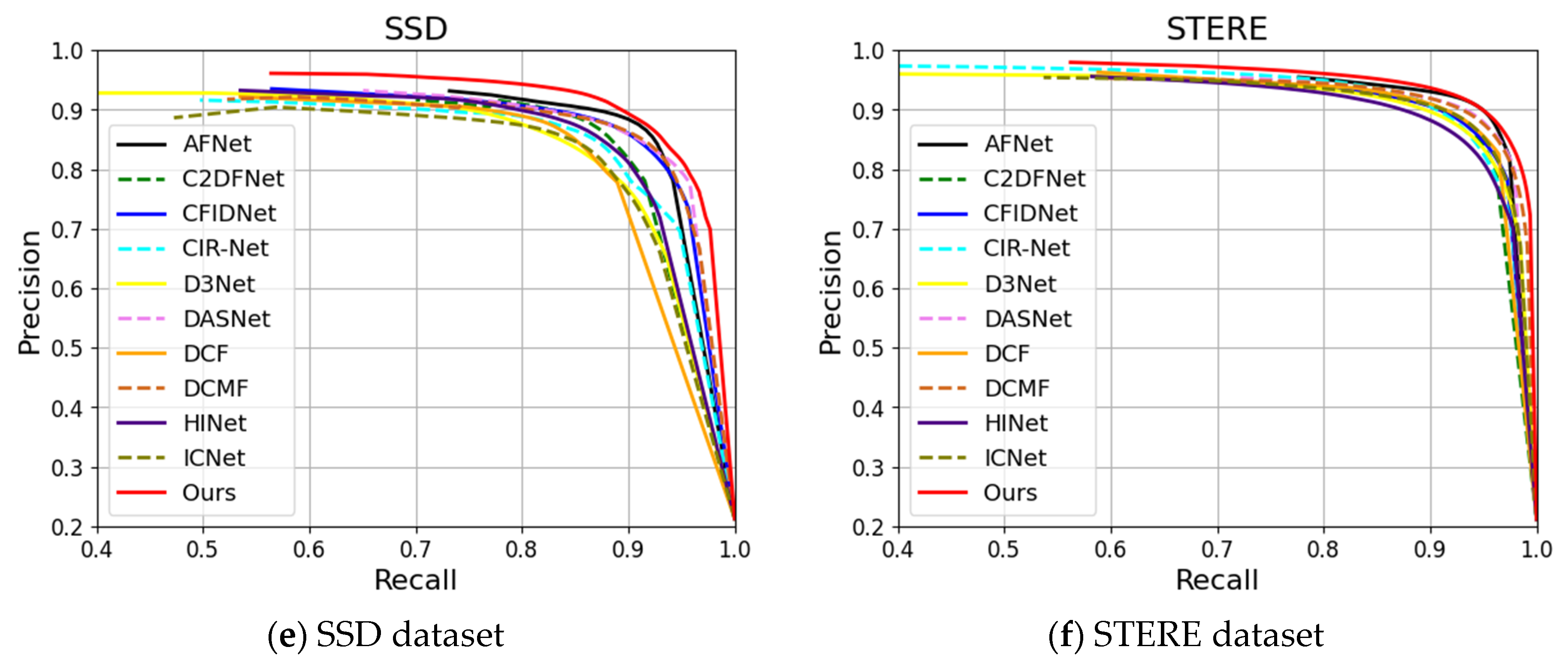
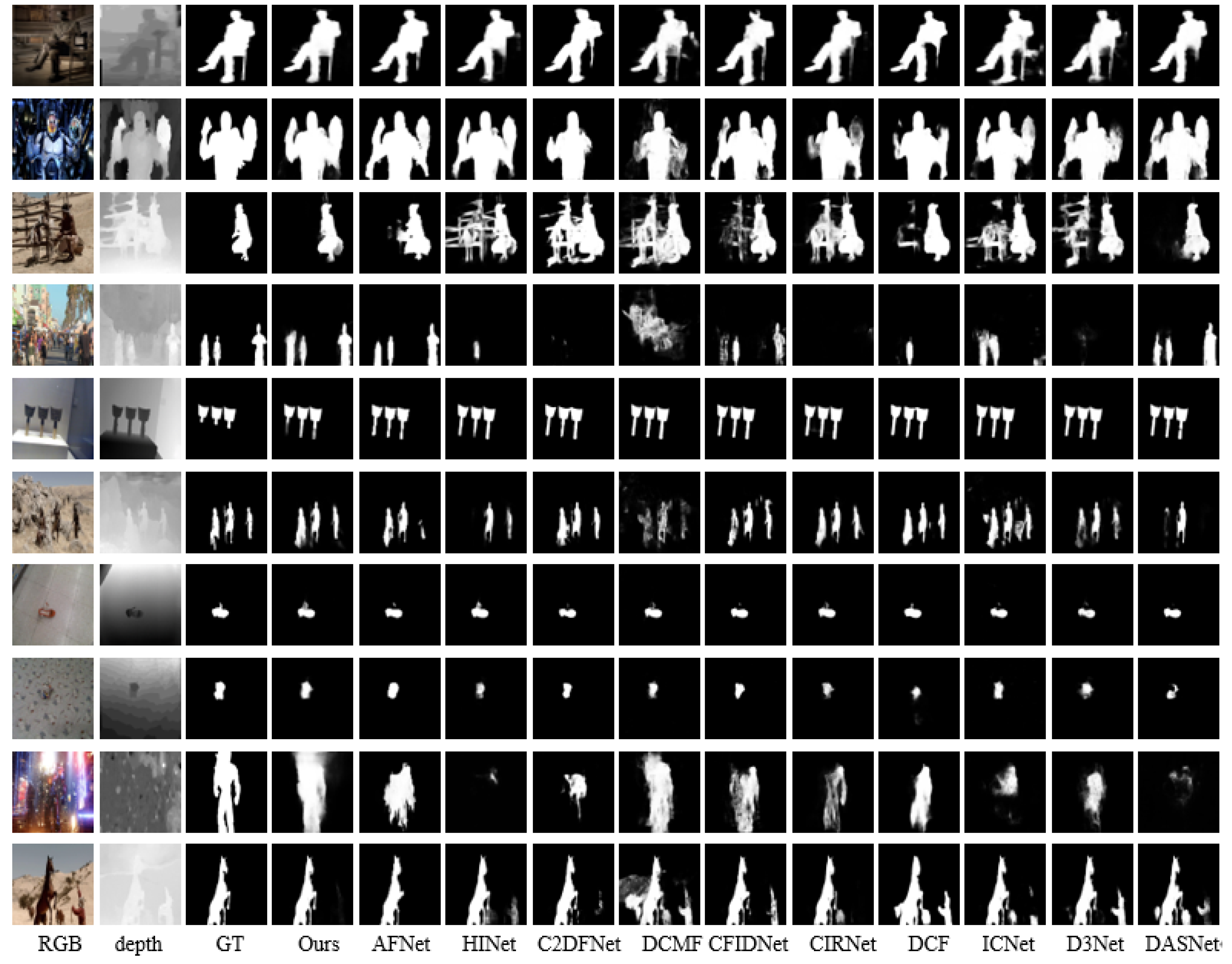
4.4. Comparison with SOTA Methods
4.4.1. Quantitative Comparison
4.4.2. Qualitative Comparison
4.5. Ablation Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.J.; Hou, Q.; Liu, Z.A.; Cheng, M.M. Poolnet+: Exploring the potential of pooling for salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 887–904. [Google Scholar] [CrossRef] [PubMed]
- Liang, Y.; Qin, G.; Sun, M.; Qin, J.; Yan, J.; Zhang, Z.H. Multi-modal interactive attention and dual progressive decoding network for RGB-D/T salient object detection. Neurocomputing 2022, 490, 132–145. [Google Scholar] [CrossRef]
- Zakharov, I.; Ma, Y.; Henschel, M.D.; Bennett, J.; Parsons, G. Object Tracking and Anomaly Detection in Full Motion Video. In Proceedings of the IGARSS 2022, 2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 7910–7913. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.D.; Weng, F.C.; Yuan, Z.H.; Luo, P.; Liu, W.Y.; Wang, X.G. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Wang, R.; Lei, T.; Cui, R.; Zhang, B.T.; Meng, H.Y.; Nandi, A.K. Medical image segmentation using deep learning: A survey. IET Image Process. 2022, 16, 1243–1267. [Google Scholar] [CrossRef]
- He, B.; Hu, W.; Zhang, K.; Yuan, S.D.; Han, X.L.; Su, C.; Zhao, J.M.; Wang, G.Z.; Wang, G.X.; Zhang, L.Y. Image segmentation algorithm of lung cancer based on neural network model. Expert Syst. 2022, 39, e12822. [Google Scholar] [CrossRef]
- Fan, J.; Zheng, P.; Li, S. Vision-based holistic scene understanding towards proactive human–robot collaboration. Robot. Comput.-Integr. Manuf. 2022, 75, 102304. [Google Scholar] [CrossRef]
- Gong, T.; Zhou, W.; Qian, X.; Lei, J.S.; Yu, L. Global contextually guided lightweight network for RGB-thermal urban scene understanding. Eng. Appl. Artif. Intell. 2023, 117, 105510. [Google Scholar] [CrossRef]
- Chen, G.; Shao, F.; Chai, X.; Chen, H.; Jiang, Q.; Meng, X.; Ho, Y.S. Modality-Induced Transfer-Fusion Network for RGB-D and RGB-T Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1787–1801. [Google Scholar] [CrossRef]
- Gao, L.; Fu, P.; Xu, M.; Wang, T.; Liu, B. UMINet: A unified multi-modality interaction network for RGB-D and RGB-T salient object detection. Vis. Comput. 2023, 1–18. [Google Scholar] [CrossRef]
- Wu, Y.H.; Liu, Y.; Xu, J.; Bian, J.W.; Gu, Y.C.; Cheng, M.M. MobileSal: Extremely efficient RGB-D salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 10261–10269. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Zhang, N.; Han, J.; Liu, N. Learning implicit class knowledge for rgb-d co-salient object detection with transformers. IEEE Trans. Image Process. 2022, 31, 4556–4570. [Google Scholar] [CrossRef]
- Wu, Y.H.; Liu, Y.; Zhang, L.; Cheng, M.M.; Ren, B. EDN: Salient object detection via extremely-downsampled network. IEEE Trans. Image Process. 2022, 31, 3125–3136. [Google Scholar] [CrossRef]
- Wu, Z.; Li, S.; Chen, C.; Hao, A.; Qin, H. Recursive multi-model complementary deep fusion for robust salient object detection via parallel sub-networks. Pattern Recognit. 2022, 121, 108212. [Google Scholar] [CrossRef]
- Fan, D.P.; Zhai, Y.; Borji, A.; Yang, J.; Shao, L. BBS-Net: RGB-D salient object detection with a bifurcated backbone strategy network. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 275–292. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer vision And Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Tong, N.; Lu, H.; Zhang, Y.; Ruan, X. Salient object detection via global and local cues. Pattern Recognit. 2015, 48, 3258–3267. [Google Scholar] [CrossRef]
- Chen, C.; Wei, J.; Peng, C.; Qin, H. Depth-quality-aware salient object detection. IEEE Trans. Image Process. 2021, 30, 2350–2363. [Google Scholar] [CrossRef] [PubMed]
- Cong, R.; Yang, N.; Li, C.; Fu, H.; Zhao, Y.; Huang, Q.; Kwong, S. Global-and-local collaborative learning for co-salient object detection. IEEE Trans. Cybern. 2022, 53, 1920–1931. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H. Suppress and balance: A simple gated network for salient object detection. In Proceedings of the Computer Vision–ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 July 2019. [Google Scholar]
- Chen, S.; Tan, X.L.; Wang, B.; Hu, X.L. Reverse attention for salient object detection. In Proceedings of the European Conference on Computer Vision ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, W.; Zhao, S.Y.; Shen, J.B.; Hoi, S.C.H.; Borji, A. Salient object detection with pyramid attention and salient edges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wang, X.; Liu, Z.; Liesaputra, V.; Huang, Z. Feature specific progressive improvement for salient object detection. Pattern Recognit. 2024, 147, 110085. [Google Scholar] [CrossRef]
- Lang, C.; Nguyen, T.V.; Katti, H.; Yadati, K.; Kankanhalli, M.; Yan, S. Depth matters: Influence of depth cues on visual saliency. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 101–115. [Google Scholar]
- Peng, H.; Li, B.; Xiong, W.; Hu, W.; Ji, R. RGBD salient object detection: A benchmark and algorithms. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 92–109. [Google Scholar]
- Zhang, Q.; Qin, Q.; Yang, Y.; Jiao, Q.; Han, J. Feature Calibrating and Fusing Network for RGB-D Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 1–15. [Google Scholar] [CrossRef]
- Ikeda, T.; Masaaki, I. RGB-D Salient Object Detection Using Saliency and Edge Reverse Attention. IEEE Access 2023, 11, 68818–68825. [Google Scholar] [CrossRef]
- Xu, K.; Guo, J. RGB-D salient object detection via convolutional capsule network based on feature extraction and integration. Sci. Rep. 2023, 13, 17652. [Google Scholar] [CrossRef]
- Cong, R.; Liu, H.; Zhang, C.; Zhang, W.; Zheng, F.; Song, R.; Kwong, S. Point-aware interaction and cnn-induced refinement network for RGB-D salient object detection. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023. [Google Scholar]
- Qu, L.; He, S.; Zhang, J.; Tang, Y. RGBD salient object detection via deep fusion. IEEE Trans. Image Process. 2017, 26, 2274–2285. [Google Scholar] [CrossRef]
- Yi, K.; Zhu, J.; Guo, F.; Xu, J. Cross-Stage Multi-Scale Interaction Network for RGB-D Salient Object Detection. IEEE Signal Process. Lett. 2022, 29, 2402–2406. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, K.; Dong, H.; Wang, Y. A cross-modal edge-guided salient object detection for RGB-D image. Neurocomputing 2021, 454, 168–177. [Google Scholar] [CrossRef]
- Sun, F.; Hu, X.H.; Wu, J.Y.; Sun, J.; Wang, F.S. RGB-D Salient Object Detection Based on Cross-modal Interactive Fusion and Global Awareness. J. Softw. 2023, 1–15. [Google Scholar] [CrossRef]
- Peng, Y.; Feng, M.; Zheng, Z. RGB-D Salient Object Detection Method Based on Multi-modal Fusion and Contour Guidance. IEEE Access 2023, 11, 145217–145230. [Google Scholar] [CrossRef]
- Sun, F.; Ren, P.; Yin, B.; Wang, F.; Li, H. CATNet: A cascaded and aggregated transformer network for RGB-D salient object detection. IEEE Trans. Multimed. 2023, 26, 2249–2262. [Google Scholar] [CrossRef]
- Theckedath, D.; Sedamkar, R.R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks. SN Comput. Sci. 2020, 1, 79. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Durrani, T. NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Ketkar, N.; Moolayil, J. Introduction to pytorch. In Deep Learning with Python: Learn Best Practices of Deep Learning Models with PyTorch; Apress: New York, NY, USA, 2021; pp. 27–91. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ju, R.; Ge, L.; Geng, W.; Ren, T.; Wu, G. Depth saliency based on anisotropic center-surround difference. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 1115–1119. [Google Scholar]
- Niu, Y.; Geng, Y.; Li, X.; Liu, F. Leveraging stereopsis for saliency analysis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 454–461. [Google Scholar]
- Zhu, C.; Li, G. A three-pathway psychobiological framework of salient object detection using stereoscopic technology. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 3008–3014. [Google Scholar]
- Fan, D.P.; Lin, Z.; Zhang, Z.; Zhu, M.; Cheng, M.M. Rethinking RGB-D salient object detection: Models, data sets, and large-scale benchmarks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2075–2089. [Google Scholar] [CrossRef]
- Cheng, Y.; Fu, H.; Wei, X.; Xiao, J.; Cao, X. Depth enhanced saliency detection method. In Proceedings of the International Conference on Internet Multimedia Computing and Service, Xiamen, China, 10–12 July 2014; pp. 23–27. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 16 July 2018; pp. 698–704. [Google Scholar]
- Chen, T.; Xiao, J.; Hu, X.; Zhang, G.; Wang, S. Adaptive fusion network for RGB-D salient object detection. Neurocomputing 2023, 522, 152–164. [Google Scholar] [CrossRef]
- Bi, H.; Wu, R.; Liu, Z.; Zhu, H.; Zhang, C.; Xiang, T.Z. Cross-modal hierarchical interaction network for RGB-D salient object detection. Pattern Recognit. 2023, 136, 109194. [Google Scholar] [CrossRef]
- Zhang, M.; Yao, S.; Hu, B.; Piao, Y. C2DFNet: Criss-Cross Dynamic Filter Network for RGB-D Salient Object Detection. IEEE Trans. Multimed. 2022, 25, 5142–5154. [Google Scholar] [CrossRef]
- Wang, F.; Pan, J.; Xu, S.; Tang, J. Learning discriminative cross-modality features for RGB-D saliency detection. IEEE Trans. Image Process. 2022, 31, 1285–1297. [Google Scholar] [CrossRef]
- Chen, T.; Hu, X.; Xiao, J.; Zhang, G.; Wang, S. CFIDNet: Cascaded feature interaction decoder for RGB-D salient object detection. Neural Comput. Appl. 2022, 34, 7547–7563. [Google Scholar] [CrossRef]
- Cong, R.; Lin, Q.; Zhang, C.; Li, C.; Cao, X.; Huang, Q.; Zhao, Y. CIR-Net: Cross-modality interaction and refinement for RGB-D salient object detection. IEEE Trans. Image Process. 2022, 31, 6800–6815. [Google Scholar] [CrossRef] [PubMed]
- Ji, W.; Li, J.; Yu, S.; Zhang, M.; Piao, Y.; Yao, S.; Bi, Q.; Ma, K.; Zheng, Y.; Lu, H.; et al. Calibrated RGB-D salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 9471–9481. [Google Scholar]
- Zhao, J.; Zhao, Y.; Li, J.; Chen, X. Is depth really necessary for salient object detection? In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1745–1754. [Google Scholar]
- Li, G.; Liu, Z.; Ling, H. ICNet: Information conversion network for RGB-D based salient object detection. IEEE Trans. Image Process. 2020, 29, 4873–4884. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Evaluation Metrics | Deep Learning-Based RGB-D Saliency Detection Methods | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DASNet ICMM2020 | D3Net TNNLS 2020 | ICNet TIP2020 | DCF CVPR2021 | CIRNet TIP2022 | CFIDNet NCA2022 | DCMF TIP2022 | C2DFNet TMM2022 | HINet PR2023 | AFNet NC2023 | Ours | ||
| NJU2K [47] | MAE↓ | 0.0418 | 0.0467 | 0.0519 | 0.0357 | 0.0350 | 0.0378 | 0.0357 | 0.0387 | 0.0385 | 0.0317 | 0.0315 |
| maxF↑ | 0.9015 | 0.8993 | 0.8905 | 0.9147 | 0.9281 | 0.9148 | 0.9252 | 0.9089 | 0.9138 | 0.9282 | 0.9352 | |
| maxE↑ | 0.9393 | 0.9381 | 0.9264 | 0.9504 | 0.9547 | 0.9464 | 0.9582 | 0.9425 | 0.9447 | 0.9578 | 0.9615 | |
| S↑ | 0.9025 | 0.9 | 0.8941 | 0.9116 | 0.9252 | 0.9142 | 0.9247 | 0.9082 | 0.9153 | 0.9262 | 0.9306 | |
| NLPR [30] | MAE↓ | 0.0212 | 0.0298 | 0.0281 | 0.0217 | 0.0280 | 0.0256 | 0.0290 | 0.0217 | 0.0257 | 0.0201 | 0.0199 |
| maxF↑ | 0.9218 | 0.8968 | 0.9079 | 0.9118 | 0.9071 | 0.9054 | 0.9057 | 0.9166 | 0.9062 | 0.9249 | 0.9298 | |
| maxE↑ | 0.9641 | 0.9529 | 0.9524 | 0.9628 | 0.9554 | 0.9553 | 0.9541 | 0.9605 | 0.9565 | 0.9684 | 0.9693 | |
| S↑ | 0.9294 | 0.9118 | 0.9227 | 0.9239 | 0.9208 | 0.9219 | 0.9220 | 0.9279 | 0.9223 | 0.9362 | 0.9388 | |
| DES [51] | MAE↓ | 0.0246 | 0.0314 | 0.0266 | 0.0241 | 0.0287 | 0.0233 | 0.0232 | 0.0199 | 0.0215 | 0.0221 | 0.0176 |
| maxF↑ | 0.9025 | 0.8842 | 0.9132 | 0.8935 | 0.8917 | 0.9108 | 0.9239 | 0.9159 | 0.9220 | 0.9225 | 0.9307 | |
| maxE↑ | 0.9390 | 0.9451 | 0.9598 | 0.9514 | 0.9407 | 0.9396 | 0.9679 | 0.9590 | 0.9670 | 0.9529 | 0.9739 | |
| S↑ | 0.9047 | 0.8973 | 0.9201 | 0.9049 | 0.9067 | 0.9169 | 0.9324 | 0.9217 | 0.9274 | 0.9252 | 0.9403 | |
| SIP [50] | MAE↓ | 0.0508 | 0.0632 | 0.0695 | 0.0518 | 0.0685 | 0.0601 | 0.0623 | 0.0529 | 0.0656 | 0.0434 | 0.0422 |
| maxF↑ | 0.8864 | 0.861 | 0.8571 | 0.8844 | 0.8662 | 0.8699 | 0.8719 | 0.8770 | 0.8550 | 0.9089 | 0.9114 | |
| maxE↑ | 0.9247 | 0.9085 | 0.9033 | 0.9217 | 0.9047 | 0.9088 | 0.9111 | 0.9160 | 0.8993 | 0.9389 | 0.9408 | |
| S↑ | 0.8767 | 0.8603 | 0.8538 | 0.8756 | 0.8615 | 0.8638 | 0.8700 | 0.8715 | 0.8561 | 0.8959 | 0.9045 | |
| SSD [49] | MAE↓ | 0.0423 | 0.0585 | 0.0637 | 0.0498 | 0.0523 | 0.0504 | 0.0731 | 0.0478 | 0.0488 | 0.0383 | 0.0321 |
| maxF↑ | 0.8725 | 0.834 | 0.8414 | 0.8509 | 0.8547 | 0.8707 | 0.8108 | 0.8598 | 0.8524 | 0.8848 | 0.9007 | |
| maxE↑ | 0.9298 | 0.9105 | 0.9025 | 0.9090 | 0.9119 | 0.9261 | 0.8970 | 0.9171 | 0.9160 | 0.9427 | 0.9565 | |
| S↑ | 0.8846 | 0.8566 | 0.8484 | 0.8644 | 0.8725 | 0.8791 | 0.8382 | 0.8718 | 0.8652 | 0.8968 | 0.9062 | |
| STERE [48] | MAE↓ | 0.0368 | 0.0462 | 0.0446 | 0.0389 | 0.0457 | 0.0426 | 0.0433 | 0.0385 | 0.0490 | 0.0336 | 0.0331 |
| maxF↑ | 0.9043 | 0.8911 | 0.8978 | 0.9009 | 0.8966 | 0.8971 | 0.9061 | 0.8973 | 0.8828 | 0.9177 | 0.9195 | |
| maxE↑ | 0.9436 | 0.9382 | 0.9415 | 0.9447 | 0.9388 | 0.9420 | 0.9463 | 0.9429 | 0.9325 | 0.9572 | 0.9584 | |
| S↑ | 0.9104 | 0.8985 | 0.9025 | 0.9022 | 0.9013 | 0.9012 | 0.9097 | 0.9023 | 0.8919 | 0.9184 | 0.9201 | |
| Datasets | Evaluation Metrics | Without DAM | Without SLM | Without MSFM | SLMSF-Net |
|---|---|---|---|---|---|
| NJU2K [47] | MAE↓ | 0.0362 | 0.0352 | 0.0393 | 0.0315 |
| maxF↑ | 0.9214 | 0.9215 | 0.9165 | 0.9352 | |
| maxE↑ | 0.9516 | 0.9508 | 0.9478 | 0.9615 | |
| S↑ | 0.921 | 0.9225 | 0.9185 | 0.9306 | |
| NLPR [30] | MAE↓ | 0.0235 | 0.0234 | 0.0284 | 0.0199 |
| maxF↑ | 0.9226 | 0.9193 | 0.911 | 0.9298 | |
| maxE↑ | 0.9627 | 0.964 | 0.9593 | 0.9693 | |
| S↑ | 0.9328 | 0.9327 | 0.9238 | 0.9388 | |
| DES [51] | MAE↓ | 0.0191 | 0.0228 | 0.0231 | 0.0176 |
| maxF↑ | 0.9284 | 0.9174 | 0.9263 | 0.9307 | |
| maxE↑ | 0.9704 | 0.9618 | 0.9687 | 0.9739 | |
| S↑ | 0.9342 | 0.9260 | 0.9317 | 0.9403 | |
| SIP [50] | MAE↓ | 0.0569 | 0.0528 | 0.0600 | 0.0422 |
| maxF↑ | 0.8827 | 0.8916 | 0.8748 | 0.9114 | |
| maxE↑ | 0.9154 | 0.9202 | 0.9119 | 0.9408 | |
| S↑ | 0.8776 | 0.8830 | 0.8739 | 0.9045 | |
| SSD [49] | MAE↓ | 0.0537 | 0.0534 | 0.0548 | 0.0321 |
| maxF↑ | 0.8378 | 0.8381 | 0.8395 | 0.9007 | |
| maxE↑ | 0.9093 | 0.9042 | 0.9045 | 0.9565 | |
| S↑ | 0.8661 | 0.865 | 0.8658 | 0.9062 | |
| STERE [48] | MAE↓ | 0.0443 | 0.0376 | 0.0508 | 0.0331 |
| maxF↑ | 0.8919 | 0.9100 | 0.8906 | 0.9195 | |
| maxE↑ | 0.9381 | 0.9479 | 0.9330 | 0.9584 | |
| S↑ | 0.9014 | 0.9143 | 0.8986 | 0.9201 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Y.; Zhai, Z.; Feng, M. SLMSF-Net: A Semantic Localization and Multi-Scale Fusion Network for RGB-D Salient Object Detection. Sensors 2024, 24, 1117. https://doi.org/10.3390/s24041117
Peng Y, Zhai Z, Feng M. SLMSF-Net: A Semantic Localization and Multi-Scale Fusion Network for RGB-D Salient Object Detection. Sensors. 2024; 24(4):1117. https://doi.org/10.3390/s24041117
Chicago/Turabian StylePeng, Yanbin, Zhinian Zhai, and Mingkun Feng. 2024. "SLMSF-Net: A Semantic Localization and Multi-Scale Fusion Network for RGB-D Salient Object Detection" Sensors 24, no. 4: 1117. https://doi.org/10.3390/s24041117