
HDPose: Post-Hierarchical Diffusion with Conditioning for 3D Human Pose Estimation

Abstract
:1. Introduction
- We propose a novel hierarchical diffusion-based (HDPose) method that can converged to a fast and accurate 3D pose by aggregating spatio-temporal information to all layers of the denoising model.
- We performed experiments with various conditioning methods, including simple 2D pose, non-hierarchical, pre-hierarchical, and post-hierarchical structure. Through empirical observation, we identified the model structure that yielded the best performance.
- Our proposed hierarchical model, when compared to state-of-the-art methods, demonstrated competitive results. It maintained a lightweight model, showcasing its effectiveness on the Human3.6M and MPI-INF-3DHP datasets.
2. Related Work
2.1. 3D Human Pose Estimation
2.2. Generative 3D Human Pose Estimation
3. Proposed Method: Hierarchical Diffusion 3D Human Pose Estimation (HDPose)
3.1. Diffusion Model
- Forward Process can be modeled as a Markov chain [38] wherein Gaussian noise is gradually added to the ground truth 3D pose at each subsequent step t until the state attains a Gaussian distribution. It is denoted as . To train the diffusion model to denoise a 3D pose in a progressive manner, it must be provided with supervisory signals in the form of ground truth distributions. We can generate samples from these distributions using the forward diffusion process iteration, starting with the ground truth 3D pose distribution and gradually adding noise. This process can predefine through variance noise scheduler and step t as follows:We used the cosine noise variance schedule [39] to control the amount of noise added to the 3D pose at each step of the diffusion process. We enabled a reparameterization trick to make the diffusion process more efficient by enabling direct sampling from the noise distribution. Following DDPM [12], this process can be expressed as:where , and Gaussian noise . We can optimize by randomly sampling t during training, thereby exploiting these properties.
- Reverse Process is a process of reconstruction of the correct 3D pose from an incorrect 3D pose. The task of accurately reconstructing a 3D pose from a random distribution remains a significant challenge. To address this, we adapted the diffusion process based on the context information derived from the 2D sequence. This approach ensured the attainment of a deterministic 3D pose that aligns with the spatial and temporal embedding vectors. Reverse processes can also be expressed as a joint distribution , which describes the probability of observing a 3D pose at timestep t.In the DDPM [12], was fixed as constant. Considering the mean parameter , we can compute the distribution of the previous timestep using the function, which is defined as follows.Therefore, the only remaining task is to predict . However, in the above method, timestep t is typically set to a value greater than 100 to ensure that the model can accurately learn the diffusion process. As a result, this can make the reverse diffusion process computationally expensive. Instead of predicting the noise, we approximated the reverse diffusion process using DDIM [40] to reduce the computational cost, which required fewer iterations. Therefore, we directly predicted the correct 3D pose from the trained network.
3.2. Training and Sampling Process
3.3. Pre-Trained Model of Conditioning
3.4. Hierarchical Conditioning Diffusion for 3D Human Pose Estimation
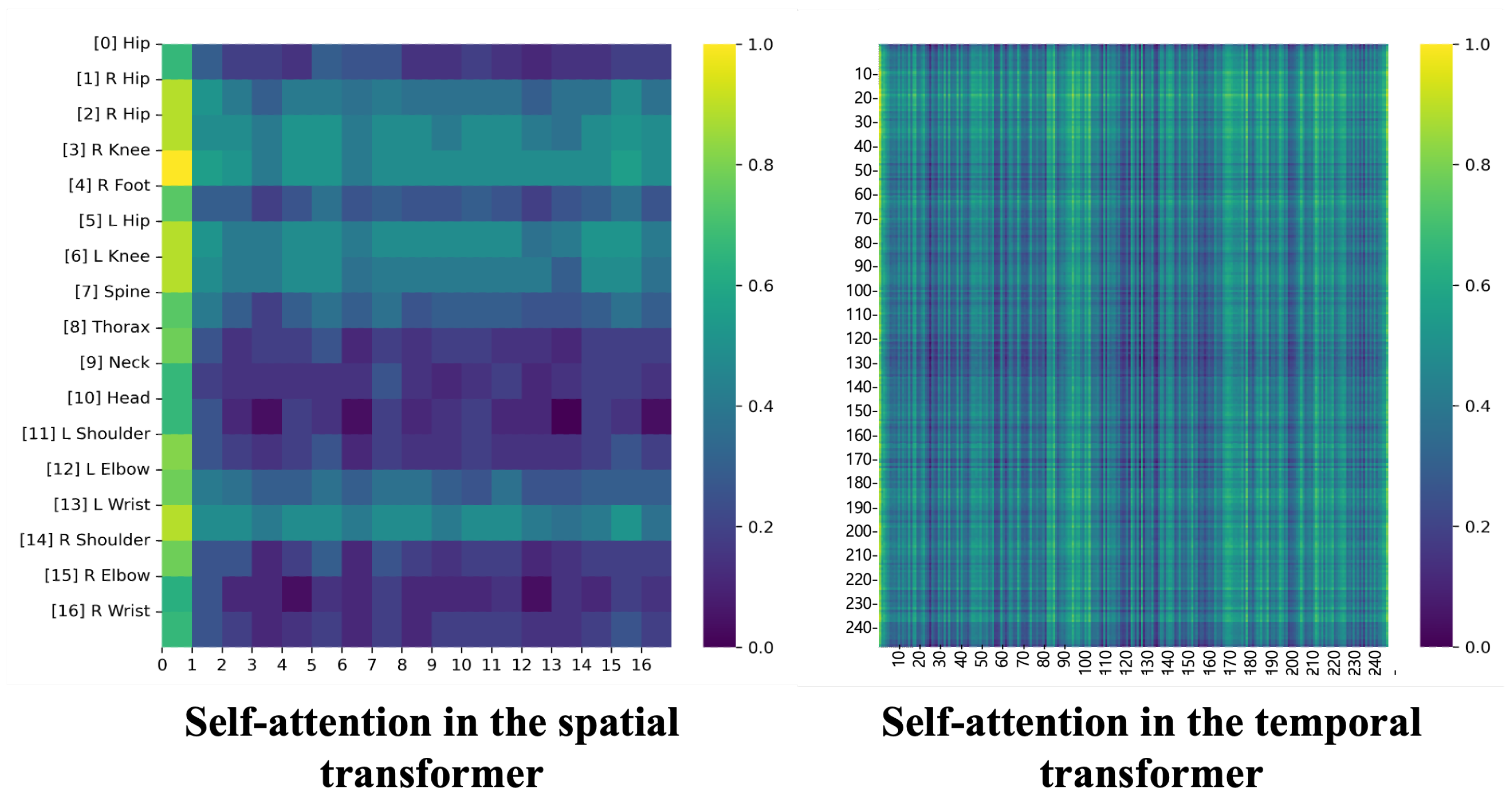
- Pre-Hierarchical StructureIn Figure 1c, this architecture is inspired by the work of Sun et al. [42]. Their work showed that connecting feature maps of varying depths allows networks to integrate and utilize multiscale information, which can lead to a more nuanced understanding of the input data. Instead of using a simple 2D pose as a condition, we use an consisting of a spatial encoder and a temporal encoder . The spatial encoder learns the spatial correlations between all joints in the frame. This approach allows the model to gain a more accurate understanding of the actual structure of the body and the natural connections between joints, leading to more precise and realistic pose estimation. Initially, the 2D pose is transformed into a higher-dimensional embedding vector via linear projection. This vector X is combined with the learnable spatial location sign and then input to . The output of is processed by , which captures the joint correlation of each frame. As observed in [16], there are significant differences in the motion trajectories of the joints from frame to frame, so it is essential to learn a distinct trajectory pattern for each joint in each frame.The depth of the encoder is denoted by L. In this framework, the fusion module uses a linear projection to align the dimensions of the concatenated features with the dimensions of the spatial encoder used for denoising. In the denoising model , the input features include both the condition and the incorrect 3D pose and the time interval t. The incorrect 3D pose is then merged with the associated condition feature and jointly trained. The training process described in Section 3.2 is then performed.
- Post-Hierarchical StructureAs shown in Figure 1d, we introduce a post-hierarchical structure as an efficient way to accurately and quickly guide the construction of the correct 3D pose. From our observations, we found that spreading the final extracted features in a hierarchical structure to each encoder layer of the denoising model yields the most effective results. Similar to (b), we extract from the final layer of the condition model. We then pass this feature, which covers the entire spatial and temporal information, to the denoising model . In traditional 3D HPE methods using diffusion, it is common to associate the condition with only in the initial encoder, whereas our approach incorporates it in all encoder layers. The incorrect 3D pose is transformed into a high-dimensional embedding vector, which is then added along with a spatial position embedding and a time interval embedding t. At each encoder step, this embedding vector is further aggregated with the global features of the condition model to produce global condition information. The output of the spatial encoder is combined with the temporal position embedding . The combined features are then reshaped in the dimension and provided as input to the temporal encoder . This procedure is repeated on all encoder layers to the final depth to extract the final 3D pose . The is utilized to generate a noisy 3D pose to be input to the denoising model as the next step, which is input via DDIM [40]. This procedure is repeated N times. The goal is to progressively refine the pose to an accurate 3D structure. This process is repeated N times, progressively refining the pose to an accurate 3D reconstruction. Figure 2 shows the detailed architecture of the Post-Hierarchical Structure.
4. Experiment Results
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Quantitative Results
- Results on benchmark dataset. Table 1 demonstrates that our method yielded nearly identical results to the previous SOTA models in terms of average MPJPE for Protocol 1 at 41.0 mm and for Protocol 2 at 32.8 mm, while outperforming other models. Specifically, on the Human3.6M, our model exhibited an improvement of approximately 4.21% (1.8 mm) for Protocol 1 and 4.65% (1.6 mm) for Protocol 2, compared to the method proposed by Shan et al. [46]. On the MPI-INF-3DHP, it exhibited a significant enhancement of 38.45% (from 58.0 mm to 35.7 mm) compared to the method proposed by Liu et al. [8]. For detailed information, refer to Table 2.
- Results on computational complexity. To evaluate the computational complexity of our model, we compared the number of trainable parameters with those of previous models. Despite its lightweight design, our model matched the performance of SOTA models, with a reasonable number of floating-point operations per second (FLOPs). The training process performed on a single GeForce 3090 GPU completes 100 epochs in about 24 h. Further emphasizing its efficiency, a comparison of frames per second (FPS) during the inference process revealed real-time capabilities. These detailed results are elucidated in Table 3.
- Results on comparison of convergence. We compared the convergence speed of our proposed method HDPose and the state-of-the-art model [7,16], and the result is reported in Figure 3. Comparing the optimal MPJPE performance over 100 epochs, Zheng et al. [7] achieved 45.1 mm in 100 epochs and Zhang et al. [16] achieved 42.2 mm in 96 epochs. On the other hand, we can see that our proposed model converges to 42.1 mm already in 60 epochs with a faster learning process. By comparing the convergence speed with other state-of-the-art (SOTA) models, we found that our proposed model outperforms others by up to 26% at peak performance. We found that our model has a faster learning convergence speed than other models using pre-trained conditioning models. The model was trained to recognize weights that were optimized to recognize features that were already useful in a spatial and temporal context.
- Results on visualization. Figure 4 presents a comparison of the state-of-the-art (SOTA) methods [7,16,28] and HDPose by visualizing their performance across three actions: Sitting, Greeting, and WalkingDog in Subject S11 of Human3.6M. We found that our proposed method generated more plausible poses than previous works and closely resembled the ground truth 3D pose. We also presented visualization results on MPI-INF-3DHP and on 3DPW [47], an “in-the-wild” dataset that reflects a real-world environment with varying lighting, backgrounds, and camera angles. More details on this can be found in the Appendix A.
4.4. Ablation Study
4.5. Limitations and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Visualization of the HDPose in Various Environments


References
- Ehlers, K.; Brama, K. A human-robot interaction interface for mobile and stationary robots based on real-time 3D human body and hand-finger pose estimation. In Proceedings of the 2016 IEEE 21st International Conference on Emerging Technologies and Factory Automation (ETFA), Berlin, Germany, 6–9 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Zheng, J.; Shi, X.; Gorban, A.; Mao, J.; Song, Y.; Qi, C.R.; Liu, T.; Chari, V.; Cornman, A.; Zhou, Y.; et al. Multi-modal 3D human pose estimation with 2D weak supervision in autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4478–4487. [Google Scholar]
- Zhou, Y.; Huang, H.; Yuan, S.; Zou, H.; Xie, L.; Yang, J. MetaFi++: WiFi-enabled Transformer-based Human Pose Estimation for Metaverse Avatar Simulation. IEEE Internet Things J. 2023, 10, 14128–14136. [Google Scholar] [CrossRef]
- Mehta, D.; Sridhar, S.; Sotnychenko, O.; Rhodin, H.; Shafiei, M.; Seidel, H.P.; Xu, W.; Casas, D.; Theobalt, C. Vnect: Real-time 3d human pose estimation with a single rgb camera. Acm Trans. Graph. (Tog) 2017, 36, 44. [Google Scholar] [CrossRef]
- Chen, C.H.; Ramanan, D. 3d human pose estimation = 2d pose estimation+ matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7035–7043. [Google Scholar]
- Hossain, M.R.I.; Little, J.J. Exploiting temporal information for 3d human pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 68–84. [Google Scholar]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3d human pose estimation with spatial and temporal transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 11656–11665. [Google Scholar]
- Li, W.; Liu, H.; Tang, H.; Wang, P.; Van Gool, L. Mhformer: Multi-hypothesis transformer for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13147–13156. [Google Scholar]
- Xu, T.; Takano, W. Graph stacked hourglass networks for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 16105–16114. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A simple yet effective baseline for 3d human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2640–2649. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3d human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7753–7762. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Choi, J.; Shim, D.; Kim, H.J. DiffuPose: Monocular 3D Human Pose Estimation via Denoising Diffusion Probabilistic Model. arXiv 2023, arXiv:2212.02796. [Google Scholar]
- Rommel, C.; Valle, E.; Chen, M.; Khalfaoui, S.; Marlet, R.; Cord, M.; Perez, P. DiffHPE: Robust, Coherent 3D Human Pose Lifting with Diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Paris, France, 2–3 October 2023; pp. 3220–3229. [Google Scholar]
- Lu, Z.; Wu, C.; Chen, X.; Wang, Y.; Qiao, Y.; Liu, X. Hierarchical Diffusion Autoencoders and Disentangled Image Manipulation. arXiv 2023, arXiv:2304.11829. [Google Scholar]
- Zhang, J.; Tu, Z.; Yang, J.; Chen, Y.; Yuan, J. MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13232–13242. [Google Scholar]
- Tekin, B.; Rozantsev, A.; Lepetit, V.; Fua, P. Direct Prediction of 3D Body Poses from Motion Compensated Sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chen, Y.; Tu, Z.; Kang, D.; Chen, R.; Bao, L.; Zhang, Z.; Yuan, J. Joint Hand-object 3D Reconstruction from a Single Image with Cross-branch Feature Fusion. arXiv 2020, arXiv:2006.15561. [Google Scholar] [CrossRef] [PubMed]
- Kocabas, M.; Athanasiou, N.; Black, M.J. VIBE: Video Inference for Human Body Pose and Shape Estimation. arXiv 2019, arXiv:1912.05656. [Google Scholar]
- Habibie, I.; Xu, W.; Mehta, D.; Pons-Moll, G.; Theobalt, C. In the wild human pose estimation using explicit 2d features and intermediate 3d representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10905–10914. [Google Scholar]
- Tekin, B.; Márquez-Neila, P.; Salzmann, M.; Fua, P. Learning to fuse 2d and 3d image cues for monocular body pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3941–3950. [Google Scholar]
- Zhao, L.; Peng, X.; Tian, Y.; Kapadia, M.; Metaxas, D.N. Semantic graph convolutional networks for 3d human pose regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3425–3435. [Google Scholar]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3d human pose estimation in the wild: A weakly-supervised approach. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 398–407. [Google Scholar]
- Tome, D.; Russell, C.; Agapito, L. Lifting from the deep: Convolutional 3d pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2500–2509. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-fine volumetric prediction for single-image 3D human pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7025–7034. [Google Scholar]
- Dabral, R.; Mundhada, A.; Kusupati, U.; Afaque, S.; Sharma, A.; Jain, A. Learning 3d human pose from structure and motion. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 668–683. [Google Scholar]
- Zeng, A.; Sun, X.; Huang, F.; Liu, M.; Xu, Q.; Lin, S. Srnet: Improving generalization in 3d human pose estimation with a split-and-recombine approach. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 507–523. [Google Scholar]
- Liu, R.; Shen, J.; Wang, H.; Chen, C.; Cheung, S.c.; Asari, V. Attention mechanism exploits temporal contexts: Real-time 3d human pose reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5064–5073. [Google Scholar]
- Zhou, L.; Chen, Y.; Wang, J. Dual-Path Transformer for 3D Human Pose Estimation. IEEE Trans. Circuits Syst. Video Technol. 2023, 1. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Sohn, K.; Yan, X.; Lee, H. Learning Structured Output Representation Using Deep Conditional Generative Models. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Sanur, Indonesia, 8–12 December 2021; MIT Press: Cambridge, MA, USA, 2015. NIPS’15. Volume 2, pp. 3483–3491. [Google Scholar]
- Rezende, D.J.; Mohamed, S. Variational Inference with Normalizing Flows. arXiv 2016, arXiv:1505.05770. [Google Scholar]
- Barsoum, E.; Kender, J.R.; Liu, Z. HP-GAN: Probabilistic 3D human motion prediction via GAN. arXiv 2017, arXiv:1711.09561. [Google Scholar]
- Sharma, S.; Varigonda, P.T.; Bindal, P.; Sharma, A.; Jain, A. Monocular 3D Human Pose Estimation by Generation and Ordinal Ranking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wehrbein, T.; Rudolph, M.; Rosenhahn, B.; Wandt, B. Probabilistic Monocular 3D Human Pose Estimation With Normalizing Flows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 11199–11208. [Google Scholar]
- Holmquist, K.; Wandt, B. Diffpose: Multi-hypothesis human pose estimation using diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 15977–15987. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Norris, J.R. Markov Chains; Number 2; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Nichol, A.; Dhariwal, P. Improved Denoising Diffusion Probabilistic Models. arXiv 2021, arXiv:2102.09672. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising Diffusion Implicit Models. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained models: Past, present and future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Ionescu, C.; Li, F.; Sminchisescu, C. Latent Structured Models for Human Pose Estimation. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Mehta, D.; Rhodin, H.; Casas, D.; Fua, P.; Sotnychenko, O.; Xu, W.; Theobalt, C. Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision. In Proceedings of the 3D Vision (3DV), 2017 Fifth International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Shan, W.; Liu, Z.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. P-stmo: Pre-trained spatial temporal many-to-one model for 3d human 545 pose estimation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 461–478. [Google Scholar]
- Von Marcard, T.; Henschel, R.; Black, M.; Rosenhahn, B.; Pons-Moll, G. Recovering Accurate 3D Human Pose in The Wild Using IMUs and a Moving Camera. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Qian, X.; Tang, Y.; Zhang, N.; Han, M.; Xiao, J.; Huang, M.C.; Lin, R.S. HSTFormer: Hierarchical Spatial-Temporal Transformers for 3D Human Pose Estimation. arXiv 2023, arXiv:2301.07322. [Google Scholar]
- Zhao, W.; Wang, W.; Tian, Y. Graformer: Graph-oriented transformer for 3d pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20438–20447. [Google Scholar]
- Cai, Y.; Ge, L.; Liu, J.; Cai, J.; Cham, T.J.; Yuan, J.; Thalmann, N.M. Exploiting spatial-temporal relationships for 3d pose estimation 537 via graph convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer 538 Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2272–2281. [Google Scholar]
- Shan, W.; Lu, H.; Wang, S.; Zhang, X.; Gao, W. Improving robustness and accuracy via relative information encoding in 3d 540 human pose estimation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 3446–3454. [Google Scholar]
- Chen, T.; Fang, C.; Shen, X.; Zhu, Y.; Chen, Z.; Luo, J. Anatomy-aware 3d human pose estimation with bone-based pose decomposition. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 198–209. [Google Scholar] [CrossRef]
- Wang, J.; Yan, S.; Xiong, Y.; Lin, D. Motion Guided 3D Pose Estimation from Videos. arXiv 2020, arXiv:2004.13985. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2019. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Protocol 1 (MPJPE) | Dir. | Disc | Eat | Greet | Phone | Photo | Pose | Purch. | Sit | SitD. | Smoke | Wait | WalkD. | Walk | WalkT. | Avg. |
| Zhao et al. [49] | 45.2 | 50.8 | 48.0 | 50.0 | 54.9 | 65.0 | 48.2 | 47.1 | 60.2 | 70.0 | 51.6 | 48.7 | 54.1 | 39.7 | 43.1 | 51.8 |
| Cai et al. [50] (N = 7) | 44.6 | 47.4 | 45.6 | 48.8 | 50.8 | 59.0 | 47.2 | 43.9 | 57.9 | 61.9 | 49.7 | 46.6 | 51.3 | 37.1 | 39.4 | 48.8 |
| Pavllo et al. [11] (N = 243) | 45.2 | 46.7 | 43.3 | 45.6 | 48.1 | 55.1 | 44.6 | 44.3 | 57.3 | 65.8 | 47.1 | 44.0 | 49.0 | 32.8 | 33.9 | 46.8 |
| Liu et al. [28] (N = 243) | 41.3 | 43.9 | 44.0 | 42.2 | 48.0 | 57.1 | 42.2 | 43.2 | 57.3 | 61.3 | 47.0 | 43.5 | 47.0 | 32.6 | 31.8 | 45.1 |
| Zeng [27] | 46.6 | 47.1 | 43.9 | 41.6 | 45.8 | 49.6 | 46.5 | 40.0 | 53.4 | 61.1 | 46.1 | 42.6 | 43.1 | 31.5 | 32.6 | 44.8 |
| Shan et al. [51] (N = 243) | 40.8 | 44.5 | 41.4 | 42.7 | 46.3 | 55.6 | 41.8 | 41.9 | 53.7 | 60.8 | 45.0 | 41.5 | 44.8 | 30.8 | 31.9 | 44.3 |
| Zheng et al. [7] (N = 81) | 41.5 | 44.8 | 39.8 | 42.5 | 46.5 | 51.6 | 42.1 | 42.0 | 53.3 | 60.7 | 45.5 | 43.3 | 46.1 | 31.8 | 32.2 | 44.3 |
| Chen et al. [52] (N = 243) | 41.4 | 43.2 | 40.1 | 42.9 | 46.6 | 51.9 | 41.7 | 42.3 | 53.9 | 60.2 | 45.4 | 41.7 | 46.0 | 31.5 | 32.7 | 44.1 |
| Li et al. [8] (N = 351) | 39.2 | 43.1 | 40.1 | 40.9 | 44.9 | 51.2 | 40.6 | 41.3 | 53.5 | 60.3 | 43.7 | 41.1 | 43.8 | 29.8 | 30.6 | 43.0 |
| Shan et al. [46] (N = 243) | 38.9 | 42.7 | 40.4 | 41.1 | 45.6 | 49.7 | 40.9 | 39.9 | 55.5 | 59.4 | 44.9 | 42.2 | 42.7 | 29.4 | 29.4 | 42.8 |
| Zhang et al. [16] (N = 243) | 37.9 | 40.7 | 37.8 | 39.6 | 42.3 | 50.2 | 39.9 | 39.9 | 51.6 | 55.6 | 42.1 | 39.9 | 40.8 | 27.9 | 28.0 | 40.9 |
| Choi et al. [13] (H = 10) ‡ | 43.4 | 50.7 | 45.4 | 50.2 | 49.6 | 53.4 | 48.6 | 45.0 | 56.9 | 70.7 | 47.8 | 48.2 | 51.3 | 43.1 | 43.4 | 49.4 |
| Holmquist et al. [36] (H = 200) ‡ | 38.1 | 43.1 | 35.3 | 43.1 | 46.6 | 48.2 | 39.0 | 37.6 | 51.9 | 59.3 | 41.7 | 47.6 | 45.4 | 37.4 | 36.0 | 43.3 |
| Ours (N = 243, H = 1) | 37.8 | 40.7 | 37.7 | 39.6 | 42.4 | 50.2 | 39.8 | 40.2 | 51.8 | 55.8 | 42.2 | 39.8 | 41.0 | 27.9 | 28.1 | 41.0 |
| Protocol 2 (PA-MPJPE) | Dir. | Disc | Eat | Greet | Phone | Photo | Pose | Purch. | Sit | SitD. | Smoke | Wait | WalkD. | Walk | WalkT. | Avg. |
| Cai et al. [50] (N = 7) | 35.7 | 37.8 | 36.9 | 40.7 | 39.6 | 45.2 | 37.4 | 34.5 | 46.9 | 50.1 | 40.5 | 36.1 | 41.0 | 29.6 | 33.2 | 39.0 |
| Liu et al. [28] (N = 243) | 32.3 | 35.2 | 33.3 | 35.8 | 35.9 | 41.5 | 33.2 | 32.7 | 44.6 | 50.9 | 37.0 | 32.4 | 37.0 | 25.2 | 27.2 | 35.6 |
| Zheng et al. [7] (N = 81) | 32.5 | 34.8 | 32.6 | 34.6 | 35.3 | 39.5 | 32.1 | 32.0 | 42.8 | 48.5 | 34.8 | 32.4 | 35.3 | 24.5 | 26.0 | 34.6 |
| Chen et al. [52] (N = 243) | 32.6 | 35.1 | 32.8 | 35.4 | 36.3 | 40.4 | 32.4 | 32.3 | 42.7 | 49.0 | 36.8 | 32.4 | 36.0 | 24.9 | 26.5 | 35.0 |
| Li et al. [8] | 31.5 | 34.9 | 32.8 | 33.6 | 35.3 | 39.6 | 32.0 | 32.2 | 43.5 | 48.7 | 36.4 | 32.6 | 34.3 | 23.9 | 25.1 | 34.4 |
| Shan et al. [46] (N = 243) | 31.3 | 35.2 | 32.9 | 33.9 | 35.4 | 39.3 | 32.5 | 31.5 | 44.6 | 48.2 | 36.3 | 32.9 | 34.4 | 23.8 | 23.9 | 34.4 |
| Zhang et al. [16] (N = 243) | 30.8 | 33.1 | 30.3 | 31.8 | 33.1 | 39.1 | 31.1 | 30.5 | 42.5 | 44.5 | 34.0 | 30.8 | 32.7 | 22.1 | 22.9 | 32.6 |
| Choi et al. [13] (H = 10) ‡ | 35.9 | 40.3 | 36.7 | 41.4 | 39.8 | 43.4 | 37.1 | 35.5 | 46.2 | 59.7 | 39.9 | 38.0 | 41.9 | 32.9 | 34.2 | 39.9 |
| Holmquist et al. [36] (H = 200) ‡ | 27.9 | 31.4 | 29.7 | 30.2 | 34.9 | 37.1 | 27.3 | 28.2 | 39.0 | 46.1 | 34.2 | 32.3 | 33.6 | 26.1 | 27.5 | 32.4 |
| Ours (N = 243, H = 1) | 31.0 | 33.2 | 30.6 | 31.9 | 33.2 | 39.2 | 31.1 | 30.7 | 42.5 | 45.0 | 34.1 | 30.7 | 32.5 | 22.0 | 23.0 | 32.8 |
| Method | PCK↑ | AUC↑ | MPJPE↓ | |
|---|---|---|---|---|
| Pavllo et al. [11] (T = 243) | CVPR’19 | 85.5 | 51.5 | 84.8 |
| Wang et al. [53] (T = 96) | ECCV’20 | 86.9 | 62.1 | 68.1 |
| Chen et al. [52] (T = 25) | TCSVT’21 | 87.9 | 54.0 | 79.1 |
| Liu et al. [8] (T = 9) | CVPR’22 | 93.8 | 63.3 | 58.0 |
| Zhang et al. [16] (T = 243) | CVPR’22 | 96.9 | 75.8 | 35.4 |
| Ours (T = 243) | Ours | 96.5 | 75.6 | 35.7 |
| Method | MPJPE | Params (M) | FLOPs | FPS |
|---|---|---|---|---|
| Zheng et al. [7] | 44.4 | 9.5 | 1358 | 269 |
| Shan et al. [46] | 42.8 | 6.7 | 1737 | 3040 |
| Zhang et al. [16] | 40.9 | 33.6 | 645 | 4547 |
| Ours | 41.0 | 5.0 | 78.5 | 4054 |
| MPJPE | Params (M) | FLOPs | ||
|---|---|---|---|---|
| 256 | 64 | 47.6 | 0.3 | 5.0 |
| 256 | 128 | 44.4 | 1.2 | 19.7 |
| 256 | 256 | 41.0 | 5.0 | 78.5 |
| 256 | 512 | 41.7 | 19.9 | 313.0 |
| Hiearchical Aggregation | Spatial | Temporal | MPJPE |
|---|---|---|---|
| Spatial only | ✓ | × | 45.9 |
| Temporal only | × | ✓ | 45.6 |
| Spatial and temporal | ✓ | ✓ | 41.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, D.; Kim, J. HDPose: Post-Hierarchical Diffusion with Conditioning for 3D Human Pose Estimation. Sensors 2024, 24, 829. https://doi.org/10.3390/s24030829
Lee D, Kim J. HDPose: Post-Hierarchical Diffusion with Conditioning for 3D Human Pose Estimation. Sensors. 2024; 24(3):829. https://doi.org/10.3390/s24030829
Chicago/Turabian StyleLee, Donghoon, and Jaeho Kim. 2024. "HDPose: Post-Hierarchical Diffusion with Conditioning for 3D Human Pose Estimation" Sensors 24, no. 3: 829. https://doi.org/10.3390/s24030829