
Omnidirectional-Sensor-System-Based Texture Noise Correction in Large-Scale 3D Reconstruction

Abstract
:1. Introduction
- We propose a comprehensive 3D reconstruction framework based on an omnidirectional sensor system for large-scale scenes. The framework includes data organization, geometry reconstruction, and texture optimization.
- We propose a frame-voting rendering mechanism in texture noise correction by integrating multiple frames according to the luminance values, which eliminates texture noise such as specular highlight, frame color inconsistency, and object occlusion.
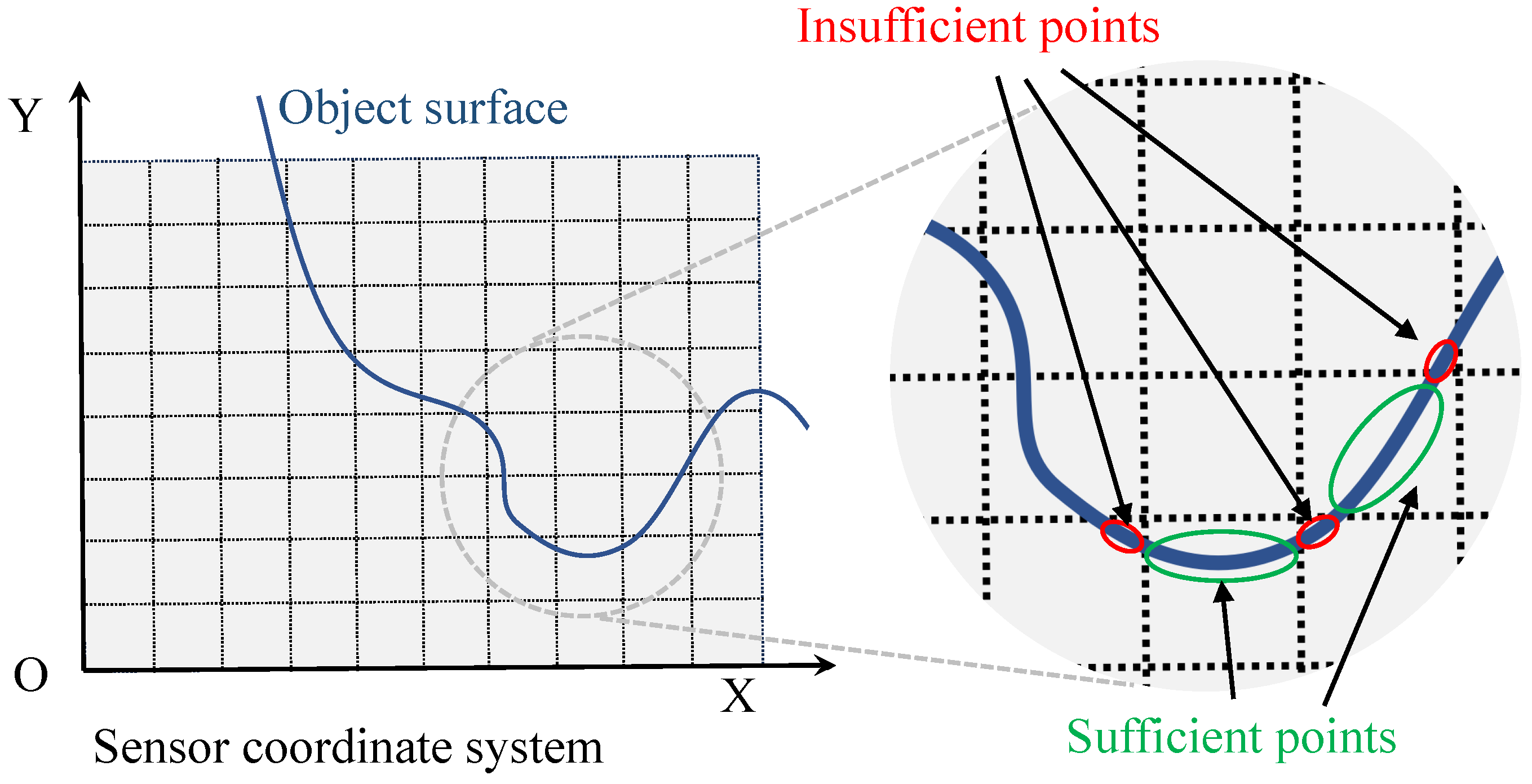
- We propose a neighbor-aided rendering mechanism to optimize color for certain voxels that has insufficient points for texture self-optimization, by using convincing color information from neighboring voxels.
2. Related Work
2.1. Imaging Sensors
2.2. Geometry Reconstruction
2.3. Texture Noise Correction
3. Methodology
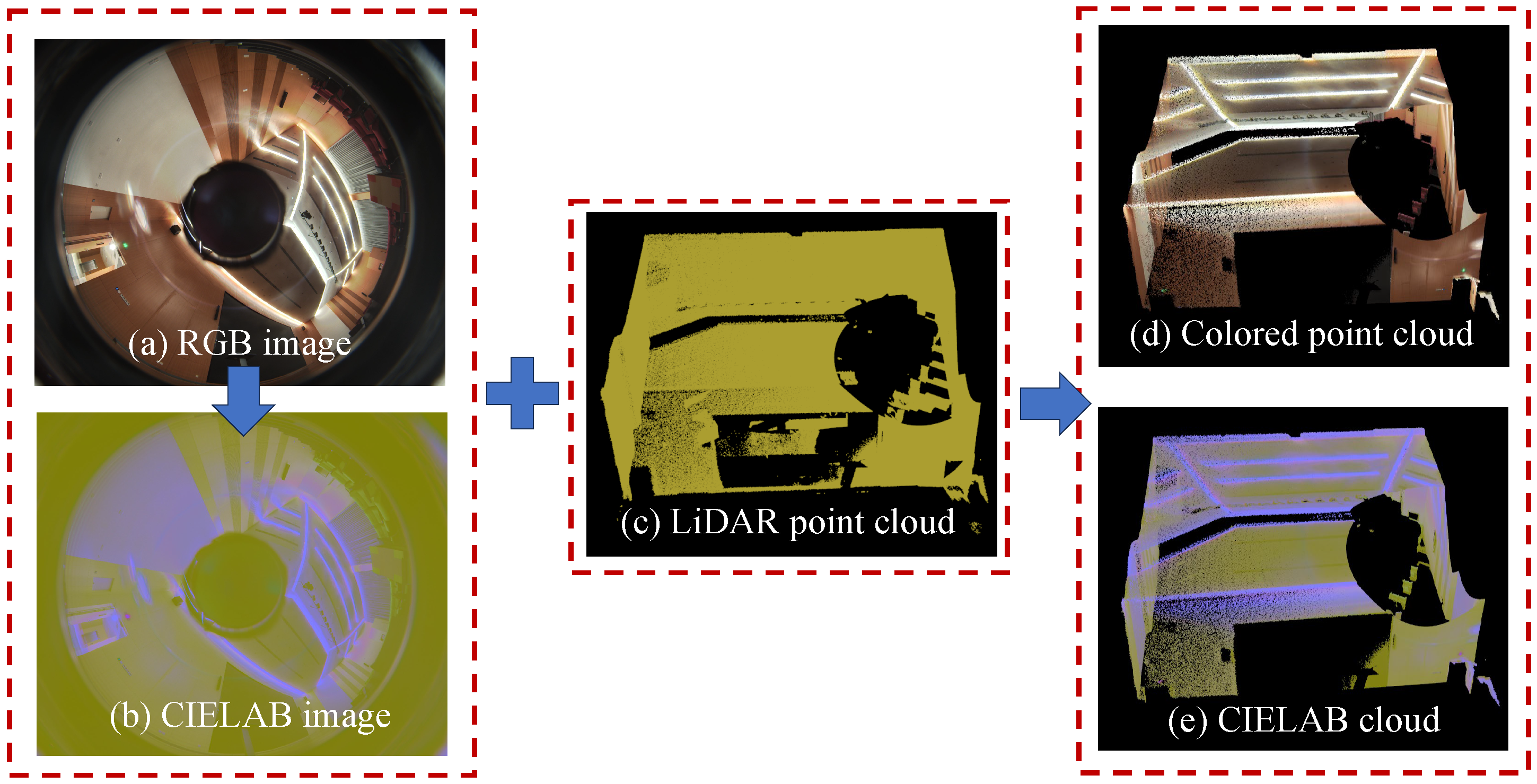
3.1. Data Organization
3.2. Geometry Reconstruction
3.3. Texture Optimization
3.3.1. Frame-Voting Rendering
3.3.2. Neighbor-Aided Rendering
| Algorithm 1: Neighbor-Aided Rendering |
 |
4. Experiment
4.1. Experimental Environment, Equipment, and Data
4.2. Efficiency Analysis
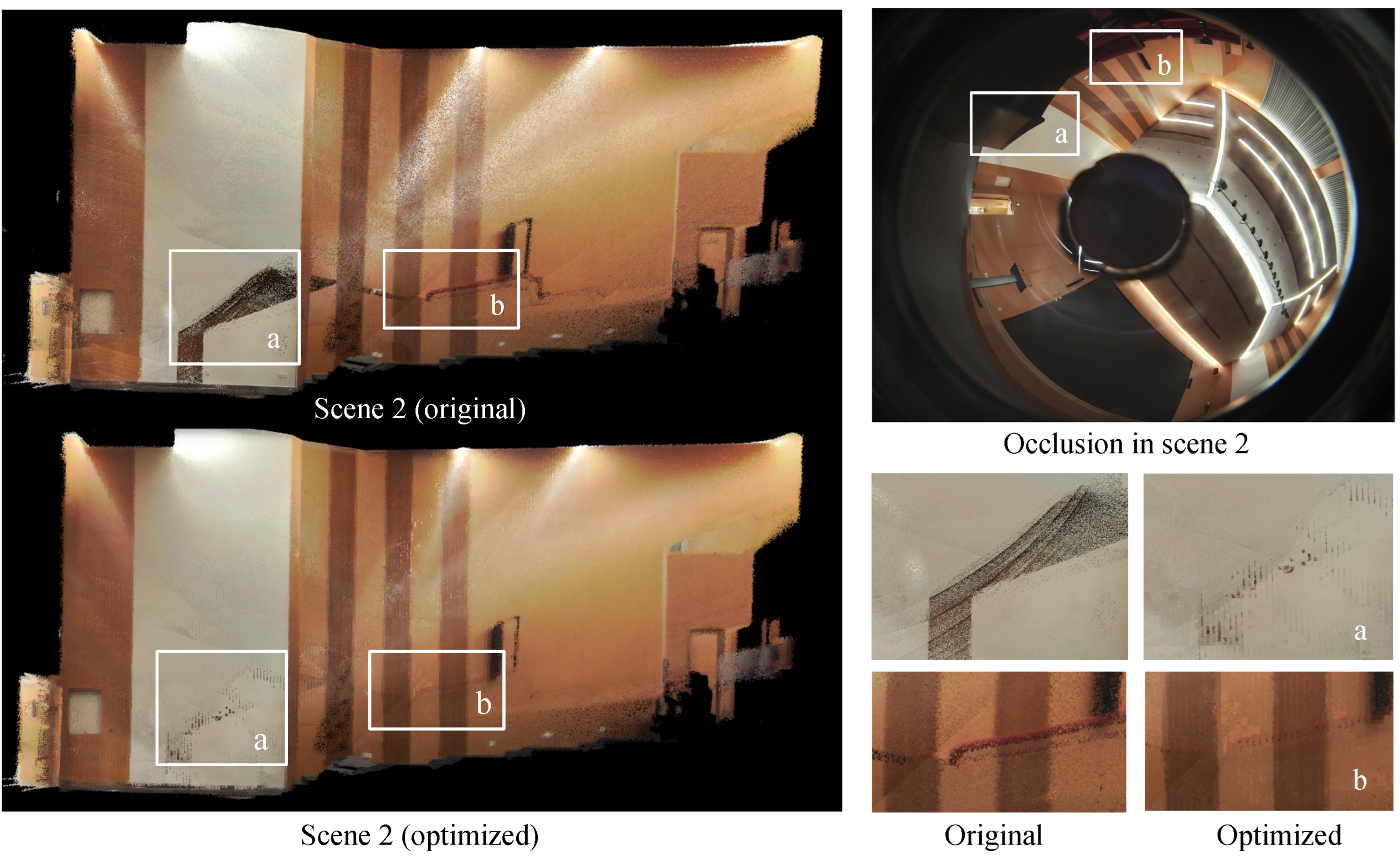
4.3. Experiment Results of Texture Optimization
4.3.1. Results on Frame-Voting Rendering
4.3.2. Results on Neighbor-Aided Rendering
4.3.3. Comparing Results of Highlight Removal
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, Y.; Khanna, N.; Boushey, C.J.; Delp, E.J. Specular highlight removal for image-based dietary assessment. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo Workshops, Melbourne, Australia, 9–13 July 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 424–428. [Google Scholar]
- Yang, Q.; Wang, S.; Ahuja, N. Real-time specular highlight removal using bilateral filtering. In Computer Vision—ECCV 2010, Proceedings of the 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Proceedings, Part IV 11; Springer: Berlin/Heidelberg, Germany, 2010; pp. 87–100. [Google Scholar]
- Shen, H.L.; Zheng, Z.H. Real-time highlight removal using intensity ratio. Appl. Opt. 2013, 52, 4483–4493. [Google Scholar] [CrossRef] [PubMed]
- Fu, G.; Zhang, Q.; Song, C.; Lin, Q.; Xiao, C. Specular Highlight Removal for Real-world Images. Comput. Graph. Forum 2019, 38, 253–263. [Google Scholar] [CrossRef]
- Yang, J.; Liu, L.; Li, S. Separating specular and diffuse reflection components in the HSI color space. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 891–898. [Google Scholar]
- Yamamoto, T.; Nakazawa, A. General improvement method of specular component separation using high-emphasis filter and similarity function. ITE Trans. Media Technol. Appl. 2019, 7, 92–102. [Google Scholar] [CrossRef]
- Wei, X.; Xu, X.; Zhang, J.; Gong, Y. Specular highlight reduction with known surface geometry. Comput. Vis. Image Underst. 2018, 168, 132–144. [Google Scholar] [CrossRef]
- Jin, Y.; Li, R.; Yang, W.; Tan, R.T. Estimating reflectance layer from a single image: Integrating reflectance guidance and shadow/specular aware learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1069–1077. [Google Scholar]
- Li, W.; Gong, H.; Yang, R. Fast texture mapping adjustment via local/global optimization. IEEE Trans. Vis. Comput. Graph. 2018, 25, 2296–2303. [Google Scholar] [CrossRef] [PubMed]
- Ye, X.; Wang, L.; Li, D.; Zhang, M. 3D reconstruction with multi-view texture mapping. In Neural Information Processing, Proceedings of the 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017; Proceedings, Part III 24; Springer: Berlin/Heidelberg, Germany, 2017; pp. 198–207. [Google Scholar]
- Chuang, M.; Luo, L.; Brown, B.J.; Rusinkiewicz, S.; Kazhdan, M. Estimating the Laplace-Beltrami operator by restricting 3d functions. Comput. Graph. Forum 2009, 28, 1475–1484. [Google Scholar] [CrossRef]
- Nießner, M.; Zollhöfer, M.; Izadi, S.; Stamminger, M. Real-time 3D reconstruction at scale using voxel hashing. ACM Trans. Graph. (TOG) 2013, 32, 169. [Google Scholar] [CrossRef]
- Marr, D.; Poggio, T. Cooperative Computation of Stereo Disparity: A cooperative algorithm is derived for extracting disparity information from stereo image pairs. Science 1976, 194, 283–287. [Google Scholar] [CrossRef] [PubMed]
- Ullman, S. The Interpretation of Visual Motion; The MIT Press: Cambridge, MA, USA, 1979. [Google Scholar]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Photo tourism: Exploring photo collections in 3D. In Proceedings of the ACM SIGGRAPH 2006 Papers, Boston, MA, USA, 30 July–3 August 2006; pp. 835–846. [Google Scholar]
- Lindner, M.; Kolb, A.; Hartmann, K. Data-fusion of PMD-based distance-information and high-resolution RGB-images. In Proceedings of the 2007 International Symposium on Signals, Circuits and Systems, Iasi, Romania, 13–14 July 2007; IEEE: Piscataway, NJ, USA, 2007; Volume 1, pp. 1–4. [Google Scholar]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced computer vision with microsoft kinect sensor: A review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [PubMed]
- Bouguet, J.Y. Camera Calibration Toolbox for Matlab. 2004. Available online: https://data.caltech.edu/records/jx9cx-fdh55 (accessed on 5 November 2023).
- Zhang, Q.; Pless, R. Extrinsic calibration of a camera and laser range finder (improves camera calibration). In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No. 04CH37566), Sendai, Japan, 28 September–2 October 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 3, pp. 2301–2306. [Google Scholar]
- Scaramuzza, D.; Harati, A.; Siegwart, R. Extrinsic self calibration of a camera and a 3d laser range finder from natural scenes. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 4164–4169. [Google Scholar]
- Miao, Z.; He, B.; Xie, W.; Zhao, W.; Huang, X.; Bai, J.; Hong, X. Coarse-to-Fine Hybrid 3D Mapping System with Co-Calibrated Omnidirectional Camera and Non-Repetitive LiDAR. IEEE Robot. Autom. Lett. 2023, 8, 1778–1785. [Google Scholar] [CrossRef]
- Curless, B.; Levoy, M. A volumetric method for building complex models from range images. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 303–312. [Google Scholar]
- Rusinkiewicz, S.; Hall-Holt, O.; Levoy, M. Real-time 3D model acquisition. ACM Trans. Graph. (TOG) 2002, 21, 438–446. [Google Scholar] [CrossRef]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. Kinectfusion: Real-time 3d reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 559–568. [Google Scholar]
- Whelan, T.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J.; Leutenegger, S. ElasticFusion: Real-time dense SLAM and light source estimation. Int. J. Robot. Res. 2016, 35, 1697–1716. [Google Scholar] [CrossRef]
- Fuhrmann, S.; Goesele, M. Fusion of depth maps with multiple scales. ACM Trans. Graph. (TOG) 2011, 30, 148. [Google Scholar] [CrossRef]
- Zeng, M.; Zhao, F.; Zheng, J.; Liu, X. A memory-efficient kinectfusion using octree. In Computational Visual Media, Proceedings of the First International Conference, CVM 2012, Beijing, China, 8–10 November 2012; Proceedings; Springer: Berlin/Heidelberg, Germany, 2012; pp. 234–241. [Google Scholar]
- Steinbrücker, F.; Sturm, J.; Cremers, D. Volumetric 3D mapping in real-time on a CPU. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2021–2028. [Google Scholar]
- Kähler, O.; Prisacariu, V.A.; Ren, C.Y.; Sun, X.; Torr, P.; Murray, D. Very high frame rate volumetric integration of depth images on mobile devices. IEEE Trans. Vis. Comput. Graph. 2015, 21, 1241–1250. [Google Scholar] [CrossRef] [PubMed]
- Prisacariu, V.A.; Kähler, O.; Golodetz, S.; Sapienza, M.; Cavallari, T.; Torr, P.H.; Murray, D.W. Infinitam v3: A framework for large-scale 3d reconstruction with loop closure. arXiv 2017, arXiv:1708.00783. [Google Scholar]
- Guo, X.; Cao, X.; Ma, Y. Robust separation of reflection from multiple images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2187–2194. [Google Scholar]
- Guo, D.; Cheng, Y.; Zhuo, S.; Sim, T. Correcting over-exposure in photographs. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 515–521. [Google Scholar]
- Xu, W.; Zhang, F. Fast-lio: A fast, robust lidar-inertial odometry package by tightly-coupled iterated kalman filter. IEEE Robot. Autom. Lett. 2021, 6, 3317–3324. [Google Scholar] [CrossRef]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-icp. In Proceedings of the Robotics: Science and Systems, Seattle, WA, USA, 28 June–1 July 2009; Volume 2, p. 435. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 2366–2369. [Google Scholar]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.; Zhang, F. R 3 LIVE: A Robust, Real-time, RGB-colored, LiDAR-Inertial-Visual tightly-coupled state Estimation and mapping package. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 10672–10678. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Scale |
|---|---|
| Frame number | 20 |
| Point number | 69,740,000 |
| Scene size | |
| Voxel resolution | 0.05 m |
| Voxel block size | |
| VB number without hash mapping | 44,000 |
| VB number with hash mapping | 11,284 |
| Stage | Computation Time(s) |
|---|---|
| Hash table creation | 1.35 |
| Point assignment | 5.93 |
| Frame-voting rendering | 21.60 |
| Neighbor-aided rendering | 21.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, W.; Hong, X. Omnidirectional-Sensor-System-Based Texture Noise Correction in Large-Scale 3D Reconstruction. Sensors 2024, 24, 78. https://doi.org/10.3390/s24010078
Xie W, Hong X. Omnidirectional-Sensor-System-Based Texture Noise Correction in Large-Scale 3D Reconstruction. Sensors. 2024; 24(1):78. https://doi.org/10.3390/s24010078
Chicago/Turabian StyleXie, Wenya, and Xiaoping Hong. 2024. "Omnidirectional-Sensor-System-Based Texture Noise Correction in Large-Scale 3D Reconstruction" Sensors 24, no. 1: 78. https://doi.org/10.3390/s24010078