
High-Precision Carton Detection Based on Adaptive Image Augmentation for Unmanned Cargo Handling Tasks


Abstract
:1. Introduction
2. Related Work
2.1. Deep Learning Models
2.2. Data Augmentations
2.3. Discussion
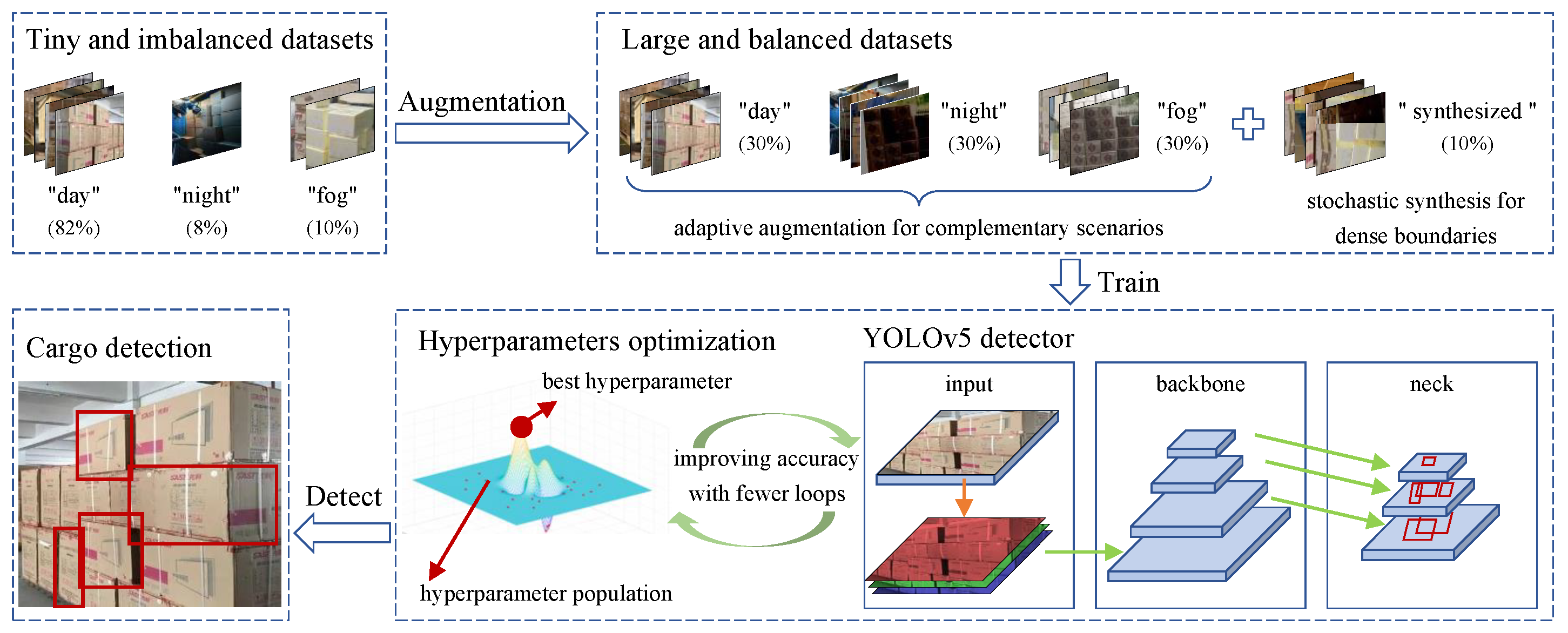
3. Methodology
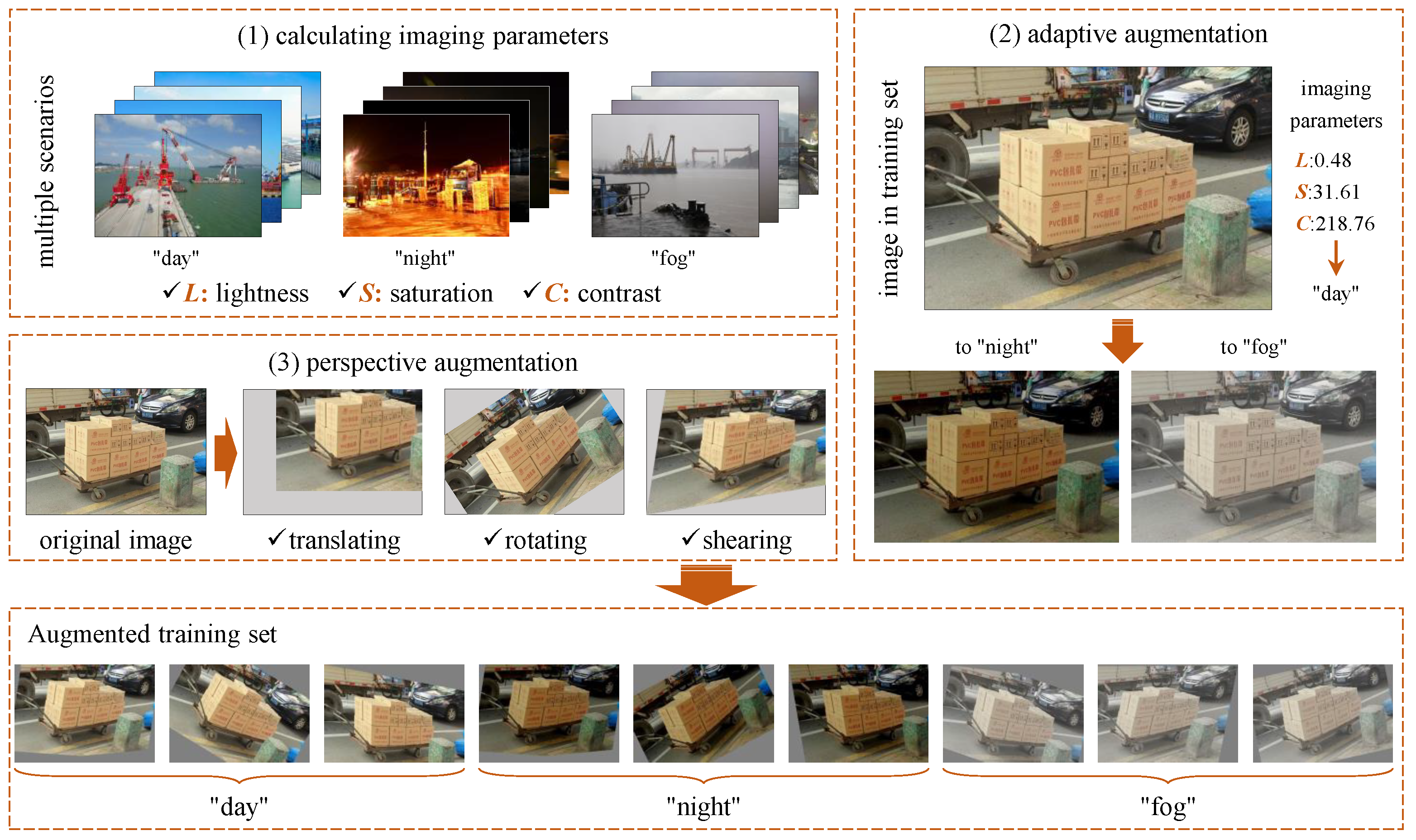
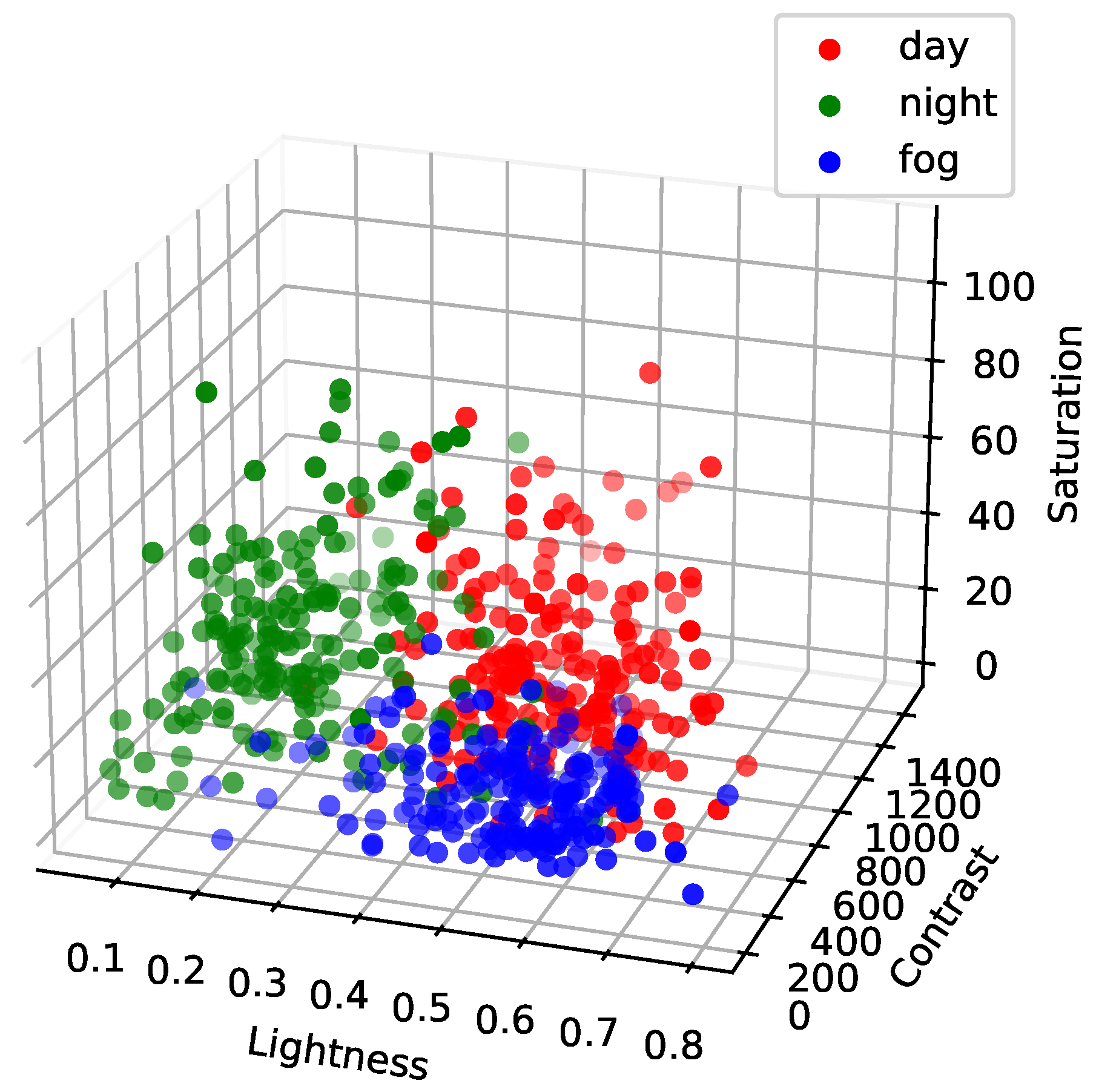
3.1. Adaptive Augmentation for Complementary Scenarios
| Algorithm 1 Adaptive Complementary Augmentation Algorithm |
Input: image sets of multiple scenarios , ; original training set ; allowable deviation of imaging parameters Output: augmented training set
|
3.2. Stochastic Synthesis of Multi-Boundary Features
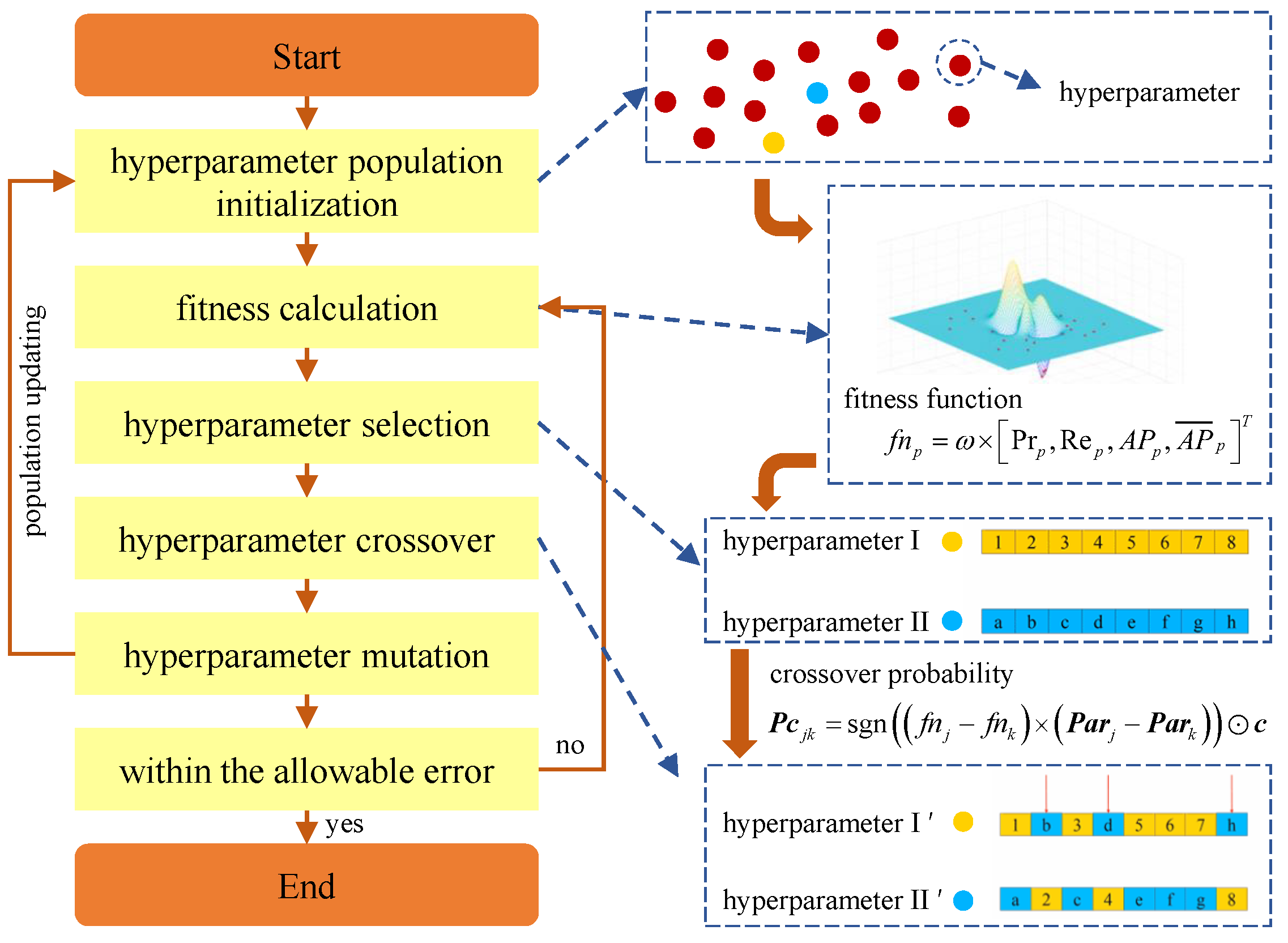
3.3. Hyperparameters Optimization Based on Modified GA
| Algorithm 2 Hyperparameters Optimization Algorithm |
Input: hyperparameters population Par Output: the optimal set of hyperparameters
|
4. Experiments
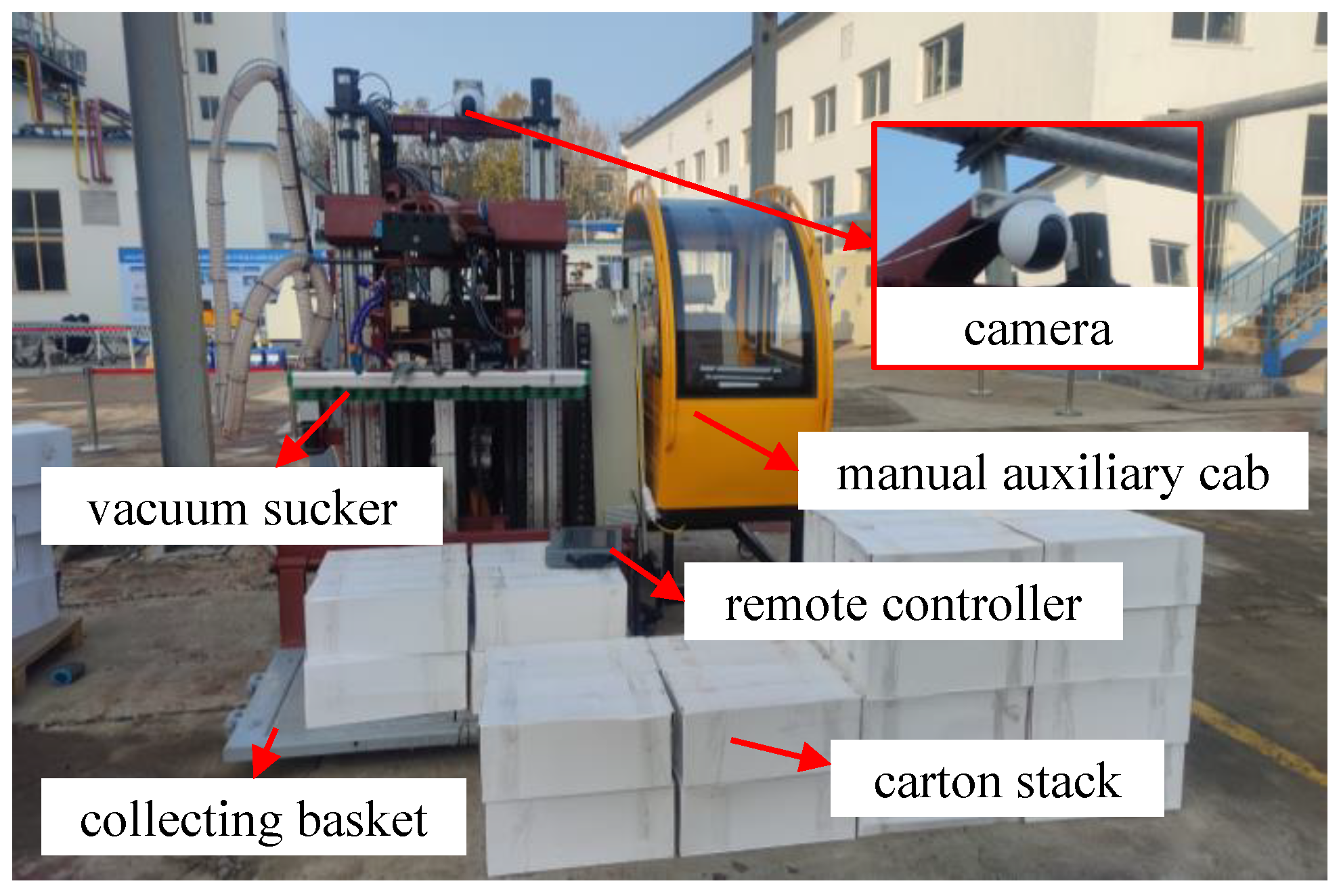
4.1. Experimental Settings
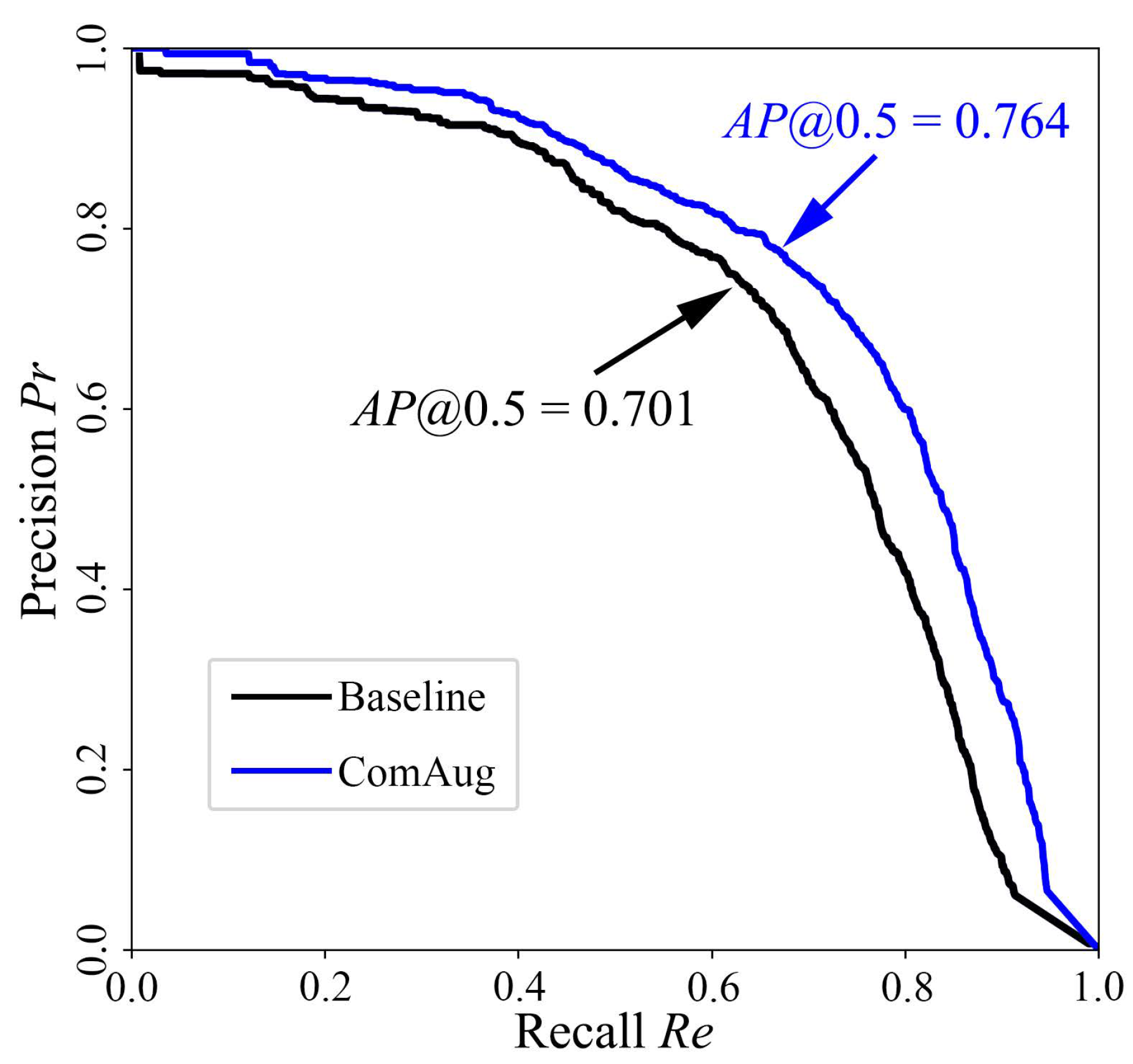
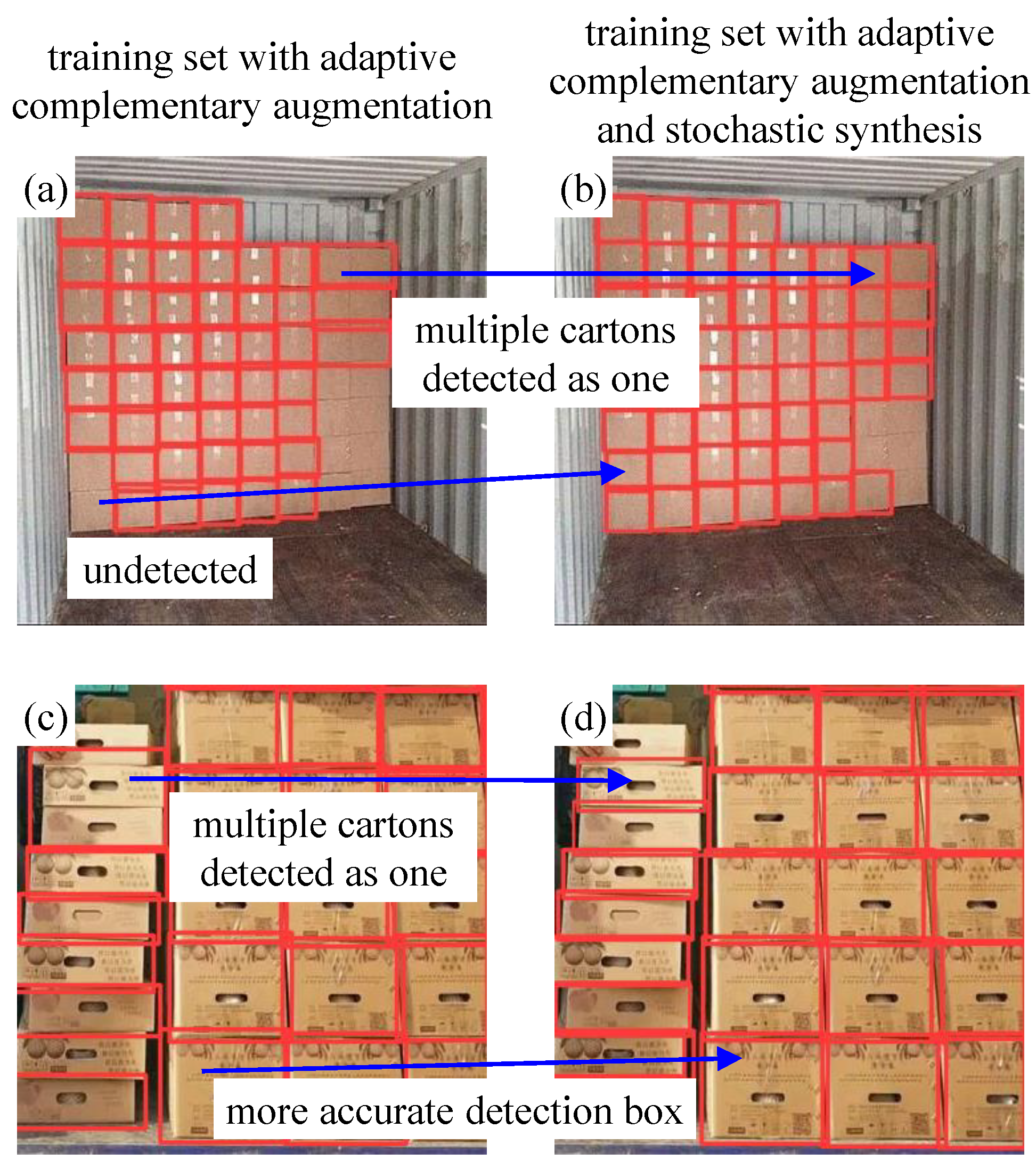
4.2. Adaptive Complementary Augmentation
4.3. Stochastic Synthesis
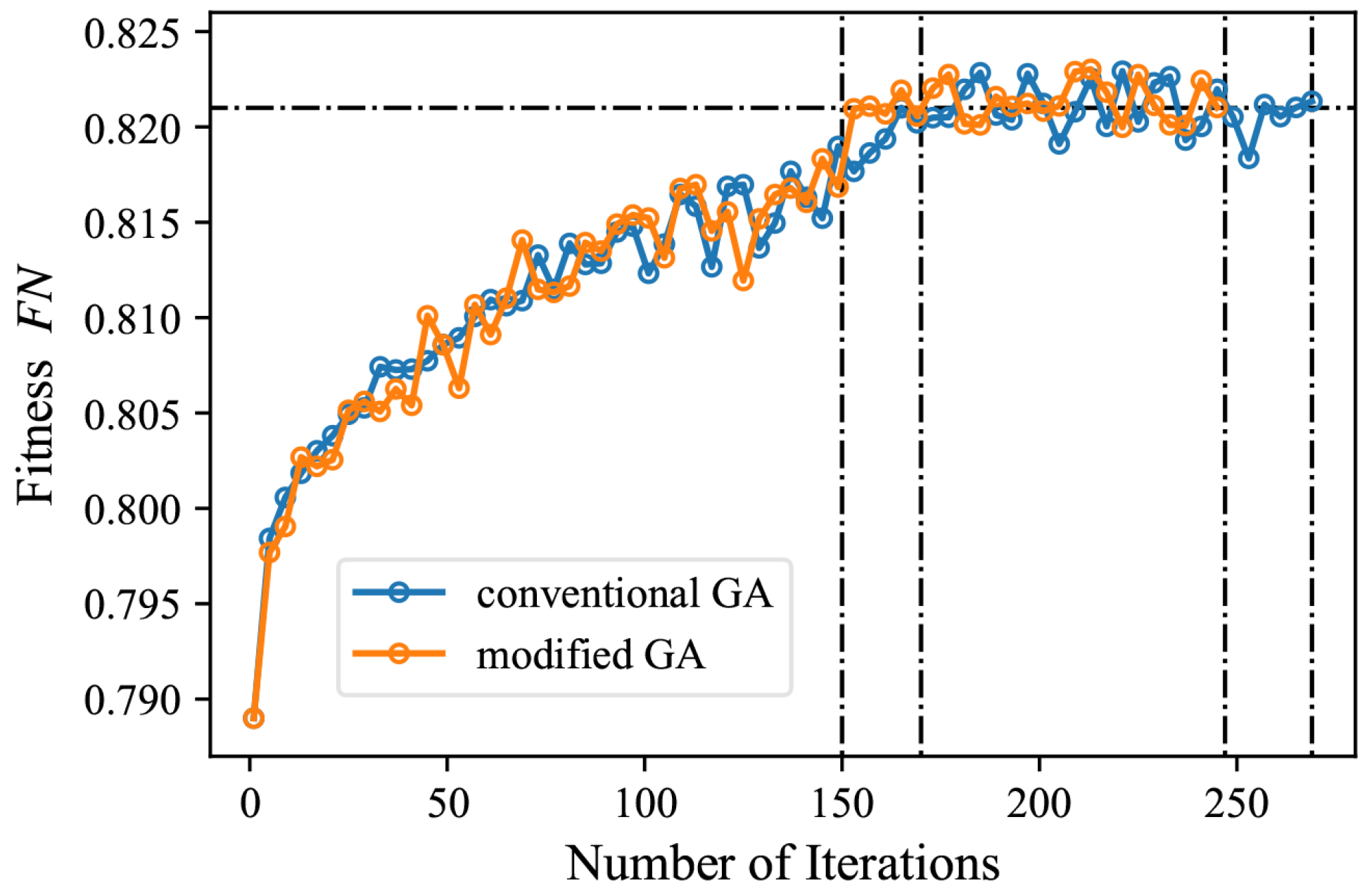
4.4. Hyperparameters Optimization
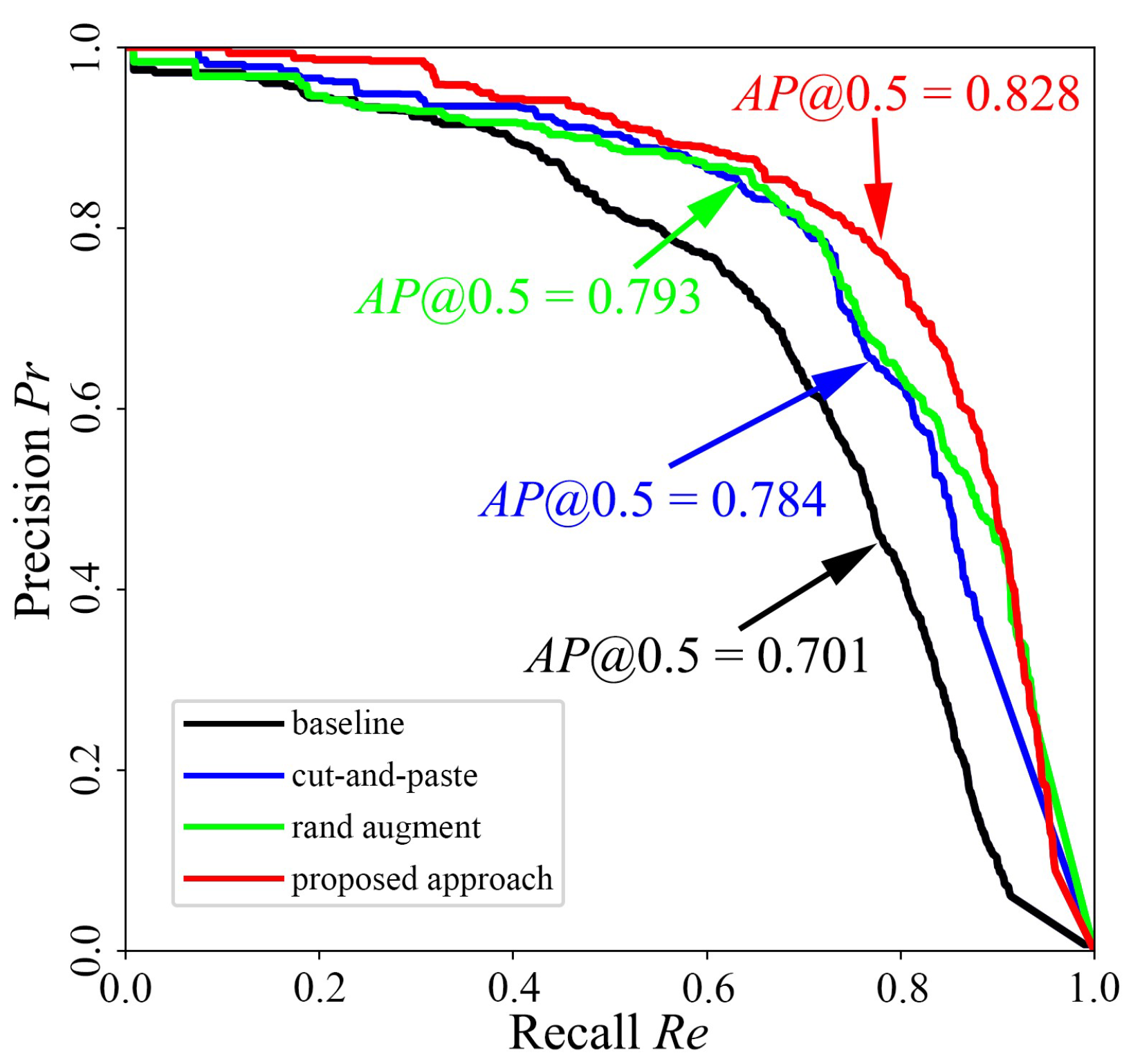
4.5. Analysis of Carton Detection Precision
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arpenti, P.; Caccavale, R.; Paduano, G.; Andrea Fontanelli, G.; Lippiello, V.; Villani, L.; Siciliano, B. RGB-D recognition and localization of cases for robotic depalletizing in supermarkets. IEEE Robot. Autom. Lett. 2020, 5, 6233–6238. [Google Scholar] [CrossRef]
- Chiaravalli, D.; Palli, G.; Monica, R.; Aleotti, J.; Rizzini, D.L. Integration of a multi-camera vision system and admittance control for robotic industrial depalletizing. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; pp. 667–674. [Google Scholar] [CrossRef]
- Passos, W.L.; Barreto, C.d.S.; Araujo, G.M.; Haque, U.; Netto, S.L.; da Silva, E.A.B. Toward improved surveillance of Aedes aegypti breeding grounds through artificially augmented data. Eng. Appl. Artif. Intell. 2023, 123, 106488. [Google Scholar] [CrossRef]
- Cui, Z.; Wang, X.; Liu, N.; Cao, Z.; Yang, J. Ship detection in large-scale SAR images Via spatial shuffle-group enhance attention. IEEE Trans. Geosci. Remote Sens. 2021, 59, 379–391. [Google Scholar] [CrossRef]
- Mushtaq, F.; Ramesh, K.; Deshmukh, S.; Ray, T.; Parimi, C.; Tandon, P.; Jha, P.K. Nuts&bolts: YOLO-v5 and image processing based component identification system. Eng. Appl. Artif. Intell. 2023, 118, 105665. [Google Scholar] [CrossRef]
- Elad, M.; Milanfar, P. Style transfer via texture synthesis. IEEE Trans. Image Process. 2017, 26, 2338–2351. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Wang, Y.; Wei, X.; Tang, X.; Shen, H.; Ding, L. CNN tracking based on data augmentation. Knowl.-Based Syst. 2020, 194, 105594. [Google Scholar] [CrossRef]
- Huang, H.; Zhou, H.; Yang, X.; Zhang, L.; Qi, L.; Zang, A.Y. Faster R-CNN for marine organisms detection and recognition using data augmentation. Neurocomputing 2019, 337, 372–384. [Google Scholar] [CrossRef]
- Chen, T.; Wang, N.; Wang, R.; Zhao, H.; Zhang, G. One-stage CNN detector-based benthonic organisms detection with limited training dataset. Neural Netw. 2021, 144, 247–259. [Google Scholar] [CrossRef]
- Park, S.; Lee, S.-b.; Park, J. Data augmentation method for improving the accuracy of human pose estimation with cropped images. Pattern Recognit. Lett. 2020, 136, 244–250. [Google Scholar] [CrossRef]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, paste and learn: Surprisingly easy synthesis for instance detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1310–1319. [Google Scholar] [CrossRef]
- Liu, S.; Guo, H.; Hu, J.G.; Zhao, X.; Zhao, C.; Wang, T.; Zhu, Y.; Wang, J.; Tang, M. A novel data augmentation scheme for pedestrian detection with attribute preserving GAN. Neurocomputing 2020, 401, 123–132. [Google Scholar] [CrossRef]
- Tripathi, S.; Chandra, S.; Agrawal, A.; Tyagi, A.; Rehg, J.M.; Chari, V. Learning to generate synthetic data via compositing. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 461–470. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Zhan, J.; Tan, L.; Gao, Y.; Zupan, R. Comparison of two deep learning methods for ship target recognition with optical remotely sensed data. Neural Comput. Appl. 2021, 33, 4639–4649. [Google Scholar] [CrossRef]
- Sun, Y.; Su, L.; Luo, Y.; Meng, H.; Li, W.; Zhang, Z.; Wang, P.; Zhang, W. Global mask R-CNN for marine ship instance segmentation. Neurocomputing 2022, 480, 257–270. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Li, Y.; Bai, X.; Xia, C. An Improved YOLOV5 Based on Triplet Attention and Prediction Head Optimization for Marine Organism Detection on Underwater Mobile Platforms. J. Mar. Sci. Eng. 2022, 10, 1230. [Google Scholar] [CrossRef]
- Zheng, R.; Zhou, Q.; Wang, C. Inland river ship auxiliary collision avoidance system. In Proceedings of the 2019 18th International Symposium on Distributed Computing and Applications for Business Engineering and Science (DCABES), Wuhan, China, 8–10 November 2019; pp. 56–59. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mané, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 3008–3017. [Google Scholar] [CrossRef]
- Qais, M.H.; Hasanien, H.M.; Alghuwainem, S. Augmented grey wolf optimizer for grid-connected PMSG-based wind energy conversion systems. Appl. Soft. Comput. 2018, 69, 504–515. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Georgakis, G.; Mousavian, A.; Berg, A.C.; Kosecka, J. Synthesizing training data for object detection in indoor scenes. In Proceedings of the 13th Conference on Robotics—Science and Systems, Cambridge, MA, USA, 12–16 July 2017. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2917–2927. [Google Scholar] [CrossRef]
- Gou, L.; Wu, S.; Yang, J.; Yu, H.; Lin, C.; Li, X.; Deng, C. Carton dataset synthesis method for loading-and-unloading carton detection based on deep learning. Int. J. Adv. Manuf. Technol. 2023, 124, 3049–3066. [Google Scholar] [CrossRef]
- Yang, J.; Wu, S.; Gou, L.; Yu, H.; Lin, C.; Wang, J.; Wang, P.; Li, M.; Li, X. SCD: A Stacked Carton Dataset for Detection and Segmentation. Sensors 2022, 22, 3617. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Carton Dataset | Training Set | Testing Set |
|---|---|---|---|
| “day” | 817 (81.7%) | 694 | 123 |
| “night” | 82 (8.2%) | 70 | 12 |
| “fog” | 101 (10.1%) | 86 | 15 |
| ALL | 1000 | 850 | 150 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, B.; Wang, X.; Zhao, W.; Wang, X. High-Precision Carton Detection Based on Adaptive Image Augmentation for Unmanned Cargo Handling Tasks. Sensors 2024, 24, 12. https://doi.org/10.3390/s24010012
Liang B, Wang X, Zhao W, Wang X. High-Precision Carton Detection Based on Adaptive Image Augmentation for Unmanned Cargo Handling Tasks. Sensors. 2024; 24(1):12. https://doi.org/10.3390/s24010012
Chicago/Turabian StyleLiang, Bing, Xin Wang, Wenhao Zhao, and Xiaobang Wang. 2024. "High-Precision Carton Detection Based on Adaptive Image Augmentation for Unmanned Cargo Handling Tasks" Sensors 24, no. 1: 12. https://doi.org/10.3390/s24010012