
SM2-Based Offline/Online Efficient Data Integrity Verification Scheme for Multiple Application Scenarios

Abstract
:1. Introduction
- (1)
- Public auditing: anyone can perform the audit. Generally, experienced and skilled TPAs are entrusted by the users to perform the audit task.
- (2)
- Dynamic updating of cloud data: users can insert, delete, and modify the data stored in the cloud at any time.
- (3)
- Privacy protection: the TPA cannot know the contents of the user data. It is also preferable that CSP should not know the contents of the user data.
- (4)
- Lightweight computation: the users’ computational overhead should be as small as possible.
- (5)
- Batch audits for multiple users: the most appropriate scheme is able to implement batch audits for multi-user data.
2. Related Works
- (1)
- Based on the SM2 signature algorithm and the SM4 block encryption algorithm, we have constructed an offline/online remote data audit scheme. The scheme supports dynamic data updates, comprehensive privacy protection, and batch audit capability. Based on the advantages of offline tags and scheme design, our scheme has low computational overheads and is suitable for lightweight environments.
- (2)
- We have carried out a security analysis and proof of the scheme. The scheme is resistant to forgery attacks from the storage side and achieves comprehensive privacy protection; even the storage side cannot obtain the real content of the data.
- (3)
- We analyzed the scheme’s efficiency and compared the functions and computing costs with the existing schemes, proving the comprehensiveness of the scheme’s functions and its high efficiency.
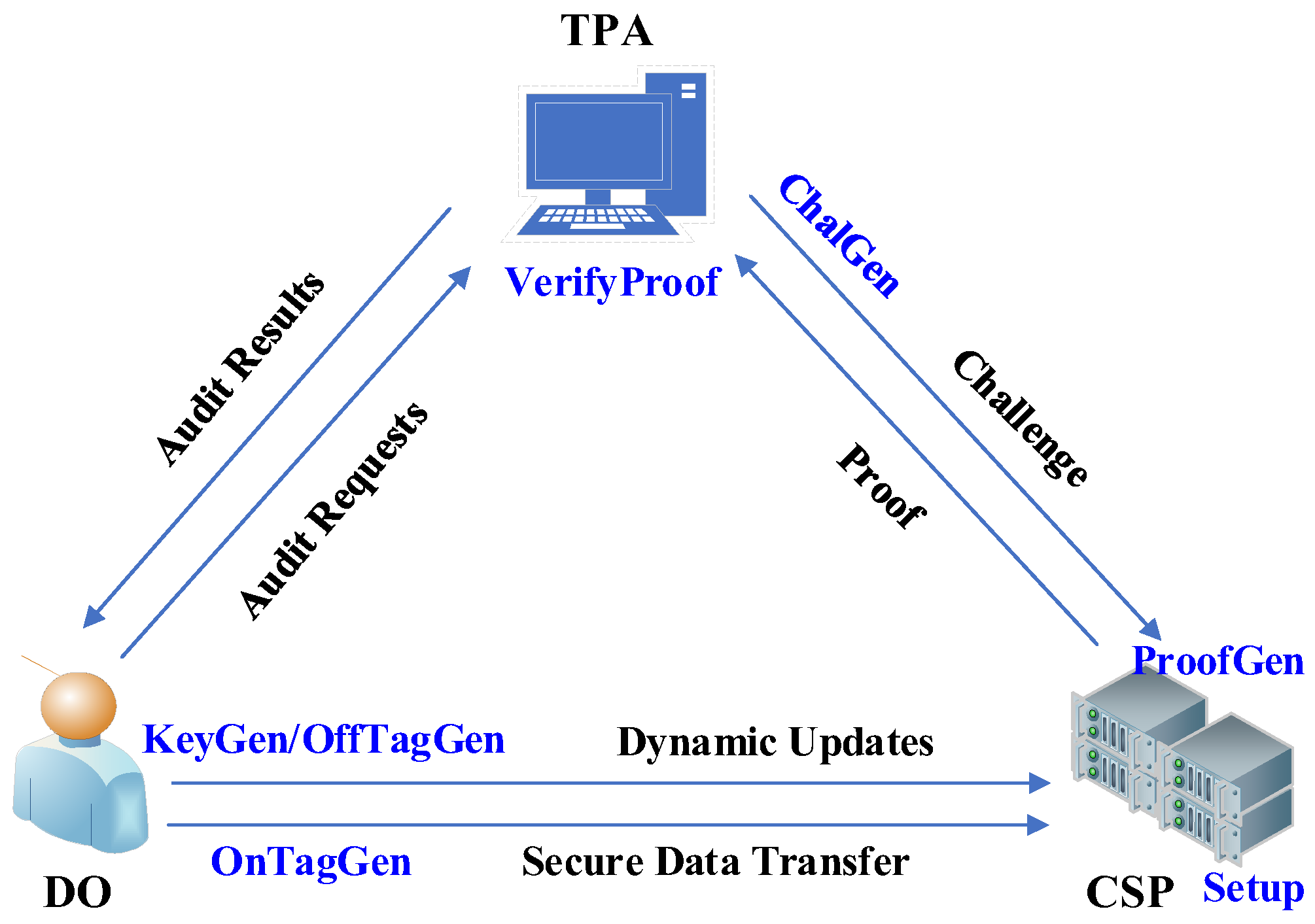
3. The System Model and Security Model
3.1. System Model
- (1)
- Setup: the CSP runs the algorithm, which inputs the security parameter, , and generates the public parameters .
- (2)
- KeyGen: the DO runs the algorithm, which outputs the private key, , and the public key, .
- (3)
- OffTagGen: the DO runs the algorithm, which inputs and the random numbers , , outputting the offline tags, .
- (4)
- OnTagGen: the DO runs the algorithm, which inputs and data blocks , then outputs the online tags .
- (5)
- ChalGen: the TPA runs the algorithm, which inputs the random number and outputs the indexes, .
- (6)
- ProofGen: the CSP runs the algorithm, which inputs the and outputs the proof .
- (7)
- VerifyProof: the TPA runs the algorithm, which inputs the proof and outputs “true” or “false” to indicate the integrity of the data.
3.2. Security Model
- (1)
- Public key query: When queries the public key of , runs the algorithm to generate and returns to .
- (2)
- Private key query: When queries the public key of , runs the algorithm to generate and returns to .
- (3)
- Tags query: can obtain the tag of under the public key of .
4. Preliminaries
4.1. Chinese Commercial Cryptography Algorithm
- (1)
- Key generation: the selected elliptic curve equation is . Let be the base point on the elliptic curve; the integer is randomly selected as the private key, then the public key is calculated.
- (2)
- Signature: Let the data to be signed be . The signer first selects a random integer , sets , and computes , ; the signature of the message is .
- (3)
- Verification: After receiving and , the verifier calculates , , and . If the values of and are equal, the signature is correct.
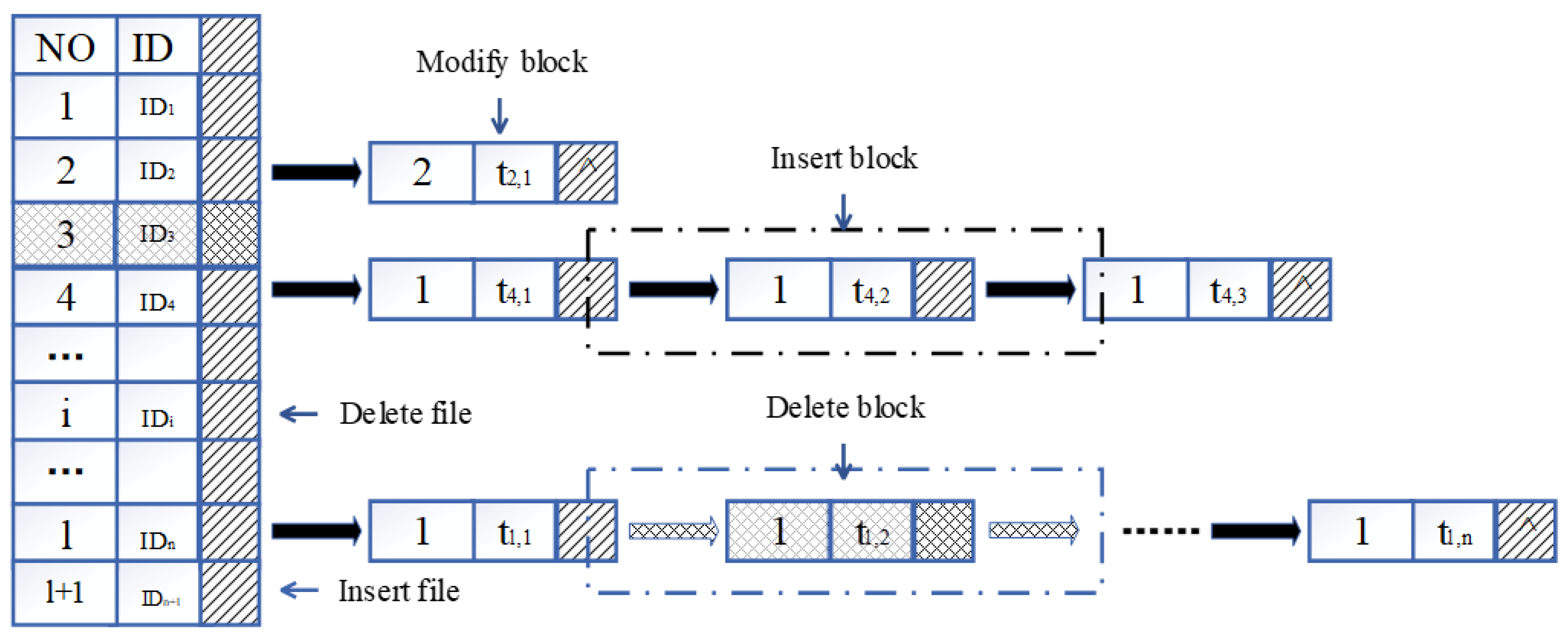
4.2. Dynamic Hash Table
4.3. Elliptic Curve Discrete Logarithm Problem
5. SM2-Based Offline/Online Efficient Data Integrity Verification Scheme
- (1)
- : the CSP inputs the security parameter and generates the public parameters . is the elliptic curve, and are large prime numbers, is an additive cyclic group of order defined on , and is the generator of the group, .
- (2)
- : the DO randomly selects as the private key and calculates as the public key.
- (3)
- : we set the number of blocks for the file to , and the block processing can improve the calculation efficiency and realize sampling verification. The DO randomly selects , calculates , and sets the coordinates of to . For , the DO calculates:and obtains the offline tag .
- (4)
- : the DO uses the SM4 block cipher algorithm to encrypt the data file with identity , and then divides into blocks as , for each data block . The DO generates the corresponding timestamp and version number , and calculates:
- (5)
- : the TPA selects the random number and sends it to the cloud server. Both parties take as input, run the same pseudo-random function, , and obtain the random numbers in as the indexes of the challenged data blocks.
- (6)
- : after the CSP receives the audit request and generates the indexes of the challenged data blocks, it calculates , , and , and sends the proof to the TPA as the proof of data possession.
- (7)
- : the TPA receives the proof , calculates ,, , and verifies whether the following equations hold:
- (8)
- : our scheme enables dynamic update operations on the cloud data, including insertion, deletion, and modification. Since the number of data blocks involved in the dynamic update is small, offline tags are not required in the dynamic update process. When a data block, , needs to be modified to , the DO selects a random number, , to calculate , where the coordinate of is set to . Then, and are generated for the data block , and the tags and are calculated. Finally, and are sent to the CSP and TPA, respectively. After receiving , the TPA finds the -th node of the linked list corresponding to the file in the dynamic hash table, and then replaces and with and . After receiving , the CSP finds the location of and replaces , , with , , .
- (9)
- : the scheme can implement a batch audit for multi-user cloud data. Each DO randomly selects the private key, , and calculates the public key,. The DO randomly selects , calculates , and sets the coordinates of to for , calculates:, , and obtains the offline tag . The DO uses the SM4 block cipher algorithm to encrypt the data file with the identity, , and then divides into blocks, expressed as ; for each data block , the DO generates the corresponding timestamp and version number , and calculates: , , as the online tag , then sends to the CSP, sends to the TPA, and finally deletes the local data. The TPA selects a random number as the parameter of and sends it to the CSP. Both sides run the same pseudo-random function, , and obtain the random number as the index of the challenged data block. After the CSP generates the indexes of the challenged data blocks, it calculates ,, and , then will be sent to the TPA as the proof. The TPA receives the proof, computes , , and , and verifies the following equations:
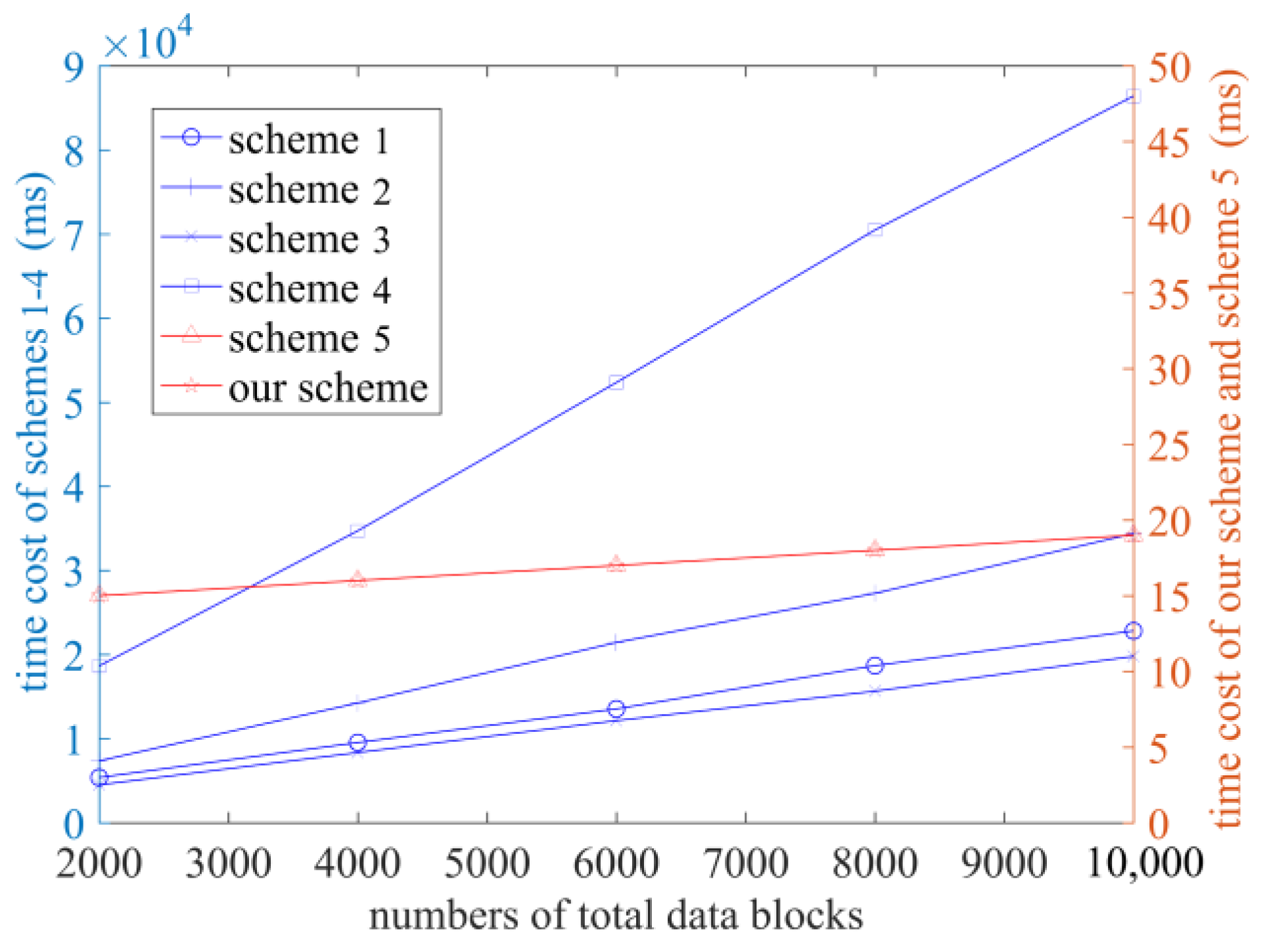
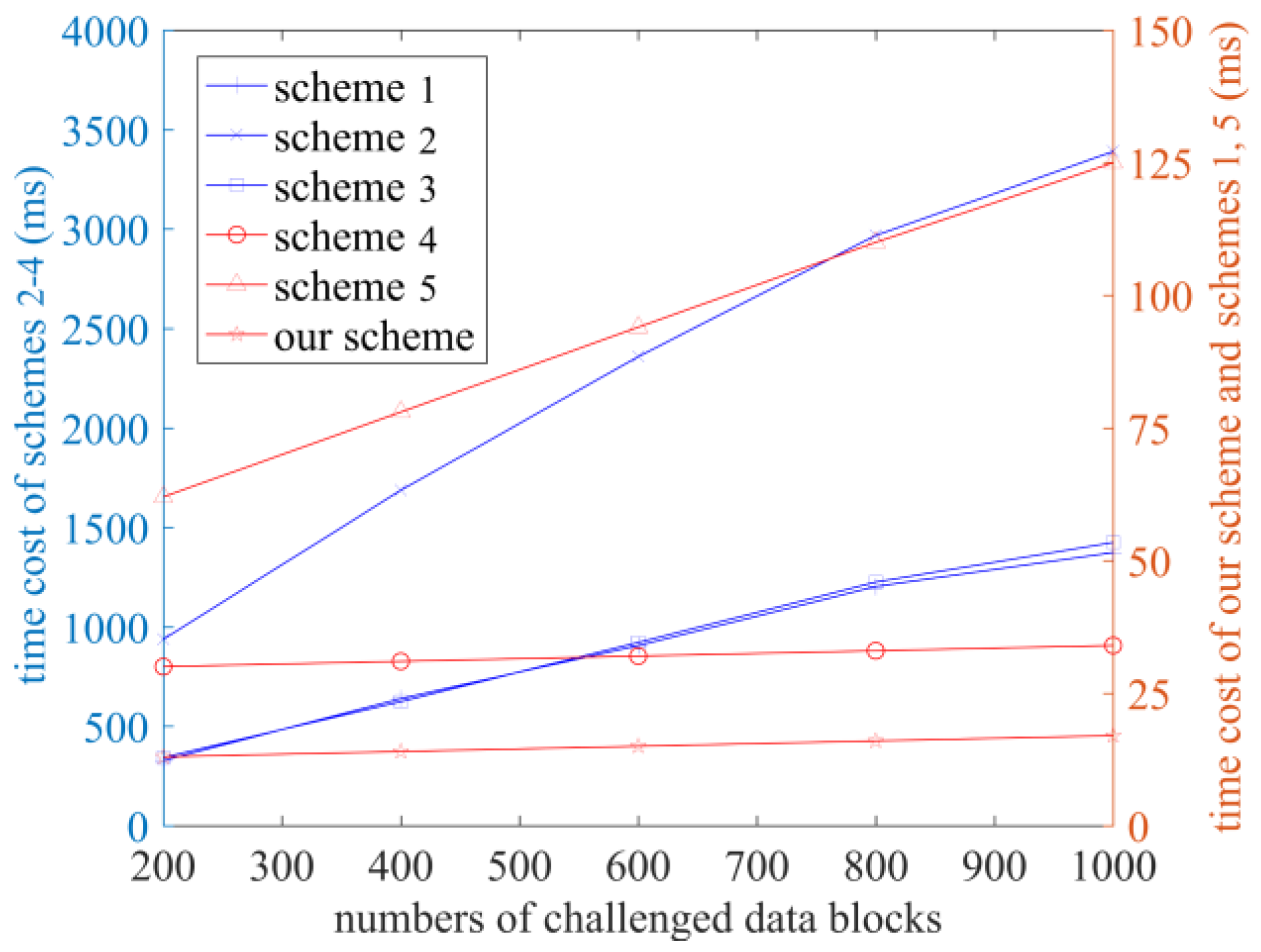
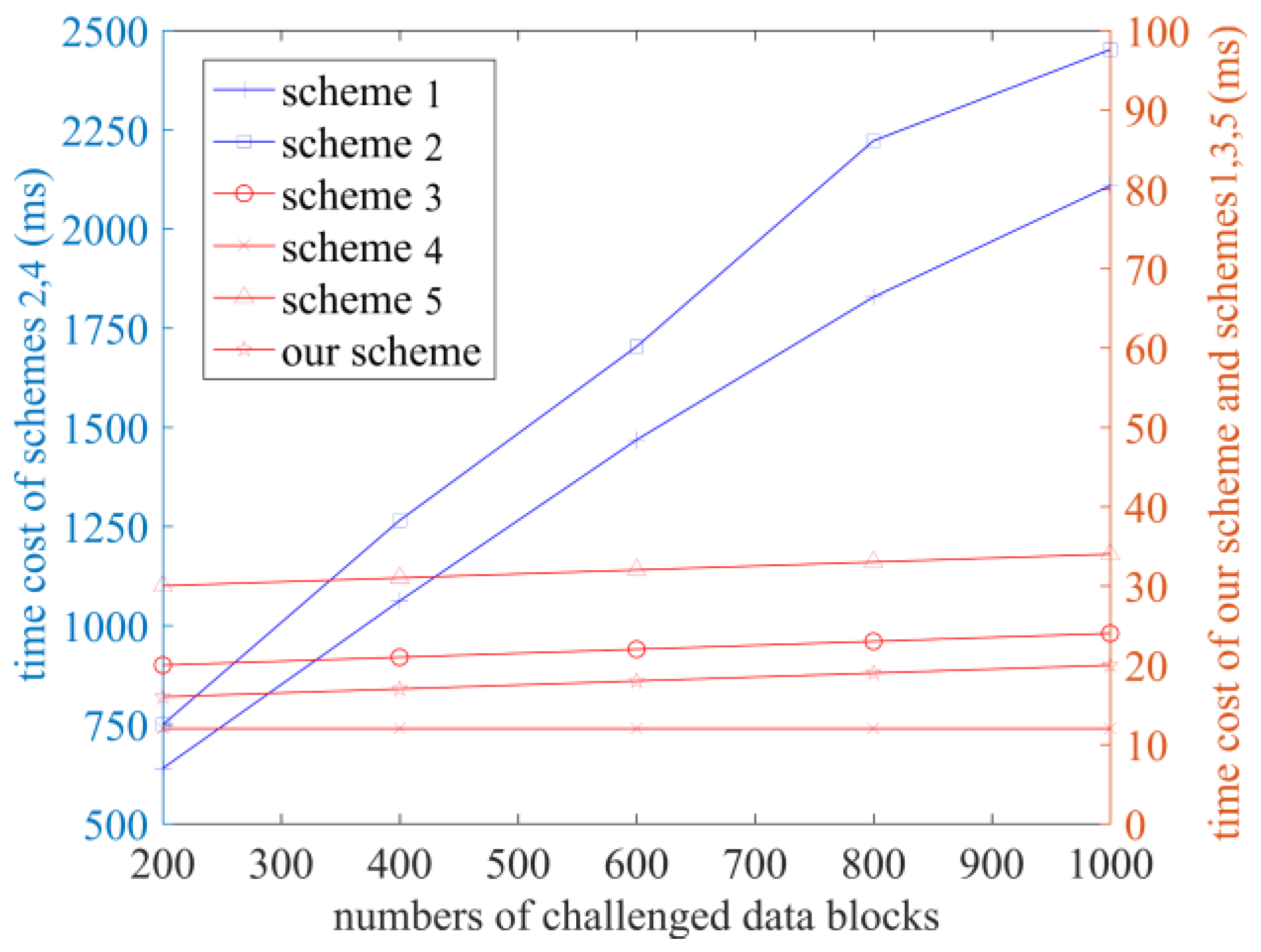
6. Performance Analysis
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Ji, Y.; Shao, B.; Chang, J.; Bian, G. Flexible identity-based remote data integrity checking for cloud storage with privacy preserving property. Clust. Comput. 2021, 25, 337–349. [Google Scholar] [CrossRef]
- Gudeme, J.R.; Pasupuleti, S.; Kandukuri, R. Certificateless Privacy Preserving Public Auditing for Dynamic Shared Data with Group User Revocation in Cloud Storage. J. Parallel Distrib. Comput. 2021, 156, 163–175. [Google Scholar] [CrossRef]
- Li, J.; Yan, H.; Zhang, Y. Certificateless Public Integrity Checking of Group Shared Data on Cloud Storage. IEEE Trans. Serv. Comput. 2021, 14, 71–81. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, Z.; Xiong, J.; Chen, L.; Ma, J.; Peng, C. Achieving graph clustering privacy preservation based on structure entropy in social IoT. IEEE Internet Things J. 2022, 9, 2761–2777. [Google Scholar] [CrossRef]
- Li, Q.; Xia, B.; Huang, H.; Zhang, Y.; Zhang, T. TRAC: Traceable and Revocable Access Control Scheme for mHealth in 5G-enabled IIoT. IEEE Trans. Ind. Inform. 2021, 18, 3437–3448. [Google Scholar] [CrossRef]
- Xiong, J.; Ma, R.; Chen, L.; Tian, Y.; Li, Q.; Liu, X.; Yao, Z. A personalized privacy protection framework for mobile crowdsensing in IIoT. IEEE Trans. Ind. Inform. 2020, 16, 4231–4241. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, C.; Zhang, Y.; Zhang, J.; Gong, J. LDVAS: Lattice-Based Designated Verifier Auditing Scheme for Electronic Medical Data in Cloud-Assisted WBANs. IEEE Access 2020, 8, 54402–54414. [Google Scholar] [CrossRef]
- Ateniese, G.; Burns, R.; Curtmola, R.; Herring, J.; Kissner, L.; Peterson, Z.; Song, D. Provable Data Possession at Untrusted Stores. In Proceedings of the 14th ACM Conference on Computer and Communications Security (CCS ‘07), Alexandria, VA, USA, 29 October–2 November 2007; pp. 598–609. [Google Scholar]
- Juels, A.; Kaliski, B.S. Pors: Proofs of retrievability for large files. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 29 October–2 November 2007; pp. 584–597. [Google Scholar]
- Guo, W.; Zhang, H.; Qin, S.; Gao, F.; Jin, Z.; Li, W.; Wen, Q. Outsourced Dynamic Provable Data Possession with Batch Update for Secure Cloud Storage. Future Gener. Comput. Syst. 2019, 95, 309–322. [Google Scholar] [CrossRef]
- Hou, G.; Ma, J.; Liang, C.; Li, J. Efficient Audit Protocol Supporting Virtual Nodes in Cloud Storage. Trans. Emerg. Telecommun. Technol. 2020, 32, e3911. [Google Scholar] [CrossRef]
- Mishra, R.; Ramesh, D.; Edla, D.R. BB-tree based secure and dynamic public auditing convergence for cloud storage. J. Supercomput. 2020, 77, 4917–4956. [Google Scholar] [CrossRef]
- Fan, K.; Li, F.; Yu, H.; Yang, Z. A Blockchain-Based Flexible Data Auditing Scheme for the Cloud Service. Chin. J. Electron. 2021, 30, 1159–1166. [Google Scholar]
- Rabaninejad, R.; Asaar, M.R.; Attari, M.A.; Aref, M. An identity-based online/offline secure cloud storage auditing scheme. Clust. Comput. 2020, 23, 1455–1468. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, Y.; Chen, F.; Chen, J. An Efficient Identity-Based Provable Data Possession Protocol with Compressed Cloud Storage. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1359–1371. [Google Scholar] [CrossRef]
- Li, S.; Xu, C.; Zhang, Y.; Du, Y.; Chen, K. Blockchain-Based Transparent Integrity Auditing and Encrypted Deduplication for Cloud Storage. IEEE Trans. Serv. Comput. 2023, 16, 134–146. [Google Scholar] [CrossRef]
- Ji, Y.; Shao, B.; Chang, J.; Xu, M.; Xue, R. Identity-based remote data checking with a designated verifier. J. Cloud Comput. 2022, 11, 7. [Google Scholar] [CrossRef]
- Li, S.; Han, J.; Tong, D.; Cui, J. Redactable Signature-Based Public Auditing Scheme with Sensitive Data Sharing for Cloud Storage. IEEE Syst. J. 2022, 16, 3613–3624. [Google Scholar] [CrossRef]
- Lin, Y.; Li, J.; Kimura, S.; Yang, Y.; Ji, Y.; Cao, Y. Consortium Blockchain-Based Public Integrity Verification in Cloud Storage for IoT. IEEE Internet Things J. 2022, 9, 3978–3987. [Google Scholar] [CrossRef]
- Yang, A.; Nam, J.; Kim, M.; Choo, K.K.R. Provably-Secure (Chinese Government) SM2 and Simplified SM2 Key Exchange Protocols. Sci. World J. 2014, 2014, 825984. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Wu, L.; Zhang, X. Key-leakage hardware Trojan with super concealment based on the fault injection for block cipher of SM4. Electron. Lett. 2018, 54, 810–812. [Google Scholar] [CrossRef]
- Yan, J.; Lu, Y.; Chen, L.; Nie, W. A SM2 Elliptic Curve Threshold Signature Scheme without a Trusted Center. KSII Trans. Internet Inf. Syst. (TIIS) 2016, 10, 897–913. [Google Scholar]
- Tian, H.; Chen, Y.; Chang, C.; Jiang, H.; Huang, Y.; Chen, Y.; Liu, J. Dynamic-Hash-Table Based Public Auditing for Secure Cloud Storage. IEEE Trans. Serv. Comput. 2017, 10, 701–714. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Descriptions |
|---|---|
| The system initialization parameter. | |
| The elliptic curve. | |
| The additive cyclic group. | |
| A large prime number. | |
| . | |
| The user’s secret key. | |
| The user’s public key. | |
| The prime field. | |
| Random numbers. | |
| , | Intermediate parameters. |
| Offline tags. | |
| The user’s data file. | |
| data blocks. | |
| The identity of the file. | |
| Online tags. | |
| . | |
| . | |
| The number of total data blocks. | |
| The number of challenged blocks. | |
| The pseudo-random function. | |
| . | |
| . | |
| The proof of data possession. |
| Symbols | Description | Time Cost/ms |
|---|---|---|
| computational cost of an addition on | 0.0003 | |
| computational cost of a multiplication on | 0.0006 | |
| computational cost of an exponentiation on | 0.0226 | |
| computational cost of an addition on | 0.0055 | |
| computational cost of a doubling on | 0.7179 | |
| computational cost of a multiplication on | 0.0511 | |
| computational cost of a hash operation to | 0.0002 | |
| computational cost of a hash operation to | 1.1268 | |
| computational cost of an exponentiation on | 0.8107 | |
| Bilinear pair operations | 5.8853 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Yi, Z.; Li, R.; Wang, X.-A.; Li, H.; Yang, X. SM2-Based Offline/Online Efficient Data Integrity Verification Scheme for Multiple Application Scenarios. Sensors 2023, 23, 4307. https://doi.org/10.3390/s23094307
Li X, Yi Z, Li R, Wang X-A, Li H, Yang X. SM2-Based Offline/Online Efficient Data Integrity Verification Scheme for Multiple Application Scenarios. Sensors. 2023; 23(9):4307. https://doi.org/10.3390/s23094307
Chicago/Turabian StyleLi, Xiuguang, Zhengge Yi, Ruifeng Li, Xu-An Wang, Hui Li, and Xiaoyuan Yang. 2023. "SM2-Based Offline/Online Efficient Data Integrity Verification Scheme for Multiple Application Scenarios" Sensors 23, no. 9: 4307. https://doi.org/10.3390/s23094307