
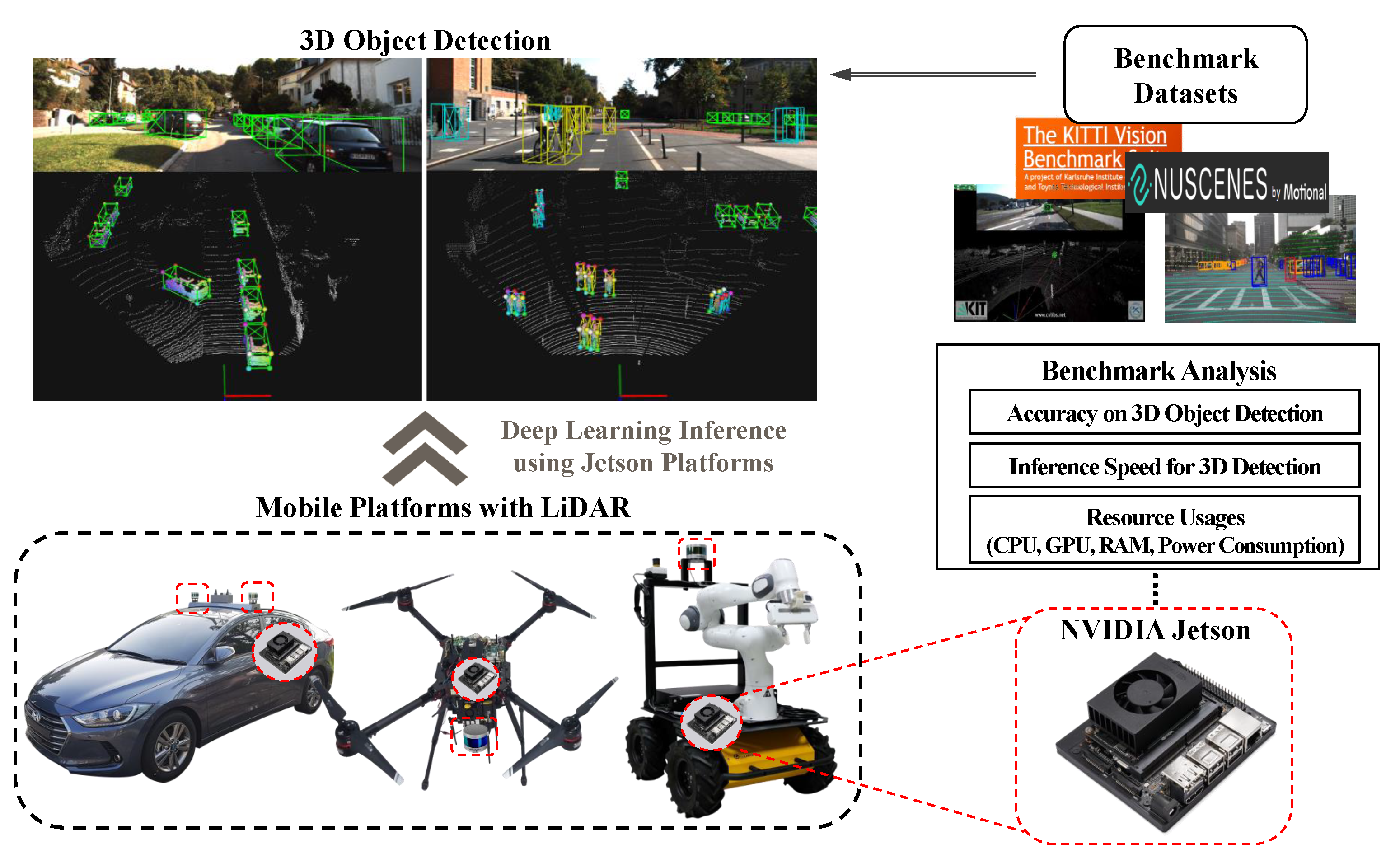
Run Your 3D Object Detector on NVIDIA Jetson Platforms:A Benchmark Analysis †


Abstract
:1. Introduction
- This paper presents extensive benchmarks of the NVIDIA Jetson platforms for a computationally expensive task, which is deep learning-based 3D object detection. Unlike image-based 2D object detection, which mostly depends on GPU resources, the 3D detection task presents a challenge for resource utilization since point cloud processing occupies considerable CPU and memory usage, and neural network processing highly relies on GPU-based computation. Thus, we conducted a thorough analysis of the performance and utilization to provide a guideline for users in choosing an appropriate platform and 3D object detector.
- We evaluated various 3D object detection frameworks with all commercially available Jetson platforms, including the lightest platform (Nano) and the most recent one (NX). We provide various metrics-based results, such as detection accuracy, FPS, and resource usage.
- In addition, we evaluated the effect of the TRT library [15] on optimizing deep learning models to enable fast inference on Jetson platforms. We investigated the impact of an optimization strategy on performance changes with resource usage.
2. Related Works
2.1. Deep Learning-Based 3D Object Detection
2.2. Applications and Benchmarks of Jetson Series
3. Preliminaries
3.1. NVIDIA Jetson Platforms
- Nano: This single board offers the opportunity to run simple deep-learning models by using a built-in GPU. However, it may suffer from the lack of memory resources when used for large-scale deep learning models.
- TX2: Jetson TX2 has been widely used for deep learning-based robotic applications owing to its better resources than those of Nano.
- Xavier NX: NX provides sufficient resources for deploying large-scale deep learning models. Moreover, NX is beneficial for various robotic systems with small payloads due to its light size and weight.
- AGX Xavier: This includes the most powerful hardware among the Jetson series. It could be suitable for industrial robots and drones that require many software functions for a mission.
3.2. Precision Analysis of Deep Learning-Based 3D Object Detection Frameworks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4. Benchmark Analysis
4.1. Setup
4.1.1. Environmental Setup
4.1.2. Default Setting for the Frameworks
4.2. Feasibility Check of the 3D Detectors
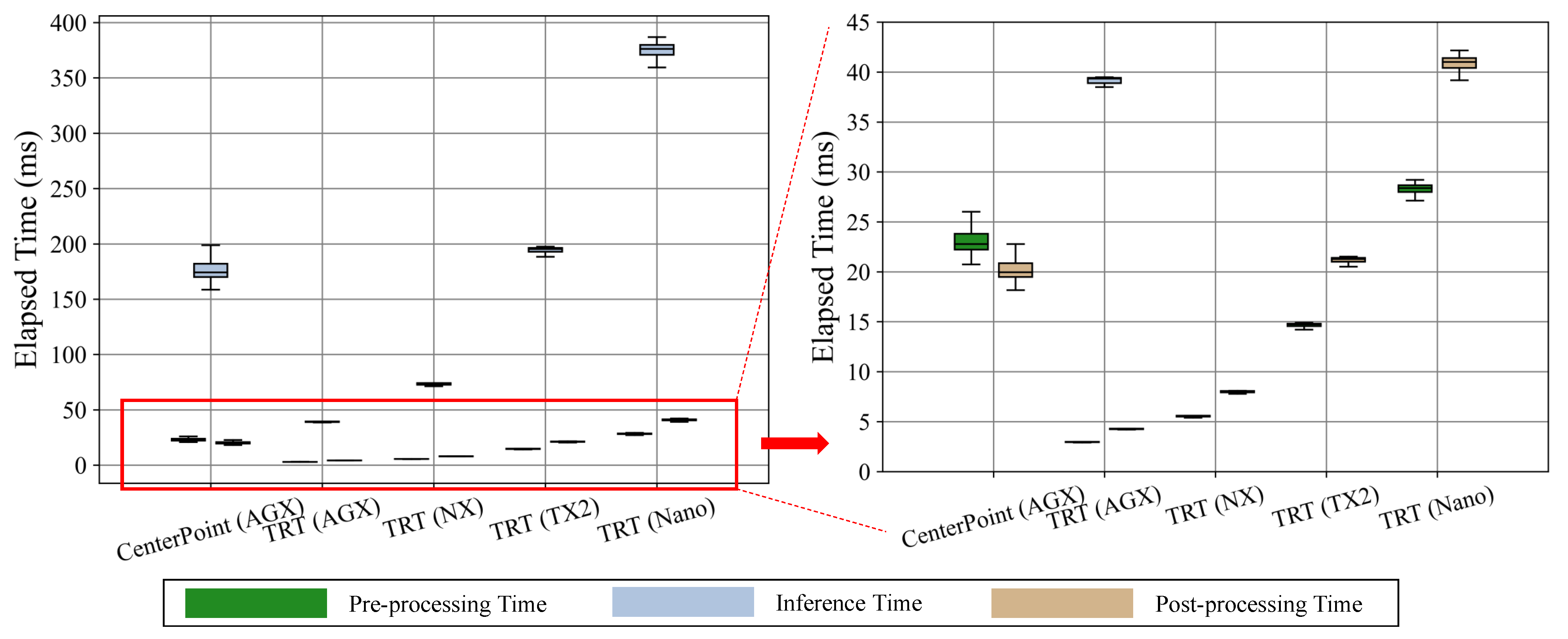
4.3. Analysis of Computational Speed
4.4. Analysis of Resource Usage and Power Consumption
4.5. Analysis of the Effect of TensorRT Library
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of Open Access Journals |
| TLA | three-letter acronym |
| LD | linear dichroism |
References
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3D object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef] [Green Version]
- Mittal, S. A Survey on optimized implementation of deep learning models on the NVIDIA Jetson platform. J. Syst. Archit. 2019, 97, 428–442. [Google Scholar] [CrossRef]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From points to parts: 3D object detection from point cloud with part-aware and part-aggregation network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef] [Green Version]
- Simony, M.; Milzy, S.; Amendey, K.; Gross, H.M. Complex-YOLO: An euler-region-proposal for real-time 3D object detection on point clouds. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for Point Cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Zheng, W.; Tang, W.; Chen, S.; Jiang, L.; Fu, C.W. CIA-SSD: Confident IoU-Aware Single-Stage Object Detector From Point Cloud. arXiv 2020, arXiv:2012.03015. [Google Scholar] [CrossRef]
- Zheng, W.; Tang, W.; Jiang, L.; Fu, C.W. SE-SSD: Self-Ensembling Single-Stage Object Detector From Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14494–14503. [Google Scholar]
- Süzen, A.A.; Duman, B.; Şen, B. Benchmark analysis of Jetson TX2, Jetson Nano and Raspberry Pi using Deep-CNN. In Proceedings of the 2020 International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 26–27 June 2020; pp. 1–5. [Google Scholar]
- Jo, J.; Jeong, S.; Kang, P. Benchmarking GPU-accelerated edge devices. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 117–120. [Google Scholar]
- Ullah, S.; Kim, D.H. Benchmarking Jetson platform for 3D point-cloud and hyper-spectral image classification. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 477–482. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Han, V. inference with tensorrt. In Proceedings of the GPU Technology Conference, San Jose, CA, USA, 4–7 April 2016; Volume 1, p. 2. [Google Scholar]
- Zhou, S.; Deng, X.; Li, C.; Liu, Y.; Jiang, H. Recognition-oriented image compressive sensing with deep learning. IEEE Trans. Multimed. 2022. Early Access. [Google Scholar] [CrossRef]
- Chen, Y.; Xia, R.; Zou, K.; Yang, K. FFTI: Image inpainting algorithm via features fusion and two-steps inpainting. J. Vis. Commun. Image Represent. 2023, 91, 103776. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Center-based 3D Object Detection and Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Bokovoy, A.; Muravyev, K.; Yakovlev, K. Real-time vision-based depth reconstruction with nvidia jetson. In Proceedings of the 2019 European Conference on Mobile Robots (ECMR), Bonn, Germany, 31 August–3 September 2019; pp. 1–6. [Google Scholar]
- Zhang, T.; Hu, X.; Xiao, J.; Zhang, G. TVENet: Transformer-based Visual Exploration Network for Mobile Robot in Unseen Environment. IEEE Access 2022, 10, 62056–62072. [Google Scholar] [CrossRef]
- Kortli, Y.; Gabsi, S.; Voon, L.F.L.Y.; Jridi, M.; Merzougui, M.; Atri, M. Deep embedded hybrid CNN–LSTM network for lane detection on NVIDIA Jetson Xavier NX. Knowl.-Based Syst. 2022, 240, 107941. [Google Scholar] [CrossRef]
- Jeon, J.; Jung, S.; Lee, E.; Choi, D.; Myung, H. Run your visual–inertial odometry on NVIDIA Jetson: Benchmark tests on a micro aerial vehicle. IEEE Robot. Autom. Lett. 2021, 6, 5332–5339. [Google Scholar] [CrossRef]
- Dzung, N.M. Complex YOLOv4. Available online: https://github.com/maudzung/Complex-YOLOv4-Pytorch (accessed on 13 September 2021).
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- CarkusL. CenterPoint-PonintPillars Pytroch Model Convert to ONNX and TensorRT. Available online: https://github.com/CarkusL/CenterPoint (accessed on 13 September 2021).
- Ghimire, D. Complex-YOLO-V3. Available online: https://github.com/ghimiredhikura/Complex-YOLOv3 (accessed on 13 September 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Bonghi, R. Jetson Stats. Available online: https://github.com/rbonghi/jetson_stats (accessed on 13 September 2021).






| Nano | TX2 | NX | AGX | |
|---|---|---|---|---|
| AI Core | 472 GFLOPs | 1.33 TFLOPs | 21 TOPs | 32 TOPs |
| CPU | 4-core Cortex A57 | 6-core Denver A57 | 6-core Carmel Arm | 8-core Carmel Arm |
| GPU | 128-core Maxwell | 256-core Pascal | 384-core Volta | 512-core Volta |
| Memory | 4 GB 64-bit LPDDR4 | 8 GB 128-bit LPDDR4 | 8 GB 128-bit LPDDR4 | 32 GB 256-bit LPDDR4 |
| Size (mm) | 100 × 80 × 29 | 50 × 110 × 37 | 100 × 90 × 32 | 105 × 105 × 65 |
| Power | 5 W (or 10 W) | 7.5 W (or 15 W) | 10W (or 15, 30 W) | 10 W (or 15, 30 W) |
| Weight | 100 g | 211 g | 184.5 g | 670 g |
| Type | Method | Car—AP (BEV) | Car—AP (3D) |
|---|---|---|---|
| Two-stage Detector | PointRCNN | 0.878 | 0.784 |
| Part- | 0.886 | 0.794 | |
| PV-RCNN | 0.879 | 0.836 | |
One-stage Detector | Complex-YOLOv3 (Tiny version) | 0.82 (0.673) | - |
| Complex-YOLOv4 (Tiny version) | 0.833 (0.68) | - | |
| SECOND | 0.837 | 0.756 | |
| PointPillar | 0.871 | 0.772 | |
| CIA-SSD | 0.867 | 0.761 | |
| SE-SSD | 0.883 | 0.792 |
| Type | Method | Nano | TX2 | NX | AGX |
|---|---|---|---|---|---|
Two-stage Detector | PointRCNN | X | X | ✓ | ✓ |
| Part- | X | X | ✓ | ✓ | |
| PV-RCNN | X | X | ✓ | ✓ | |
| CenterPoint (TRT version) | X (✓) | X (✓) | X (✓) | ✓ (✓) | |
One-stage Detector | Complex-YOLOv3 (Tiny version) | ✓ (✓) | ✓ (✓) | ✓ (✓) | ✓ (✓) |
| Complex-YOLOv4 (Tiny version) | ✓ (✓) | ✓ (✓) | ✓ (✓) | ✓ (✓) | |
| SECOND | X | X | ✓ | ✓ | |
| PointPillar | X | X | ✓ | ✓ | |
| CIA-SSD | X | X | ✓ | ✓ | |
| SE-SSD | X | X | ✓ | ✓ |
| Type | Method | Nano | TX2 | NX | AGX |
|---|---|---|---|---|---|
| Two-stage Detector | PointRCNN | - | - | ||
| Part- | - | - | |||
| PV-RCNN | - | - | |||
One-stage Detector | Complex-YOLOv3 (Tiny version) | () | () | () | () |
| Complex-YOLOv4 (Tiny version) | (7) | () | () | () | |
| SECOND | - | - | |||
| PointPillar | - | - | |||
| CIA-SSD | - | - | |||
| SE-SSD | - | - |
| Type | Method | Nano | TX2 | NX | AGX |
|---|---|---|---|---|---|
| Two-stage Detector | PointRCNN | - | - | ||
| Part- | - | - | |||
| PV-RCNN | - | - | |||
One-stage Detector | Complex-YOLOv3 (Tiny version) | () | () | () | () |
| Complex-YOLOv4 (Tiny version) | () | () | () | () | |
| SECOND | - | ||||
| PointPillar | - | - | |||
| CIA-SSD | - | - | |||
| SE-SSD | - | - |
| Method | Nano | TX2 | NX | AGX |
|---|---|---|---|---|
| CenterPoint | - | - | - | |
| CenterPoint-TRT |
| Method | Resource | Nano | TX2 | NX | AGX |
|---|---|---|---|---|---|
CenterPoint | CPU (%) | - | - | - | |
| Mem (%) | - | - | - | ||
| GPU (%) | - | - | - | ||
| Power (W) | - | - | - | ||
CenterPoint-TRT | CPU (%) | ||||
| Mem (%) | |||||
| GPU (%) | |||||
| Power (W) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choe, C.; Choe, M.; Jung, S. Run Your 3D Object Detector on NVIDIA Jetson Platforms:A Benchmark Analysis. Sensors 2023, 23, 4005. https://doi.org/10.3390/s23084005
Choe C, Choe M, Jung S. Run Your 3D Object Detector on NVIDIA Jetson Platforms:A Benchmark Analysis. Sensors. 2023; 23(8):4005. https://doi.org/10.3390/s23084005
Chicago/Turabian StyleChoe, Chungjae, Minjae Choe, and Sungwook Jung. 2023. "Run Your 3D Object Detector on NVIDIA Jetson Platforms:A Benchmark Analysis" Sensors 23, no. 8: 4005. https://doi.org/10.3390/s23084005