In this section, we analyze the actual needs of monocular cameras used for cross-country skiing motion recognition and describe the research methods proposed, including the algorithm framework, the target detection method, the three-dimensional pose estimation algorithm by two-dimensional joint detection, and the sub-motion recognition method.
3.1. Requirements and Analysis of Sub-Action
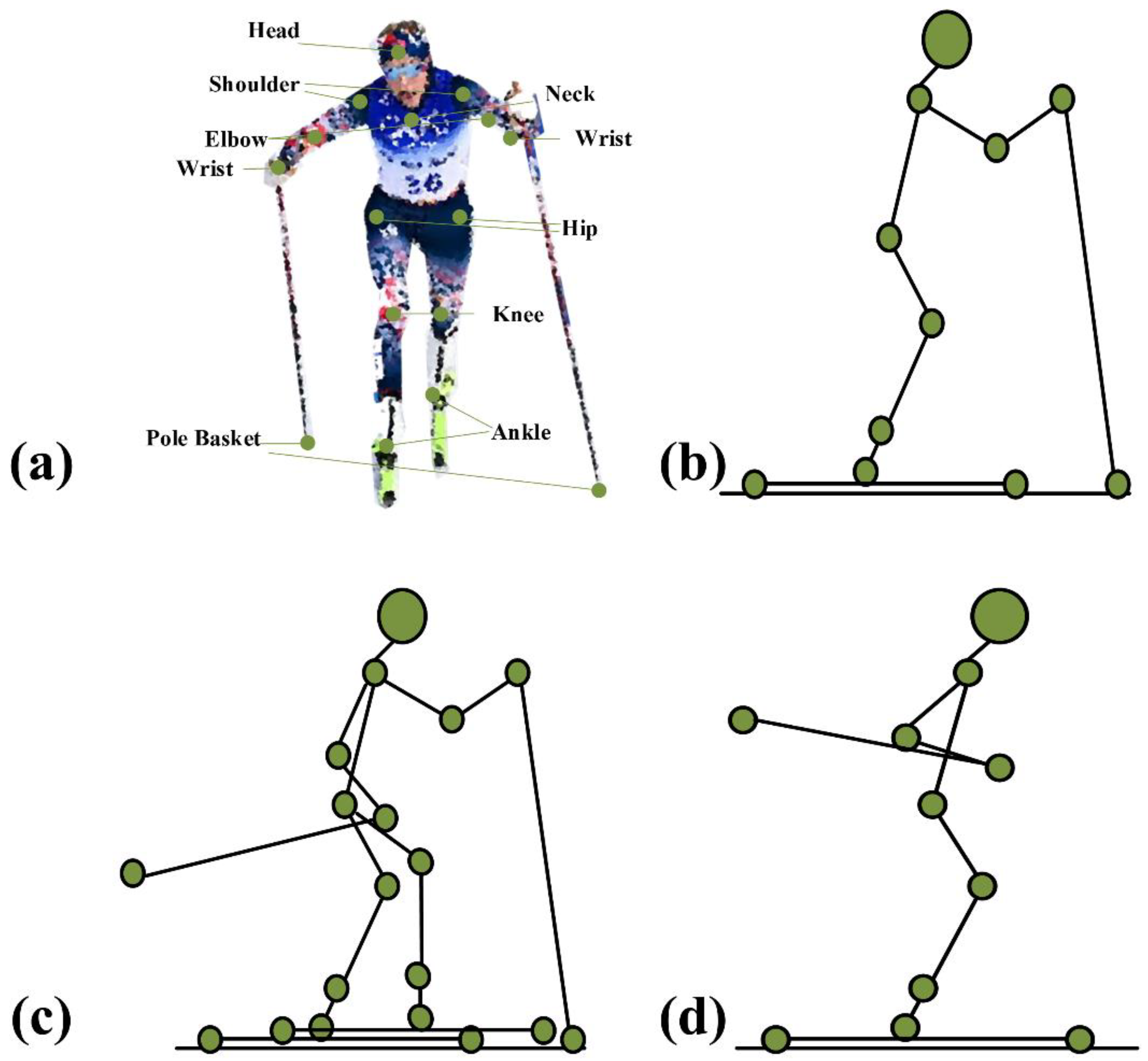
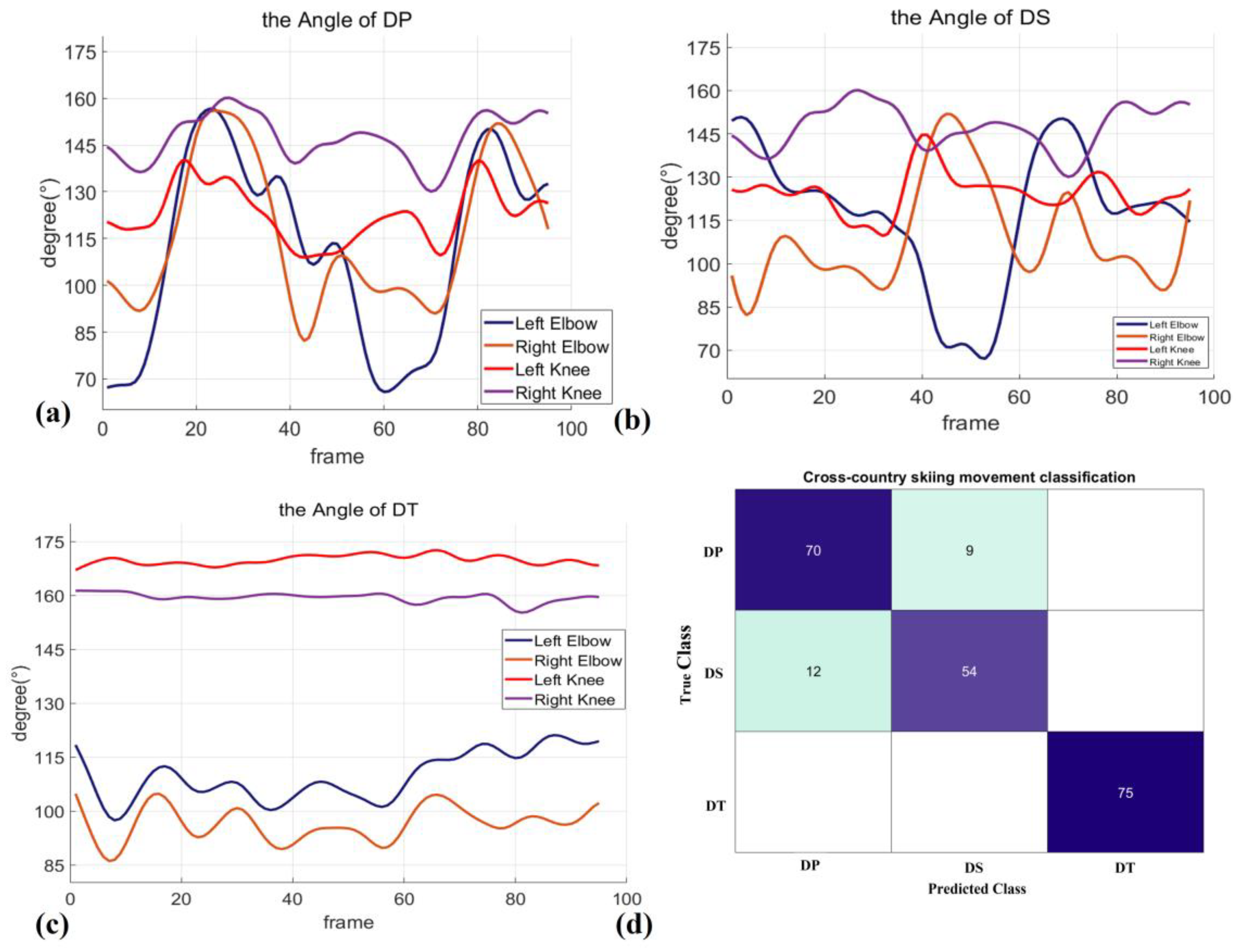
The first step is to analyze the real needs of scientific training in cross-country skiing. Cross-country skiing is essentially divided into three typical sub-actions. These sub-actions mainly include double poling (DP), diagonal striding (DS), and downhill techniques (DT) [
37]. The DP sub-action means the athletes slide the ski poles at the same time and the legs on both sides also move synchronously, as shown in
Figure 1b. During the DS action, the athletes’ poles are poled alternately, while the two legs move forward alternately, as shown in
Figure 1c. In DT, in
Figure 1d, the ski poles are clamped between the athlete’s arm and body to bend and tuck. The technical actions have a decisive impact on the competition results of skiing. The technical action selection, technical action cycle, and sliding rhythm of cross-country skiing will directly affect the performance of skiing in training and competition. The research shows that the changes in technical tactics and training strategies can significantly reduce the metabolic cost per meter of cross-country skiing [
38]. By optimizing performances under different terrains based on feedback, athletes can improve competition results. Considering each method, the ski pole position and the ankle joint position are different at the same time, and the changing trend of the joint angle is different. The ankle joint position, ski pole position, and knee joint angle at the same time are used as the characteristic signal input to the algorithm. By matching the ski pole position information and the human body movement parameters, the classification of technical actions and the recognition of the movement phase are analyzed to achieve an understanding of skiers’ movements and improve the scientific training level. According to the characteristics of the different sub-actions, the following classification can be made, as shown in
Table 1.
According to the results of sport biomechanical analysis of cross-country skiing, the range of motion of elbow and shoulder joints, angular velocity, and the angle between the snowball and the ground are all related to sports performance. In addition, the coordination of joint activities is also conducive to improving work efficiency and athletic performance. At the same time, the coordination between the shoulder, elbow, and trunk can cause the body to have a large inclination change, which is conducive to the active extension of the elbow joint, thus generating greater propulsion [
39]. Therefore, according to the characteristics of the movement, we can build a physiological model and analyze the kinematic model to implement pose recognition. The joint angle used in this article is calculated from the spatial position between coordinate points in space. The kinematic model consists of 17 anatomical points corresponding to the right (left) temple, shoulder, elbow, wrist, hip, knee, and ankle, respectively; in addition, two additional points are added: the bottom point of the snow poles, as shown in
Figure 1a.
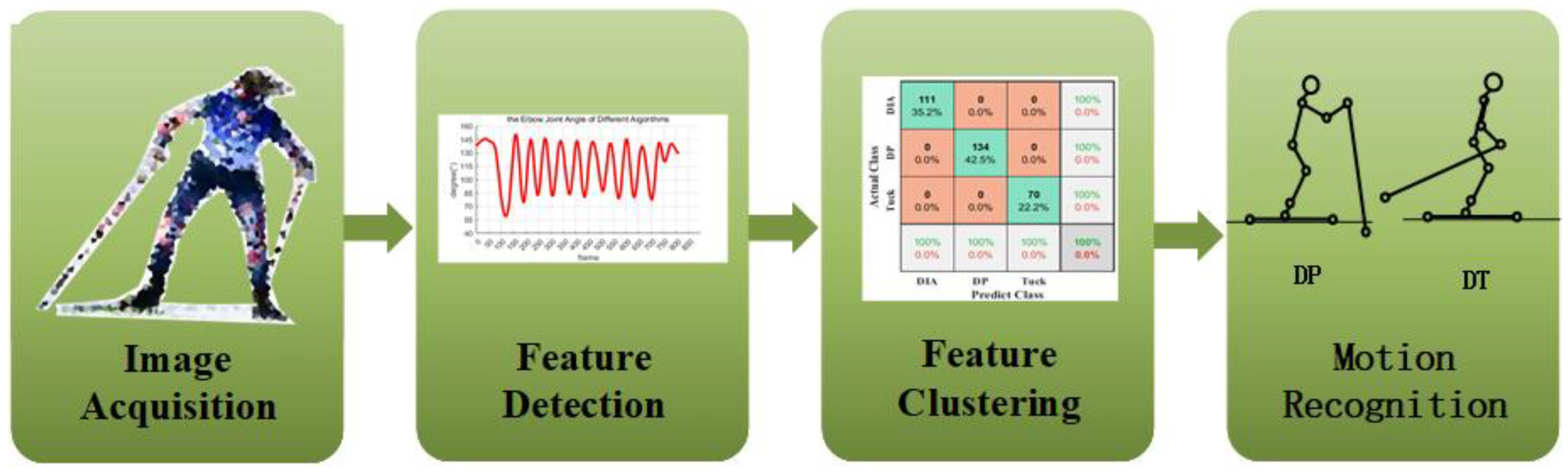
To sum up, monocular outdoor motion recognition faces three major challenges: different attitude displacement scale transformation, attitude size scale transformation, key-point noise, and recognition errors caused by missing key points. To solve these problems, we designed an action recognition algorithm based on multiple neural networks and feature generation, as shown in
Figure 2. First, a human body detector was designed to find the target human body and each human candidate region by detecting key points in the image or video. A similar top-down detection method does not easily generate interference between different joint points. The depth information was obtained by calculation or prediction, and the three-dimensional key-point coordinates were obtained by using the depth information to implement the three-dimensional construction of human posture. Finally, the attitude data were divided into sub-action regions according to prior knowledge and feature generation was performed. Finally, the generated feature information was divided into sub-action regions using support vector machines, as shown in
Figure 3. The whole algorithm framework is made up of three modules: a key-point region detection module based on YOLO [
40], a 3D pose estimation module, and an action recognition module.
3.2. Two-Dimensional Pose Estimation Module
Currently, most mainstream human posture estimation methods take high-resolution images as input and use a Gaussian heatmap to estimate the position information of key points. The research shows that in the same model, the higher the resolution of the input image, the higher the recognition accuracy of the heatmap [
41]. The accuracy of key-point prediction is essentially limited by the resolution of the heatmap, which leads to the accuracy problem of the commonly used heatmap method. At the same time, Feature Pyramid Networks (FPNs) are often used in the recognition process to restore the size of the input. In the outdoor environment, the distance between the camera and the target is often large, and the proportion of the target in the field of view is small. Therefore, the true resolution of the target area is low, the accuracy of the heatmap is reduced, and there is a feature shift in the feature layers of different scales, which increases the uncertainty of the key-point location. For example, if two key points of the same category are close to each other, they may be mistaken for the same key point due to overlapping heatmap signals, leading to key-point detection failure and affecting the final recognition effect [
42,
43]. Given the obvious shortcomings of the heatmap, this work calibrates the human body and joints based on YOLOv5, does not use a heatmap, and contains an efficient network design. It simultaneously detects the target and its key points at the same time and uses a matching algorithm to fuse the two kinds of results.
The two-dimensional pose recognition module in this article uses a CNN to extract features and then uses the full connectivity layer to regress the coordinates of key points by MSE (mean square error) loss. During pre-training, the input training set was classified into different key points of the human body, and the output has 18-dimensional object class scores, including the key-point categories and the person category. All key points are computed simultaneously and share the same feature information. For each grid scale in the image, the confidence is calculated for all categories, and the target category has the highest confidence in the location.
The output grid scales of YOLO are 8, 16, 32, and 64, selected by the hypermeters of reference [
42]. Each grid uses different anchors. The smaller grid has a larger receptive field and can predict larger objects; the larger grid has a smaller receptive field and is more suitable for predicting smaller objects.
In this paper, the multi-task loss function was used to train the network, which mainly includes the loss of probability of target existence, the loss of boundary box size, and the loss of category score. The loss of each task is calculated as follows:
where category loss, confidence loss, and positioning loss are represented by
,
, and
, respectively, and
,
, and
are shown as the balancing coefficients.
The category loss is calculated using binary cross entropy. In this paper, there are 18 kinds of joint points and human targets and a total of 19 kinds of targets. The formula is as follows:
where
and
are used to represent the category of the target identified by the algorithm in this paper and the truth label of the target, respectively.
The confidence loss is used to describe whether there is a center point on this grid; that is, whether there is an object. The algorithm in this paper regards confidence as a two-class problem. The closer the predicted value is to 1, the more likely it is that there is a target at that location, and the less likely it is that there is no target. The formula is as follows:
where
is used to describe the number of targets,
is used to describe the total number of bounding boxes, and
is used to indicate whether there is a type
target in the bounding box
or not.
is used to indicate the probability of the existence of the type
target in the boundary box
detected by our method.
The calculation of location loss is mainly to improve the accuracy of the detection method in this paper. The
is used to describe the prediction box.
,
,
, and
are used to show the center-point coordinates and the width and height values of the prediction box, respectively. We use
,
,
, and
to represent the true center-point coordinates and width and height, respectively. The location loss is calculated by the total number of samples and the sum of squares of the difference between the target positions estimated by the algorithm and the target positions labeled by the truth value. The formula is as follows:
For the anchor, the general height of the human body is 3–4 times the width, and the commonly used square hyperparameter anchors are obviously not suitable for the research content of the subject. Therefore, instead of using the basic hyperparameters, we modified the default values of the anchors and used the width-to-height ratio of 1:4 for the human target.
where
,
,
, and
are used as candidate boxes predicted by the algorithm in this paper.
,
,
and
are used to describe the predicted regression parameters.
,
,
and
are used to describe the coordinates, width, and height of the anchor.
is shown as the sigmoid function.
Non-maximum suppression is applied to the training results, and the scores of all the boxes are calculated. The candidate boxes are sorted by confidence and then the intersection over union (IOU) is calculated with the highest confidence candidate box, respectively. If it is greater than the set threshold, the box is deleted.
To determine which target the key points belong to, this paper uses a fusion method. After detecting human targets (candidate regions) and key points, if there are candidate regions, the Euclidean distance between all key points and the center of the candidate region is calculated. For each type of key point, the result of the minimum distance from the candidate region is selected as the key point of the target.
When training the two-dimensional pose estimation module, the three hyperparameters of the balancing coefficients were 0.6, 0.2, and 0.3, respectively. The hyperparameters of the human target anchors for the 8 scale were (12, 20), (26, 46), and (43, 102), respectively. The module was trained by 500 epochs. The training set used by the network consisted of three parts: the COCO dataset images containing both the person and snowboard categories, part of the COCO dataset images containing the person category, and the cross-country skiing dataset labeled in this work.
In 2D human pose estimation, the key points are projected onto the two-dimensional plane and the key-point detection results have no depth information. Three-dimensional pose estimation adds depth information based on 2D pose estimation, and the key points are expressed more accurately [
44]. Its application research value in ski motion recognition is higher than 2D estimation. Therefore, after extracting accurate 2D key-point coordinate information, we designed a 3D key-point estimation strategy to estimate the depth information.
3.3. Three-Dimensional Pose Estimation Module
We designed a 3D key-point estimation strategy. First, in order to finally ensure that the target contains a complete person, we take the head and neck as the root feature and use each head and neck as a marker to read more complete pose information, so as to ensure the existence of the candidate targets according to the head and neck. Then, according to the completed two-dimensional key-point data, the depth information of each key point is predicted through the network, and the three-dimensional depth information of each key point is obtained. Finally, according to the predicted joint information, a complete human posture is formed from the root node to implement the three-dimensional posture estimation. If any key points are lost, the 3D position information of the missing key points in the front and back frames is used to supplement the missing information using the least squares method. The reason why the system chooses to use the least squares method is that the video frame rate is higher than 50 Hz and the position of the key-point position information in the adjacent frames does not change much, and the second reason is that the human key-point motion attitude is relatively linear. We use the head key point and neck key point as root features, and use each head and neck as a marker to read more complete pose information, so as to ensure the existence of candidate targets based on the head and neck. Then, according to the completed two-dimensional key-point data, the depth information of the key points is predicted through the network, and the three-dimensional depth information of each key point is obtained to achieve the depth information prediction. Considering the position deviation loss and rotation compensation loss of key points, the total loss function (
) used for the training module is defined as
where
represents the offset of key points, and
is described as a rotation error. The
is shown as follows:
where
is shown as the total loss of all targets and
represents the loss of each joint of each target. The loss of rotation is described by Formula (7).
where
is used to describe the rotation matrix in three directions of
, and
.
is used to represent the true value of the rotation matrix.
We used the network structure and method of [
45] with ResNet-50 [
46] as the backbone, applied Euclidean loss, and used 12 of the 14 available camera views in the MPI-INF-3DHP (MPI) dataset for training [
47]. For training, we crop around the subject closest to the camera and apply rotation, scaling, and bounding box jitter enhancement. We use a size of 6 batches and the cycle learning rate ranges from 0.1 to 0.000001.
This work estimates the position of human joints in three-dimensional space using two-dimensional key-point coordinates as input. During training, the 3D pose estimation network uses the MPI-INF-3DHP (MPI) dataset for training. In application, our input is a series of two-dimensional points and our output is three-dimensional coordinates with depth information as reference [
48]. It uses the AdaDelta solver, with a momentum of 0.9, a weight decay multiplier of 0.005, and a batch size of 6, and trains the model for 360k iterations with a cyclical learning rate ranging from 0.1 to 0.000001.
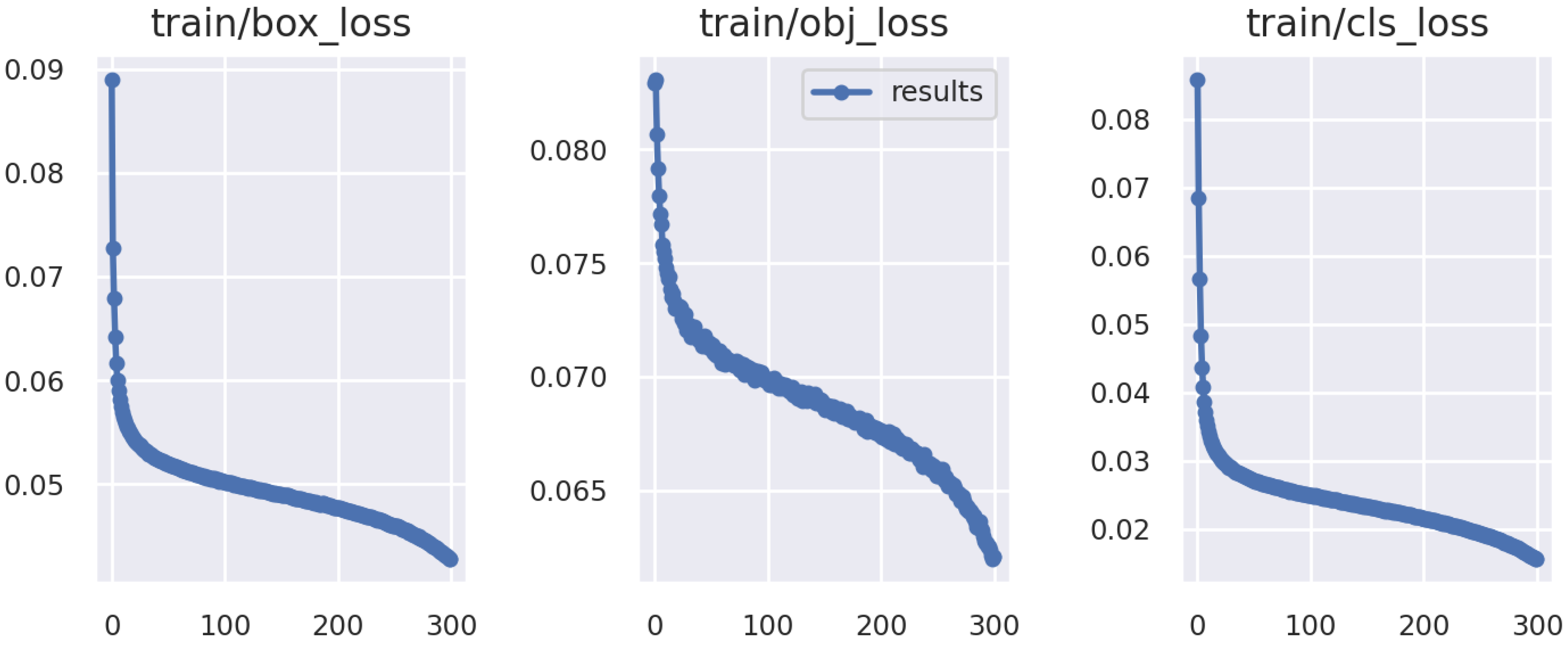
The loss curve is shown in
Figure 4. It can be seen that our curve gradually converges smoothly, and the convergence curve reflects the performance of the algorithm.
The algorithm estimates the depth information of the key points using a pre-trained model (
Figure 5). In the actual estimation, there are still some key points that cannot be predicted in occlusion and target deformation. The video frame rate is 60 Hz, and the human movement in each frame is relatively close. Therefore, through linear interpolation on the tensor product mesh of 3D discrete predicted data, the position of the key point can be obtained by using the position information of adjacent frames. The unrecognized joint point coordinates are (
), and the formula is as follows:
where
and
represent the position information of key points in the next frame, and
, and
represent the key-point information of the previous frame of the lost frame, respectively. In this way, the missing key points can be supplemented, and the success rate of subsequent action feature recognition can be improved to a certain extent.
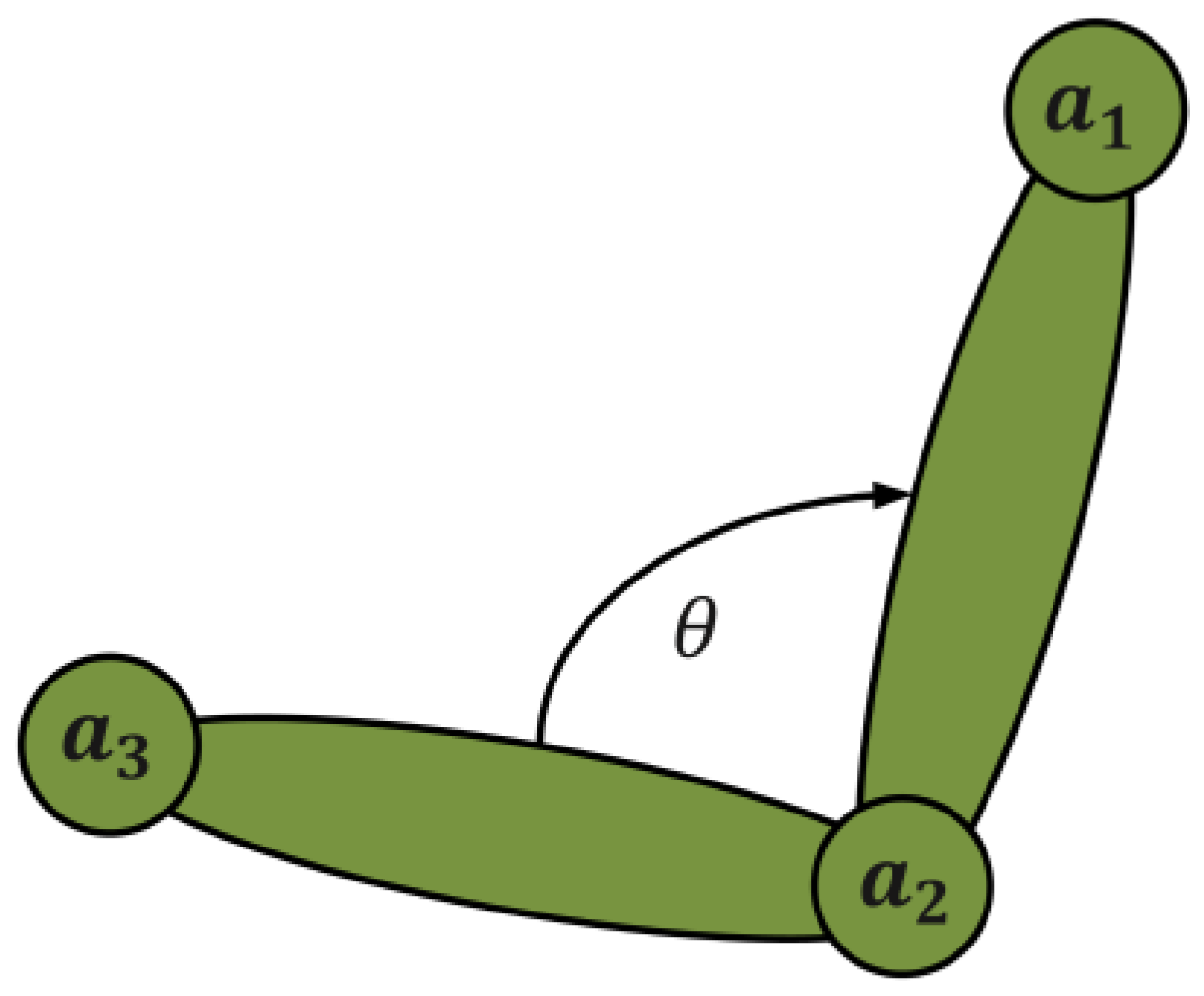
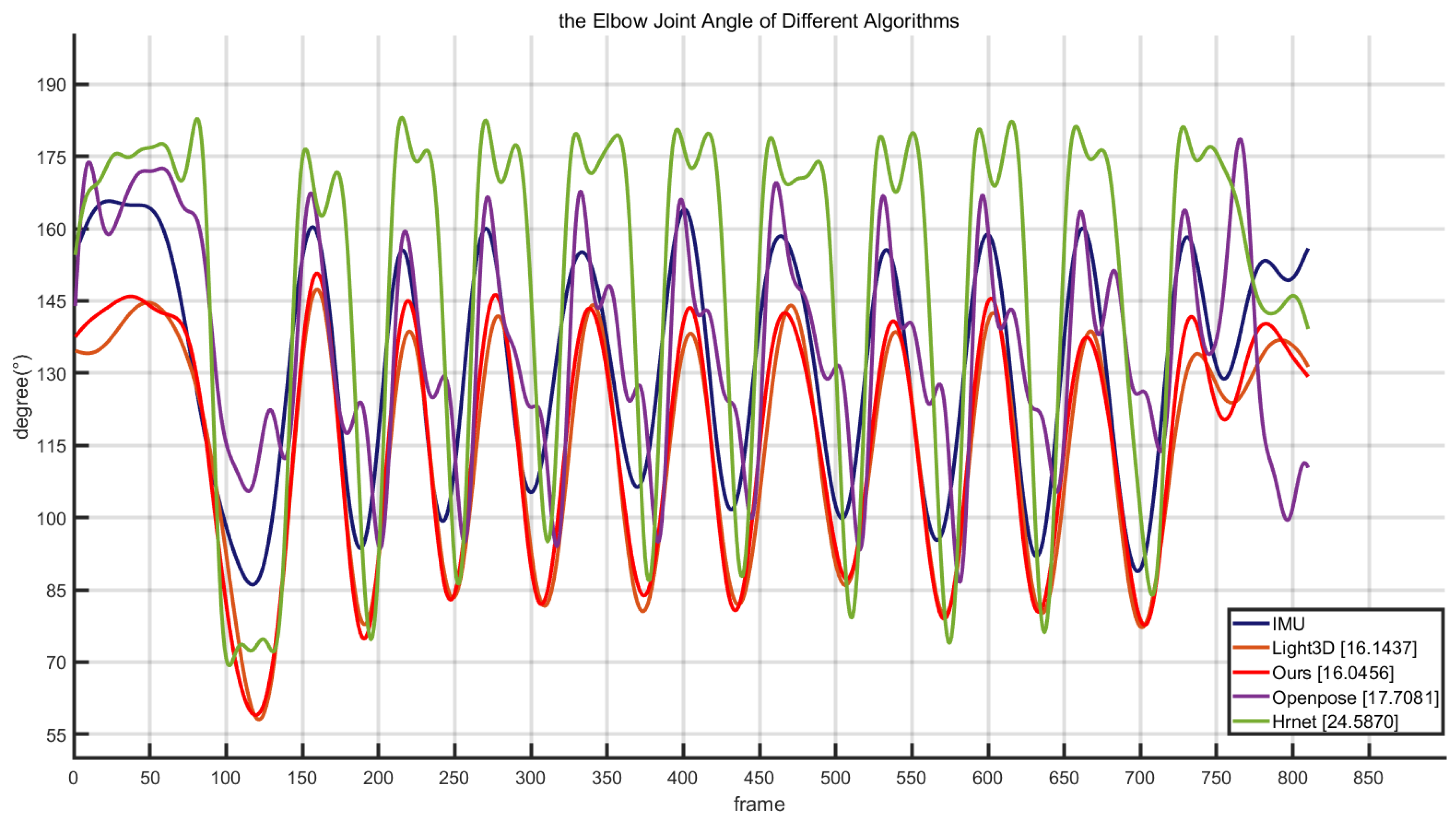
In the pose evaluation, each joint angle in the movement process will significantly affect the movement posture, and the movement posture will significantly affect the mobility. Therefore, in the process of maneuvering, obtaining information on the athlete’s posture joint angle is conducive to assisting the coach in improving the athlete’s mobility. The joint angle used in this article is calculated from the spatial position between coordinate points in space. After extracting the position of each joint point in 3D space, this paper calculates the angle between joints. In this process, the connection between joint points is regarded as a chain structure in which the local stiffness is not changed. Take the right elbow joint as an example, as shown in the
Figure 5, where
,
, and
represent the right shoulder joint, right elbow joint, and right wrist joint. The angle of the elbow joint is the included angle with the right elbow joint as the vertex
. The calculation is publicized as follows:
3.4. Action Recognition Module
In the experiment, the predicted joint trajectory is not smooth enough, and the joint position produces jitter. It is impossible to easily identify the key frames related to the feature stage by the spatial position information of the coordinate points. To reduce the effect of this kind of jitter, this paper uses the expectation maximization (EM) algorithm for parameter estimation and the Butterworth filter to achieve accurate joint recognition and jitter suppression.
The EM algorithm consists of two steps, which are called expectation (E step) and maximization (M step). Step E calculates the posterior probability of implicit variables according to the initial value of parameters or the model parameters of the previous iteration, which is actually the expectation of implicit variables. As the current estimated value of hidden variables, it is calculated as follows:
where
is used to describe the posterior probability.
and
are used to represent input and response, respectively. The initialization distribution parameter uses
θ express. The solution is the maximum likelihood estimate of
θ, as follows:
Through continuous iteration, the lower bound continues to increase, and the maximum likelihood estimation shows a monotonic increasing trend, eventually reaching the maximum value of the maximum likelihood estimation. This step is called the M step.
In practical applications, the ultimate goal is to achieve the detection and understanding of the key-point location and sub-action. In order to reduce the negative impact of the data jitter caused by each frame recognition result on the detection result, we also use the Butterworth filter to further reduce jitter. The characteristic of the Butterworth filter is that the frequency response curve in the passband is as flat as possible without fluctuation, which can effectively reduce the interference in the process of motion, which is more suitable for the purpose of finding poles. The formula of the Butterworth filter is as follows:
where
is the result of passing the Butterworth filter, and
is the corresponding input. The order of the filter is expressed by
, and the cut-off frequency is shown as
. We have tested that the third-order Butterworth filter has a good effect. Too high an order of the Butterworth filter will result in too flat a curve and pole loss, which is not conducive to improving the detection success rate and detection accuracy. The low order of the Butterworth filter will still cause the jitter of the characteristic curve, which can easily lead to false detection. After the parameter test, the third-order Butterworth filter, the cut-off frequency is 14 Hz, the key-point curve is relatively flat, and the information storage is also rich.
After the motion path has been smoothed, the x-coordinate of the time series is clustered into segments representing the standing stage or the pole stage. It is assumed that in the standing stage, the y coordinate of the ankle joint stays approximately constant with the increase in the number of frames, while the x coordinate of the ankle joint increases with the number of frames that the mobile person moves from left to right. The same valley point can be regarded as the landing of the mobile person’s foot, and the distance and time between the two valleys can be regarded as a progression. The camera frame rate used in this paper is 60 Hz–120 Hz, and each frame is very unblocked. Because the change between image frames is relatively small, the y-direction coordinate is not used for judgment. For each x coordinate, calculate the backward finite difference between the
x-axis coordinate of the ankle joint, and the previous value is calculated as follows:
where
is used to describe the number of frames, and
is used to represent the position information of the key points on the
x-axis at the time of frame number
t. After calculating the position information of each frame, the values are classified according to the International Snow Federation rules.
The three technical actions are mainly judged by the pole position and height of the ski pole and joint angle data. The cycle of sliding movement mainly depends on the combination of the contact and separation of the ankle joint and standing position and the position of the snow stick. For example, in the alternate sliding, the technical action is similar to the walking posture. When the right foot makes contact with the ground to exert force, the right ski stick is at the back position; at this time, the left foot is lifted backward. On the contrary, when the right ski stick and the left foot exert force relative to the front of the body, the left ski stick and the right foot wave backward. When using the double-pole push-and-hold technique, the ski poles on both sides are completely synchronized, and the ankle joints on both sides are also completely synchronized. During the descent, both feet are on the ground at the same time, and there is no stick support for a long time. Therefore, the left and right ankle joint data and the left and right ski pole vertex data are selected as the feature information.
The jitter in the motion curve of key points produces redundant poles, which affect the result to some extent. To overcome this problem, by observation and estimation, a complete motion phase is generally not less than 150 frames. Therefore, any two adjacent troughs that are fewer than 60 frames apart are combined. The same merging method is applied to the ascending and descending phases, although the y-axis parameters have changed during the ascending and descending phases. The step size in pixels is defined as the absolute difference between two adjacent high x-value troughs and the Euclidean distance between two troughs. The duration of each step is divided by the frame rate (i.e., 60 FPS–120 FPS) by calculating the number of frames between the two troughs in the rise and fall phases. Finally, the incorrect step size is removed from each video, including the incomplete step size at the beginning and end of the video. By comparing the parameters, the step size that is less than 50 pixels from the median step size of the video is removed.
There are certain differences between different movements due to the changes in the coordinate positions and the angles of the key points of their movement modes, but the trend of athletic movement has rules to follow. Set the position information of feature points as
, and use fast Fourier transform (FFT) to obtain the estimated power spectral density, where the parameters are frequency
and spectrum
[
49]. The generated features are shown in
Table 2. Each variable has 10 time domain features and 3 frequency domain features, respectively. High-dimensional features will provide rich information, which is conducive to better distinguishing action features and realizing action recognition.
Normalization can prevent one or more dimensions from having a significant impact on the data, allowing each feature to contribute equally to the results, which would play an unbalanced role in training. Common normalization methods include deviation standardization and center standardization. Among them, deviation standardization is a linear transformation of the original data to make the results fall in the range of 0–1. Center standardization is to transform the values of all the features to be converted into a normal distribution with a mean value of 0 and a standard deviation of 1. Compared with central standardization, deviation standardization cannot solve the problem of outliers very well. Therefore, select center standardization to process the generated features.
In human motion recognition, due to the limited number of samples and the features not being prominent, the classification recognition algorithm has high requirements. At present, the human motion recognition algorithm still needs to rely on a large amount of label data when it is applied. The large-scale labeling work not only consumes a lot of human, financial, and material resources but also the data quality is difficult to guarantee, which reduces the training value of the human motion recognition algorithm in ice and snow sports. For the obtained key-point motion curve and angle change curve, this paper uses a support vector machine (SVM) algorithm as collaborative recognition after feature extraction [
50]. The formulas of the SVM methods are shown in Formula (7).
where
is described as the normal vector of the optimal separation hyperplane, and the offset is described as
. SVMs are used as classifiers in collaborative training. The classification confidence of the algorithms is a floating-point number between 0 and 1.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}