
Domain Adaptation Methods for Lab-to-Field Human Context Recognition †

 , and
, and
Abstract
:1. Introduction
- 1.
- We provide Triple-DARE, a novel UDA deep-learning architecture that employs a scripted dataset to increase the HCR accuracy of predicting contexts in the wild. Triple-DARE employs a domain alignment loss for domain-independent feature learning, a classification loss to keep task-discriminative features, and a joint fusion triplet loss to improve intra-class compactness and inter-class separation;
- 2.
- We carefully assessed Triple-DARE, comparing it to numerous state-of-the-art unsupervised domain approaches, including DAN [18], CORAL [19], and HDCNN [17], and bench-marking advances in HCR performance on target domains in multiple application scenarios. Our ablation study demonstrates that all component of Triple-DARE contributes non-trivially;
- 3.
- We illustrate that Triple-DARE minimizes in-the-wild dataset problems when compared to state-of-the-art DA algorithms, delivering improved prediction accuracy on the target (in-the-wild) domain without the requirement for large amounts of source-labeled samples.
2. Background
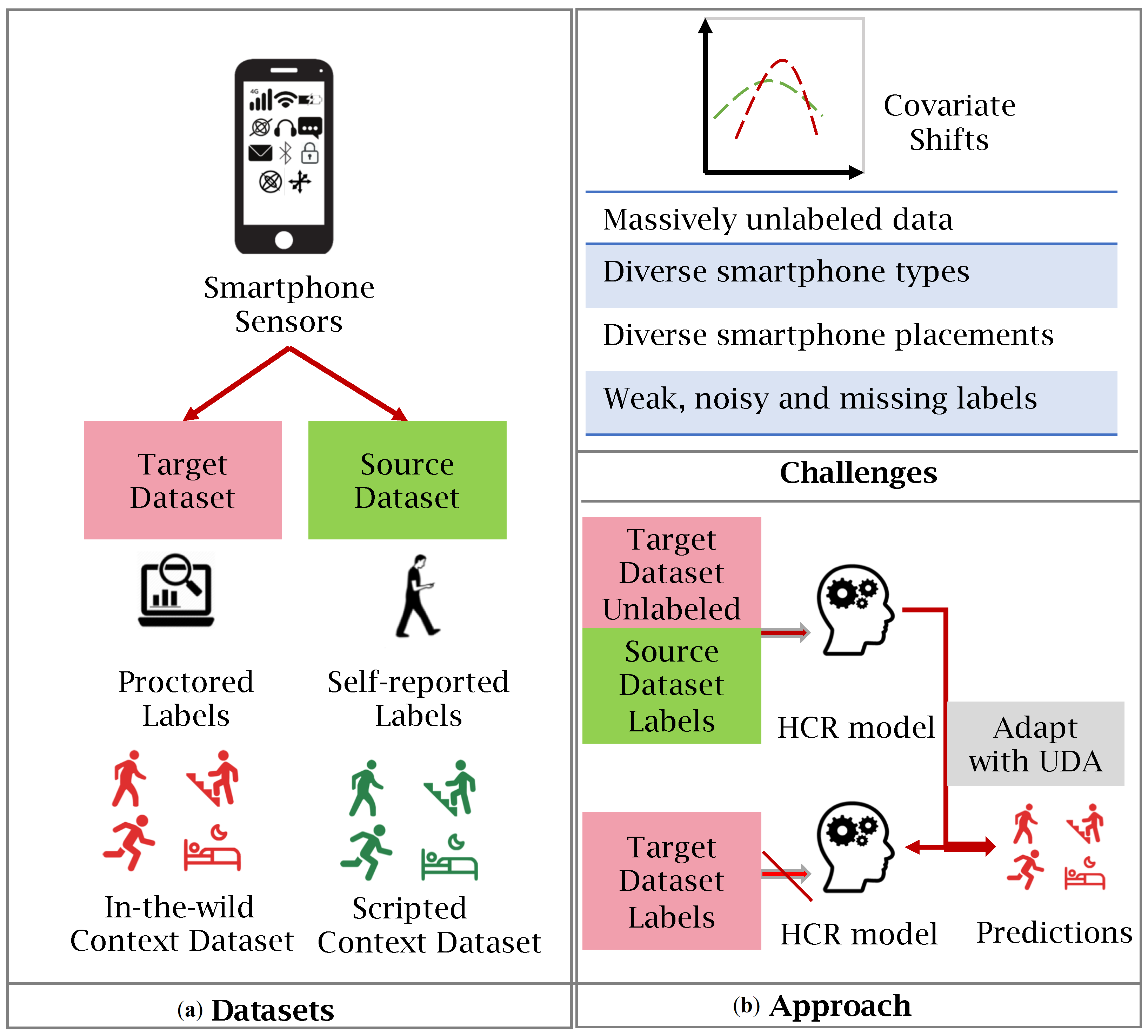
2.1. Covariate Shifts
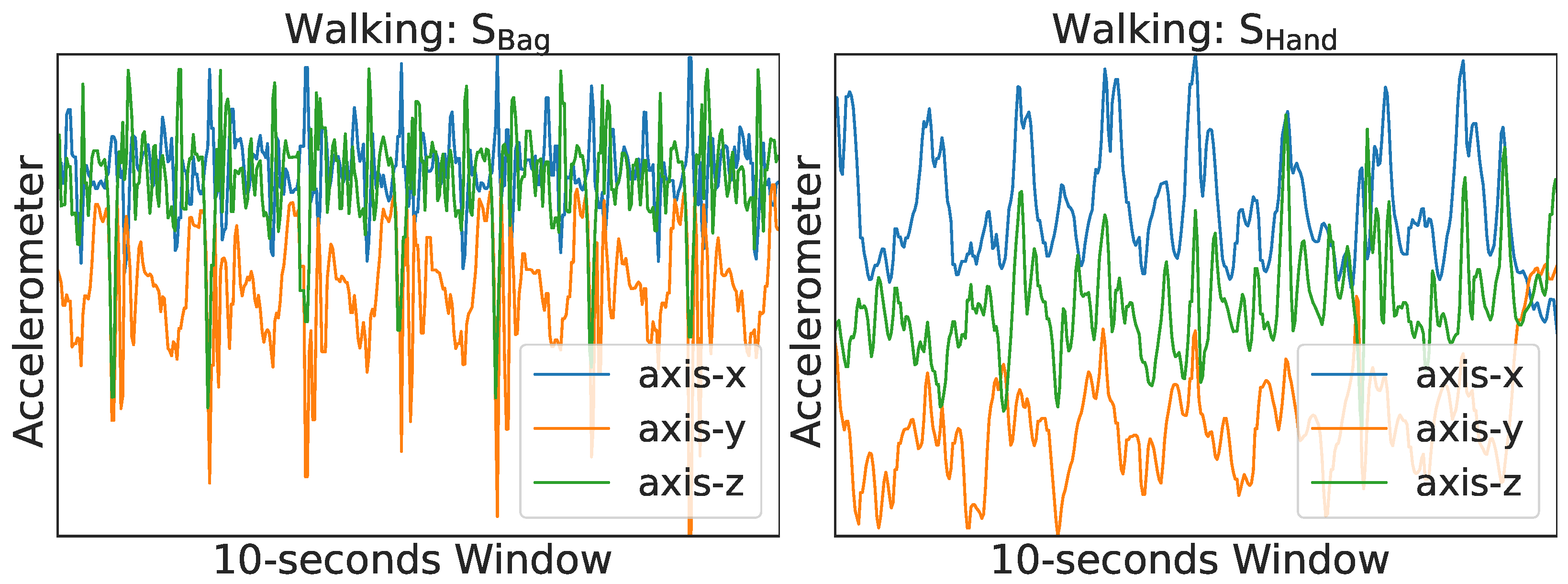
2.2. Sensor Data Collection Studies
2.3. DARPA WASH Project: Motivation Use Case
2.4. Our Coincident Data Gathering Study Approach
2.5. Weakly Supervised Learning (WSL)
- 1.
- Inexact supervision in which only coarse-grained labels are provided. Due to the nature of the annotation process of sensor data, only a few selected sub-segments of each training sensor segment can be considered accurate representatives of their respective labels. However, their precise length, as well as their position within the segment, is unknown;
- 2.
- Inaccurate supervision in which data labels are not always correct. For example, in-the-wild datasets often depend on self-reported labels. However, users may erroneously provide wrong labels as they might not recall which contexts they previously visited accurately;
- 3.
- Incomplete supervision that utilizes unlabeled training data. When study participants get busy with their lives, they might forget to label the data in the dataset, which means that some of the context labels might be missing from the dataset.
3. Related Work
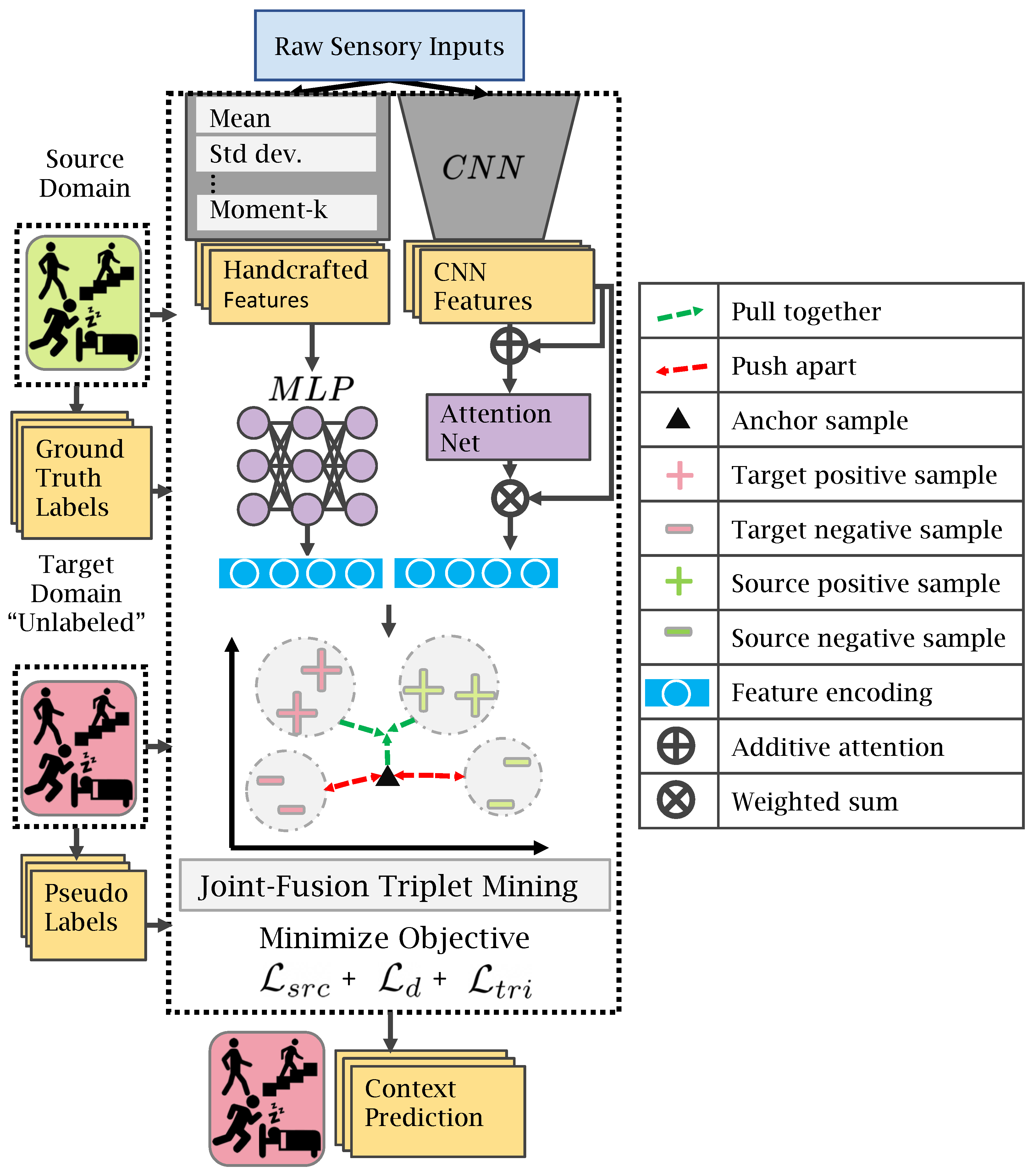
4. Proposed Triple-DARE Methodology
4.1. Problem Formulation
4.2. Overview
4.3. Feature Generation
4.4. Domain Alignment Loss
4.5. Classification Loss
4.6. Triplet Loss
4.7. Joint-Fusion Triplet Mining
| Algorithm 1:Joint-fusion online triplet mining finds triplets with multi-labeled vectors |
Input: Number of samples in a batch m, classifier , , , distance d, Output: List of triplets [(a, p, n)] ← Read next mini-batch (); ← Random sample mini-batch (); ←Assign pseudo labels using f on ; ← concatenate( , ); ← {}  return triplets |
5. Experiments
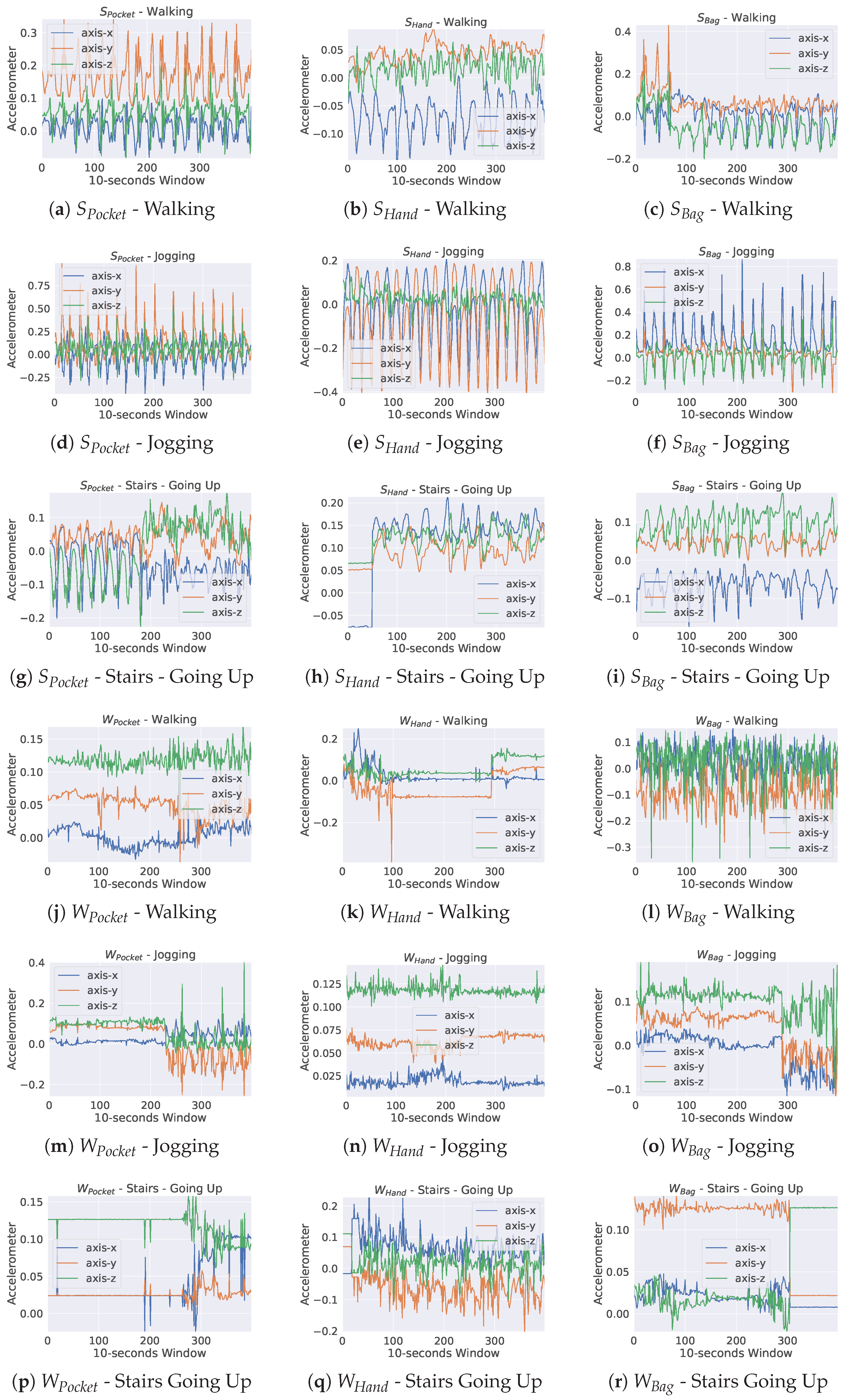
5.1. Datasets
5.2. Baselines
5.3. Implementation and Experimental Settings
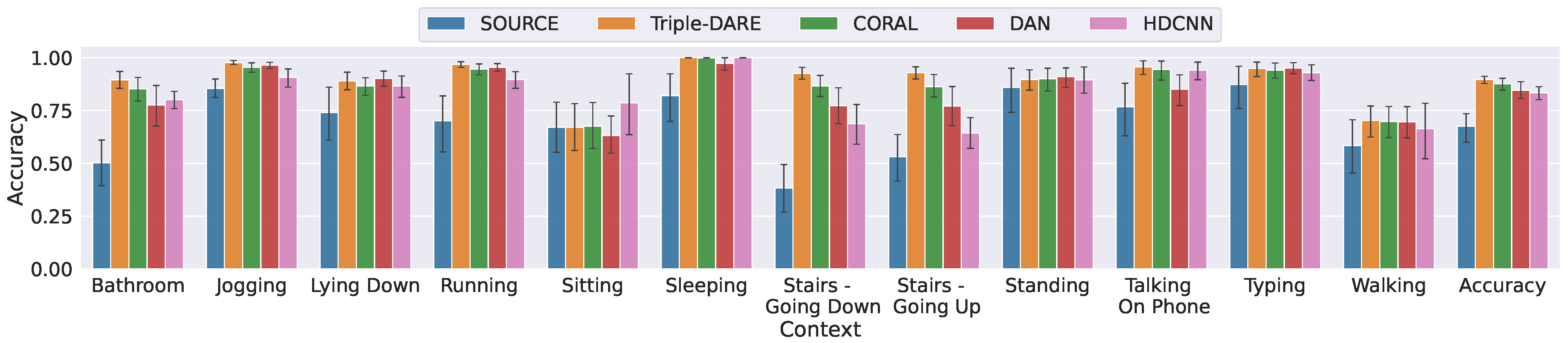
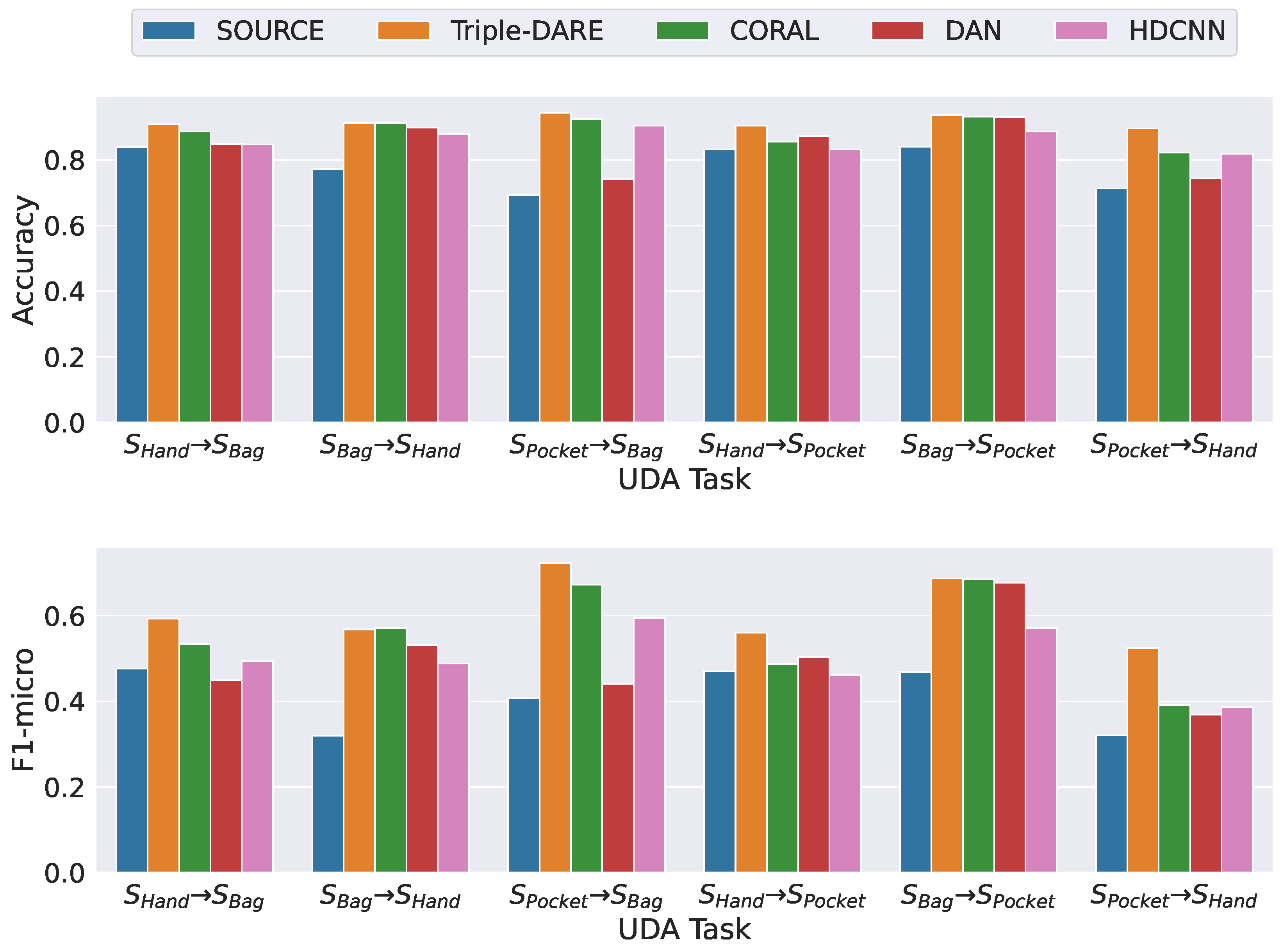
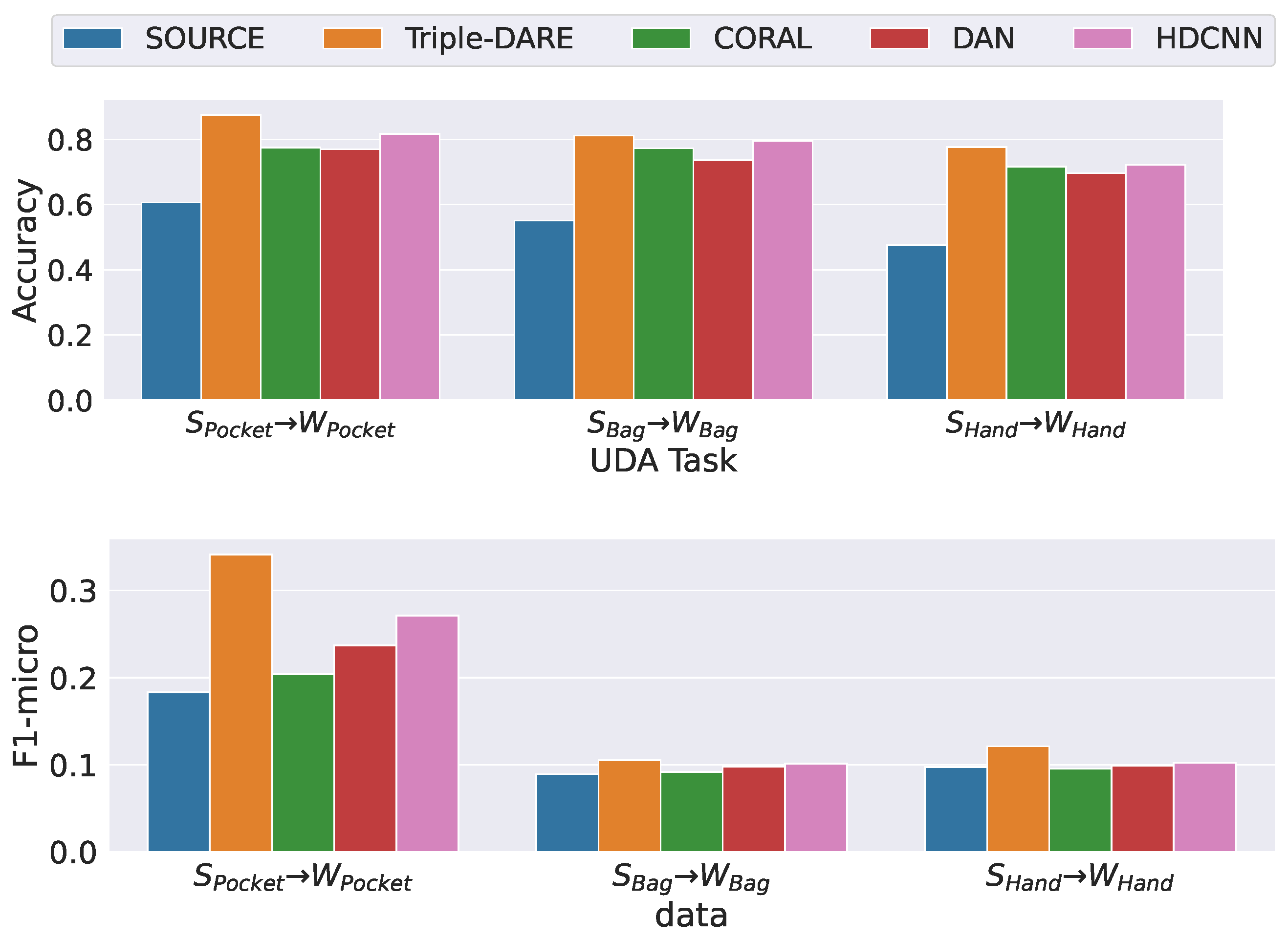
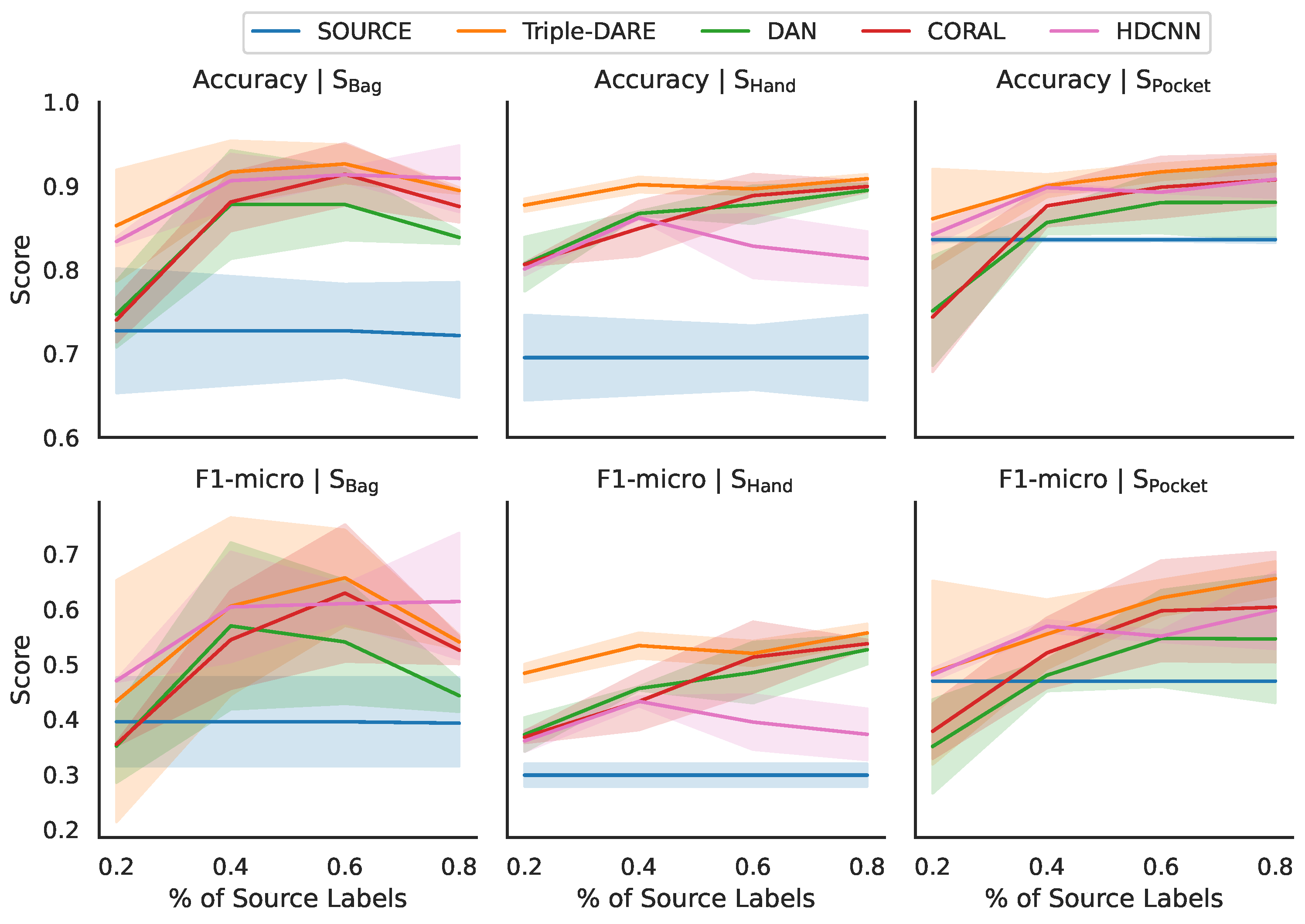
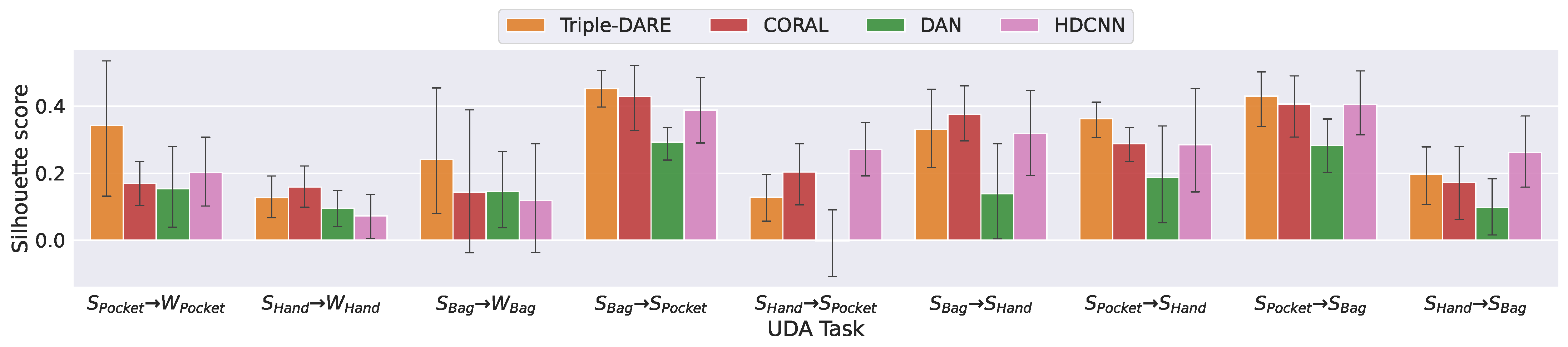
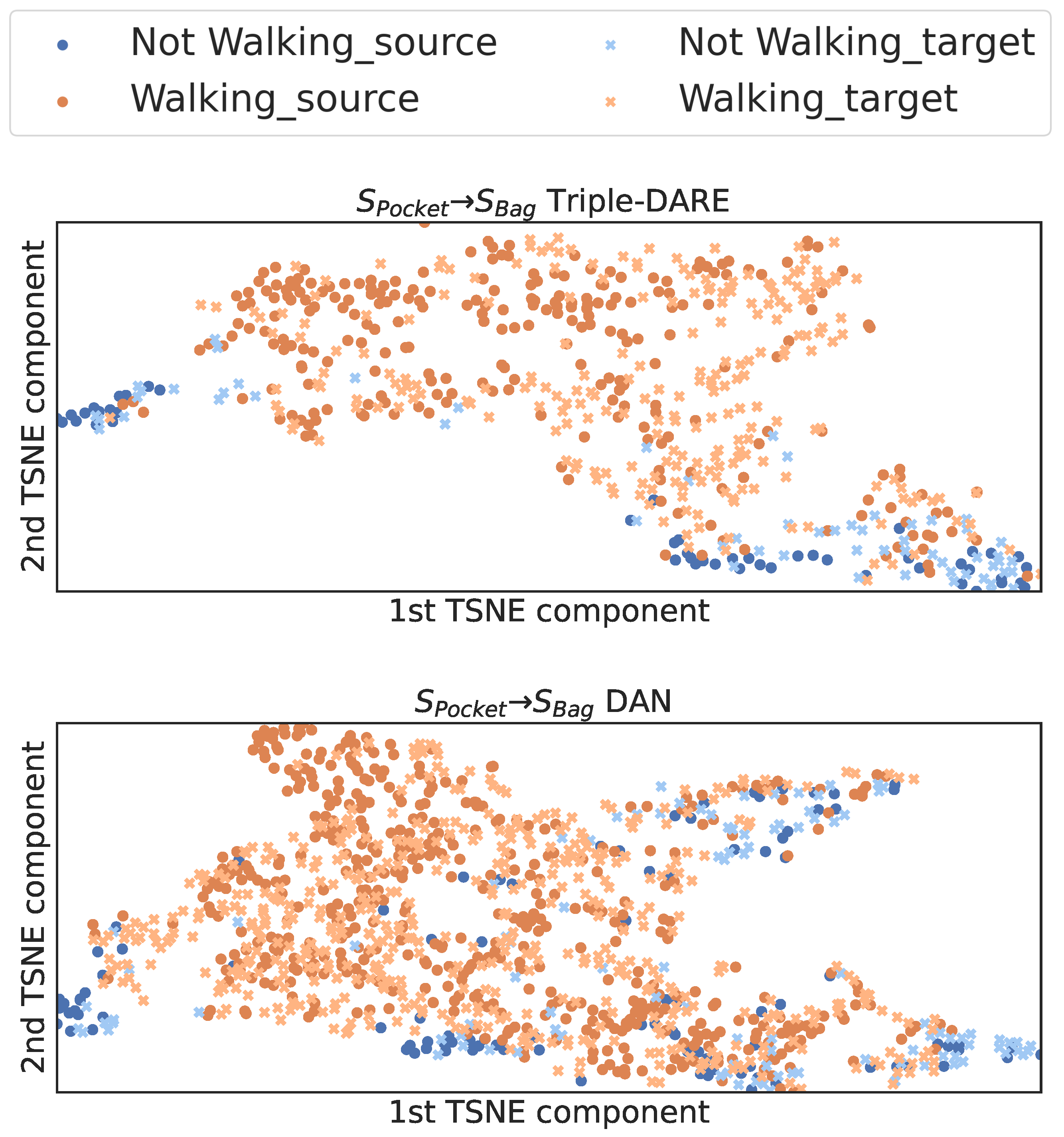
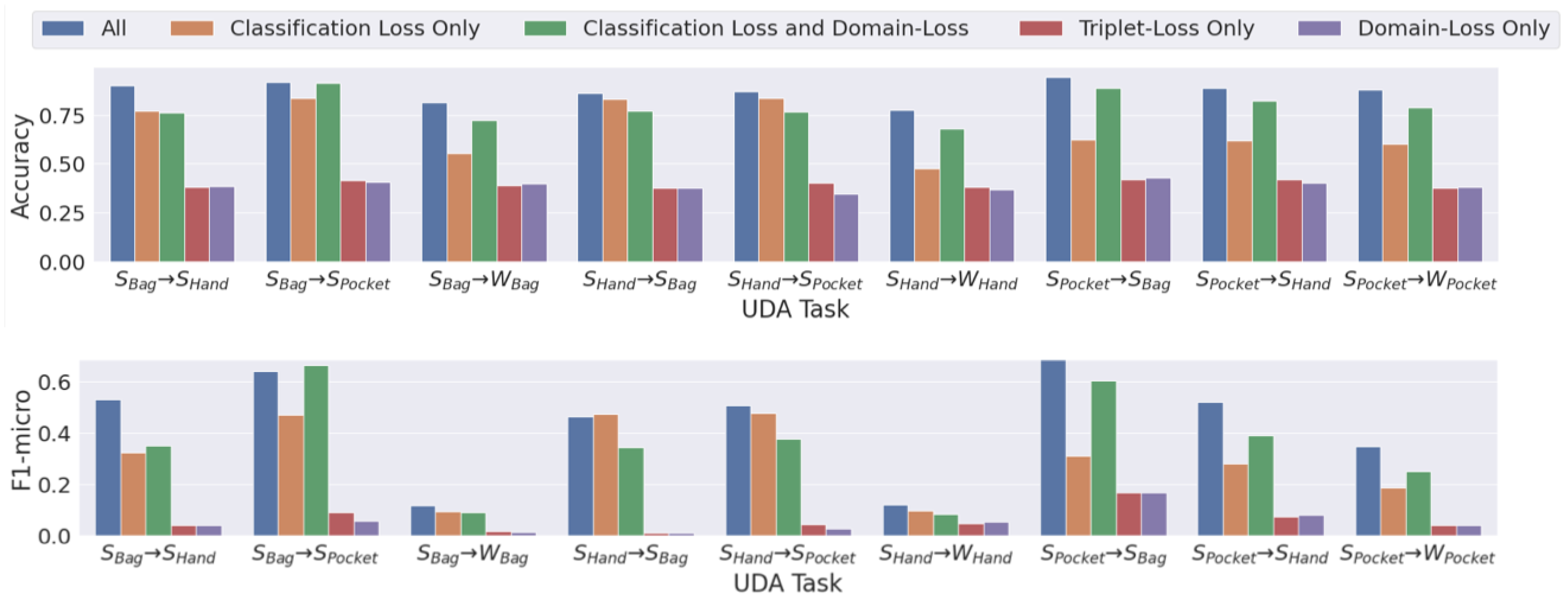
5.4. Results and Findings
6. Limitations and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| HCR | Human Context Recognition |
| CA | Context Aware |
| DA | Domain Adaptation |
| UDA | Usupervised Domain Adaptation |
| CNN | Convolutional neural network |
| MLP | Multilayer perceptron |
| WASH | Warfighter Analytics using Smartphone for Healthcare |
| UMMS | University of Massachusetts Medical School |
| WSL | Weakly Supervised Learning |
| ECG | Wearable electrocardiogram |
| RKHS | Reproducing Kernel Hilbert Space |
| KL | Kullback-Leibler |
| STL | Stratified Transfer Learning |
| MMD | Maximum Discrepancy Mean |
| MK-MMD | Multi Kernel Maximum Discrepancy Mean |
References
- Alajaji, A.; Gerych, W.; Buquicchio, L.; Chandrasekaran, K.; Mansoor, H.; Agu, E.; Rundensteiner, E.A. Smartphone Health Biomarkers: Positive Unlabeled Learning of In-the-Wild Contexts. IEEE Pervasive Comput. 2021, 20, 50–61. [Google Scholar] [CrossRef]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS), Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar]
- Vaizman, Y.; Ellis, K.; Lanckriet, G. Recognizing detailed human context in the wild from smartphones and smartwatches. IEEE Pervasive Comput. 2017, 16, 62–74. [Google Scholar] [CrossRef] [Green Version]
- Alajaji, A.; Gerych, W.; Chandrasekaran, K.; Buquicchio, L.; Agu, E.; Rundensteiner, E. DeepContext: Parameterized Compatibility-Based Attention CNN for Human Context Recognition. In Proceedings of the 2020 IEEE 14th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, 3–5 February 2020; pp. 53–60. [Google Scholar]
- Chang, Y.; Mathur, A.; Isopoussu, A.; Song, J.; Kawsar, F. A Systematic Study of Unsupervised Domain Adaptation for Robust Human-Activity Recognition. ACM IMWUT 2020, 4, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Stisen, A.; Blunck, H.; Bhattacharya, S.; Prentow, T.; Kjærgaard, M.; Dey, A.; Sonne, T.; Jensen, M. Smart Devices are Different: Assessing and Mitigating Mobile Sensing Heterogeneities for Activity Recognition. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Republic of Korea, 1–4 November 2015; pp. 127–140. [Google Scholar] [CrossRef]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Mansoor, H.; Gerych, W.; Buquicchio, L.; Chandrasekaran, K.; Agu, E.; Rundensteiner, E. DELFI: Mislabelled Human Context Detection Using Multi-Feature Similarity Linking. In Proceedings of the 2019 IEEE VDS, Vancouver, BC, Canada, 20 October 2019; pp. 11–19. [Google Scholar]
- Natarajan, A.; Angarita, G.; Gaiser, E.; Malison, R.; Ganesan, D.; Marlin, B.M. Domain adaptation methods for improving lab-to-field generalization of cocaine detection using wearable ECG. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; ACM: Heidelberg, Germany, 2016; pp. 875–885. [Google Scholar] [CrossRef] [Green Version]
- A unifying view on dataset shift in classification. Pattern Recognit. 2012, 45, 521–530.
- Kouw, W.M. An introduction to domain adaptation and transfer learning. arXiv 2018, arXiv:1812.11806. [Google Scholar]
- Deng, W.; Zheng, L.; Jiao, J. Domain Alignment with Triplets. arXiv 2018, arXiv:1812.00893. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Khaertdinov, B.; Ghaleb, E.; Asteriadis, S. Deep Triplet Networks with Attention for Sensor-based Human Activity Recognition. In Proceedings of the 2021 IEEE International Conference on Pervasive Computing and Communications (PerCom), Kassel, Germany, 22–26 March 2021; pp. 1–10. [Google Scholar]
- Hachiya, H.; Sugiyama, M.; Ueda, N. Importance-weighted least-squares probabilistic classifier for covariate shift adaptation with application to human activity recognition. Neurocomputing 2012, 80, 93–101. [Google Scholar] [CrossRef]
- Khan, M.A.A.H.; Roy, N.; Misra, A. Scaling Human Activity Recognition via Deep Learning-based Domain Adaptation. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom), Athens, Greece, 19–23 March 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning Transferable Features with Deep Adaptation Networks. arXiv 2015, arXiv:1502.02791. [Google Scholar]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In Proceedings of the ECCV Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016. [Google Scholar]
- Wilson, G.; Doppa, J.R.; Cook, D.J. Multi-Source Deep Domain Adaptation with Weak Supervision for Time-Series Sensor Data. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 23–27 August 2020; ACM: Virtual Event, CA, USA, 2020; pp. 1768–1778. [Google Scholar] [CrossRef]
- Shimodaira, H. Improving predictive inference under covariate shift by weighting the log-likelihood function. J. Stat. Plan. Inference 2000, 90, 227–244. [Google Scholar] [CrossRef]
- DARPA. DARPA WASH BAA. Available online: https://beta.sam.gov/opp/cfb9742c60d055931003e6386d98c044/view (accessed on 7 June 2020).
- Alajaji, A.; Gerych, W.; Chandrasekaran, K.; Buquicchio, L.; Mansoor, H.; Agu, E.; Rundensteiner, E. Triplet-based Domain Adaptation (Triple-DARE) for Lab-to-field Human Context Recognition. In Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events (PerCom Workshops), Pisa, Italy, 21–25 March 2022; pp. 155–161. [Google Scholar]
- Byrd, J.; Lipton, Z.C. What is the Effect of Importance Weighting in Deep Learning? In Proceedings of the ICML, Long Beach, CA, USA, 9–15 June 2019.
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Chen, Y.; Wang, J.; Huang, M.; Yu, H. Cross-position activity recognition with stratified transfer learning. Pervasive Mob. Comput. 2019, 57, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Sanabria, A.R.; Ye, J. Unsupervised domain adaptation for activity recognition across heterogeneous datasets. Pervasive Mob. Comput. 2020, 64, 101147. [Google Scholar] [CrossRef]
- Vaizman, Y.; Ellis, K.; Lanckriet, G.; Weibel, N. Extrasensory app: Data collection in-the-wild with rich user interface to self-report behavior. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–27 April 2018; pp. 1–12. [Google Scholar]
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Parra, X.; Anguita, D. Transition-Aware Human Activity Recognition Using Smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef] [Green Version]
- Jetley, S.; Lord, N.A.; Lee, N.; Torr, P.H.S. Learn To Pay Attention. arXiv 2018, arXiv:1804.02391. [Google Scholar]
- Gretton, A.; Sriperumbudur, B.K.; Sejdinovic, D.; Strathmann, H.; Balakrishnan, S.; Pontil, M.; Fukumizu, K. Optimal kernel choice for large-scale two-sample tests. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Maaten, L.V.D.; Hinton, G.E. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traumatic Brain Injury | |
|---|---|
| Diagnostic Test | Context |
| Inferior Reaction Time | < Interaction with Phone, in Hand, *, *> |
| Elevated Light Sensitivity | <*, in Hand, *, *> |
| Pupil Dilation | < Interaction w/ Phone, in Hand, Typing, *> |
| Hands Shaking | <*, in Hand, *, *> |
| Slurred Speech | <Speaking into Phone, *, *, *> |
| Infectious Diseases | |
| Ailment Test | Test Context |
| Elevated Frequency of Coughing | <Coughing, *, *, *> |
| Elevated Frequency of Sneezing | <Sneezing,*, *, *> |
| Rate of Heart at Rest | <Sitting, in Pocket, *, *> |
| Elevated Toilet use Frequency | <Using Toilet, *, *, *> |
| Variation in respiration | <Sleeping, on Table, *, *> |
| <Exercising, *, *, *> | |
| Both TBI and Infectious Disease | |
| Ailment Test | Test Context |
| Elevation In Activity Transition Period | <Lying down, in Pocket, *, *> |
| <Sitting, in Pocket, *, *> | |
| <Standing, in Pocket, *, *> | |
| Variation in Sleep Quality | <Sleeping, *, *, *> |
| Variation in Gait | <Walking, in Pocket/Hand, *, *> |
| Phone Placement | |
|---|---|
| Phone in Hand | Phone in Bag |
| Phone in Table—Facing Up | Phone in Table—Facing Down |
| Phone in Pocket | |
| Long Activity | |
| Standing | Sleeping |
| Walking | Sitting |
| Stairs—Going Up | Stairs—Going Down |
| Talking On Phone | Trembling |
| Jumping | Jogging |
| Typing | In Bathroom |
| Lying Down | Running |
| Short Activity | |
| Coughing | Sneezing |
| Sitting Down (transition) | Sitting Up (transition) |
| Standing up (transition) | Laying Down (transition) |
| Research Work | Method | Type of Data | Task | Lab-to-Field | Distribution Discrepancy Minimization |
|---|---|---|---|---|---|
| Natarajan et al. [9] | Importance-reweighting | Wearable electrocardiogram sensor data | Cocaine use detection | × | No |
| Alajaji et al. [1] | Positive Unlabeled Classifier | Smarthpone sensor data | Context recognition | × | No |
| Chang et al. [5] | Feature matching and confusion maximization | Wearable sensor data | UDA for activity recognition under sensor position variability | Global only | |
| Long et al. [18] | MK-MMD | Images | UDA for cross-dataset image classification | Global only | |
| Sun et al. [19] | Correlation Alignment | Images | UDA for cross-dataset image classification | Global only | |
| Khan et al. [17] | KL Divergence | Smartphone and smartwatch sensor data | DA for cross-device activity recognition | Global only | |
| Chen et al. [26] | Stratified Transfer Learning | Wearable sensor data | DA for cross sensor placement | Non-scalable intra-class separation | |
| Sanabria et al. [27] | Variational Autoencoder | Binary event sensor data | DA for cross-user activity recognition | Global only | |
| Wilson et al. [20] | Weak-supervision using target label distribution | Wearable sensor data | DA for cross-user activity recognition | Global only and utilized target labels |
| Feature | Formulation |
|---|---|
| Tri-axial sensors Features | |
| Arithmetic mean | |
| Standard deviation | |
| Frequency signal Skewness | |
| Frequency signal Kurtosis | |
| Signal magnitude area | |
| Pearson Correlation coefficient | |
| Spectral energy of a frequency band [a, b] | |
| s: signal vector Q: quartile, N: signal vector length, cov: covariance | |
| GPS Features | |
| Significant changes from the prior location state | |
| Estimated speed | |
| Variations in latitude and longitude | |
| Phone State Features | |
| Is smartphone screen unlocked? | Is smartphone charging? |
| Is ringer setting set to silent? | Is smartphone connected to WIFI? |
| Contexts | Scripted % P | In-the-Wild % P |
|---|---|---|
| Bathroom | 3.15% | 2.17% |
| Jogging | 2.04% | 0.27% |
| Lying Down | 1.10% | 16.24% |
| Running | 1.95% | 0.37% |
| Sitting | 11.99% | 38.71% |
| Sleeping | 2.19% | 37.69% |
| Stairs—Going Down | 2.52% | 2.00% |
| Stairs—Going Up | 0.89% | 1.92% |
| Standing | 1.71% | 8.46% |
| Talking On Phone | 1.41% | 1.27% |
| Typing | 3.65% | 6.45% |
| Walking | 64.00% | 13.51% |
| Phone Prioceptions | ||
| Phone In Hand | Phone In Pocket | Phone In Bag |
| Datasets Notations | ||
| Scripted context dataset | ||
| In-the-wild context dataset | ||
| e.g., refers to scripted contexts, annotated with “Phone In Pocket” | ||
| Overall UDA Tasks | Accuracy | F1-micro |
| Triple-DARE | 0.879 | 0.366 |
| CORAL | 0.806 | 0.302 |
| DAN | 0.673 | 0.294 |
| HDCNN | 0.816 | 0.3215 |
| Source (no adaptation) | 0.433 | 0.259 |
| Lab-to-field UDA Tasks | Accuracy | F1-micro |
| Triple-DARE | 0.845 | 0.188 |
| CORAL | 0.839 | 0.127 |
| DAN | 0.698 | 0.122 |
| HDCNN | 0.768 | 0.146 |
| Source (no adaptation) | 0.552 | 0.133 |
| Scripted Contexts with Cross-Prioception UDA Tasks | Lab-to-Field UDA Tasks | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Training % | Method | → | → | → | → | → | → | Avg | → | → | → | Avg |
| 0.2 | Triple-DARE | 0.500 | 0.651 | 0.213 | 0.318 | 0.652 | 0.467 | 0.467 | 0.101 | 0.080 | 0.326 | 0.169 |
| CORAL | 0.357 | 0.328 | 0.357 | 0.428 | 0.352 | 0.378 | 0.367 | 0.089 | 0.087 | 0.150 | 0.109 | |
| DAN | 0.341 | 0.436 | 0.285 | 0.265 | 0.418 | 0.403 | 0.358 | 0.079 | 0.077 | 0.165 | 0.107 | |
| HDCNN | 0.341 | 0.492 | 0.472 | 0.470 | 0.468 | 0.380 | 0.437 | 0.087 | 0.084 | 0.181 | 0.117 | |
| 0.4 | Triple-DARE | 0.557 | 0.617 | 0.444 | 0.492 | 0.767 | 0.511 | 0.565 | 0.118 | 0.143 | 0.359 | 0.207 |
| CORAL | 0.380 | 0.584 | 0.455 | 0.457 | 0.633 | 0.484 | 0.499 | 0.092 | 0.075 | 0.165 | 0.111 | |
| DAN | 0.452 | 0.509 | 0.418 | 0.451 | 0.721 | 0.459 | 0.502 | 0.101 | 0.093 | 0.244 | 0.146 | |
| HDCNN | 0.424 | 0.580 | 0.504 | 0.558 | 0.704 | 0.441 | 0.535 | 0.106 | 0.108 | 0.266 | 0.160 | |
| 0.6 | Triple-DARE | 0.497 | 0.588 | 0.570 | 0.653 | 0.744 | 0.542 | 0.599 | 0.111 | 0.112 | 0.341 | 0.188 |
| CORAL | 0.577 | 0.688 | 0.505 | 0.505 | 0.754 | 0.448 | 0.580 | 0.110 | 0.123 | 0.210 | 0.148 | |
| DAN | 0.540 | 0.634 | 0.428 | 0.459 | 0.653 | 0.429 | 0.524 | 0.100 | 0.084 | 0.209 | 0.127 | |
| HDCNN | 0.345 | 0.561 | 0.575 | 0.540 | 0.645 | 0.445 | 0.518 | 0.094 | 0.102 | 0.285 | 0.160 | |
| Average | Triple-DARE | 0.518 | 0.619 | 0.409 | 0.488 | 0.721 | 0.507 | 0.544 | 0.111 | 0.112 | 0.341 | 0.188 |
| CORAL | 0.438 | 0.533 | 0.439 | 0.463 | 0.580 | 0.437 | 0.482 | 0.097 | 0.093 | 0.173 | 0.122 | |
| DAN | 0.440 | 0.526 | 0.377 | 0.392 | 0.597 | 0.430 | 0.461 | 0.096 | 0.087 | 0.198 | 0.127 | |
| HDCNN | 0.370 | 0.544 | 0.517 | 0.523 | 0.606 | 0.422 | 0.497 | 0.096 | 0.098 | 0.244 | 0.146 | |
| - | No Adaptation | 0.319 | 0.469 | 0.476 | 0.470 | 0.260 | 0.315 | 0.385 | 0.108 | 0.110 | 0.180 | 0.133 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alajaji, A.; Gerych, W.; Buquicchio, L.; Chandrasekaran, K.; Mansoor, H.; Agu, E.; Rundensteiner, E. Domain Adaptation Methods for Lab-to-Field Human Context Recognition. Sensors 2023, 23, 3081. https://doi.org/10.3390/s23063081
Alajaji A, Gerych W, Buquicchio L, Chandrasekaran K, Mansoor H, Agu E, Rundensteiner E. Domain Adaptation Methods for Lab-to-Field Human Context Recognition. Sensors. 2023; 23(6):3081. https://doi.org/10.3390/s23063081
Chicago/Turabian StyleAlajaji, Abdulaziz, Walter Gerych, Luke Buquicchio, Kavin Chandrasekaran, Hamid Mansoor, Emmanuel Agu, and Elke Rundensteiner. 2023. "Domain Adaptation Methods for Lab-to-Field Human Context Recognition" Sensors 23, no. 6: 3081. https://doi.org/10.3390/s23063081