
Semi-Supervised Behavior Labeling Using Multimodal Data during Virtual Teamwork-Based Collaborative Activities
 , ,
, ,
Abstract
:1. Introduction
- In this paper, we expand our novel multimodal dataset of autistic and neurotypical individuals working together to complete a collaborative task in virtual reality.
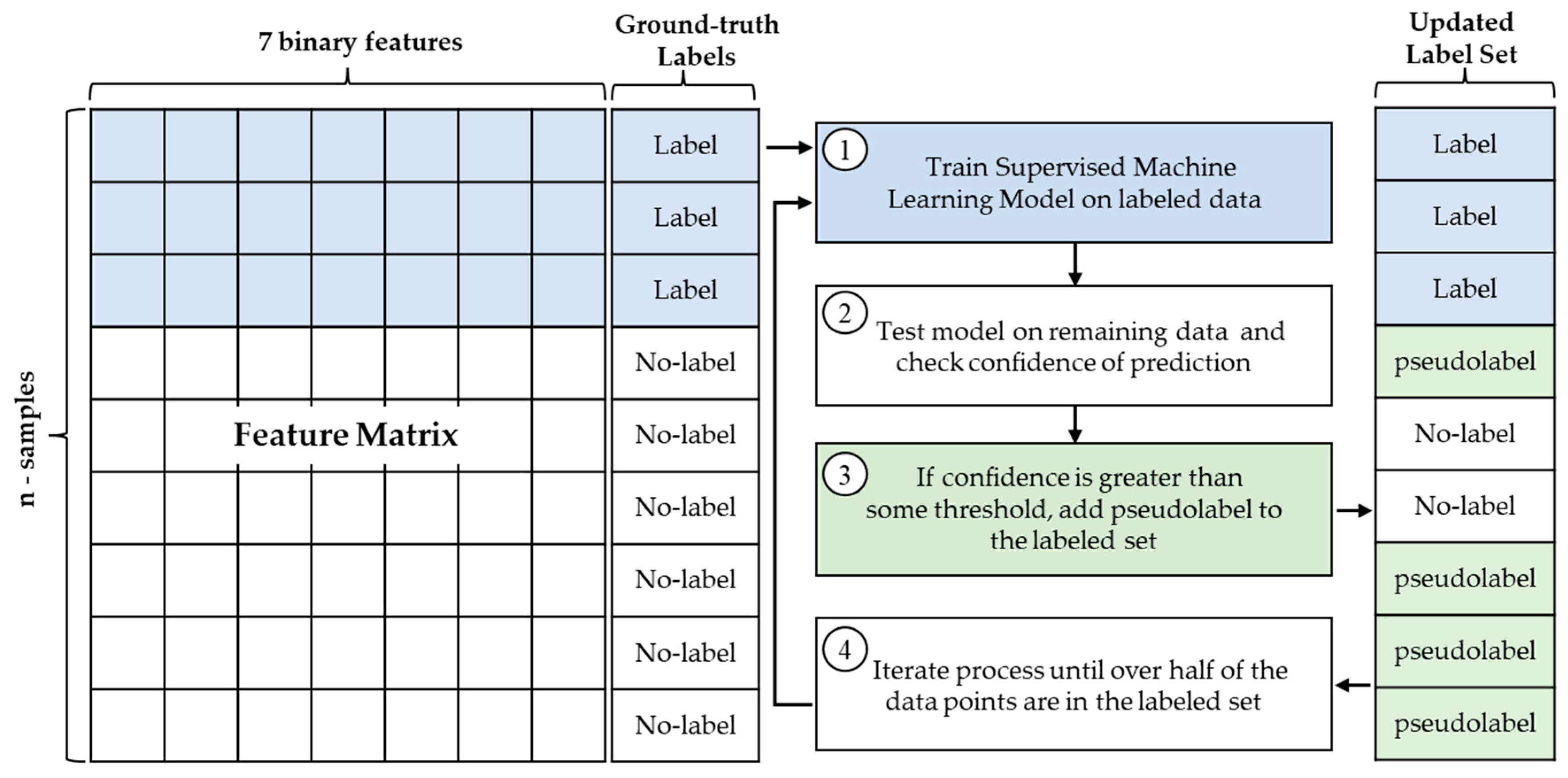
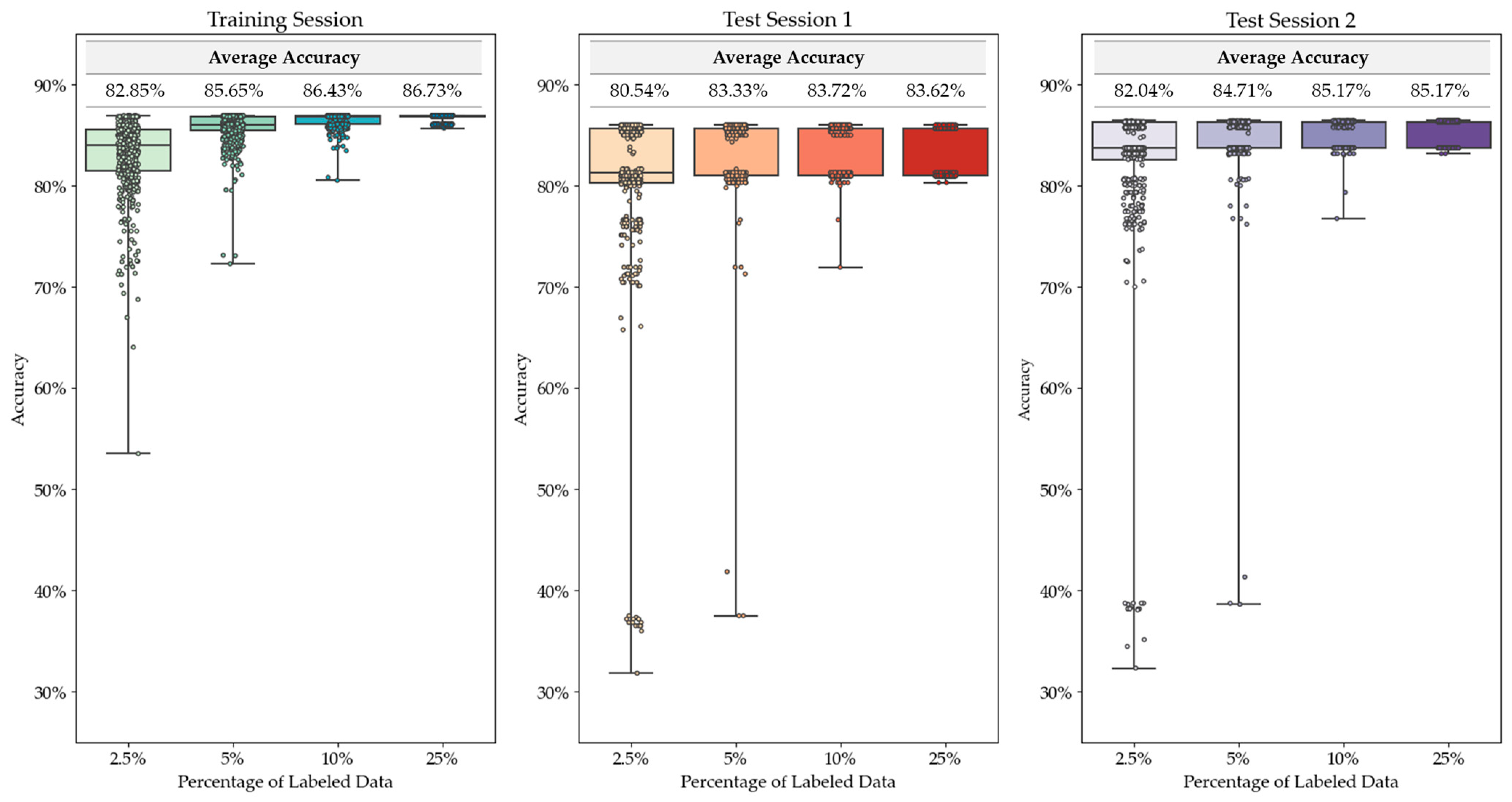
- Using this dataset, we developed a semi-supervised self-training affective model. In doing so, we determined the percentage of labeled data needed for consistent high-accuracy results between our model and ground-truth labels.
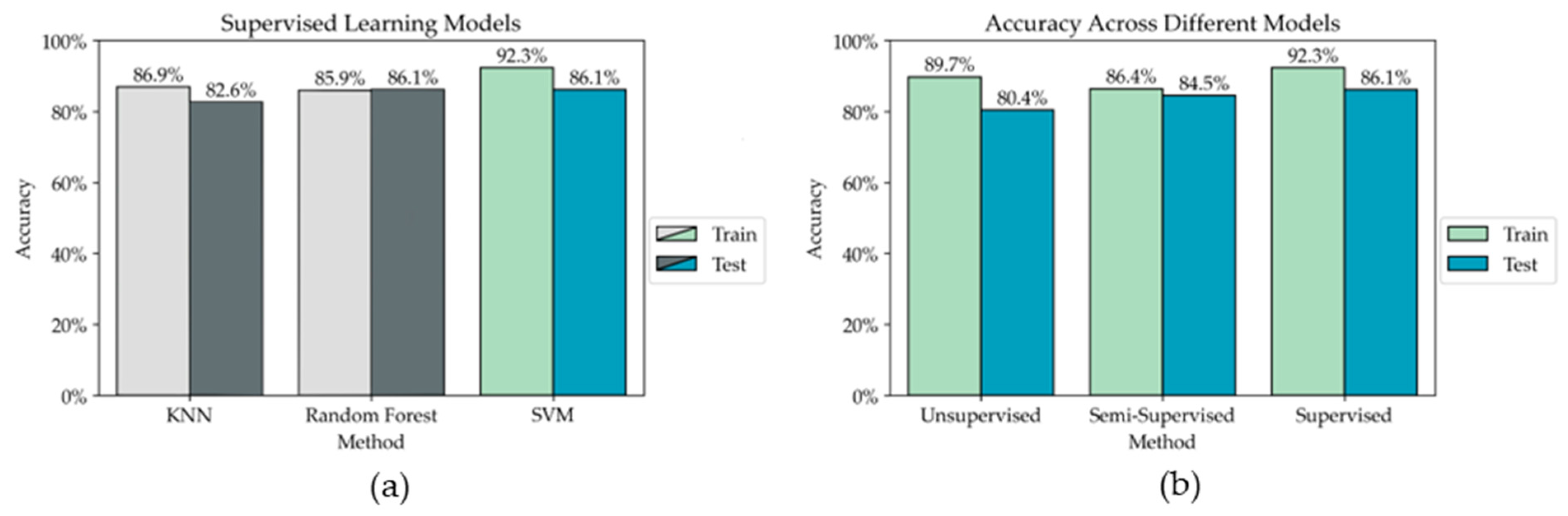
- We compared the performance of our semi-supervised model to both a supervised and unsupervised model to prove the effectiveness of this model. Our semi-supervised model outperformed the unsupervised model and performed comparably to the supervised model. The semi-supervised model is an improvement over the supervised model when considering the trade-off between performance accuracy and manual data labeling.
2. System Design
2.1. Collaborative Tasks
2.2. Data Collection and Processing
2.3. Manual Data Labeling
3. Methods
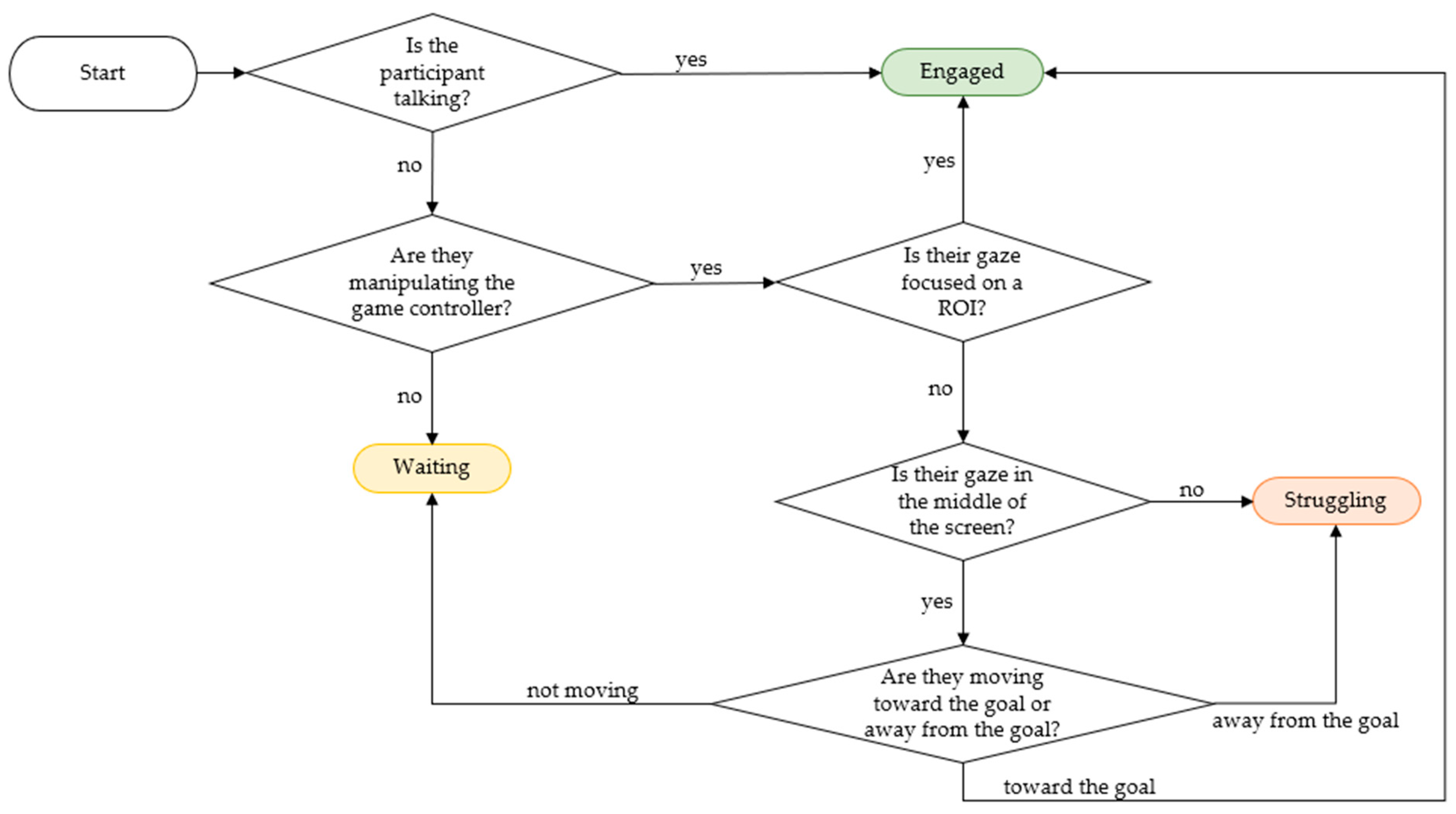
3.1. Semi-Supervised Self-Training Algorithm
3.2. Performance Metrics
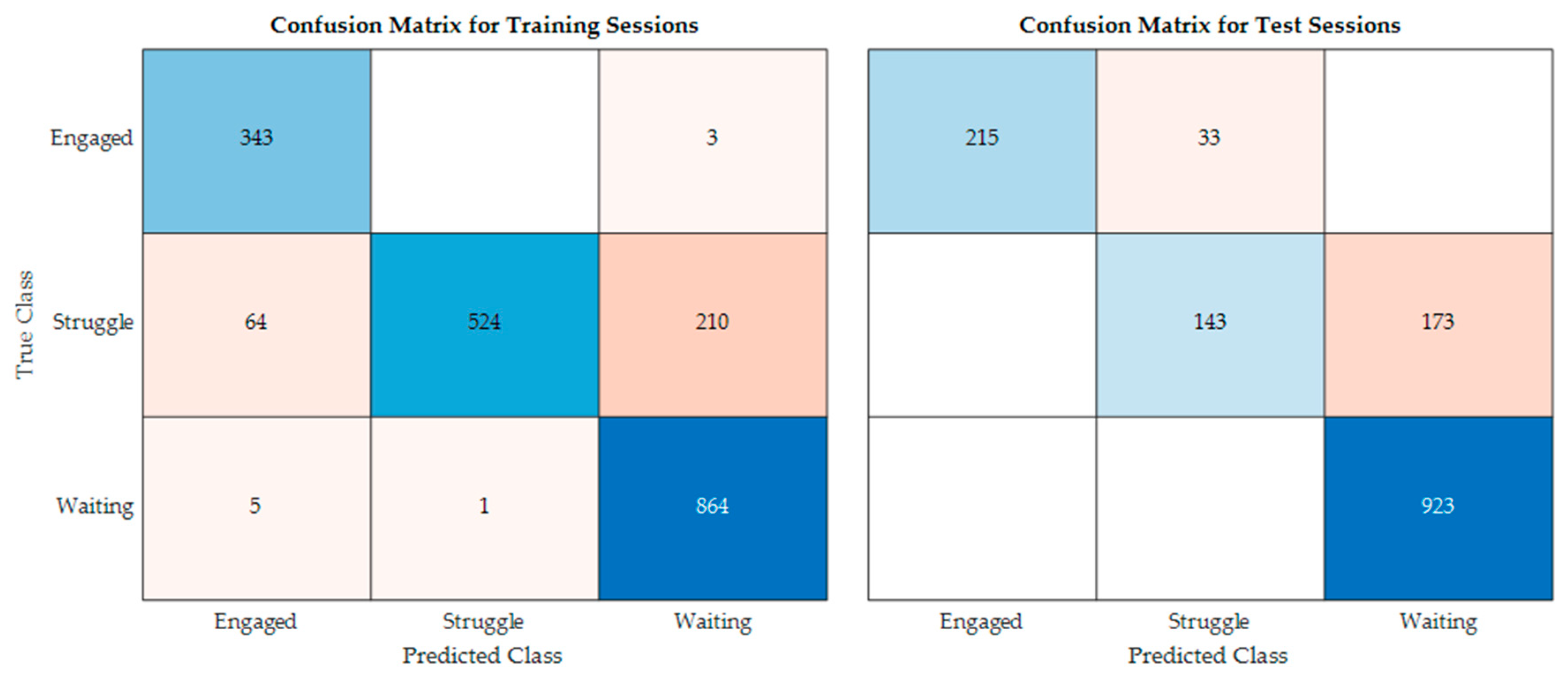
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Unbehauen, H.D. Control Systems, Robotics and Automation—Volume XXI: Elements of Automation; EOLSS Publications: Oxford, UK, 2009; ISBN 978-1-84826-160-0. [Google Scholar]
- Stauch, T.A.; Plavnick, J.B. Teaching Vocational and Social Skills to Adolescents with Autism Using Video Modeling. Educ. Treat. Child. 2020, 43, 137–151. [Google Scholar] [CrossRef]
- Dwyer, P.; Ryan, J.G.; Williams, Z.J.; Gassner, D.L. First Do No Harm: Suggestions Regarding Respectful Autism Language. Pediatrics 2022, 149, e2020049437N. [Google Scholar] [CrossRef] [PubMed]
- Kenny, L.; Hattersley, C.; Molins, B.; Buckley, C.; Povey, C.; Pellicano, E. Which terms should be used to describe autism? Perspectives from the UK autism community. Autism Int. J. Res. Pract. 2016, 20, 442–462. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Conn, K.; Sarkar, N.; Stone, W. Physiology-based affect recognition for computer-assisted intervention of children with Autism Spectrum Disorder. Int. J. Hum.-Comput. Stud. 2008, 66, 662–677. [Google Scholar] [CrossRef]
- Lorenzo, G.; Lledó, A.; Pomares, J.; Roig, R. Design and application of an immersive virtual reality system to enhance emotional skills for children with autism spectrum disorders. Comput. Educ. 2016, 98, 192–205. [Google Scholar] [CrossRef] [Green Version]
- O’Hara, S.; Lui, Y.M.; Draper, B.A. Unsupervised Learning of Human Expressions, Gestures, and Actions. Proceedings of 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG), Santa, Barbara, CA, USA, 21–25 March 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–8. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Rosenberg, C.; Hebert, M.; Schneiderman, H. Semi-Supervised Self-Training of Object Detection Models; Carnegie Mellon University: Pittsburgh, PA, USA, 2005. [Google Scholar] [CrossRef]
- AbaeiKoupaei, N.; Osman, H.A. Multimodal Semi-supervised Bipolar Disorder Classification. In 22nd International Conference, Proceedings of the Intelligent Data Engineering and Automated Learning—IDEAL 2021, Manchester, UK, November 25–27; Yin, H., Camacho, D., Tino, P., Allmendinger, R., Tallón-Ballesteros, A.J., Tang, K., Cho, S.-B., Novais, P., Nascimento, S., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 575–586. [Google Scholar]
- Liu, T.; Yang, Y.; Huang, G.-B.; Yeo, Y.K.; Lin, Z. Driver Distraction Detection Using Semi-Supervised Machine Learning. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1108–1120. [Google Scholar] [CrossRef]
- Zhang, Z.; Ringeval, F.; Dong, B.; Coutinho, E.; Marchi, E.; Schüller, B. Enhanced semi-supervised learning for multimodal emotion recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5185–5189. [Google Scholar]
- Hodges, H.; Fealko, C.; Soares, N. Autism spectrum disorder: Definition, epidemiology, causes, and clinical evaluation. Transl. Pediatr. 2020, 9, S55–S65. [Google Scholar] [CrossRef]
- Autism Facts & Statistics—Autism Society Greater Cincinnati. Available online: https://www.autismcincy.org/autism-facts-statistics/ (accessed on 3 November 2022).
- Litchfield, P.; Cooper, C.; Hancock, C.; Watt, P. Work and Wellbeing in the 21st Century. Int. J. Environ. Res. Public Health 2016, 13, 1065. [Google Scholar] [CrossRef]
- Creed, P.A.; Macintyre, S.R. The relative effects of deprivation of the latent and manifest benefits of employment on the well-being of unemployed people. J. Occup. Health Psychol. 2001, 6, 324–331. [Google Scholar] [CrossRef]
- Scott, M.; Falkmer, M.; Girdler, S.; Falkmer, T. Viewpoints on Factors for Successful Employment for Adults with Autism Spectrum Disorder. PLoS ONE 2015, 10, e0139281. [Google Scholar] [CrossRef] [Green Version]
- Park, H.R.; Lee, J.M.; Moon, H.E.; Lee, D.S.; Kim, B.-N.; Kim, J.; Kim, D.G.; Paek, S.H. A Short Review on the Current Understanding of Autism Spectrum Disorders. Exp. Neurobiol. 2016, 25, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schmutz, J.B.; Meier, L.L.; Manser, T. How effective is teamwork really? The relationship between teamwork and performance in healthcare teams: A systematic review and meta-analysis. BMJ Open 2019, 9, e028280. [Google Scholar] [CrossRef] [Green Version]
- Walsh, E.; Holloway, J.; Lydon, H. An Evaluation of a Social Skills Intervention for Adults with Autism Spectrum Disorder and Intellectual Disabilities preparing for Employment in Ireland: A Pilot Study. J. Autism Dev. Disord. 2018, 48, 1727–1741. [Google Scholar] [CrossRef] [PubMed]
- Chen, W. Multitouch Tabletop Technology for People with Autism Spectrum Disorder: A Review of the Literature. Procedia Comput. Sci. 2012, 14, 198–207. [Google Scholar] [CrossRef] [Green Version]
- Bernard-Opitz, V.; Sriram, N.; Nakhoda-Sapuan, S. Enhancing social problem solving in children with autism and normal children through computer-assisted instruction. J. Autism Dev. Disord. 2001, 31, 377–384. [Google Scholar] [CrossRef]
- Sung, C.; Connor, A.; Chen, J.; Lin, C.-C.; Kuo, H.-J.; Chun, J. Development, feasibility, and preliminary efficacy of an employment-related social skills intervention for young adults with high-functioning autism. Autism Int. J. Res. Pract. 2019, 23, 1542–1553. [Google Scholar] [CrossRef]
- Cordell, A.T. Creating a Vocational Training Site for Individuals With Autism Spectrum Disorder. Interv. Sch. Clin. 2023; online first. [Google Scholar] [CrossRef]
- Mesa-Gresa, P.; Gil-Gómez, H.; Lozano-Quilis, J.-A.; Gil-Gómez, J.-A. Effectiveness of Virtual Reality for Children and Adolescents with Autism Spectrum Disorder: An Evidence-Based Systematic Review. Sensors 2018, 18, 2486. [Google Scholar] [CrossRef] [Green Version]
- Chițu, I.B.; Tecău, A.S.; Constantin, C.P.; Tescașiu, B.; Brătucu, T.-O.; Brătucu, G.; Purcaru, I.-M. Exploring the Opportunity to Use Virtual Reality for the Education of Children with Disabilities. Children 2023, 10, 436. [Google Scholar] [CrossRef]
- Wu, X.; Liu, W.; Jia, J.; Zhang, X.; Leifer, L.; Hu, S. Prototyping an Online Virtual Simulation Course Platform for College Students to Learn Creative Thinking. Systems 2023, 11, 89. [Google Scholar] [CrossRef]
- Thordarson, A.; Vilhjálmsson, H.H. SoCueVR: Virtual Reality Game for Social Cue Detection Training. In Proceedings of the 19th ACM International Conference on Intelligent Virtual Agents, Paris, France, 2–5 July 2019; ACM: Paris, France, 2019; pp. 46–48. [Google Scholar]
- Amat, A.; Breen, M.; Hunt, S.; Wilson, D.; Khaliq, Y.; Byrnes, N.; Cox, D.; Czarnecki, S.; Justice, C.; Kennedy, D.; et al. Collaborative Virtual Environment to Encourage Teamwork in Autistic Adults in Workplace Settings; Springer International Publishing: Cham, Switzerland, 2021; pp. 339–348. ISBN 978-3-030-78091-3. [Google Scholar]
- Plunk, A.; Amat, A.Z.; Wilkes, D.M. Automated Behavior Labeling During Team-Based Activities Involving Neurodiverse and Neurotypical Partners Using Multimodal Data. In Proceedings of the Human Behavior Understanding Workshop in conjunction with the International Conference on Pattern Recognition, Montreal, QC, Canada, 21–25 August 2022. [Google Scholar]
- Technologies, U. Unity Real-Time Development Platform|3D, 2D VR & AR Engine. Available online: https://unity.com/ (accessed on 28 September 2022).
- Meier, A.; Spada, H.; Rummel, N. A rating scheme for assessing the quality of computer-supported collaboration processes. Int. J. Comput.-Support. Collab. Learn. 2007, 2, 63–86. [Google Scholar] [CrossRef] [Green Version]
- MathWorks—Makers of MATLAB and Simulink. Available online: https://www.mathworks.com/ (accessed on 28 September 2022).
- Support Vector Machines for Binary Classification—MATLAB & Simulink. Available online: https://www.mathworks.com/help/stats/support-vector-machines-for-binary-classification.html#bsr5b42 (accessed on 9 March 2023).
- Gandhi, R. Support Vector Machine—Introduction to Machine Learning Algorithms. Available online: https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47 (accessed on 9 March 2023).
- Catania, C.A.; Bromberg, F.; Garino, C.G. An autonomous labeling approach to support vector machines algorithms for network traffic anomaly detection. Expert Syst. Appl. 2012, 39, 1822–1829. [Google Scholar] [CrossRef]
- Classify Observations Using Support Vector Machine (SVM) Classifier—MATLAB Predict. Available online: https://www.mathworks.com/help/stats/classreg.learning.classif.compactclassificationsvm.predict.html (accessed on 9 March 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Input Method (Ease of Use) | Description | Aspects of Collaboration |
|---|---|---|---|
| Fulfillment Center | Mouse and Keyboard (Easy) | Drive a forklift to pick up and deliver crates from a storage shelf to a collection area in a warehouse | The two forklifts had varying height capacities making teamwork integral for success. |
| Furniture Assembly | Haptic Device (Required Extra Practice) | Assemble various pieces of furniture such as a coffee table and a bookcase using either assembly instructions or an image of the completed furniture. | The participants had varying information in their instructions. Also, each participant was tasked with different aspects of assembly making collaboration vital for assembly. |
| PC Assembly | Gamepad (Required Minimal Practice) | Build a computer by putting together different pieces of computer hardware. | The two users had different pieces of computer hardware as well as extra components. In addition, participants had mismatched assembly instructions making teamwork and communication essential for task completion. |
| Metrics | ASD (N = 6) | TD (N = 6) |
|---|---|---|
| Age Mean (SD) | 20.5 (2.81) | 22.83 (3.60) |
| Gender (% Male) | 50% | 50% |
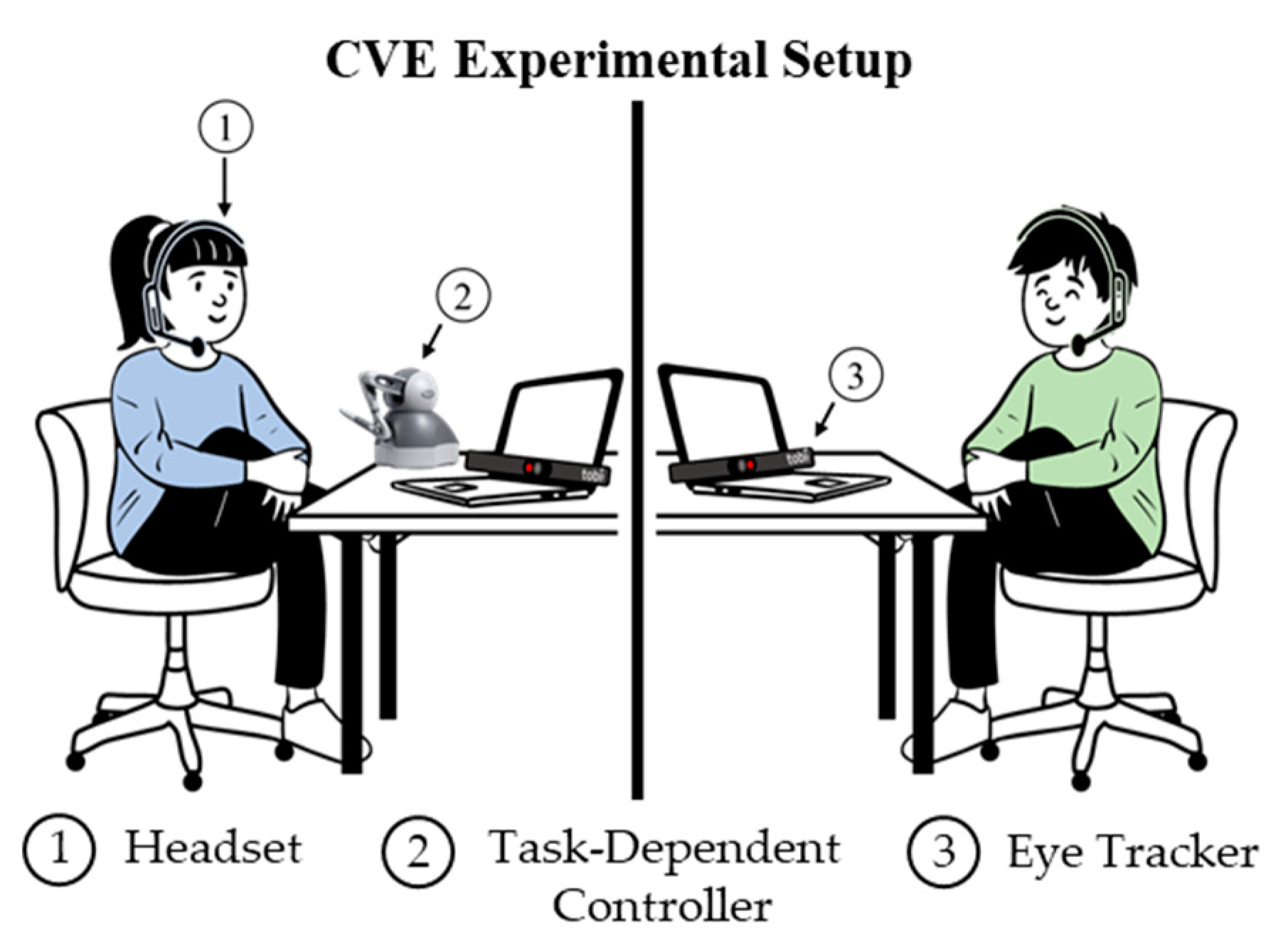
| Modality | Binary Feature | Description | Example of ‘1’ for Each Feature |
|---|---|---|---|
| Headset | Speech | If the participant is speaking, the feature is ‘1’ otherwise it is ‘0’. | Participant 1 is encouraging participant 2 in the PC assembly task by saying “Great Job!” |
| Task-Dependent Controller | Controller Activated | If the controller is activated, the feature is ‘1’ otherwise it is ‘0’. | Participant 1 moves the haptic controller in the furniture assembly task. |
| Object Manipulated | If the controller is activated in an area of interest, the feature is ‘1’ otherwise it is ‘0’. | Participant 2 moves the haptic controller to move a table leg in the furniture assembly task. | |
| Moving Towards Goal | Uses distance to determine if the participant is progressing toward the goal. If they are, the feature is ‘1’ otherwise it is ‘0’. | Participant 1 is moving a table leg towards the desired position in the furniture assembly task. | |
| Moving Away from Goal | Uses distance to determine if the participant is moving away from to goal. If they are, the feature is ‘1’ otherwise it is ‘0’. | Participant 2 is struggling to move a table leg in the furniture assembly task and is moving away from the desired position. | |
| Eye Tracker | Focused on Object | If the gaze is focused on an area of interest, the feature is ‘1’ otherwise it is ‘0’. | Participant 1 is looking at the motherboard in the PC assembly task. |
| Not Focused on Screen | If the gaze is not focused on the middle of the screen, the feature is ‘1’ otherwise it is ‘0’. | Participant 2 is looking at the couch in the furniture assembly task which is in the outer portion of the screen. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Plunk, A.; Amat, A.Z.; Tauseef, M.; Peters, R.A.; Sarkar, N. Semi-Supervised Behavior Labeling Using Multimodal Data during Virtual Teamwork-Based Collaborative Activities. Sensors 2023, 23, 3524. https://doi.org/10.3390/s23073524
Plunk A, Amat AZ, Tauseef M, Peters RA, Sarkar N. Semi-Supervised Behavior Labeling Using Multimodal Data during Virtual Teamwork-Based Collaborative Activities. Sensors. 2023; 23(7):3524. https://doi.org/10.3390/s23073524
Chicago/Turabian StylePlunk, Abigale, Ashwaq Zaini Amat, Mahrukh Tauseef, Richard Alan Peters, and Nilanjan Sarkar. 2023. "Semi-Supervised Behavior Labeling Using Multimodal Data during Virtual Teamwork-Based Collaborative Activities" Sensors 23, no. 7: 3524. https://doi.org/10.3390/s23073524