






AoI-Aware Optimization of Service Caching-Assisted Offloading and Resource Allocation in Edge Cellular Networks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Challenges
1.1.1. Cost of the Task
1.1.2. Bandwidth Consumption of the Application Server
1.1.3. Matching between Wireless Channels and IoT Devices
1.2. Related Work
1.2.1. Offloading with Cache
1.2.2. Cache of Data
1.2.3. Cache of Service
1.2.4. Age of Information
1.3. Contribution
- To minimize the average time overhead cost and energy consumption of inference tasks, we transform the problem into a Lagrangian dual problem. Then, we propose the LMKO module based on the method of Lagrange multipliers with Karush–Kuhn–Tucker (KKT) conditions to make an optimal offloading decision.
- To minimize the required average bandwidth, we transform the problem into a Lyapunov plus penalty problem by minimizing the total required bandwidth while keeping the requesting data queue backlog stable. Further, we propose the LLUC module based on the Lyapunov optimization to derive an optimal dequeued rate.
- To minimize the fetching time of IoT devices, we consider the problem of finding the perfect matching by maximizing the sum of the link weights in the equalling subgraph. Moreover, we propose the KCDF module based on the KM algorithm to obtain the optimal matching decision.
2. System Model
2.1. Task Model
2.2. Communication Model
2.3. Caching Model
2.4. Execution Model
2.5. Energy Model
2.6. Cost Model
2.6.1. Case 1: Offloading with Fresh Cache
2.6.2. Case 2: Offloading with Stale Cache
2.6.3. Case 3: Offloading without Cache
2.6.4. Case 4: Local Execution with Fresh Cache
2.6.5. Case 5: Local Execution with Stale Cache
2.6.6. Case 6: Local Execution without Cache
3. Problem Formulation
3.1. Average Cost Minimization Problem
3.2. Bandwidth Consumption Minimization Problem
3.3. Service Fetching Time Minimization Problem
4. Solution
4.1. Method of Lagrange Multipliers with the KKT Condition-Based Offloading Module (LMKO)
4.2. Lyapunov Optimization-Based Learning and Update Control Module (LLUC)
| Algorithm 1 Method of Lagrange multipliers with the KKT condition-based offloading module (LMKO). |
|
| Algorithm 2 Lyapunov optimization-based learning and update control module (LLUC). |
|
4.3. KM Algorithm-Based Channel Division Fetching Module (KCDF)
- Initialize , , and .
- Enumerate , find satisfies based on the Hungarian algorithm.
- If , add into ; otherwise, calculate the matching distance , set and . Then, change the reachable path into links, e.g., to .
- Repeat 2 and 3 until obtaining of .
| Algorithm 3 KM algorithm-based channel-division fetching module (KCDF). |
|
5. Evaluation
5.1. System Implementation
5.2. Case Study
5.3. Experiment Setup
- Fresh cache offloading priority (FCOP): An algorithm where the mobile device searches a MEC server with a fresh parameter cache and immediately offloads the task.
- Cache offloading priority (COP): An algorithm where the mobile device searches a MEC server with cache and immediately offloads the task.
- Offloading priority (OP): An algorithm where the mobile device searches a MEC server and immediately offloads the task.
- Local execution with fresh cache priority (LEFC): An algorithm where the mobile device executes the task locally if it maintains a fresh parameter cache; otherwise, it offloads the task to a MEC server.
- Queue backlog priority (QBP): An algorithm constrains the penalty weight in a relatively low range of the Lyapunov optimization.
- Total bandwidth priority (TBP): An algorithm constrains the penalty weight in a relatively high range.
- Queue backlog empty (QBE): An algorithm fixes the penalty weight to 0 of the Lyapunov optimization.
- Fixed total bandwidth (FTB): An algorithm fixes the penalty weight in an extremely high value.
- Hungary algorithm (HA) [29]: An algorithm is leveraged to solve the maximal matching problem of a non-weight bipartite graph.
- Channel bandwidth allocated-based size (CBAS): An algorithm where the total bandwidth is allocated based on the responding service data size.
- Channel bandwidth allocated-based case (CBAC): An algorithm where the total bandwidth is allocated based on the requesting offloading case.
- Uniform allocation of channel bandwidth (UACB): An algorithm where the total bandwidth is allocated uniformly.
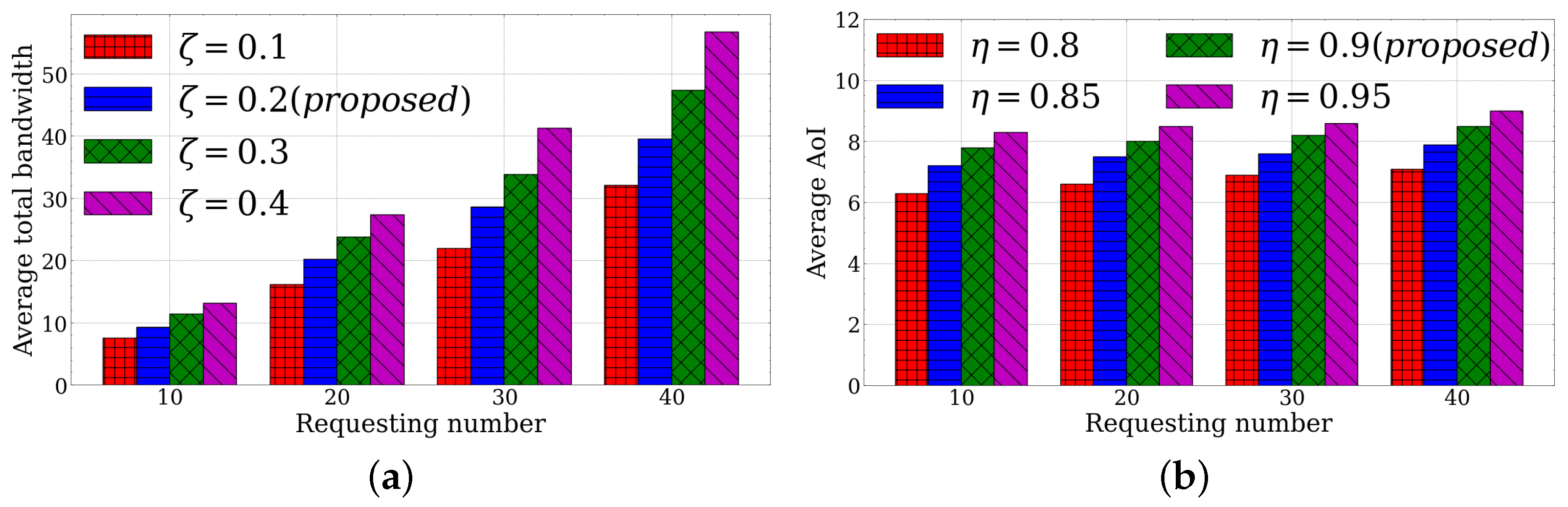
5.4. LLUC Evaluation
5.5. KCDF Evaluation
5.6. Performance Comparison
5.6.1. Average Cost Comparison
5.6.2. Average Total Bandwidth Comparison
5.6.3. Average Fetching Time Comparison
5.6.4. Average Time Cost of Baselines Combination
5.6.5. Average Energy Cost of Baselines Combination
5.6.6. Average Bandwidth Consumption of Baselines Combination
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Feng, J.; Gong, J. Joint Detection and Computation Offloading With Age of Information in Mobile Edge Networks. IEEE Trans. Netw. Sci. Eng. 2022, 1–14. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef] [Green Version]
- Parvez, I.; Rahmati, A.; Guvenc, I.; Sarwat, A.I.; Dai, H. A survey on low latency towards 5G: RAN, core network and caching solutions. IEEE Commun. Surv. Tutor. 2018, 20, 3098–3130. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Zhang, Y.; Wang, L.; Yang, J.; Wang, W. A survey on mobile edge networks: Convergence of computing, caching and communications. IEEE Access 2017, 5, 6757–6779. [Google Scholar] [CrossRef]
- Waqas, M.; Tu, S.; Halim, Z.; Rehman, S.U.; Abbas, G.; Abbas, Z.H. The role of artificial intelligence and machine learning in wireless networks security: Principle, practice and challenges. Artif. Intell. Rev. 2022, 55, 5215–5261. [Google Scholar] [CrossRef]
- Verbraeken, J.; Wolting, M.; Katzy, J.; Kloppenburg, J.; Verbelen, T.; Rellermeyer, J.S. A survey on distributed machine learning. ACM Comput. Surv. 2020, 53, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Kaul, S.; Yates, R.; Gruteser, M. Real-time status: How often should one update? In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2731–2735. [Google Scholar]
- Sun, Y.; Chen, Z.; Tao, M.; Liu, H. Bandwidth gain from mobile edge computing and caching in wireless multicast systems. IEEE Trans. Wirel. Commun. 2020, 19, 3992–4007. [Google Scholar] [CrossRef] [Green Version]
- Ning, Z.; Zhang, K.; Wang, X.; Guo, L.; Hu, X.; Huang, J.; Hu, B.; Kwok, R.Y. Intelligent edge computing in internet of vehicles: A joint computation offloading and caching solution. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2212–2225. [Google Scholar] [CrossRef]
- Yang, X.; Fei, Z.; Zheng, J.; Zhang, N.; Anpalagan, A. Joint multi-user computation offloading and data caching for hybrid mobile cloud/edge computing. IEEE Trans. Veh. Technol. 2019, 68, 11018–11030. [Google Scholar] [CrossRef]
- Guo, H.; Liu, J. Collaborative computation offloading for multiaccess edge computing over fiber–wireless networks. IEEE Trans. Veh. Technol. 2018, 67, 4514–4526. [Google Scholar] [CrossRef]
- Wu, H.; Lyu, F.; Zhou, C.; Chen, J.; Wang, L.; Shen, X. Optimal UAV caching and trajectory in aerial-assisted vehicular networks: A learning-based approach. IEEE J. Sel. Areas Commun. 2020, 38, 2783–2797. [Google Scholar] [CrossRef]
- Ko, S.W.; Huang, K.; Kim, S.L.; Chae, H. Live prefetching for mobile computation offloading. IEEE Trans. Wirel. Commun. 2017, 16, 3057–3071. [Google Scholar] [CrossRef] [Green Version]
- Lyu, F.; Ren, J.; Cheng, N.; Yang, P.; Li, M.; Zhang, Y.; Shen, X.S. LEAD: Large-scale edge cache deployment based on spatio-temporal WiFi traffic statistics. IEEE Trans. Mob. Comput. 2020, 20, 2607–2623. [Google Scholar] [CrossRef]
- Gu, Z.; Lu, H.; Zhu, Z. On throughput optimization and bound analysis in cache-enabled fiber-wireless networks. IEEE Trans. Veh. Technol. 2020, 69, 9068–9082. [Google Scholar] [CrossRef]
- Chen, L.; Xu, J.; Ren, S.; Zhou, P. Spatio–temporal edge service placement: A bandit learning approach. IEEE Trans. Wirel. Commun. 2018, 17, 8388–8401. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Chen, L.; Zhou, P. Joint service caching and task offloading for mobile edge computing in dense networks. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 207–215. [Google Scholar]
- Zhao, T.; Hou, I.H.; Wang, S.; Chan, K. Red/led: An asymptotically optimal and scalable online algorithm for service caching at the edge. IEEE J. Sel. Areas Commun. 2018, 36, 1857–1870. [Google Scholar] [CrossRef]
- He, T.; Khamfroush, H.; Wang, S.; La Porta, T.; Stein, S. It’s hard to share: Joint service placement and request scheduling in edge clouds with sharable and non-sharable resources. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 365–375. [Google Scholar]
- Ma, M.; Wong, V.W. Age of information driven cache content update scheduling for dynamic contents in heterogeneous networks. IEEE Trans. Wirel. Commun. 2020, 19, 8427–8441. [Google Scholar] [CrossRef]
- Xu, C.; Xie, Y.; Wang, X.; Yang, H.H.; Niyato, D.; Quek, T.Q. Optimal status update for caching enabled IoT networks: A dueling deep R-network approach. IEEE Trans. Wirel. Commun. 2021, 20, 8438–8454. [Google Scholar] [CrossRef]
- Zhang, S.; Li, J.; Luo, H.; Gao, J.; Zhao, L.; Shen, X.S. Low-latency and fresh content provision in information-centric vehicular networks. IEEE Trans. Mob. Comput. 2020, 21, 1723–1738. [Google Scholar] [CrossRef]
- Boyd, S.; Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Davis, D.; Drusvyatskiy, D.; Kakade, S.; Lee, J.D. Stochastic subgradient method converges on tame functions. Found. Comput. Math. 2020, 20, 119–154. [Google Scholar] [CrossRef] [Green Version]
- Neely, M.J. Stochastic network optimization with application to communication and queueing systems. Synth. Lect. Commun. Netw. 2010, 3, 1–211. [Google Scholar]
- Kuhn, H.W. Variants of the Hungarian method for assignment problems. Nav. Res. Logist. Q. 1956, 3, 253–258. [Google Scholar] [CrossRef]
- Mills-Tettey, G.A.; Stentz, A.; Dias, M.B. The Dynamic Hungarian Algorithm for the Assignment Problem with Changing Costs; Tech. Rep. CMU-RI-TR-07-27; Robotics Institute: Pittsburgh, PA, USA, 2007. [Google Scholar]
- Li, H.; Wang, P.; Shen, C. Toward end-to-end car license plate detection and recognition with deep neural networks. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1126–1136. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, J.; Gong, J. AoI-Aware Optimization of Service Caching-Assisted Offloading and Resource Allocation in Edge Cellular Networks. Sensors 2023, 23, 3306. https://doi.org/10.3390/s23063306
Feng J, Gong J. AoI-Aware Optimization of Service Caching-Assisted Offloading and Resource Allocation in Edge Cellular Networks. Sensors. 2023; 23(6):3306. https://doi.org/10.3390/s23063306
Chicago/Turabian StyleFeng, Jialiang, and Jie Gong. 2023. "AoI-Aware Optimization of Service Caching-Assisted Offloading and Resource Allocation in Edge Cellular Networks" Sensors 23, no. 6: 3306. https://doi.org/10.3390/s23063306