1. Introduction
As large-scale 3D models are the basis for smart cities, there has always been an urgent need for digitizing large-scale scenes. There are a number of applications and research fields that can benefit from 3D models of large-scale scenes, including digital cities, virtual reality, augmented reality and digital twins. However, rapidly reconstructing high-quality, large-scale 3D scene data remains a difficult task in computer vision and graphics research. First, as the scale of the scene increases, the number of input images increases significantly.
When using a single computational node, 3D reconstruction will exceed its own computational and storage capacity, leading to the failure of large-scale-scene 3D-reconstruction tasks. Additionally, in large-scale 3D reconstruction, it is assumed that even if a single computing unit could complete the reconstruction task, the vast amount of data would often lead to a longer computing time.
Finally, the scale of the 3D data of the reconstructed large-scale scene needs to be increased, thereby, resulting in a high degree of data redundancy and a significant number of noise problems, which is not conducive to the expression and rendering of 3D data. To address the problem of large-scale 3D-scene reconstruction that a single computing node cannot handle, we propose a cluster-based camera-graph-structure clustering algorithm and a cluster-based global camera pose-registration algorithm. All camera positions are converted into graph-structured nodes, and several strongly correlated camera subsets are constructed using graph-structured partitioning.
A reasonable subset of the parallel computational data is assigned to each computational node in the cluster. The overlapping camera information among the subgraphs is used to optimize and complete the task of registering global camera positions. In conclusion, our proposed algorithm relies on a divide-and-conquer framework to break through the limitations of a single computational node and uses a cluster approach to handle the 3D-reconstruction task of large-scale scenes. To maximize the utilization of computational resources on a single computational node, we propose a GPU parallel depth-estimation algorithm based on patch matching in the dense point-cloud reconstruction phase to assess the candidate solutions’ merit using an improved normalized correlation score.
During the iterative process, the search neighborhood size is continuously adjusted according to the distribution location of the solutions to accelerate the convergence speed further. This reduces the time needed to solve the dense reconstruction problem on a single computational node and alleviates the time-consuming problem of depth-map estimation when reconstructing dense point clouds of large-scale 3D scenes. The 3D reconstructed mesh has disadvantages, including data redundancy, a non-uniform structure, spatial noise and non-fine detail features. We propose a 3D mesh-optimization method based on cluster geometric detail recovery.
First, we simplify the mesh to maintain the detailed features of the model while reducing the redundancy of the mesh model as much as possible. Secondly, in the process of mesh smoothing, we propose a mesh-smoothing homogenization algorithm based on the second-order umbrella operator, which makes the triangular surface slices regular and uniform, thus, reducing the noise and anomalies of the mesh. Finally, we construct an energy function using the image color-consistency term and the Laplacian smoothness term, which not only removes noise and outliers but also restores the detailed features of the mesh.
Based on the above method, our developed large-scale 3D modeling system, BHReconstruction, realizes the need for cluster-based, high-efficiency reconstruction of large-scale 3D scenes. BHReconstruction supports exporting mainstream 3D model formats and the real-time rendering of 3D models, thereby, meeting the needs of further applications, such as surveying and mapping, 3D maps, digital cities, digital cultural relics, virtual reality and augmented reality. BHReconstruction consists of three modules: the reconstruction configuration module, 3D-reconstruction module and rendering module.
Our system provides two modes for different users: (1) simple mode, which only needs to configure the basic options to achieve one-click reconstruction of large-scale 3D scenes and (2) expert mode, which provides detailed parameter settings to meet the specialized 3D-reconstruction needs of professionals who have mastered 3D-reconstruction theory.
In summary, this study makes the following contributions to the existing literature:
We propose a cluster-based method for clustering the camera graph algorithm. A divide-and-conquer framework is used to precisely partition the camera graph into several subsets. The algorithm ensures weak correlations between subsets and strong correlations within subsets, which allows the subsets to perform in parallel local camera pose-estimation tasks on cluster nodes.
We propose a cluster-based global camera pose-alignment algorithm. Using the overlapping camera positions between each subgraph for global camera pose fusion, we mainly solve the nonlinear optimization problem of rotation and translation in the camera pose to obtain a more accurate global camera pose.
We propose a GPU parallel fast depth-estimation method based on patch matching. The candidate solutions are measured by an improved normalized correlation score, which makes the parallel estimation of image depth values more efficient.
We propose a cluster-based mesh optimization for the geometric detail-recovery method, which uses the proposed second-order umbrella operator to enhance the mesh’s uniformity and increase the mesh model’s fidelity.
Compared with similar open-source libraries and commercial reconstruction software, our system can reconstruct large-scale city-level 3D scenes in a cluster environment with one click and has a faster 3D-reconstruction speed within a certain reconstruction quality.
3. System Design
3.1. Overall Structure
To solve the problems in large-scale scene 3D reconstruction, we propose four methods to improve the speed and quality of large-scale 3D reconstruction and integrate these algorithms into our system.
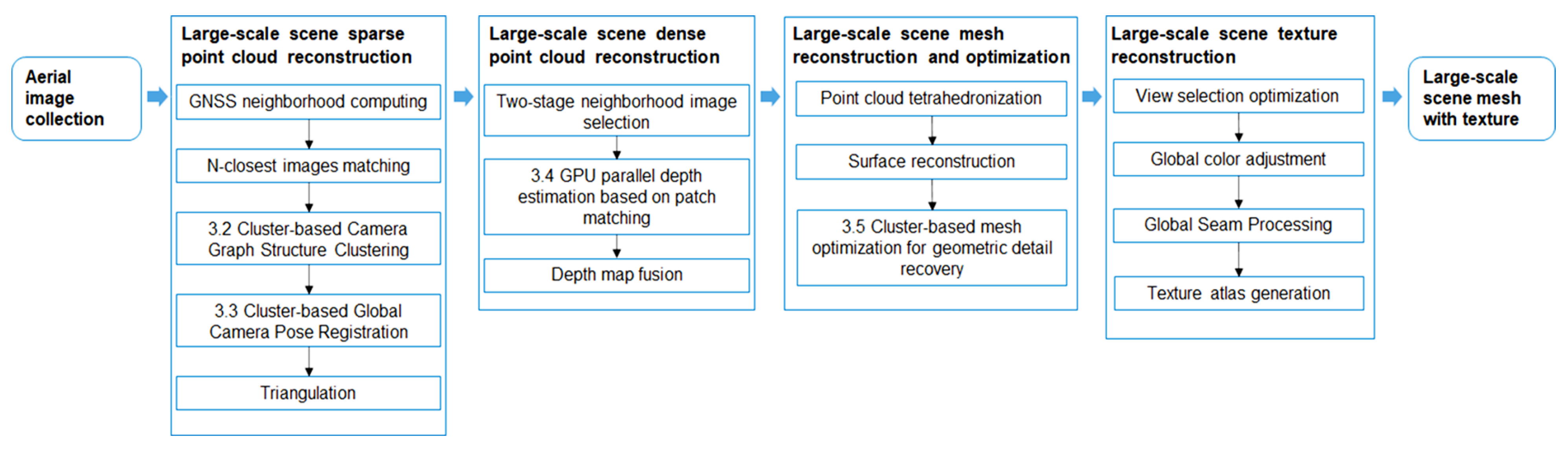
Figure 1 shows the 3D-reconstruction pipeline of our system.
The data on the input side of the system are images taken by unmanned aerial vehicles (UAVs) from large-scale scenes. In the large-scale-scene sparse point-cloud reconstruction module, the time complexity of image matching is optimized to be approximately linear through the global navigation satellite system (GNSS) neighborhood computing step, which initially filters each image’s neighbors based on spatial location gathered from GPS information. Cluster-based camera graph structure clustering (
Section 3.2) and cluster-based global camera pose registration (
Section 3.3) are utilized to obtain the global camera pose and perform triangulation and optional bundle adjustment to obtain a sparse point cloud for large-scale scenes.
In the dense point-cloud reconstruction module for large-scale scenes, the two-stage neighborhood image selection method is adopted to ensure that the subsets of neighborhood images are uniformly distributed and that the image content is representative. In addition, GPU parallel depth estimation based on patch matching (
Section 3.4) is used to estimate the depth of all views quickly. Finally, the depth map fusion method generates dense point clouds of large-scale scenes.
Our large-scale mesh reconstruction and optimization module obtains the mesh model by using point cloud tetrahedron and surface reconstruction methods, followed by a cluster-based mesh-optimization method for geometric detail recovery (
Section 3.5), which produces a mesh model with low redundancy and recovers details from a large-scale scene. We go through several steps in the large-scale-scene texture reconstruction module, including view selection optimization, global color adjustment, global seam processing, and texture atlas generation. As a final step, the system produces a mesh model with texture.
3.2. Cluster-Based Camera Graph Structure Clustering
The required number of camera poses grows proportionally with the amount of photos used as input. If all camera poses are directly calculated, a single computing node’s resource limit will be exceeded, and the execution will fail. Additionally, due to the constraints of collecting large-scale-scene data, some cameras have inadequate image-matching relationships, leading to the elimination of these cameras as external points and to a subsequent drop in the quality of the 3D reconstructed models, or to the emergence of holes and other issues. We present a camera graph clustering method based on graph partitioning that clusters all input cameras into multiple camera subsets based on their matching relationship.
Each subset consists of cameras from the same category, ensuring a low correlation across subsets and a high correlation within subsets. Separate camera categories conduct local camera pose estimations in parallel on different cluster computing nodes, ensuring the quality and efficiency of the reconstruction.
3.2.1. Normalized Cut Algorithm
The fundamental rule of camera graph partitioning for large-scale-scene 3D reconstruction is that the number of cameras in each cluster is comparable and controllable. We present a normalized partitioning to handle the problem of clustering camera graph nodes in large-scale scenes. The approach takes into account the partition value and the node’s degree of connectedness, and a normalized cut [
80] function is built:
where
is the partition value defined by the minimum cut algorithm and
is the sum of the connecting edge weights of node A and every other node in the camera network structure. Using the ratio of
to the degree of connection before cut
as the standard of normalized segmentation can prevent a small number of points from being cut during the minimum partitioning. If a single node is cut to create a subgraph, the ratio equals 1, but it is not the minimum value of the normalized cut value. Consequently, a normalized cut can alleviate the issue that the minimal partitioning is not consistent within subgraphs and is sensitive to external points.
3.2.2. Camera Graph Division
After extracting and matching the image feature points of a large-scale-scene image set, the matching relationship between each image may be determined, allowing the camera graph structure to be formed, where each vertex in the set V represents an image or camera position. The edge connecting two vertices in set E demonstrates a matching relationship between two photos. In this study, the number of matching feature points between two pictures is represented by the edge weight , where i and j represent two nodes.
Using all the nodes, edges and edge weights in the camera graph
G as input, the normalized cut algorithm may break the camera graph into two subgraphs. Consequently, the original camera graph can be subdivided into
k subgraphs by conducting normalized segmentation iteratively on the subgraphs. If there are an excessive number of subgraph nodes, the task of computing the camera’s position will surpass the resource limit of a single computing node. Conversely, if there are insufficient subgraph nodes, more image-matching associations will be severed, and more compute nodes would lose data transmission. In light of the use of computational resources and the integrity of the image-matching connection, the segmented subgraph must satisfy the following conditions:
where
represents the set of all subgraphs after partitioning,
and
stand for the subgraph,
represents the number of vertices in the subgraph, and
represents the threshold value of the number of cameras in the subgraph.
Our strategy can fully exploit the benefits of clusters. If the cluster contains n compute nodes, the original camera graph should be partitioned into at least n subgraphs, and then the normalized cut process should be repeated until the partition requirement is satisfied. The partitioning procedure resembles a tree structure. The normalized cut algorithm guarantees that the number of nodes in each layer is comparable. Each partition selects the subgraph with the greatest number of nodes from the root node.
The original camera graph can be partitioned into numerous subgraphs G based on the cluster resources and the number of input images using camera graph partition. All subparagraphs comprise subparagraph set . Consequently, the existing relationship is .
3.2.3. Camera Graph Expansion
The original camera graph is separated into many camera subgraphs once the camera graph is divided and no coincidence is found between them. However, overlapping cameras between subgraphs are required to perform the future 3D-reconstruction task, and the subgraphs after the camera graph partition should be enlarged accordingly. Specifically, each subgraph does not have to share points with all other subgraphs. It is worth noting that the coincidence ratio between subgraphs is guaranteed to allow each subgraph to be fused.
We define the camera block graph structure
, where each node represents a subgraph and the edges between nodes indicate the cut edge set between subgraphs. The weight of an edge is the sum of the weights cut between subgraphs divided by the total number of nodes in the two subgraphs. In a block graph, the weight of the edge connecting subgraphs A and B can be written as:
where
denotes the division between subgraphs
A and
B.
and
indicate the number of nodes in subgraphs
A and
B, respectively.
In the camera graph expansion, excessive redundancy will develop if each subgraph restores the cut edges between all its surrounding subgraphs. In addition, low-weighted matching relationships are susceptible to wrong camera postures, resulting in faulty camera posture registration. Consequently, based on the concept of a maximum spanning tree, we build the maximum spanning tree of the camera block diagram and extend the camera diagram based on the obtained edges.
First, a weighted undirected graph adjacency matrix that includes all vertices and edges from the original camera graph, i.e., all image-matching associations, is maintained. The elements in the adjacency matrix’s row i and column j denote the number of image-matching feature points for images i and j, where there is a value of 0 if no matching relationship occurs. To satisfy the query requirements with constant time complexity, save the adjacency matrix in a hash table.
Secondly, based on the information of the adjacency matrix and the vertex labels in the subgraph, it is simple to obtain all the edges that have been cut as a result of the normalized splitting and apply the inverted approach to rank all the cut edges from a heavy to light weight. By querying the adjacency matrix in pairs using the sequence numbers of all nodes between subgraphs A and B, it is possible to determine the values between subgraphs.
Finally, the ratio of of subgraphs A and B to the total number of nodes in both subgraphs and is utilized as the edge weight of the camera block diagram, that is, , ensuring that edges with higher weights have a higher quality image-matching relationship.
Camera graph expansion does not require the restoration of all severed edges. In addition, there may be numerous subgraph extensions whose stop condition is that all the severed edges are restored, resulting in a reduced overall expansion ratio and insufficient matching relationships. Therefore, we define the extension condition as follows:
where
represents the number of new vertices that contribute to the expansion, and
represents the number of images present before the expansion of the subgraph.
represents the expansion scale, with values typically ranging from 0.5 to 0.7. Expansion stops when the scale of expansion vertices is equal to or greater than that scale, or when all severed edges between subgraphs have been restored.
3.3. Cluster-Based Global Camera Pose Registration
The registration of camera posture is a vital stage in motion recovery structure technology. The precision of the camera pose has a direct effect on the precision of the reconstruction of 3D sparse point clouds. Since the registration of camera poses necessitates simultaneous computation of all camera rotation matrices and translation vectors, it is time-consuming and frequently exceeds the memory limit of computing nodes. This section proposes a quick and precise camera pose averaging approach for combining and optimizing the camera pose of each subgraph.
Similar to [
81], a camera pose fusion method based on similarity transformation is employed to unify the local camera poses of the preceding subgraphs in order to generate a global camera pose coexisting in the same world coordinate system. The following function converts between the two camera poses:
where
and
represent the rotation and translation of camera
i.
and
represent the rotation and translation of camera
j. The relative rotation and translation between cameras i and j are denoted by
and
, respectively.
and
can be inferred to be:
These calculations demonstrate the conversion between two camera poses. The relative rotation and translation of two cameras can be determined based on their camera poses in their respective world coordinate systems. Using the similarity transformation method, global rotation and global shift fusion are performed, and the combined camera poses are optimized using nonlinear optimization to obtain correct global camera poses.
3.3.1. Global Rotation Registration
After camera graph expansion, the overlapping camera set created by two camera sets
and
is denoted as
. Initially, using the similarity transformation approach, the relative rotation of each camera in the camera set is computed. The global rotation of the coincidence camera in
is therefore fixed, and the relative rotation of the camera in camera set
, with respect to all other cameras, is utilized. The final formula for calculating the global rotation of all cameras in
in the coordinate system of
is as follows:
where
represents the camera rotation of the cameras in camera sets
and
following the fusing of their coordinate systems.
represents the rotational relationship between the coincident camera
and the other cameras in the set
. Likewise,
represents the camera rotation of the corresponding camera
in set
.
In our method, the rotation fusion of two camera sets, and , is accomplished by securing a coincident camera, . Consequently, it is necessary to select the most precise coincident camera as the reference camera for the camera rotation fusion of the two camera collections. Since we compute all camera rotations belonging to the camera set, with the exception being the reference camera, some coincident cameras may be calculated several times. These constantly calculated camera rotations serve as the evaluation criteria for inaccuracies. We set as the outcome of the calculation for the rotation of coincident cameras, excluding the reference camera.
The rotation of that coinciding camera in camera set is set to , and the error is determined as the Euclidean distance between and the matrix. Through iterative calculation, a specific reference camera is chosen to minimize the sum of errors between the rotations of all coincident cameras and the initial rotation. Theoretically, we believe the fixed camera to be the most accurate reference camera, and this camera serves as the reference for global rotation and the fusion of the two camera sets.
3.3.2. Global Rotation Registration
Each camera subgraph performs a local estimation of the camera’s position, resulting in translations with varying translation scales. The translation scale has no effect on the global rotational fusion problem described in
Section 3.3.1. Nonetheless, the fusion of global translations necessitates the computation of the scale value of the local translation vector in each subgraph. Using the similarity transformation approach, the relationship between the translation vectors of two cameras belonging to a collection of coincident cameras in the same coordinate system can be determined.
where
and
are the camera 1 and 2 translation amounts from subgraph 1, and
and
are the camera 1 and 2 translation amounts from subgraph 2.
and
represent the relative translation between camera 1 and camera 2 in subgraph 1 and 2, respectively. The preceding Equations (
9) and (
10) describe the translation of two identical cameras in two distinct coordinate systems, and their relative rotation is denoted by
.
All coincident cameras are grouped into
camera pairs in
, where
. Each camera pair’s scale is computed as
. Then, based on the following formula, the precise scale of the two cameras’ coordinates is obtained:
We directly utilize the reference camera from the global rotation fusion task for the global translation fusion. The reference camera is
in the current coordinate system and
in the target coordinate system.
and
in the current and target coordinate systems, respectively, represent the camera to be fused.
indicates the rotational relationship between the reference camera and the other cameras. The pertinent formula for the camera translation fusion method is as follows:
First, using Equation (
12), we determine the relative shift
between the
of the camera to be processed and the
of the reference camera. Then, the base camera translation
is transformed to the target coordinate system translation
. Finally, the global translation vector
in the target coordinate system is computed using Equation (
13) and the obtained translation scale
.
This section discussed the method of fusing two camera subgraphs. Our method does not necessitate overlapping subgraphs but rather ensures that, for each merging, each new subgraph has a coincidence relationship with the merged camera cluster.
3.3.3. Optimization of Camera Poses
If the coarse precision global camera pose information is directly entered into the subsequent reconstruction module following the global camera pose fusion, the reconstruction details will be significantly flawed. Therefore, we optimize all camera poses in the same global coordinate system in order to obtain more precise and reliable global camera poses.
The relative rotation and relative shift obtained by performing local camera pose estimation on each subgraph are saved and recorded as
and
, respectively. The global rotation and global shift set of all cameras after global camera pose fusion are recorded as
,
. The following optimization formulas are defined:
where
denotes the angular distance,
denotes the Euclidean distance, and
P takes a value of 2 to denote the
paradigm.
Due to the estimation of the relative rotation and translation based on the local camera location of each subgraph, the relationship between subgraphs can be ensured to have the benefit of normalized segmentation. In other words, the blocks are highly interconnected. Taking these close correlations and as inputs not only eliminates the need to calculate the relationships between all camera poses but also optimizes the overall global camera pose. The global solid camera pose is derived by optimizing the above formula iteratively. The subsequent reconstruction pipeline generates sparse point clouds by triangulation and obtains more accurate camera pose and sparse point cloud results through bundle adjustment.
3.4. GPU Parallel Depth Estimation Based on Patch Matching
During the dense reconstruction phase of the point cloud, we may still utilize the method outlined previously to compute the smaller dense reconstruction tasks in parallel on each cluster node. The dense point-cloud reconstruction method using depth map fusion is ideally suited for GPU-based parallel computation. Therefore, in this part we propose a GPU parallel fast depth-estimation method for a single computing node, which completely uses the computing resources of a single node and reduces the reconstruction time of dense point clouds on a single computing node.
3.4.1. Random Initialization of the Depth Normal Vector
Our first step is to randomly establish the normal depth vector, whose primary activity is to randomly initialize a collection of possible values for each pixel point in the input reference picture
. Due to the localization of the continuous variation of the image’s photometric information, the problem of estimating the depth value
Z is transformed into the problem of estimating the support plane
f, which is described as follows:
where
n is the normal vector supporting the plane and
d is the distance between the center of the plane
O and the center of the reference camera
. It is possible to translate the pixel coordinates
in the ith image to the 3D point
in the ith camera coordinate system, and its relationship to the depth value
Z is given by
.
Typically, the depth of a camera-captured image varies nonlinearly. In particular, the depth distribution is dense around the light’s center and sparse the more distant it is from the camera. The depth value conforms to the features of a dense distribution when close and a sparse distribution when far away. The values for parallax and depth satisfy the following formulas:
B is the camera baseline distance, and
F is the focal length.
is the parallax value, which satisfies the uniform distribution of
.
and
use sparse point clustering
S estimates while expanding the value space to increase the range of random initialization values for
d and to ensure coverage of the entire scene depth range where
is double:
This changes the problem of depth estimation into one of planar parameter estimation. The random initialization method is used as described above to provide a fair distribution of normal vector n, which is the distance d between the center of the camera and the center of the supporting plane.
3.4.2. Cost Assessment Based on Patch Matching
Next, we analyze possible solutions using an enhanced patch-matching method. A square neighborhood pixel set is defined with the pixel p as the center and the radius r as the patch W. Assuming that all of the pixels in a patch block are on the same support plane f, the homography rule is satisfied between the patch blocks of two adjacent images.
Homography is used to map each pixel
in the patch block of the reference image to the matching point
in the neighborhood image. This part does not directly calculate the feature difference between two adjacent pixels in order to improve the robustness of the similarity calculation. Instead, to calculate the similarity of patch blocks, the NCC approach is used [
50]. Pixels
and
should correspond to the same position
X in the 3D scene if the proposed solution is true. Due to the local nature of the image, the similarity between patches should be strong.
The similarity score computed by NCC is essentially the deformed correlation coefficient. Here, we specify [0, 1] as the value range. To reduce the influence of extreme values, separate weights are provided for each pixel of patch block
W based on its physical distance from the central pixel and the difference in texture information. This section measures the correlation between pixel
b and the central pixel
p in patch block
W using bilateral weights:
As the NCC approach solely evaluates photometric data, it is significantly affected by variations in local illumination. To tackle the problem of similarity measurement failure caused by the change in brightness information resulting from visual angle translation, the picture gradient information item is added to the similarity measurement algorithm.
In this section, we estimated the confidence of candidate solutions using the modified NCC technique, which is simple for quick parallel calculations and is stable for measuring the benefits and drawbacks of candidate solutions.
3.4.3. GPU Parallel Depth Map Generation and Optimization
The GPU architecture is an infrastructure that is more suited for multi-core parallel computing, since it has a large number of cores and can handle the simultaneous processing of a huge amount of data as compared to the CPU architecture’s strong scheduling management and coordination capability. Numerous techniques [
82,
83,
84] have adopted the propagation mode of a red-and-black checkerboard grid by partitioning the image pixels into groups via a red-and-black checkerboard, and sampling the adjacent pixels through diffusion.
To limit the influence of extreme values and increase the method’s robustness, the current pixel solution is built using k-candidate solutions with the smallest cost loss. In the adaptive neighborhood,
k candidate solutions with the lowest cost loss are chosen for each pixel point
p. Using the cost evaluation method in
Section 3.4.2, the cost loss of the
k candidate solutions in the
n neighboring view angles is recalculated to yield the loss matrix
M.
It can be assumed that a particular view angle of pixel
p does not satisfy the photometric consistency assumption due the presence of object occlusion and similar conditions. In such a scenario, the cost losses of
k potential options become considerable. In contrast, there will be at least one candidate solution with a minor cost loss from an excellent neighborhood perspective, and the cost loss from a good neighborhood perspective will decrease gradually as the number of iterations increases. The permissible cost’s upper bound for iteration
t is defined as follows:
where
is the upper bound of the initial cost and
is a constant. The threshold
is defined as the greatest cost loss and the cost loss
is the
i-th potential solution from the
j-th perspective. If
is matched, the
i-th candidate solution is a superior solution from the
j-th perspective, and it is added to the set
. If
is matched, the
i-th candidate solution is added to the set
as an incorrect solution at the
j-th view. If the number of better solutions of the
j-th view is greater than
and fewer than
, we consider the
j-th view to be the better neighborhood image of the pixel in the
t-th iteration and add it to the neighborhood image set
of the pixel.
Despite the fact that photos with uneven brightness are eliminated by setting the threshold TB, each neighborhood image will contribute varied weights to the results due to noise, scale and other variables. The following weights are applied to each neighborhood image, given that
is a constant.
Due to issues, such as occlusion, weak texture and lighting conditions, it is impossible to ensure the correctness of the depth map estimate in natural scenes when solely using the photometric consistency assumption. In light of this, we introduce the geometric consistency assumption while maintaining the photometric consistency assumption. It is believed that the 3D point recovered using the depth information of the pixel p in the reference image is identical to the 3D point restored using the depth information of the corresponding point in the neighboring image.
We employ the reprojection error metric to satisfy the degree of geometric consistency constraint, assuming the depth of the pixel
p equals
. The formula for the point
corresponding to the j-th neighborhood image is as follows:
To obtain a pixel
, the pixel
projection that refers the image back in the same manner based on its depth value
is:
The definition of the reprojection error
of the
i-th candidate solution at the
j-th viewing angle is:
In order to improve the robustness of the reprojection error and tackle the excessive error generated by masking and other factors, it is necessary to increase the error resistance. We select the ideal solution from the candidate solutions based on the photometric geometric consistency cost
, where
is a constant.
From the
k candidate solutions, the average value of the
n candidate solutions with the lowest cost of photometric geometric consistency is chosen as the new solution. During the entire photometric geometric consistency-solving procedure, only the current pixel and the candidate solution pixel are utilized. The parallel calculation at the pixel level can be performed by combining the red-and-black checkerboard sampling method described in
Section 3.4.1.
Using the random initialization method described in
Section 3.4.1, we reintroduce a set of random solutions
for each pixel. The random solution is independent of any prior knowledge. It is chosen with equal probability over the whole solution space, essentially preventing the approach from settling on the optimal local answer. Using the perturbation method, we construct another set of perturbed solutions
. The disturbance solution is dependent on the now-achieved ideal solution, and the result is refined by searching in close proximity to the optimal solution.
Then, we utilize the Eulerian angle to represent the rotation disturbance of the normal vector and uniformly sample the Eulerian angle within
to produce the disturbed normal vector
. Finally, using the random solution, the perturbed solution and the current solution, we recombine them into nine new solutions as follows:
The preceding nine solutions are candidate solutions chosen in
Section 3.4.2, and the
k value is set to nine. The multi-candidate solution joint depth-estimation method is re-executed, and the final solution provided is considered the method’s optimal solution.
3.5. Cluster-Based Mesh Optimization for Geometric Detail Recovery
We rebuilt large-scale 3D mesh models using a mesh generation method [
85] based on Delaunay point cloud tetrahedralization. Due to redundant data, an uneven structure, a high level of spatial noise and imprecise mesh details, this section provides a mesh-optimization strategy for large-scale mesh scenarios based on cluster geometry detail recovery. The method consists of three main steps: the first step is mesh simplification, which focuses on maintaining the model’s detailed features while minimizing the mesh model’s redundancy.
The second step is mesh smoothing. To effectively eliminate the noise and outliers of the mesh, we propose a mesh-smoothing homogenization method based on the second-order umbrella operator, which makes the mesh regular and homogeneous. The last step is mesh-detail recovery. As a result of combining the image color-consistency term and the Laplace smoothing term, we construct an energy function that further removes noise and outliers while recovering more detailed features of the mesh.
3.5.1. Mesh Simplification
To ensure that the generated mesh model meets the accuracy requirements, the reconstruction process as a whole uses a very high resolution to retain as much of the input information as possible. This causes the data amount of the generated mesh model to increase rapidly as the reconstruction range expands. Nonetheless, a significant number of redundant meshes will cause the subsequent texture reconstruction to take an excessive amount of time and memory. On the basis of maintaining the accuracy and realism of the grid model, the complex mesh model will be replaced with a reduced mesh model, thereby enhancing the model’s operational efficiency.
The majority of mesh simplification algorithms [
59,
60,
61,
62] not only lower the amount of model data, but also fail to preserve the model’s detailed features, resulting in a reduction in the mesh model’s realism. Consequently, the complexity of different sections of the mesh model must be taken into account, and varying degrees of simplification are applied based on the region’s characteristics in order to preserve the model’s details.
Inspired by Jiang et al. [
65], we employ a feature-preserving-based mesh-simplification method, which differs from the QEM mesh-simplification method in that the semantic information of the mesh vertices, the vertex first-order neighborhood triangular patch area, the approximate vertex curvature, the average shape of the vertex first-order neighborhood triangular patch, and the position of the vertex pair in the model are introduced to enhance the new vertex replacement cost calculation method. Simultaneously, the replacement cost of new vertex pairs located on the local detail-rich surface of the model and the vertex pairs located on unrelated objects is increased, thereby preventing these vertex pairs from being selected as simplified objects and preserving the local characteristics and authenticity of the mesh model.
3.5.2. Mesh Smoothing
Although the mesh-smoothing method based on Laplace’s theorem can reduce the roughness of the model surface, make the mesh model surface smooth and effectively reduce the impact of noise points on the model quality of dense point-cloud data, there is a more effective way to reduce the impact of noise points on the model quality. However, after multiple iterations of this procedure, the model will become more visibly deformed, and the mesh model will decrease, diminishing the realism of the object.
We present an approach for smoothing homogenization based on a second-order umbrella operator. The fundamental idea is to modify the coordinates of the vertices by referencing the position adjustment of vertices in the first-order neighborhood to minimize the model distortion that results from the adjustment of vertex coordinates. The movement direction of the vertex is closer to the projected gradient along the vertex’s corresponding tangent plane, resulting in a more regular and uniform triangular patch.
In the mesh-smoothing approach, the Laplacian smoothing algorithm has a high operation efficiency, and the smoothing process applies the umbrella operator to the mesh iterative vertex movement. The computation procedure can be expressed by the following equation:
where
is the input initial mesh model to be processed and
is the iteratively moving vertex constraint term. The iterative process, i.e., the Laplace operator, can be stated using the following equation:
where
t indicates the number of smoothing rounds,
represents the mesh model after
t rounds of smoothing, and
represents the radical smoothing degree. A large value suggests a more extreme mesh-smoothing degree. As demonstrated in the following equation, the 3D Cartesian coordinates of each mesh vertex are converted into the appropriate Laplace coordinates
.
where
v represents the 3D Cartesian coordinates of the mesh model’s vertices and
indicates their corresponding Laplace coordinates.
indicates a vertex in the vertex’s first-order neighborhood.
is the set of all vertices in vertex
v’s first-order neighborhood.
represents the weight of vertex
in the calculation of the Laplace coordinates of vertex
v.
is used to normalize the weighted combination of the vertices’ 3D coordinates in the first-order neighborhood.
Since several iterations of the Laplacian mesh-smoothing approach are employed, the model will undergo evident deformation, and the mesh model will contract as a whole. We describe a method for mesh smoothing and homogenization based on a second-order umbrella operator that can solve mesh deformation and contraction issues and make the mesh transition between different regions smoother. Our proposed second-order umbrella operator is depicted in Equation (
32).
where
is the second-order umbrella operator and the weight
of the vertex
in the first-order neighborhood is set with the cotangent weight and normalized by
. Equation (
33) illustrates the improved iterative computation approach for vertex coordinates.
When the parameter is less than 1, it is considered a balance parameter. A greater value of implies that each iterative calculation tends to lessen the interference of noise points, resulting in a smoother surface on the mesh model. A decreasing value suggests that each repeated calculation tends to produce a mesh model of triangular patches that is more uniform and regular.
3.5.3. Mesh-Detail Recovery
The mesh-simplification approach and the mesh-smoothing method can improve the mesh quality of the model by eliminating mesh redundancy; however, they only process the details of the mesh’s features, which may result in a mesh that lacks visual realism. In this phase, we optimize the mesh vertex position adjustment and restore the model with more details, which is one of the most crucial steps and improves the quality of the final created model.
To eliminate the noise of the initial mesh and restore the mesh’s detail features, we utilize the photo color consistency and Laplacian smoothing approach to develop an energy formula that comprises the following data items and smoothing terms:
where
is the k-th image dataset’s data item and
is the smoothing term’s weight. To minimize the energy equation, we generate a gradient vector corresponding to the mesh’s vertices and shift the vertices to the gradient vector until convergence. The image data item is constructed according to the image’s color consistency and is meant to restore the mesh’s intricate details. The smoothing term is derived from the Laplacian operator in order to reduce the image’s noise and improve the quality of the mesh.
The picture data item is produced based on the image’s color consistency. Our goal is to minimize the image reprojection error between image pairings by projecting the pixel points from image
onto image
and then calculating the total color consistency of the pixel point and its nearby pixel points. Consequently, this data item is formatted as follows:
where
is the reprojection of image
onto image
through the mesh and
and
are the processes of projecting and back-projecting image I onto the mesh, respectively.
is a decreasing function of the color consistency at pixel
of images
and
.
is the region where the image
is reprojected to the image
. Equation (
35) describes the degree of correspondence between the two images and the triangular mesh. The greater the mesh inaccuracy, the greater the
value.
Equation (
35) must be discretized because it is continuous while the mesh is discrete. Assuming the two pictures are
and
and
, the following equation may be derived:
Any vertex
can be viewed simultaneously by the images
I and
J. Images
I and
J are matched pairs that satisfy the equation below:
where
N is the normal vector of the point
x perpendicular to the outward direction of the curved surface,
is the vector of the camera’s center facing point
x, and
is the depth of x in the camera
i’s coordinate system. According to Equation (
38), the following formula can be derived:
where
H is the abbreviation for the
function,
is the function of the Jacoby matrix, and
is the partial derivative of function
with respect to image
J. According to the aforementioned Formula (
39), for every vertex
, the barycenter coordinate of the triangle is
.
Equation (
40) computes the gradient of each vertex corresponding to the discrete triangular mesh in order to change the vertex location along the gradient direction. The appeal process reduces the inaccuracy of the picture color consistency, increases the degree of matching between the image and the mesh and then restores the detail features of the mesh.
Since errors remain in the obtained picture data, we add a smoothing component based on the image color consistency to reduce the influence of image noise on the mesh and boost the mesh’s smoothness. The calculation is as follows:
where
and
are the major curvatures of the mesh surface at the same vertex and the smoothing term measures the entire mesh’s curvature to make it smooth. We construct the smoothing term using the Laplacian smoothing approach. Since the mesh was already smoothed as described in
Section 3.5.2, we merely employ the more efficient first-order umbrella operator. The final gradient vector and iterative formulas are as follows:
In Equation (
43),
represents the increment size. We can move the vertices iteratively in accordance with the equation until the requirement
is satisfied. The iteration is convergent and restores every detail feature in its entirety.
5. System Usage Information
This section demonstrates the use cases of the simple and expert modes in our reconstruction system from the user’s perspective. Simple mode means that the user does not need any expertise and only needs to set the input and output paths, work paths, cluster task-assignment parameters and quality parameters. This enables the user to complete partial and overall reconstruction tasks. Expert mode is meant for users that have some expertise in reconstruction algorithms and can set detailed parameters for each reconstruction job to complete a professional custom reconstruction project.
5.1. Simple Mode
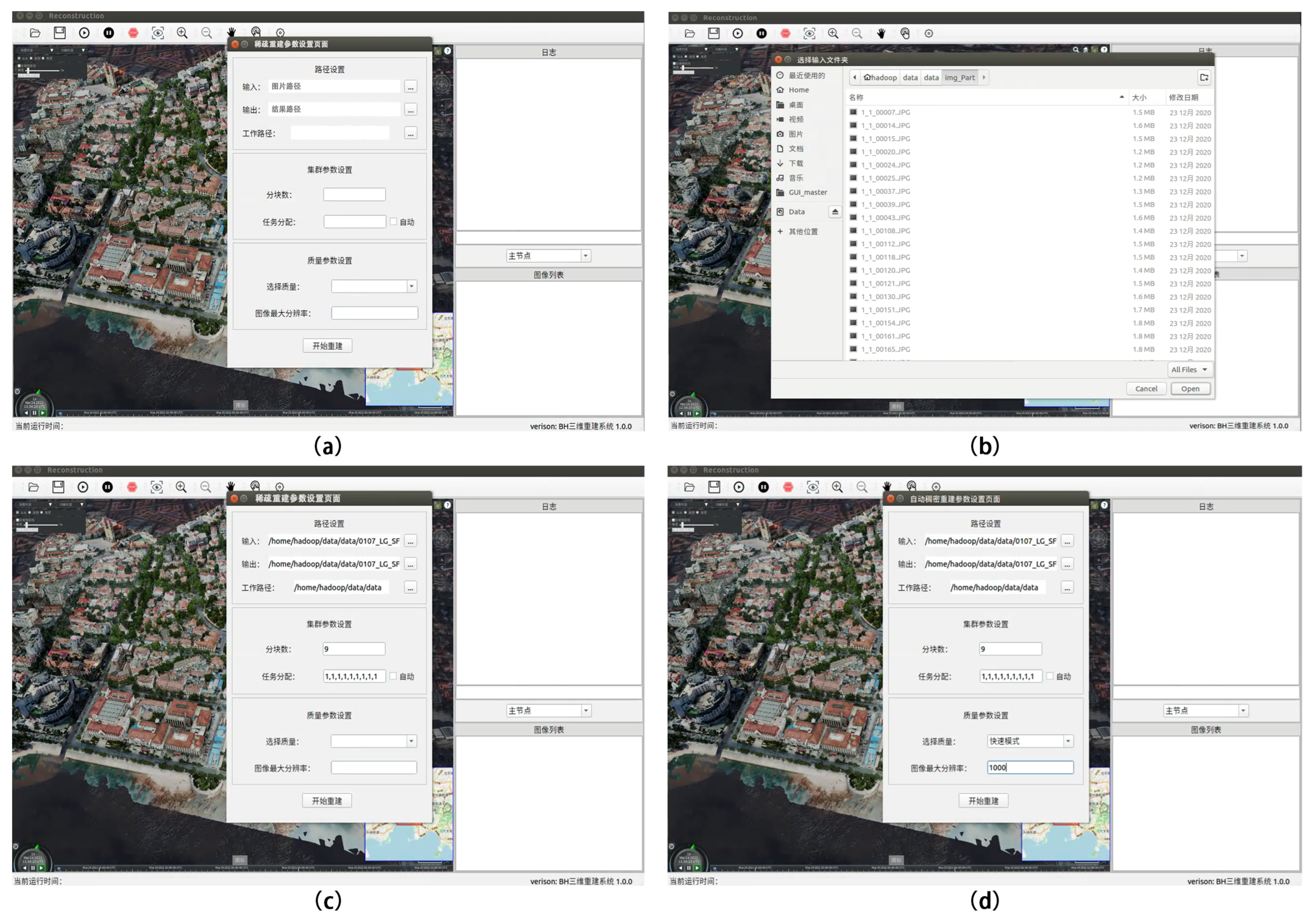
Our system can complete sparse point-cloud reconstruction, dense point-cloud reconstruction, mesh reconstruction, mesh optimization, texture reconstruction and the entire 3D-reconstruction process. It can also complete the subprocesses of the reconstruction process individually. In simple mode, let us take sparse point-cloud reconstruction as an example. First, open the “Sparse Reconstruction—Automatic Sparse Reconstruction Parameter Settings” dialog box and enter the input, output and project work file paths in order as required.
Next, set the number of cluster chunks and the task allocation ratio of each computing node in the cluster. Finally, set the reconstruction quality and the resolution parameters of the image during the reconstruction process. Then, click Rebuild to fully and automatically reconstruct the point-cloud model without any human intervention. The specific operations are shown in
Table 5, and
Figure 9 shows the demonstration results of the associated operations.
5.2. Expert Mode
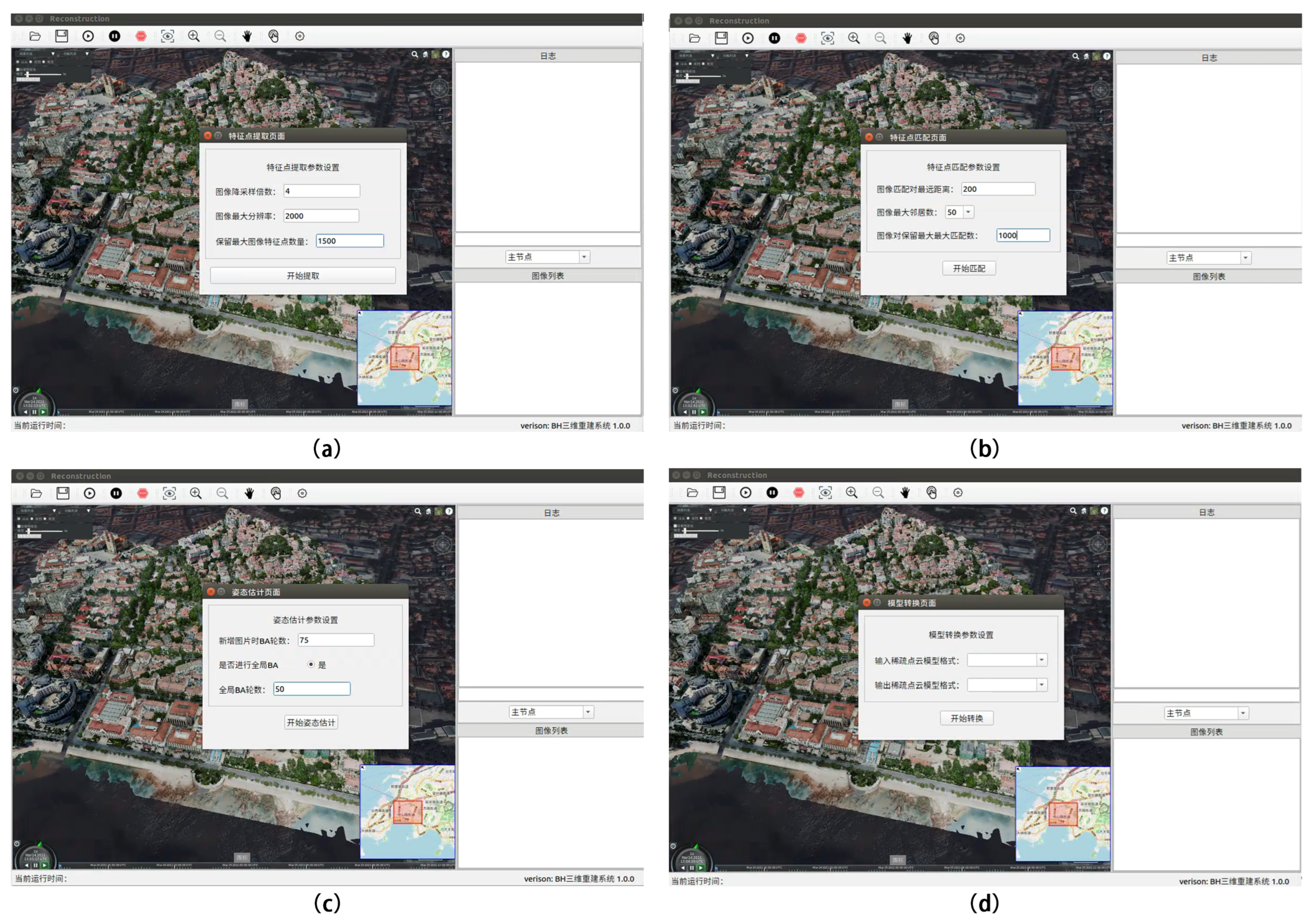
The system can provide a one-click 3D-reconstruction mode for beginner users in simple mode, whereas expert mode is for professional users who have mastered 3D-reconstruction algorithms. Expert mode provides detailed parameter settings for sparse point-cloud reconstruction, dense point-cloud reconstruction, mesh reconstruction, mesh optimization, and texture reconstruction subprojects throughout the 3D-reconstruction process. Professional users can manually adjust the parameters of each reconstruction subproject to meet their needs, including scene timeliness and scene 3D-reconstruction fineness.
Let us take sparse point-cloud reconstruction as an example. First, click “Sparse Reconstruction—Feature Point Extraction” in the menu bar to automatically bring up the “Feature Point Extraction” dialog box and enter the relevant parameters to control the feature-point extraction quality in the sparse point-cloud reconstruction process. Secondly, select “Sparse Reconstruction—Feature Point Matching” in the menu bar, and fill in the relevant parameters to effectively control the matching quality between image pairs. Again, select “Sparse Reconstruction—BA” in the menu bar and fill in the appropriate BA parameters in the “BA” dialog box to adjust the nonlinear model optimization.
The final step is to choose “Sparse Reconstruction—Model Conversion” from the menu bar. In the model conversion dialog box, the user can choose the output sparse point-cloud model format for reconstruction (the input is not chosen). Alternatively, the user can convert the sparse point-cloud format by selecting the input sparse point-cloud format and converting it to the output sparse point-cloud format. The detailed operating instructions for expert mode are presented in
Table 6, and
Figure 10 illustrates the most significant operating steps.
6. Conclusions
We developed a cluster-based system for large-scale 3D reconstruction. We proposed cluster-based camera-graph-structure clustering and cluster-based global camera pose-registration methods with a partitioning strategy, which helps to avoid the limitations of a single computing node and can handle 3D-reconstruction tasks of large-scale scenes within the framework of clusters.
In order to fully utilize the computational resources on a single computational node, we developed a GPU parallel depth estimation based on a patch-matching method that uses GPU computational units to achieve the pixel-level parallel computation of depth values, which significantly reduces the time needed to solve the dense point-cloud reconstruction problem on a single computational node. We propose a 3D mesh-optimization method based on cluster geometric detail recovery, which not only effectively reduces the size of the data but also maintains the local characteristics and realism of the model.
Our system can efficiently and rapidly generate large-scale-scene 3D models in both standard and fast modes and outperformed state-of-the-art 3D-reconstruction libraries and commercial systems in terms of the reconstruction speed. In the future, we plan to continue to enhance our system by adding functions to generate digital orthophoto maps (DOM), digital surface models (DSMs) and track-planning and model-accuracy reports. We will continue to improve the reconstruction algorithm of the system to achieve higher reconstruction accuracy and faster reconstruction speed.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}