

Event-Guided Image Super-Resolution Reconstruction
Abstract
:1. Introduction
- We designed a novel network model suitable for super-resolution reconstruction of intensity images from event cameras, named EFSR-Net. Our algorithm is based on a hybrid paradigm of frames and events. The final super-resolution effect is significantly better than that of simply reconstructing from a low-resolution event stream as input;
- We designed the coupled response block (CRB) in the network. It can fuse the event data and APS frame data to complement each other, and recover the texture details contained in the real image shadows by using the high dynamic range characteristics of the event data.
2. Related Work
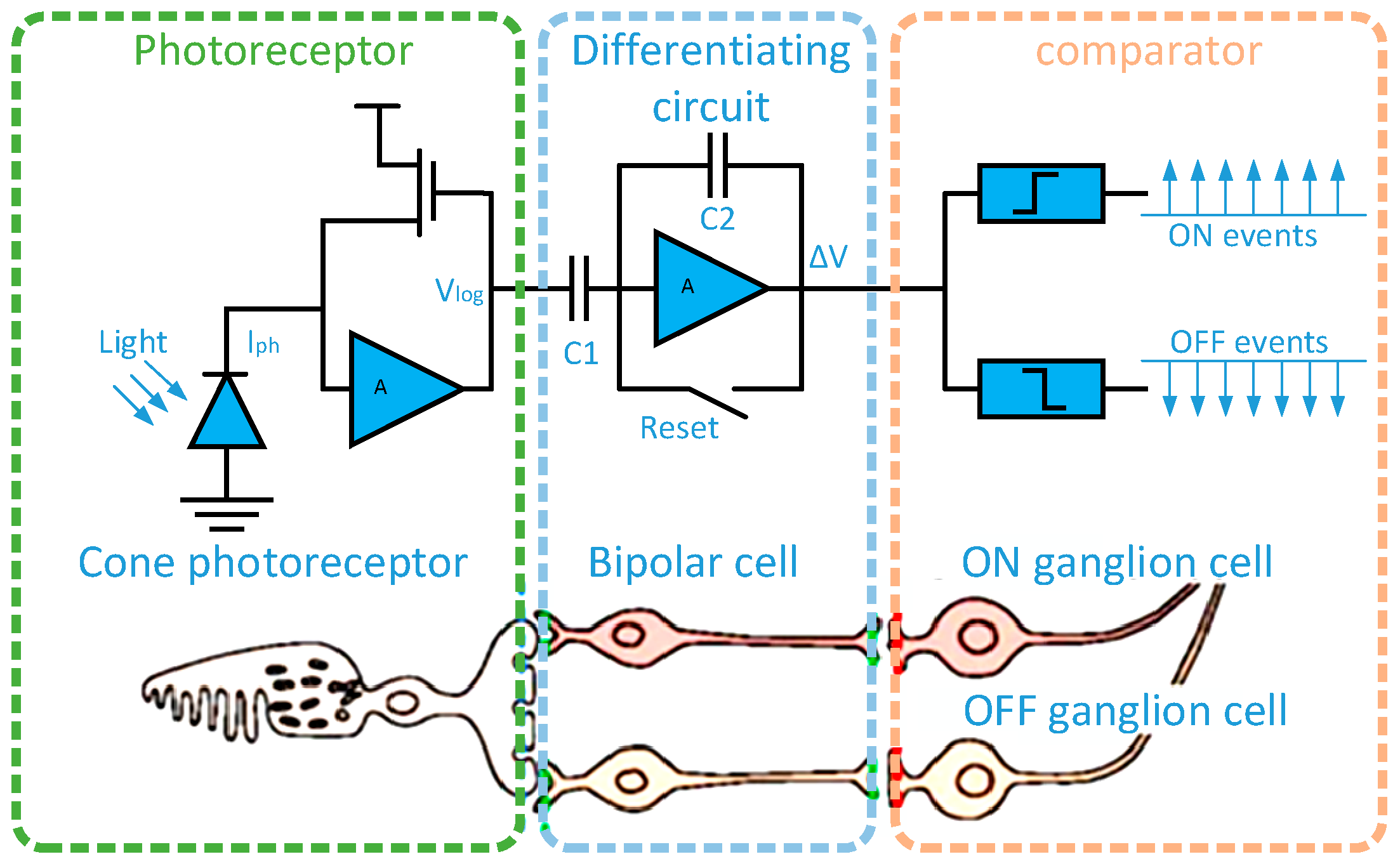
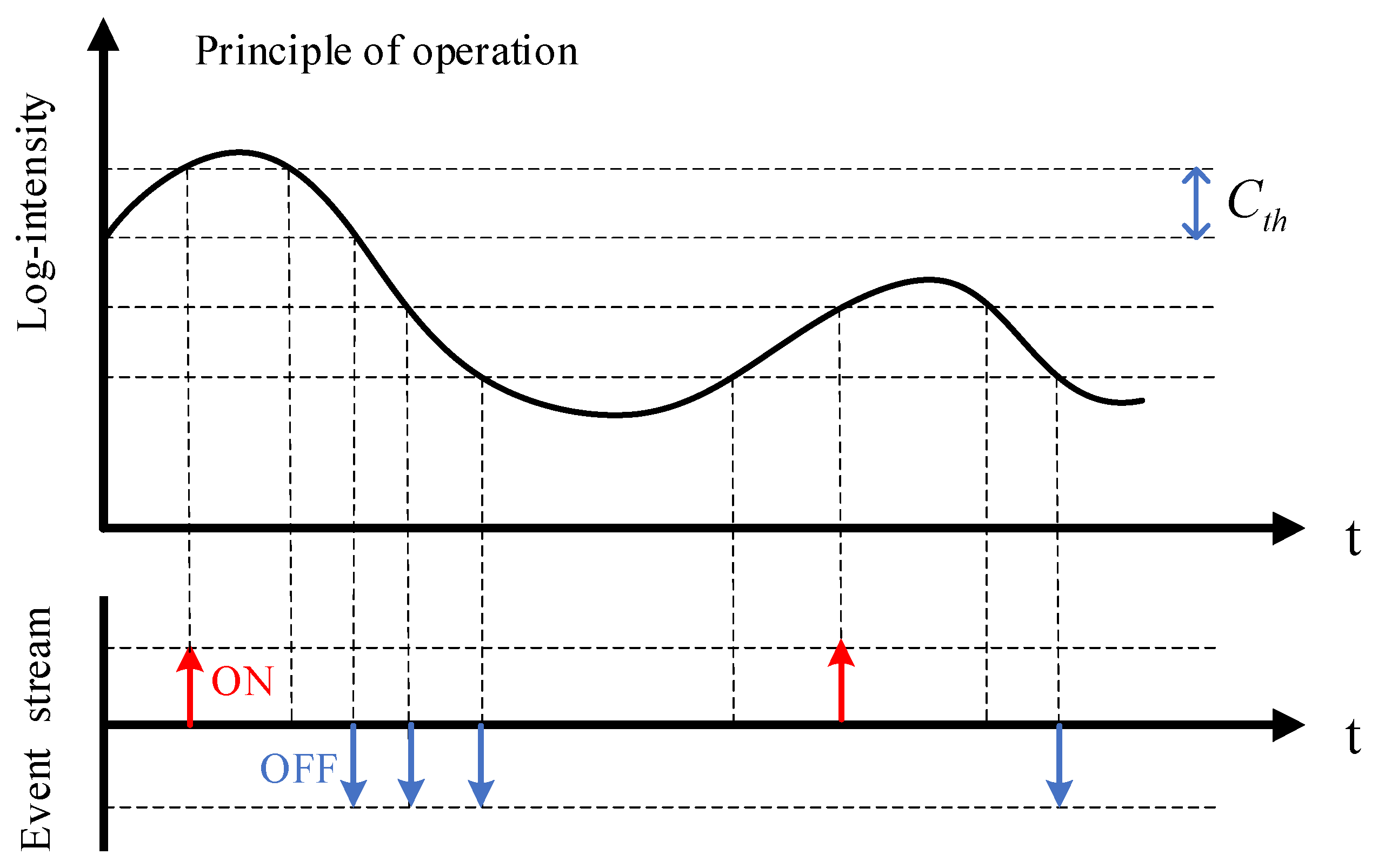
2.1. Event Data Processing Method
2.2. Event-Based Intensity Reconstruction
2.3. Event-Based Super-Resolution
3. Proposed Method
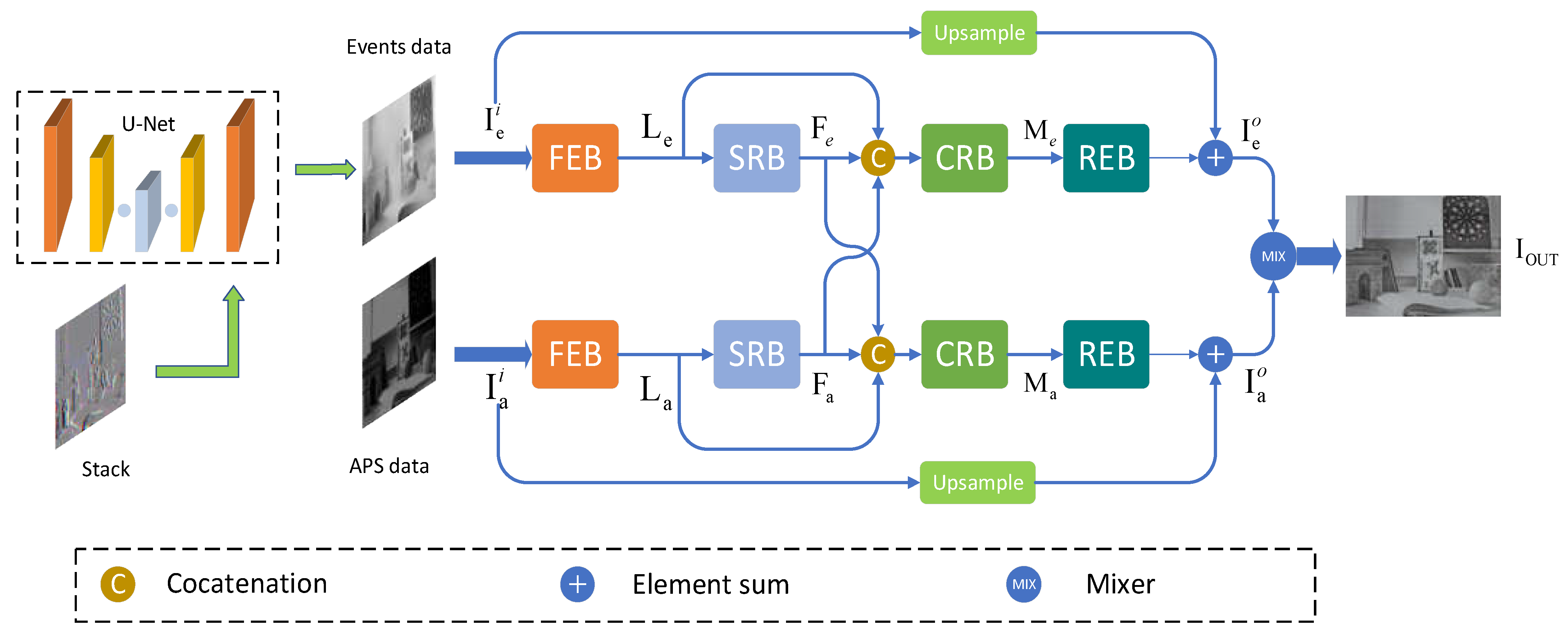
3.1. Overview
3.2. Event Data Preprocessing
3.3. Network Architecture
3.4. Loss Function
4. Experiment
4.1. Dataset Preparation
4.2. Implementation Details
4.3. Compare with Advanced Algorithms
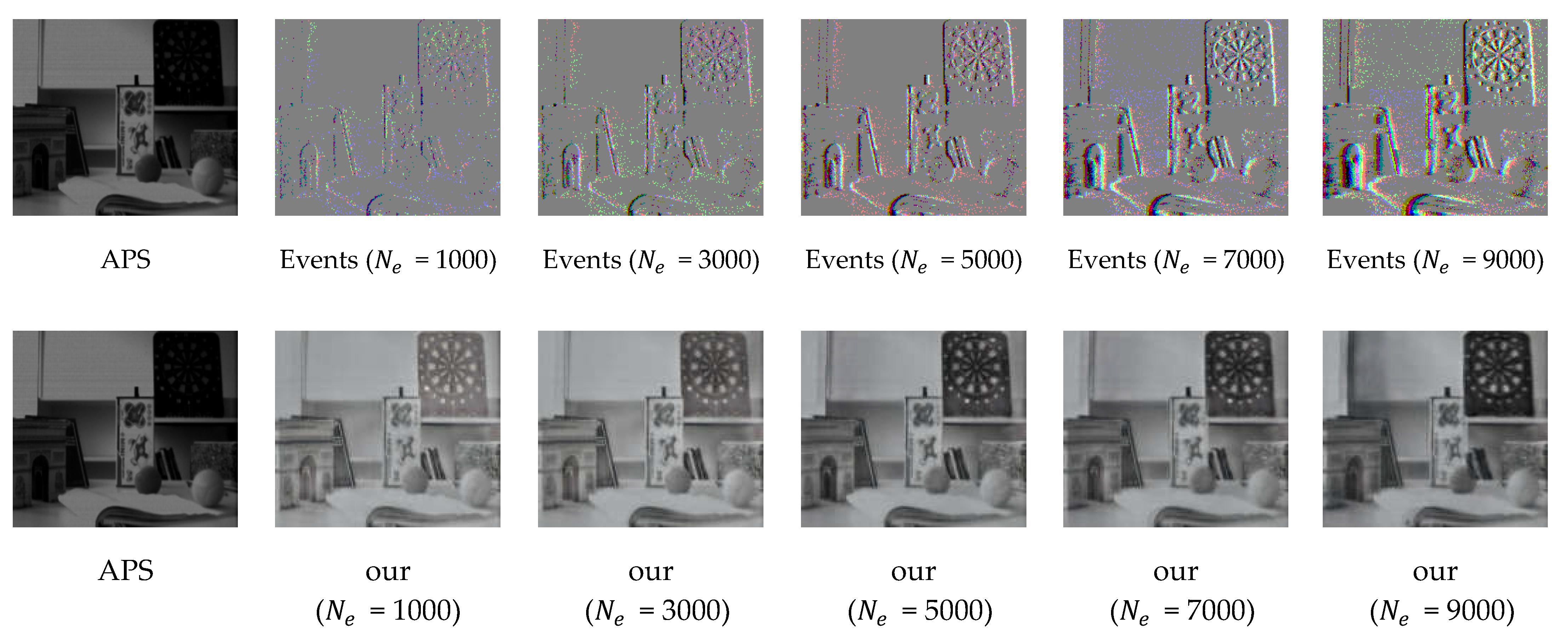
4.3.1. Evaluation on Synthetic Datasets
4.3.2. Evaluation on Real Dataset
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Posch, C.; Serrano-Gotarredona, T.; Linares-Barranco, B.; Delbruck, T. Retinomorphic Event-Based Vision Sensors: Bioinspired Cameras with Spiking Output. Proc. IEEE 2014, 102, 1470–1484. [Google Scholar] [CrossRef]
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 × 128 120 dB 15 μs Latency Asynchronous Temporal Contrast Vision Sensor. IEEE J. Solid-State Circuits 2008, 43, 566–576. [Google Scholar] [CrossRef]
- Reverter Valeiras, D.; Lagorce, X.; Clady, X.; Bartolozzi, C.; Ieng, S.H.; Benosman, R. An Asynchronous Neuromorphic Event-Driven Visual Part-Based Shape Tracking. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 3045–3059. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yang, J.; Peng, X.; Wu, P.; Gao, L.; Huang, K.; Chen, J.; Kneip, L.J.S. Visual odometry with an event camera using continuous ray warping and volumetric contrast maximization. Sensors 2022, 22, 5687. [Google Scholar] [CrossRef] [PubMed]
- Delbruck, T.; Li, C.; Graca, R.; Mcreynolds, B. Utility and feasibility of a center surround event camera. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 381–385. [Google Scholar]
- Brandli, C.; Berner, R.; Minhao, Y.; Shih-Chii, L.; Delbruck, T. A 240 × 180 130 dB 3 µs Latency Global Shutter Spatiotemporal Vision Sensor. IEEE J. Solid-State Circuits 2014, 49, 2333–2341. [Google Scholar] [CrossRef]
- Hidalgo-Carrió, J.; Gallego, G.; Scaramuzza, D. Event-aided direct sparse odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–22 June 2022; pp. 5781–5790. [Google Scholar]
- Ozawa, T.; Sekikawa, Y.; Saito, H.J.S. Accuracy and Speed Improvement of Event Camera Motion Estimation Using a Bird’s-Eye View Transformation. Sensors 2022, 22, 773. [Google Scholar] [CrossRef] [PubMed]
- Cannici, M.; Ciccone, M.; Romanoni, A.; Matteucci, M. Attention mechanisms for object recognition with event-based cameras. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1127–1136. [Google Scholar]
- Barranco, F.; Teo, C.L.; Fermuller, C.; Aloimonos, Y. Contour detection and characterization for asynchronous event sensors. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 486–494. [Google Scholar]
- Barranco, F.; Fermuller, C.; Ros, E. Real-time clustering and multi-target tracking using event-based sensors. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 5764–5769. [Google Scholar]
- Kim, H.; Leutenegger, S.; Davison, A.J. Real-time 3D reconstruction and 6-DoF tracking with an event camera. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 349–364. [Google Scholar]
- Rebecq, H.; Ranftl, R.; Koltun, V.; Scaramuzza, D. Events-to-video: Bringing modern computer vision to event cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3857–3866. [Google Scholar]
- Scheerlinck, C.; Barnes, N.; Mahony, R. Continuous-time intensity estimation using event cameras. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 308–324. [Google Scholar]
- Wang, L.; Ho, Y.-S.; Yoon, K.-J. Event-based high dynamic range image and very high frame rate video generation using conditional generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10081–10090. [Google Scholar]
- Choi, J.; Yoon, K.-J. Learning to super resolve intensity images from events. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2020; pp. 2768–2776. [Google Scholar]
- Han, J.; Yang, Y.; Zhou, C.; Xu, C.; Shi, B. Evintsr-net: Event guided multiple latent frames reconstruction and super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 4882–4891. [Google Scholar]
- Wang, L.; Kim, T.-K.; Yoon, K.-J. Eventsr: From asynchronous events to image reconstruction, restoration, and super-resolution via end-to-end adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2020; pp. 8315–8325. [Google Scholar]
- Gehrig, D.; Loquercio, A.; Derpanis, K.G.; Scaramuzza, D. End-to-end learning of representations for asynchronous event-based data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 5633–5643. [Google Scholar]
- Kim, H.; Handa, A.; Benosman, R.; Ieng, S.-H.; Davison, A.J.J.J.S.S.C. Simultaneous mosaicing and tracking with an event camera. Br. Mach. Vis. Conf. 2008, 43, 566–576. [Google Scholar] [CrossRef]
- Cook, M.; Gugelmann, L.; Jug, F.; Krautz, C.; Steger, A. Interacting maps for fast visual interpretation. In Proceedings of the The 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 770–776. [Google Scholar]
- Bardow, P.; Davison, A.J.; Leutenegger, S. Simultaneous optical flow and intensity estimation from an event camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 884–892. [Google Scholar]
- Munda, G.; Reinbacher, C.; Pock, T. Real-time intensity-image reconstruction for event cameras using manifold regularisation. Int. J. Comput. Vis. 2018, 126, 1381–1393. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Pan, L.; Scheerlinck, C.; Yu, X.; Hartley, R.; Liu, M.; Dai, Y. Bringing a blurry frame alive at high frame-rate with an event camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6820–6829. [Google Scholar]
- Pan, L.; Hartley, R.; Scheerlinck, C.; Liu, M.; Yu, X.; Dai, Y. High Frame Rate Video Reconstruction Based on an Event Camera. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2519–2533. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Yezzi, A.; Gallego, G. Formulating Event-based Image Reconstruction as a Linear Inverse Problem with Deep Regularization using Optical Flow. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1, 1–18. [Google Scholar] [CrossRef]
- Li, H.; Li, G.; Shi, L. Super-resolution of spatiotemporal event-stream image. Neurocomputing 2019, 335, 206–214. [Google Scholar] [CrossRef]
- Duan, P.; Wang, Z.W.; Zhou, X.; Ma, Y.; Shi, B. EventZoom: Learning to denoise and super resolve neuromorphic events. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12824–12833. [Google Scholar]
- Wang, B.; He, J.; Yu, L.; Xia, G.-S.; Yang, W. Event enhanced high-quality image recovery. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 155–171. [Google Scholar]
- Wang, Z.W.; Duan, P.; Cossairt, O.; Katsaggelos, A.; Huang, T.; Shi, B. Joint filtering of intensity images and neuromorphic events for high-resolution noise-robust imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2020; pp. 1609–1619. [Google Scholar]
- Weng, W.; Zhang, Y.; Xiong, Z. Boosting event stream super-resolution with a recurrent neural network. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part VI. pp. 470–488. [Google Scholar]
- Song, C.; Huang, Q.; Bajaj, C. E-cir: Event-enhanced continuous intensity recovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–22 June 2022; pp. 7803–7812. [Google Scholar]
- Gallego, G.; Delbruck, T.; Orchard, G.; Bartolozzi, C.; Taba, B.; Censi, A.; Leutenegger, S.; Davison, A.J.; Conradt, J.; Daniilidis, K.; et al. Event-Based Vision: A Survey. IEEE Trans. Pattern. Anal. Mach. Intell. 2022, 44, 154–180. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3867–3876. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Nah, S.; Baik, S.; Hong, S.; Moon, G.; Son, S.; Timofte, R.; Mu Lee, K. Ntire 2019 challenge on video deblurring and super-resolution: Dataset and study. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Rebecq, H.; Gehrig, D.; Scaramuzza, D. ESIM: An open event camera simulator. In Proceedings of the Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; pp. 969–982. [Google Scholar]
- Diederik, P.K.; Jimmy, B. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 191–207. [Google Scholar]
- Mueggler, E.; Rebecq, H.; Gallego, G.; Delbruck, T.; Scaramuzza, D. The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and SLAM. Int. J. Robot. Res. 2017, 36, 142–149. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale | Method | PSNR ↑ | SSIM ↑ |
|---|---|---|---|
| 2× | EV [15] + SISR [40] | 12.52 | 0.466 |
| E2SRI [16] | 16.41 | 0.587 | |
| eSL-Net [30] | 15.76 | 0.534 | |
| Ours | 22.02 | 0.746 | |
| 4× | EV [15] + SISR [40] | 11.93 | 0.572 |
| E2SRI [16] | - | - | |
| eSL-Net [30] | 21.84 | 0.683 | |
| Ours | 23.25 | 0.714 |
| Loss | PSNR | SSIM |
|---|---|---|
| L1 | 21.98 | 0.698 |
| 22.02 | 0.746 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, G.; Feng, Y.; Lv, H.; Zhao, Y.; Liu, H.; Bi, G. Event-Guided Image Super-Resolution Reconstruction. Sensors 2023, 23, 2155. https://doi.org/10.3390/s23042155
Guo G, Feng Y, Lv H, Zhao Y, Liu H, Bi G. Event-Guided Image Super-Resolution Reconstruction. Sensors. 2023; 23(4):2155. https://doi.org/10.3390/s23042155
Chicago/Turabian StyleGuo, Guangsha, Yang Feng, Hengyi Lv, Yuchen Zhao, Hailong Liu, and Guoling Bi. 2023. "Event-Guided Image Super-Resolution Reconstruction" Sensors 23, no. 4: 2155. https://doi.org/10.3390/s23042155