
JUTAR: Joint User-Association, Task-Partition, and Resource-Allocation Algorithm for MEC Networks

Abstract
:1. Introduction
1.1. Related Works
1.2. Motivation and Contributions
- We build up the optimization function with respect to the joint user-association, task-partition, and resource-allocation issues given an MEC network with massive servers. With the joint optimization of these problems, the optimization function could explore better results for the realistic MEC network.
- We define a user-association metric, which comprehensively considers the distance and overload of each UE and the target SBS, to indicate the user-association for each UE. In addition, we employed the smooth approximation to further simplify the optimization function.
- We propose using the particle swarm algorithm (PSA) to find the optimal results of the optimization function. The PSA can heuristically find the optimal solutions for the function and contribute to better system performance.
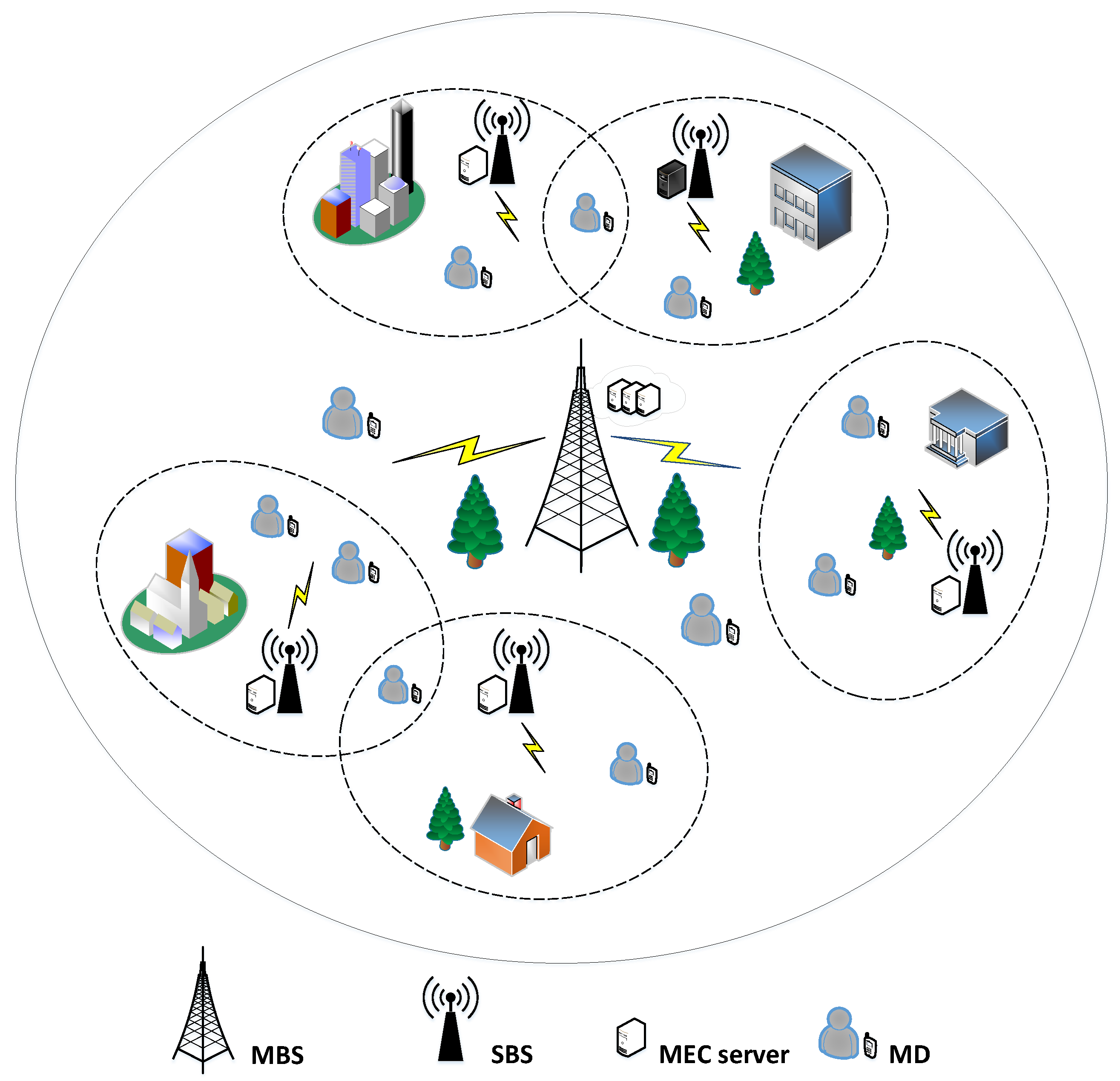
2. System Model and Problem Formulation
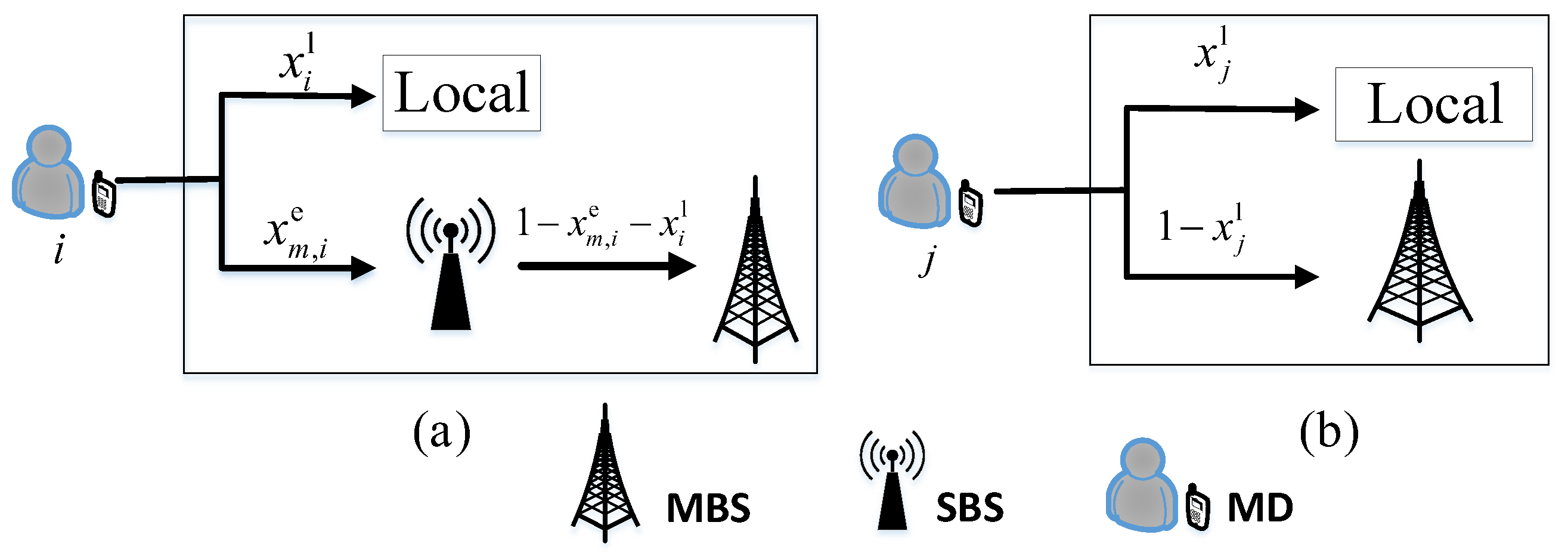
2.1. Local Computing Model
2.2. Computing Model in SBS
2.3. Computing Model for the MBS
3. Methodology
3.1. User Association
3.2. Smooth Approximation
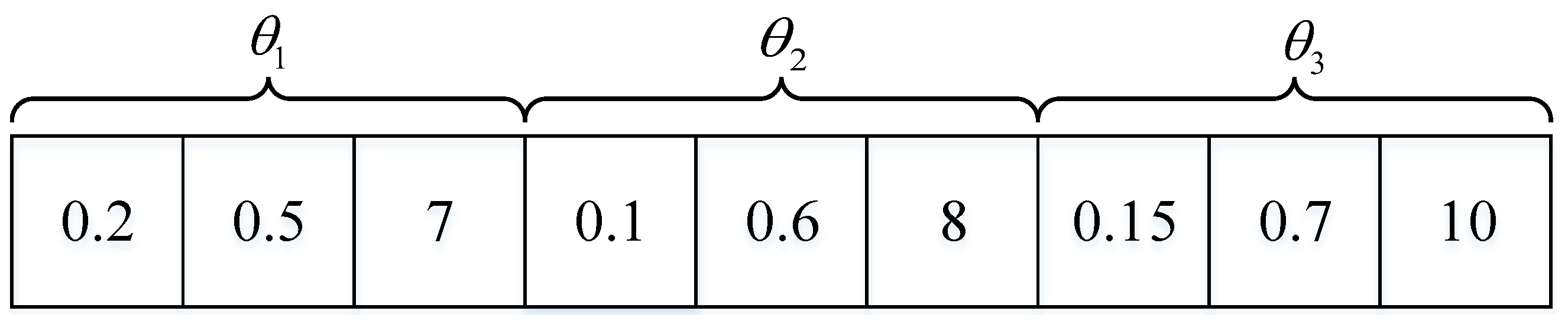
3.3. Optimized with PSA Algorithm
- and are two acceleration factors,
- W is a constant weight of the inertia,
- and are random factors chosen from ,
- is the optimal position for the m-th particle in the single SBS scenario,
- is the optimal position for m-th particle in the global MEC network.
3.4. Proposed JUTAR Algorithm
| Algorithm 1: JUTAR Algorithm |
 |
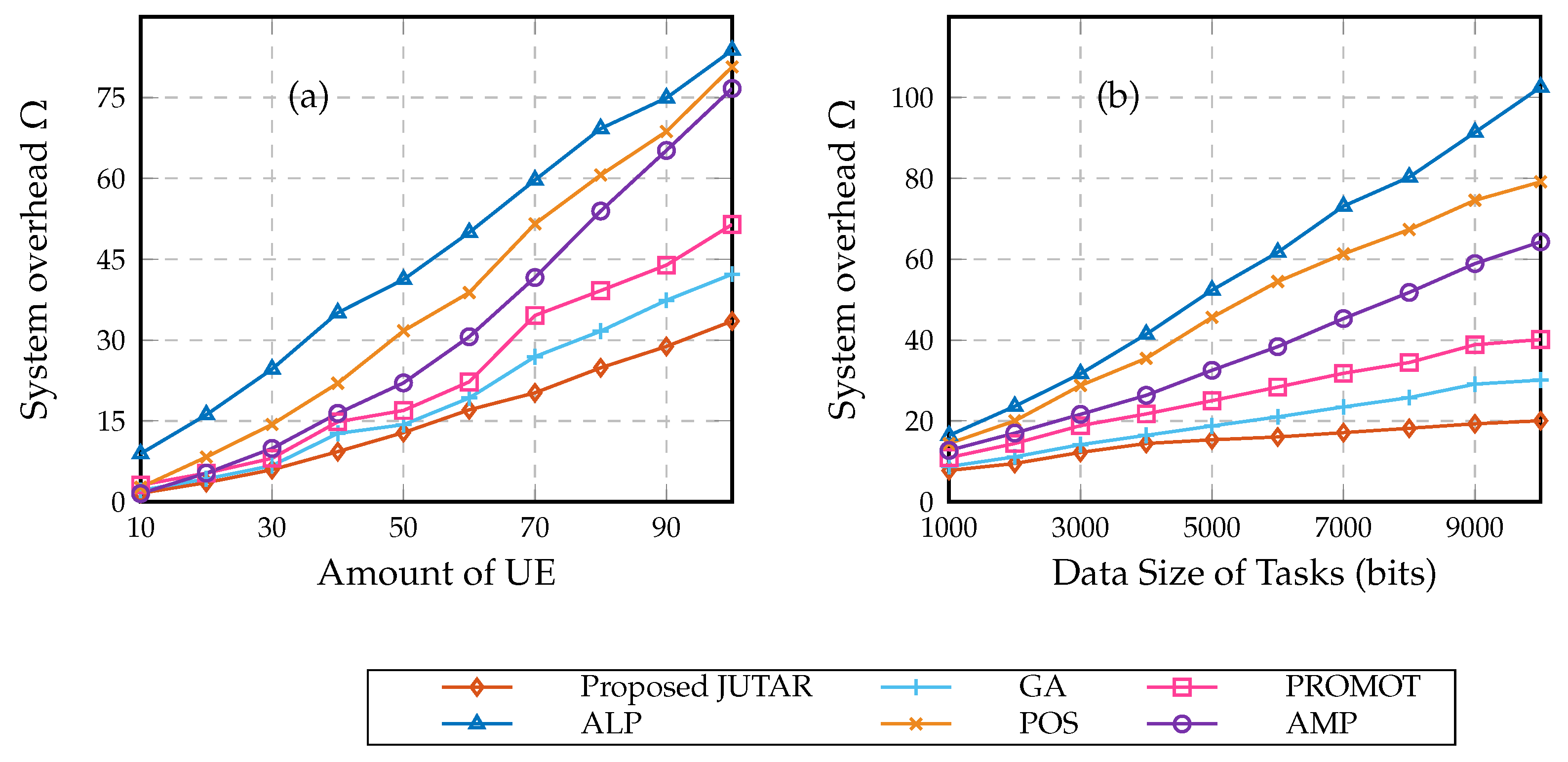
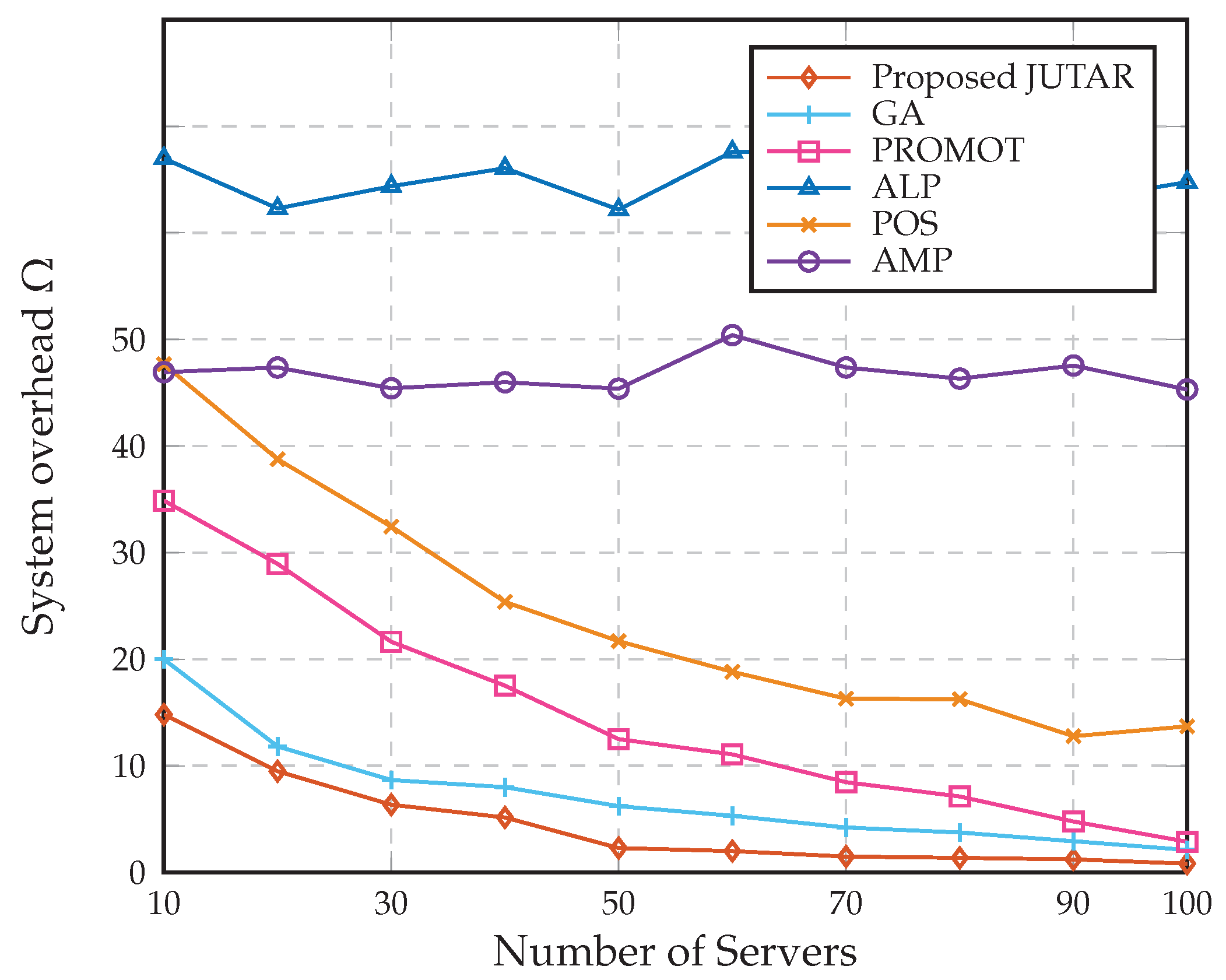
4. Numerical Results
- All local processing (ALP) algorithm [8]: all tasks of the user are processed locally.
- Partial offloading strategy (POS) algorithm [8]: partial tasks of each UE are offloaded into either SBS or MBS based on a possible user association.
- All MBS processing (AMP) algorithm [10]: the overall tasks of each UE can only be uploaded to the MBS.
- GA [18]: partial tasks of each UE are uploaded to either SBS or MBS, which is decided according to the genetic algorithm.
- Priority offloading mechanism with joint offloading proportion and transmission (PROMOT) algorithm [19]: partial tasks of each UE are offloaded into SBS or MBS according to not only the GA algorithm but also its offloading prior probability.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Dong, X.; Zhao, Y. Decentralized computation offloading over wireless-powered mobile-edge computing networks. In Proceedings of the IEEE International Conference on Artificial Intelligence and Information Systems (ICAIIS), Dalian, China, 20–22 March 2020; pp. 137–140. [Google Scholar]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile edge computing: A survey. IEEE Internet Things J. 2017, 5, 450–465. [Google Scholar] [CrossRef]
- Wei, X.; Wang, S.; Zhou, A.; Xu, J.; Su, S.; Kumar, S.; Yang, F. MVR: An architecture for computation offloading in mobile edge computing. In Proceedings of the 2017 IEEE International Conference on Edge Computing (EDGE), Honolulu, HI, USA, 25–30 June 2017; pp. 232–235. [Google Scholar]
- Ren, J.; Yu, G.; He, Y.; Li, G.Y. Collaborative cloud and edge computing for latency minimization. IEEE Trans. Veh. Technol. 2019, 68, 5031–5044. [Google Scholar] [CrossRef]
- Bi, S.; Zhang, Y.J. Computation rate maximization for wireless powered mobile-edge computing with binary computation offloading. IEEE Trans. Wirel. Commun. 2018, 17, 4177–4190. [Google Scholar] [CrossRef]
- Chen, L.; Li, X.; Ji, H.; Leung, V. Computation offloading balance in small cell networks with mobile edge computing. Wirel. Netw. 2019, 25, 4133–4145. [Google Scholar] [CrossRef]
- Wu, Y.H.; Wang, Y.H.; Zhou, F.H.; Hu, R.O. Computation efficiency maximization in OFDMA-based mobile edge computing networks. IEEE Commun. Lett. 2019, 24, 159–163. [Google Scholar] [CrossRef]
- Ning, Z.L.; Dong, P.R.; Kong, X.J.; Xia, F. A cooperative partial computation offloading scheme for mobile edge computing enabled internet of things. IEEE Internet Things J. 2018, 6, 4804–4814. [Google Scholar] [CrossRef]
- Zhang, Y.; Fu, J.Q. Energy-efficient computation offloading strategy with tasks scheduling in edge computing. Wirel. Netw. 2021, 27, 609–620. [Google Scholar] [CrossRef]
- Tao, X.Y.; Ota, K.; Dong, M.X.; Qi, H.; Li, K.Q. Performance guaranteed computation offloading for mobile-edge cloud computing. IEEE Wirel. Commun. Lett. 2017, 6, 774–777. [Google Scholar] [CrossRef]
- Zhou, S.C.; Jadoon, W. The partial computation offloading strategy based on game theory for multi-user in mobile edge computing environment. Comput. Netw. 2020, 178, 107334. [Google Scholar] [CrossRef]
- Feng, M.; Krunz, M.; Zhang, W. Joint task partitioning and user association for latency minimization in mobile edge computing networks. IEEE Trans. Veh. Technol. 2021, 70, 8108–8121. [Google Scholar] [CrossRef]
- Xiao, Y.; Krunz, M. Distributed optimization for energy-efficient fog computing in the tactile internet. IEEE J. Sel. Areas Commun. 2018, 36, 2390–2400. [Google Scholar] [CrossRef]
- Han, Q.; Yang, B.; Miao, G.; Chen, C.; Wang, X.; Guan, X. Backhaul-aware user association and resource allocation for energy-constrained hetnets. IEEE Trans. Veh. Technol. 2016, 66, 580–593. [Google Scholar] [CrossRef]
- Zhou, Y.; Yeoh, P.L.; Pan, C.; Wang, K.; Elkashlan, M.; Wang, Z.; Vucetic, B.; Li, Y. Offloading optimization for low-latency secure mobile edge computing systems. IEEE Wirel. Commun. Lett. 2019, 9, 480–484. [Google Scholar] [CrossRef]
- Li, H.L.; Xu, H.T.; Zhou, C.C.; Lu, X.; Han, Z. Joint optimization strategy of computation offloading and resource allocation in multi-access edge computing environment. IEEE Trans. Veh. Technol. 2020, 69, 10214–10226. [Google Scholar] [CrossRef]
- Tran, T.X.; Pompili, D. Joint task offloading and resource allocation for multi-server mobile-edge computing networks. IEEE Trans. Veh. Technol. 2018, 68, 856–868. [Google Scholar] [CrossRef]
- Liao, Z.F.; Peng, J.; Xiong, B.; Huang, J.W. Adaptive offloading in mobile-edge computing for ultra-dense cellular networks based on genetic algorithm. J. Cloud Comput. 2021, 10, 15. [Google Scholar] [CrossRef]
- Wang, J.; Wu, W.; Liao, Z.; Sherratt, R.S.; Kim, G.-J.; Alfarraj, O.; Alzubi, A.; Tolba, A. A probability preferred priori offloading mechanism in mobile edge computing. IEEE Access 2020, 8, 39758–39767. [Google Scholar] [CrossRef]
- Li, J.; Gao, H.; Lv, T.; Lu, Y. Deep reinforcement learning based computation offloading and resource allocation for MEC. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Jehangiri, A.I.; Maqsood, T.; Umar, A.I.; Shuja, J.; Ahmad, Z.; Dhaou, I.B.; Alsharekh, M.F. LIMPO: Lightweight mobility prediction and offloading framework using machine learning for mobile edge computing. Clust. Comput. 2022, 1–19. [Google Scholar]
- Zaman, S.K.U.; Jehangiri, A.I.; Maqsood, T.; Umar, A.I.; Khan, M.A.; Jhanjhi, N.Z.; Shorfuzzaman, M.; Masud, M. COME-UP: Computation offloading in mobile edge computing with LSTM based user direction prediction. Appl. Sci. 2022, 12, 3312. [Google Scholar] [CrossRef]
- Wang, R. Adjustable entropy method for solving convex inequality problem. J. Syst. Eng. Electr. 2009, 20, 1111–1114. [Google Scholar]
- Huynh, L.N.T.; Pham, Q.V.; Pham, X.; Nguyen, T.D.T.; Hossain, M.D.; Huh, E.N. Efficient computation offloading in multi-tier multi-access edge computing systems: A particle swarm optimization approach. Appl. Sci. 2019, 10, 203. [Google Scholar] [CrossRef] [Green Version]
- Tammer, K. The application of parametric optimization and imbedding to the foundation and realization of a generalized primal decomposition approach. Math. Res. 1987, 35, 376–386. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| n-th UE | |
| m-th SBS | |
| Indicator of if the n-th UE is associated with the m-th SBS | |
| Data size of the task | |
| Required CPU clock cycles to process a bit of data in the task | |
| Maximum tolerance latency of this task | |
| Latency of the local tasks | |
| Energy consumption of the local tasks | |
| Computational capability of the n-th UE | |
| Transmission rate of the n-th UE | |
| Latency of the tasks of the n-th UE and processed in the m-th SBS | |
| Energy consumption of the tasks of the n-th UE and processed in the m-th SBS | |
| Latency of the tasks of the n-th UE and processed in the MBS | |
| Energy consumption of the tasks of the n-th UE and processed in the MBS | |
| Overall latency of the tasks for the n-th UE | |
| Overall energy consumption of the tasks of the n-th UE | |
| Task offloading ratio | |
| UE association metric | |
| Overload of the -th SBS |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, L.; Wang, Y.; Hu, Y.; Jiang, F.; Bai, N.; Deng, Y. JUTAR: Joint User-Association, Task-Partition, and Resource-Allocation Algorithm for MEC Networks. Sensors 2023, 23, 1601. https://doi.org/10.3390/s23031601
Kang L, Wang Y, Hu Y, Jiang F, Bai N, Deng Y. JUTAR: Joint User-Association, Task-Partition, and Resource-Allocation Algorithm for MEC Networks. Sensors. 2023; 23(3):1601. https://doi.org/10.3390/s23031601
Chicago/Turabian StyleKang, Ling, Yi Wang, Yanjun Hu, Fang Jiang, Na Bai, and Yu Deng. 2023. "JUTAR: Joint User-Association, Task-Partition, and Resource-Allocation Algorithm for MEC Networks" Sensors 23, no. 3: 1601. https://doi.org/10.3390/s23031601