
LRF-SRNet: Large-Scale Super-Resolution Network for Estimating Aircraft Pose on the Airport Surface
Abstract
:1. Introduction
- The end-to-end low-resolution aircraft 2D pose estimation network LRF-SRNet is proposed, which combines SR methods with pose estimation methods to precisely estimate the pose of an aircraft from low-resolution images.
- A large receptive field block (LRF block) is created as a core component to assist the network in extending its effective perceptual field and identifying the overall characteristics of the aircraft.
- The results of our experiments demonstrate that, when applied to the real-world airport surface surveillance dataset, our approach can successfully assist the pose estimate network in improving its performance.
2. Related Work
Super-Resolution-Based Method
3. Methodology
3.1. Aircraft Keypoint Heatmap
3.2. Loss Function
3.3. Aircraft Super-Resolution Network
3.4. Aircraft Pose Estimation Network
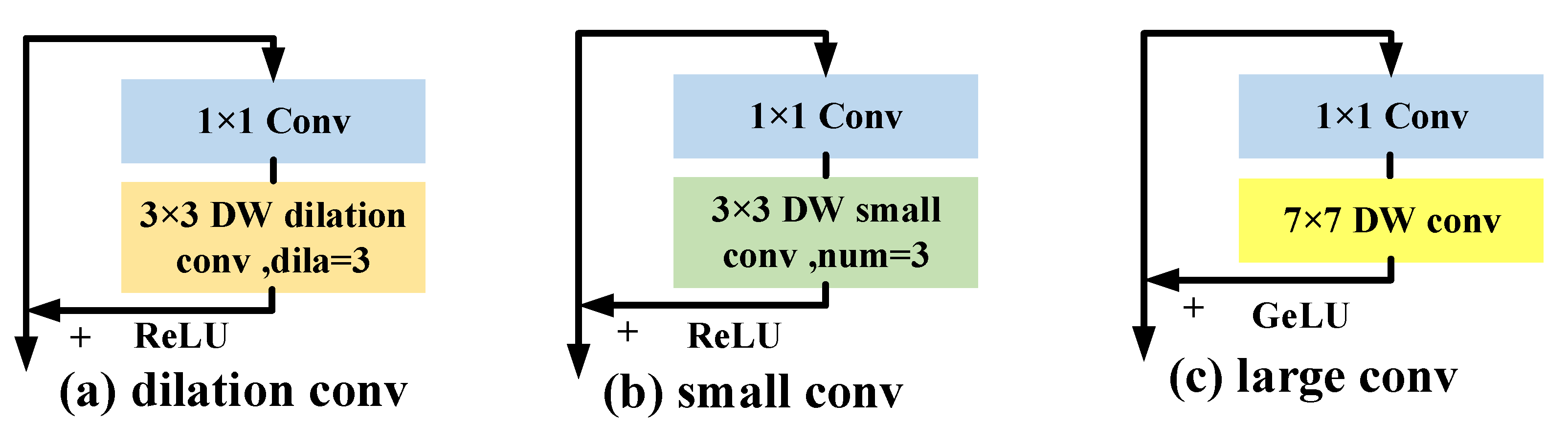
Large Receptive Field Block
4. Experiments
4.1. Aircraft Dataset
4.2. Evaluation Metric
4.3. Implement Details
4.4. Comparison with State-of-the-Art Baseline Methods
4.5. Ablation Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| TLA | Three letter acronym |
| LD | Linear dichroism |
References
- Pavlidou, N.; Grammalidis, N.; Dimitropoulos, K.; Simitopoulos, D.; Strintzis, M.; Gilbert, A.; Piazza, E.; Herrlich, C.; Heidger, R. Using intelligent digital cameras to monitor aerodrome surface traffic. IEEE Intell. Syst. 2005, 20, 76–81. [Google Scholar] [CrossRef]
- Ji, C.; Gao, M.; Zhang, X.; Li, J. A Novel Rescheduling Algorithm for the Airline Recovery with Flight Priorities and Airport Capacity Constraints. Asia-Pac. J. Oper. Res. 2021, 38, 2140025. [Google Scholar] [CrossRef]
- Yan, Z.; Yang, H.; Li, F.; Lin, Y. A Deep Learning Approach for Short-Term Airport Traffic Flow Prediction. Aerospace 2021, 9, 11. [Google Scholar] [CrossRef]
- Ji, C.; Cheng, L.; Li, N.; Zeng, F.; Li, M. Validation of global airport spatial locations from open databases using deep learning for runway detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1120–1131. [Google Scholar] [CrossRef]
- Oliveira, P.P. Digital twin development for airport management. J. Airpt. Manag. 2020, 14, 246–259. [Google Scholar]
- Julian, K.D.; Kochenderfer, M.J.; Owen, M.P. Deep neural network compression for aircraft collision avoidance systems. J. Guid. Control. Dyn. 2019, 42, 598–608. [Google Scholar] [CrossRef] [Green Version]
- Saifutdinov, F.; Jackson, I.; Tolujevs, J.; Zmanovska, T. Digital twin as a decision support tool for airport traffic control. In Proceedings of the 2020 61st International Scientific Conference on Information Technology and Management Science of Riga Technical University (ITMS), Riga, Latvia, 15–16 October 2020; pp. 1–5. [Google Scholar]
- Zeng, F.; Wang, X.; Zha, M. Extracting built-up land area of airports in China using Sentinel-2 imagery through deep learning. Geocarto Int. 2021, 1–21. [Google Scholar] [CrossRef]
- Fu, D.; Han, S.; Li, W.; Lin, H. The pose estimation of the aircraft on the airport surface based on the contour features. IEEE Trans. Aerosp. Electron. Syst. 2022. [Google Scholar] [CrossRef]
- Fu, D.; Li, W.; Han, S.; Zhang, X.; Zhan, Z.; Yang, M. The Aircraft Pose Estimation Based on a Convolutional Neural Network. Math. Probl. Eng. 2019, 2019, 7389652. [Google Scholar] [CrossRef]
- Fan, R.; Xu, T.B.; Wei, Z. Estimating 6D Aircraft Pose from Keypoints and Structures. Remote Sens. 2021, 13, 663. [Google Scholar] [CrossRef]
- Li, Y.; Yu, R.; Zhu, B. 2D-Key-Points-Localization-Driven 3D Aircraft Pose Estimation. IEEE Access 2020, 8, 181293–181301. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7103–7112. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative embedding: End-to-end learning for joint detection and grouping. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7093–7102. [Google Scholar]
- Jin, Y.; Zhang, Y.; Cen, Y.; Li, Y.; Mladenovic, V.; Voronin, V. Pedestrian detection with super-resolution reconstruction for low-quality image. Pattern Recognit. 2021, 115, 107846. [Google Scholar] [CrossRef]
- Wang, Z.Z.; Xie, K.; Zhang, X.Y.; Chen, H.Q.; Wen, C.; He, J.B. Small-Object Detection Based on YOLO and Dense Block via Image Super-Resolution. IEEE Access 2021, 9, 56416–56429. [Google Scholar] [CrossRef]
- Hsu, W.Y.; Chen, P.C. Pedestrian detection using a translation-invariant wavelet residual dense super-resolution. Opt. Express 2022, 30, 41279–41295. [Google Scholar] [CrossRef]
- He, Q.; Schultz, R.; Thomas, C. Super-resolution reconstruction by image fusion and application to surveillance videos captured by small unmanned aircraft systems. In Sensor Fusion and its Applications; Sciyo: Rijeka, Croatia, 2010; pp. 475–486. [Google Scholar]
- Li, J.; Chan, W.K. Super-Resolution Virtual Scene of Flight Simulation Based on Convolutional Neural Networks. In Proceedings of the International Conference on Big Data Management and Analysis for Cyber Physical Systems, Singapore, 22–24 April 2022; Tang, L.C., Wang, H., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 138–147. [Google Scholar]
- Chen, X.; Xiang, S.; Liu, C.L.; Pan, C.H. Aircraft detection by deep belief nets. In Proceedings of the 2013 2nd IAPR Asian Conference on Pattern Recognition, Naha, Japan, 5–8 November 2013; pp. 54–58. [Google Scholar]
- Tang, W.; Deng, C.; Han, Y.; Huang, Y.; Zhao, B. SRARNet: A Unified Framework for Joint Superresolution and Aircraft Recognition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 327–336. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, J.; Li, W.; Shan, P.; Wang, X.; Li, L.; Fu, Q. MS-IAF: Multi-Scale Information Augmentation Framework for Aircraft Detection. Remote Sens. 2022, 14, 3696. [Google Scholar] [CrossRef]
- Li, W.; Liu, J.; Mei, H. Lightweight convolutional neural network for aircraft small target real-time detection in Airport videos in complex scenes. Sci. Rep. 2022, 12, 14474. [Google Scholar] [CrossRef]
- Wu, Q.; Feng, D.; Cao, C.; Zeng, X.; Feng, Z.; Wu, J.; Huang, Z. Improved mask R-CNN for aircraft detection in remote sensing images. Sensors 2021, 21, 2618. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 11963–11975. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic understanding of scenes through the ade20k dataset. Int. J. Comput. Vis. 2019, 127, 302–321. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European conference on computer vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2016, 29, 4905–4913. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 19–25 June 2021; pp. 11313–11322. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, L.; Guo, Y.; Liu, L.; Lin, Z.; Deng, X.; An, W. Deep Video Super-Resolution Using HR Optical Flow Estimation. IEEE Trans. Image Process. 2020, 29, 4323–4336. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Li, L.; Xue, Y.; Jiang, C.; Wang, J.; Sun, K.; Ma, H. FeNet: Feature Enhancement Network for Lightweight Remote-Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5622112. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Parameters | AP | AP | AP | AR | AR | AR |
|---|---|---|---|---|---|---|---|---|
| TokenPose [40] | Transformer | 13.5M | 78.4 | 80.6 | 83.8 | 83.1 | 81.2 | 89.7 |
| Baseline [38] | Resnet-50 | 34.0M | 83.3 | 82.7 | 86.9 | 88.4 | 83.4 | 94.1 |
| Baseline+SR | ResNet-50 | 35.9M | 85.3 | 85.7 | 87.6 | 90.2 | 86.2 | 94.8 |
| Baseline+LRF | ResNet-50 | 34.4M | 86.3 | 84.9 | 89.4 | 91.2 | 88.7 | 93.9 |
| Baseline+both | ResNet-50 | 36.3M | 87.5 | 88.1 | 89.3 | 90.9 | 89.0 | 93.0 |
| Baseline [38] | ResNet-101 | 53.0M | 84.8 | 81.4 | 89.2 | 89.4 | 86.2 | 93.0 |
| Baseline+SR | ResNet-101 | 54.9M | 85.5 | 85.5 | 88.0 | 89.7 | 86.3 | 93.4 |
| Baseline+LRF | ResNet-101 | 53.4M | 86.5 | 88.0 | 87.6 | 90.9 | 89.6 | 92.3 |
| Baseline+both | ResNet-101 | 55.3M | 87.9 | 89.4 | 88.6 | 92.2 | 90.1 | 94.6 |
| HRNet-W32 [39] | HRNet-W32 | 28.5M | 84.6 | 83.0 | 88.6 | 89.4 | 85.4 | 94.0 |
| HRNet-W32+SR | HRNet-W32 | 30.4M | 87.0 | 86.9 | 88.4 | 91.4 | 89.9 | 93.0 |
| HRNet-W32+LRF | HRNet-W32 | 28.6M | 86.7 | 82.7 | 91.0 | 91.1 | 88.2 | 94.3 |
| HRNet-W32+both | HRNet-W32 | 30.5M | 88.7 | 91.6 | 87.6 | 92.3 | 91.9 | 92.6 |
| HRNet-W48 [39] | HRNet-W48 | 63.6M | 85.6 | 86.7 | 87.3 | 90.2 | 87.7 | 93.1 |
| HRNet-W48+SR | HRNet-W48 | 65.5M | 89.4 | 86.7 | 92.2 | 92.9 | 91.2 | 94.8 |
| HRNet-W48+LRF | HRNet-W48 | 63.7M | 86.9 | 86.4 | 90.5 | 90.9 | 86.7 | 95.7 |
| HRNet-W48+both | HRNet-W48 | 65.6M | 90.1 | 86.6 | 96.4 | 94.1 | 91.3 | 97.3 |
| Method | Backbone | GFLOPs | AP | AP | AP | AR | AR | AR |
|---|---|---|---|---|---|---|---|---|
| +FSRCNN [41] | ResNet-50 | +4.18 | 83.6 | 84.8 | 84.4 | 89.0 | 85.6 | 90.2 |
| +RDN [42] | ResNet-50 | +16.3 | 84.2 | 85.4 | 85.0 | 89.3 | 86.2 | 91.6 |
| +SOF-VSR [43] | ResNet-50 | +15.6 | 84.8 | 85.7 | 86.3 | 89.5 | 86.3 | 92.8 |
| +FeNet [44] | ResNet-50 | +1.87 | 84.1 | 84.9 | 85.6 | 89.2 | 85.8 | 91.5 |
| +SR | ResNet-50 | +3.77 | 85.3 | 86.8 | 87.6 | 90.2 | 87.3 | 94.8 |
| +FSRCNN [41] | HRNet-W32 | +4.18 | 85.3 | 85.4 | 86.0 | 89.2 | 87.3 | 89.6 |
| +RDN [42] | HRNet-W32 | +16.3 | 85.9 | 86.5 | 86.2 | 90.0 | 89.9 | 90.1 |
| +SOF-VSR [43] | HRNet-W32 | +15.6 | 86.1 | 86.9 | 84.6 | 90.0 | 89.6 | 90.4 |
| +FeNet [44] | HRNet-W32 | +1.87 | 85.6 | 86.0 | 85.6 | 89.9 | 86.8 | 89.8 |
| +SR | HRNet-W32 | +3.77 | 87.0 | 89.2 | 88.4 | 91.4 | 89.9 | 93.0 |
| Conv Type | Backbone | AP | AP | AP | AR | AR | AR |
|---|---|---|---|---|---|---|---|
| Dilation | ResNet-50 | 82.6 | 81.4 | 85.2 | 88.6 | 85.2 | 92.4 |
| Small | ResNet-50 | 83.8 | 82.9 | 87.0 | 88.8 | 85.5 | 92.5 |
| Large | ResNet-50 | 86.3 | 84.9 | 89.4 | 91.2 | 88.7 | 93.9 |
| Dilation | ResNet-101 | 84.0 | 85.2 | 85.9 | 89.5 | 86.3 | 93.1 |
| Small | ResNet-101 | 85.3 | 86.3 | 87.4 | 90.0 | 87.0 | 93.3 |
| Large | ResNet-101 | 86.5 | 88.0 | 87.6 | 90.9 | 89.6 | 92.3 |
| Dilation | HRNet-W32 | 82.1 | 79.5 | 85.0 | 87.0 | 84.5 | 89.8 |
| Small | HRNet-W32 | 85.1 | 80.7 | 90.0 | 89.6 | 85.7 | 94.1 |
| Large | HRNet-W32 | 86.7 | 82.7 | 91.0 | 91.1 | 88.2 | 94.3 |
| Dilation | HRNet-W48 | 84.8 | 81.4 | 89.2 | 89.4 | 86.2 | 93.0 |
| Small | HRNet-W48 | 85.9 | 83.0 | 89.3 | 90.9 | 88.5 | 93.6 |
| Large | HRNet-W48 | 86.9 | 86.4 | 90.5 | 90.9 | 86.7 | 95.7 |
| Kernel | Backbone | Activation Function | AP | AP | AP | AR | AR | AR |
|---|---|---|---|---|---|---|---|---|
| 3 | ResNet-50 | GeLU | 83.6 | 84.4 | 85.2 | 88.7 | 85.9 | 91.9 |
| 7 | ResNet-50 | GeLU | 86.3 | 84.9 | 89.4 | 91.2 | 88.7 | 93.9 |
| 11 | ResNet-50 | GeLU | 85.8 | 84.4 | 90.3 | 89.3 | 85.1 | 94.2 |
| 13 | ResNet-50 | GeLU | 84.9 | 79.5 | 91.6 | 88.7 | 84.0 | 94.1 |
| 7 | ResNet-50 | ReLU | 84.0 | 83.4 | 88.0 | 88.3 | 83.7 | 93.5 |
| 3 | HRNet-W32 | GeLU | 84.8 | 87.4 | 82.3 | 89.6 | 91.1 | 87.9 |
| 7 | HRNet-W32 | GeLU | 86.7 | 82.7 | 91.0 | 91.1 | 88.2 | 94.3 |
| 11 | HRNet-W32 | GeLU | 86.6 | 82.7 | 91.3 | 91.1 | 88.2 | 94.3 |
| 13 | HRNet-W32 | GeLU | 85.8 | 84.4 | 90.3 | 89.3 | 85.1 | 94.2 |
| 7 | HRNet-W32 | ReLU | 86.5 | 83.6 | 90.4 | 90.9 | 89.0 | 93.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, X.; Fu, D.; Han, S. LRF-SRNet: Large-Scale Super-Resolution Network for Estimating Aircraft Pose on the Airport Surface. Sensors 2023, 23, 1248. https://doi.org/10.3390/s23031248
Yuan X, Fu D, Han S. LRF-SRNet: Large-Scale Super-Resolution Network for Estimating Aircraft Pose on the Airport Surface. Sensors. 2023; 23(3):1248. https://doi.org/10.3390/s23031248
Chicago/Turabian StyleYuan, Xinyang, Daoyong Fu, and Songchen Han. 2023. "LRF-SRNet: Large-Scale Super-Resolution Network for Estimating Aircraft Pose on the Airport Surface" Sensors 23, no. 3: 1248. https://doi.org/10.3390/s23031248