
Accurate Monocular SLAM Initialization via Structural Line Tracking

Abstract
:1. Introduction
Motivations and Contributions
- (1)
- A modified structural line feature tracking method that combines descriptor-based and optical-flow-based tracking. We aim to continuously track structural lines as much as possible in a sequence of image frames. Conventional line tracking methods suffer from problems of misalignment and missed matches, which pose challenges to the quantity and tracking stability of structural line matching. In particular, indiscriminate line matching introduces many non-structural lines, resulting in additional computational costs. By utilizing vanishing point constraints and performing line filtering in advance, we can reduce these costs and eliminate interference. Finally, we combine line descriptor matching and optical flow tracking to achieve the best matching results for structural lines.
- (2)
- The introduction of VPPO as a novel camera pose optimization strategy that utilizes 3D–2D line reprojection and the geometric constraints of structural features. We extensively employ the geometric constraints of structural features to optimize the camera pose. Apart from reprojection error terms, we integrate error terms associated with geometric constraints into the optimization process. These encompass vanishing point direction error terms that effectively restrict camera rotation and plane error terms that positively influence camera translation.
- (3)
- Novel evaluation metrics for assessing the map quality and evaluating the structural properties of the 3D line landmark. We propose two novel definitions for assessing the quality of initialization maps generated using structural features. This is crucial because the structural features within a scene are not solely tied to the pixels in the camera images. It is essential to evaluate and describe their spatial relationships within the generated initialization maps. Consequently, we introduce the evaluation of orthogonal and parallel positional relationships among the structural features in the initialization map as new indicators for assessing map quality. This also helps to further illustrate the advantages of our method in the generation of initialization maps. Instead of discrete 3D point coordinates, we now have 3D lines with geometric positional relationships.
2. Related Work
2.1. Classification of Visual Motion Estimation Methods
2.2. Geometric Constraint Methods
2.3. Monocular Initialization Algorithms
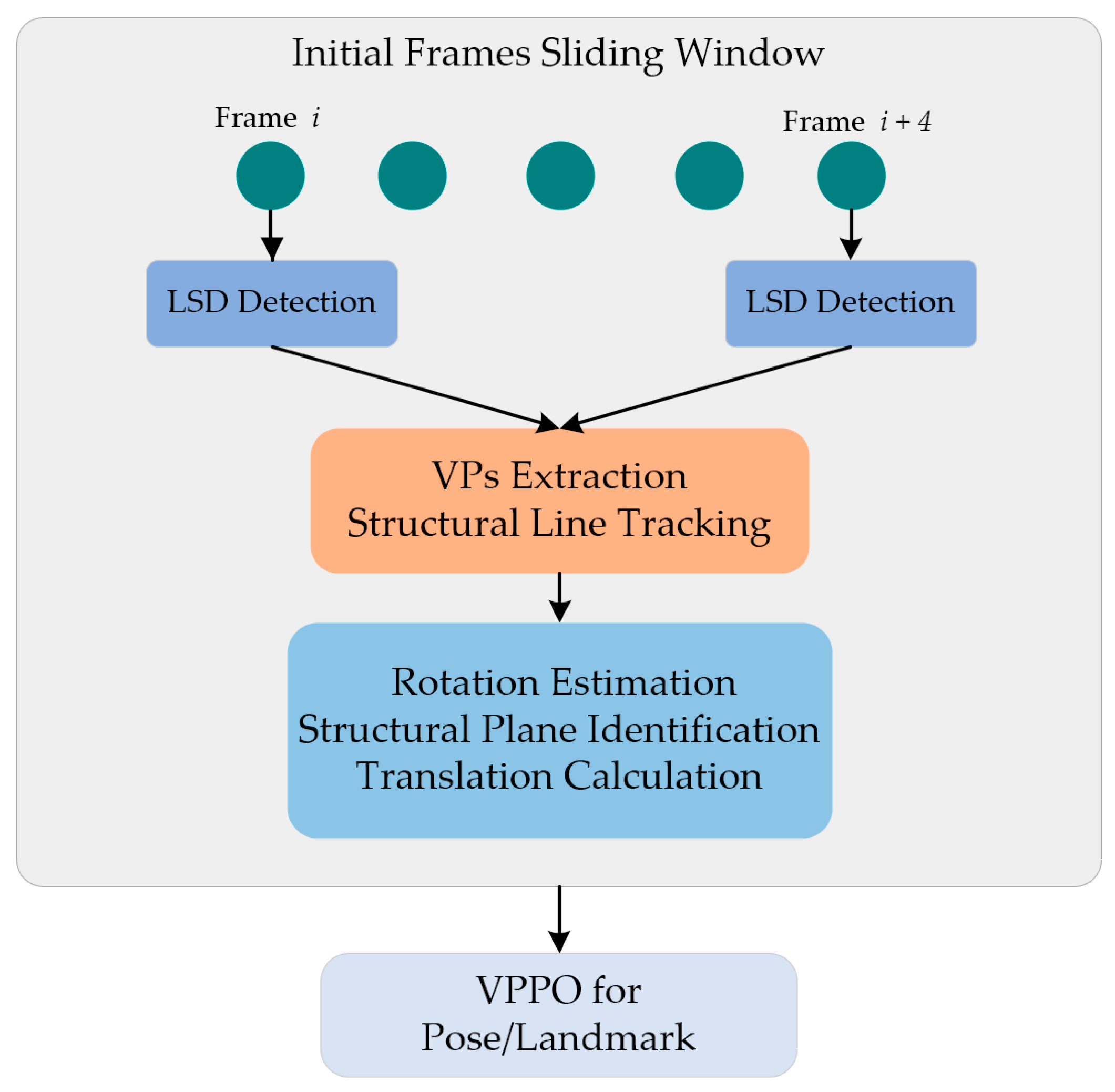
3. Algorithm Overview
Notations
4. Structural-Line-Based SLAM Initialization
4.1. VP Extraction and Structural Line Tracking
4.2. Rotation Estimation with VPs
4.3. Structural Plane Identification
4.4. Translation Calculation
4.5. Map Initialization and Optimization
5. Experimental Results
5.1. Dataset, Evaluation Metrics
5.2. Implementation Details
5.3. Baseline Methods Discussion
5.3.1. Aggregation-Based PnP
5.3.2. Multi-Frame Optimization
5.4. Ablation Study for Line Tracking
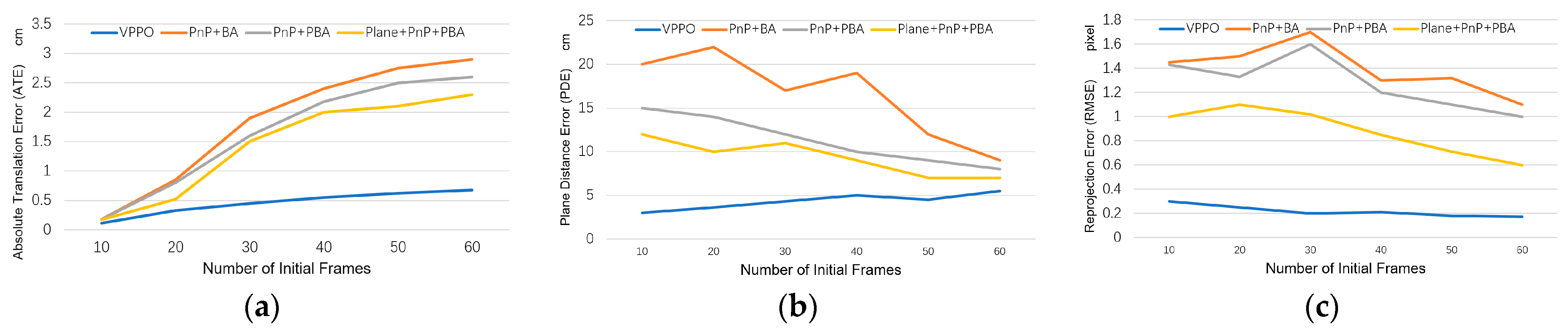
5.5. Comparison with Aggregation-Based PnP Methods
5.6. Comparison with Multi-Frame Optimization Methods
5.7. Initialize Map Quality Evaluation
5.8. Qualitative Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marchand, E.; Uchiyama, H.; Spindler, F. Pose Estimation for Augmented Reality: A Hands-On Survey. IEEE Trans. Vis. Comput. Graph. 2016, 22, 2633–2651. [Google Scholar] [CrossRef] [PubMed]
- Ros, G.; Sappa, A.; Ponsa, D.; Lopez, A.M. Visual slam for driverless cars: A brief survey. In Proceedings of the Intelligent Vehicles Symposium (IV) Workshops, Madrid, Spain, 3 June 2012; Volume 2, pp. 1–6. [Google Scholar]
- Xu, G.; Zhang, Q.; Li, N. Study on the method of SLAM initialization for monocular vision. IOP Conf. Ser. Mater. Sci. Eng. 2019, 569, 052085. [Google Scholar] [CrossRef]
- Kottas, D.G.; Roumeliotis, S.I. Efficient and consistent vision-aided inertial navigation using line observations. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 1540–1547. [Google Scholar]
- Coughlan, J.M.; Yuille, A.L. Manhattan world: Compass direction from a single image by bayesian inference. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 941–947. [Google Scholar]
- Orghidan, R.; Salvi, J.; Gordan, M.; Orza, B. Camera calibration using two or three vanishing points. In Proceedings of the 2012 Federated Conference on Computer Science and Information Systems (FedCSIS), Wroclaw, Poland, 9–12 September 2012; pp. 123–130. [Google Scholar]
- Li, H.; Yao, J.; Bazin, J.-C.; Lu, X.; Xing, Y.; Liu, K. A monocular SLAM system leveraging structural regularity in Manhattan world. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2518–2525. [Google Scholar]
- Elloumi, W.; Treuillet, S.; Leconge, R. Real-time estimation of camera orientation by tracking orthogonal vanishing points in videos. In International Conference on Computer Vision Theory and Applications; SCITEPRESS: San Francisco, CA, USA, 2013; Volume 2, pp. 215–222. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense Tracking and Mapping in Real-Time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect visual odometry for monocular and multicamera systems. IEEE Trans. Robot. 2016, 33, 249–265. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8690, pp. 834–849. [Google Scholar]
- Younes, G.; Asmar, D.; Shammas, E. A survey on non-filter-based monocular visual SLAM systems. arXiv 2016, arXiv:1607.00470. [Google Scholar]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Nistér, D. An efficient solution to the five-point relative pose problem. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 756–770. [Google Scholar] [CrossRef] [PubMed]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Vincent, E.; Laganiére, R. Detecting planar homographies in an image pair. In Proceedings of the 2nd International Symposium on Image and Signal Processing and Analysis. In Conjunction with 23rd International Conference on Information Technology Interfaces, Pula, Croatia, 19–21 June 2001; pp. 182–187. [Google Scholar]
- Guerrero, J.J.; Sagüés, C. Robust line matching and estimate of homographies simultaneously. In Proceedings of the Pattern Recognition and Image Analysis: First Iberian Conference, IbPRIA 2003, Puerto de Andratx, Mallorca, Spain, 4–6 June 2003; Proceedings 1. Springer: Berlin/Heidelberg, Germany, 2003; pp. 297–307. [Google Scholar]
- Zhou, Z.; Jin, H.; Ma, Y. Robust plane-based structure from motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1482–1489. [Google Scholar]
- Gomez-Ojeda, R.; Briales, J.; Gonzalez-Jimenez, J. PL-SVO: Semi-Direct Monocular Visual Odometry by Combining Points and Line Segments. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4211–4216. [Google Scholar]
- Kim, P.; Coltin, B.; Kim, H.J. Low-drift visual odometry in structured environments by decoupling rotational and translational motion. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 7247–7253. [Google Scholar]
- Kim, P.; Coltin, B.; Kim, H.J. Linear RGB-D SLAM for planar environments. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 333–348. [Google Scholar]
- Zhou, H.; Zou, D.; Pei, L.; Ying, R.; Liu, P.; Yu, W. StructSLAM: Visual SLAM with building structure lines. IEEE Trans. Veh. Technol. 2015, 64, 1364–1375. [Google Scholar] [CrossRef]
- Zou, D.; Wu, Y.; Pei, L.; Ling, H.; Yu, W. StructVIO: Visual-inertial odometry with structural regularity of man-made environments. IEEE Trans. Robot. 2019, 35, 999–1013. [Google Scholar] [CrossRef]
- Zhang, J.; Zeng, G.; Zha, H. Structure-aware SLAM with planes and lines in man-made environment. Pattern Recognit. Lett. 2019, 127, 181–190. [Google Scholar] [CrossRef]
- Li, Y.; Brasch, N.; Wang, Y.; Navab, N.; Tombari, F. Structure-slam: Low-drift monocular slam in indoor environments. IEEE Robot. Autom. Lett. 2020, 5, 6583–6590. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Herrera, D.C.; Kim, K.; Kannala, J.; Pulli, K.; Heikkila, J. Dt-slam: Deferred triangulation for robust slam. In Proceedings of the 2nd International Conference on 3D Vision, Tokyo, Japan, 8–11 December 2014; Volume 1, pp. 609–616. [Google Scholar]
- Hartley, R.I.; Sturm, P. Triangulation. Comput. Vis. Image Underst. 1997, 68, 146–157. [Google Scholar] [CrossRef]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An accurate O(n) solution to the PnP problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Cui, Z.; Tan, P. Global structure-from-motion by similarity averaging. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 864–872. [Google Scholar]
- Butt, M.M.; Zhang, H.; Qiu, X.; Ge, B. Monocular SLAM Initialization Using Epipolar and Homography Model. In Proceedings of the 2020 5th International Conference on Control and Robotics Engineering (ICCRE), Osaka, Japan, 24–26 April 2020; pp. 177–182. [Google Scholar]
- Qin, T.; Shen, S. Robust initialization of monocular visual-inertial estimation on aerial robots. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4225–4232. [Google Scholar]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.-M.; Randall, G. LSD: A line segment detector. Image Process. Line 2012, 2, 35–55. [Google Scholar] [CrossRef]
- Kroeger, T.; Dai, D.; Van Gool, L. Joint vanishing point extraction and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2449–2457. [Google Scholar]
- He, Q.; Chu, C.H.H. An efficient vanishing point detection by clustering on the normalized unit sphere. In Proceedings of the International Workshop on Computer Architecture for Machine Perception and Sensing, Montreal, QC, Canada, 18–20 August 2006; pp. 203–207. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Pumarola, A.; Vakhitov, A.; Agudo, A.; Sanfeliu, A.; Moreno-Noguer, F. PL-SLAM: Real-time monocular visual SLAM with points and lines. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4503–4508. [Google Scholar]
- Zuo, X.; Xie, X.; Liu, Y.; Huang, G. Robust visual SLAM with point and line features. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1775–1782. [Google Scholar]
- Lee, S.J.; Hwang, S.S. Elaborate monocular point and line slam with robust initialization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 Octobar–2 November 2019; pp. 1121–1129. [Google Scholar]
- Zhang, L.; Koch, R. An efficient and robust line segment matching approach based on LBD descriptor and pairwise geometric consistency. J. Vis. Commun. Image Represent. 2013, 24, 794–805. [Google Scholar] [CrossRef]
- Pérez, J.S.; López, N.M.; de la Nuez, A.S. Robust optical flow estimation. Image Process. Online 2013, 3, 252–270. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Gu, T.; Zhang, Y.; Xing, G. Real-time camera pose estimation via line tracking. Vis. Comput. 2018, 34, 899–909. [Google Scholar] [CrossRef]
- Kim, C.; Manduchi, R. Planar structures from line correspondences in a manhattan world. In Proceedings of the 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Springer: Singapore, 2015; pp. 509–524. [Google Scholar]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4104–4113. [Google Scholar]
- OpenCV. Open Source Computer Vision Library. 2015. [Google Scholar]
- Agarwal, S.; Mierle, K.; The Ceres Solver Team. Ceres Solver. Available online: http://ceres-solver.org (accessed on 13 December 2023).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Number of Sequences | Frames per Test | Repeated Test per Sequence | Frames Involved in Test per Sequence |
|---|---|---|---|---|
| Chessboard | 8 | 60 | 6 | 360 |
| ICL-NUM | 2 | 60 | 10 | 600 |
| Real-world scenes | 2 | 60 | 10 | 600 |
| VPPO | PnP + BA | PnP + PBA | Plane + PnP + PBA | |
|---|---|---|---|---|
| Pose estimation time (ms) | 3.3 | 7.6 | 6.8 | 10.8 |
| Optimization time (ms) | 25.1 | 60.3 | 45.5 | 35.4 |
| VPPO | PnP + BA | PnP + PBA | Plane + PnP + PBA | |
|---|---|---|---|---|
| OAE (radian) | 0.0352 | 0.1835 | 0.1785 | 0.1584 |
| PAE (radian) | 0.0385 | 0.3212 | 0.1973 | 0.1885 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, T.; Zhang, J.; Liu, Y. Accurate Monocular SLAM Initialization via Structural Line Tracking. Sensors 2023, 23, 9870. https://doi.org/10.3390/s23249870
Gu T, Zhang J, Liu Y. Accurate Monocular SLAM Initialization via Structural Line Tracking. Sensors. 2023; 23(24):9870. https://doi.org/10.3390/s23249870
Chicago/Turabian StyleGu, Tianlun, Jianwei Zhang, and Yanli Liu. 2023. "Accurate Monocular SLAM Initialization via Structural Line Tracking" Sensors 23, no. 24: 9870. https://doi.org/10.3390/s23249870