
VP-SOM: View-Planning Method for Indoor Active Sparse Object Mapping Based on Information Abundance and Observation Continuity

Abstract
:1. Introduction
- We propose a view-planning method for indoor object active mapping, including the selection of candidate views and NBVs.
- We propose a view-evaluation function for sparse object models, to ensure the information abundance and observation continuity of objects.
- We validated our method through the accuracy, precision of object maps, and observation efficiency in the simulation environments.
2. Related Work
2.1. Information-Entropy-Based Methods
2.2. Object-Based Methods
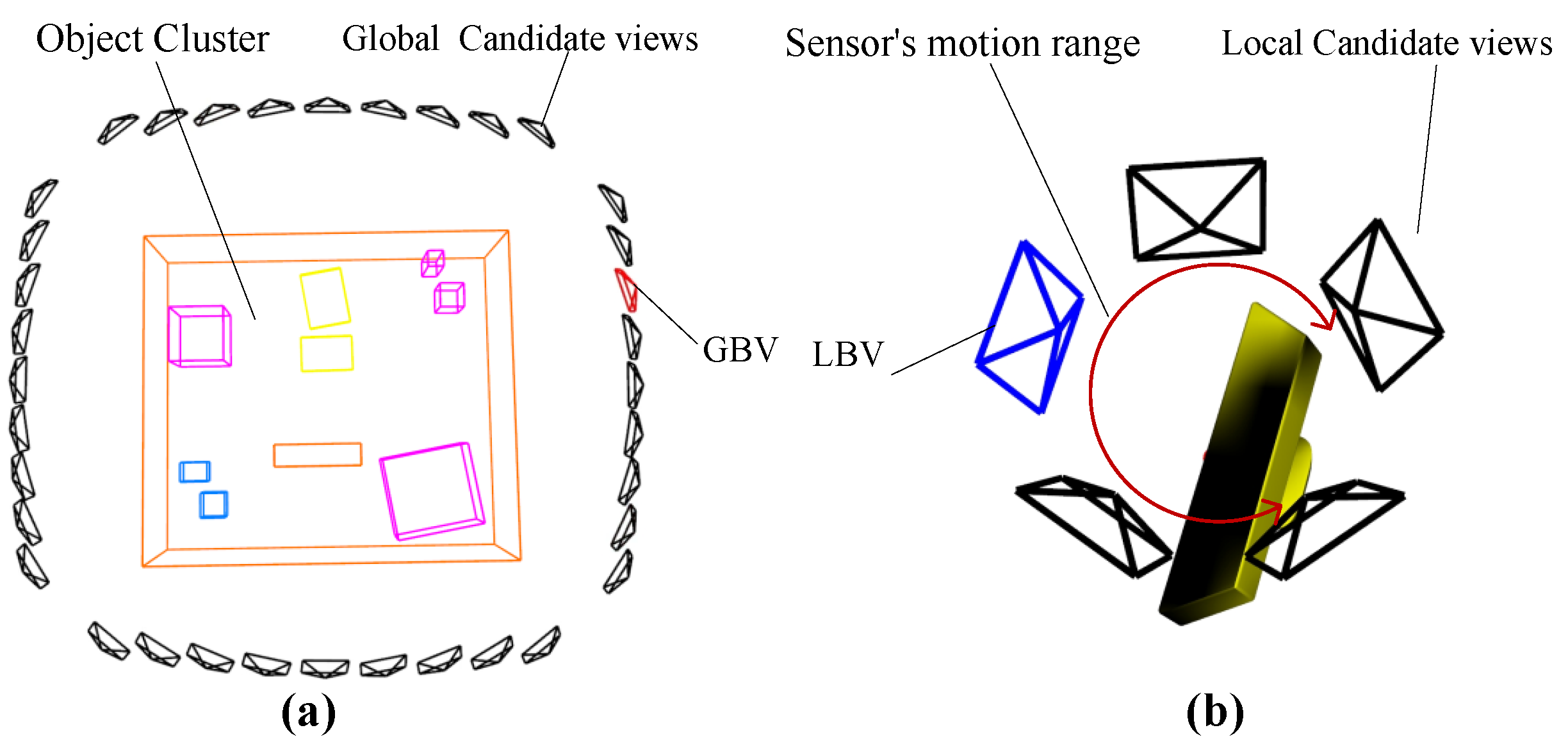
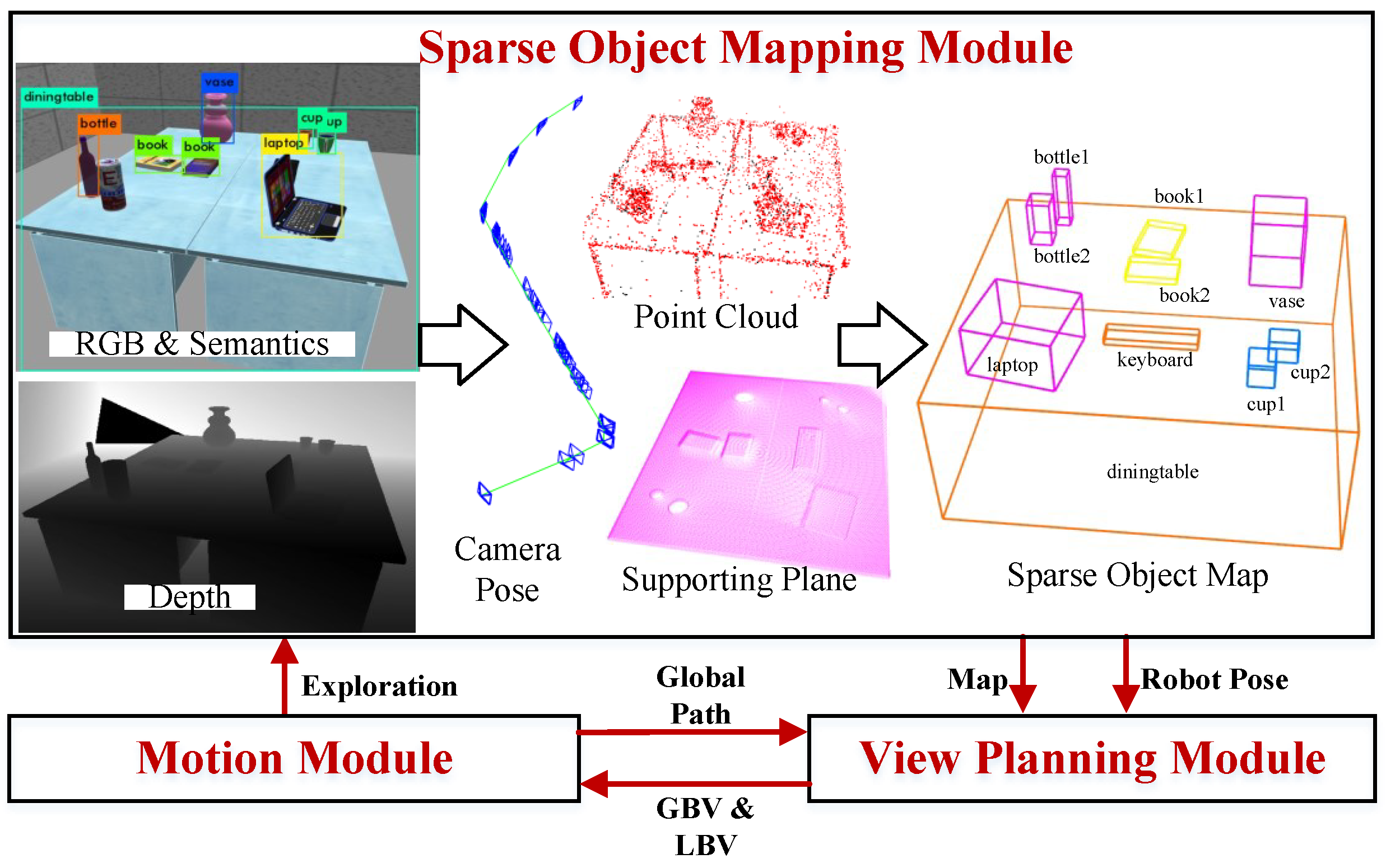
3. View-Planning Method for Indoor Sparse Object Mapping
3.1. View-Evaluation Function
| Algorithm 1 VP-SOM. |
|
3.2. Global Candidates and Global Best View
3.3. Local Candidates and Local Best View
3.4. Termination Condition
4. Evaluation on Information Abundance
4.1. Model Uncertainty
- Unknown: The grid is not observed, and . This state is represented by the gray grid.
- Occupied: The grid is occupied by points, and . This state is represented by the deep-colored grid.
- Free: The grid is observed, but not occupied, and . This state is represented by the light-colored grid.
- If , the observation for g is unknown, and , .
- If and , the observation for g is occupied, and , .
- If and , the observation for g is free, and . equals the minimum observation number of occupied grids in the same column.
4.2. Deviation of Foreground Object’s Best LoS
4.3. Object–Point Cloud Association Confidence
4.4. Non-Occlusion
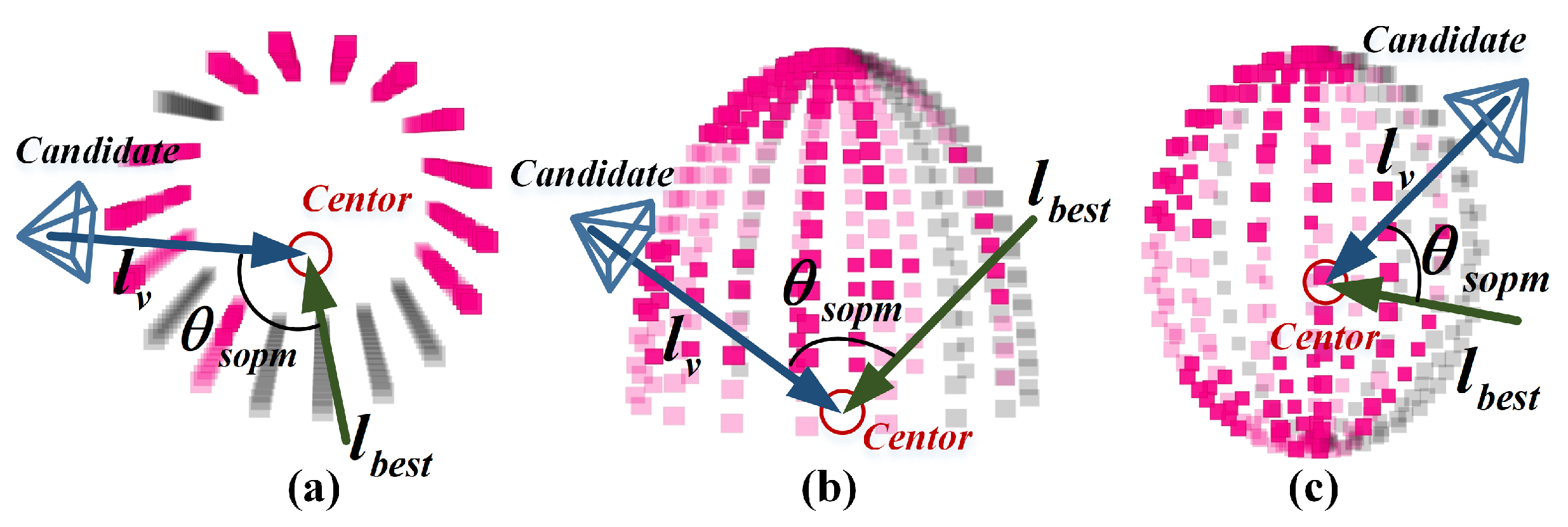
5. Evaluation on Observation Continuity
5.1. Co-Visibility Proportion
- The point p is inside the FoV of candidate view v;
- The point p is inside the object cluster tracked;
- The distance between point p and the candidate view is within the camera’s sensing range, to ensure the performance of the point feature descriptors;
- The co-visibility angle between the candidate view and the old co-visible LoS is less than the threshold . The old co-visible LoS is the mean LoS of point p in the neighboring views.
5.2. Deviation of Object Cluster’s Best LoS
6. Active Mapping System Based on View-Planning Method for Indoor Active Sparse Object Mapping
| Algorithm 2 Active mapping based on VP-SOM |
|
7. Experiment
7.1. Experiment Setup
- VP-SOM: We applied Algorithm 1 to generate the GBVs and LBVs and directed the robot to autonomously explore the indoor environment. The robot navigated to the GBVs using its chassis navigation. Simultaneously, the robot continuously rotated its neck to align the camera with the LBVs. Foreground object mapping ended when the model uncertainty was less than 0.42.
- All-views’ coverage: The robot walked a complete circle around every object cluster, while its top camera constantly pointed at the center of the current object cluster, ensuring coverage of all observation angles of the object cluster. Every view on the observation trajectory of this method can be considered as one LBV. This method ended when the robot revolved around each object cluster once.
- Frontier exploration: According to [10], frontiers of 3D point cloud were used as GBVs to guide robot exploration of the indoor environment. This method ended when there are no more reachable frontiers in the map.
7.2. Sparse Object Map
- Precision: An object was considered to be accurately modeled if its semantic label matched its ground-truth and the center distance was less than 0.1 m. Precision is the ratio of the number of correct models to the total number of models .
- Recall: Recall is the ratio of the number of correct models to the total number of ground-truths .
- IoU: Align the centers and orientations of the object model and its ground-truth, then calculate their 3D IoU, which reflects the size accuracy of the object model.
- Center Distance Error (CDE): the center distance (in meters) between the object model and its ground-truth.
7.3. Observation Trajectory of Active Mapping
- Trajectory length: The distance traveled by the robot’s chassis from the start to the end of active mapping.
- Object non-occlusion degree: Calculate the average non-occlusion degree of the objects from all NBV perspectives according to (21).
- Number of localization failures: When visual localization failed in SLAM, we let the robot keep moving until successful relocalization. If the time interval between failure to localize and successful relocalization exceeded 1 s and the distance exceeded 0.3 m, the number of failures increased by one.
7.4. The Role of Each View-Evaluation Item
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rünz, M.; Agapito, L. Co-fusion: Real-time segmentation, tracking and fusion of multiple objects. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4471–4478. [Google Scholar]
- Runz, M.; Buffier, M.; Agapito, L. Maskfusion: Real-time recognition, tracking and reconstruction of multiple moving objects. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 16–20 October 2018; pp. 10–20. [Google Scholar]
- Yang, S.; Scherer, S. Cubeslam: Monocular 3-d object slam. IEEE Trans. Robot. 2019, 35, 925–938. [Google Scholar] [CrossRef]
- Nicholson, L.; Milford, M.; Sünderhauf, N. Quadricslam: Dual quadrics from object detections as landmarks in object-oriented slam. IEEE Robot. Autom. Lett. 2018, 35, 925–938. [Google Scholar] [CrossRef]
- Liao, Z.; Hu, Y.; Zhang, J.; Qi, X.; Zhang, X.; Wang, W. So-slam: Semantic object slam with scale proportional and symmetrical texture constraints. IEEE Robot. Autom. Lett. 2022, 7, 4008–4015. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, W. Making parameterization and constrains of object landmark globally consistent via spd (3) manifold. IEEE Robot. Autom. Lett. 2022, 7, 6383–6390. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Y.; Zhu, D.; Feng, Y.; Coleman, S.; Kerr, D. Eao-slam: Monocular semi-dense object slam based on ensemble data association. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 4966–4973. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar]
- Ok, K.; Liu, K.; Frey, K.; How, J.P.; Roy, N. Robust object-based slam for high-speed autonomous navigation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 669–675. [Google Scholar]
- Bai, S.; Wang, J.; Chen, F.; Englot, B. Information-theoretic exploration with bayesian optimization. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2016), Daejeon, Republic of Korea, 9–14 October 2016; pp. 1816–1822. [Google Scholar]
- Yamauchi, B. Frontier-based exploration using multiple robots. In Proceedings of the Second International Conference on Autonomous Agents, St. Paul, MN, USA, 9–13 May 1998; pp. 47–53. [Google Scholar]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. Octomap: An efficient probabilistic 3d mapping framework based on octrees. Auton. Robot. 2013, 34, 189–206. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Bourgault, F.; Makarenko, A.A.; Williams, S.B.; Grocholsky, B.; Durrant-Whyte, H.F. Information based adaptive robotic exploration. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Lausanne, Switzerland, 30 September–4 October 2002; Volume 1, pp. 540–545. [Google Scholar]
- Carrillo, H.; Dames, P.; Kumar, V.; Castellanos, J.A. Autonomous robotic exploration using a utility function based on rényi’s general theory of entropy. Auton. Robot. 2018, 42, 235–256. [Google Scholar] [CrossRef]
- Isler, S.; Sabzevari, R.; Delmerico, J.; Scaramuzza, D. An information gain formulation for active volumetric 3d reconstruction. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3477–3484. [Google Scholar]
- Wang, Y.; Ramezani, M.; Fallon, M. Actively mapping industrial structures with information gain-based planning on a quadruped robot. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 8609–8615. [Google Scholar]
- Zheng, L.; Zhu, C.; Zhang, J.; Zhao, H.; Huang, H.; Niessner, M.; Xu, K. Active scene understanding via online semantic reconstruction. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2019; Volume 38, pp. 103–114. [Google Scholar]
- Placed, J.A.; Rodríguez, J.J.G.; Tardós, J.D.; Castellanos, J.A. ExplORB-SLAM: Active visual SLAM exploiting the pose-graph topology. In Proceedings of the Iberian Robotics Conference, Zaragoza, Spain, 23 November 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 199–210. [Google Scholar]
- Placed, J.A.; José, A. Castellanos. A general relationship between optimality criteria and connectivity indices for active graph-SLAM. IEEE Robot. Autom. Lett. 2022, 8, 816–823. [Google Scholar] [CrossRef]
- Scott, W.R.; Roth, G.; Rivest, J.-F. View planning for automated three-dimensional object reconstruction and inspection. ACM Comput. (CSUR) 2003, 35, 64–96. [Google Scholar] [CrossRef]
- Scott, W.R. Model-based view planning. Mach. Vis. Appl. 2009, 20, 47–69. [Google Scholar] [CrossRef]
- Cui, J.; Wen, J.T.; Trinkle, J. A multi-sensor next-best-view framework for geometric model-based robotics applications. In Proceedings of the 2019 IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8769–8775. [Google Scholar]
- Chen, S.; Li, Y. Vision sensor planning for 3-d model acquisition. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2005, 35, 894–904. [Google Scholar] [CrossRef] [PubMed]
- Whaite, P.; Ferrie, F.P. Autonomous exploration: Driven by uncertainty. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 193–205. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Z. Information entropy-based view planning for 3-d object reconstruction. IEEE Trans. Robot. 2005, 21, 324–337. [Google Scholar] [CrossRef]
- Wong, L.M.; Dumont, C.; Abidi, M.A. Next best view system in a 3d object modeling task. In Proceedings of the 1999 IEEE International Symposium on Computational Intelligence in Robotics and Automation, CIRA’99 (Cat. No. 99EX375). Monterey, CA, USA, 8–9 November 1999; pp. 306–311. [Google Scholar]
- Dornhege, C.; Kleiner, A. A frontier-void-based approach for autonomous exploration in 3d. Adv. Robot. 2013, 27, 459–468. [Google Scholar] [CrossRef]
- Monica, R.; Aleotti, J. Contour-based next-best view planning from point cloud segmentation of unknown objects. Auton. Robot. 2018, 42, 443–458. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Y.; Zhu, D.; Chen, X.; Coleman, S.; Sun, W.; Hu, X.; Deng, Z. Object slam-based active mapping and robotic grasping. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; pp. 1372–1381. [Google Scholar]
- Wu, Y.; Zhang, Y.; Zhu, D.; Deng, Z.; Sun, W.; Chen, X.; Zhang, J. An Object SLAM Framework for Association, Mapping, and High-Level Tasks. In IEEE Transactions on Robotics; Springer International Publishing: Cham, Switzerland, 2023. [Google Scholar]
- Patten, T.; Zillich, M.; Fitch, R.; Vincze, M.; Sukkarieh, S. View evaluation for online 3-d active object classification. IEEE Robot. Autom. Lett. 2015, 1, 73–81. [Google Scholar] [CrossRef]
- Liu, Y.; Petillot, Y.; Lane, D.; Wang, S. Global localization with object-level semantics and topology. In Proceedings of the 2019 IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4909–4915. [Google Scholar]
- Thrun, S. Probabilistic robotics. Commun. ACM 2002, 45, 52–57. [Google Scholar] [CrossRef]
- Mu, B.; Liu, S.; Paull, L.; Leonard, J.; How, J.P. Slam with objects using a nonparametric pose graph. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4602–4609. [Google Scholar]
- Hannu, O. Multivariate Nonparametric Methods with R: An Approach Based on Spatial Signs and Ranks; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene | Metrics | VP-SOM | Cover | Frontier |
|---|---|---|---|---|
| 1 | Precision | 0.90 | 0.50 | 0.38 |
| Recall | 1 | 1 | 0.67 | |
| IoU | 0.769 | 0.558 | 0.590 | |
| CDE(m) | 0.041 | 0.084 | 0.113 | |
| 2 | Precision | 0.79 | 0.64 | 0.41 |
| Recall | 1 | 0.82 | 0.63 | |
| IoU | 0.789 | 0.562 | 0.728 | |
| CDE(m) | 0.089 | 0.127 | 0.103 | |
| 3 | Precision | 0.59 | 0.45 | 0.35 |
| Recall | 0.91 | 0.82 | 0.73 | |
| IoU | 0.795 | 0.647 | 0.401 | |
| CDE(m) | 0.052 | 0.062 | 0.534 | |
| Ave | Precision | 0.76 | 0.53 | 0.38 |
| Recall | 0.97 | 0.88 | 0.68 | |
| IoU | 0.784 | 0.589 | 0.573 | |
| CDE(m) | 0.061 | 0.091 | 0.250 |
| Scene | Metrics | VP-SOM | Cover | Frontier |
|---|---|---|---|---|
| 1 | Length of path | 10.39 | 12.05 | 8.58 |
| Cost time | 248 | 295 | 273 | |
| Non-occlusion | 0.631 | 0.426 | 0.279 | |
| Localization failure | 3 | 4 | 7 | |
| 2 | Length of path | 17.94 | 21.22 | 11.25 |
| Cost time | 385 | 463 | 472 | |
| Non-occlusion | 0.601 | 0.519 | 0.200 | |
| Localization failure | 7 | 9 | 14 | |
| 3 | Length of path | 18.80 | 23.62 | 19.55 |
| Cost time | 664 | 830 | 807 | |
| Non-occlusion | 0.464 | 0.383 | 0.239 | |
| Localization failure | 5 | 6 | 13 | |
| Ave | Length of path | 15.71 | 18.96 | 13.13 |
| Cost time | 432 | 529 | 517 | |
| Non-occlusion | 0.565 | 0.443 | 0.239 | |
| Localization failure | 5 | 6 | 11 |
| Local Candidate | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 0 | 0.073 | 0.637 | 0.9 | 1.383 | 0.773 | 0.133 | |
| −0.494 | 0.111 | 0.413 | 0.674 | 0.979 | 0.994 | 0.739 | |
| Evaluation value | 0 | 0.008 | 0.263 | 0.607 | 1.354 | 0.768 | 0.098 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wang, W. VP-SOM: View-Planning Method for Indoor Active Sparse Object Mapping Based on Information Abundance and Observation Continuity. Sensors 2023, 23, 9415. https://doi.org/10.3390/s23239415
Zhang J, Wang W. VP-SOM: View-Planning Method for Indoor Active Sparse Object Mapping Based on Information Abundance and Observation Continuity. Sensors. 2023; 23(23):9415. https://doi.org/10.3390/s23239415
Chicago/Turabian StyleZhang, Jiadong, and Wei Wang. 2023. "VP-SOM: View-Planning Method for Indoor Active Sparse Object Mapping Based on Information Abundance and Observation Continuity" Sensors 23, no. 23: 9415. https://doi.org/10.3390/s23239415