1. Introduction
In the last decade, deep learning has enabled significant progress in a variety of applications including object detection [
1,
2], face recognition [
3], iris recognition [
4], genetic algorithms applied to CNNs [
5,
6], rock lithological classification [
7], trademark image retrieval [
8], and semantic segmentation [
9], among others. Pedestrian detection is one of the key tasks in computer vision, for which several models have been developed in the past few years [
10,
11,
12,
13,
14,
15,
16,
17,
18,
19]. The performance has shown a steady improvement over time, especially with the boom of deep-learning-based methods, with certain benchmarks approaching human performance [
20], e.g., the Caltech benchmark [
21]. Many real-world applications require high performance on pedestrian detection, e.g., autonomous driving, robotic navigation, video surveillance, action recognition, and tracking [
22,
23,
24]. In autonomous driving, a robust pedestrian detection method is a key element to develop. Pedestrians tended to suffer more injuries when a crash occurred between vehicles and pedestrians. According to the National Highway Traffic Safety Administration, traffic accidents in the United States generated 7388 pedestrian fatalities, and 60,577 pedestrians were injured in the year 2021 [
25]. In Europe, 3608 pedestrian fatalities were reported in 2020, this being 19% of the total road fatalities [
26].
The nature of the possible applications involving pedestrian detection makes it necessary to have performance characterized by high accuracy and real-time operation [
27]. Some of the main challenges for pedestrian detection methods are that the individuals in the images present different scales, several occlusions, and various aspect ratios, among others [
28].
The pedestrian detection problem could be viewed as a sub-problem of the broader object detection problem, and, therefore, many methods can be adapted to detect pedestrians instead of generic objects [
29]. In the deep learning approaches, two main methods have been used for object detection: one-stage approaches, such as SSD [
30] and YOLO [
31], and two-stage approaches, with methods such as Faster R-CNN [
2] and Cascade R-CNN [
32]. A two-stage object detector includes an intermediate task of generating region proposals, and then, an object classification for each region proposed [
32]. In general, one-stage methods are faster than two-stage methods; however, two-stage methods achieve more robust performance [
32]. The pedestrian detection task, however, has its own challenges, not shared with the general object detection task. For example, the hard negative instances from background regions usually lead to confusion when detecting pedestrians [
33].
The ability of the current state-of-the-art (SOTA) methods to perform with high performance on cross-dataset testing is a problem that has not yet been solved. Hasan et al. [
20] showed that the current pedestrian detection methods are unsuccessful when the domain is changed, diminishing performance results when evaluated in cross-dataset scenarios.
In this context, domain change or domain shift is defined as the problem that arises when a distribution shift occurs between a set of training (source) data and a set of test (target) data. This problem is caused by most of the statistical learning methods relying on the assumption that both the source and target data are independent and identically distributed, while ignoring out-of-distribution scenarios that are commonly encountered in practice. This leads to a performance drop when an algorithm trained only with source data is tested on an out-of-distribution target domain. This problem has limited the deployment of large-scale models [
34]. Domain generalization is a machine learning problem in which the model learns from labeled training data across related tasks and then is expected to generalize to a future prediction task without access to labeled data [
35]. This concept was introduced to address the challenges of domain shift and a lack of target data. The objective is to train a model using data from one or more related but distinct source domains so that it can generalize to perform well and effectively in any out-of-distribution target domain [
34].
Our proposed method intends to improve some of the limitations mentioned, relying explicitly on approaches for domain adaptation, such as the triplet loss function. This family of loss functions has been used successfully in other computer vision tasks, e.g., face recognition [
3]. Here, we use triplet loss as an additional loss for the classification head, after the region of interest (ROI) extraction, in a two-stage pedestrian detector approach. We use this triplet loss function alongside the traditional classification and bounding box regression losses.
The main contribution of this study is a novel approach to pedestrian detection: the development of a new classification head for two-stage object detectors that incorporates the triplet loss function, to complement the classification and bounding box regression losses, with the objective of enhancing domain generalization capabilities in pedestrian detection tasks. The addition of triplet loss resulted in a new combined loss, that enhanced the feature compactness of pedestrian samples, thereby improving object detection performance relative to SOTA. This head is used at the final stage, being applied to the embeddings generated by the ROI extractor. According to our literature review, the proposed approach has not been used for the pedestrian detection task. One of the main goals of the proposed method is increasing performance on cross-dataset scenarios by maximizing the inter-class distance explicitly, and minimizing the intra-class distance, when a margin term is used to determine the decision boundary between positive and negative pairs. In this way, pedestrians coming from different domains (datasets) are clustered together in the feature space. Another important contribution is achieving improved results, relative to those of the SOTA, for the CityPersons benchmark, for the hardest partition available, using cross-training with a different dataset, i.e., not trained explicitly on any partition of the target dataset, and applied to a complex real-world dataset. Our proposed head could be used as a new direction for improving cross-dataset performance in other pedestrian detectors with compatible architectures, or other object detection tasks, considering real-world applications such as autonomous driving and video surveillance.
2. Related Work
The early approaches to pedestrian detection, and in general for object detection, used sliding windows over all the scales and locations [
36,
37,
38]. One of the first methods using this approach was proposed by Papageorgiou and Poggio [
37], who used a combination of multiscale Haar wavelets and Support Vector Machines (SVM). The work of Viola and Jones [
38] uses the concept of integral images, aimed at speeding up the Haar features computation, and then applies a cascade structure for efficient detection based on AdaBoost classifiers. Dalal and Triggs [
39] used features based on the Histogram of Oriented Gradients (HOG), and SVM for human detection, outperforming existing intensity-based features. Dollár et al. [
40] proposed Aggregate Channel Features (ACF) for pedestrian detection, improving the speed without sacrificing performance, approximating features on a finely sampled pyramid. Felzenszwalb et al. [
41] developed a method for object detection, based on mixtures of multiscale deformable models, using discriminative training of classifiers that make use of latent information.
Currently, the SOTA methods rely on deep learning, mostly on Convolutional Neural Networks (CNNs). These methods improved the performance of the object detection problem considerably [
1,
2,
30,
42]. Many of the generic object detection techniques were used as a base for modern pedestrian detection methods. One of the first CNN-based methods was proposed by Angelova et al. [
43]. Cascade classifiers and deep neural network features were used, resulting in a fast and accurate method, that runs in real-time on the Caltech Pedestrian detection benchmark.
Cai et al. [
44] developed a boosting algorithm called CompACT, by using a cascade design, optimizing a risk that accounts for both accuracy and complexity, and enabling the use of features with different complexities in a single detector. This includes a cascade combining CNNs with an object proposal mechanism, thus obtaining good results on Caltech and KITTI benchmarks. Hosang et al. [
45] performed several experiments with different CNN architectures available at that time, avoiding custom designs adapted for pedestrian detection. The authors show competitive results on Caltech and KITTI benchmark datasets. Zhang et al. [
33] proposed a method based on the Region Proposal Network (RPN) followed by cascaded boosted forests to classify the region proposals. Thus, features of arbitrary resolutions from any layers are combined, and hard negative mining is performed, overcoming the limitations of the original Faster R-CNN method. Brazil et al. [
10] proposed a multi-task infusion framework for joint semantic segmentation and pedestrian detection, obtaining SOTA results on the Caltech dataset, and competitive performance on the KITTI dataset.
Zhou and Yuan [
11] developed a method for both pedestrian detection, and occlusion estimation, using a CNN with two branches. The first branch was for full body estimation, and the second was for visible body part estimation. Both branches produce outputs that complement each other, improving detection performance. The method was assessed on the Caltech and CityPersons datasets, obtaining excellent results in detecting both non-occluded and occluded pedestrians.
Liu et al. [
12] proposed a Single Stage Detector (SSD) method, named Asymptotic Localization Fitting (ALF), which stacks a series of predictors to evolve the default anchor boxes of SSD, step by step, closer to labeled boxes, and then uses a pedestrian detection architecture called ALFNet. This method improved accuracy while maintaining the efficiency of single-stage detectors, achieving SOTA performance on the CityPersons and Caltech datasets.
Liu et al. [
13] proposed the CSP method, in which the pedestrian detection task is considered to be a high-level semantic feature detection, predicting the pedestrian center and scale using CNNs. This simple method reached competitive results in both detection and computing times on several pedestrian detection benchmarks.
Yin et al. [
46] proposed a method called DA-Net, utilizing a two-stage detector Feature Pyramid Network (FPN) and incorporating a Dense Connected Block (DCB), which comprises a Channel-Wise Attention Module (CWAM) and a Global Attention Module (GAM). By adding several DCBs to the network, the prediction layers captured richer semantic information from targets, leading to more precise target localization. The method was assessed on CityPersons and one of the evaluations was performed on the Heavy subset, obtaining good results.
Lin et al. [
47] proposed a pedestrian detector called PedJointNet, that simultaneously regresses two bounding boxes to the head–shoulder and full body regions based on a feasible object detection backbone. The detector achieved excellent performance in detecting both non-occluded and occluded pedestrians. The method was assessed on the CUHK-SYSU, TownCentre, and CityPersons datasets.
Cai et al. [
48] proposed an anchor-free and proposal-free pedestrian detector, called Pedestrian-as-Points Network (PP-Net), which finds a better trade-off between accuracy and efficiency. The authors modeled pedestrians as single points, i.e., the center point of the instance, and then predicted the pedestrian scale at each detected center point. To avoid the high-level information loss on the top-down pathway, a Deep Guidance Module (DGM) was built at the top of the backbone. They obtained SOTA results on Caltech and CityPersons benchmarks.
Zhang et al. [
49] assessed the performance of a Faster R-CNN pedestrian detector using a new dataset, CityPersons, that consists of person annotations on the Cityscapes dataset. The diversity of this dataset allowed training of a single model that generalizes well over various benchmarks.
Li et al. [
50] developed a pedestrian detector based on YOLOv7, aimed to improve the detection of obscured pedestrians. For this purpose, the default backbone for YOLOv7 was replaced with a lightweight MobileNetV3 backbone. Then, a high-resolution feature pyramid structure was used to improve missed detection of hidden pedestrians, and an attention mechanism was used to lower the redundant bounding boxes. The method was applied to the CrowdHuman dataset, obtaining promising results.
Liu et al. [
51] developed a pedestrian detector in a foggy traffic environment, named YOLO-GW, using the dark channel de-fogging algorithm, in conjunction with a YOLOv7 detector. Also, an ECA module and a detection head were added, aimed to improve object classification and regression. Results showed an improvement in the frame rate by 63.08%, and detection using mAP metric increased by 9.06%.
Braun et al. [
52] assessed the generalization capacity of four deep learning object detectors applied to pedestrian detection: Faster R-CNN, R-FCN, SSD, and YOLOv3, using a new dataset, EuroCity Persons. They studied the effect on the detector performance for many variables related to training set size, dataset diversity and detail, and annotation quality. It was observed that pre-training with very large sets outperforms using only target training sets.
Chao et al. [
53] also evaluated the generalization of human detectors. For this purpose, they created a large dataset, CrowdHuman, and assessed the cross-dataset generalization, obtaining new SOTA results on the Caltech, CityPersons, and Brainwash datasets. They demonstrated that the proposed new dataset could serve for pre-training human detectors.
Hasan et al. [
20] performed extensive assessment using many SOTA pedestrian detection methods. They tested their domain generalization capacities on certain popular general object detection methods, not specifically designed for pedestrian detection. The authors found that these general methods performed better compared to specific pedestrian detectors when cross-dataset experiments were performed. In general, the methods reached good detection performance when trained and tested on the same dataset, but results worsened when assessed on a different dataset.
The triplet loss function has been used in different machine learning and computer vision tasks, beginning with the work of Schroff et al. [
3], that used this function in the context of face recognition, proposing a method named FaceNet, that obtained a new record for accuracy on the LFW and YouTube Faces datasets. Other studies in face recognition using triplet loss were developed by Parkhi et al. [
54], Trigueros et al. [
55], Boutros et al. [
56], Yeung et al. [
57], and Feng et al. [
58].
Triplet loss has also been used successfully in the context of person re-identification in recent years. This problem is related to pedestrian detection, but presents some important differences, and is defined as the task of identifying and matching the same individuals either across various cameras or across time within a single camera [
59]. Along this line, many methods for person re-identification using triplet loss and reaching SOTA results have been proposed in the past few years, as in [
60,
61,
62,
63,
64,
65]. Interesting work was proposed by Wang et al. [
66], in which the triplet loss function is used to adjust the feature distance of each pedestrian to distinguish different pedestrians in crowded scenarios. However, in our method, we use the triplet loss function to help cluster together the features of all the pedestrians, instead of identifying single individuals.
The triplet loss function has been successfully used for domain generalization in various tasks. The research of Lee [
67], applied the triplet loss function for cross-corpus speech emotion recognition to generalize across domains. Yu et al. [
68] introduced an adapted triplet loss as a novel approach to mitigate bias in triplet selection, and address distribution shift in selected triplets, evaluating different image classification datasets. Wang et al. [
69] introduced a novel domain generalization framework, EISNet, which learns to generalize across diverse domains concurrently by utilizing both extrinsic relationship supervision and intrinsic self-supervision, particularly for images from multiple source domains. In the work of Dou et al. [
70], they used a model-agnostic learning paradigm to expose the optimization to domain shift, introducing two complementary losses that regularize the semantic structure of the feature space explicitly. Deng et al. [
71] studied metric learning within domain adaptation, introducing a similarity-guided constraint in the form of a triplet loss, where each triplet is taken from both the source and target domains.
Finally, we can mention other machine learning tasks, not restricted to computer vision, where triplet loss has been used. Here we can cite some tasks such as object tracking [
72,
73,
74], speaker recognition [
75,
76], intention detection for spoken language understanding in dialogue systems [
77], remote sensing image retrieval [
78], 3D gesture recognition [
79], automatic music cover detection [
80], and low-light image enhancement [
81].
Currently, there are many benchmarks for assessing pedestrian detection; for example, Daimler [
82], INRIA [
39], ETH [
83], TUDBrussels [
84], and WiderPedestrian [
85]. Many of these datasets were captured from surveillance scenarios, and were not suitable for autonomous driving applications. Instead, there are other datasets specifically aimed at autonomous driving, such as Caltech [
21], KITTI [
86], CityPersons [
49], and EuroCity Persons [
52].
From our literature review, it can be concluded that many methods reached good pedestrian detection performance when trained and tested on the same datasets. However, results worsened significantly when cross-dataset experiments were performed using a testing dataset different from that used for training. The ability to perform well on unseen scenarios is crucial for methods to be deployed in real-life applications. For example, the pedestrian detector in an autonomous vehicle is effectively a cross-dataset scenario, in which most of the data seen is new for the detector. We concluded that cross-dataset testing is a problem that has not yet been solved in the current SOTA. Another important issue present in our literature review is the limited ability to detect pedestrians with a high degree of occlusion. This can be confirmed by analyzing the results for the heavy partition on the CityPersons dataset, whose current SOTA results are still far from the results obtained for the reasonable partition, an easier scenario on which methods are able to obtain useful results for real-life applications.
3. Materials and Methods
Most two-stage pedestrian detectors that are present in the literature have two losses in the second stage: one loss for bounding box regression, and another for classification. Two-stage methods are preferred because they have achieved better performance, sacrificing speed when compared to the one-stage approaches. The two-stage methods proved to be successful if the train and test datasets come from the same domain, i.e., belong to the same dataset, but when these methods are evaluated on new, unseen datasets, performance drops significantly, as shown by Hasan et al. in [
20]. To overcome this issue, we designed a new head in the second stage, to try concentrating pedestrian examples in the feature space explicitly, independent of from which dataset they came, and separating the background examples from them. Our proposed method uses the concept of triplets that has been used successfully in other computer vision tasks [
3,
58]. We used the triplet loss function, which involves three samples in the calculation: an anchor sample, a sample of the same class as the anchor, and a sample with a different label. In this way, the network learns to minimize the distance between samples of the same label, while maximizing the distance of samples of different labels.
3.1. Two-Stage Object Detectors
In this work, we targeted our effort at improving the two-stage detector architecture. We performed experiments using Faster R-CNN [
2], and Cascade R-CNN [
32], which both belong to the R-CNN methods family. Cascade R-CNN outperforms Faster R-CNN in many object detection benchmarks, but we also included the latter method because it is still used, as is reported in the literature, to serve as a baseline for comparison. Both methods approach the detection as a multi-task learning problem, combining classification and bounding box regression.
Faster R-CNN [
2] is based on Fast R-CNN [
1], but the main difference includes a region proposal stage that is performed using a novel Region Proposal Network (RPN) that shares convolutional features with the detection network, thus enabling nearly cost-free region proposals. This RPN is a fully convolutional network that predicts bounding boxes and objectness scores at each position, at the same time. This improvement was developed to reduce the execution time of the region proposal stage which acted as a bottleneck in terms of speed.
Cascade R-CNN [
32] tackles the problem of noisy detections when a detector is trained with a low IoU threshold, such as 0.5 in most cases. This is not trivial to solve, since performance tends to degrade when the IoU thresholds are increased. To overcome this problem, a sequence of detection heads is trained with increasing IoU thresholds, stage by stage, to be more selective sequentially against close false positives. In this manner, false positive anchors are filtered out, generating better-quality proposals.
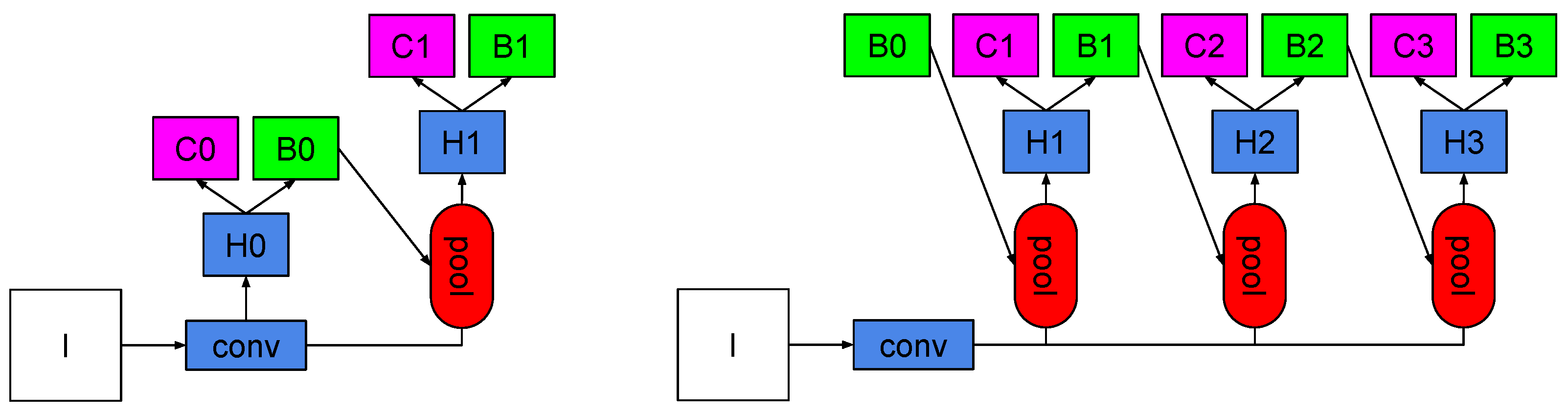
The generic architectures of both Faster R-CNN and Cascade R-CNN are shown in
Figure 1. In Faster R-CNN, the first stage is a region proposal sub-network H0, which operates on the entire image, generating preliminary detection hypotheses, known as object proposals, and denoted as B0. In the second stage, hypotheses are processed by a region-of-interest detection sub-network, H1, denoted as the detection head, assigning a final classification score, C1, and a refined bounding box, B1. This is analogous to Cascade R-CNN.
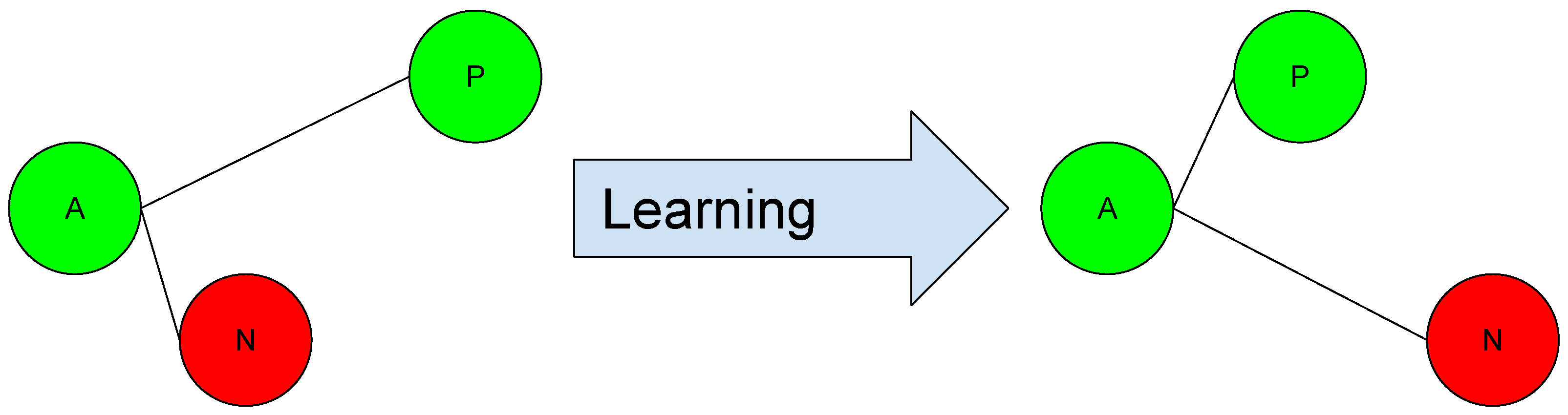
3.2. Triplet Loss
The triplet loss function trains the neural network to embed features of the same class, while maximizing the distance among embeddings of different classes. An anchor is chosen, along with one negative and one positive sample, to compute the loss. As a result, the triplet loss maximizes the inter-class distance explicitly while it minimizes the intra-class distance, where a margin term is used to determine the decision boundary between positive and negative pairs. Generally, this family of functions is applied to the sample projection (Embeddings), performed by a neural network. The behavior of this type of function is shown in
Figure 2. This function has been used successfully in many machine learning and computer vision applications, for example, in face recognition [
3,
54,
56], person re-identification [
59,
62,
63], object tracking [
72,
73,
74], and speaker recognition [
75,
76], etc.
Formally, this function is defined by triplets of embeddings, defining the following concepts:
An anchor sample a, for example, a pedestrian.
A positive sample p, with the same class as the anchor.
A negative sample n of a different class, for example, background.
For some distance
d on the embedding space (typically Euclidean distance), the loss for a triplet
is defined as:
Our goal is to minimize this loss function, pushing to 0 and to be greater than . As soon as n becomes an “easy negative”, the loss becomes zero.
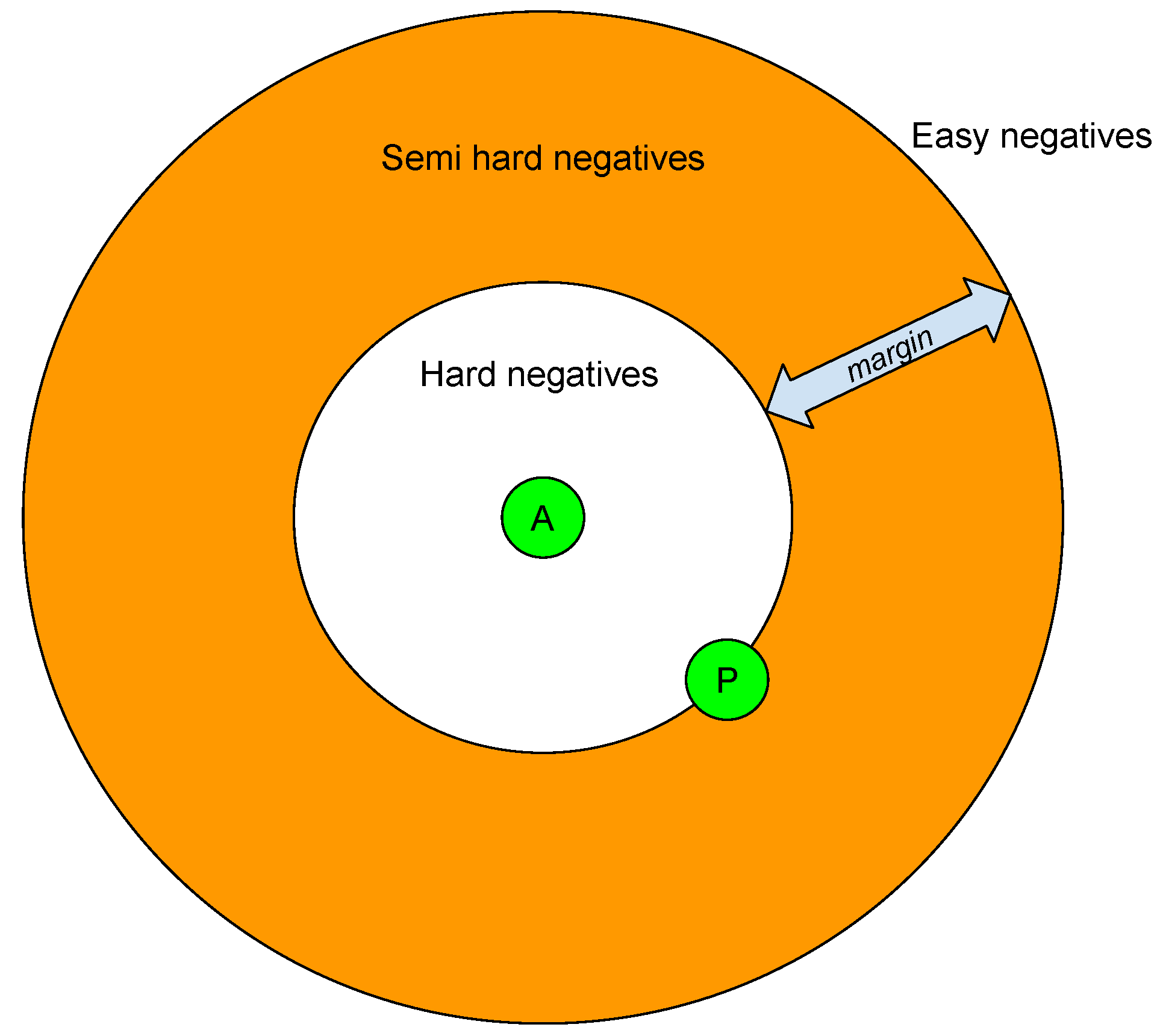
Based on the definition given in Equation (
1), there are three categories of triplets:
Easy triplets: Triplets which have a loss of 0, because ;
Hard triplets: Triplets where the negative is closer to the anchor than the positive, i.e., ;
Semi-hard triplets: Triplets in which the negative sample is not closer to the anchor than the positive sample, but still have positive loss: .
According to the previous definition, we can categorize the negative samples into hard negatives, semi-hard negatives, and easy negatives. This is related to the location of the negative sample in relation to the anchor and positive samples within the embedded space. It can be observed in
Figure 3.
The strategy for triplet selection is a crucial step for achieving good detection performance, as stated in the literature [
65,
72]. It is necessary to select which triplets the network will process, because if all possible triplets were generated, many of them would be “easy” triplets, and would not contribute to the training. This would result in slower convergence, as all the triplets require computation through the network. Therefore, it is crucial to select active triplets, i.e., hard and semi-hard triplets, that can contribute to improving the model during training [
3]. In our case, we followed the strategy used in [
3], using online negative exemplar mining, that ensures increasing difficulty of triplets as the network training progresses. For this purpose, we generated the triplets online, selecting the hard positive/negative exemplars from within a mini-batch. It is also important to avoid the problem of unstable training. For this purpose, a meaningful representation of the anchor-positive distances needs to be guaranteed. It is necessary to ensure that a minimal number of exemplars of each class is present in each mini-batch. We adapted the procedure used in [
3] to our particular case. We ensured that for each image, during training, there is at least one pedestrian that generates a few positive samples, after the ROI pooling stage, that are used for generating the triplets.
3.3. Modified Classification Head with Embeddings
The proposed method focuses on the classification head that occurs immediately after the pooling feature extraction stage, with the features calculated from the regions generated by the RPN. As stated previously, current two-stage object detectors are designed for multi-task learning, performing classification and bounding box regression simultaneously. We modified the current final classification head, adding a third loss function, so that the distances among the embeddings are optimized according to the triplet loss function defined previously.
The behavior of a regular two-stage object detector can be summarized as follows: First, an image is taken, which generates multiple regions of interest (ROIs) that are fed into a fully convolutional network. Then, each region is pooled into a fixed-size feature map and projected onto a feature vector by a fully connected network. These vectors enter a network with two sibling output layers, on which the first delivers a discrete probability distribution
for each ROI over the
categories, and the other provides regression offsets
for bounding boxes for each of the
K classes. Each ROI is labeled with a ground truth
u and an annotated bounding box
v. For training, a multi-task loss function was used, given by the following equation:
with the classification function
defined as the log loss for true class
u, while the regression function
is usually the Smooth
function, this function being a robust
loss that is less sensitive to outliers than the
loss. The weight for balancing both functions is represented by
. It can be observed from the above equation, that there is no notion of a ground-truth bounding box for background ROIs, so
is neglected [
1].
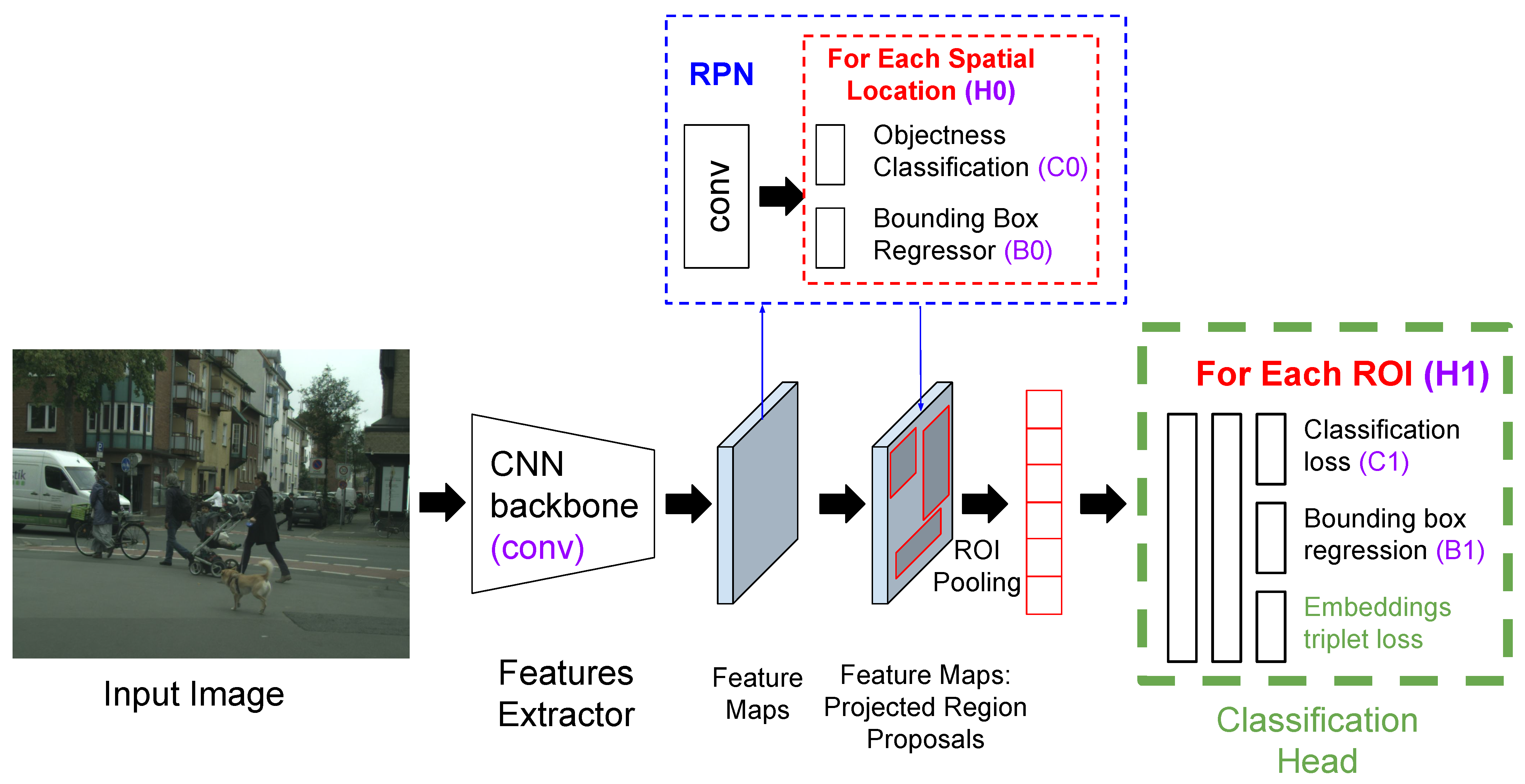
In our work, the samples are the ROIs projected onto the embedded space, generated by the ROI extractor. They can therefore be compared since the vectors have the same length. The proposed architecture, but in a Faster R-CNN framework, can be observed in
Figure 4. We applied the triplet loss function using these features to emulate somewhat the behavior of an embedded space in, for example, a face recognition task, where faces of the same subject must be closer, concentrated in space, and farther away from other subject faces. In this case, we want the features for the pedestrians to lie closer than the features for the background.
The loss function for the new classification head is defined as follows:
In the above equation, represents the classification loss function, and represents the regression loss function. Finally, represents the function applied to the embeddings; in this case, the Triplet Loss, which operates on the extracted features f after the region of interest extraction. On the other hand, represents the weight assigned to the regression function, and represents the weight assigned to the function applied to the embeddings.
For Faster R-CNN, the head was modified by adding triplet loss directly as a third loss function, complementing the classification and bounding box regression losses. For Cascade R-CNN, as observed at the right in
Figure 1, we can use this new modified head to replace any of the existing three heads, H1, H2, or H3. Several experiments were performed to find the optimal location of this new head in the Cascade R-CNN approach. In all the experiments performed, the margin used was 1.0, as a default value, and it performed well. We used this value because it was used in several deep learning frameworks [
87,
88].
3.4. Experiments
For training, we used the same progressive pipeline protocol described in [
20], which allowed us to have an advantage in enhancing pedestrian detection performance over datasets obtained from multiple sources. This pipeline trains detectors using a dataset that is diverse, but different from that of the target domain. Subsequently, the pipeline fine tunes the detectors on a dataset that closely resembles the target domain. As expected, we used only the training subset of each dataset for training and the evaluation subset for the performance assessment.
We used CityPersons for training Faster R-CNN and Cascade R-CNN with triplet loss, in the same domain experiments as follows: We used the training partition available in the CityPersons dataset for training. For the cross-dataset experiments, we used the validation partition of CityPersons for evaluation; we did not use the training partition. We used the validation partition instead of the testing partition, because the latter is intended as a challenge dataset, with no available annotations, compared to the validation partition, which does have annotations available. This is the standard procedure used in the literature [
13,
14,
20,
89]. About the data augmentation, we used only vertical flipping. In future work, we can apply other data augmentation operations, aimed at improving the generalization capabilities of our method.
We performed experiments on different detectors comparing their performance. As detectors, we used Faster R-CNN [
2] and Cascade R-CNN [
32]. The backbone used was HRNet [
90], because in the SOTA this backbone has shown performance advantages over other backbones, such as ResNet50 or ResNeXt [
20].
For assessing the detector performance, we used the standard protocol available whose use has been reported extensively in the literature [
49,
52,
91]. The
metric, also called
, is defined as the log average miss rate over the False Positive Per Image (FPPI), computed by averaging the miss rate, at nine FPPI rates evenly spaced in log-space, in the interval
. This metric was chosen because it allowed us to compare the results obtained by our method with the current SOTA. It must also be mentioned that this metric was used in the articles that introduced the most used datasets in the field, Caltech [
91] and CityPersons [
49]. It was presented as an evaluation metric for pedestrian detection by Dollar et al. [
91], in which the Caltech dataset was introduced. This metric serves as a suitable indicator for algorithms applied in real-world applications. As this metric quantifies the error, a lower value represents a better performance for the assessed algorithm. This metric has been used extensively in recent years for the pedestrian detection problem, as stated in [
12,
13,
14,
20,
89,
92]. The methods were assessed at different pedestrian sizes and occlusion levels, as defined on
Table 1.
3.5. Datasets
The datasets used in our work are the following:
CityPersons [
49]: This dataset is a subset of the Cityscapes dataset [
93], but with only person annotations. The images were captured in different cities of Germany, and in adjacent countries. There are 2975 images for training, 500 for validation, and 1575 for testing. There is a 6.47 average number of pedestrians per image. Annotations are provided for a person’s visible region and full body. To be able to compare our results to those of the SOTA, we used only the train and validation subsets in this work.
EuroCity Persons [
52]: This is a large-scale dataset recorded in 31 European cities, with a variety of different scenarios. According to the time of recording, EuroCity Persons provides two subsets: daytime and nighttime. There are 21,975 images for training, with an average of 9.2 pedestrians per image. To be able to compare our results to those of SOTA we used only the daytime training subset.
WiderPedestrian [
85]: This dataset addresses the problem of pedestrian detection in unconstrained environments. The images were acquired in autonomous driving and surveillance applications. The dataset contains 90,000 images for training, with an average of 3.2 pedestrians per image. We also used only the training subset in this case to be able to compare it to other SOTA results.
Examples of the datasets employed in this work are shown in
Figure 5.
We focused our work on obtaining the best pedestrian detection results on the validation partition of the CityPersons dataset, and compared them to those of the SOTA.
All the experiments were conducted using the MMDetection [
94] open source object detection toolbox, which is based on PyTorch, as a part of the OpenMMLab project. The GPU used for the experiment was an NVIDIA GeForce 2080TI with 11GB of RAM. Similarly, as in other SOTA work, we used only vertical flipping for data augmentation [
20]. The optimizer used was SGD, with learning rate = 0.002, momentum = 0.9, and weight decay = 0.0001.
4. Results and Discussion
In this section, we performed several experiments applying our newly developed Classification Head with Triplet Loss to Faster R-CNN and Cascade R-CNN detectors. Then, we performed an ablation study to assess the impact of our head compared to the regular detectors. Finally, we performed a comparison study with the SOTA, and reviewed some qualitative results, comparing our method with a SOTA method.
4.1. Faster R-CNN with Triplet Loss Head Results
The first set of experiments was performed using our new proposed head, with the triplet loss function, replacing the standard classification head of a Faster R-CNN object detector with an ImageNet pre-trained HRNet backbone. The results obtained are shown in
Table 2.
We can see in
Table 2 that a small contribution from the triplet loss function to the classification head obtains the best results. Conversely, increasing the weight for triplet loss leads to a significant decrease in performance.
Cross-dataset generalization experiments were then performed. We trained a Faster R-CNN detector using WiderPedestrian, and evaluated it on CityPersons, as can be seen in
Table 3. From the results shown in
Table 2, we can observe that using weights in the interval
resulted in the lowest error. Therefore, we performed cross-dataset generalization experiments, focusing only on low values, in the range
, for the triplet loss weight.
The results shown in
Table 3, are worse than those shown in
Table 2 because the source dataset in
Table 3 is different from the target dataset. This effect is amplified on the heavy subset, the most difficult one on the benchmark. However, in
Table 2, the source and target datasets are the same. If we observe the results in
Table 3, the performance using triplet loss is the best, in general terms for all the subsets, when the weight is 0.2. Nevertheless, in the following experiments, the results improved significantly when the model was fine-tuned using the triplet loss on datasets that are closer to the target domain, in this case, EuroCity Persons.
4.2. Cascade R-CNN with Triplet Loss Head Results
The next step was to perform the experiments using the Cascade R-CNN framework. There are multiple classification heads in this detector, and, therefore, we had to choose the place to apply the triplet loss function. For this purpose, we performed several experiments, modifying the head where triplet loss is applied, and the weight for the triplet loss function within the selected head. A summary of the experiments performed is shown in
Table 4, where, in general terms, applying triplet loss in the first classification head seems to perform better, since it performs well on the reasonable, small, and heavy subsets at the same time. The detection performance increased compared to the results obtained using Faster R-CNN as shown in
Table 2. In this case, the best result for the reasonable subset was obtained using a small weight of 0.05 for the triplet loss function in the first classification head.
Proceeding in a similar fashion to Faster R-CNN, we performed cross-dataset experiments for Cascade R-CNN. In this case, we trained our models on WiderPedestrian, and then evaluated them on CityPersons. Since the results seemed to be better rounded for all the datasets in which we applied our head in the first head, we chose this head for the following experiments. We also focused on small values for the weight, because, as stated previously, it seems that only a small weight has the most positive impact on the detector. Results for this set of experiments can be observed on
Table 5.
The same effect that occurred with Faster R-CNN can be seen here, where the results shown in
Table 5 are worse than those shown in
Table 4. This is also because the source dataset on
Table 5 is different from the target dataset. Again, this effect is most noticeable in the heavy subset. The best global result for Cascade R-CNN was obtained by applying triplet loss with a weight of 0.15 to the first classification head, H1. This weight worked well in all the subsets on CityPersons.
4.3. Ablation Study
In this section, we compare the best results for cases of Faster R-CNN and Cascade R-CNN with Triplet Loss, with our new head, and without it.
In
Table 6, results for Faster R-CNN and Cascade R-CNN detectors, trained and evaluated on CityPersons, when using our modified head vs. the regular detector are shown.
We can observe in
Table 6, that for both Faster R-CNN and Cascade R-CNN, a small contribution from the triplet loss function to the classification head improves the performance on almost all the subsets in CityPersons. For the Faster R-CNN method, results in the reasonable subset improved moderately, but the improvement was significant on the heavy subset. For Cascade R-CNN, results on the reasonable subset improved significantly, and moderately on heavy and small subsets.
Then, in
Table 7, results are shown for Faster R-CNN and Cascade R-CNN detectors, trained on WiderPedestrian and evaluated on CityPersons, when using our modified head vs. the regular detector.
We can see in
Table 7 that using triplet loss again improved the results compared to the results obtained without it. This behavior can be seen for both Faster R-CNN and Cascade R-CNN. The improvement in the performance is especially evident for the Cascade R-CNN, where the error for the reasonable subset decreased by 2.2%, 3.5% for the small subset, and an impressive 6.5% for the heavy subset. This shows the impact of the triplet loss head on a cross-dataset scenario for the most difficult samples in the dataset, that belong in the heavy subset.
4.4. Comparison Study
SOTA results, for the CityPersons benchmark, can be observed in
Table 8. All these results were obtained using the target dataset for training and testing, and therefore, no generalization capabilities were tested.
It can be seen that when comparing the best Faster R-CNN results on
Table 8 (15.4% on the reasonable subset), with the best result on
Table 2 (13.7% on the reasonable subset), we observe a significant reduction in
of about 1.7% for the reasonable subset. Also, the results on the small subset improved by 7.3%, from 25.6% when using Faster R-CNN with a VGG16 backbone and without triplet loss, to 18.3% using triplet loss and an HRNet backbone. This is a combined effect of the triplet loss function, and the HRNet backbone, because in [
49], an older VGG16 [
95] backbone was used.
A comparison including the best results of our method, using Faster R-CNN and Cascade R-CNN detectors, can be seen in
Table 9, compared to those of the SOTA for domain generalization using WiderPedestrian, taken from Hasan et al. [
20]. It can be observed in the third row of
Table 9, that the Faster R-CNN method with triplet loss outperforms the Cascade R-CNN algorithm without triplet loss shown in the first row, the latter being a modern method that on most object detection tasks outperforms Faster R-CNN [
20,
32]. The fourth row of
Table 9 shows the results of our method using Cascade R-CNN. It can be observed that our results outperform those of the regular Cascade R-CNN shown on the first row, obtaining an improvement for the reasonable subset by 2.2%, and 6.5% on the heavy subset.
Finally, we performed a set of experiments to assess the generalization capabilities of our method, applying Hasan’s progressive training pipeline [
20], and always using the CityPersons benchmark as a target set to be able to compare our results to those of the SOTA. The best results obtained for this set of experiments are shown in
Table 10. We followed the same sequence of cascade training as in the SOTA to be able to compare our results to those already published. We performed the first training on the WiderPedestrian dataset, and then, with the best result obtained (last row of
Table 9), we fine-tuned using the EuroCity Persons daytime subset. We obtained the best result with a weight of 0.1 for the first classification head (H1) in the Cascade R-CNN detector. In summary, we trained a detector on WiderPedestrian, using a weight of 0.15 on H1, and then, fine-tuned it on EuroCity Persons, using a weight of 0.1 on the H1 head. As shown in
Table 10, our results outperform the current SOTA on two of the three subsets of CityPersons, i.e., the small and heavy subsets, and obtained a comparable performance on the reasonable subset. The difference in performance is about 1.5% better for the heavy subset, which has been shown to be the most difficult subset in CityPersons in the literature [
13,
20,
47,
48]. We hypothesize that the results in the target subset will improve with our method when using additional datasets in the training pipeline, since the base performance is greater.
4.5. Qualitative Results Comparison and Discussion
In the following examples, qualitative results of our model on the CityPersons dataset can be observed and compared to those of CSP [
13], where the images on the left, (a), show the results of our method, while the images on the right, (b), show the results of CSP. False negatives are shown in white, false positives in red, and true positives in green. In
Figure 6a,
Figure 7a, and
Figure 8a, some false negatives are shown when observing the results obtained by our method, but under careful observation, it can be seen that most of the missed detections occur in areas where occlusion is generated by another pedestrian. In cases of other occlusion types, e.g., generated by cars or other objects, the method performed well, even with pedestrians of low visibility and short stature. Specifically, in
Figure 6 and
Figure 7, a significant difference in performance can be observed between both methods, with our method able to detect more of the most difficult pedestrians when compared to CSP, especially those who are short and occluded. In
Figure 8a, our method shows better results when applied to occluded pedestrians. In general terms, our method shows some errors that are mainly caused by occlusions made by other pedestrians, and it shows that it handles occlusions better than CSP in
Figure 8b. Performing a qualitative analysis of the whole testing set, this seems to be the main cause of our method missing occluded pedestrians. It must be noted that riders (cyclists and motorists) are intentionally not detected, since they belong to another class in the Cityscapes dataset. In
Figure 7a, a false positive can also be noted in red, but when observed carefully, it seems to be a highly occluded pedestrian that is not annotated in that location.
Figure 9a shows instances of many false positives, and also one false negative, that seems to be caused by another pedestrian, as in
Figure 6a,
Figure 7a, and
Figure 8a. Observing carefully, it can be seen that all the red bounding boxes are effectively pedestrians, some of which are highly occluded, but they are counted as false positives according to the evaluation procedure in the literature. Comparing our results to those of CSP,
Figure 9b shows only one of these misses labeled false positives, resulting in worse performance (also not detecting a short pedestrian in the middle of the scene). Finally, in
Figure 10a, a single detection can be observed, in red, that is also a highly occluded pedestrian. This pedestrian is not detected by CSP, as can be seen in
Figure 10b.
From the qualitative results obtained, it can be observed that the proposed method works well on difficult images, handling occlusions and scales better than CSP [
13], and even detecting some difficult pedestrians, i.e., those that in the evaluation are marked as false positives (red bounding boxes), but are effectively pedestrians, some of whom are highly occluded. Our method is able to manage pedestrians in different scales, with different illumination and occlusion degrees, and even avoid detecting bicycle riders, who are visually highly similar to pedestrians, creating an additional degree of difficulty. These results could be explained by the triplet loss design that tries to explicitly cluster all types of pedestrians together, independent of their degrees of occlusion or size. Therefore, the network learns that different degrees of occlusion and scale must be close in the feature space. Several examples of good detections of highly occluded pedestrians are shown in
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10. One limitation that can be observed occurs when occlusions are generated by other pedestrians, instead of by fixed objects in the scene, for example, cars or trees. Future research could be focused on how to handle this type of occlusion.
The results obtained also showed that our method can generalize well from datasets with different scenarios. The dataset on which our method is evaluated, CityPersons, has images captured in different cities in Germany and its neighboring countries, during three seasons and under various weather conditions. On the other hand, training data comes from WiderPedestrian and EuroCity Persons, with WiderPedestrian being composed of surveillance and car-driving images, with very different camera angles, object scale, and illumination, and even some images captured at night. EuroCity Persons was captured in 31 cities of 12 European countries, spanning a large geographical area, during four seasons, which implies a variety of clothing styles, i.e., light/short for summer and thick/long for winter, and weather conditions being dry or wet. Having all these different conditions in the training set, and the triplet loss capability to cluster together samples of the same class, in this case, pedestrians, allows our detector to generalize well, because it can project samples closer together in the feature space, even if they are captured under different conditions, for example, in winter and summer, with rain, snow, different degrees of occlusion, etc. Even if there are fewer samples from one scenario to another, they are forced to lie together in the feature space.
The computational cost, in terms of the execution time of adding the triplet loss function to the existing classification and regression losses, is small according to our measurements. During training, the computational time increases by about 1%, with an average iteration time of 0.6853 s with the triplet loss, compared to 0.6799 s without it, while employing an NVIDIA GeForce 1080TI GPU. This could be explained by the fact that all computations performed for the new loss, require a distance computation within a mini-batch that uses up most of the time. During inference, the computational time is the same for the cases with and without triplet loss, because this loss is only used during training time. Therefore, the triplet loss does not have a negative impact while using the model for pedestrian detection, once the network is trained.
5. Conclusions
Pedestrian detection is one of the key tasks in computer vision for which several models have been developed in the past few years and that have shown a steady improvement over time, especially with deep-learning-based methods. Many real-world applications require high performance in pedestrian detection, such as the following: autonomous driving, robotic navigation, video surveillance, action recognition, and tracking. In this work, we developed a new pedestrian detection method using a new classification head for two-stage detectors. This method is aimed at improving the domain generalization capabilities of existing object detectors applied to pedestrians. We added a third loss function, based on the triplet loss function, to the classification and bounding box regression losses, and applied it to the embeddings generated to the regions of interest by the RPN network. This method improves the feature compactness of pedestrian samples, and therefore, features are clustered together in the feature space. We obtained SOTA results on the CityPersons benchmark, but it was done without training the method explicitly within the target dataset. We used progressive pipeline training, first using WiderPedestrian, and then fine-tuning on EuroCity Persons, achieving a major improvement on the heavy partition, which, with the current SOTA results, is the most difficult partition for the CityPersons benchmark. We obtained an of 9.9 for the reasonable, 11.0 for the small, and 36.2 for the heavy subsets, which surpasses the current SOTA results for the small and heavy subsets, and is highly competitive for the reasonable subset. These results showed that our method is able to generalize well in different cities and weather conditions, because of how the CityPersons dataset is composed. Also, our proposed head could be used as a new direction for improving cross-dataset performance in other pedestrian detectors with compatible architectures, or other object detection tasks, considering real-world applications such as autonomous driving and video surveillance. For future work, we think that our method would benefit from training with additional datasets in the progressive training pipeline, since the base performance of our method is significantly higher. Also, because all the images in CityPersons are captured under daylight conditions, in future work our method could be trained and tested using datasets that have nighttime images, for example, the nighttime partition of EuroCity Persons.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}