1. Introduction
With the continuous advancement of communication technologies and the rapid growth of global communication demands, the existing terrestrial network can provide high-speed and diversified services for densely populated areas, but it still has obvious shortcomings in dealing with long distances, a wide coverage, large capacity, and harsh terrain communication environment. At the same time, as an important supplement to the ground network, a satellite network has significant advantages in expanding the communication coverage, improving the communication capacity and reliability in hot spots, and realizing the space–air–ground–sea integrated network [
1,
2]. Among them, low-earth orbit (LEO) satellite communication systems have become a project pursued by many enterprises in the Internet, communication, aerospace, and other fields due to its advantages, including a low delay, low cost, high spectrum utilization, and low terminal power requirements [
3]. However, LEO satellites are characterized by their low cost, small size, and lightweight design, but they result in severely limited on-board power resources. LEO satellites orbit at low altitudes and move at high speeds, leading to constantly changing coverage areas and complex and dynamic electromagnetic environments. Furthermore, user terminals are unevenly distributed across different countries and regions within the coverage area, and there are varying demands for traditional voice and data services as well as emerging streaming media services. In summary, LEO satellites must address the dynamic changes in user terminal distribution and service demands. Hence, addressing the challenge of allocating resources effectively within the constraints of limited resources such as the satellite spectrum, ensuring equitable admission control for diverse services, and achieving efficient alignment between on-board resources and service demands has emerged as a pressing issue in the realm of satellite communication.
Multi-beam satellite communication technology is an effective approach to solve the above challenges. This technology achieves multiple frequency reuses and polarization reuse through spatial isolation, which can increase satellite communication capacity exponentially. At the same time, the dynamically adjusted beam direction can help the satellite system allocate resources more effectively and further meet the needs of the variability in coverage area and the diversity of communication requirements [
4]. However, the flexibility of multi-beam satellite communication systems also increases the complexity of resource allocation. There are usually different communication requirements in the coverage area of each beam, which requires the satellite communication system to be able to sense the differences between beams and dynamically adjust the resource allocation scheme to ensure that the services within each beam are properly served [
5]. For these reasons, the academic community has proposed some solutions from the perspectives of beamforming schemes and on-board resource joint allocation.
Lin et al. [
6,
7] proposed a beamforming scheme for a multi-beam satellite communication system from the perspective of security and energy saving, thereby improving the secrecy energy efficiency (SEE) of communication networks. Lin et al. [
8] adopted the alternating optimization scheme and the Taylor expansion penalty function to optimize the beamforming weight vector and phase shift, aiming to minimize the total transmission power of the satellite and the base station, while meeting the user rate requirements. Deng et al. [
9] proposed an adaptive packet splitting scheme based on a discrete firefly algorithm for cross-layer and cross-dimension radio resources optimization and an irregular gradient algorithm to ensure communication efficiency and reliability. Zhang et al. [
10] proposed an uplink cooperative user scheduling and power allocation method based on game theory in an uplink multi-beam satellite Internet of Things (S-IoT). Takahashi et al. [
11] constructed a power resource allocation model to jointly control the transmit power and multi-beam directivity according to the traffic demand, so as to improve the efficiency of communication resource allocation. Jia et al. [
12] considered the inter-beam interference, channel conditions, delay, capacity, bandwidth utilization variance, and other factors, and a joint resource allocation algorithm is proposed, which can flexibly allocate resources according to specific service requirements and channel conditions. Wang et al. [
13] proposed a resource management scheme to maximize resource utilization and user service weight, and introduced an improved cuckoo optimization algorithm to ensure the quality of service (QoS) for high-priority users. In addition, Cai et al. [
14] proposed a cognitive S-IoT system supporting code division multiple access (CDMA), which can jointly optimize the transmission power of the traditional satellite system and the IoT by maximizing the total rate of the IoT users under the premise of ensuring the performance requirements of the traditional satellite system.
The emergence of the above research results brings new ideas and methods for the resource allocation of multi-beam LEO satellite communication. However, when dealing with the diverse and time-varying communication requirements in the network, these methods are difficult for meeting the needs of rapid and dynamic resource allocation due to high algorithm complexity and long calculation times. Machine learning (ML) [
15] has super strong learning and inference capabilities, and has been shown as a good application prospect in network resource allocation [
16,
17,
18,
19]. In particular, the introduction of deep reinforcement learning (DRL) provides a more intelligent, flexible, and efficient solution for the resource allocation of multi-beam LEO satellite communication.
Liao et al. [
20] designed a cooperative multi-agent deep reinforcement learning (CMDRL) framework to solve the bandwidth allocation problem of multi-beam satellite communication systems. Chan et al. [
21] proposed an efficient power and bandwidth allocation method, which uses two linear ML algorithms and takes channel conditions and traffic demand as inputs to achieve the optimal resource allocation under dynamic channel conditions. Hu et al. [
22] considered inter-beam interference and resource utilization difference, and a game theory based on bandwidth allocation model for forward links was established. Furthermore, considering that the addition of satellite beams results in a larger action space for individual agents in DRL, thereby increasing time complexity, this paper proposed a multi-agent cooperative deep reinforcement learning approach to achieve optimal bandwidth allocation. He et al. [
23] proposed a multi-objective deep-reinforcement-learning-based time-frequency (MODRL-TF) two-dimensional resource allocation algorithm to achieve the joint optimization goal of maximizing the number of users and system throughput for the joint allocation problem of multi-dimensional resources such as QoS, time, and frequency in multi-beam satellite communication. Huang et al. [
24] proposed a learning-based hybrid-action deep Q-network (HADQN) algorithm to solve the sequential decision optimization problem in dynamic resource allocation in multi-beam satellite systems. By using a parameterized hybrid action space, HADQN can schedule the beam pattern and allocate the transmitter power more flexibly, which greatly reduces the on-orbit energy consumption without affecting the QoS.
By introducing DRL, the above research provided a forward-looking solution for solving resource allocation in multi-beam LEO satellite networks. However, current research still has some shortcomings, with the main deficiency being the lack of consideration for fair user service admission in the optimal allocation of resources. In the multi-beam LEO satellite communication system, the coverage area of the satellite is constantly changing, and the needs of users in the area are diverse.
If fairness is not considered in resource allocation, this will result in some users being overlooked or frequently denied access, while others consistently occupy more resources. Over time, this leads to a significant decline in user experience, causing dissatisfaction with the services provided by the satellite. However, in the existing research, traditional algorithms exhibit limited flexibility and adaptability when confronted with the complexities of the satellite communication environment. Moreover, accurately extracting the key information required for fair admission control strategies from a vast array of service demand characteristics often proves challenging. Additionally, a comprehensive and effective hierarchical admission control strategy capable of achieving the cooperative optimization of resource allocation rationality and admission control fairness has yet to be established. Hence, we propose an intelligent hierarchical admission control (IHAC) strategy based on DRL. This approach incorporates the user service model, the dynamic priority model, and carefully designed controller feature inputs, along with a reward and punishment mechanism. Through the utilization of DRL, IHAC aims to efficiently allocate multi-beam resources and exercise control over user service access within the coverage area, simultaneously addressing both objectives.
The contributions of this paper are as follows:
In this paper, the DLR method is employed to effectively manage the multi-beam satellite communication system. By combining deep deterministic policy gradient (DDPG) and deep Q-network (DQN) algorithms, a hierarchical admission control strategy is constructed, encompassing both upper- and lower-level controllers. The upper-level controller employs DDPG to comprehensively consider the service demands of various ground zones and formulate resource scheduling strategies from a global perspective. This ensures optimized resource utilization while ensuring the coordinated allocation of beam resources among different ground zones. The lower-level controller employs DQN to receive decisions from the upper-level controller and refines the global strategy into localized admission control strategies for each ground zone’s services.
This paper develops user service models and dynamic priority models for services. The user service model enables controllers to have a deeper understanding of different types of service characteristics, leading to more precise decision-making. By introducing the adaptive dynamic priority model, controllers can achieve efficient resource utilization while considering the fairness of competitive services, leading to a more balanced resource allocation. Furthermore, careful design is applied to the feature inputs, reward functions, and penalty terms of both upper- and lower-level controllers, facilitating a more comprehensive and detailed understanding of service demands. This guides controller decisions towards optimizing both efficient resource utilization and overall fairness of the communication system.
In simulation experiments, the proposed strategy is compared with DAQC [
25] and WOA [
26]. The results demonstrate that the proposed strategy performs well in terms of the channel access service quantity, successful service admission rate, service drop rate, and resource allocation fairness. This highlights the effectiveness of the proposed strategy.
The remainder of this paper is organized as follows.
Section 1 describes the related works on resource allocation and admission control for multi-beam satellites and the motivation of this paper.
Section 2 describes the system model of the resource allocation and admission control strategy in this paper.
Section 3 outlines the hierarchical admission control framework based on DRL.
Section 4 provides a detailed explanation of the hierarchical admission control strategy.
Section 5 presents the evaluation results of the experiments.
Section 6 summarizes the entire paper and elaborates on the contributions of this work.
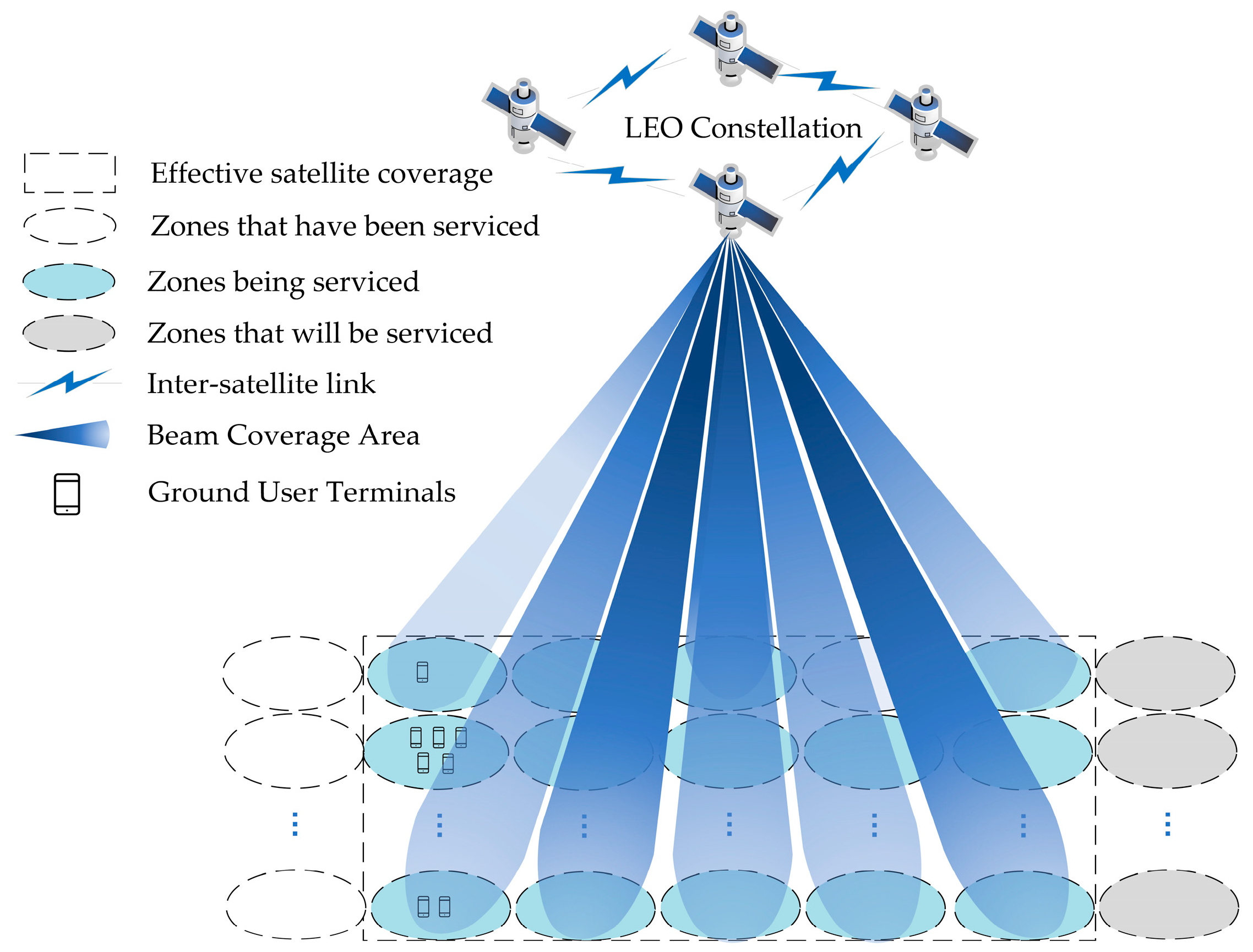
4. Strategy of Intelligent Hierarchical Admission Control Based on DRL
4.1. Hierarchical Controller Structure
We delve into the exploration of DDPG and DQN, evolved from the traditional Q-learning algorithm, and their collaborative implementation in the hierarchical admission control framework. However, these methods also inherit issues such as instability, overestimation, and convergence challenges that have been associated with traditional Q-learning, especially when utilizing neural networks to estimate Q-values.
In conventional Q-learning, a common practice involves using a single online network to estimate Q-values for each state-action pair, and decisions are made based on the action with the highest Q-value. Nevertheless, this approach can lead to unstable Q-value estimations, particularly during the initial stages of training. This instability arises from the chain reaction triggered by the parameter updates in the neural network, resulting in fluctuations in Q-values. Furthermore, as traditional Q-learning employs a greedy strategy to select actions with the highest Q-values, it can lead to the overestimation of Q-values, subsequently affecting the accuracy of the policy.
To overcome these challenges, we introduce the concepts of a target network and experience replay mechanism in DRL. Specifically, the target network shares the same structure as the online network but employs a different parameter update strategy. The target network’s parameters are copied from the online network at regular intervals or through a soft update approach. This separation of neural networks ensures that the calculation of the target network Q-values is unaffected by the direct influence of the online network, reducing the immediate impact of the online network’s instability and mitigating the chain reaction caused by parameter updates.
Furthermore, in interactive environments, the acquired data are often highly correlated, with potential correlations between consecutive data points. This correlation can lead to the neural network being influenced by related data during the training process, thereby causing instability. The experience replay mechanism, by randomly sampling from an experience buffer, breaks down data correlation, enhancing data utilization efficiency. The deployment of neural networks is as follows.
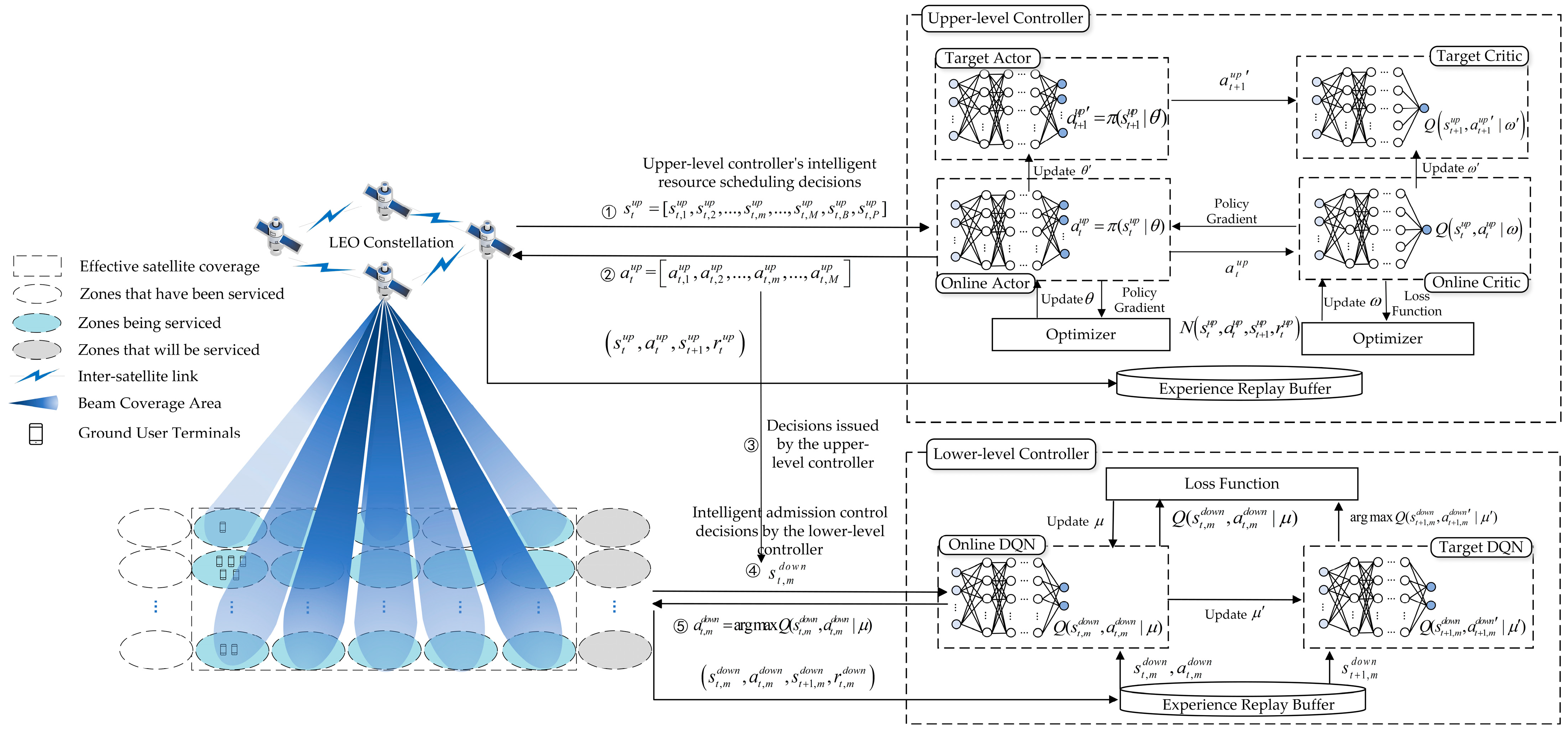
4.1.1. DDPG in the Upper-Level Controller
Online Actor Network: , where represents the neural network parameters. Responsible for generating the scheduling strategy for various ground zones’ beam resources based on the ground zone and satellite resource state features .
Online Critic Network: , where represents the neural network parameters. Primarily evaluates the quality of actions made by the online actor network based on , guiding the optimization of the action network’s decision-making capability.
Target Actor Network and Target Critic Network: and , where and are the parameters of these two neural networks, and is the action computed by the target action network based on , but not executed during the interaction process.
4.1.2. DQN in the Lower-Level Controller
Online DQN: , where represents the neural network parameters. In the distributed scenario of ground zone user service admission control, each ground zone possesses an independent online DQN, sequentially making admission control decisions for the user service within its zone.
4.2. DRL Training
While interacting with the environment, the upper- and lower-level controllers accumulate a variety of state-action pairs’ experience samples and by trying different actions. These experience samples encompass the behavior and outcomes of the satellite communication system under various states. They are stored in an experience replay pool for neural network training. By obtaining and through random sampling, the correlation between samples is broken, thereby enhancing training stability and the system’s understanding and adaptability to different situations.
4.2.1. Training of the Upper-Level Controller DDPG
During the training phase of DDPG, the online actor network utilizes the experience samples
from the replay pool to update its weights based on Equation (15):
The online actor network relies on the backpropagation of the policy gradient
for updates. Additionally, the online critic network can be trained by minimizing the loss function, as expressed below:
where
is referred to as the target Q-value, which can be expressed in a sample
as follows:
The target Q-value is obtained by taking a weighted sum of the current reward
and
, where
is considered the discount factor, and
is computed by the target action network, expressed as follows:
Finally, we adopted a soft update approach for updating the parameters of both target networks, where in each update iteration, the parameters are updated by weighting them with the learning rate
, expressed as follows:
4.2.2. Training of the Lower-Level Controller DQN
Given that we have adopted a distributed ground zone approach with multiple intelligent agents and treated each ground zone as an individual agent, in this architecture, each ground zone needs to balance resource allocation and services admission decisions while collaborating and interacting with others. This involves finding a balance between cooperation and competition among multiple intelligent agents. Moreover, we recognize that the upper-level controller comprehensively considers the dynamic situations of each ground zone based on global information, thereby partially balancing the resource competition process among them and indirectly providing a global perspective for the lower-level controller. Therefore, we opt for a decentralized training approach for the deployment of lower-level controller agents. In this scheme, each ground zone’s agent is relatively independent in its training, making decisions based on local information. Here, we provide an overview of the training process for a single intelligent agent.
The lower-level controller primarily focuses on training the online DQN, and its principle is similar to training the online critic network in the upper-level controller. Similarly, based on the sample
, we train the online DQN by minimizing the loss function:
The parameter update of the target DQN still adopts the soft update method:
4.3. Intelligent Hierarchical Admission Control Strategy
Considering the characteristics of satellite high-speed movement and the real-time variability of users’ needs and demands, we have adopted a strategy of online decision-making and offline learning for the training and decision-making of intelligent agents. This strategy aims to ensure that the agents can make adaptive decisions in real-time environments and continuously enhance their decision-making capabilities through offline learning.
During the online decision-making phase, the intelligent agents interact with the environment through the upper and lower-level controllers, accumulating experiences. This real-time interaction process enables the agents to promptly perceive changes in the satellite movement, the distribution of user services, and the actual utilization of resources. In the offline learning phase, we utilize these accumulated experiences to optimize the agents’ decision-making capabilities. By deeply learning and analyzing the experiential data, the agents can acquire insights into more intricate patterns and trends. The detailed strategy process is illustrated in
Table 3.
Overall, the dual approach of online decision-making and offline learning allows the agents to balance the real-time responsiveness and learning capability. This strategy not only enables the agents to make timely decisions in dynamic environments but also continuously enhances their decision-making abilities through offline learning, thereby achieving a more intelligent and adaptive hierarchical admission control system.
5. Simulation Analysis
5.1. Simulation Parameter Settings
According to the relevant parameters of the Iridium constellation, a simulation environment is built by STK to obtain the satellite coverage time of each ground zone. Then, we establish a simulation system, and implement an intelligent hierarchical admission control strategy through MATLAB. Its simulation parameters are shown in
Table 4.
5.2. Simulation Result Analysis
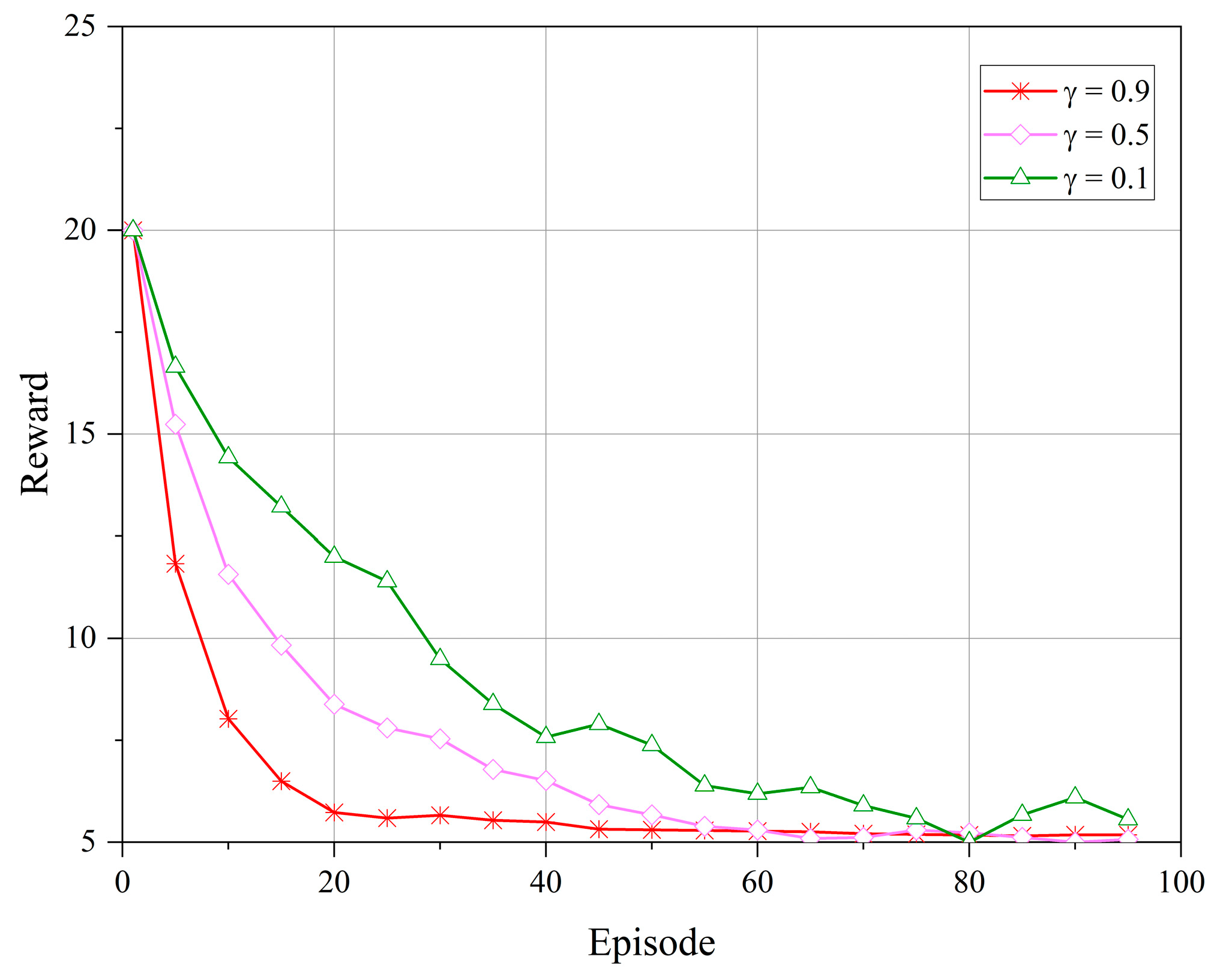
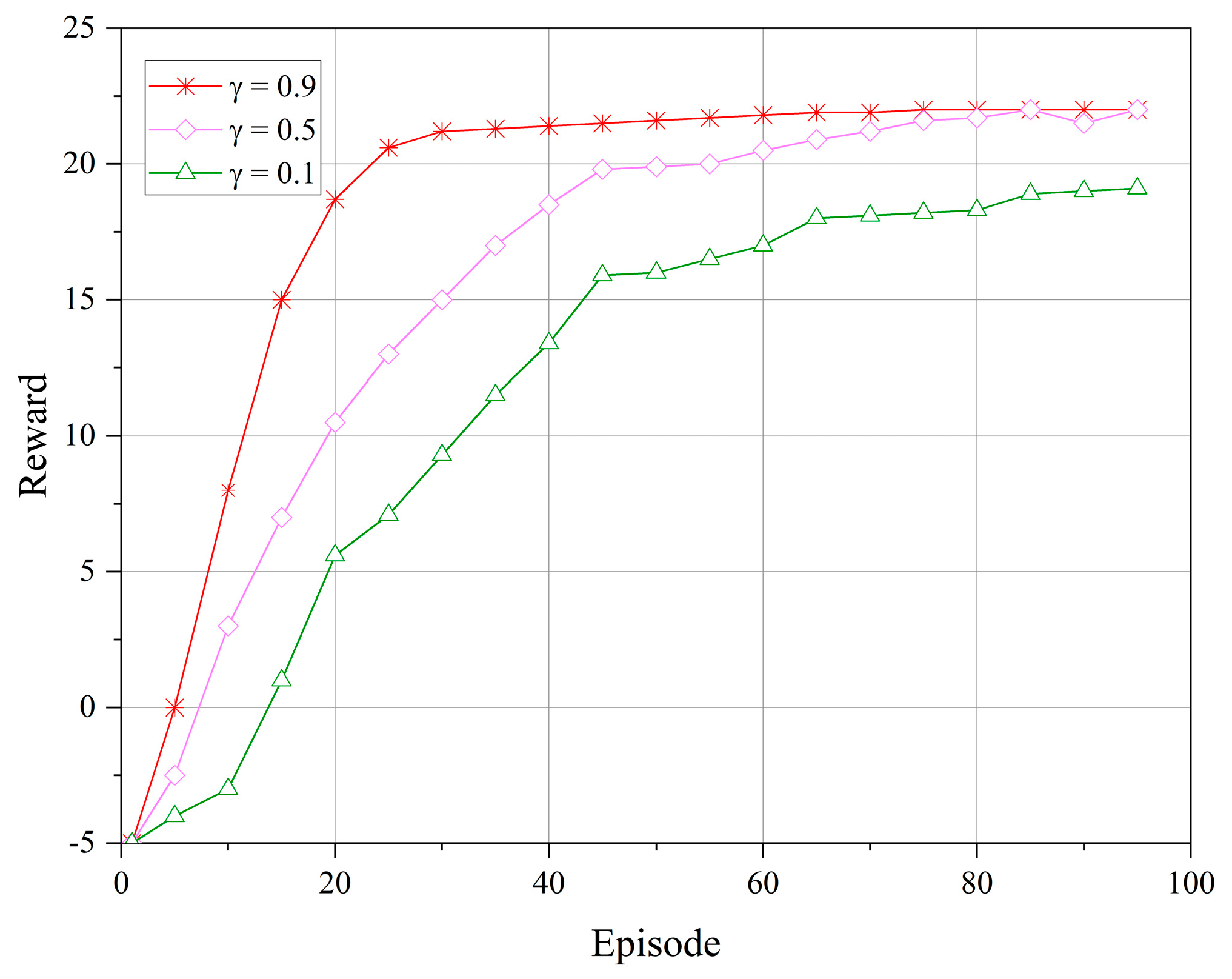
In the field of DRL, the convergence of algorithms is regarded as a key indicator for evaluating the performance and effectiveness of the algorithm. Especially when applied to LEO satellite communication systems, the convergence speed and stability of the reward function directly reflect the optimization level of the algorithm and its adaptability under different circumstances. Therefore, we observed the changes in the reward function during model training to obtain the optimal settings for model parameters. Furthermore, in simulation experiments, the proposed IHAC strategy is compared with DAQC and WOA in terms of channel user quantity, successful access probability, and drop call rate, demonstrating the applicability and superiority of the proposed strategy.
Figure 3 and
Figure 4 depict the reward performance of the upper- and lower-level controllers during the training process, where the
x-axis represents the number of training episodes and the
y-axis represents the reward value. In DRL algorithms, the objective is to learn to select the optimal policy to maximize the cumulative reward. The reward discount factor can be used to balance the immediate reward at the current time step and the future rewards, with a larger discount factor focusing more on future rewards, allowing the controller to consider the long-term impact of actions and promoting algorithm convergence. Therefore, in our experiments, we set the reward discount factors as
. From the figures, it can be observed that the reward values tend to stabilize during the algorithm iterations. However, when
, the reward function stabilizes more rapidly and remains stable without significant fluctuations over a longer period. This indicates that when
, the upper- and lower-level controllers exhibit a higher adaptability to different communication scenarios and service demands in the LEO satellite communication system.
In this paper, simulation verification is conducted using a time division approach, where a single resource allocation time window is divided into 10 units of simulated time.
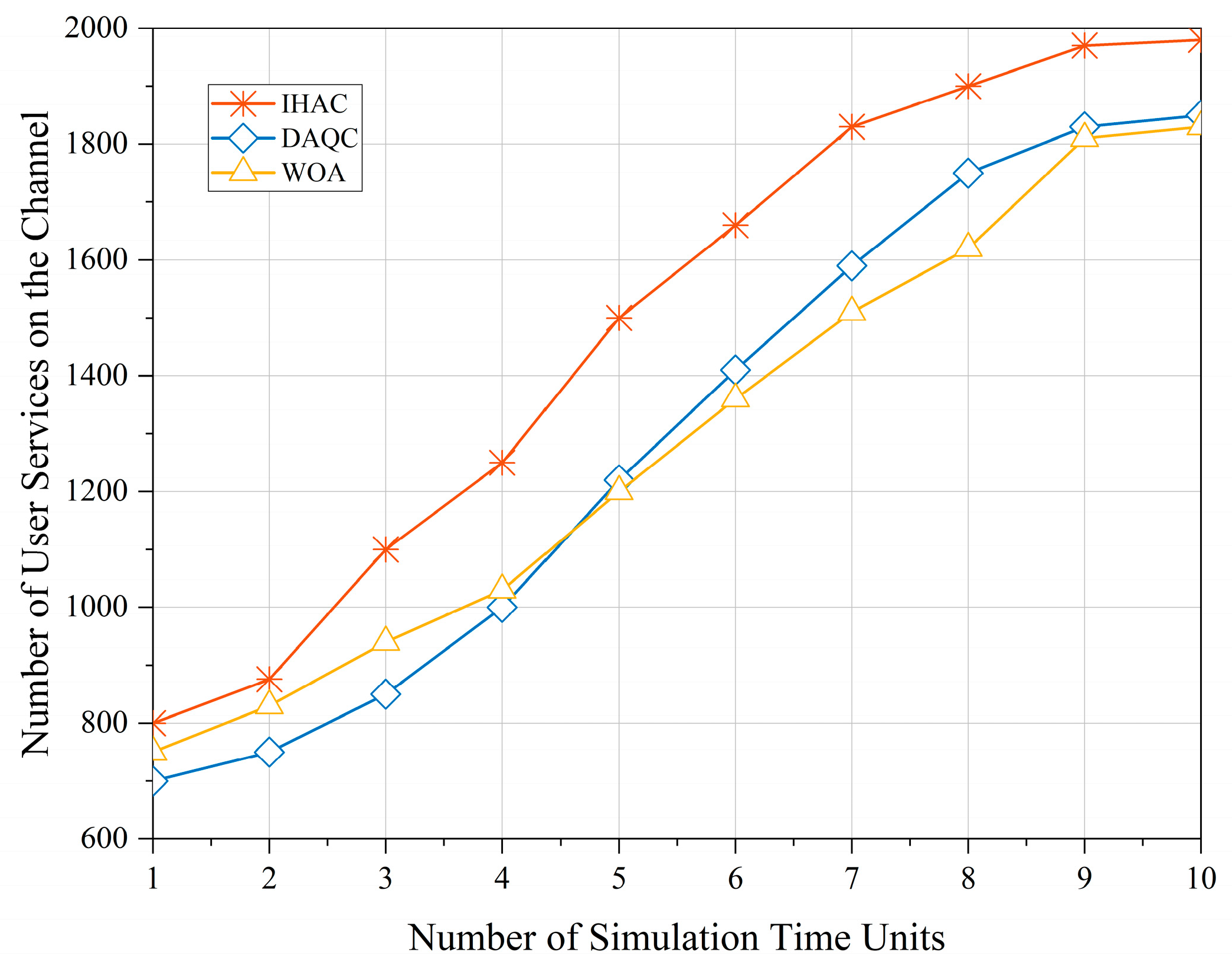
Figure 5 presents the changing trend of the number of user services on the channel as the simulation progresses. From the figure, it is evident that the intelligent hierarchical admission control strategy interacts continuously with beam resources and user service states. This interaction, constrained by the reward function, maximizes the utilization of beam resources. By continuously interacting with beam resources and user service states through hierarchical admission control, the maximum utilization of beam resources is achieved, thereby avoiding resource idleness.
The proposed strategy in this paper shows a significant improvement in channel utilization after sufficient training. It not only avoids resource wastage but also effectively meets the access demands of user services. Compared to DAQC and WOA, the proposed strategy achieves the highest received service count of 280 and 320, respectively, while the accepted service count is increased by 22.95% and 21.19%, respectively. The results highlight that the proposed intelligent strategy, after training, significantly enhances the utilization of channels, not only preventing resource wastage but also efficiently satisfying the access requirements of user services.
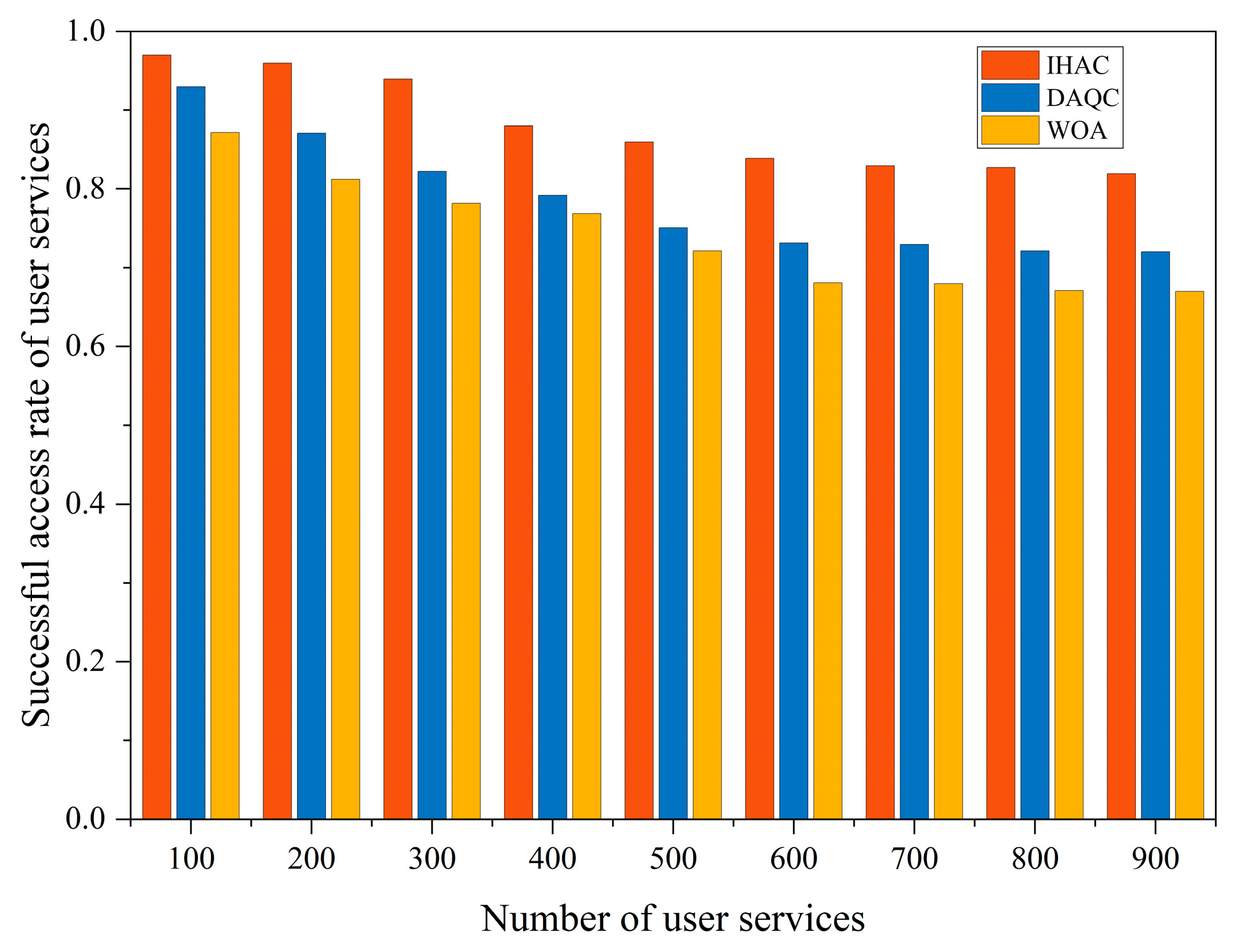
The rate of successful service access is a critical parameter that reflects user service satisfaction and is one of the core goals of satellite networks. A high rate of successful service access implies that services are more likely to be effectively provided. Especially in scenarios with numerous service demands, terminal users need to compete for limited beam resources. Therefore, the level of this indicator significantly impacts user experience. As shown in
Figure 6, as the number of services increases, the rate of successful service access gradually decreases. This is due to network congestion that might prevent accommodating all service access requests. However, the strategy proposed in this paper maintains a relatively high rate of successful service access across various service quantity scenarios. Compared to DAQC and WOA, the average success access rate is increased by 12.12% and 19.05%, respectively. This demonstrates the strategy’s remarkable adaptability in highly competitive environments.
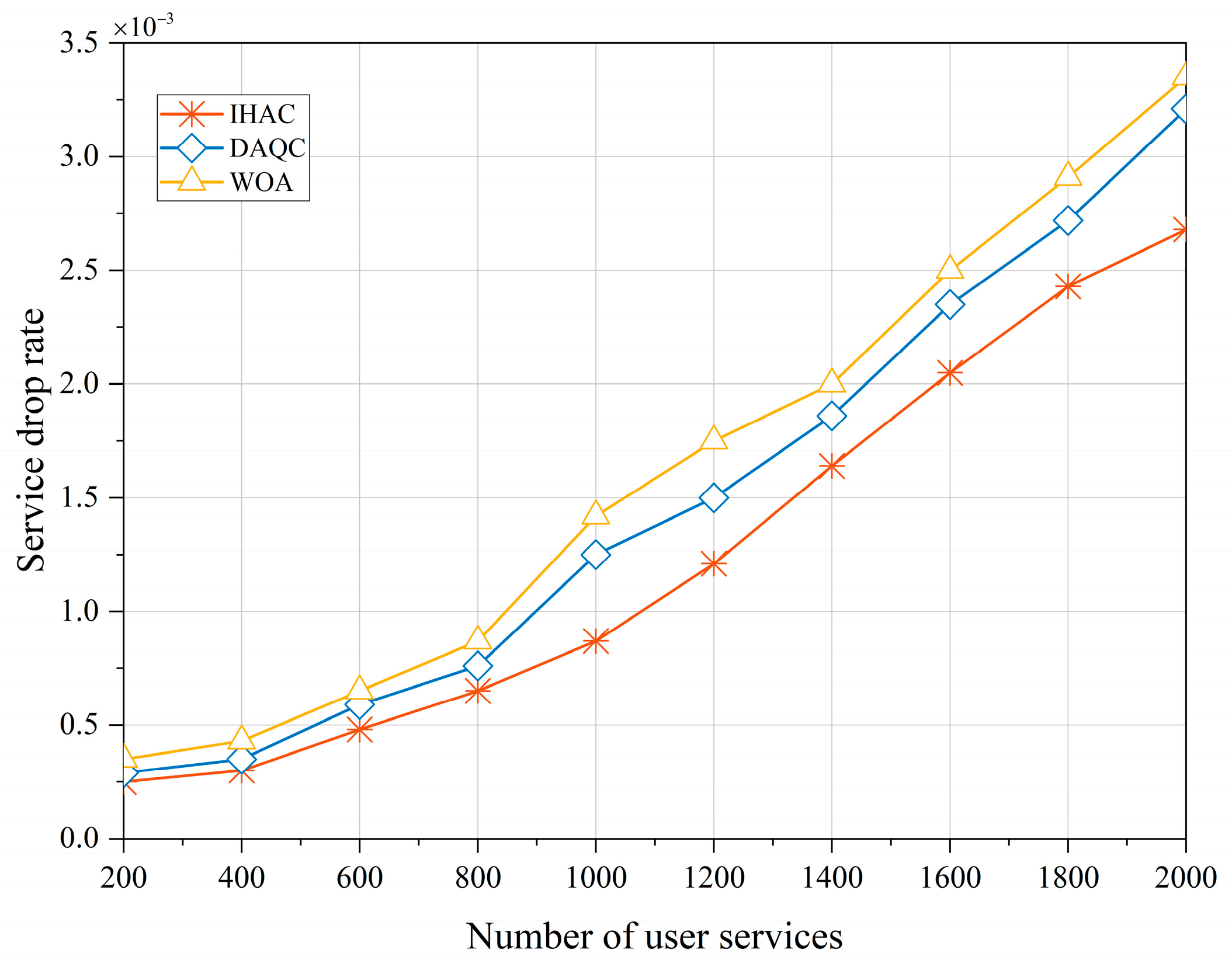
Compared to services that have not been accessed yet, services that are interrupted after accessing are more challenging to accept. This not only means that the resources allocated to the service are released but that this also requires reapplication and resource competition to continue the service. As shown in
Figure 7, the service drop rate changes based on different service quantities. The graph clearly indicates that the proposed strategy maintains a lower drop rate across various service quantity scenarios. This further underscores the strategy’s efficiency in resource allocation and admission decisions, reducing service interruptions and dropped calls, thus enhancing user experience and satisfaction.
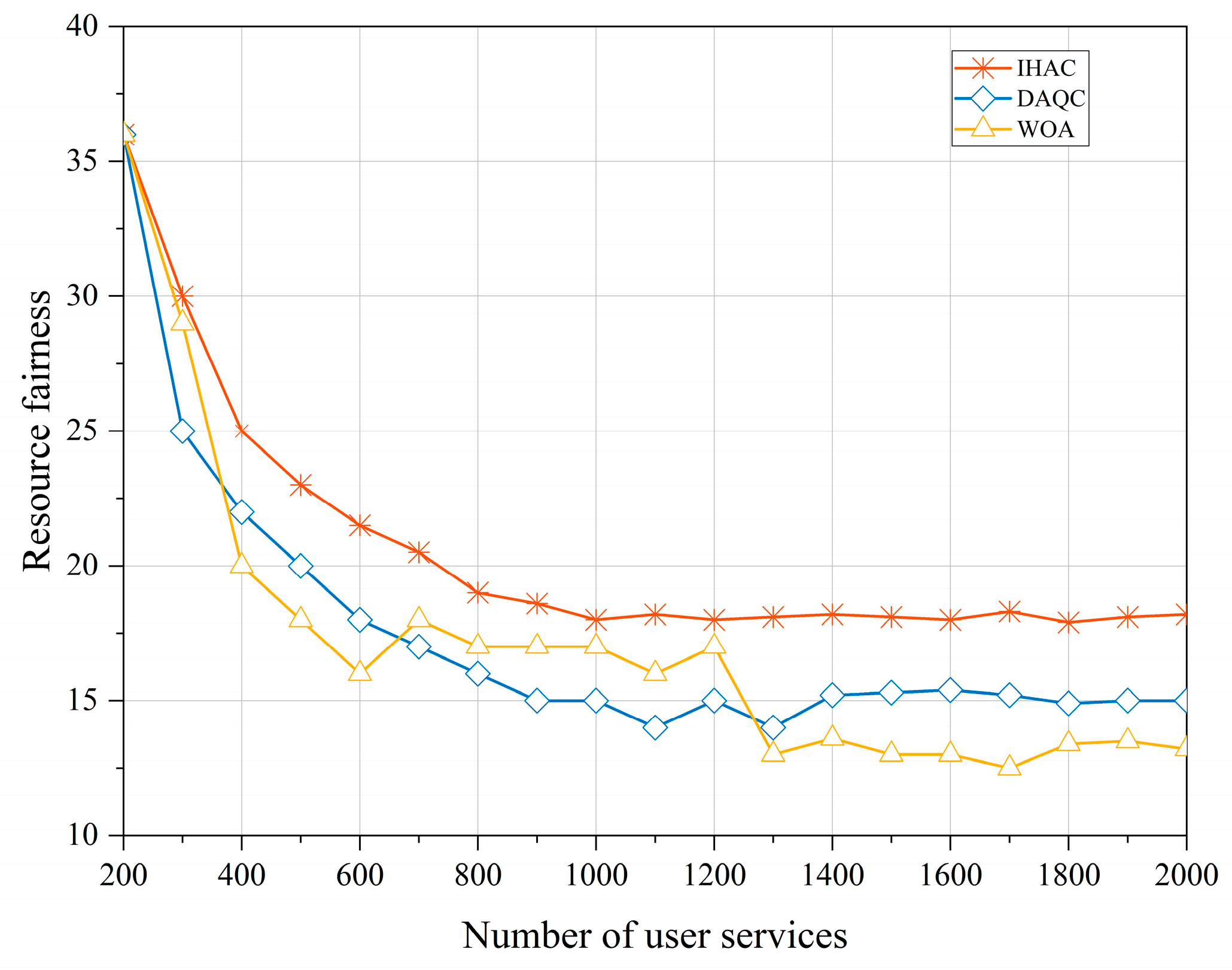
The fairness of resource allocation is defined by the ratio of allocated resources to requested resources, which reflects the satisfaction of ground zone services. Achieving fair resource allocation can reduce unnecessary resource competition. An analysis of
Figure 8 indicates that in the initial stages of the strategy, due to the relatively low number of services initially connected to the satellite and the relatively abundant system resources, the fairness of resource allocation is relatively high. However, as the number of requested communication services gradually increases, differences in dynamic priorities among ground zones and within each zone’s services become more apparent, leading to a gradual decrease in the fairness of resource scheduling. During the process where the number of services reaches 1000, the strategy proposed in this paper reaches and maintains stable resource fairness at the fastest pace. It outperforms DAQC and WOA in terms of resource fairness. This demonstrates the strategy’s exceptional adaptability when facing dynamic and diverse priorities. It maintains high fairness even as the number of services increases, showcasing its ability to effectively handle varying priority scenarios.
Finally, we show the performance comparison between IHAC and baseline algorithms with average metric data, as shown in
Table 5. In addition, we analyze the time and space complexity of IHAC. As we mentioned before, the ground zone and user service status characteristics in each zone are reported to the upper and lower controllers, respectively, in order to train and run the DDPG and DQN in the controller. Since all training and running tasks are performed by the controller, most of the computation and storage cost is incurred in the controller.
In the controller, the computation related to DRL consumes most of the resources, and we focus on analyzing its time and space complexity. During the inference and operation of DDPG and DQN, their computational overhead mainly depends on the number of nodes in the input layer. Specifically, if M represents the number of ground zones, K represents the characteristic dimension of each ground zone, N represents all user services within the satellite coverage, and L represents the characteristic dimension of user services, then the input layer of DDPG consists of MK units, and the input layer of DQN consists of NL units. Then the time complexity can be expressed as . Since DAQC also uses the Markov decision process to model the problem, which is similar to the DRL modeling process, we estimate that its computational complexity is comparable to IHAC. However, for swarm intelligence heuristic algorithms such as WOA, the computational complexity is related to the dimension of search space D and the time complexity f of the fitness function. That is, it can be roughly expressed as . In addition, the space complexity of the upper and lower controllers can be expressed as . However, in the training process, we only need to use a set of samples to carry out the forward propagation of DDPG and DQN. So, the actual space complexity is much less than .
We can find that DL techniques require more computation and storage costs compared to traditional strategies. However, the IHAC we consider can not only achieve the adaptive ability to the dynamic environment through the feature extraction of massive data, but also achieve the dual goals of efficient utilization of beam resources and service fairness.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}