
Parallelized Particle Swarm Optimization on FPGA for Realtime Ballistic Target Tracking

Abstract
:1. Introduction
2. Background
- To the best of our knowledge, this is the first approach to accelerate PSO for ballistic target tracking with an FPGA.
- This paper has parallelized most of the computationally time-consuming parts of the PSO.
- A new parallelization method for realtime ballistic target tracking has been developed.
- The proposed approach has been validated on a real embedded system, and the computation time has been significantly reduced.
3. Problem Description
3.1. The Problem of Target Tracking
3.2. The Problem of Real Time
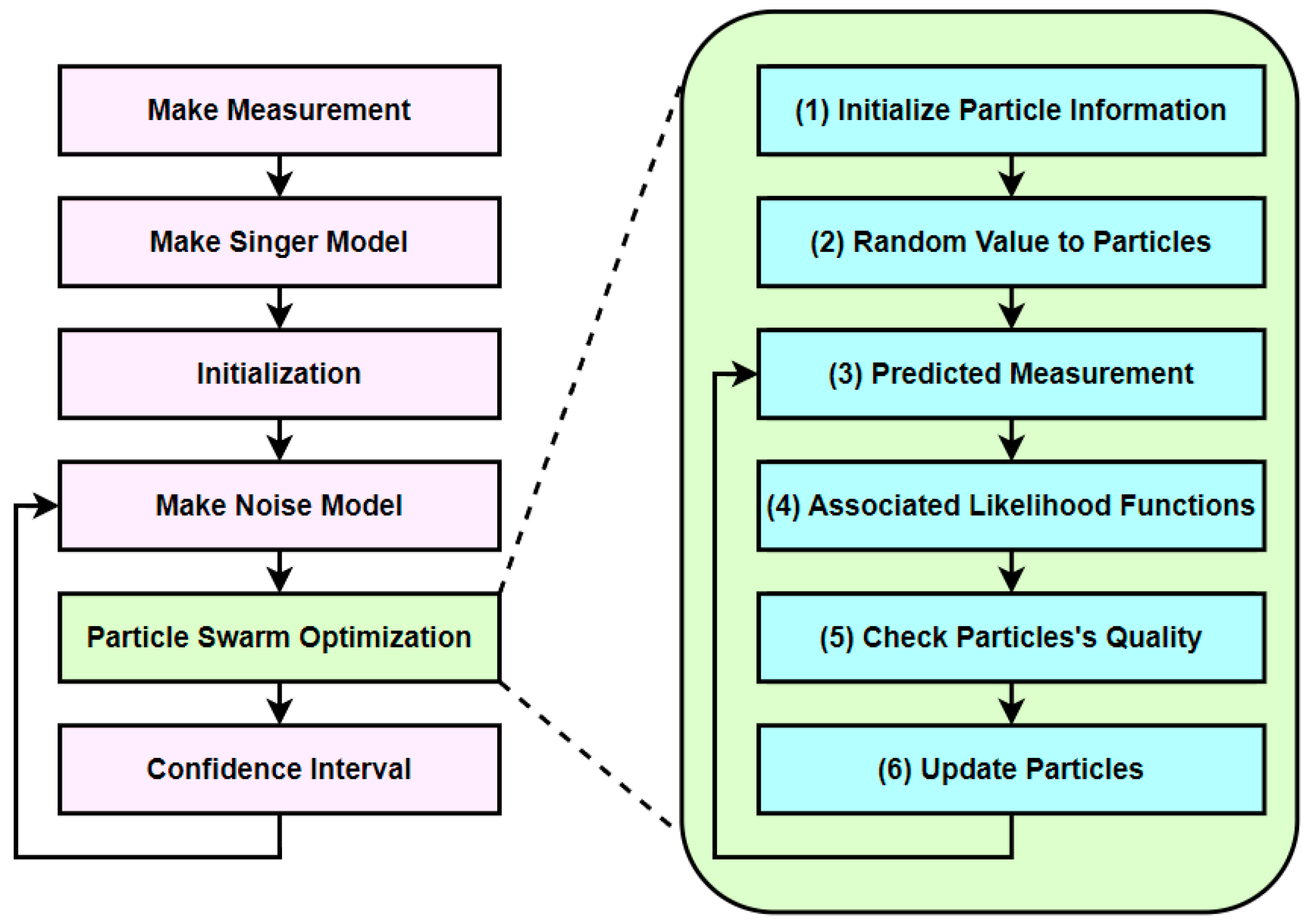
4. Proposed Method
4.1. Overview of the Proposed Method
4.2. Computation Time Profiling
4.3. Parallelization Method #1: Random Value to Particles
| Algorithm 1: Random Value to Particles | |
| Input | Particle position array and Random number array |
| Output | Updated particle position array |
| 1. | for i = 0: the number of particle |
| 2. | for j = 0: the number of rows of transition matrix |
| 3. | |
| 4. | |
| 5. | for = 0: the number of columns of transition matrix |
| 6. | |
| 7. | |
| 8. | end |
| 9. | |
| 10. | end |
| 11. | end |
| Algorithm 2: Parallelized Random Value to Particles | |
| Input | Particle position uint32 array Random number uint32 array |
| Output | Updated particle position uint32 array |
| 1. | do in sequential: for x = 0: Particle Dimension |
| 2. | uint32_to_float_datatype_casting( |
| 3. | end |
| 4. | do in sequential: for y = 0: Particle number Particle Dimension |
| 5. | uint32_to_float_datatype_casting() |
| 6. | end |
| 7. | do in parallel: for = 0: the number of particle |
| 8. | do in parallel: for j = 0: the number of rows of transition matrix |
| 9. | |
| 10. | |
| 11. | do in sequential: for = 0: the number of columns |
| 12. | |
| 13. | |
| 14. | end |
| 15. | |
| 16. | end |
| 17. | end |
| 18. | do in sequential: for z = 0: Particle number Particle Dimension |
| 19. | float_to_uint32_datatype_casting( |
| 20. | end |
4.4. Parallelization Method #2: Predicted Measurement and Associated Likelihood Functions
| Algorithm 3: Predicted Measurements and Associated Likelihood Function | |
| Input | Particle’s position information: Distance, angle, rotation angle measurement: |
| Output | Particle Quality |
| 1. | for i =0: the number of particles |
| 2. | calculate estimation of distance Equation (2) |
| 3. | calculate estimation of angle Equation (3) |
| 4. | calculate estimation of rotation angle Equation (4) |
| 5. | calculate error of distance Equation (5) |
| 6. | Equations (6)–(9) |
| 7. | calculate error of angle Equation (10) |
| 8. | Equations (6)–(9) |
| 9. | calculate error of rotation angle Equation (10) |
| 10. | calculate error of particle Equation (11) |
| 11. | end |
| Algorithm 4: Parallelized Predicted Measurements and Associated Likelihood Function | |
| Input | Particle’s position information uint32 array: Distance, angle, rotation angle measurement uint32 array: |
| Output | Particle Quality uint32 array |
| 1. | do in sequential: for x = 0: the number of particles |
| 2. | uint32_to_float_datatype_casting( |
| 3. | uint32_to_float_datatype_casting( |
| 4. | uint32_to_float_datatype_casting( |
| 5. | end |
| 6. | do in sequential: for x = 0:2 |
| 7. | uint32_to_float_datatype_casting( |
| 8. | end |
| 9. | do in parallel: for i = 0: the number of particles/5 |
| 10. | do in sequential: for j = 0:4 |
| 11. | calculate estimation of distance Equation (2) |
| 12. | calculate estimation of angle Equation (3) |
| 13. | calculate estimation of rotation angle Equation (4) |
| 14. | calculate error of distance Equation (5) |
| 15. | Equations (6)–(9) |
| 16. | calculate error of angle Equation (10) |
| 17. | Equations (6)–(9) |
| 18. | calculate error of rotation angle Equation (10) |
| 19. | calculate error of particle Equation (11) |
| 20. | end |
| 21. | end |
| 22. | do in sequential: for x = 0: the number of particles |
| 23. | float_to_uint32_datatype_casting( |
| 24. | end |
4.5. Parallelization Method #3: Update Particles
| Algorithm 5: Update Particles | |
| Input | Particle’s information in current cycle: Global Optimal Point: Local Optimal Point: Current epoch number |
| Output | Particle’s information in next cycle: |
| 1. | If < max cycle number |
| 2. | for i = 0: the number of particles |
| 3. | for j = 0: the number of particle’s dimension |
| for k = 0:4 | |
| 4. | Equation (12) |
| 5. | Equation (13) |
| 6. | Equation (14) |
| end | |
| 7. | end |
| 8. | end |
| 9. | end |
| Algorithm 6: Parallelized Update Particles | |
| Input | Particle information for the current cycle uint32 array: Global Optimal Point uint32 array: Local Optimal Point uint32 array: Current epoch number: |
| Output | Particle’s information for the next cycle uint32 array: |
| 1. | do in parallel: for x = 0: the number of particles |
| 2. | uint32_to_float_datatype_casting ( |
| 3. | uint32_to_float_datatype_casting ( |
| 4. | uint32_to_float_datatype_casting ( |
| 5. | if x < particle’s dimension: |
| 6. | uint32_to_float_datatype_casting ( |
| 7. | end |
| 8. | end |
| 9. | do in parallel: for i = 0: the number of particles/5 |
| 10. | do in parallel: for j = 0: the number of particle’s dimension |
| 11. | do in sequential: for k = 0:4 |
| 12. | Equation (12) |
| 13. | Equation (13) |
| 14. | Equation (14) |
| 15. | end |
| 16. | end |
| 17. | end |
| 18. | do in parallel: for x = 0: the number of particles |
| 19. | float_to_uint32_datatype_casting ( |
| 20. | float_to_uint32_datatype_casting ( |
| 21. | float_to_uint32_datatype_casting |
| 22. | end |
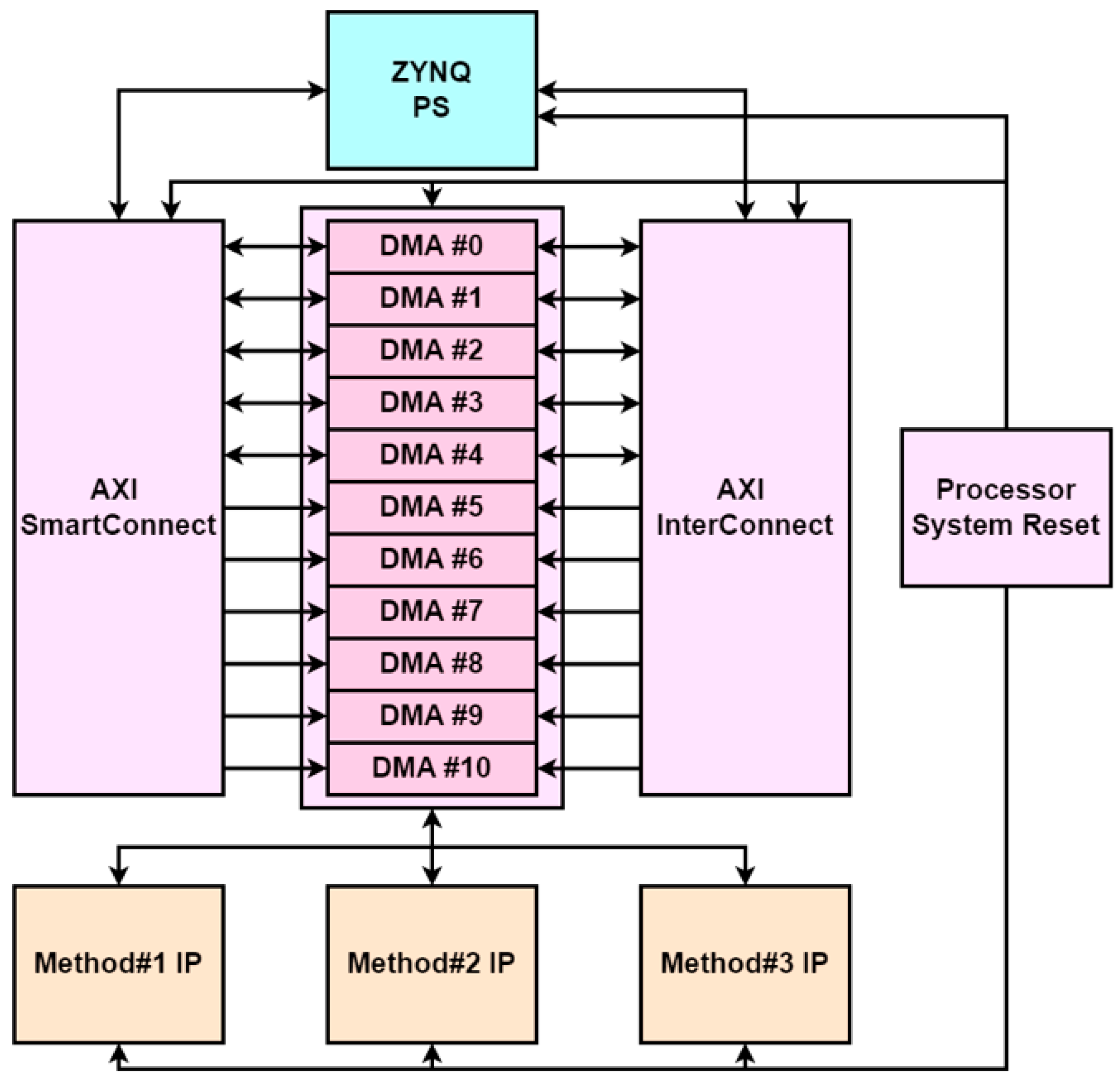
4.6. Hardware Platform Design
5. Results
5.1. Hardware Platform Design Results
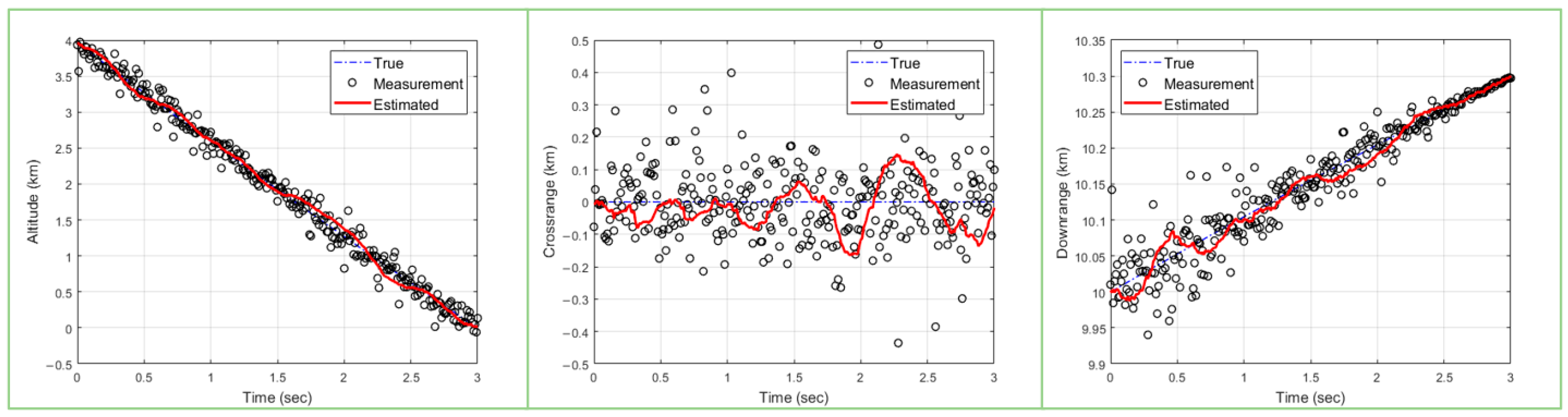
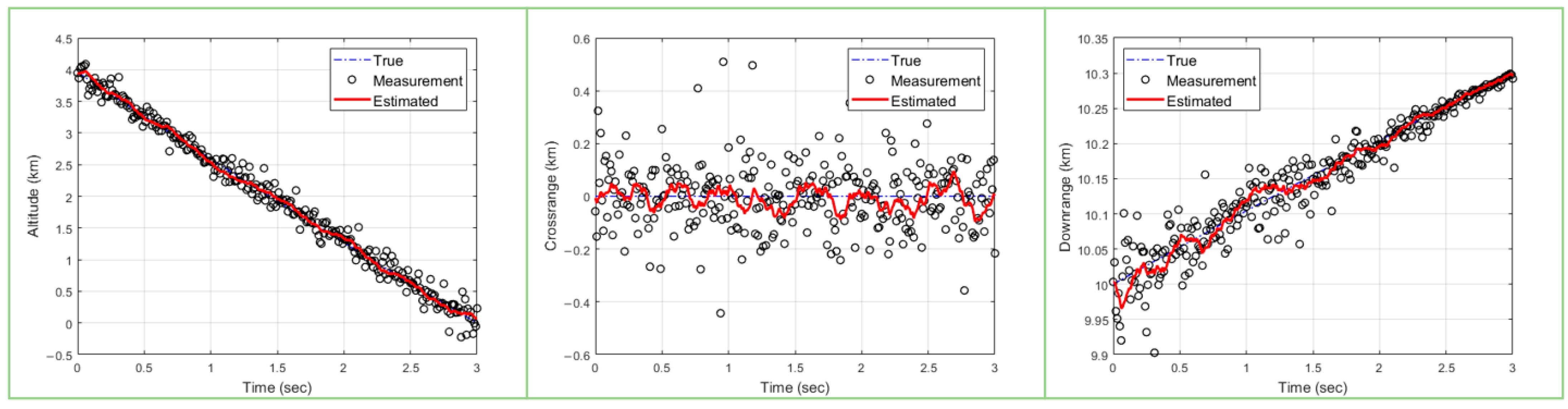
5.2. Simulation Results
5.3. Results of Algorithm Acceleration with FPGA
5.4. Analysis and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Siouris, G.M. Missile guidance and control systems. Appl. Mech. Rev. 2004, 57, 113–119. [Google Scholar] [CrossRef]
- Hewer, G.A.; Martin, R.D.; Zeh, J. Robust preprocessing for Kalman filtering of glint noise. IEEE Trans. Aerosp. Electron. Syst. 1987, 1, 120–128. [Google Scholar] [CrossRef]
- Dong, L.; Xu, H.; Feng, X.; Han, X.; Yu, C. An adaptive target tracking algorithm based on EKF for AUV with unknown Non-Gaussian process noise. Appl. Sci. 2020, 10, 3413. [Google Scholar] [CrossRef]
- Arulampalam, M.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Ge, B.; Zhang, H.; Jiang, L.; Li, Z.; Butt, M.M. Adaptive unscented Kalman filter for target tracking with unknown time-varying noise covariance. Sensors 2019, 19, 1371. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Lee, H.; Gwon, H.; Choi, W.; Jeong, B. Parallelized Particle Swarm Optimization with GPU for Real-Time Ballistic Target Tracking. J. Korean Soc. Embed. Eng. 2022, 17, 355–365. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: Piscataway, NJ, USA, 1995; pp. 1942–1948. [Google Scholar]
- Eberhart; Shi, Y. Particle swarm optimization: Developments, applications and resources. In Proceedings of the 2001 Congress on Evolutionary Computation (IEEE Cat. No. 01TH8546), Seoul, Republic of Korea, 27–30 May 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 81–86. [Google Scholar]
- Song, M.-P.; Gu, G.-C. Research on particle swarm optimization: A review. In Proceedings of the 2004 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 04EX826), Shanghai, China, 26–29 August 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 2236–2241. [Google Scholar]
- Shami, T.M.; El-Saleh, A.A.; Alswaitti, M.; Al-Tashi, Q.; Summakieh, M.A.; Mirjalili, S. Particle Swarm Optimization: A Comprehensive Survey. IEEE Access 2022, 10, 10031–10061. [Google Scholar] [CrossRef]
- Rafi, S.; Kumar, A.; Singh, G. An improved particle swarm optimization method for multirate filter bank design. J. Frankl. Inst. 2013, 350, 757–769. [Google Scholar] [CrossRef]
- Kaveh, A.; Izadifard, R.; Mottaghi, L. Optimal design of planar RC frames considering CO2 emissions using ECBO, EVPS and PSO metaheuristic algorithms. J. Build. Eng. 2020, 28, 101014. [Google Scholar] [CrossRef]
- Bacanin, N.; Antonijevic, M.; Bezdan, T.; Zivkovic, M.; Venkatachalam, K.; Malebary, S. Energy efficient offloading mechanism using particle swarm optimization in 5G enabled edge nodes. Clust. Comput. 2023, 26, 587–598. [Google Scholar] [CrossRef]
- Singh, A.; Sharma, A.; Rajput, S.; Bose, A.; Hu, X. An investigation on hybrid particle swarm optimization algorithms for parameter optimization of PV cells. Electronics 2022, 11, 909. [Google Scholar] [CrossRef]
- Ding, W.; Fang, W. Target tracking by sequential random draft particle swarm optimization algorithm. In Proceedings of the 2018 IEEE International Smart Cities Conference (ISC2), Kansas City, MI, USA, 16–19 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Rayala, S.S.; Kumar, N.A. Ashok. Particle Swarm Optimization for robot target tracking application. Mater. Today Proc. 2020, 33, 3600–3603. [Google Scholar] [CrossRef]
- Keshavarz-Mohammadiyan, A.; Khaloozadeh, H. PSO-PF target tracking in range-based Wireless Sensor Networks with distance-dependent measurement noise. In Proceedings of the 2015 23rd Iranian Conference on Electrical Engineering, Tehran, Iran, 10–14 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 911–915. [Google Scholar]
- Wu, Y.; Wu, C.; Wang, L.; Sun, L.; Wang, D. Radar Target Tracking Algorithm Based on New Particle Swarm Optimization Particle Filter. In Proceedings of the 2021 10th International Conference on Networks, Communication and Computing, Athens, Greece, 19–22 July 2021; pp. 91–96. [Google Scholar]
- Cheng, Z.; Fan, L.; Zhang, Y. Multi-agent decision support system for missile defense based on improved PSO algorithm. J. Syst. Eng. Electron. 2017, 28, 514–525. [Google Scholar]
- Xu, Z.; Gao, Y.; Jing, W.; Wang, Y. Multidisciplinary integrated design of long-range ballistic missile using PSO algorithm. J. Syst. Eng. Electron. 2020, 31, 335–349. [Google Scholar]
- Zhang, Z.; Seah, H.S.; Quah, C.K.; Sun, J. GPU-accelerated real-time tracking of full-body motion with multi-layer search. IEEE Trans. Multimed. 2012, 15, 106–119. [Google Scholar] [CrossRef]
- dos Santos JÚnior, J.G.; do Monte Lima, J.P.S. Particle swarm optimization for 3D object tracking in RGB-D images. Comput. Graph. 2018, 76, 167–180. [Google Scholar] [CrossRef]
- Rymut, B.; Kwolek, B. Real-time multiview human pose tracking using graphics processing unit-accelerated particle swarm optimization. Concurr. Comput. Pract. Exp. 2015, 27, 1551–1563. [Google Scholar] [CrossRef]
- Huang, H.-C. A Taguchi-based heterogeneous parallel metaheuristic ACO-PSO and its FPGA realization to optimal polar-space locomotion control of four-wheeled redundant mobile robots. IEEE Trans. Ind. Inform. 2015, 11, 915–922. [Google Scholar] [CrossRef]
- Li, S.-A.; Hsu, C.-C.; Wong, C.-C.; Yu, C.-J. Hardware/software co-design for particle swarm optimization algorithm. Inf. Sci. 2011, 181, 4582–4596. [Google Scholar] [CrossRef]
- Ettouil, M.; Smei, H.; Jemai, A. Particle swarm optimization on fpga. In Proceedings of the 2018 30th International Conference on Microelectronics (ICM), Sousse, Tunisia, 16–19 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 32–35. [Google Scholar]
- Tavares, Y.M.; Nedjah, N.; de Macedo Mourelle, L. Hardware/software co-design system for template matching using Particle Swarm Optimization and Pearson’s Correlation Coefficient. In Proceedings of the 2016 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Bariloche, Argentina, 20–23 February 2017; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Weitz, L.A. Derivation of a Point-Mass Aircraft Model Used for Fast-Time Simulation; MITRE Corporation: Bedford, MA, USA, 2015. [Google Scholar]
- Singer, R.A. Estimating optimal tracking filter performance for manned maneuvering targets. IEEE Trans. Aerosp. Electron. Syst. 1970, 4, 473–483. [Google Scholar] [CrossRef]
- Li, X.R.; Jilkov, V.P. Survey of maneuvering target tracking. Part I. Dynamic models. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1333–1364. [Google Scholar]
- Yager, R.J. Army research lab aberdeen proving ground md weapons and materials research directorate. In Generating Pseudorandom Numbers from Various Distributions Using C++; US Army Research Laboratory: Aberdeen Proving Ground, MD, USA, 2014. [Google Scholar]
- Wright, D.C.; Kadyshev, T. An analysis of the North Korean Nodong missile. Sci. Glob. Secur. 1994, 4, 129–160. [Google Scholar] [CrossRef]
- Nasr, M.; Farouk, O.; Mohamedeen, A.; Elrafie, A.; Bedeir, M.; Khaled, A. Benchmarking meta-heuristic optimization. arXiv 2020, arXiv:2007.13476. [Google Scholar] [CrossRef]
- Ghambari, S.; Lepagnot, J.; Jourdan, L.; Idoumghar, L. A comparative study of meta-heuristic algorithms for solving UAV path planning. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bengaluru, India, 18–21 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 174–181. [Google Scholar]
- Abdor-Sierra, J.A.; Merchán-Cruz, E.A.; Rodríguez-Cañizo, R.G. A comparative analysis of metaheuristic algorithms for solving the inverse kinematics of robot manipulators. Results Eng. 2022, 16, 100597. [Google Scholar] [CrossRef]
- Sahin, O.; Akay, B. Comparisons of metaheuristic algorithms and fitness functions on software test data generation. Appl. Soft Comput. 2016, 49, 1202–1214. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Works | Parallelization | Parallelization Part | Missile Application |
|---|---|---|---|
| [15,16,17] | X | - | X |
| [18,19,20] | X | - | O |
| [21] | GPU | Propagate particle swarm Compute objective error Update “best” Update positions | X |
| [22] | GPU | Calculation of error | X |
| [23] | GPU | Calculation of the cost Function | X |
| [24] | FPGA | Initialization Evaluation Position update | X |
| [25] | FPGA | Particle updating | X |
| [26] | FPGA | Particle updating Finding best particle | X |
| [27] | FPGA | Calculation of Pearson’s correlation coefficient | X |
| Ours | FPGA | Random value to particles Predicted measurements Associated likelihood function Particle update | O |
| Resource | Utilization | Available | Utilization (%) |
|---|---|---|---|
| LUT | 88,558 | 218,600 | 40.51 |
| LUTRAM | 5244 | 70,400 | 7.45 |
| FF | 94,978 | 437,200 | 21.72 |
| BRAM | 100 | 545 | 18.35 |
| DSP | 375 | 900 | 41.67 |
| Static | Dynamic | ||||||
|---|---|---|---|---|---|---|---|
| Device | Clocks | Signals | Logic | BRAM | DSP | PS | |
| Power Consumption(W) | 0.232 | 0.194 | 0.507 | 0.455 | 0.038 | 0.114 | 1.568 |
| Ratio (%) | 7.5 | 6.2 | 16.3 | 14.6 | 1.2 | 3.7 | 50.4 |
| Particle (Samples) | Errors with MCO (km) | Errors with PSO (km) | ||||||
|---|---|---|---|---|---|---|---|---|
| Downrange | Crossrange | Altitude | MSE | Downrange | Crossrange | Altitude | MSE | |
| 500 | 0.0133 | 0.0319 | 0.0627 | 0.072 | 0.0117 | 0.0524 | 0.0555 | 0.077 |
| 1000 | 0.0151 | 0.0220 | 0.0638 | 0.069 | 0.0158 | 0.0257 | 0.0698 | 0.076 |
| 1500 | 0.0115 | 0.0319 | 0.0499 | 0.060 | 0.0080 | 0.0376 | 0.0420 | 0.057 |
| 2000 | 0.0127 | 0.0246 | 0.0493 | 0.057 | 0.0079 | 0.0283 | 0.0358 | 0.046 |
| 2500 | 0.0102 | 0.0299 | 0.0417 | 0.052 | 0.0085 | 0.0254 | 0.0363 | 0.045 |
| Number of Particles | PS Only (ms) | PS + PL (ms) | Acceleration (×) |
|---|---|---|---|
| 500 | 11,361.02 | 1524.74 | 7.45 |
| 1000 | 22,695.18 | 3044.62 | 7.45 |
| 1500 | 34,327.68 | 4602.71 | 7.46 |
| 2000 | 45,456.47 | 6071.05 | 7.49 |
| 2500 | 57,199.55 | 7675.52 | 7.45 |
| 3000 | 68,115.51 | 9105.85 | 7.48 |
| Number of Particles | PS Only (ms) | PS + PL (ms) | Acceleration (×) |
|---|---|---|---|
| 500 | 5326.16 | 748.85 | 7.11 |
| 1000 | 11,142.67 | 1653.90 | 6.74 |
| 1500 | 16,948.53 | 2595.53 | 6.53 |
| 2000 | 22,470.24 | 34,876.89 | 6.44 |
| 2500 | 28,299.83 | 4621.18 | 6.12 |
| 3000 | 33,907.71 | 5710.24 | 5.94 |
| Number of Epochs | PS Only (ms) | PS + PL (ms) | Acceleration (×) |
|---|---|---|---|
| 5 | 8046.33 | 1110.77 | 7.24 |
| 10 | 16,948.53 | 2595.52 | 6.53 |
| 15 | 26,041.55 | 4768.62 | 5.46 |
| 20 | 34,477.19 | 6496.31 | 5.31 |
| 25 | 43,515.75 | 8208.57 | 5.30 |
| Number of Particles | PS Only (ms) | PS + PL (ms) | Acceleration (×) |
|---|---|---|---|
| 500 | 7520.93 | 5356.54 | 1.40 |
| 1000 | 15,439.34 | 10,694.70 | 1.44 |
| 1500 | 24,290.23 | 16,393.26 | 1.48 |
| 2000 | 31,390.19 | 21,727.67 | 1.44 |
| 2500 | 40,636.12 | 27,443.28 | 1.48 |
| 3000 | 47,189.01 | 32,950.91 | 1.43 |
| Number of Epochs | PS Only (ms) | PS + PL (ms) | Acceleration (×) |
|---|---|---|---|
| 5 | 9603.01 | 7146.623 | 1.34 |
| 10 | 24,290.23 | 16,392.51 | 1.48 |
| 15 | 41,529.85 | 25,573.33 | 1.62 |
| 20 | 62,120.61 | 39,063.76 | 1.59 |
| 25 | 81,150.53 | 48,362.21 | 1.68 |
| Number of Particles | PS Only (ms) | PS + PL (ms) | Acceleration (×) |
|---|---|---|---|
| 500 | 24,796.47 | 8256.29 | 3.25 |
| 1000 | 50,601.06 | 16,767.23 | 3.16 |
| 1500 | 77,585.86 | 25,727.49 | 3.12 |
| 2000 | 102,039.91 | 34,199.77 | 3.08 |
| 2500 | 129,611.31 | 43,473.34 | 3.06 |
| 3000 | 153,392.16 | 52,223.67 | 3.01 |
| Number of Epochs | PS Only (ms) | PS + PL (ms) | Acceleration (×) |
|---|---|---|---|
| 5 | 52,384.83 | 13,459.42 | 3.89 |
| 10 | 77,585.86 | 25,724.92 | 3.02 |
| 15 | 105,879.64 | 39,467.58 | 2.68 |
| 20 | 137,987.21 | 57,831.46 | 2.39 |
| 25 | 169,369.51 | 72,241.48 | 2.34 |
| Number of Particles | PS Only (ms) | PS + PL (ms) | Acceleration (×) |
|---|---|---|---|
| 500 | 26,790.02 | 10,168.72 | 2.63 |
| 1000 | 52,984.94 | 19,031.35 | 2.78 |
| 1500 | 80,338.84 | 28,373.23 | 2.83 |
| 2000 | 105,170.13 | 37,193.46 | 2.82 |
| 2500 | 133,116.34 | 46,854.30 | 2.84 |
| 3000 | 157,289.37 | 55,978.17 | 2.81 |
| Number of Epochs | PS Only (ms) | PS + PL (ms) | Acceleration (×) |
|---|---|---|---|
| 5 | 55,014.56 | 16,033.68 | 3.43 |
| 10 | 80,338.84 | 28,361.65 | 2.83 |
| 15 | 108,783.71 | 42,171.31 | 2.58 |
| 20 | 140,860.32 | 60,564.57 | 2.33 |
| 25 | 172,240.61 | 74,963.45 | 2.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Lee, H.; Kwon, H.-H.; Hwang, Y.; Choi, W. Parallelized Particle Swarm Optimization on FPGA for Realtime Ballistic Target Tracking. Sensors 2023, 23, 8456. https://doi.org/10.3390/s23208456
Park J, Lee H, Kwon H-H, Hwang Y, Choi W. Parallelized Particle Swarm Optimization on FPGA for Realtime Ballistic Target Tracking. Sensors. 2023; 23(20):8456. https://doi.org/10.3390/s23208456
Chicago/Turabian StylePark, Juhyeon, Heoncheol Lee, Hyuck-Hoon Kwon, Yeji Hwang, and Wonseok Choi. 2023. "Parallelized Particle Swarm Optimization on FPGA for Realtime Ballistic Target Tracking" Sensors 23, no. 20: 8456. https://doi.org/10.3390/s23208456