
Reinforcement-Learning-Based Routing and Resource Management for Internet of Things Environments: Theoretical Perspective and Challenges

Abstract
:1. Introduction
1.1. Context
1.2. Motivation
1.3. Contributions
- We highlight key issues regarding IoT network resource management with a focus on network layer improvements.
- We examine the RL concept as a potential solution to enhance IoT network routing performances.
- A detailed overview of how RL is being applied within the IoT network layer environment is provided.
- We discuss the challenges and explore associated open issues when using RL algorithms in the context of IoT networks.
2. Internet of Things Environment
2.1. System Model
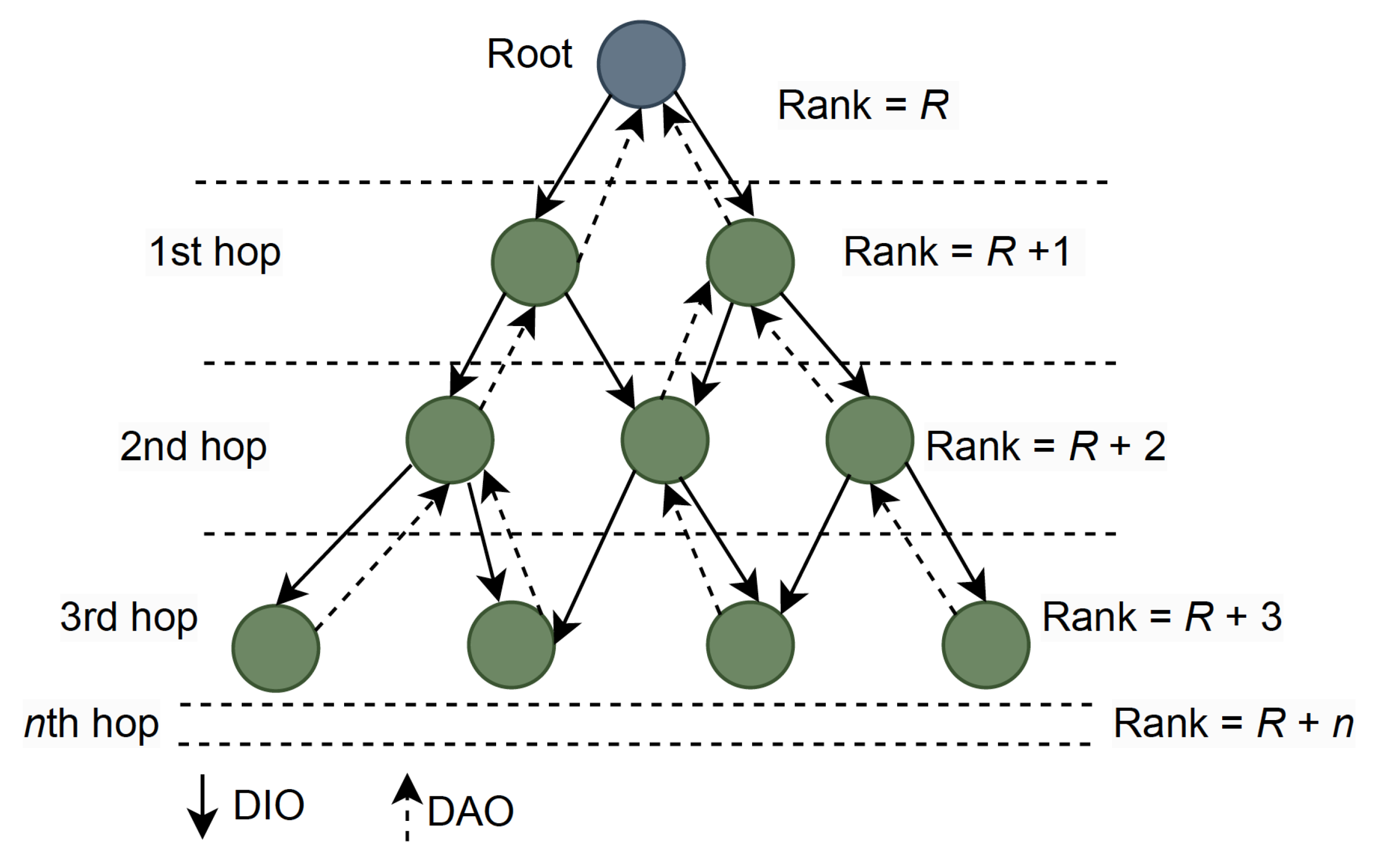
2.2. Network Layer
2.3. MAC Layer
2.4. Resource Management Problems in IoT Environments
3. Reinforcement Learning
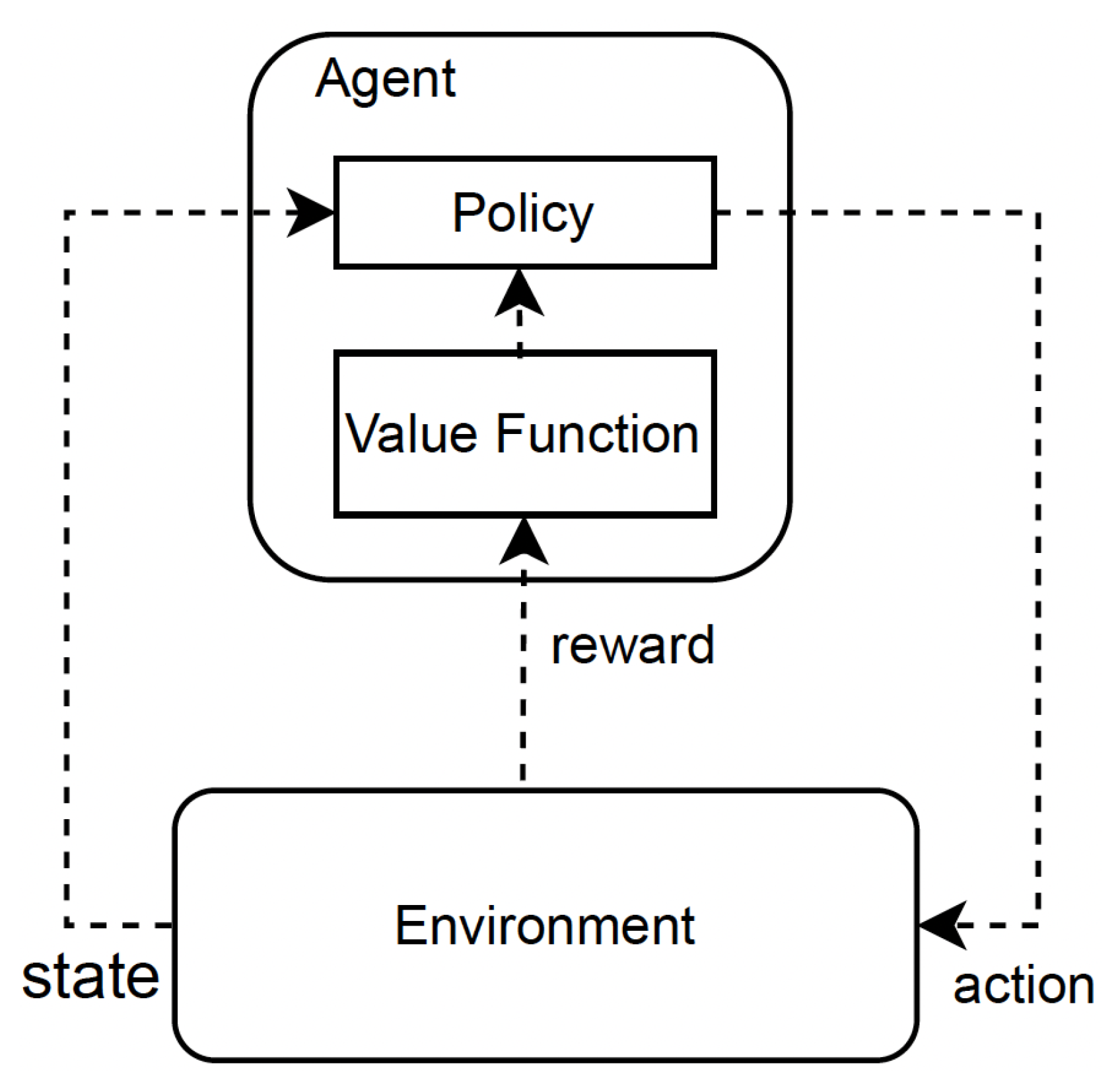
3.1. Basic Concept
3.2. State Space
3.3. Action Space
3.4. Reward Function
3.5. Policy
3.6. State Value and State–Action Value Function
4. Reinforcement Learning for IoT Networking Management
4.1. Related Research Studies
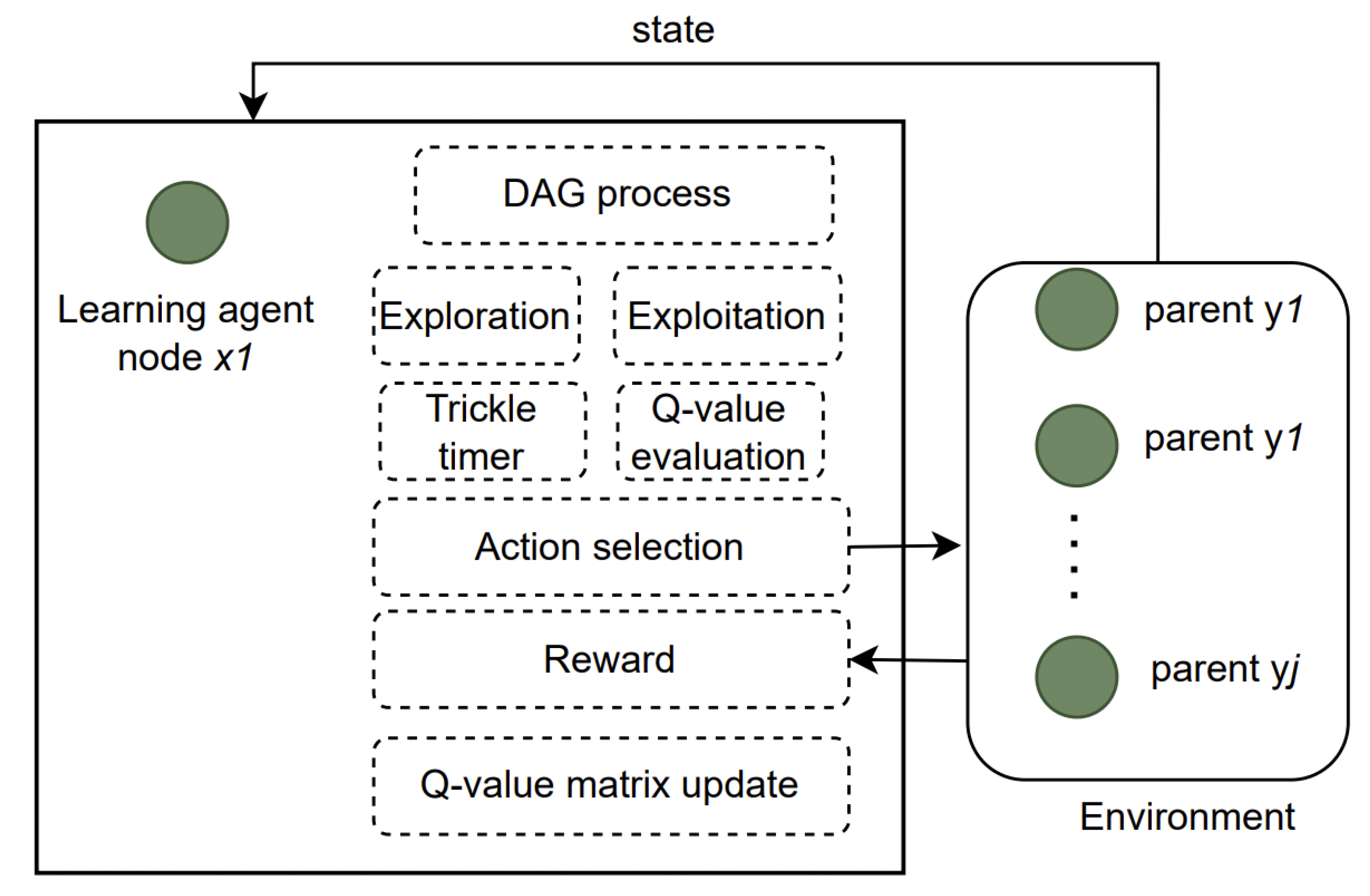
4.2. RL Model for RPL Management
4.3. Federated Learning Model for RPL Management
5. Challenges and Open Issues of RL-Based Algorithms in IoT Networks
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| RL | Reinforcement learning |
| LLN | Low-power and lossy networks |
| MAC | Medium access control |
| RPL | Routing protocol for low-power and lossy networks |
| DODAG | Destination-oriented directed acyclic graph |
| BE | Backoff exponent |
| ML | Machine learning |
| CRs | Cognitive radios |
| LoRa | Long-range |
| DRL | Deep learning with RL |
| OF | Objective function |
| OF0 | Objective function zero |
| MRHOF | Minimum rank with hysteresis OF |
| ETX | Expected transmission count |
| DIO | DODAG information object |
| DAO | DODAG advertisement object |
| DIS | DODAG information solicitation |
| DCF | Distributed coordinated function |
| DIFS | DCF interframe space |
| CW | Contention window |
| NB | Number of backoffs |
| ACKs | Acknowledgments |
| MDP | Markov decision process |
| RCAR | RL-based congestion-avoided routing |
| CARMA | Channel-aware RL-based multi-path adaptive routing |
| ISVM-Q | Q-learning-based improved support vector machine |
| QLRR-WA | Q-learning reliable routing approach with a weighting agent |
| SDNs | Software-defined networks |
| CNNs | Convolutional neural networks |
| QAZP | Q-learning-based adaptive zone partition |
| WSNs | Wireless sensor networks |
| MANETs | Mobile ad hoc networks |
| MiFi | Mean field RL |
| UCB | Upper confidence bound |
References
- Ahmadi, H.; Arji, G.; Shahmoradi, L.; Safdari, R.; Nilashi, M.; Alizadeh, M. The application of internet of things in healthcare: A systematic literature review and classification. Univers. Access Inf. Soc. 2019, 18, 837–869. [Google Scholar] [CrossRef]
- Wang, R.; Yu, C.; Wang, J. Construction of supply chain financial risk management mode based on Internet of Things. IEEE Access 2019, 7, 110323–110332. [Google Scholar] [CrossRef]
- Pivoto, D.G.; de Almeida, L.F.; da Rosa Righi, R.; Rodrigues, J.J.; Lugli, A.B.; Alberti, A.M. Cyber-physical systems architectures for industrial internet of things applications in Industry 4.0: A literature review. J. Manuf. Syst. 2021, 58, 176–192. [Google Scholar] [CrossRef]
- Virmani, C.; Pillai, A. Internet of Things and Cyber Physical Systems: An Insight. In Recent Advances in Intelligent Systems and Smart Applications; Springer: Cham, Switzerland, 2021; pp. 379–401. [Google Scholar]
- Musaddiq, A.; Zikria, Y.B.; Hahm, O.; Yu, H.; Bashir, A.K.; Kim, S.W. A Survey on Resource Management in IoT Operating Systems. IEEE Access 2018, 6, 8459–8482. [Google Scholar] [CrossRef]
- Ghasempour, A. Internet of things in smart grid: Architecture, applications, services, key technologies, and challenges. Inventions 2019, 4, 22. [Google Scholar] [CrossRef]
- Fantin Irudaya Raj, E.; Appadurai, M. Internet of things-based smart transportation system for smart cities. In Intelligent Systems for Social Good: Theory and Practice; Springer: Singapore, 2022; pp. 39–50. [Google Scholar]
- Shrestha, R.; Mishra, A.; Bajracharya, R.; Sinaei, S.; Kim, S. 6G Network for Connecting CPS and Industrial IoT (IIoT). In Cyber-Physical Systems for Industrial Transformation; CRC Press: Boca Raton, FL, USA, 2023; pp. 17–38. [Google Scholar]
- Almusaylim, Z.A.; Zaman, N. A review on smart home present state and challenges: Linked to context-awareness internet of things (IoT). Wirel. Netw. 2019, 25, 3193–3204. [Google Scholar] [CrossRef]
- Kritsis, K.; Papadopoulos, G.Z.; Gallais, A.; Chatzimisios, P.; Théoleyre, F. A Tutorial on Performance Evaluation and Validation Methodology for Low-Power and Lossy Networks. IEEE Commun. Surv. Tutorials 2018, 20, 1799–1825. [Google Scholar] [CrossRef]
- Yaqoob, I.; Ahmed, E.; Hashem, I.A.T.; Ahmed, A.I.A.; Gani, A.; Imran, M.; Guizani, M. Internet of things architecture: Recent advances, taxonomy, requirements, and open challenges. IEEE Wirel. Commun. 2017, 24, 10–16. [Google Scholar] [CrossRef]
- Dutta, D. IEEE 802.15. 4 as the MAC protocol for internet of things (IoT) applications for achieving QoS and energy efficiency. In Proceedings of the Advances in Communication, Cloud, and Big Data: Proceedings of 2nd National Conference on CCB 2016, Gangtok, India, 2–3 November 2016; Springer: Berlin/Heidelberg, Germany, 2019; pp. 127–132. [Google Scholar]
- Ahmed, N.; Rahman, H.; Hussain, M.I. A comparison of 802.11 ah and 802.15. 4 for IoT. Ict Express 2016, 2, 100–102. [Google Scholar] [CrossRef]
- Winter, T.; Thubert, P.; Brandt, A.; Hui, J.; Kelsey, R.; Levis, P.; Pister, K.; Struik, R.; Vasseur, J.P.; Alexander, R. RPL: IPv6 Routing Protocol for Low-Power and Lossy Networks; Technical Report; Internet Engineering Task Force (IETF): Fremont, CA, USA, 2012. [Google Scholar]
- Clausen, T.; Herberg, U.; Philipp, M. A critical evaluation of the IPv6 routing protocol for low power and lossy networks (RPL). In Proceedings of the 2011 IEEE 7th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Shanghai, China, 10–12 October 2011; pp. 365–372. [Google Scholar]
- Musaddiq, A.; Rahim, T.; Kim, D.S. Enhancing IEEE 802.15.4 Access Mechanism with Machine Learning. In Proceedings of the 2021 Twelfth International Conference on Ubiquitous and Future Networks (ICUFN), Jeju Island, Republic of Korea, 17–20 August 2021; pp. 210–212. [Google Scholar] [CrossRef]
- Musaddiq, A.; Zikria, Y.B.; Kim, S.W. Routing protocol for Low-Power and Lossy Networks for heterogeneous traffic network. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 1–23. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Yang, H.; Xie, X.; Kadoch, M. Machine learning techniques and a case study for intelligent wireless networks. IEEE Netw. 2020, 34, 208–215. [Google Scholar] [CrossRef]
- Xu, Y.; Xu, W.; Wang, Z.; Lin, J.; Cui, S. Load balancing for ultradense networks: A deep reinforcement learning-based approach. IEEE Internet Things J. 2019, 6, 9399–9412. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Gomes, P.H.; Krishnamachari, B. Deep reinforcement learning for dynamic multichannel access in wireless networks. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 257–265. [Google Scholar] [CrossRef]
- Musaddiq, A.; Ali, R.; Choi, J.G.; Kim, B.S.; Kim, S.W. Collision observation-based optimization of low-power and lossy IoT network using reinforcement learning. Comput. Mater. Contin. 2021, 67, 799–814. [Google Scholar] [CrossRef]
- Uprety, A.; Rawat, D.B. Reinforcement learning for iot security: A comprehensive survey. IEEE Internet Things J. 2020, 8, 8693–8706. [Google Scholar] [CrossRef]
- Le, N.; Rathour, V.S.; Yamazaki, K.; Luu, K.; Savvides, M. Deep reinforcement learning in computer vision: A comprehensive survey. Artif. Intell. Rev. 2022, 55, 2733–2819. [Google Scholar] [CrossRef]
- Luketina, J.; Nardelli, N.; Farquhar, G.; Foerster, J.; Andreas, J.; Grefenstette, E.; Whiteson, S.; Rocktäschel, T. A survey of reinforcement learning informed by natural language. arXiv 2019, arXiv:1906.03926. [Google Scholar]
- Lin, Y.; Wang, C.; Wang, J.; Dou, Z. A novel dynamic spectrum access framework based on reinforcement learning for cognitive radio sensor networks. Sensors 2016, 16, 1675. [Google Scholar] [CrossRef]
- Bajracharya, R.; Shrestha, R.; Hassan, S.A.; Konstantin, K.; Jung, H. Dynamic Pricing for Intelligent Transportation System in the 6G Unlicensed Band. IEEE Trans. Intell. Transp. Syst. 2022, 23, 9853–9868. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Chen, Y.; Liu, Y.; Zeng, M.; Saleem, U.; Lu, Z.; Wen, X.; Jin, D.; Han, Z.; Jiang, T.; Li, Y. Reinforcement learning meets wireless networks: A layering perspective. IEEE Internet Things J. 2020, 8, 85–111. [Google Scholar] [CrossRef]
- Jayanetti, A.; Halgamuge, S.; Buyya, R. Deep reinforcement learning for energy and time optimized scheduling of precedence-constrained tasks in edge–cloud computing environments. Future Gener. Comput. Syst. 2022, 137, 14–30. [Google Scholar] [CrossRef]
- Tran-Dang, H.; Bhardwaj, S.; Rahim, T.; Musaddiq, A.; Kim, D.S. Reinforcement learning based resource management for fog computing environment: Literature review, challenges, and open issues. J. Commun. Netw. 2022, 24, 83–98. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Zhou, C.; He, H.; Yang, P.; Lyu, F.; Wu, W.; Cheng, N.; Shen, X. Deep RL-based trajectory planning for AoI minimization in UAV-assisted IoT. In Proceedings of the 2019 11th International Conference on Wireless Communications and Signal Processing (WCSP), Xi’an, China, 23–25 October 2019; pp. 1–6. [Google Scholar]
- Hamdi, R.; Baccour, E.; Erbad, A.; Qaraqe, M.; Hamdi, M. LoRa-RL: Deep reinforcement learning for resource management in hybrid energy LoRa wireless networks. IEEE Internet Things J. 2021, 9, 6458–6476. [Google Scholar] [CrossRef]
- Wang, Y.; Ye, Z.; Wan, P.; Zhao, J. A survey of dynamic spectrum allocation based on reinforcement learning algorithms in cognitive radio networks. Artif. Intell. Rev. 2019, 51, 493–506. [Google Scholar] [CrossRef]
- Bajracharya, R.; Shrestha, R.; Jung, H. Bandit Approach for Fair and Efficient Coexistence of NR-U in Unlicensed Bands. IEEE Trans. Veh. Technol. 2022, 72, 5208–5223. [Google Scholar] [CrossRef]
- Bajracharya, R.; Shrestha, R.; Kim, S.W. Q-learning based fair and efficient coexistence of LTE in unlicensed band. Sensors 2019, 19, 2875. [Google Scholar] [CrossRef]
- Yadav, R.; Zhang, W.; Elgendy, I.A.; Dong, G.; Shafiq, M.; Laghari, A.A.; Prakash, S. Smart healthcare: RL-based task offloading scheme for edge-enable sensor networks. IEEE Sensors J. 2021, 21, 24910–24918. [Google Scholar] [CrossRef]
- Naparstek, O.; Cohen, K. Deep multi-user reinforcement learning for distributed dynamic spectrum access. IEEE Trans. Wirel. Commun. 2018, 18, 310–323. [Google Scholar] [CrossRef]
- Shurrab, M.; Singh, S.; Mizouni, R.; Otrok, H. Iot sensor selection for target localization: A reinforcement learning based approach. Ad Hoc. Netw. 2022, 134, 102927. [Google Scholar] [CrossRef]
- Gregor, S. The nature of theory in information systems. MIS Q. 2006, 30, 611–642. [Google Scholar] [CrossRef]
- Gaddour, O.; Koubâa, A. RPL in a nutshell: A survey. Comput. Netw. 2012, 56, 3163–3178. [Google Scholar] [CrossRef]
- Gnawali, O.; Levis, P. Rfc 6719: The Minimum Rank with Hysteresis Objective Function; Internet Engineering Task Force (IETF): Fremont, CA, USA, 2012. [Google Scholar]
- Musaddiq, A.; Zikria, Y.B.; Kim, S.W. Energy-Aware Adaptive Trickle Timer Algorithm for RPL-based Routing in the Internet of Things. In Proceedings of the 2018 28th International Telecommunication Networks and Applications Conference (ITNAC), Sydney, NSW, Australia, 21–23 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Khorov, E.; Kiryanov, A.; Lyakhov, A.; Bianchi, G. A Tutorial on IEEE 802.11ax High Efficiency WLANs. IEEE Commun. Surv. Tutorials 2019, 21, 197–216. [Google Scholar] [CrossRef]
- IEEE Std 802.15.4-2020 (Revision of IEEE Std 802.15.4-2015); IEEE Standard for Low-Rate Wireless Networks. IEEE: New York, NY, USA, 2020. [CrossRef]
- Lindelauf, R. Nuclear Deterrence in the Algorithmic Age: Game Theory Revisited. NL ARMS 2021, 2, 421. [Google Scholar]
- Moerland, T.M.; Broekens, J.; Plaat, A.; Jonker, C.M. Model-based reinforcement learning: A survey. Found. Trends Mach. Learn. 2023, 16, 1–118. [Google Scholar] [CrossRef]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Kim, C. Deep reinforcement learning by balancing offline Monte Carlo and online temporal difference use based on environment experiences. Symmetry 2020, 12, 1685. [Google Scholar] [CrossRef]
- Kovári, B.; Hegedüs, F.; Bécsi, T. Design of a reinforcement learning-based lane keeping planning agent for automated vehicles. Appl. Sci. 2020, 10, 7171. [Google Scholar] [CrossRef]
- Mousavi, S.S.; Schukat, M.; Howley, E. Deep reinforcement learning: An overview. In Proceedings of SAI Intelligent Systems Conference (IntelliSys) 2016: Volume 2; Springer: Cham, Switzerland, 2018; pp. 426–440. [Google Scholar]
- Chandak, Y.; Theocharous, G.; Kostas, J.; Jordan, S.; Thomas, P. Learning action representations for reinforcement learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 941–950. [Google Scholar]
- Kanervisto, A.; Scheller, C.; Hautamäki, V. Action space shaping in deep reinforcement learning. In Proceedings of the 2020 IEEE Conference on Games (CoG), Osaka, Japan, 24–27 August 2020; pp. 479–486. [Google Scholar]
- Kumar, A.; Buckley, T.; Lanier, J.B.; Wang, Q.; Kavelaars, A.; Kuzovkin, I. Offworld gym: Open-access physical robotics environment for real-world reinforcement learning benchmark and research. arXiv 2019, arXiv:1910.08639. [Google Scholar]
- Clifton, J.; Laber, E. Q-learning: Theory and applications. Annu. Rev. Stat. Its Appl. 2020, 7, 279–301. [Google Scholar] [CrossRef]
- Jin, Z.; Zhao, Q.; Su, Y. RCAR: A Reinforcement-Learning-Based Routing Protocol for Congestion-Avoided Underwater Acoustic Sensor Networks. IEEE Sensors J. 2019, 19, 10881–10891. [Google Scholar] [CrossRef]
- Di Valerio, V.; Presti, F.L.; Petrioli, C.; Picari, L.; Spaccini, D.; Basagni, S. CARMA: Channel-aware reinforcement learning-based multi-path adaptive routing for underwater wireless sensor networks. IEEE J. Sel. Areas Commun. 2019, 37, 2634–2647. [Google Scholar] [CrossRef]
- Safdar Malik, T.; Razzaq Malik, K.; Afzal, A.; Ibrar, M.; Wang, L.; Song, H.; Shah, N. RL-IoT: Reinforcement Learning-Based Routing Approach for Cognitive Radio-Enabled IoT Communications. IEEE Internet Things J. 2023, 10, 1836–1847. [Google Scholar] [CrossRef]
- Mao, B.; Tang, F.; Fadlullah, Z.M.; Kato, N. An Intelligent Route Computation Approach Based on Real-Time Deep Learning Strategy for Software Defined Communication Systems. IEEE Trans. Emerg. Top. Comput. 2021, 9, 1554–1565. [Google Scholar] [CrossRef]
- Safdar, T.; Hasbulah, H.B.; Rehan, M. Effect of reinforcement learning on routing of cognitive radio ad hoc networks. In Proceedings of the 2015 International Symposium on Mathematical Sciences and Computing Research (iSMSC), Ipoh, Malaysia, 19–20 May 2015; pp. 42–48. [Google Scholar]
- Stampa, G.; Arias, M.; Sánchez-Charles, D.; Muntés-Mulero, V.; Cabellos, A. A deep-reinforcement learning approach for software-defined networking routing optimization. arXiv 2017, arXiv:1709.07080. [Google Scholar]
- Cicioğlu, M.; Çalhan, A. MLaR: Machine-learning-assisted centralized link-state routing in software-defined-based wireless networks. Neural Comput. Appl. 2023, 35, 5409–5420. [Google Scholar] [CrossRef]
- Cheng, S.T.; Chang, T.Y. An Adaptive Learning Scheme for Load Balancing with Zone Partition in Multi-Sink Wireless Sensor Network. Expert Syst. Appl. 2012, 39, 9427–9434. [Google Scholar] [CrossRef]
- Wei, Z.; Zhang, Y.; Xu, X.; Shi, L.; Feng, L. A task scheduling algorithm based on Q-learning and shared value function for WSNs. Comput. Netw. 2017, 126, 141–149. [Google Scholar] [CrossRef]
- Wei, Z.; Liu, F.; Zhang, Y.; Xu, J.; Ji, J.; Lyu, Z. A Q-learning algorithm for task scheduling based on improved SVM in wireless sensor networks. Comput. Netw. 2019, 161, 138–149. [Google Scholar] [CrossRef]
- Ancillotti, E.; Vallati, C.; Bruno, R.; Mingozzi, E. A Reinforcement Learning-Based Link Quality Estimation Strategy for RPL and Its Impact on Topology Management. Comput. Commun. 2017, 112, 1–13. [Google Scholar] [CrossRef]
- Guo, X.; Lin, H.; Li, Z.; Peng, M. Deep-Reinforcement-Learning-Based QoS-Aware Secure Routing for SDN-IoT. IEEE Internet Things J. 2020, 7, 6242–6251. [Google Scholar] [CrossRef]
- Künzel, G.; Indrusiak, L.S.; Pereira, C.E. Latency and Lifetime Enhancements in Industrial Wireless Sensor Networks: A Q-Learning Approach for Graph Routing. IEEE Trans. Ind. Inform. 2020, 16, 5617–5625. [Google Scholar] [CrossRef]
- Jung, W.S.; Yim, J.; Ko, Y.B. QGeo: Q-learning-based geographic ad hoc routing protocol for unmanned robotic networks. IEEE Commun. Lett. 2017, 21, 2258–2261. [Google Scholar] [CrossRef]
- Sharma, V.K.; Shukla, S.S.P.; Singh, V. A tailored Q-Learning for routing in wireless sensor networks. In Proceedings of the 2012 2nd IEEE International Conference on Parallel, Distributed and Grid Computing, Solan, India, 6–8 December 2012; pp. 663–668. [Google Scholar]
- Su, X.; Ren, Y.; Cai, Z.; Liang, Y.; Guo, L. A Q-learning based routing approach for energy efficient information transmission in wireless sensor network. IEEE Trans. Netw. Serv. Manag. 2022, 20, 1949–1961. [Google Scholar] [CrossRef]
- Akbari, Y.; Tabatabaei, S. A new method to find a high reliable route in IoT by using reinforcement learning and fuzzy logic. Wirel. Pers. Commun. 2020, 112, 967–983. [Google Scholar] [CrossRef]
- Liu, Y.; Tong, K.F.; Wong, K.K. Reinforcement learning based routing for energy sensitive wireless mesh IoT networks. Electron. Lett. 2019, 55, 966–968. [Google Scholar] [CrossRef]
- Sharma, D.K.; Rodrigues, J.J.; Vashishth, V.; Khanna, A.; Chhabra, A. RLProph: A dynamic programming based reinforcement learning approach for optimal routing in opportunistic IoT networks. Wirel. Netw. 2020, 26, 4319–4338. [Google Scholar] [CrossRef]
- Chakraborty, I.; Das, P.; Pradhan, B. An Intelligent Routing for Internet of Things Mesh Networks. Trans. Emerg. Telecommun. Technol. 2022, e4628. [Google Scholar] [CrossRef]
- Muthanna, M.S.A.; Muthanna, A.; Rafiq, A.; Hammoudeh, M.; Alkanhel, R.; Lynch, S.; Abd El-Latif, A.A. Deep reinforcement learning based transmission policy enforcement and multi-hop routing in QoS aware LoRa IoT networks. Comput. Commun. 2022, 183, 33–50. [Google Scholar] [CrossRef]
- Kaur, G.; Chanak, P.; Bhattacharya, M. Energy-efficient intelligent routing scheme for IoT-enabled WSNs. IEEE Internet Things J. 2021, 8, 11440–11449. [Google Scholar] [CrossRef]
- Zhang, A.; Sun, M.; Wang, J.; Li, Z.; Cheng, Y.; Wang, C. Deep reinforcement learning-based multi-hop state-aware routing strategy for wireless sensor networks. Appl. Sci. 2021, 11, 4436. [Google Scholar] [CrossRef]
- Krishnan, M.; Lim, Y. Reinforcement learning-based dynamic routing using mobile sink for data collection in WSNs and IoT applications. J. Netw. Comput. Appl. 2021, 194, 103223. [Google Scholar] [CrossRef]
- Serhani, A.; Naja, N.; Jamali, A. AQ-Routing: Mobility-, stability-aware adaptive routing protocol for data routing in MANET–IoT systems. Clust. Comput. 2020, 23, 13–27. [Google Scholar] [CrossRef]
- Pandey, O.J.; Yuvaraj, T.; Paul, J.K.; Nguyen, H.H.; Gundepudi, K.; Shukla, M.K. Improving energy efficiency and QoS of LPWANs for IoT using Q-learning based data routing. IEEE Trans. Cogn. Commun. Netw. 2021, 8, 365–379. [Google Scholar] [CrossRef]
- Ren, J.; Zheng, J.; Guo, X.; Song, T.; Wang, X.; Wang, S.; Zhang, W. MeFi: Mean Field Reinforcement Learning for Cooperative Routing in Wireless Sensor Network. IEEE Internet Things J. 2023, 1. [Google Scholar] [CrossRef]
- Nazari, A.; Kordabadi, M.; Mohammadi, R.; Lal, C. EQRSRL: An energy-aware and QoS-based routing schema using reinforcement learning in IoMT. Wireless Netw. 2023, 29, 3239–3253. [Google Scholar] [CrossRef]
- De Couto, D.S.; Aguayo, D.; Bicket, J.; Morris, R. A high-throughput path metric for multi-hop wireless routing. In Proceedings of the 9th Annual International Conference on Mobile Computing and Networking, San Diego, CA, USA, 14–19 September 2003; pp. 134–146. [Google Scholar]
- Botvinick, M.; Ritter, S.; Wang, J.X.; Kurth-Nelson, Z.; Blundell, C.; Hassabis, D. Reinforcement learning, fast and slow. Trends Cogn. Sci. 2019, 23, 408–422. [Google Scholar] [CrossRef]
- Clavera, I.; Nagabandi, A.; Fearing, R.S.; Abbeel, P.; Levine, S.; Finn, C. Learning to adapt: Meta-learning for model-based control. arXiv 2018, arXiv:1803.11347. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Parameters | Labels |
|---|---|
| t | Time step t |
| State of the agent at t | |
| Action of the agent at t | |
| Reward of the agent at t | |
| A | Action space |
| S | State space |
| R | Cumulative reward or return |
| Policy | |
| Discount factor | |
| Learning rate |
| Reference | Year | Contribution | Application Domain | Algorithm Model |
|---|---|---|---|---|
| Jin et al. [60] | 2019 | The authors of this paper propose RL-based congestion-avoided routing for underwater acoustic sensor networks to reduce end-to-end delay and energy consumption. | Underwater acoustic sensor networks—RCAR | Q-learning |
| Di Valerio et al. [61] | 2019 | In this paper, the authors propose an RL-based data forwarding scheme for a node based on the number of unsuccessful transmissions. The node adaptively switches between single-path and multi-path routing to optimize energy consumption and the packet delivery ratio. | Underwater WSN—CARMA | Q-learning |
| Safdar Malik et al. [62] | 2023 | This paper presents a routing approach based on RL for CRs. The idea of this study is to add the channel selection decision capability to provide improvements in the average data rate and throughput. | CRs—RL-IoT | Q-learning |
| Mao et al. [63] | 2019 | In this paper, the authors propose a CNN-based scheme that continuously adapts and optimizes routing decisions based on network conditions. This approach computes the routing path combinations with high accuracy. | SDNs | CNN |
| Safdar et al. [64] | 2015 | The authors of this paper propose RL-based routing in CR ad hoc networks to reduce the protocol overhead and end-to-end delay and improve the packet delivery ratio. | CRs ad hoc networks—CRAHN | Q-learning |
| Stampa et al. [65] | 2017 | This paper proposes a DRL approach for optimizing routing in SDNs. The agent in this approach optimizes the routing policy based on traffic conditions to minimize network delays. | SDN | DQL |
| Cicioğlu et al. [66] | 2023 | The authors of this paper proposed an ML-assisted centralized link-state routing system for an SDN-based network. This scheme utilizes historical data of parameters such as the latency, bandwidth, signal-to-noise ratio, and distance to make routing decisions. | SDN—MLaR | Supervised learning |
| Cheng et al. [67] | 2012 | In this paper, the authors proposed load balancing in a multi-sink WSN. This approach divides the network into several zones based on the remaining energy of hotspots around the sink node. ML is applied to the mobile anchor, enabling it to adapt to traffic patterns and discover an optimal control policy for its movement. | WSNs—QAZP | Q-learning |
| Wei et al. [68] | 2017 | In this approach, the authors present a task scheduling algorithm for dynamic WSNs that minimizes the exchange of cooperative information and balances resource utilization. | WSNs—QS | Q-learning with shared value function |
| Wei et al. [69] | 2019 | In this paper, the authors introduce a Q-learning algorithm for task scheduling in WSNs based on support vector machine. Their proposed approach optimizes the application performance and reduces energy consumption. | WSNs—ISVM-Q | Q-learning and support vector machine |
| Ancillotti et al. [70] | 2017 | This paper proposes a link quality monitoring strategy for the RPL in IPv6-WSN using a multi-armed bandit algorithm. The proposed approach minimizes overhead and energy consumption by employing both synchronous and asynchronous monitoring. | WSNs—RL-Probe | Multi-armed bandit |
| Guo et al. [71] | 2020 | The authors of this paper propose a DRL-based QoS-aware secure routing protocol for the SDN-IoT. The primary objective is to design a routing protocol that efficiently routes traffic in a large-scale SDN. | SDN—DQSP | DQL |
| Künzel et al. [72] | 2020 | This paper introduces a Q-learning approach in which an agent adjusts weight values in an industrial WSN, leading to improved communication reliability and reduced network latency. | Industrial WSN—QLRR-WA | Q-learning |
| Jung et al. [73] | 2017 | In this paper, the authors introduce Q-learning-based geographic routing to enhance the performance of unmanned robotic networks and address the challenge of network overhead in high-mobility scenarios. | Unmanned robotic networks—QGeo | Q-learning |
| Sharma et al. [74] | 2017 | The authors of this paper introduce a tailored Q-learning algorithm for routing in WSNs with a focus on minimizing energy consumption, addressing the challenge of reliance on non-renewable energy sources. | WSNs | Tailored Q-learning |
| Su et al. [75] | 2022 | This paper presents an approach to enhance energy efficiency and prolong network lifetime using Q-learning-based routing for WSNs. It allows nodes to select neighboring nodes for transmission by considering various energy consumption factors, resulting in a reduced and balanced energy usage. | WSNs | Q-learning |
| Akbari et al. [76] | 2020 | This paper addresses the need for efficient routing structures in sensor networks to optimize their lifetime and reduce energy consumption. The paper combines fuzzy logic and RL, utilizing factors such as the remaining node energy, available bandwidth, and distance to the sink for routing decisions. | WSNs | RL with fuzzy logic |
| Liu et al. [77] | 2019 | The authors of this paper address the importance of connectivity solutions for wide-area applications in IoT networks. The proposed technique uses a distributed and energy-efficient RL-based routing algorithm for wide-area scenarios. | Wireless mesh IoT networks | Temporal difference |
| Sharma et al. [78] | 2020 | In this paper, the authors propose routing in opportunistic IoT networks using the Policy Iteration algorithm to automate routing and enhance message delivery possibilities. | IoT networks—RLProph | Policy Iteration algorithm |
| Chakraborty et al. [79] | 2022 | In this paper, the authors proposed a routing algorithm that adjusts its routing policy based on local information, aiming to find an optimal solution that balances the network latency and lifetime in wireless mesh IoT networks. | Wireless mesh IoT networks | Q-learning |
| Muthanna et al. [80] | 2022 | This paper presents a system that optimizes transmission policy parameters and implements multi-hop routing for a high QoS in LoRa networks. | LoRa IoT networks—MQ-LoRa | Soft actor-critic |
| Kaur et al. [81] | 2021 | The authors of this paper proposed an algorithm that divides the network into clusters based on sensor node data loads, preventing premature network failure. This paper addresses issues such as high communication delays, low throughputs, and poor network lifetimes. | IoT-enabled WSNs | DQL |
| Zhang et al. [82] | 2021 | The authors of this paper use recurrent neural networks and the deep deterministic policy gradient method to predict the network traffic distribution. They employ a double deep Q-network to make routing decisions based on the current network state. | IoT-enabled WSNs | RNN and the deep deterministic policy gradient |
| Krishnan et al. [83] | 2021 | This paper focuses on addressing the challenge of maximizing the network lifetime in WSNs. Q-learning is employed to facilitate automatic learning to find the shortest routes. | IoT-enabled WSNs | Q-learning |
| Serhani et al. [84] | 2020 | This paper explores the challenges of integrating MANETs with the IoT and focuses on the issue of network node mobility. The authors introduce an adaptive routing protocol that enhances link stability in both static and mobile scenarios. | MANETs-IoT systems—AQ-Routing | Q-learning |
| Pandey et al. [85] | 2022 | In this paper, the authors address the challenge of establishing large-scale connectivity among IoT devices. They introduce a multi-hop data routing approach utilizing the Q-learning method. | Low-power wide-area networks for IoT | Q-learning |
| Ren et al. [86] | 2023 | In this paper, the authors address the challenges of energy efficiency and network lifetime using the mean field RL method. Mean field theory simplifies interactions among nodes, and a prioritized sampling, loop-free algorithm prevents routing loops. | IoT-enabled WSNs | Mean field RL |
| Serhani et al. [87] | 2023 | In this paper, the authors introduce an efficient routing mechanism for the Internet of Medical Things. The proposed technique categorizes network traffic into three classes, optimizes paths based on QoS and energy metrics, and employs RL for path computation. | Internet of Medical Things—EQRSRL | Q-learning |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Musaddiq, A.; Olsson, T.; Ahlgren, F. Reinforcement-Learning-Based Routing and Resource Management for Internet of Things Environments: Theoretical Perspective and Challenges. Sensors 2023, 23, 8263. https://doi.org/10.3390/s23198263
Musaddiq A, Olsson T, Ahlgren F. Reinforcement-Learning-Based Routing and Resource Management for Internet of Things Environments: Theoretical Perspective and Challenges. Sensors. 2023; 23(19):8263. https://doi.org/10.3390/s23198263
Chicago/Turabian StyleMusaddiq, Arslan, Tobias Olsson, and Fredrik Ahlgren. 2023. "Reinforcement-Learning-Based Routing and Resource Management for Internet of Things Environments: Theoretical Perspective and Challenges" Sensors 23, no. 19: 8263. https://doi.org/10.3390/s23198263