
Foreground Segmentation-Based Density Grading Networks for Crowd Counting

Abstract
:1. Introduction
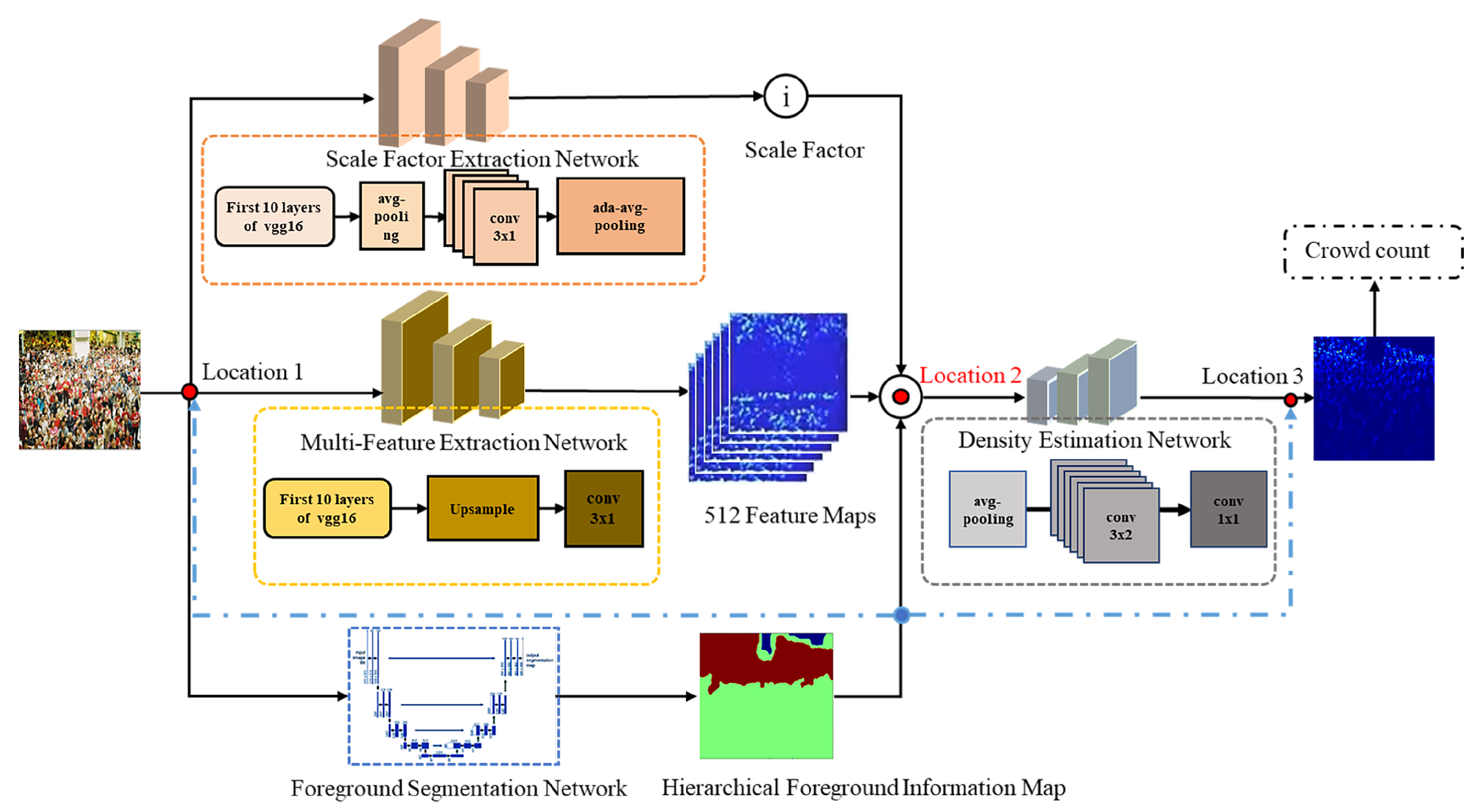
- This paper proposes a novel architecture for crowd density estimation. To achieve accurate results, the model employs a three-branch structure that integrates foreground segmentation with density prediction and adjusts the global density using a scale factor, which evaluates the crowd density level in the original image.
- This article utilizes image segmentation techniques for crowd counting. Specifically, the image undergoes segmentation into three distinct categories: background, regions with low crowd density, and regions with high crowd density. This segmentation approach provides hierarchical foreground information that effectively guides the network in distinguishing areas with varying levels of crowd density.
- In this paper, we investigate and compare three distinct locations for the integration of hierarchical foreground information. Finally, we identify the hierarchical foreground information fusion location that yields the highest performance.
2. Related Work
2.1. Density Map-Based Methods
2.2. Image Segmentation-Based Methods
3. Our Method
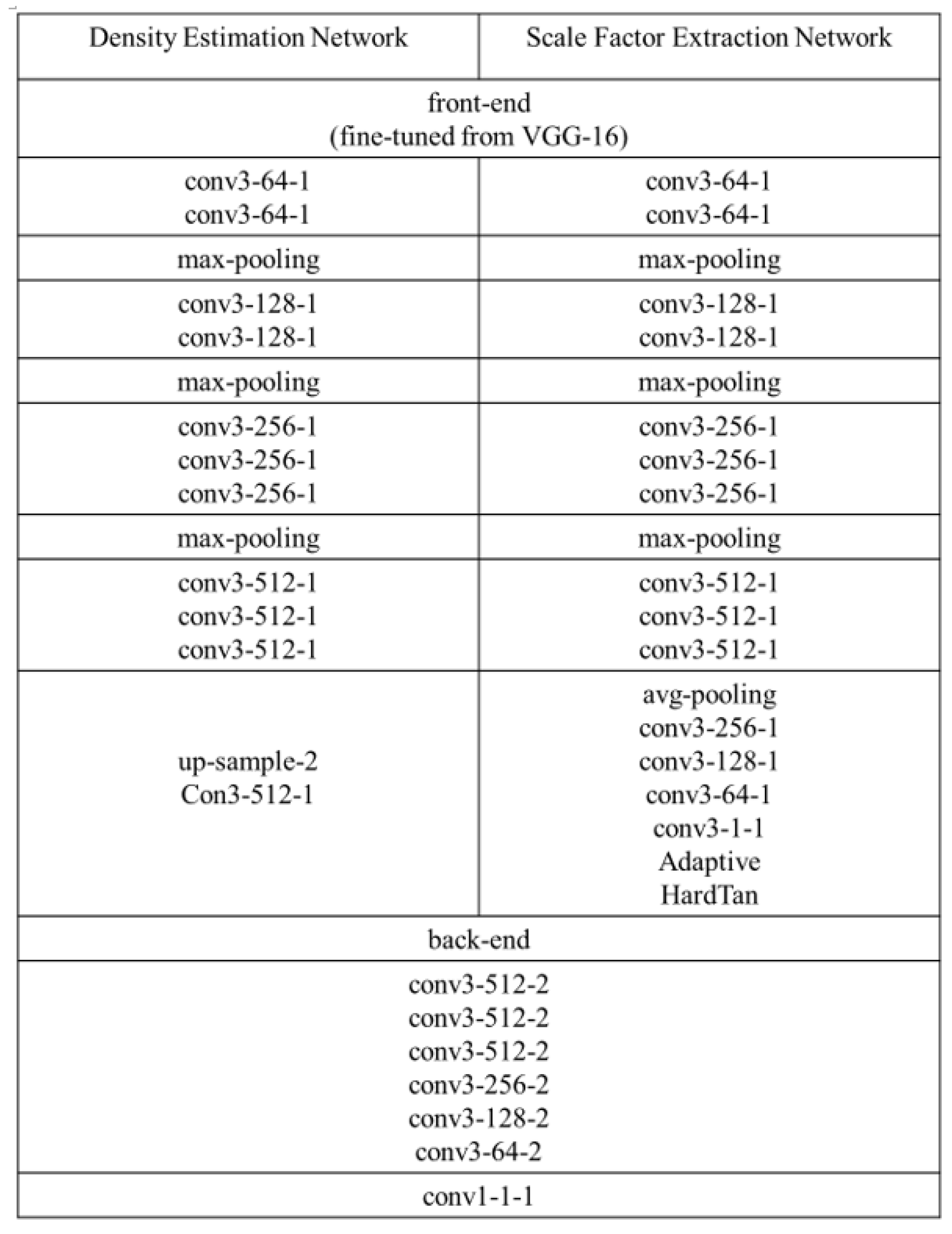
3.1. Density Map Generation Network
3.2. Scale Factor Extraction Network
3.3. Generation of Ground Truth and Foreground Segmentation Network
3.3.1. Generation of Density Map
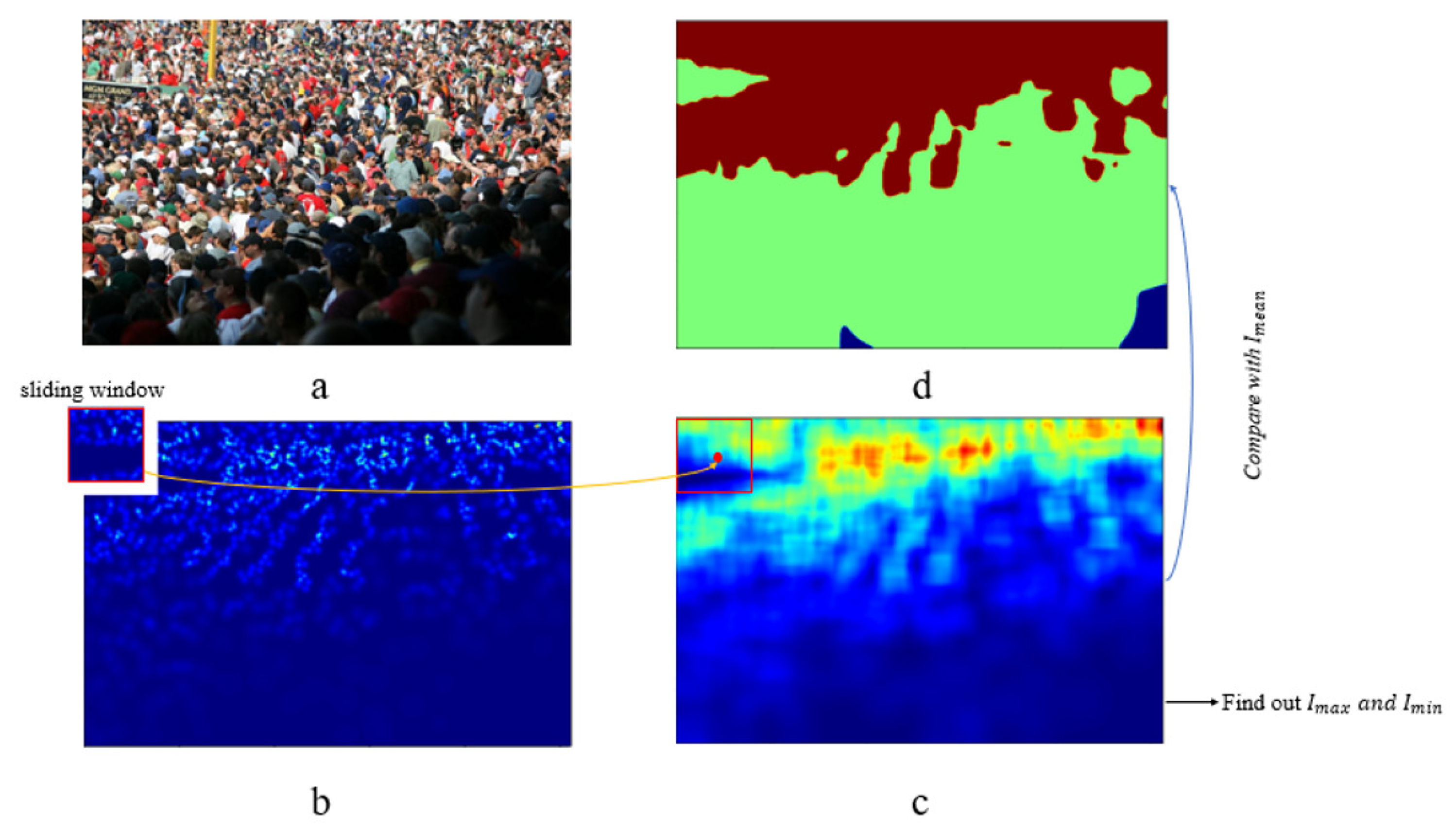
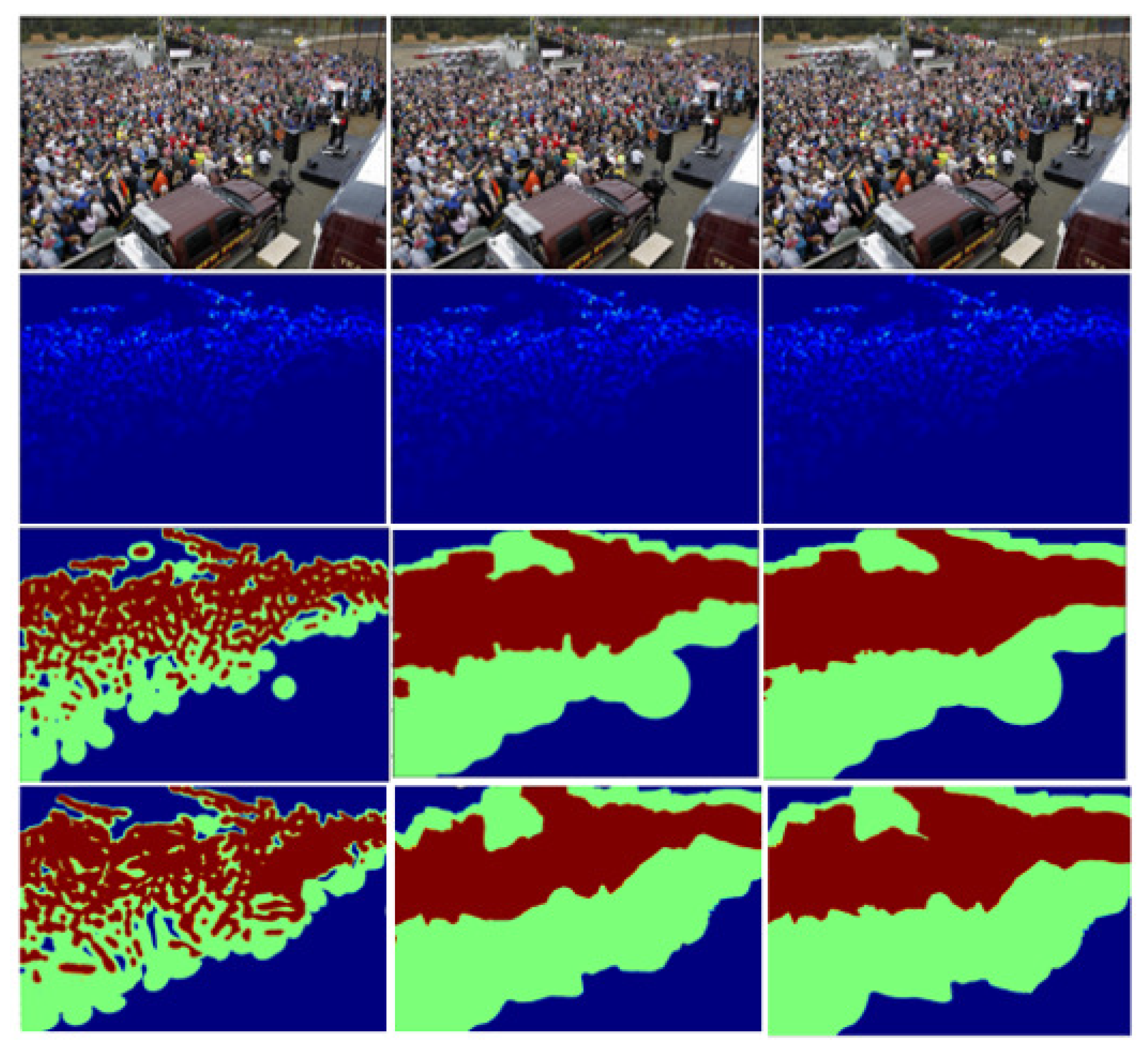
3.3.2. Generation of Hierarchical Foreground Information Map
3.3.3. Foreground Segmentation Network
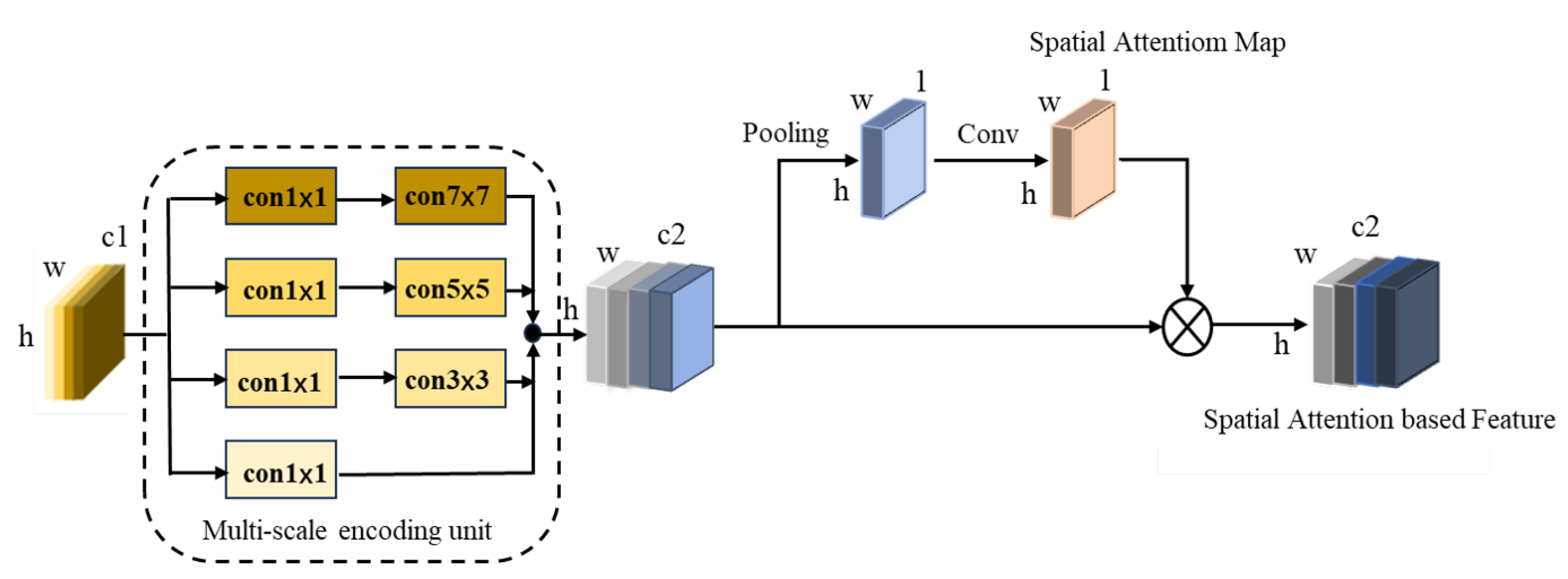
3.4. Multi-Scale Feature Extraction Module
4. Experiments
4.1. Dataset
- UCF_CC_50 is the first challenging dataset created from publicly available web images. It contains various densities and different perspective distortions in various scenes, including concerts, protests, stadiums, and marathons. Given the dataset’s size of only 50 images, it is typically processed with five-fold data partitioning before training and further processed with cross-validation during training. The limited dataset size often leads to suboptimal results, even with state-of-the-art CNN-based methods.
- WorldExpo’10 is a large-scale, data-driven, cross-scenario crowd-counting dataset collected from the 2010 Shanghai World Expo. It comprises 1132 annotated video sequences captured by 108 surveillance cameras. The dataset contains a total of 3920 frames with a size of 576 × 720 pixels, encompassing scenes both indoors and outdoors, and includes annotations for 199,923 people.
- ShanghaiTech is one of the largest crowd-counting datasets to emerge in recent years, comprising 1198 images and 330,165 annotations. The dataset is divided into two parts, A and B, based on differing density distributions. Part A consists of pictures randomly selected from the Internet, while those in part B are captured on a busy street in downtown Shanghai, featuring lower image density. Notably, the scale changes and perspective distortions within this dataset introduce new challenges and opportunities for many CNN-based network designs.
4.2. Experimental Details
4.3. Evaluation Metrics
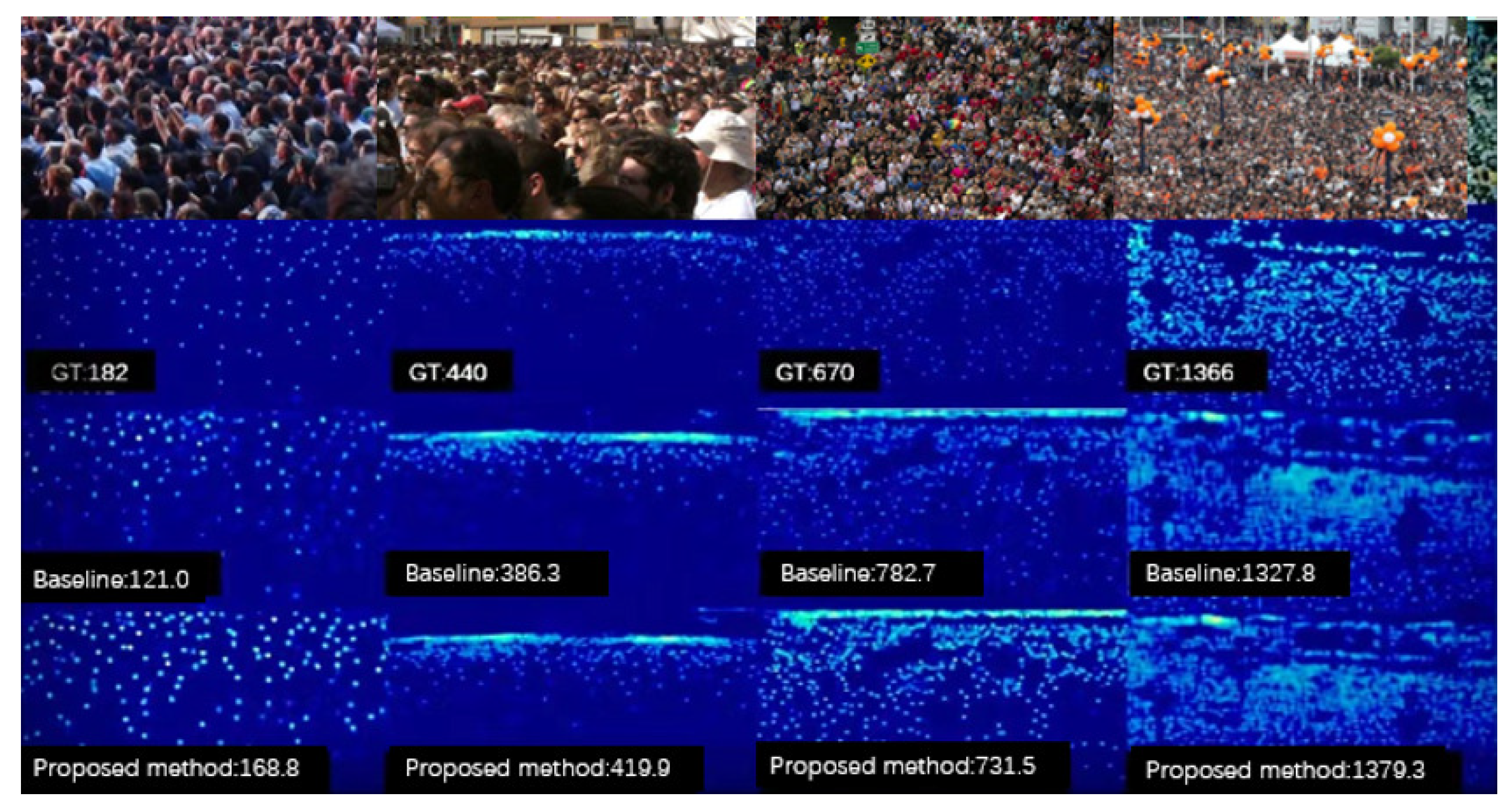
4.4. Comparison with Other Methods
4.5. Ablation Experiment
4.5.1. Study on Sliding Window Sizes
4.5.2. Study on the Location of Hierarchical Foreground Information Fusion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ammar, A.; Koubaa, A.; Ahmed, M.; Saad, A.; Benjdira, B. Vehicle Detection from Aerial Images Using Deep Learning: A Comparative Study. Electronics 2021, 10, 820. [Google Scholar] [CrossRef]
- Zhang, H.; Kyaw, Z.; Chang, S.F.; Chua, T.S. Visual translation embedding network for visual relation detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5532–5540. [Google Scholar]
- Norouzzadeh, M.S.; Nguyen, A.; Kosmala, M.; Swanson, A.; Palmer, M.S.; Packer, C.; Clune, J. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc. Natl. Acad. Sci. USA 2018, 115, E5716–E5725. [Google Scholar] [CrossRef] [PubMed]
- Arteta, C.; Lempitsky, V.; Zisserman, A. Counting in the wild. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–498. [Google Scholar]
- Moradi Rad, R.; Saeedi, P.; Au, J.; Havelock, J. Cell-Net: Embryonic Cell Counting and Centroid Localization via Residual Incremental Atrous Pyramid and Progressive Upsampling Convolution. IEEE Access 2019, 7, 81945–81955. [Google Scholar] [CrossRef]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Zhang, Z.; Huang, K.; Tan, T. Estimating the number of people in crowded scenes by MID based foreground segmentation and head-shoulder detection. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Tuzel, O.; Porikli, F.; Meer, P. Pedestrian Detection via Classification on Riemannian Manifolds. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1713–1727. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature mining for localised crowd counting. In Proceedings of the BMVC, Surrey, UK, 3–7 September 2012; Volume 1, p. 3. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source Multi-scale Counting in Extremely Dense Crowd Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Rodriguez, M.; Laptev, I.; Sivic, J.; Audibert, J.Y. Density-aware person detection and tracking in crowds. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2423–2430. [Google Scholar] [CrossRef]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar] [CrossRef]
- Yang, B.; Cao, J.; Wang, N.; Zhang, Y.; Zou, L. Counting challenging crowds robustly using a multi-column multi-task convolutional neural network. Signal Process. Image Commun. 2018, 64, 118–129. [Google Scholar] [CrossRef]
- Subburaman, V.B.; Descamps, A.; Carincotte, C. Counting People in the Crowd Using a Generic Head Detector. In Proceedings of the 2012 IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance, Beijing, China, 18–21 September 2012; pp. 470–475. [Google Scholar] [CrossRef]
- Viola; Jones; Snow. Detecting pedestrians using patterns of motion and appearance. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 2, pp. 734–741. [Google Scholar] [CrossRef]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar] [CrossRef]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching Convolutional Neural Network for Crowd Counting. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4031–4039. [Google Scholar] [CrossRef]
- Shen, Z.; Xu, Y.; Ni, B.; Wang, M.; Hu, J.; Yang, X. Crowd Counting via Adversarial Cross-Scale Consistency Pursuit. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5245–5254. [Google Scholar] [CrossRef]
- Ma, J.; Dai, Y.; Tan, Y.P. Atrous convolutions spatial pyramid network for crowd counting and density estimation. Neurocomputing 2019, 350, 91–101. [Google Scholar] [CrossRef]
- Pham, V.Q.; Kozakaya, T.; Yamaguchi, O.; Okada, R. COUNT Forest: CO-Voting Uncertain Number of Targets Using Random Forest for Crowd Density Estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Wang, C.; Zhang, H.; Yang, L.; Liu, S.; Cao, X. Deep People Counting in Extremely Dense Crowds. In Proceedings of the 23rd ACM International Conference on Multimedia (MM ’15), New York, NY, USA, 26–30 October 2015; pp. 1299–1302. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. Generating High-Quality Crowd Density Maps Using Contextual Pyramid CNNs. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Xu, C.; Qiu, K.; Fu, J.; Bai, S.; Xu, Y.; Bai, X. Learn to scale: Generating multipolar normalized density maps for crowd counting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 8382–8390. [Google Scholar]
- Zhou, J.T.; Zhang, L.; Jiawei, D.; Peng, X.; Fang, Z.; Xiao, Z.; Zhu, H. Locality-aware crowd counting. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3602–3613. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Zhang, L.; Xu, M.; Zhang, T.; Lv, P.; Zhou, B.; Yang, X.; Pang, Y. Attention Scaling for Crowd Counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ma, Z.; Wei, X.; Hong, X.; Gong, Y. Bayesian loss for crowd count estimation with point supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 6142–6151. [Google Scholar]
- Wan, J.; Liu, Z.; Chan, A.B. A Generalized Loss Function for Crowd Counting and Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1974–1983. [Google Scholar]
- Geng, Q.; Liang, D.; Zhou, H.; Zhang, L.; Sun, H.; Liu, N. Dense Face Detection via High-level Context Mining. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Liu, X.; Yang, J.; Ding, W.; Wang, T.; Wang, Z.; Xiong, J. Adaptive mixture regression network with local counting map for crowd counting. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 241–257. [Google Scholar]
- Zhang, Y.; Zhao, H.; Duan, Z.; Huang, L.; Deng, J.; Zhang, Q. Congested Crowd Counting via Adaptive Multi-Scale Context Learning. Sensors 2021, 21, 3777. [Google Scholar] [CrossRef] [PubMed]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. UNETR: Transformers for 3D Medical Image Segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar]
- Hossain, M.; Hosseinzadeh, M.; Chanda, O.; Wang, Y. Crowd Counting Using Scale-Aware Attention Networks. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1280–1288. [Google Scholar] [CrossRef]
- Jiang, S.; Lu, X.; Lei, Y.; Liu, L. Mask-aware networks for crowd counting. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3119–3129. [Google Scholar] [CrossRef]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale Aggregation Network for Accurate and Efficient Crowd Counting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Jiang, X.; Xiao, Z.; Zhang, B.; Zhen, X.; Cao, X.; Doermann, D.; Shao, L. Crowd counting and density estimation by trellis encoder-decoder networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6133–6142. [Google Scholar]
- Liu, L.; Jiang, J.; Jia, W.; Amirgholipour, S.; Wang, Y.; Zeibots, M.; He, X. Denet: A universal network for counting crowd with varying densities and scales. IEEE Trans. Multimed. 2020, 23, 1060–1068. [Google Scholar] [CrossRef]
- Wan, J.; Wang, Q.; Chan, A.B. Kernel-Based Density Map Generation for Dense Object Counting. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1357–1370. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SHTech Part A | SHTech Part B | UCF_CC_50 | WorldExpo10 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | MAE | MSE | MAE | MSE | MAE | MSE | S1 | S2 | S3 | S4 | S5 | avg |
| MCNN [13] | 110.2 | 173.2 | 26.4 | 41.3 | 377.6 | 509.1 | 3.4 | 20.6 | 12.9 | 13 | 8.1 | 11.6 |
| CPCNN [23] | 73.6 | 110.2 | 20.1 | 30.1 | 295.8 | 320.9 | 2.9 | 14.7 | 10.5 | 10.9 | 5 | 8.8 |
| CSRNET [24] | 68.2 | 115 | 10.6 | 16.8 | 266.1 | 397.5 | 2.9 | 11.5 | 8.6 | 16.6 | 3.4 | 8.6 |
| MANET [35] | 66.3 | 109.4 | 16.9 | 28.4 | 283.3 | 411.6 | 3 | 16.7 | 11.6 | 12.5 | 4.1 | 9.6 |
| SANet [36] | 67 | 104.5 | 8.4 | 13.6 | 258.4 | 334.6 | 2.6 | 13.2 | 9.0 | 13.3 | 3.0 | 8.2 |
| TEDNET [37] | 64.2 | 109.1 | 8.2 | 12.7 | 249.4 | 354.6 | 2.3 | 10.1 | 11.3 | 13.8 | 2.6 | 8.0 |
| DENET [38] | 65.9 | 105.4 | 9.8 | 15.4 | 247.3 | 350.6 | 3.1 | 10.7 | 8.6 | 15.2 | 3.5 | 8.2 |
| KDMG [39] | 63.8 | 99.3 | 7.8 | 12.7 | 241.3 | 351.6 | 3.0 | 9.1 | 8.6 | 11.2 | 3.1 | 7.0 |
| Ours | 63.8 | 104.6 | 9.6 | 13.7 | 246.6 | 356.1 | 3.3 | 9.8 | 9.1 | 12.7 | 3.2 | 7.6 |
| Ours_M | 61.9 | 103.8 | 9.0 | 12.3 | 240.1 | 351.1 | 3.1 | 10.7 | 8.9 | 12.1 | 3.1 | 7.6 |
| Window Size | Without | 48 | 64 | 80 |
|---|---|---|---|---|
| MAE (SHTech PartA) | 68.2 | 66.1 | 63.8 | 65.9 |
| MSE (SHTech PartA) | 115.3 | 107.6 | 104.6 | 109.4 |
| MAE (SHTech PartB) | 10.6 | 10.8 | 9.6 | 10.7 |
| MSE (SHTech PartB) | 16.8 | 14.0 | 13.7 | 15.9 |
| Fusing Location | Without | Location 1 | Location 2 | Location 3 |
|---|---|---|---|---|
| MAE (SHTech PartA) | 68.2 | 66.1 | 63.8 | 66.6 |
| MSE (SHTech PartA) | 115.3 | 108.4 | 104.6 | 109.8 |
| MAE (SHTech PartB) | 10.6 | 10.8 | 9.6 | 10.7 |
| MSE (SHTech PartB) | 16.8 | 13.5 | 13.7 | 14.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Zhou, X.; Zhou, T.; Chen, Y. Foreground Segmentation-Based Density Grading Networks for Crowd Counting. Sensors 2023, 23, 8177. https://doi.org/10.3390/s23198177
Liu Z, Zhou X, Zhou T, Chen Y. Foreground Segmentation-Based Density Grading Networks for Crowd Counting. Sensors. 2023; 23(19):8177. https://doi.org/10.3390/s23198177
Chicago/Turabian StyleLiu, Zelong, Xin Zhou, Tao Zhou, and Yuanyuan Chen. 2023. "Foreground Segmentation-Based Density Grading Networks for Crowd Counting" Sensors 23, no. 19: 8177. https://doi.org/10.3390/s23198177