
Dataset Condensation via Expert Subspace Projection

Abstract
:1. Introduction
2. Related Work
2.1. Dataset Condensation
2.2. Subspace Training
2.3. Coreset Selection
3. Method
3.1. Preliminaries
3.2. Expert Subspace Projection
3.3. Inner Optimization
3.4. Outer Optimization
3.5. Memory Consumption
| Algorithm 1: Expert Subspace Projection |
 |
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Comparison with State-of-the-Art Methods
4.4. Cross-Architecture Generalization
4.5. Memory Analysis
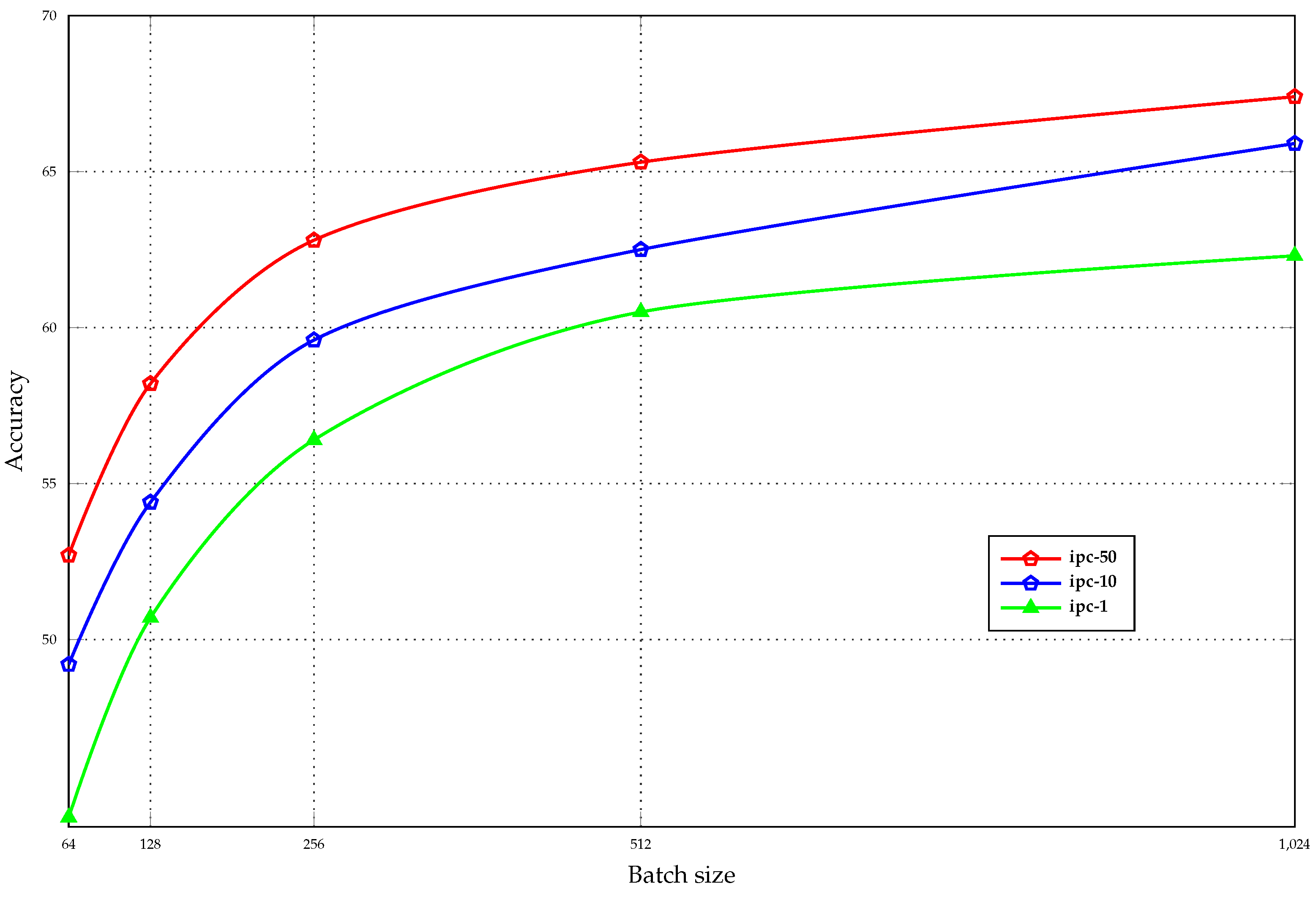
4.6. Synthetic Batch Size Analysis
4.7. Ablation Study
5. Conclusions
6. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, H.B.; Lee, D.B.; Hwang, S.J. Dataset Condensation with Latent Space Knowledge Factorization and Sharing. arXiv 2022, arXiv:2208.10494. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Annu. Conf. Neural Inf. Process. Syst. (NeurIPS) 2020, 33, 1877–1901. [Google Scholar]
- Cui, J.; Wang, R.; Si, S.; Hsieh, C.J. DC-BENCH: Dataset condensation benchmark. Adv. Neural Inf. Process. Syst. 2022, 35, 810–822. [Google Scholar]
- Wang, T.; Zhu, J.Y.; Torralba, A.; Efros, A.A. Dataset distillation. arXiv 2018, arXiv:1811.10959. [Google Scholar]
- Zhao, B.; Bilen, H. Dataset Condensation with Distribution Matching. arXiv 2021, arXiv:2110.04181. [Google Scholar]
- Zhao, B.; Mopuri, K.R.; Bilen, H. Dataset Condensation with Gradient Matching. Int. Conf. Learn. Represent. (ICLR) 2021, 1, 3. [Google Scholar]
- Zhao, B.; Bilen, H. Dataset condensation with differentiable siamese augmentation. In Proceedings of the International Conference on Machine Learning (ICML), PMLR, Virtual Event, 18–24 July 2021; pp. 12674–12685. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning (ICML), PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Cazenavette, G.; Wang, T.; Torralba, A.; Efros, A.A.; Zhu, J.Y. Dataset distillation by matching training trajectories. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4750–4759. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Turc, I.; Chang, M.W.; Lee, K.; Toutanova, K. Well-read students learn better: On the importance of pre-training compact models. arXiv 2019, arXiv:1908.08962. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. Tinybert: Distilling bert for natural language understanding. arXiv 2019, arXiv:1909.10351. [Google Scholar]
- Gur-Ari, G.; Roberts, D.A.; Dyer, E. Gradient descent happens in a tiny subspace. arXiv 2018, arXiv:1812.04754. [Google Scholar]
- Li, C.; Farkhoor, H.; Liu, R.; Yosinski, J. Measuring the intrinsic dimension of objective landscapes. arXiv 2018, arXiv:1804.08838. [Google Scholar]
- Gressmann, F.; Eaton-Rosen, Z.; Luschi, C. Improving neural network training in low dimensional random bases. Annu. Conf. Neural Inf. Process. Syst. (NeurIPS) 2020, 33, 12140–12150. [Google Scholar]
- Li, T.; Tan, L.; Tao, Q.; Liu, Y.; Huang, X. Low dimensional landscape hypothesis is true: DNNs can be trained in tiny subspaces. arXiv 2021, arXiv:2103.11154. [Google Scholar]
- Bachem, O.; Lucic, M.; Krause, A. Practical coreset constructions for machine learning. arXiv 2017, arXiv:1703.06476. [Google Scholar]
- Borsos, Z.; Mutny, M.; Krause, A. Coresets via bilevel optimization for continual learning and streaming. Annu. Conf. Neural Inf. Process. Syst. (NeurIPS) 2020, 33, 14879–14890. [Google Scholar]
- Har-Peled, S.; Kushal, A. Smaller coresets for k-median and k-means clustering. In Proceedings of the Twenty-First Annual Symposium on Computational Geometry, Pisa, Italy, 6–8 June 2005; pp. 126–134. [Google Scholar]
- Sener, O.; Savarese, S. Active learning for convolutional neural networks: A core-set approach. arXiv 2017, arXiv:1708.00489. [Google Scholar]
- Tsang, I.W.; Kwok, J.T.; Cheung, P.M.; Cristianini, N. Core vector machines: Fast SVM training on very large data sets. J. Mach. Learn. Res. JMRL 2005, 6, 363–392. [Google Scholar]
- Krizhevsky, A.; Vinod, N.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Technical Report. University of Toronto. 2009. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 11 August 2023).
- Le, Y.; Yang, X. Tiny imagenet visual recognition challenge. CS 231N 2015, 7, 3. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 16–17 December 2011. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Chen, Y.; Welling, M.; Smola, A. Super-samples from kernel herding. arXiv 2012, arXiv:1203.3472. [Google Scholar]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2001–2010. [Google Scholar]
- Belouadah, E.; Popescu, A. Scail: Classifier weights scaling for class incremental learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1266–1275. [Google Scholar]
- Castro, F.M.; Marín-Jiménez, M.J.; Guil, N.; Schmid, C.; Alahari, K. End-to-end incremental learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 233–248. [Google Scholar]
- Nguyen, T.; Novak, R.; Xiao, L.; Lee, J. Dataset distillation with infinitely wide convolutional networks. Annu. Conf. Neural Inf. Process. Syst. (NeurIPS) 2021, 34, 5186–5198. [Google Scholar]
- Wang, K.; Zhao, B.; Peng, X.; Zhu, Z.; Yang, S.; Wang, S.; Huang, G.; Bilen, H.; Wang, X.; You, Y. Cafe: Learning to condense dataset by aligning features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12196–12205. [Google Scholar]
- Kim, J.H.; Kim, J.; Oh, S.J.; Yun, S.; Song, H.; Jeong, J.; Ha, J.W.; Song, H.O. Dataset Condensation via Efficient Synthetic-Data Parameterization. arXiv 2022, arXiv:2205.14959. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 10096–10106. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | SVHN | CIFAR10 | CIFAR100 | TinyImageNet | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | Accuracy (%) | Accuracy (%) | Accuracy (%) | Accuracy (%) | ||||||
| Images/Class | 1 | 10 | 50 | 1 | 10 | 50 | 1 | 10 | 1 | 10 |
| Param./Class | 3072 | 30,720 | 153,600 | 3072 | 30,720 | 153,600 | 3072 | 30,720 | 12,288 | 122,880 |
| Random | 14.6±1.6 | 35.1±4.1 | 70.9±0.9 | 14.4±2.0 | 26.0±1.2 | 43.4±1.0 | 4.2±0.3 | 14.6±0.5 | 1.4±0.1 | 5.0±0.2 |
| Herding | 20.9±1.3 | 50.5±3.3 | 72.6±0.8 | 21.5±1.2 | 31.6±0.7 | 40.4±0.6 | 8.4±0.3 | 17.3±0.3 | 2.8±0.2 | 6.3±0.2 |
| DC [6] | 31.2±1.4 | 76.1±0.6 | 82.3±0.3 | 28.3±0.5 | 44.9±0.5 | 53.9±0.5 | 12.8±0.3 | 25.2±0.3 | - | - |
| DSA [7] | 27.5±1.4 | 79.2±0.5 | 84.4±0.4 | 28.8±0.7 | 52.1±0.5 | 60.6±0.5 | 13.9±0.3 | 32.3±0.3 | - | - |
| DM [5] | 20.3±2.1 | 73.5±1.0 | 84.2±0.0 | 26.0±0.8 | 48.9±0.6 | 63.0±0.4 | 11.4±0.3 | 29.7±0.3 | 3.9±0.2 | 12.9±0.4 |
| KIP to NN [36] | 57.3±0.1 | 75.0±0.1 | 80.5±0.1 | 49.9±0.2 | 62.7±0.3 | 68.6±0.2 | 15.7±0.2 | 28.3±0.1 | - | - |
| CAFE + DSA [37] | 42.9±3.0 | 77.9±0.6 | 82.3±0.4 | 31.6±0.8 | 50.9±0.5 | 62.3±0.4 | 14.0±0.3 | 31.5±0.2 | - | - |
| Traj. Matching [10] | - | - | - | 46.3±0.8 | 65.3±0.7 | 71.6±0.2 | 24.3±0.3 | 40.1±0.4 | 8.8±0.3 | 23.2±0.2 |
| IDC [38] | 68.1±0.1 | 87.3±0.2 | 90.2±0.1 | 50.0±0.4 | 67.5±0.5 | 74.5±0.1 | - | 44.8±0.2 | - | - |
| KFS [1] | 82.9±0.4 | 91.4±0.2 | 92.2±0.1 | 59.8±0.5 | 72.0±0.3 | 75.0±0.2 | 40.0±0.5 | 50.6±0.2 | 22.7±0.2 | 27.8±0.2 |
| ESP (ours) | 84.8±0.3 | 91.6±0.1 | 92.8±0.1 | 63.0±0.4 | 73.8±0.2 | 76.1±0.3 | 41.1±0.3 | 48.0±0.1 | 24.9±0.3 | 26.6±0.5 |
| Full dataset | 95.4±0.1 | 84.8±0.1 | 56.2±0.3 | 37.6±0.4 | ||||||
| Dataset | Images/Class | 1 | 10 | 50 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | Accuracy (%) | Accuracy (%) | Accuracy (%) | |||||||
| Test Architecture | Conv3 | RN10 | DN121 | Conv3 | RN10 | DN121 | Conv3 | RN10 | DN121 | |
| SVHN | DSA [7] | 27.5±1.4 | 13.2±1.1 | 13.3±1.4 | 79.2±0.5 | 19.5±1.5 | 23.1±1.9 | 84.4±0.4 | 41.6±2.1 | 58.0±3.1 |
| DM [5] | 20.3±2.1 | 10.5±2.8 | 13.6±1.0 | 73.5±1.0 | 28.2±1.5 | 24.8±2.5 | 84.2±0.0 | 54.7±1.3 | 58.4±2.7 | |
| IDC [38] | 68.1±0.1 | 39.6±1.5 | 39.9±2.9 | 87.3±0.2 | 83.3±0.2 | 82.8±0.2 | 90.2±0.1 | 89.1±0.2 | 91.0±0.3 | |
| KFS [1] | 82.9±0.4 | 75.7±0.8 | 81.0±0.7 | 91.4±0.2 | 90.3±0.2 | 89.7±0.2 | 92.2±0.1 | 90.9±0.2 | 90.2±0.2 | |
| ESP (ours) | 84.8±0.3 | 84.7±0.6 | 82.0±0.1 | 91.6±0.2 | 93.5±0.1 | 90.7±0.3 | 92.8±0.1 | 93.7±0.1 | 91.0±0.5 | |
| Full dataset | 95.4±0.1 | 93.8±0.5 | 89.1±0.8 | 95.4±0.1 | 93.8±0.5 | 89.1±0.8 | 95.4±0.1 | 93.8±0.5 | 89.1±0.8 | |
| CIFAR10 | DSA [7] | 28.8±0.7 | 25.1±0.8 | 25.9±1.8 | 52.1±0.5 | 31.4±0.9 | 32.9±1.0 | 60.6±0.5 | 49.0±0.7 | 53.4±0.8 |
| DM [5] | 26.0±0.8 | 13.7±1.6 | 12.9±1.8 | 48.9±0.6 | 31.7±1.1 | 32.2±0.8 | 63.0±0.4 | 49.1±0.7 | 53.7±0.7 | |
| IDC [38] | 50.0±0.4 | 41.9±0.6 | 39.8±1.2 | 67.5±0.5 | 63.5±0.1 | 61.6±0.6 | 74.5±0.1 | 72.4±0.5 | 71.8±0.6 | |
| KFS [1] | 59.8±0.5 | 47.0±0.8 | 49.5±1.3 | 72.0±0.3 | 70.3±0.3 | 69.2±0.4 | 75.0±0.2 | 75.1±0.3 | 76.3±0.4 | |
| ESP (ours) | 63.0±0.4 | 50.4±0.5 | 51.6±0.6 | 73.0±0.3 | 71.8±0.4 | 69.4±0.3 | 75.9±0.3 | 75.3±0.2 | 73.0±0.5 | |
| Full dataset | 84.8±0.1 | 87.9±0.2 | 90.5±0.3 | 84.8±0.1 | 87.9±0.2 | 90.5±0.3 | 84.8±0.1 | 87.9±0.2 | 90.5±0.3 | |
| Dataset | Images/Class | 1 | 10 | 50 |
|---|---|---|---|---|
| Metric | Accuracy (%) | Accuracy (%) | Accuracy (%) | |
| Test Architecture | ENs | ENs | ENs | |
| CIFAR10 | DSA [7] | 16.5±0.3 | 25.6±0.4 | 33.7±0.2 |
| DC [6] | 16.1±1.7 | 22.3±1.4 | 25.7±0.9 | |
| Traj. Matching [10] | 17.7±0.2 | 24.0±0.4 | 33.9±0.6 | |
| ESP (ours) | 35.3±0.4 | 55.0±1.2 | 63.9±0.8 | |
| Full dataset | 98.7±0.2 | 98.7±0.2 | 98.7±0.2 |
| Loss | Images/Class | ||||
|---|---|---|---|---|---|
| 1 | 10 | 50 | |||
| Proj | ✓ | 41.3±0.2 | 40.6±0.4 | 39.5±0.3 | |
| DM | ✓ | 48.0±0.3 | 71.3±0.3 | 74.0±0.1 | |
| Proj + DM | ✓ | ✓ | 62.6±0.1 | 73.0±0.3 | 75.9±0.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Gao, D.; Yang, S.; Wei, X.; Gong, Y. Dataset Condensation via Expert Subspace Projection. Sensors 2023, 23, 8148. https://doi.org/10.3390/s23198148
Ma Z, Gao D, Yang S, Wei X, Gong Y. Dataset Condensation via Expert Subspace Projection. Sensors. 2023; 23(19):8148. https://doi.org/10.3390/s23198148
Chicago/Turabian StyleMa, Zhiheng, Dezheng Gao, Shaolei Yang, Xing Wei, and Yihong Gong. 2023. "Dataset Condensation via Expert Subspace Projection" Sensors 23, no. 19: 8148. https://doi.org/10.3390/s23198148