1. Introduction
In recent years, edge computing-related research has gradually received attention from researchers and scholars [
1,
2]. Vehicular edge computing (VEC), as a part of edge computing, provides users with real-time service, and has excellent prospects in the fields of intelligent transportation systems, smart city applications, and in-vehicle applications. Meanwhile, how to provide users with the higher quality of service (QoS) of VEC becomes one of the challenges. The QoS still cannot be improved significantly, and one of its bottlenecks is the inefficient task offloading. Traditional task offloading methods which offload the tasks from the vehicles to the cloud server have considerable communication delay [
3,
4]. Compared with these methods, a lot of research improved task offloading methods through vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) communications, which reduce the distance of the task transmission [
1]. Moreover, resource allocation [
5] and network slicing [
6] are optimized for task offloading in VEC.
Meanwhile, a variety of task offloading schemes based on trajectory prediction have been proposed to optimize task offloading. For example, high-computation-complexity tasks are computed on the nearby edge servers or the cloud server, and the results are transmitted to another edge server in the direction of the vehicle’s movement through multihop transmission. Once the vehicle enters the transmission range of this server, the computation results are downloaded by the vehicle [
7]. However, existing prediction schemes focus on the energy consumption optimization [
8,
9,
10] and ignore the importance of prediction efficiency and accuracy. However, efficient and accurate prediction results are essential to predictive-mode task offloading in VEC.
There are very limited works on the prediction results for multihop transmission in VEC [
11,
12]. As a result, we have extended existing research and deeply explored the trajectory prediction algorithms. Recently, some studies have used deep learning methods to predict vehicle trajectories including the recurrent neural network (RNN) method [
13] and the Transformer method based on the attention mechanism [
14]. These deep learning methods require a large amount of memory space and training time. However, the current performance of edge servers is not capable of deploying high-complexity deep learning algorithms [
15,
16]. At the same time, deep learning algorithms take a long time to predict vehicle trajectories, which cannot meet the demand for real-time prediction [
15]; this is discussed in the experiment part. Refs. [
11,
12] ignore the time consumption of the training process and the prediction process. Trajectory prediction methods based on a frequent pattern do not require large computation and storage resources [
17]. These methods also have high accuracy or efficiency. For example, vehicle trajectories can be predicted in real time by constructing T-pattern tree [
18,
19,
20,
21], but they have low accuracy. The frequent pattern prediction method proposed in [
22] has a higher accuracy rate, but the method is not efficient enough to predict the vehicle trajectory in real time. Therefore, existing trajectory prediction methods based on frequent patterns are not compatible with accuracy and efficiency. Meanwhile, the existing frequent pattern method has to store all of the historical trajectories which take up a lot of storage space.
In order to solve the vehicle trajectory prediction problem in task offloading, this paper designs a T-pattern prediction tree (TPPT) and proposes a real-time vehicle trajectory prediction framework based on frequent patterns. Based on the prediction framework, task offloading strategies and an optimization algorithm are designed.
The main contributions of this work are summarized as follows:
We define a new TPPT data structure for trajectory prediction in VEC. To reduce the storage resources in VEC, the TPPT only stores the trajectories related to the current edge server. To improve the accuracy and efficiency, the TPPT stores the vehicle frequent item and the vehicle frequent pattern. The TPPT is updated in real time according to the feedback of the prediction result transmitted from the predicted edge server.
In order to improve accuracy and efficiency when using the TPPT in VEC, we propose a TPPT construction algorithm, a TPPT prediction algorithm and a TPPT updating algorithm, respectively. By analyzing the characteristics of edge computing servers, we apply the TPPT in this scenario with the aim of improving efficiency and accuracy. At the same time, it provides real-time prediction results for task offloading.
We design the task offloading strategies via V2I and V2V communication based on the proposed prediction. By analyzing the energy consumption, we propose a search algorithm for task offloading to minimize the energy consumption with the constraint of time consumption.
Experiments are carried out on real-vehicle datasets [
23] and Capital Bikeshare datasets [
24] to verify that the vehicle trajectory prediction based on the vehicle frequent pattern has high accuracy and efficiency, which optimizes task offloading in VEC in real time.
The remaining of this paper is organized as follows.
Section 2 introduces the relevant literature, definitions and prediction problem.
Section 3 presents the data structure and algorithms of trajectory prediction for task offloading in the VEC scenario. The experimental and performance results are included in
Section 4.
Section 5 concludes this study and points out our future work.
3. Materials and Methods
In order to accomplish the optimization problem given in this paper, a vehicle trajectory prediction framework based on the vehicle frequent pattern is proposed and this framework is introduced with VEC. This framework is divided into three parts: initializing the edge computing server, predicting the vehicle trajectory, and updating the T-pattern prediction tree in real time. Specifically, the details of the three parts are as follows:
We construct the TPPT on the edge server in the initialization stage of the VEC scenario. We propose a TPPT construction algorithm which constructs the vehicle T-pattern tree, vehicle frequent itemset and vehicle frequent pattern based on the historical vehicle trajectories on the edge server locally.
We predict the vehicle trajectory based on the TPPT in the VEC scenario. We propose a TPPT prediction algorithm which predicts the future location of the edge server in real time. The computation tasks are transmitted to the prediction result via V2I or V2V communication for the task offloading optimization of VEC.
We update the TPPT based on the feedback of prediction results in the VEC scenario. In order to maintain the timeliness of the TPPT in VEC, we propose a TPPT updating algorithm which updates the vehicle frequent itemset and vehicle frequent pattern of the TPPT in real time according to the feedback of the prediction result transmitted from the predicted edge server.
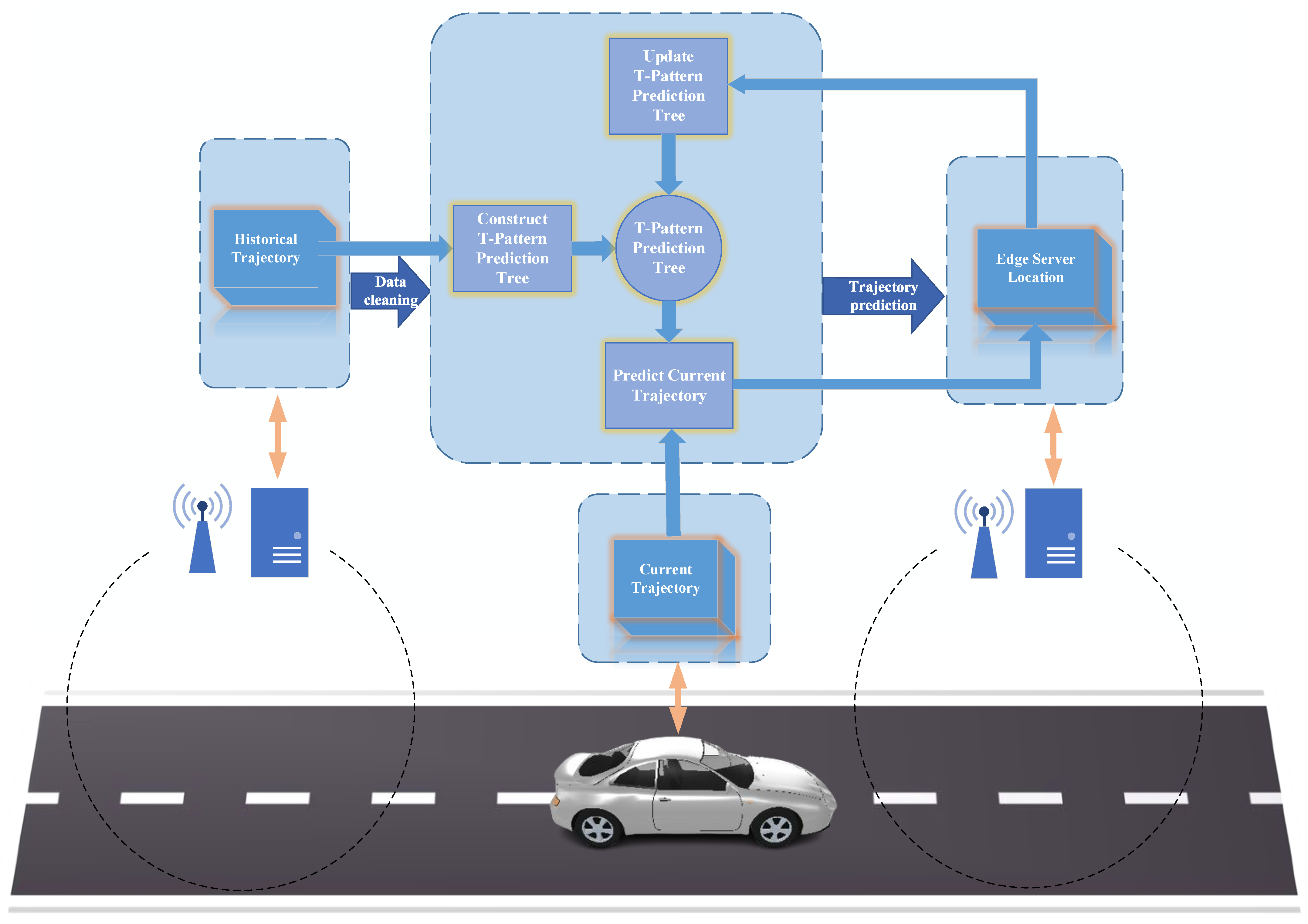
The vehicle trajectory prediction framework based on the vehicle frequent pattern is shown in
Figure 2.
In
Figure 2, the arrows do not indicate direct transmission relationships between the vehicle (edge servers) and flow chart. The historical trajectories are stored on edge servers. These trajectories are updated in the updating process. The current trajectory is provided by the vehicle. The edge server location which is the prediction result indicates the name or the serial number of an edge server.
The storage and computation resources are limited in the task offloading of VEC. Meanwhile, predictive-mode task offloading in VEC requires real-time vehicle trajectory prediction. Therefore, in order to ensure the efficiency and accuracy of vehicle trajectory prediction, this paper designs a T-pattern prediction tree (TPPT), a data structure that stores only the historical vehicle trajectories and the vehicle frequent pattern related to the current edge server. The framework shown in
Figure 2 mainly solves the optimization problem of this paper through the T-pattern prediction tree.
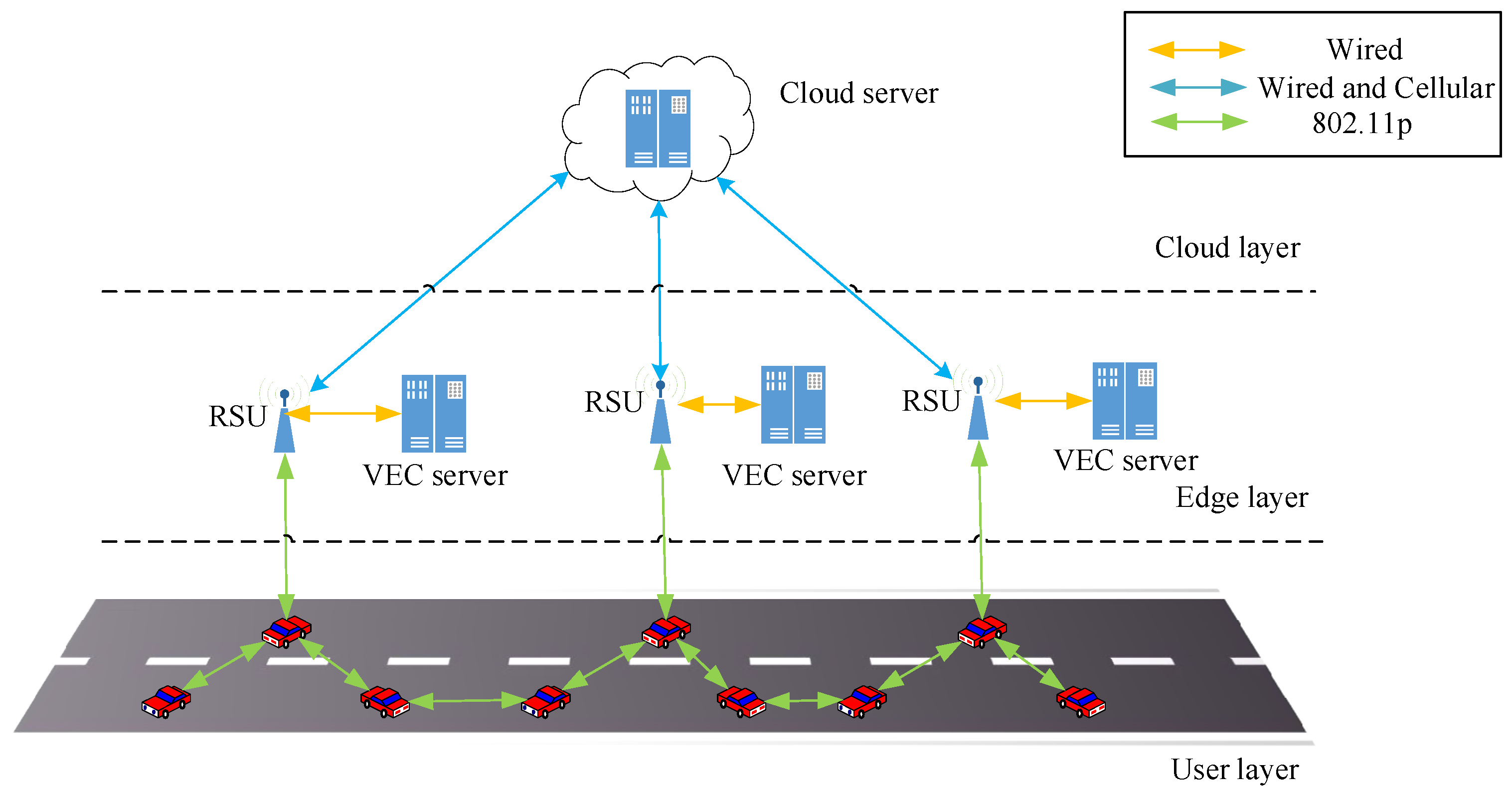
The TPPT can be deployed in both V2I and V2V communications of VEC. In the initialization stage of V2I communication, the edge server constructs the TPPT based on historical vehicle trajectories. Then, the current trajectory and computation tasks in a vehicle are offloaded to the edge server when the vehicle enters the transmission range of the edge server. Based on the TPPT, the edge server predicts the location of another edge server that the vehicle will pass through in the future. After that, the edge server processes the computation tasks or transmits these tasks to other edge servers or cloud server according to the complexity of the tasks and load balance. If the tasks are completed, the results are transmitted to the predicted edge server. Once the vehicle arrives within the transmission range, the results are downloaded by the vehicle. Finally, the edge server updates the TPPT in real time based on the feedback of the prediction results. In V2V communication, the vehicle offloads the real-time trajectory and downloads the overhead prediction results. The computational tasks and prediction results are transmitted to the predicted location of the edge server through the surrounding vehicles via V2V communication. Therefore, V2I and V2V communications are similar in the trajectory prediction process. In terms of task offloading, V2I communication transmits the prediction results and computation tasks to the predicted edge server through RSU, whereas V2V communication transmits the predicted results and computation tasks through wireless technology between vehicles.
We use the prediction time as the optimization objective of the prediction algorithm. Without incorporating the energy consumption, a computation task is defined as
T [
7],
T = {
c,
d,
tmax}, where
c is the number of computation resources required to complete the task,
d is the size of the task, and
tmax denotes the maximum tolerable delay. The computation process of VEC usually considers 2 scenarios. If the computation task uses local computation resources, then it takes time
t1 =
c/
cl to complete this task, where
cl denotes the local computation resources. Since the local computing resource
cl is usually small, it is difficult for time
t1 to satisfy
t1 <
tmax. The computation task can also be transmitted to the edge server
b0. Therefore, the overall process requires time
t2 =
c/
cs +
tc +
ty, where
cs denotes the computational resources of the edge server,
tc denotes the time of communication, and
ty denotes the time of trajectory prediction. The vehicle trajectory prediction method based on the vehicle frequent pattern makes the total time
t2 satisfy
t2 <
tmax as much as possible by reducing
tc and
ty.
3.1. Definition of the T-Pattern Prediction Tree
The three data structures in the TPPT are the vehicle T-pattern tree, the vehicle frequent itemset and the vehicle frequent pattern. Among them, the vehicle T-pattern tree is composed of the prefixes of the vehicle T-pattern. The vehicle frequent itemset is composed of the suffixes of the vehicle T-pattern and their corresponding vehicle trajectory supports. The vehicle frequent pattern embodies the corresponding relationships of the vehicle T-pattern tree and the vehicle frequent itemset. The formal definition of the TPPT is shown below.
Definition 4. T-Pattern Prediction Tree. A T-pattern prediction tree is a ternary tuple containing a vehicle T-pattern tree, a vehicle frequent itemset and a vehicle frequent pattern.
Given the vehicle trajectory datasets D, the T-pattern prediction tree can be represented aswhere TPPT denotes the T-pattern prediction tree. Tree(D), Item(D) and Frequent(D) denote the vehicle T-pattern tree, the vehicle frequent itemset and the vehicle frequent pattern under the vehicle trajectory set D, respectively. In this paper, we provide a detailed explanation of the vehicle T-pattern tree, the vehicle frequent itemset and the vehicle frequent pattern.
Definition 5. Vehicle T-Pattern Tree.
A vehicle T-pattern tree is a tree structure consisting of a set of edge servers and a set of edges, formally defined aswhere TB denotes the set of edge servers, i.e., N = {b0, b1, …, bk, …, bn}, bk denotes the edge server in Equation (1); E is similar to the set of edges in Equation (4), i.e., E = {R1, R2, …, Rh, …, Rm}, Rh = (bk−1, bk, sk). In the vehicle T-pattern tree, the data structure is not a sequence. As a result, there is no direct relationship between the length of edge servers n and the length of edges m. In the vehicle T-pattern tree, node bk is the child of node bk−1, and node bk−1 is the parent of node bk. If bk does not have a parent node, bk is the root node; if bk does not have a child node, bk is a leaf node. A branch of a vehicle T-pattern tree is a binary tuple. Specifically, given TPT = (TB, E), TPT′ = (TB′, E′), N′ ⊆ N, E′ ⊆ E, if ∀bk ϵ N′, Rh ϵ E′ such that 1 ≤ |{Rh|bk ϵ Rh}| ≤ 2, TPT′ is a branch of the vehicle T-pattern tree TPT, denoted as TR.
In addition, the vehicle T-pattern tree needs to satisfy the following 3 conditions:
Each node has different children;
Each branch is a portion of the vehicle T-pattern;
All the branches starting with the root node and ending with the parent of the leaf node are the prefixes of the vehicle T-pattern.
Definition 6. Vehicle Frequent Itemset. The vehicle frequent itemset is the set consisting of the suffixes of the vehicle T-pattern and their corresponding vehicle trajectory support, i.e.,
where set denotes the elements of the vehicle frequent itemset. b is the suffix of the vehicle T-pattern in Equation (6), denoting the key of set. s is the vehicle trajectory support in Equation (3), denoting the value of set.
According to Definition 3, there exists a derivation relation which is also called the vehicle frequent pattern in Equation (7) between the prefix and suffix of a vehicle T-pattern. In the TPPT, we define the vehicle frequent pattern integrating the vehicle T-pattern tree and the vehicle frequent itemset as follows.
Definition 7. Vehicle Frequent Pattern.
A vehicle frequent pattern is a set consisting of branches of a vehicle T-pattern tree and suffixes of a vehicle frequent itemset, which is formally defined aswhere U is the vehicle frequent pattern between TR and b, TR is the branch of the vehicle T-pattern tree, and the edge server b is the key of the vehicle frequent itemset.
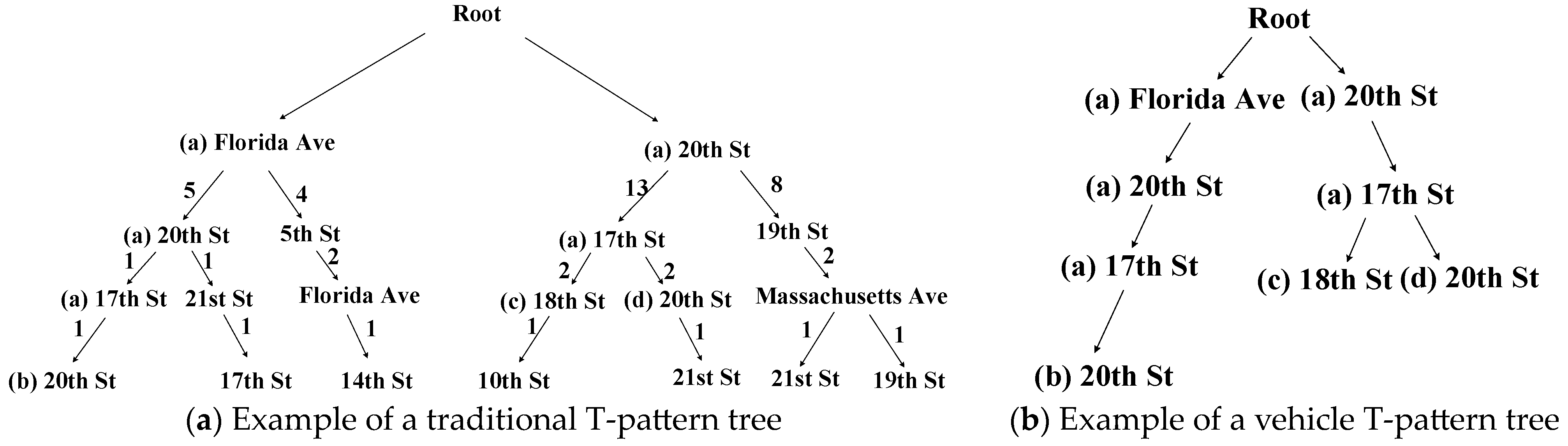
To compare the advantages of the vehicle T-pattern prediction tree in Definition 4 and the vehicle T-pattern tree in Definition 5, taking the Capital Bikeshare datasets as an example, we construct the traditional T-pattern tree in [
17,
18] and the vehicle T-pattern tree which is a portion of the vehicle T-pattern prediction tree.
Figure 3 shows examples of a traditional T-pattern tree and a vehicle T-pattern tree. The main difference between the traditional T-pattern tree in
Figure 3a and the T-pattern prediction tree in
Figure 3b is the storage content and the prediction process. In terms of storage content, the traditional T-pattern tree stores all of the historical trajectories, while the TPPT only stores the historical trajectories related to the current edge server. Therefore, the TPPT saves storage space and improves prediction efficiency. In terms of the prediction process, the traditional T-pattern tree traverses and searches for the node with the largest support of the vehicle trajectory, while the TPPT searches all of the leaf nodes through the vehicle frequent pattern and mines the leaf node with the largest support of the vehicle trajectory through the vehicle frequent itemset. Therefore, the TPPT optimizes the prediction process.
The TPPT consists of three parts: (1)
Figure 3b shows a vehicle T-pattern tree. (2)
Table 1 shows an example of a vehicle frequent itemset. (3) The branch of the vehicle T-pattern tree in
Figure 3b and the key of the vehicle frequent itemset in
Table 1 constitute the vehicle frequent pattern.
In the VEC scenario, we assume that the TPPT is stored in the edge server “17th St” which is the name of the edge server. Then, the TPPT maintained on the edge server is a data structure that consists of the vehicle T-pattern tree in
Figure 3, the vehicle frequent itemset in
Table 1, and the vehicle frequent pattern formed between them. Given the current vehicle trajectory formed by nodes (a) in
Figure 3b and its corresponding edges, nodes (b), (c) and (d) in
Figure 3b are potential following edge servers. The vehicle frequent itemset shown in
Table 1 also consists of these potential following edge servers.
3.2. Construction of the T-Pattern Prediction Tree
In order to deploy the TPPT faster in VEC, this paper designed an algorithm for the construction of the TPPT. This algorithm is an initialization algorithm running on the edge server to optimize task offloading in VEC. At this initialization stage of V2I and V2V communications, the edge server downloads the historical data related to it from the cloud server and deploys the TPPT according to the construction algorithm in its memory. The Algorithm 1 is shown below.
| Algorithm 1: Algorithm for construction of the T-pattern prediction tree. |
| Input: vehicle trajectory datasets D, D = {TB1, TB2, …, TBj, …, TBz}. |
| Output: T-pattern prediction tree TPPT. |
| 1. Init(TPT, IT, FR) |
| 2. for each TBj in D |
| 3. for each bk in TBj |
| 4. TBk = <b0, …, bk> |
| 5. TPk = convert_TP(TBk) |
| 6. if TPk in TPT: |
| 7. TPi = TPT.find_branch(TPk) |
| 8. TPi.support += 1 |
| 9. if TPk not in TPT: |
| 10. TPi−1 = TPT.find_branch(TPk−1) |
| 11. TPi = TPi−1. Add_node(bk) |
| 12. TPi.support = 1 |
| 13. end for |
| 14. end for |
| 15. for bk in TPT.Leaf_node |
| 16. TBk = <b0, …, bk> |
| 17. TPk = Convert_TP(TBk) |
| 18. setk = (bk, TPk.support) |
| 19. IT.Add_set(setk) |
| 20. FR.Add_relationship(TPk, bk) |
| 21. end for |
| 22. return TPPT = (TPT, IT, FR) |
Among them, lines 2~14 construct the vehicle T-pattern tree. Lines 2~3 traverse each edge server bk of the vehicle trajectory TBj. Lines 4~5 construct the vehicle trajectory TBk and its corresponding vehicle T-pattern TPk, with b0 as the start and bk as the end. Lines 6~12 determine whether there is the same vehicle T-pattern as TPi in the vehicle T-pattern tree. If there is, the vehicle trajectory support corresponding to TPi is incremented; otherwise, TPi is constructed in the vehicle T-pattern tree and the vehicle trajectory support corresponding to TPi is set to 1.
Lines 15~22 construct the vehicle frequent itemset and the vehicle frequent pattern. Lines 15~17 traverse each leaf node bk of the vehicle T-pattern tree to construct the vehicle trajectory TBk and its corresponding vehicle T-pattern TPk starting from b0 and ending at bk. Lines 18~19 construct a set composed of the leaf node bk and the corresponding vehicle trajectory support. Then, the set is added into the vehicle frequent itemset. Line 20 constructs a binary tuple jointly constituted by the vehicle T-pattern TPk and the leaf node bk. Then, the binary tuple is added into the vehicle frequent patten.
For the construction process of the
TPPT, we take the Capital Bikeshare datasets as an example, which is shown in
Figure 3. In the example, after cleaning the data from the Capital Bikeshare datasets, the
TPPT is constructed according to Algorithm 1. Specifically, the edge server “17th St” maintains this
TPPT. The edge server “20th St” and “18th St” are the leaf nodes, which are the elements in the vehicle frequent itemset.
3.3. Prediction Based on the T-Pattern Prediction Tree
The TPPTs maintained by edge servers are designed to optimize predictive-mode task offloading in VEC. In this section, this paper proposes a prediction method based on the TPPT, in order to meet the real-time, accuracy and efficiency requirement of VEC. The prediction method is based on statistical theory. It needs to satisfy one assumption: assuming that a vehicle trajectory appears multiple times, then it can be assumed that this vehicle trajectory is related to the user’s driving habits. This assumption is applied in the TPPT as follows.
Both V2V and V2I communications require maintaining a T-pattern prediction tree. In V2I and V2V communications, a vehicle offloads the current trajectory to the edge server when it passes the edge server. The edge server matches the vehicle trajectory in the maintained vehicle T-pattern tree and finds the vehicle frequent itemset based on the matched vehicle trajectory and its vehicle frequent pattern. Then, the edge servers of the vehicle frequent itemset and their corresponding vehicle trajectory support are counted, and the edge server with the largest vehicle trajectory support is selected to accomplish the final prediction task.
The vehicle trajectory support in the vehicle frequent itemset indicates the number of occurrences of the trajectory. When predicting the trajectory, the same edge servers in the vehicle frequent itemset can be merged, and the corresponding vehicle trajectory support needs to be accumulated. In this paper, the accumulated result is called the support score, denoted as
score. Its calculation formula is as follows:
where
set.key is the former element of the
set in the vehicle frequent itemset, i.e., the edge server
bp.
set.value is the latter element of the
set in the vehicle frequent itemset, i.e., the vehicle trajectory support
sp. The optimization scheme is to find the edge server that has the highest support score among the vehicle frequent itemset, which can also be represented as
where
bp+1 is the prediction result, i.e., the edge server that the vehicle trajectory will pass through in the future. For this optimization scheme, this paper designed a prediction algorithm for the T-pattern prediction tree, also called the TPPT algorithm. The Algorithm 2 is shown below.
| Algorithm 2: Prediction algorithm for the T-pattern prediction tree. |
| Input: T-pattern prediction tree TPPT, current vehicle trajectory TBp. |
| Output: Edge computing server bp+1. |
| 1. TPT = extract_TPT(TPPT) |
| 2. while IT = Ø do: |
| 3. TB = match_TB(TPT, TBp) |
| 4. IT = match_IT(TB, FR) |
| 5. TBp = delete_first_node(TBp) |
| 6. end while |
| 7. merge(IT) |
| 8. Highest_score = 0 |
| 9. for each set in IT: |
| 10. if set.value > Highest_score: |
| 11. bp+1 = set.key |
| 12. Highest_score = set.value |
| 13. end for |
| 14. return bp+1 |
Among them, lines 1~7 obtain the vehicle T-pattern tree and match the current vehicle trajectory in the vehicle T-pattern tree. Lines 3~4 find the vehicle frequent itemset related to the current vehicle trajectory through the vehicle frequent pattern. Then, that portion of the vehicle frequent itemset is merged according to the name or the serial number of the edge server. Lines 2~6 loop to match the current vehicle trajectory. If no vehicle frequent itemset is found, the first node of the vehicle trajectory is deleted. Lines 9~13 iterate through each set to find the set with the highest support score as the final prediction result.
In the example in
Figure 3, the support scores corresponding to “18th St” and “20th St” are calculated and updated separately. The maximum value is taken as the highest support score. In
Figure 3, “20th St” has the highest support score of 3. Finally, the edge server corresponding to the highest support score is output as the final prediction result. In
Figure 3, “20th St” is the final prediction result.
3.4. Real-Time Updating of the T-Pattern Prediction Tree
The vehicle trajectories have a certain degree of effectiveness. To ensure the accuracy of the vehicle trajectory prediction, the T-pattern prediction tree maintained by edge servers needs to be updated in real time. For this reason, this paper designed a real-time updating algorithm for the T-pattern prediction tree. The application scenario of this method is as follows.
Given the prediction result
bp+1 of the edge server
bp and the time threshold
t, if the current vehicle has passed the edge server
bp+1 within the time threshold
t, the prediction result is correct. Otherwise, the prediction result is incorrect. The edge server
bp+1 generates feedback of the prediction result based on whether the prediction result is correct or not. The feedback is transmitted to the edge server
bp. The edge server
bp updates the maintained TPPT after obtaining the feedback. The Algorithm 3 is shown below.
| Algorithm 3: Real-time updating algorithm for the T-pattern prediction tree. |
| Input: original T-pattern prediction tree TPFTα, feedback of prediction result. |
| Output: updated T-pattern prediction tree TPFTβ. |
| 1. TB = match_TB(TPT, result.TB) |
| 2. IT = match_IT(TB, FR) |
| 3. if result.prediction = True: |
| 4. TB.support += 1 |
| 5. IT.set.value += 1 |
| 6. if result.prediction = False: |
| 7. TB.support −= 1 |
| 8. IT.set.value −= 1 |
| 9. TPFTβ = update(TPFTα, TB, IT) |
| 10. return TPFTβ |
Among them, lines 1~3 obtain the vehicle T-pattern tree and the vehicle frequent itemset in the T-pattern prediction tree TPFTα. Lines 4~9 determine whether the prediction result is correct or not. If the prediction result is correct, the vehicle trajectory support corresponding to this vehicle trajectory is incremented. Otherwise, the vehicle trajectory support corresponding to this vehicle trajectory is decremented. Line 10 synchronizes the update results to the T-pattern prediction tree.
Taking the Capital Bikeshare datasets as an example, as shown in
Figure 3, assume that the vehicle trajectory is <“20th St”, “17th St”> and the prediction result is “20th St”. If the vehicle trajectory subsequently passes through the edge server “20th St”, then the vehicle trajectory support corresponding to this vehicle trajectory in the TPPT is incremented. Otherwise, the vehicle trajectory support corresponding to this vehicle trajectory is decremented.
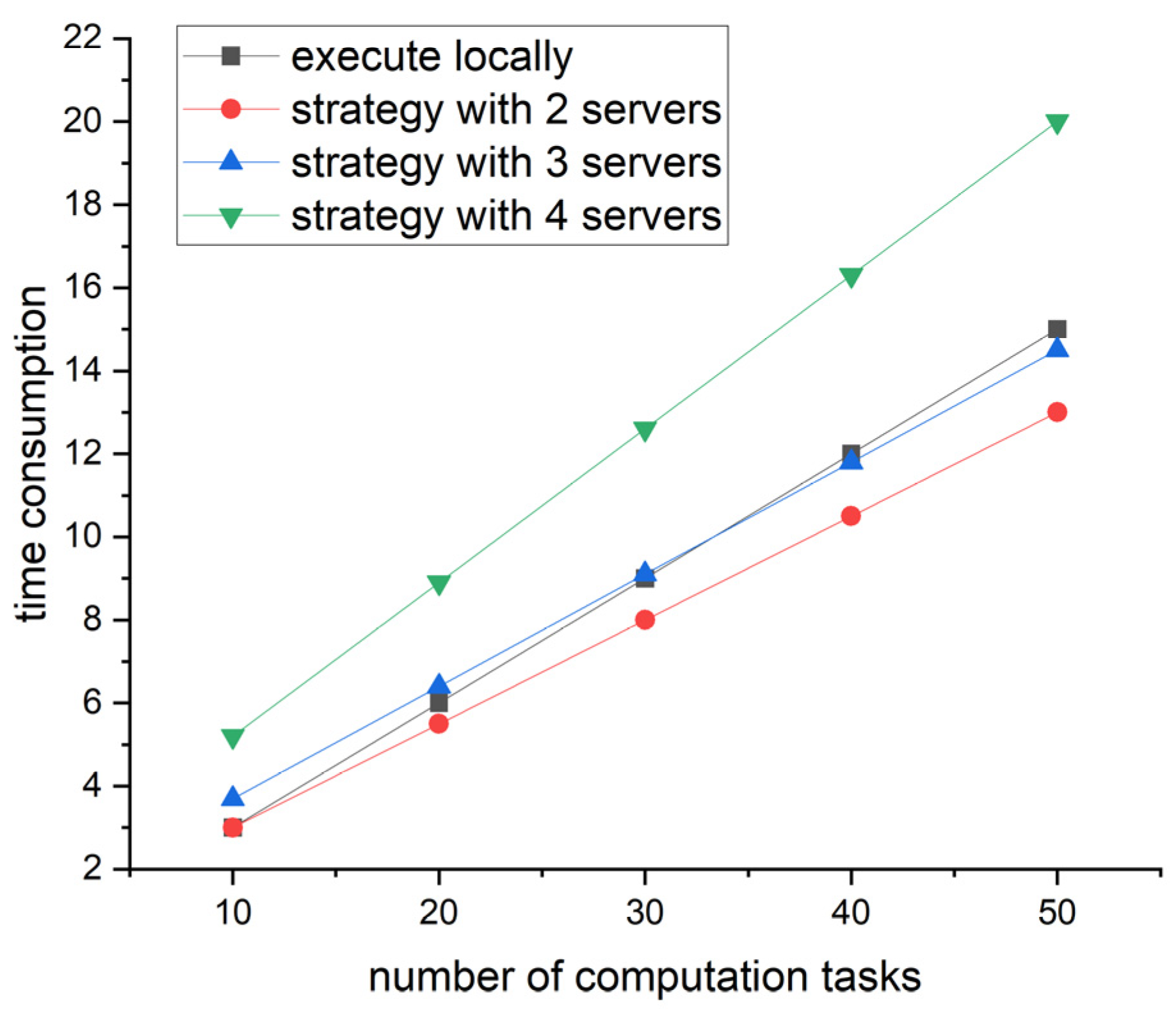
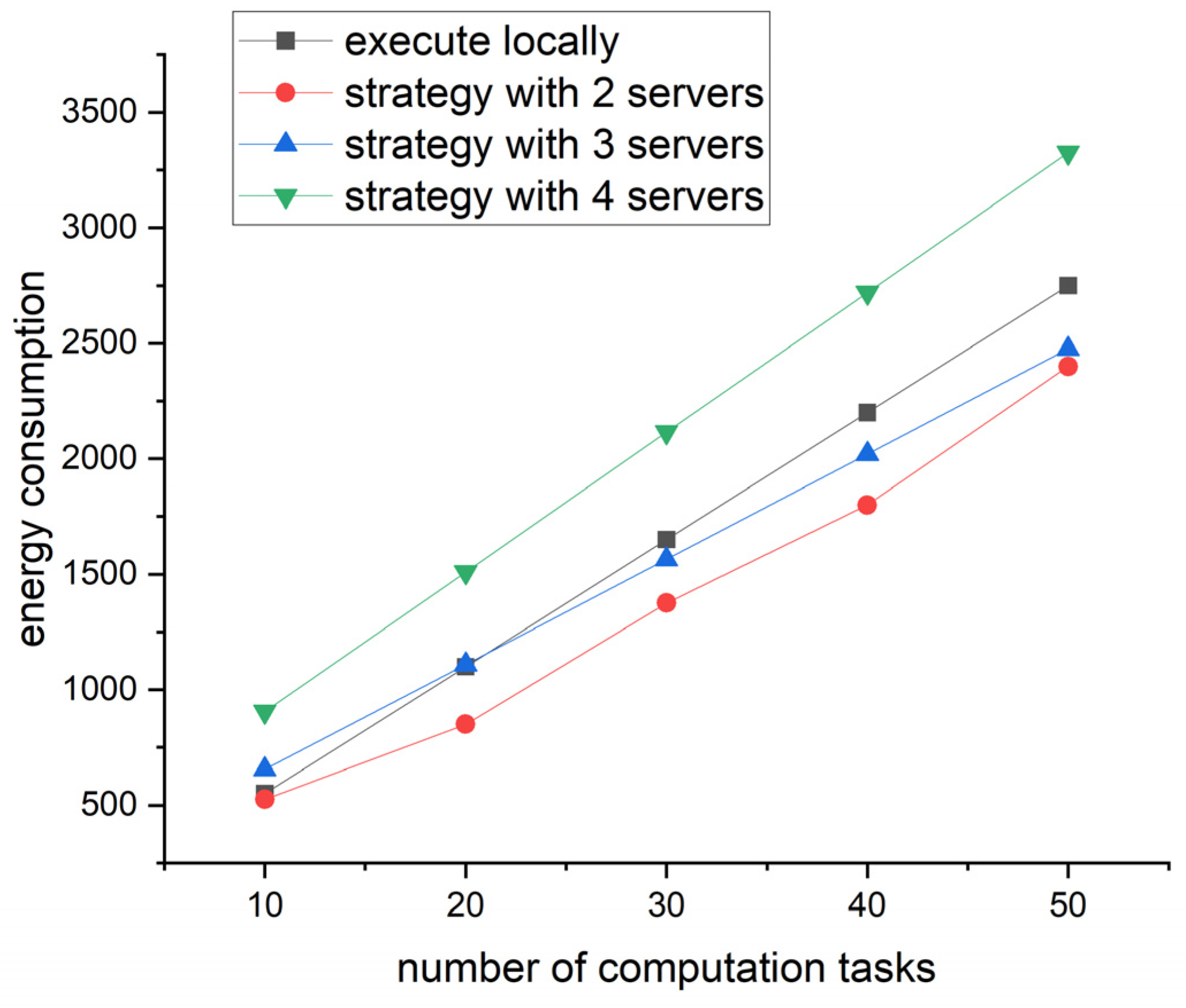
3.5. Task Offloading Strategies, Energy Consumption and Search Algorithm
In this section, we propose two task offloading strategies based on the proposed prediction method in
Section 3.3. In addition, the incorrect prediction is considered in the strategies. After that, by analyzing the energy consumption, we also present a task offloading optimization algorithm, which minimizes the energy consumption with the time constraints.
Refs. [
7,
8] proposed the predictive-mode task offloading method via V2I and V2V, respectively. However, the trajectory was random. They did not integrate the trajectory prediction in the task offloading. In our task offloading strategies, we integrate the proposed prediction method. Before the task offloading, each edge server is initialized using Algorithm 1. The task offloading strategy in V2I communication is divided into 4 steps.
Step 1. When the vehicle arrives within the transmission range of the RSU, the computation tasks and the prediction tasks are offloaded to the edge server.
Step 2. The edge server predicts the location of the next edge server based on Algorithm 2. The computation tasks and/or their results are transmitted to the predicted edge server via V2I based on the search algorithm (which is introduced in the following part of this section).
Step 3. If the tasks are completed on two edge servers and the prediction result is correct, the results of the computation tasks are transmitted to the vehicle once it arrives. If the tasks are not completed on these two edge servers and the vehicle arrives within the transmission range of the last edge server, then go back to Step 2 and repeat. If the prediction result is incorrect and detected by Algorithm 3, the computation tasks and/or their results have to be transmitted to the known correct edge server via V2I communication.
Step 4. If the computation tasks and/or their results are transmitted to the known correct edge server, but the vehicle has been out of the transmission range, then go back to Step 2 and repeat.
The task offloading strategy in V2V communication is divided into 4 steps.
Step 1. When the vehicle arrives within the transmission range of the RSU, only the prediction tasks are offloaded to the edge server
Step 2. The edge server also predicts the location of the next edge server. Then, the prediction results are transmitted to the vehicle. After that, the computation tasks are transmitted to the predicted edge server via V2V communication based on the search algorithm.
Steps 3 and 4. The process is similar to that in V2I. The only difference is that the communication method is V2V.
For the energy consumption, we improve the definition in [
7,
8]. First, we consider the computation tasks is a set
C = {
T1,
T2, …,
Tv, …,
Tw}. Each task
Tv = {
cv,
dv,
tv} is a ternary tuple
Tv where
cv is the number of computation resources required to complete the task
Tv,
dv is the size of the task, and
tv denotes the maximum tolerable delay. Then, for each edge server,
b is a quintet defined as
, where
are the computation rate, computation power and transmission power, respectively. Finally, let
fr be the transmission rate.
According to the above definition, the computation time is
and the transmission time is
The computation energy consumption is
and the transmission energy consumption is
According to the above strategies, we do not know how many hops it will take to complete the computation tasks. Based on the proposed prediction algorithm, we can predict the neighboring edge server. Therefore, time is used as a constraint to locally optimize the computation tasks. As a result, we calculate the time consumption and energy consumption of neighboring edge servers. The time consumption is
where
tp denotes the time consumption of the prediction, and the energy consumption is
where
is a binary variable indicating the status of task
v. In the time and energy consumption, the tasks’ allocation and computation are only executed on two edge servers. Meanwhile, only the transmission of computation tasks is calculated. The size of the results is usually so small that they can be ignored in transmission.
The optimization problem based on the proposed prediction method for task offloading can be formulated as
where the constraints are such that there is no localized out-of-delay.
Finally, we propose a search algorithm to address the optimization problem according to Equation (21). The search algorithm is to minimize the energy consumption in Equation (20) with the time consumption in Equation (19). The Algorithm 4 is as follows.
| Algorithm 4: Search algorithm for task offloading. |
| Input: computation tasks set C, edge server b1, edge server b2. |
| Output: minimum energy consumption Emin. |
| 1. Emin = +ꝏ |
| 2. for each v in |C|: |
| 3. tall = calculate t in Equation (19) based on v, b1, b2 |
| 4. Eall = calculate E in Equation (20) based on v, b1, b2 |
| 5. if tall < min(t1, …, tw): |
| 6. if Eall < Emin: |
| 7. Eall = Emin |
| 8. return Eall |
Among them, lines 2~7 traverse the computation tasks to obtain the minimum energy consumption with the constraint of time. Lines 3~4 calculate the time and energy consumption at each iteration. Line 5 takes the constraint into account. Lines 6~7 obtain the minimum energy consumption.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}