

Scale-Hybrid Group Distillation with Knowledge Disentangling for Continual Semantic Segmentation

Abstract
:1. Introduction
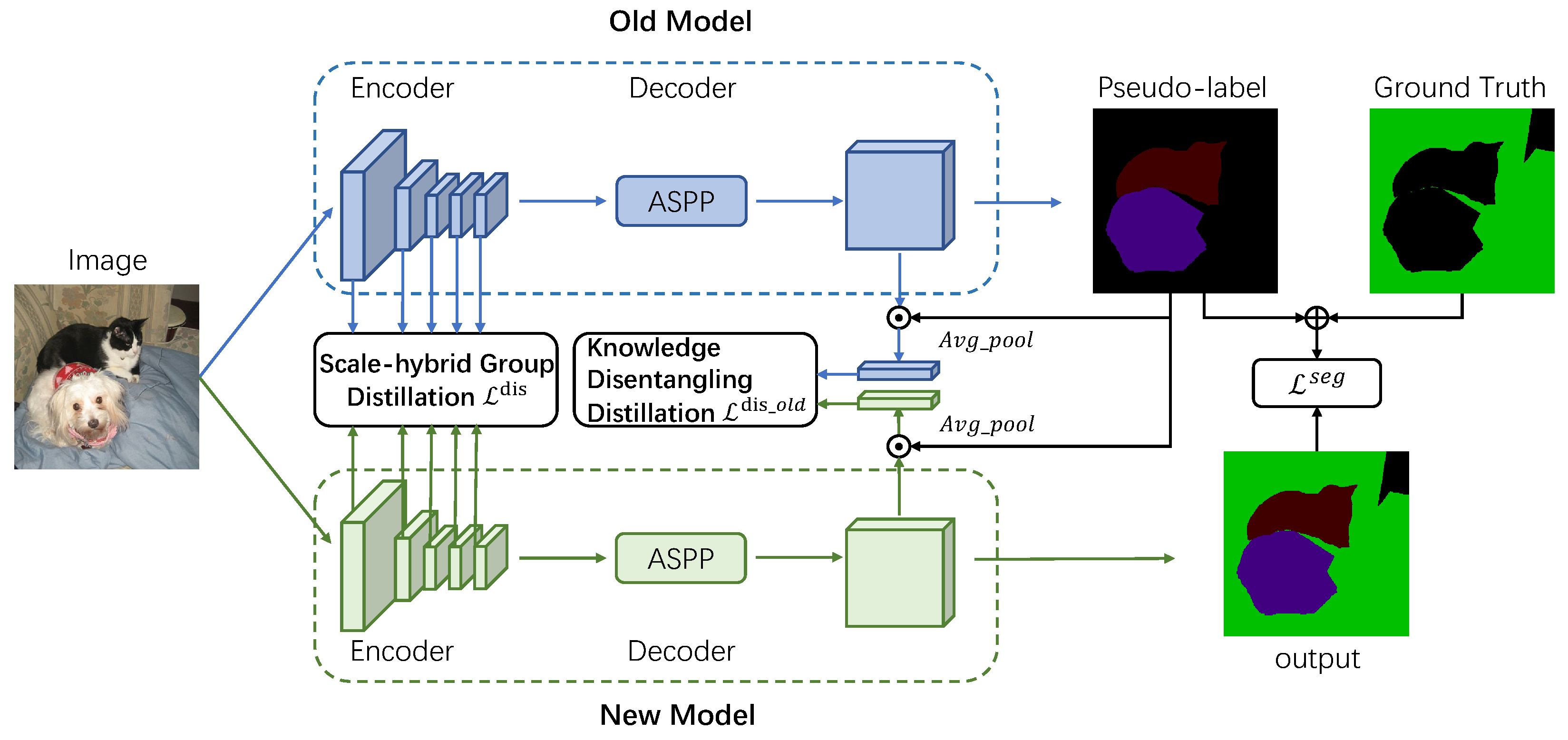
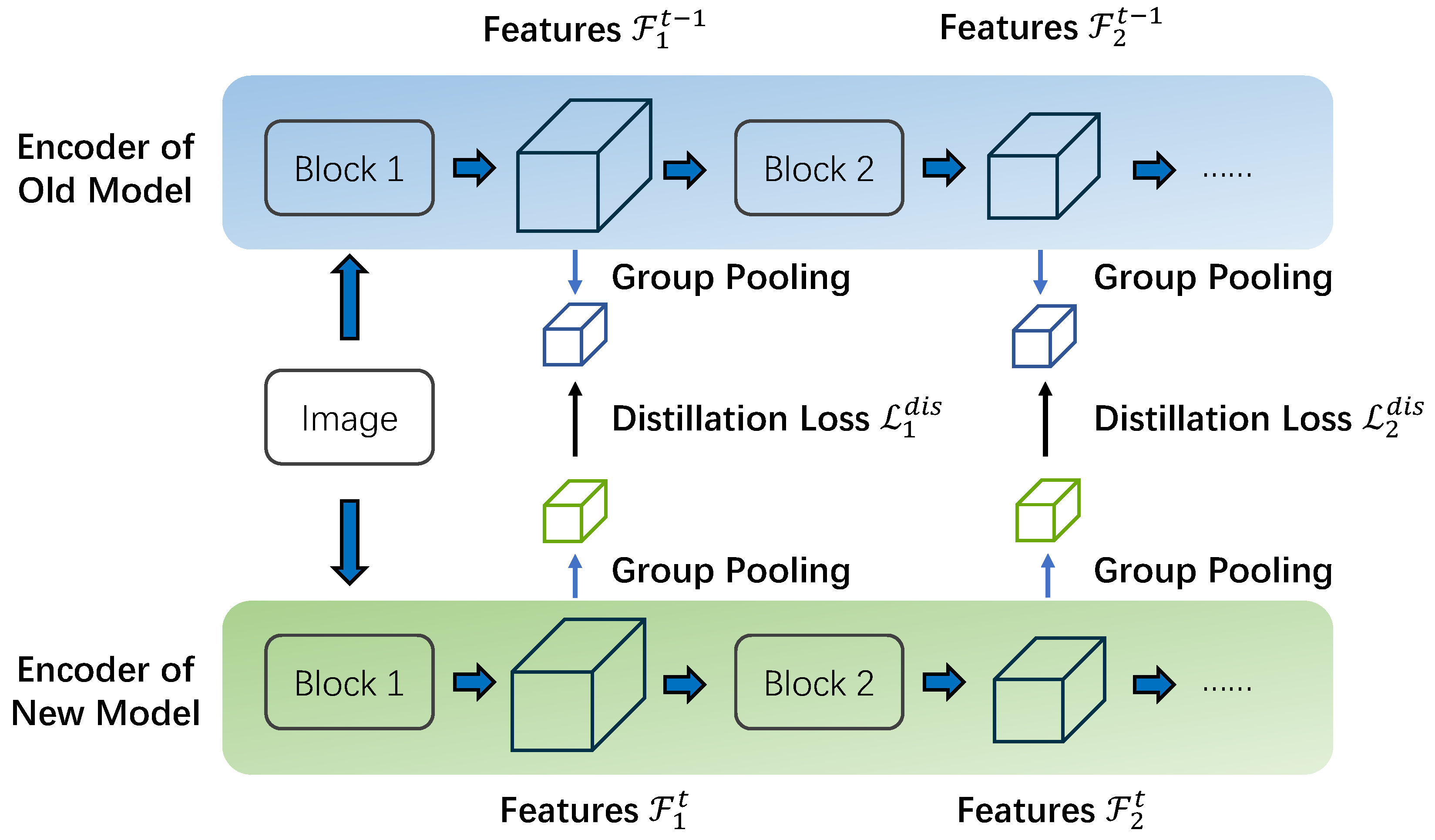
- We propose a scale-hybrid group distillation (SGD) for encoding to transfer richer semantic knowledge from the old model’s feature encoder in different scales in a novel group pooling manner to preserve comprehensive knowledge without the catastrophic forgetting problem.
- We propose a knowledge disentangling distillation (KDD) for decoding to decompose the learning of old and new knowledge based on the corresponding model. This approach can reduce the interference of incorrect guides from old models for the new knowledge.
- Extensive experiments on Pascal VOC and ADE20k datasets are conducted on the typical continual semantic segmentation settings, and the results demonstrate the effectiveness of our proposed method.
2. Related Work
2.1. Semantic Segmentation
2.2. Continual Learning
2.3. Continual Semantic Segmentation
3. Method
3.1. Preliminaries
3.2. Basic Framework
3.3. Scale-Hybrid Group Distillation
3.4. Knowledge Disentangling Distillation
3.4.1. Pseudo-Label Generation
3.4.2. Distillation of Old Class
3.4.3. Learning of New Class
4. Experiments
4.1. Datasets, Protocols, and Metrics
4.1.1. Datasets
4.1.2. Protocols
4.1.3. Metrics
4.1.4. Implementation Details
4.2. Main Results
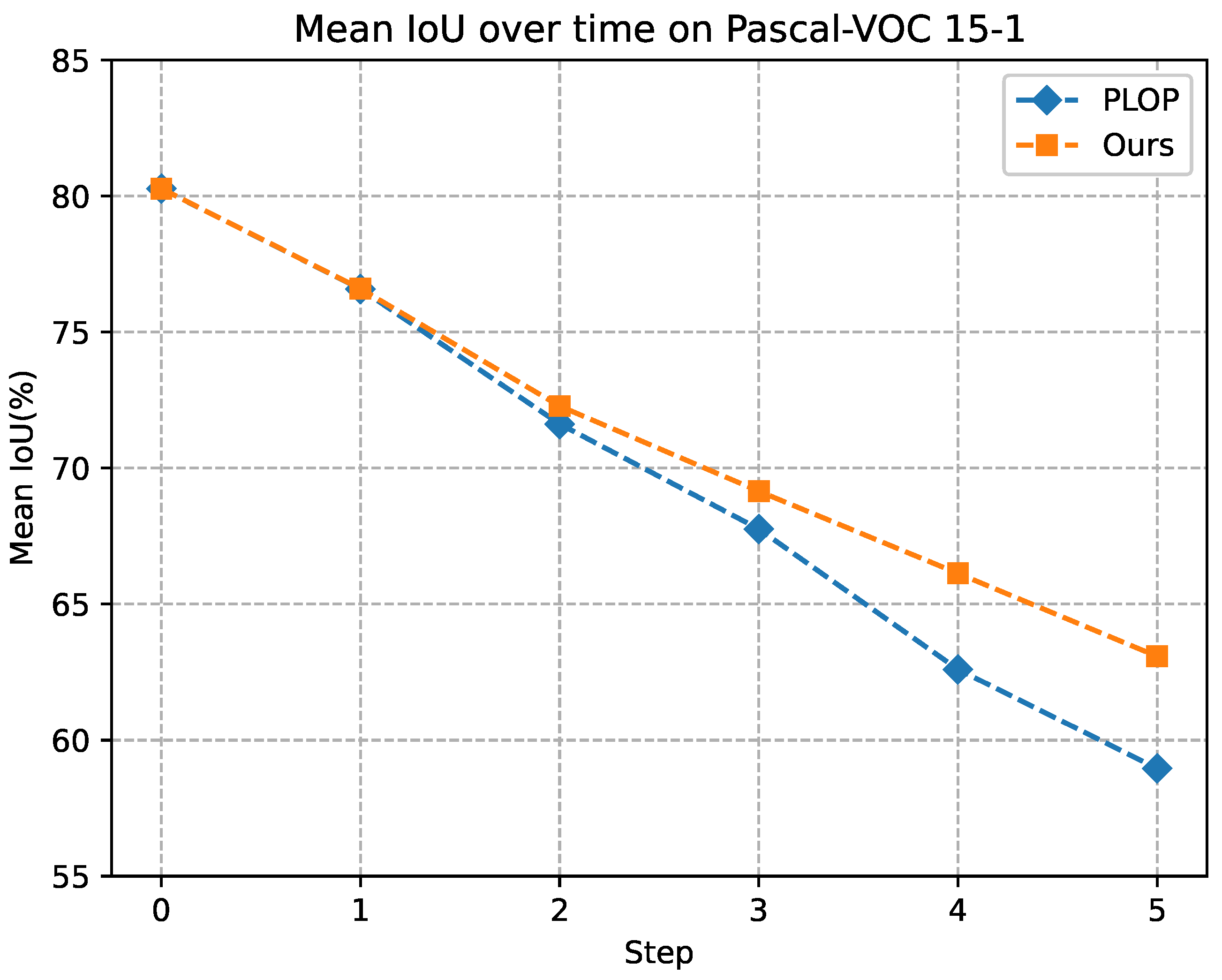
4.2.1. Pascal VOC
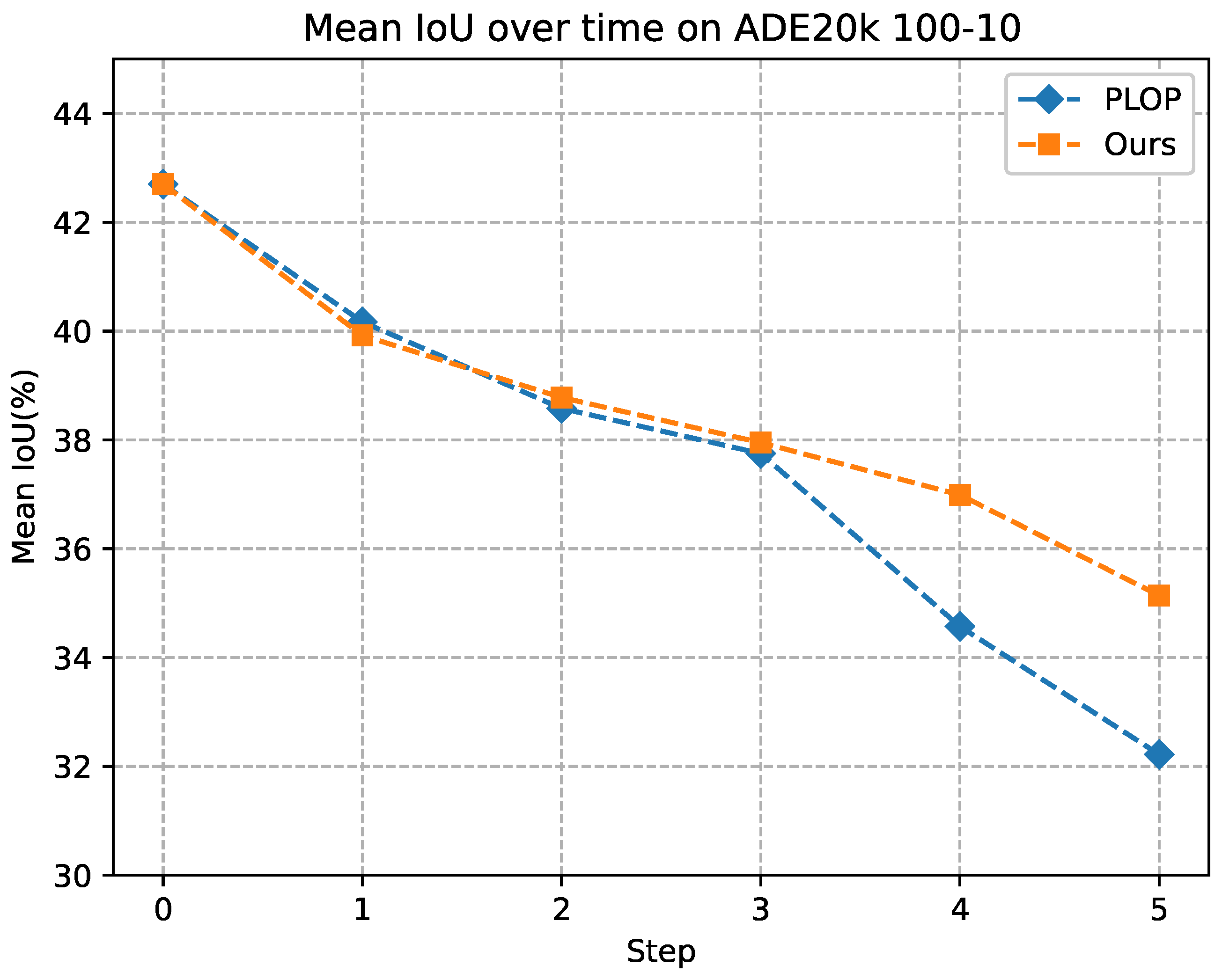
4.2.2. ADE20K
4.3. Ablation Study
4.3.1. Distillation Mechanism
4.3.2. Different Group Pooling Kernel Sizes
4.3.3. Different Pooling Methods
4.4. Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of Learning and Motivation; Academic Press: New York, NY, USA, 1989; Volume 24, pp. 109–165. [Google Scholar]
- Goodfellow, I.J.; Mirza, M.; Xiao, D.; Courville, A.; Bengio, Y. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv 2013, arXiv:1312.6211. [Google Scholar]
- Michieli, U.; Zanuttigh, P. Incremental Learning Techniques for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 3205–3212. [Google Scholar]
- Douillard, A.; Chen, Y.; Dapogny, A.; Cord, M. PLOP: Learning Without Forgetting for Continual Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4040–4050. [Google Scholar]
- Michieli, U.; Zanuttigh, P. Continual Semantic Segmentation via Repulsion-Attraction of Sparse and Disentangled Latent Representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1114–1124. [Google Scholar]
- Maracani, A.; Michieli, U.; Toldo, M.; Zanuttigh, P. RECALL: Replay-Based Continual Learning in Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 7026–7035. [Google Scholar]
- Zhang, C.B.; Xiao, J.W.; Liu, X.; Chen, Y.C.; Cheng, M.M. Representation Compensation Networks for Continual Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7053–7064. [Google Scholar]
- Zhao, H.; Yang, F.; Fu, X.; Li, X. RBC: Rectifying the Biased Context in Continual Semantic Segmentation. In Proceedings of the European conference on computer vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 55–72. [Google Scholar]
- Cermelli, F.; Mancini, M.; Bulo, S.R.; Ricci, E.; Caputo, B. Modeling the Background for Incremental Learning in Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9230–9239. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing Through ADE20K Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017. [Google Scholar]
- Caesar, H.; Uijlings, J.; Ferrari, V. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1209–1218. [Google Scholar]
- Liang-Chieh, C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Ding, H.; Jiang, X.; Shuai, B.; Liu, A.Q.; Wang, G. Context contrasted feature and gated multi-scale aggregation for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2393–2402. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-maximization attention networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9167–9176. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4003–4012. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation From a Sequence-to-Sequence Perspective With Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 7262–7272. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-Attention Mask Transformer for Universal Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2001–2010. [Google Scholar]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual learning with deep generative replay. In Proceedings of the 30th Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kemker, R.; Kanan, C. FearNet: Brain-Inspired Model for Incremental Learning. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Castro, F.M.; Marín-Jiménez, M.J.; Guil, N.; Schmid, C.; Alahari, K. End-to-end incremental learning. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 233–248. [Google Scholar]
- Hayes, T.L.; Kafle, K.; Shrestha, R.; Acharya, M.; Kanan, C. Remind your neural network to prevent catastrophic forgetting. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 466–483. [Google Scholar]
- Zhu, F.; Zhang, X.Y.; Wang, C.; Yin, F.; Liu, C.L. Prototype augmentation and self-supervision for incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5871–5880. [Google Scholar]
- Zenke, F.; Poole, B.; Ganguli, S. Continual learning through synaptic intelligence. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 3987–3995. [Google Scholar]
- Aljundi, R.; Babiloni, F.; Elhoseiny, M.; Rohrbach, M.; Tuytelaars, T. Memory aware synapses: Learning what (not) to forget. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 139–154. [Google Scholar]
- Hou, S.; Pan, X.; Loy, C.C.; Wang, Z.; Lin, D. Learning a unified classifier incrementally via rebalancing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 831–839. [Google Scholar]
- Dhar, P.; Singh, R.V.; Peng, K.C.; Wu, Z.; Chellappa, R. Learning without memorizing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5138–5146. [Google Scholar]
- Douillard, A.; Cord, M.; Ollion, C.; Robert, T.; Valle, E. Podnet: Pooled outputs distillation for small-tasks incremental learning. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 86–102. [Google Scholar]
- Xiang, Y.; Fu, Y.; Ji, P.; Huang, H. Incremental learning using conditional adversarial networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6619–6628. [Google Scholar]
- Ebrahimi, S.; Meier, F.; Calandra, R.; Darrell, T.; Rohrbach, M. Adversarial continual learning. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 386–402. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Pan, P.; Swaroop, S.; Immer, A.; Eschenhagen, R.; Turner, R.; Khan, M.E.E. Continual deep learning by functional regularisation of memorable past. Adv. Neural Inf. Process. Syst. 2020, 33, 4453–4464. [Google Scholar]
- Zhao, B.; Xiao, X.; Gan, G.; Zhang, B.; Xia, S.T. Maintaining discrimination and fairness in class incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13208–13217. [Google Scholar]
- Frankle, J.; Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv 2018, arXiv:1803.03635. [Google Scholar]
- Golkar, S.; Kagan, M.; Cho, K. Continual learning via neural pruning. arXiv 2019, arXiv:1903.04476. [Google Scholar]
- Hung, C.Y.; Tu, C.H.; Wu, C.E.; Chen, C.H.; Chan, Y.M.; Chen, C.S. Compacting, picking and growing for unforgetting continual learning. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Feng, T.; Wang, M.; Yuan, H. Overcoming catastrophic forgetting in incremental object detection via elastic response distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9427–9436. [Google Scholar]
- Yang, B.; Deng, X.; Shi, H.; Li, C.; Zhang, G.; Xu, H.; Zhao, S.; Lin, L.; Liang, X. Continual object detection via prototypical task correlation guided gating mechanism. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9255–9264. [Google Scholar]
- Ganea, D.A.; Boom, B.; Poppe, R. Incremental few-shot instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1185–1194. [Google Scholar]
- Nguyen, K.; Todorovic, S. ifs-rcnn: An incremental few-shot instance segmenter. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7010–7019. [Google Scholar]
- Yan, S.; Zhou, J.; Xie, J.; Zhang, S.; He, X. An em framework for online incremental learning of semantic segmentation. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 3052–3060. [Google Scholar]
- Phan, M.H.; Phung, S.L.; Tran-Thanh, L.; Bouzerdoum, A. Class Similarity Weighted Knowledge Distillation for Continual Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16866–16875. [Google Scholar]
- Stan, S.; Rostami, M. Unsupervised model adaptation for continual semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 2593–2601. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Hariharan, B.; Arbelaez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic Contours from Inverse Detectors. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bulo, S.R.; Porzi, L.; Kontschieder, P. In-place activated batchnorm for memory-optimized training of dnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5639–5647. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Cong, W.; Cong, Y.; Dong, J.; Sun, G.; Ding, H. Gradient-Semantic Compensation for Incremental Semantic Segmentation. arXiv 2023, arXiv:2307.10822. [Google Scholar]
- Yang, G.; Fini, E.; Xu, D.; Rota, P.; Ding, M.; Nabi, M.; Alameda-Pineda, X.; Ricci, E. Uncertainty-Aware Contrastive Distillation for Incremental Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 2567–2581. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.; Fini, E.; Xu, D.; Rota, P.; Ding, M.; Hao, T.; Alameda-Pineda, X.; Ricci, E. Continual Attentive Fusion for Incremental Learning in Semantic Segmentation. IEEE Trans. Multimed. 2022, 25, 3841–3854. [Google Scholar] [CrossRef]
- Lin, Z.; Wang, Z.; Zhang, Y. Continual Semantic Segmentation via Structure Preserving and Projected Feature Alignment. In Proceedings of the European conference on computer vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 345–361. [Google Scholar]
- Goswami, D.; Schuster, R.; van de Weijer, J.; Stricker, D. Attribution-Aware Weight Transfer: A Warm-Start Initialization for Class-Incremental Semantic Segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–7 January 2023; pp. 3195–3204. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 19-1 (2 Steps) | 15-5 (2 Steps) | 15-1 (6 Steps) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0–19 | 20 | All | 0–15 | 16–20 | All | 0–15 | 16–20 | All | |
| ILT [6] | 67.75 | 10.88 | 65.05 | 67.08 | 39.23 | 60.45 | 8.75 | 7.99 | 8.56 |
| MiB [12] | 71.43 | 23.59 | 69.15 | 76.37 | 49.97 | 70.08 | 34.22 | 13.50 | 29.29 |
| SDR [8] | 69.10 | 32.60 | 67.40 | 75.40 | 52.60 | 69.90 | 44.70 | 21.80 | 39.20 |
| PLOP [7] | 75.35 | 37.35 | 73.54 | 75.73 | 51.71 | 70.09 | 65.12 | 21.11 | 54.64 |
| RECALL [9] | 67.90 | 53.50 | 68.40 | 66.60 | 50.90 | 64.00 | 65.70 | 47.80 | 62.70 |
| UCD [65] | 71.40 | 47.30 | 70.00 | 77.50 | 53.10 | 71.30 | 49.00 | 19.50 | 41.90 |
| CAF [66] | 75.50 | 34.80 | 73.40 | 77.20 | 49.90 | 70.40 | 55.70 | 14.10 | 45.30 |
| RCN [10] | - | - | - | 78.80 | 52.00 | 72.40 | 70.60 | 23.70 | 59.40 |
| RBC [11] | 77.26 | 55.60 | 76.23 | 76.59 | 52.78 | 70.92 | 69.54 | 38.44 | 62.14 |
| SPPFA [67] | 76.50 | 36.20 | 74.60 | 78.10 | 52.90 | 72.10 | 66.20 | 23.30 | 56.00 |
| AWT [68] | - | - | - | 77.30 | 52.90 | 71.50 | 59.10 | 17.20 | 49.10 |
| GSC [64] | 76.90 | 42.70 | 75.30 | 78.30 | 54.20 | 72.60 | 72.10 | 24.40 | 60.80 |
| Ours | 77.01 | 39.97 | 75.25 | 78.82 | 56.16 | 73.43 | 73.92 | 28.37 | 63.08 |
| Joint | 77.40 | 78.00 | 77.40 | 79.10 | 72.56 | 77.39 | 79.10 | 72.56 | 77.39 |
| Method | 19-1 (2 Steps) | 15-5 (2 Steps) | 15-1 (6 Steps) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0–19 | 20 | All | 0–15 | 16–20 | All | 0–15 | 16–20 | All | |
| ILT [6] | 69.10 | 16.40 | 66.40 | 63.20 | 39.50 | 57.30 | 3.70 | 5.70 | 4.20 |
| MiB [12] | 69.60 | 25.60 | 67.40 | 71.80 | 43.30 | 64.70 | 46.20 | 12.90 | 37.90 |
| SDR [8] | 69.90 | 37.30 | 68.40 | 73.50 | 47.30 | 67.20 | 59.20 | 12.90 | 48.10 |
| PLOP [7] | 75.37 | 38.89 | 73.64 | 71.00 | 42.82 | 64.29 | 57.86 | 13.67 | 46.48 |
| RECALL [9] | 65.20 | 50.10 | 65.80 | 66.30 | 49.80 | 63.50 | 66.00 | 44.90 | 62.10 |
| UCD [65] | 73.40 | 33.70 | 71.50 | 71.90 | 49.50 | 66.20 | 53.10 | 13.00 | 42.90 |
| CAF [66] | 75.50 | 30.80 | 73.30 | 72.90 | 42.10 | 65.20 | 57.20 | 15.50 | 46.70 |
| RCN [10] | - | - | - | 75.00 | 42.80 | 67.30 | 66.10 | 18.20 | 54.70 |
| RBC [11] | 76.43 | 45.79 | 75.01 | 75.12 | 49.71 | 69.89 | 61.68 | 19.52 | 51.60 |
| SPPFA [67] | 75.50 | 38.00 | 73.70 | 75.30 | 48.70 | 69.00 | 59.60 | 15.60 | 49.10 |
| GSC [64] | 75.90 | 31.00 | 74.00 | 74.40 | 45.80 | 67.60 | 67.20 | 19.20 | 55.80 |
| Ours | 77.10 | 39.91 | 75.33 | 75.42 | 44.84 | 68.14 | 69.38 | 19.00 | 57.38 |
| Joint | 77.40 | 78.00 | 77.40 | 79.10 | 72.56 | 77.39 | 79.10 | 72.56 | 77.39 |
| Method | 100-50 (2 Steps) | 50-50 (3 Steps) | 100-10 (6 Steps) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0–100 | 101–150 | All | 0–50 | 51–150 | All | 0–100 | 101–150 | All | |
| ILT [6] | 18.29 | 14.40 | 17.00 | 3.53 | 12.85 | 9.70 | 0.11 | 3.06 | 1.09 |
| MiB [12] | 40.52 | 17.17 | 32.79 | 45.57 | 21.01 | 29.31 | 38.21 | 11.12 | 29.24 |
| PLOP [7] | 41.87 | 14.89 | 32.94 | 48.83 | 20.99 | 30.40 | 40.48 | 13.61 | 31.59 |
| UCD [65] | 42.12 | 15.84 | 33.31 | 47.12 | 24.12 | 31.79 | 40.80 | 15.23 | 32.29 |
| RCN [10] | 42.30 | 18.80 | 34.50 | 48.30 | 25.00 | 32.50 | 39.30 | 17.60 | 32.10 |
| RBC [11] | 42.90 | 21.49 | 35.81 | 49.59 | 26.32 | 34.18 | 39.01 | 21.67 | 33.27 |
| SPPFA [67] | 42.90 | 19.90 | 35.20 | 49.80 | 23.90 | 32.50 | 41.00 | 12.50 | 31.50 |
| AWT [68] | 40.90 | 24.70 | 35.60 | 46.60 | 26.85 | 33.50 | 39.10 | 21.28 | 33.20 |
| GSC [64] | 42.40 | 19.20 | 34.80 | 46.20 | 26.20 | 33.00 | 40.80 | 17.60 | 32.60 |
| Ours | 42.32 | 22.38 | 35.72 | 48.71 | 25.18 | 33.22 | 43.23 | 20.83 | 35.14 |
| Joint | 43.90 | 27.20 | 38.30 | 50.90 | 32.10 | 38.30 | 43.90 | 27.20 | 38.30 |
| PLOP [7] | RCN [10] | SGD | KDD | 15-1 (6 Steps) |
|---|---|---|---|---|
| ✔ | 58.32 | |||
| ✔ | 59.64 | |||
| ✔ | 62.03 | |||
| ✔ | ✔ | 62.17 | ||
| ✔ | ✔ | 62.81 | ||
| ✔ | ✔ | 63.08 |
| Kernel Sizes | 15-1 (6 Steps) |
|---|---|
| (8,8,8) | 49.90 |
| (4,4,4) | 58.96 |
| (2,2,2) | 63.02 |
| (2,4,8) | 49.97 |
| (8,4,2) | 63.08 |
| Method | 15-1 (6 Steps) |
|---|---|
| Strip Pooling | 62.17 |
| Spatial Pooling | 48.55 |
| Channel Pooling | 44.12 |
| Spatial and Channel Pooling | 62.81 |
| Max Pooling | 62.42 |
| Group Pooling | 63.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Z.; Zhang, X.; Shi, Z. Scale-Hybrid Group Distillation with Knowledge Disentangling for Continual Semantic Segmentation. Sensors 2023, 23, 7820. https://doi.org/10.3390/s23187820
Song Z, Zhang X, Shi Z. Scale-Hybrid Group Distillation with Knowledge Disentangling for Continual Semantic Segmentation. Sensors. 2023; 23(18):7820. https://doi.org/10.3390/s23187820
Chicago/Turabian StyleSong, Zichen, Xiaoliang Zhang, and Zhaofeng Shi. 2023. "Scale-Hybrid Group Distillation with Knowledge Disentangling for Continual Semantic Segmentation" Sensors 23, no. 18: 7820. https://doi.org/10.3390/s23187820