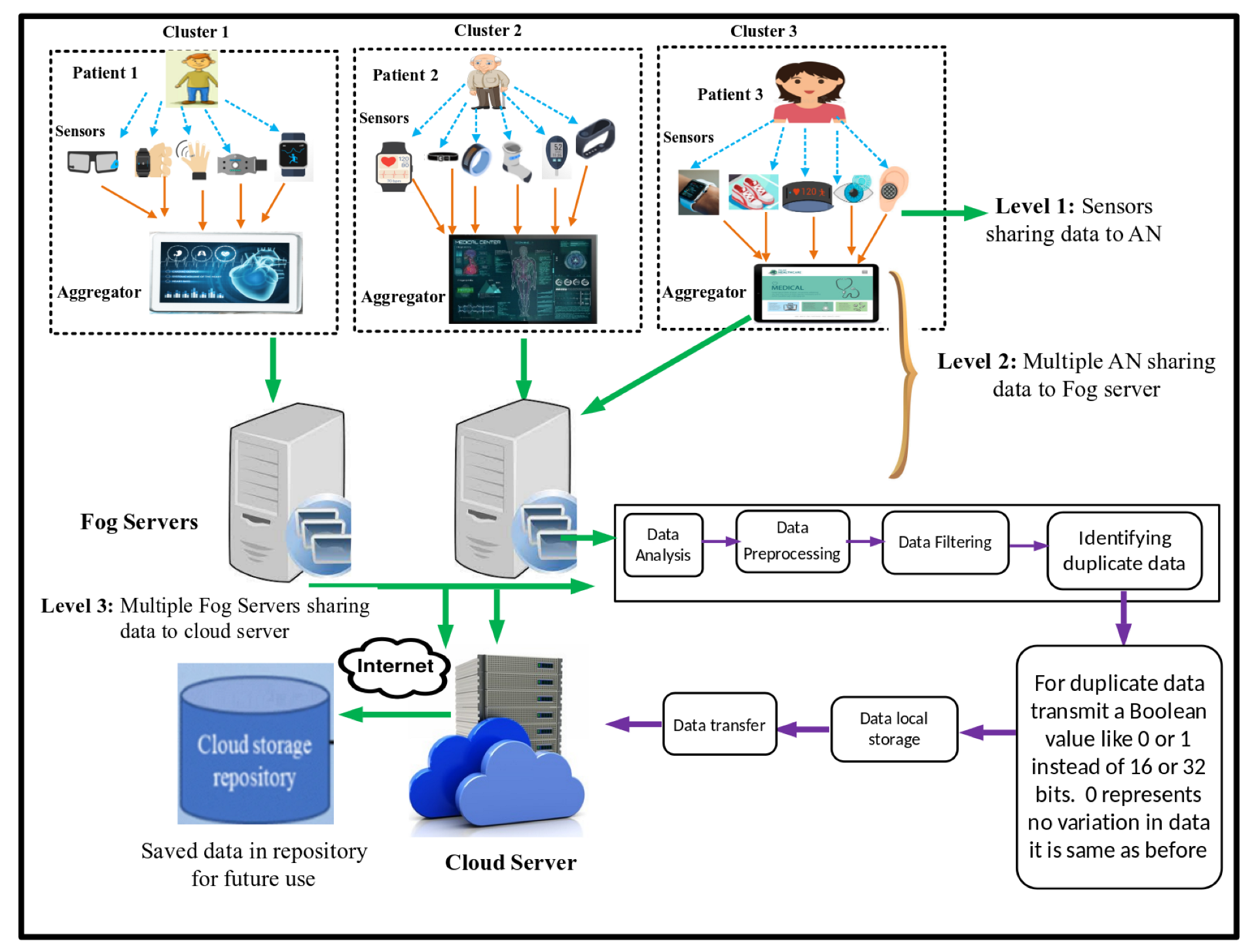
This section describes the literature on data aggregation schemes and the role of AI in enhancing the overall mechanism. The data are gathered from many sensor nodes that collect the data and share the aggregated data with the base station (BS) and central repositories in the cloud in IoMT and wireless sensor networks (WSNs). Data aggregation aims to efficiently transmit large amounts of data to BS to increase the network’s lifespan. For efficient data aggregation, artificial-intelligence-based schemes have been explored. The AI techniques described in this part have been used in many of the most recent research in this field.
2.1. Data Aggregation Using Artificial Intelligence Techniques
Kulkarni et al. highlighted the use of a computational intelligence (CI)-based algorithm. These CI-based algorithms deal efficiently with dynamic environment sand limited node energy. As CI-based solutions are not perfect under some conditions, artificial neural networks (ANNs), genetic algorithms (GAs), and particle swarm optimization (PSA) can be used [
41]. In [
42], swarm-intelligence-based schemes were elaborated that have improved network lifespan and use energy efficiently. Chen et al. presented the data aggregation ACO algorithm (DAACA) to utilize network energy efficiently, which is based on the ant colony optimization algorithm approach. The DAACA has features of both local and global pheromone methods. The different versions of DAACA assist in reducing computational and communicational overhead and increasing node life. The advantage of this scheme is that it features fault tolerance, low complexity, and higher flexibility [
43].
Imitating the dynamic nature of a river, intelligent water drops (IWDs) are used in WSNs, where every drop shows a solution. This method is deployed after amendments in tree-based data aggregation to obtain optimal solutions [
44]. To economically use energy in WSNs, an ant-colony-based optimization scheme called the minimum incremental dissemination tree (AMIDT) was introduced. This scheme consists of two main stages: in the first stage, an online tree is formed; during the second phase, a path- and reference-based heuristic is applied. AIMDT has reduced cost and energy utilization compared with existing schemes [
45]. For different optimization issues, the ABC algorithm outperforms others in cases where nodes do not directly transmit data to the aggregator node or BS. Knowing the best traveling path of a mobile robot is important for reducing energy consumption. For this issue, the ABC algorithm performs better than greedy algorithms. The positive point of this scheme is that the retrieved results are very stable but cannot be implemented in the case of multiple robots [
46]. As the number of sensors increases, the data they produce also increase, which is problematic for data mining techniques. To overcome this problem, a decentralized scheme using a WSN neural network was presented. A data technique was trained using data gathered from nodes in the network. The system performs well and was used for higher WSNs [
47]. An optimum cluster was chosen using the shuffled frog algorithm. It showed better efficacy, fast searching, and optimal energy usage. CHs were selected based on the residual energy of WSN nodes [
48]. The PSO method was used to aggregate data from complex and large networks. These methods assist in finding a better transmission path between nodes that lessens hop distances but increase hop counts. This method has lower energy consumption and is suitable for the dynamic nature of the environment [
49].
The F-LEACH scheme was presented to extend the network life span and economical energy utilization. Selecting an appropriate cluster head improves network performance. For this purpose, the FIS function was used to determine cluster heads in the network. FIS considers the distance of nodes from the base station and residual energy level; a node with a low distance from the BS and high energy has a high probability of being selected as the cluster head. If N nodes are in the network and the total clusters are K, there are approximately N/K clusters in the network. One of them is a CH node, while others are ordinary nodes. The proposed scheme has fewer dead nodes, improved residual energy, and improved work performance up to 5–20% [
50].
Abid et al. designed a scheme that deals with the problem of efficient data aggregation and transmission in time-constrained wireless sensor networks. For the aggregation of data, multilevel clustering was used, in which a structure-free approach was considered. In this clustering, nodes are divided into large clusters during first-phase clustering. Each group has one cluster head (CH) collecting member data. The CH node needs more energy to work efficiently, so it is important to check the energy level of nodes from time to time and select the CH node intelligently. For this purpose, the event-driven cluster head election (EDC) algorithm was used in which node residual energy is checked against threshold energy E0 and checking the CF bit. If the current CH fulfills both conditions, no change occurs. Otherwise, a node near the present CH is selected as the next CH to reduce energy wastage. The proposed scheme was simulated using NS-2, and the results proved that the proposed method achieved better aggregation gain and lower delay. The drawback of the process is that if the energy level of primary CH dissipates, the communication of the whole network is affected [
51]. Singh et al. proposed an energy-efficient scheme to overcome the probability of transmitting redundant data and balanced energy utilization. For clustering, four main parameters were considered in the fitness function: the energy level of the node, density near CH, Euclidean distance of the CH and the sensor nodes calculated usinf Equation (
1) [
52], and distance from CH to BS.
where
denotes the maximum Euclidean distance among nodes and the respective
, while
represents the total nodes lying in the communication range of egg e of a cluster named
k. to calculate the total amount of energy of nodes lies in a network; Equation (
2) [
52] is used.
Using a fitness function,
of the nodes are considered for
, and after calculating their cost, the best host nest is obtained.
denotes the maximum Euclidean distance among nodes and their respective
; Equation (
3) [
52] is used to calculate cost
C. The value of
is considered as 0.5. The lower value obtained by
and
assists in reducing the intracluster distance, which ultimately helps with the selection of ideal
.
Vasim et al. presented a scheme emphasizing prolonging network life while efficiently consuming energy. The proposed method consists of four important phases. In phase 1, node mobility is monitored using the distance formula. Mobility dissipates energy quickly, so the node having low mobility is selected to minimize utilization. For determining CH, the AE-LEACH algorithm is implemented in the next phase, which uses residual energy, and distances from BS are used. A threshold value is calculated for all the nodes that lie in the range of zero or one. A certain node works as a head if the computed value exceeds the capacity. The CH broadcasts messages in the network; all nodes that reply to that message become cluster group members. Member nodes transmit data to the CH, which are sent to the BS after performing aggregations. The particle filter algorithm estimates the targets’ next state in the third phase. In the last step, the Gini index is used to check the even consumption of energy level. NS-2 evaluates the proposed scheme and provides better results in network lifetime, energy utilization, and residual energy. The benefit of this scheme is that the CH is not fixed and changes frequently, reducing the burden on the node playing the role of CH. The drawback of this technique is that the case of malicious nodes is not handled efficiently [
53].
Amutha presented a hybrid scheme that caters to both cases when the sink node is static and moveable. In both scenarios, the CH is selected by checking some circumstances, including residual energy, node density, distance factor, and node centrality. The node centrality is a new parameter that has yet to be included in previous studies, which leads to selecting the optimal CH; the members a short distance from the CH and high energy are clustered under that head. For the static case, static sink nodes (SSNs) are placed in left, right, and center in an area of interest (AOI) to check the CH’s energy level and effective path. In the second case, the mobile sink (MS) node moves randomly to collect data. The mobility model was introduced to resolve the hot-spot problem in a later approach. The simulation was conducted using NS-2; for different metrics, it showed better energy consumption and data delivery, low delay, and higher throughput than former schemes. The advantage of this scheme is that in the case of a static sink node, all possible directions for calculating the optimal path to disseminate aggregated data to SN are considered. The problem in the case of MS is that it works well only for short-range communication but not long-range communication [
54].
Yan et al. proposed using game theory to cluster sensor nodes and reduce energy consumption in wireless sensor networks (WSNs). Each sensor node is viewed as a player node and uses its current state (active or passive) to cluster them. GEC introduces the transition of active nodes into a sleeping state and vice versa when required and introduces penalty principles to control energy violations caused by selfish or greedy nodes in the network. These penalties aim to reduce the energy consumption of communicating nodes in the network [
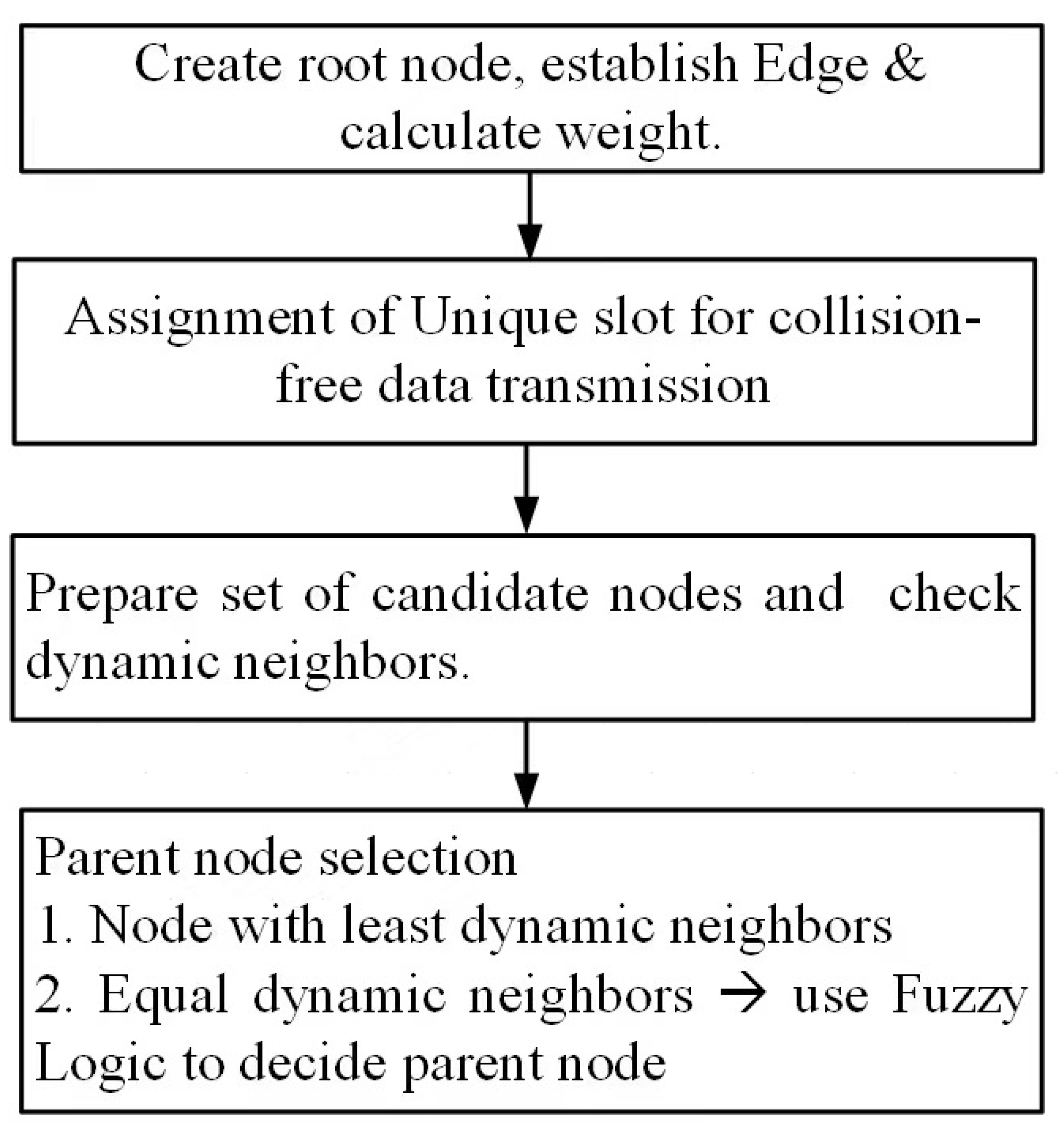
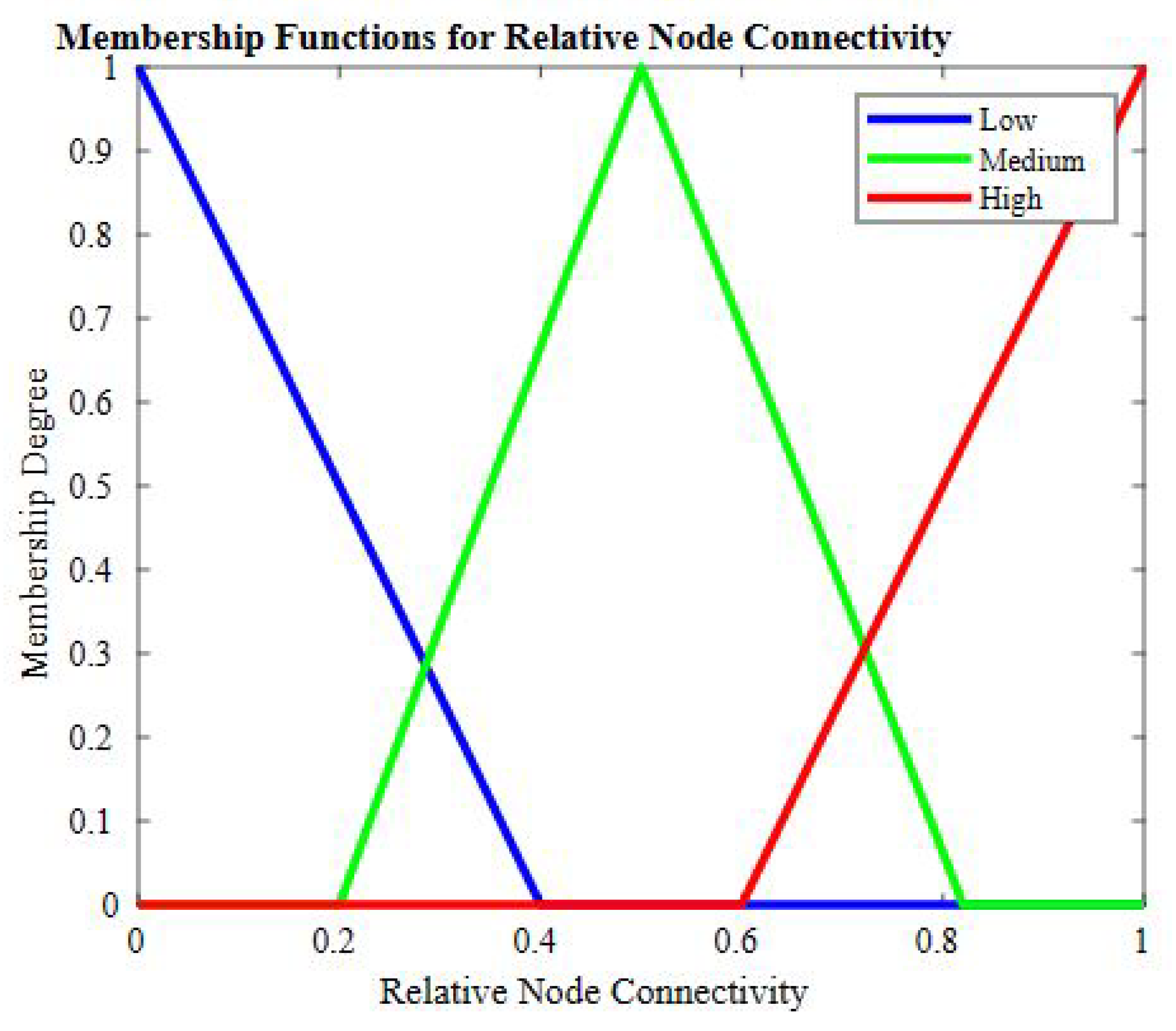
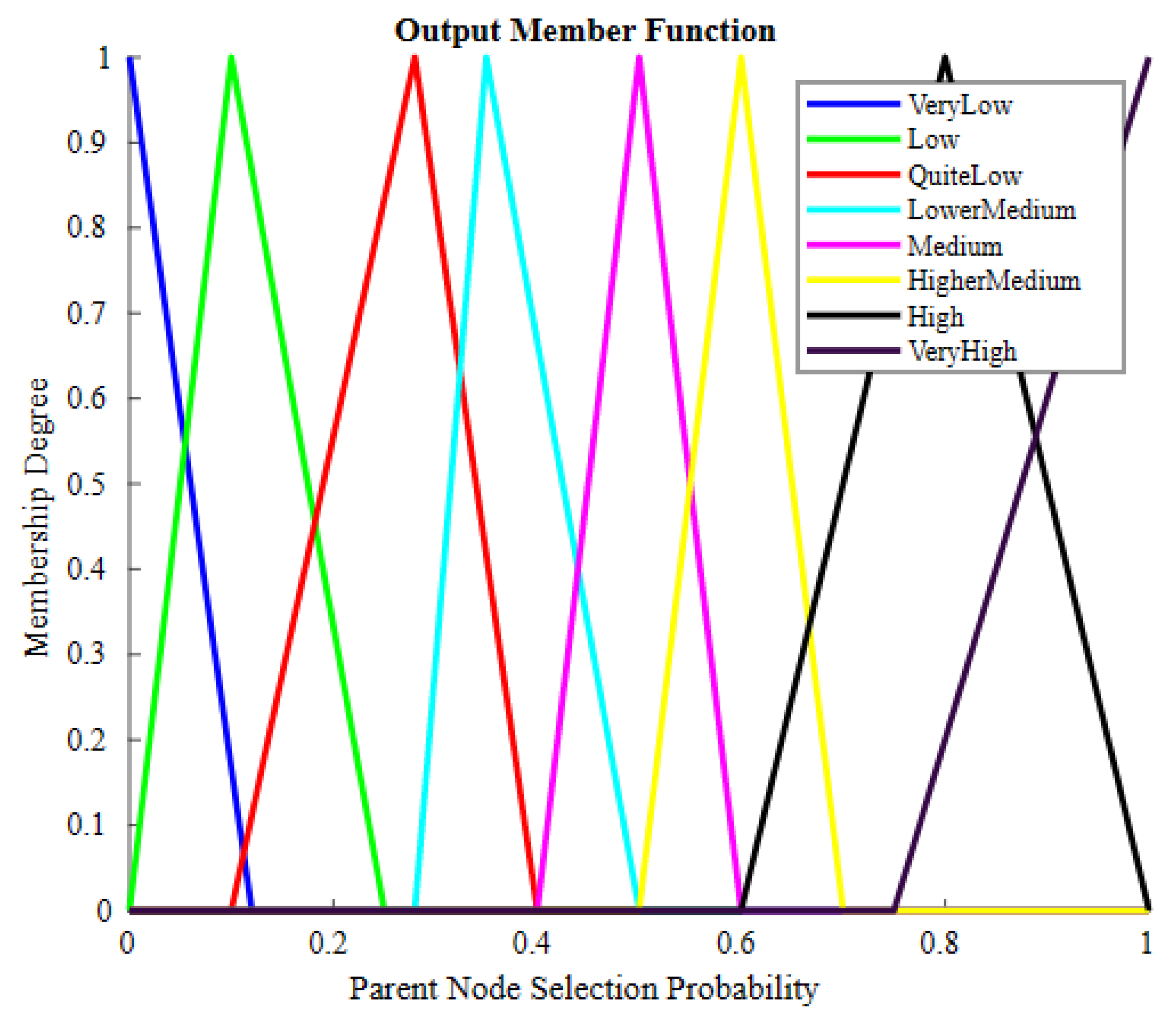
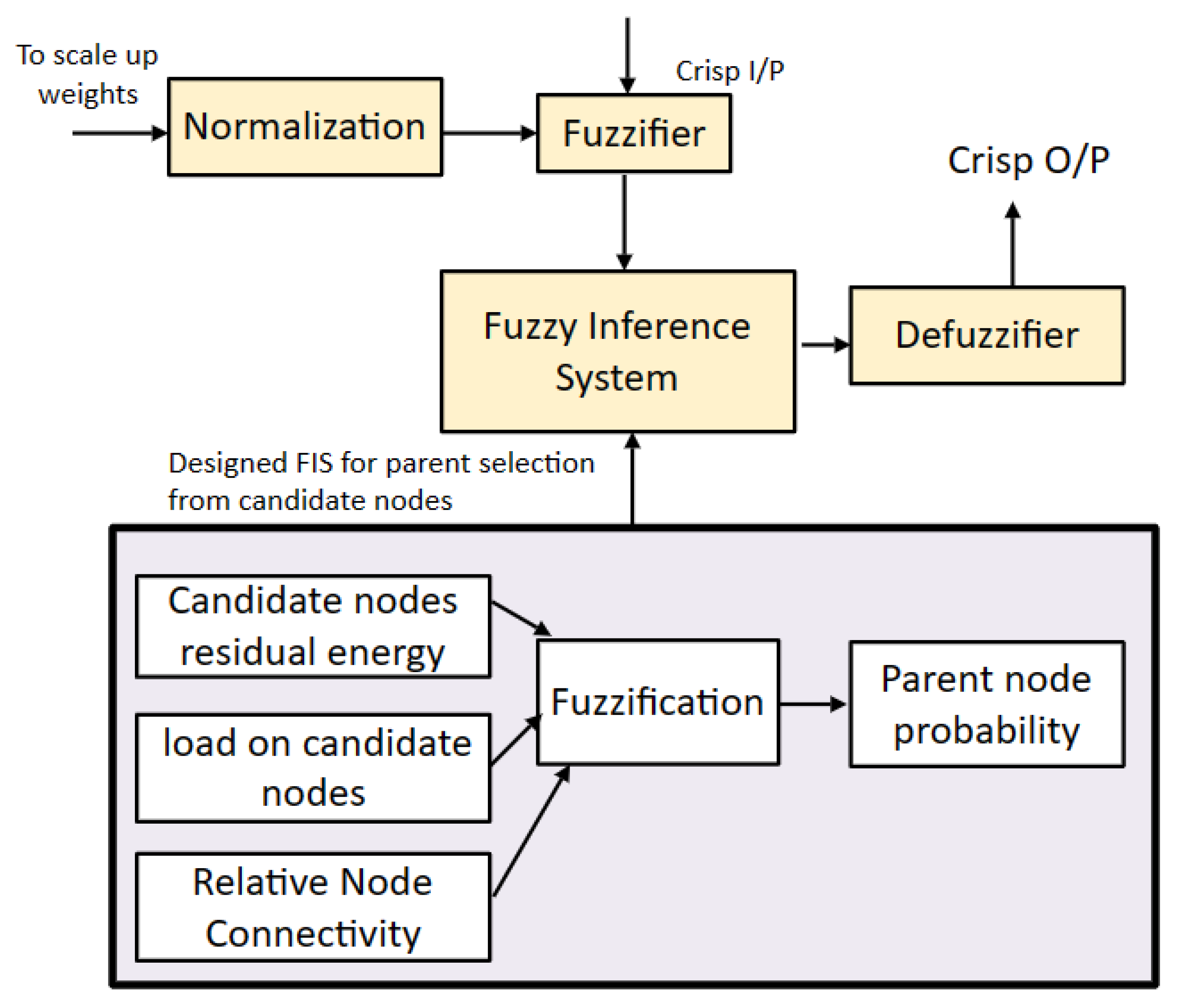
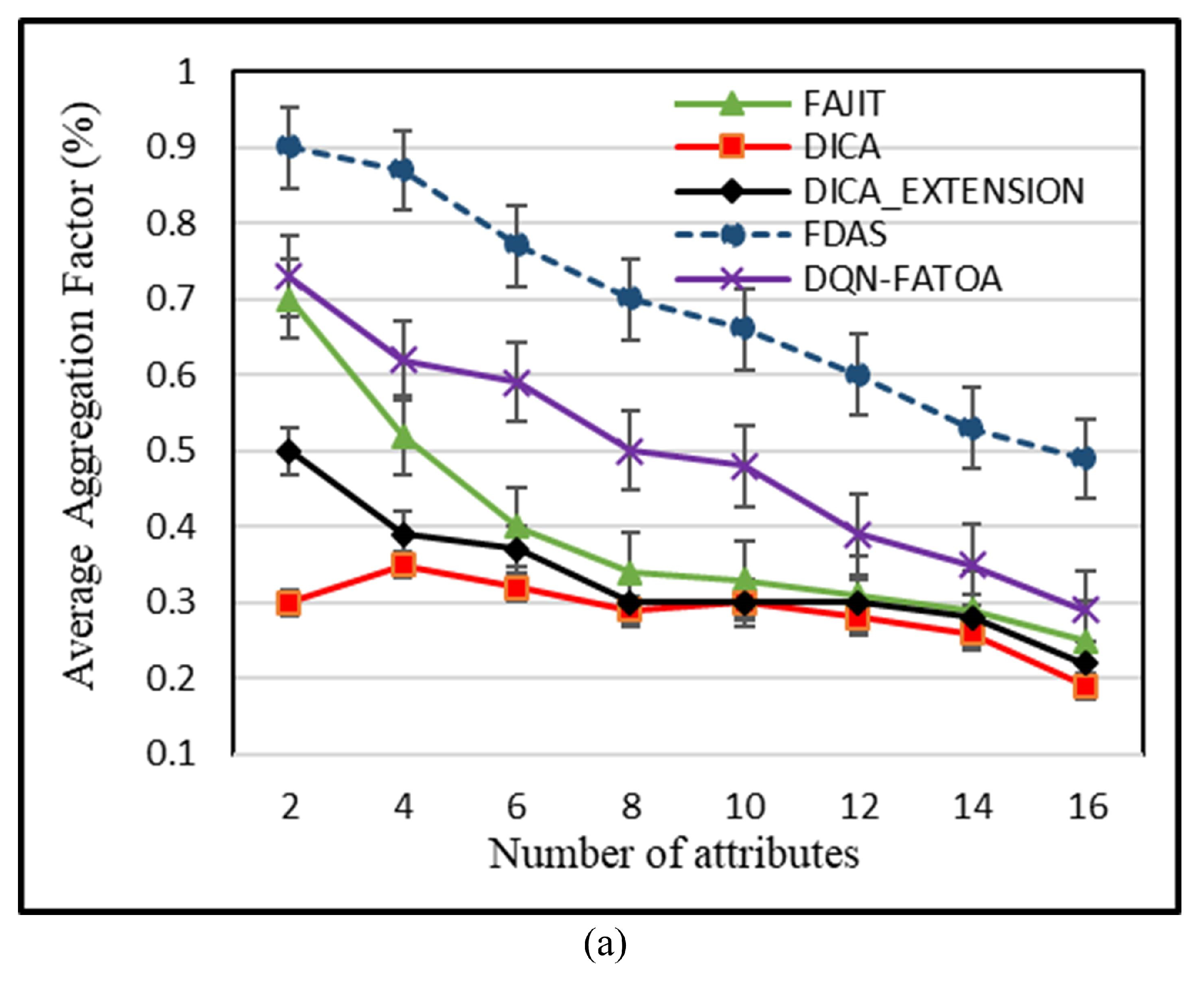
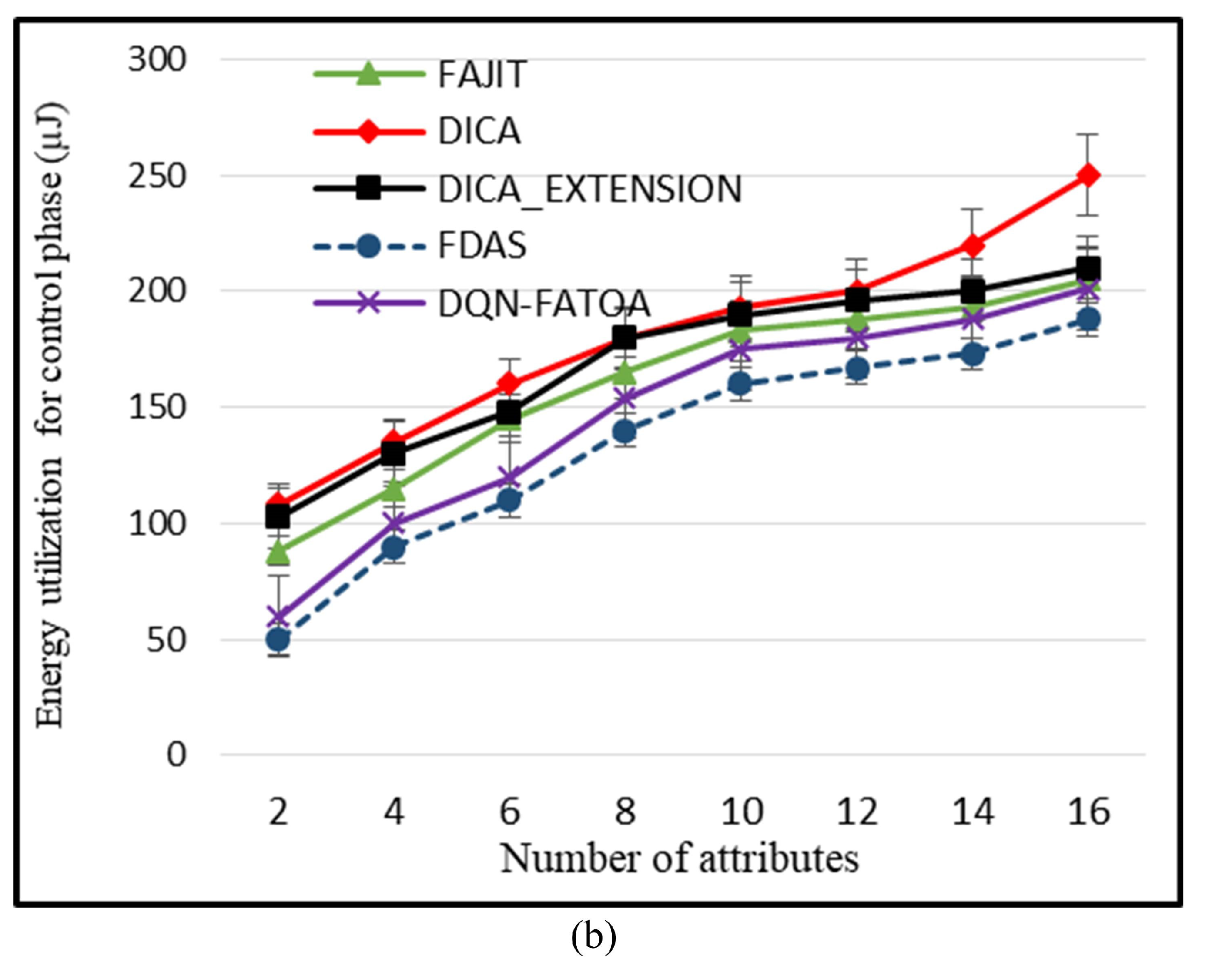
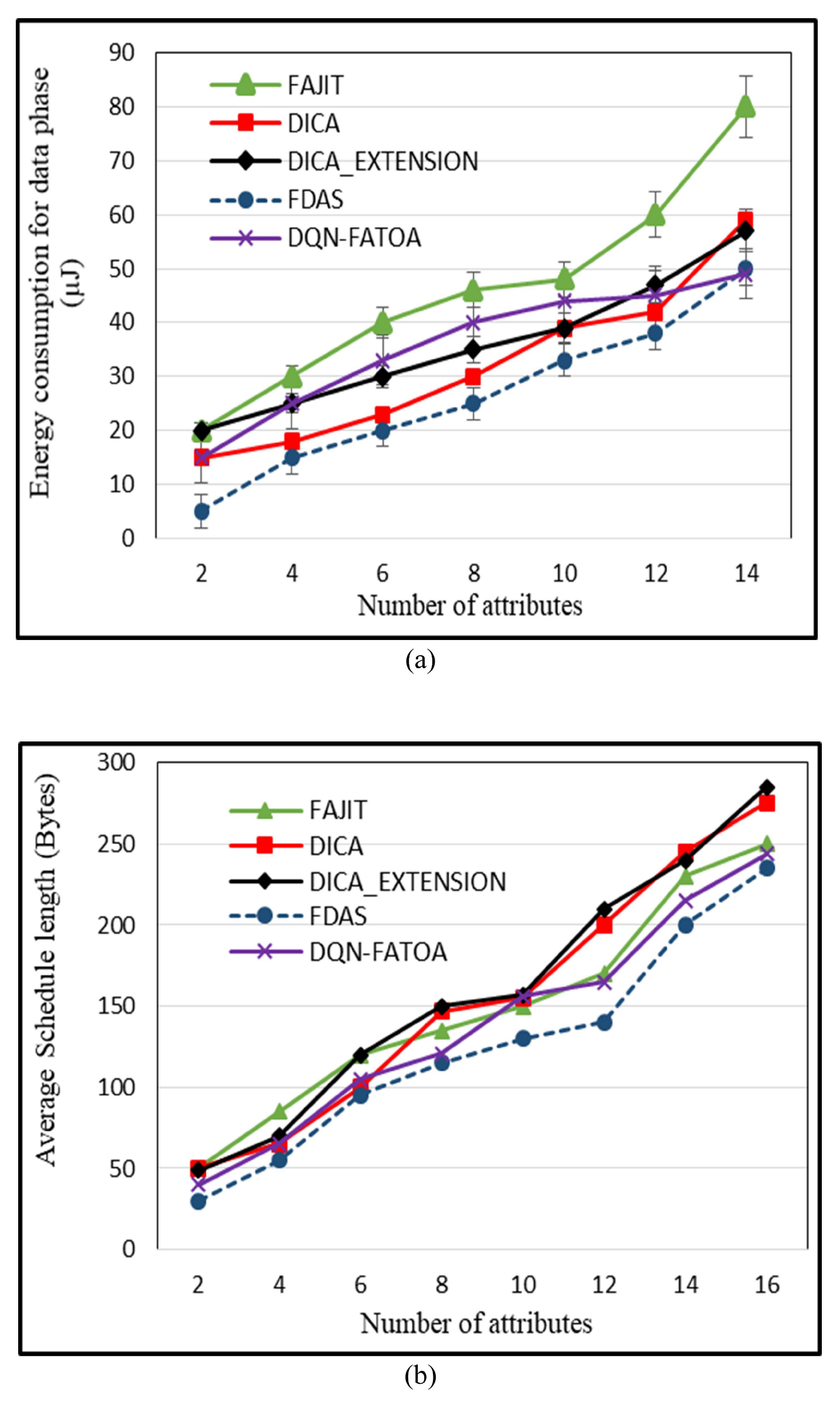
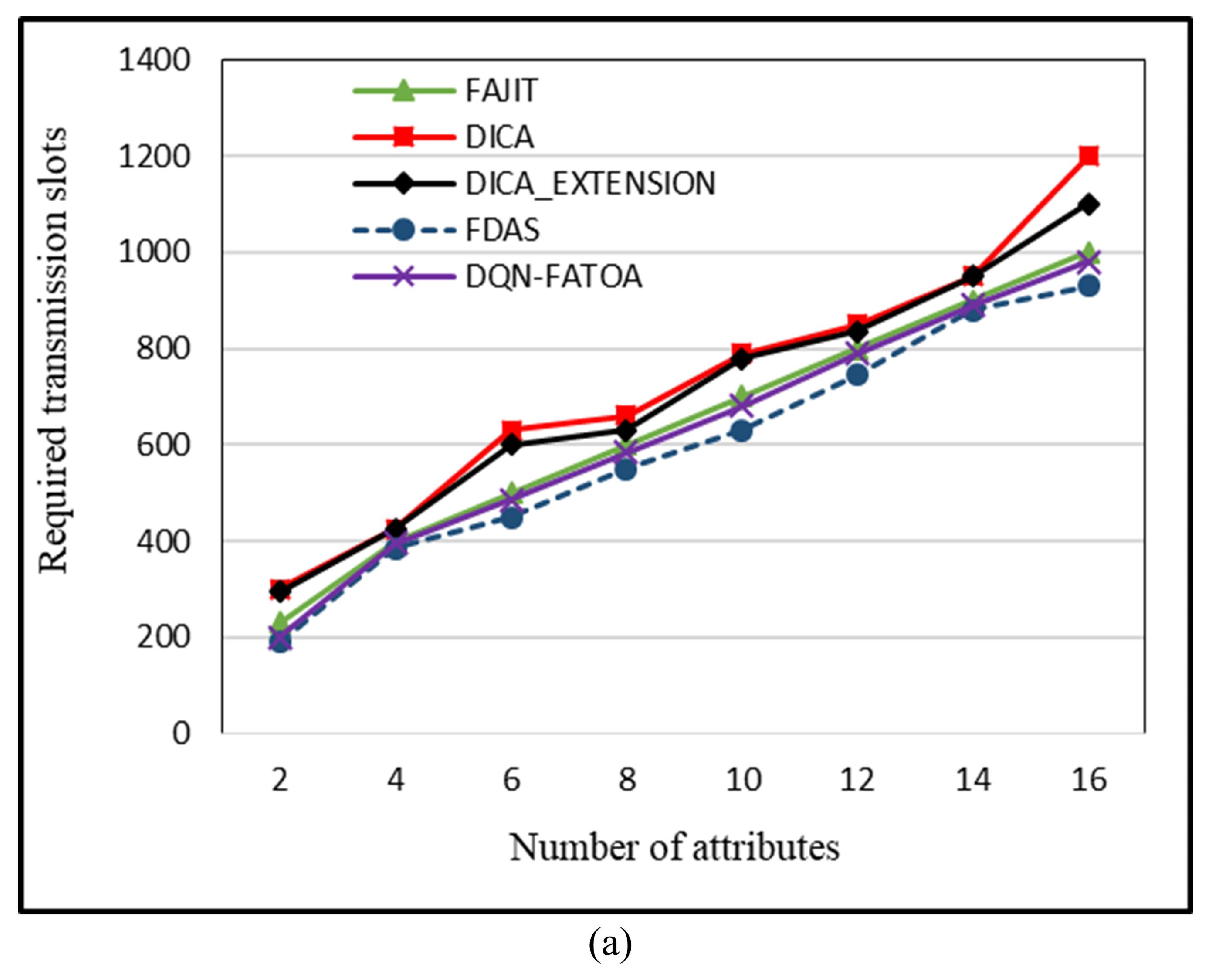
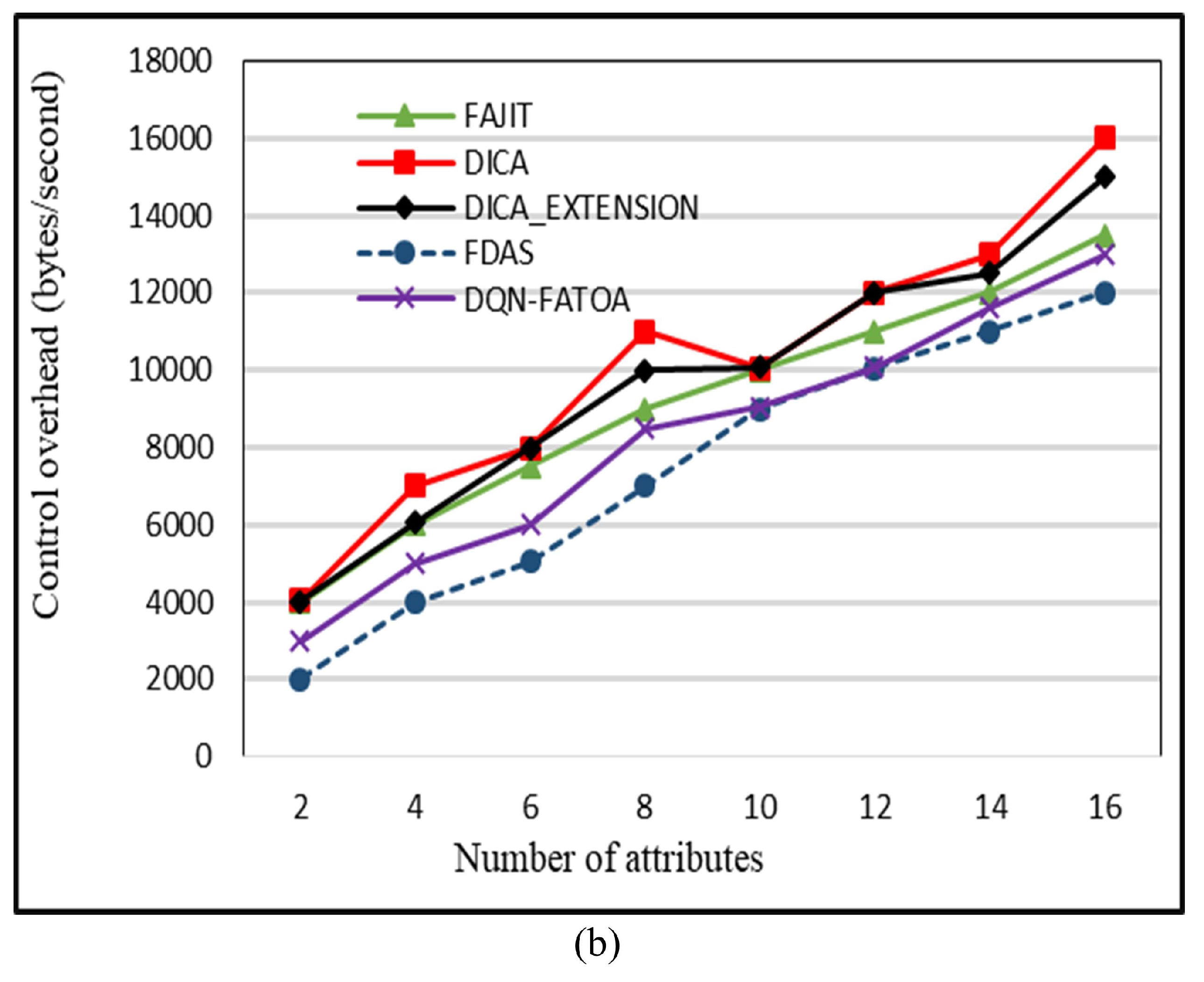
55]. The benefit of this scheme is that it provides reliable performance even in harsh environments. The drawback of this scheme is that it is not suitable for heterogeneous WSNs. To reduce energy consumption in a heterogeneous WSN environment, Bhushan et al. presented a fuzzy-attribute-based joint integrated scheduling and tree formation technique, which intelligently selects different parents for different types of nodes. Two phases were defined: control phase and data phase. In the control phase, nodes choose lots and parents, and they have information about the number and type of data packets and the type of packet that the node itself has generated. In the second phase, nodes are created, and data are transmitted. For each outgoing data packet, a different parent can be chosen per its type. To fuzzify the system, min–max normalization is used to scale the weights. These weights act as membership functions, having small consequences with a straight connection to a node having a high probability of being selected as the parent for data aggregation and transmission to an SN. For packet t, a neighbor of type t is chosen; if it is present, data are forwarded to it. Otherwise, having the node’s neighbor of type t, data are forwarded to it. In case no such scenario occurs, the node with the fewest dynamic nodes is considered the parent node. For checking the performance of the proposed schemed FAJIT, a simulation was performed and compared with DICA and DICA_EXTENSION under different metrics. The results showed that FAJIT performs better than the previous two schemes. The benefit of this scheme is that it is considered a heterogeneous environment for sustaining energy levels. The drawback of the method is that complications increase when deploying it for large networks [
40].
In [
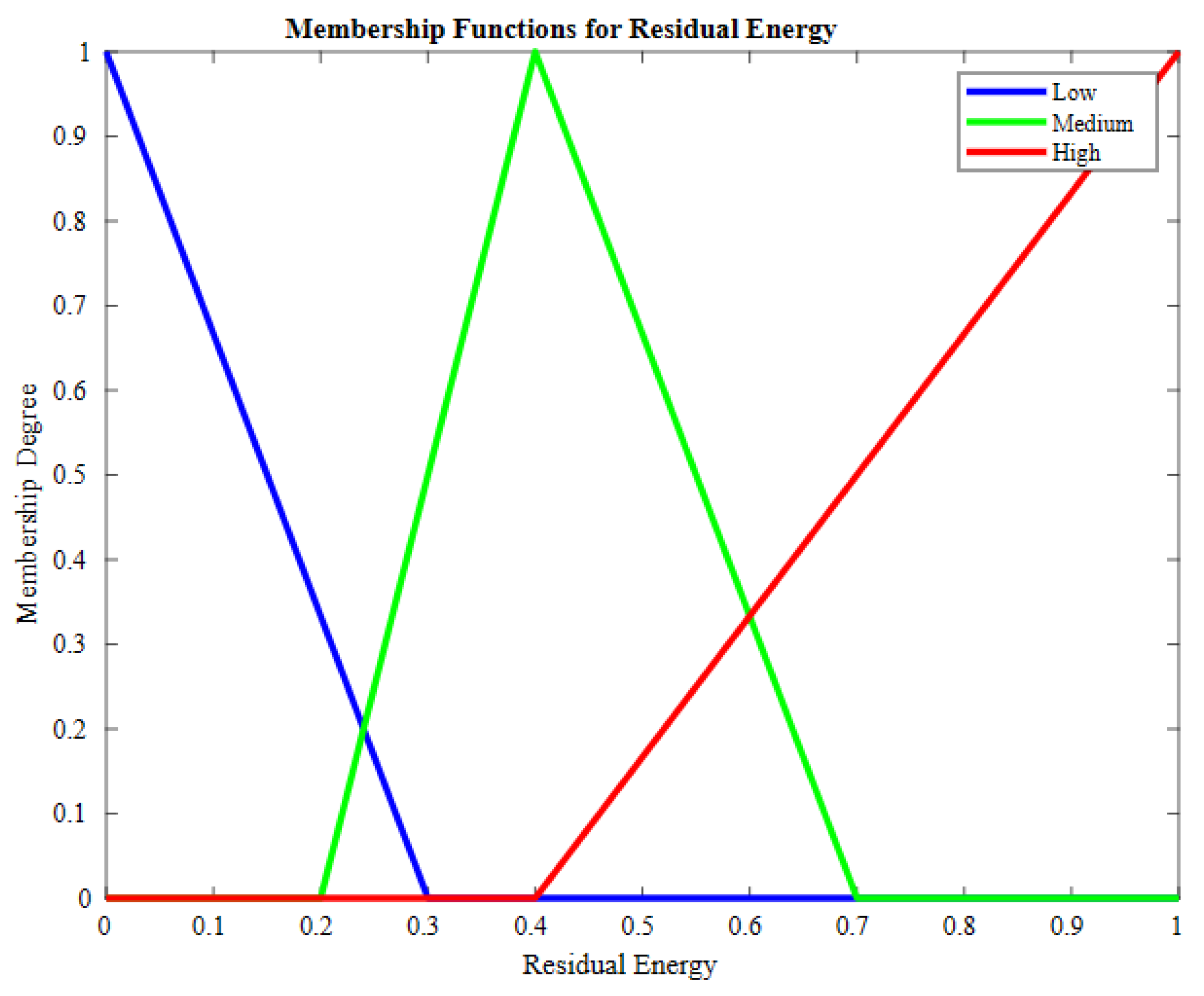
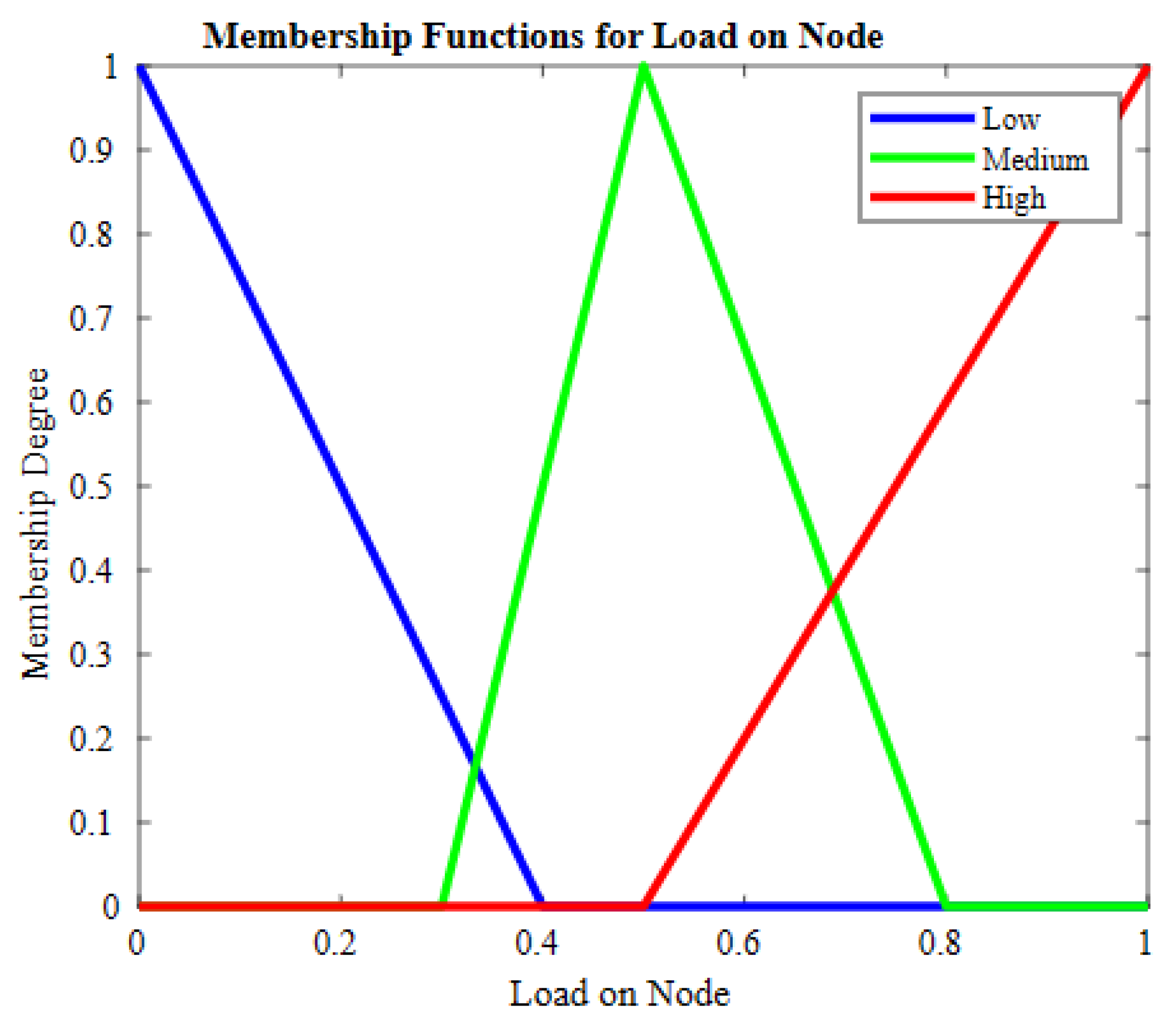
56], the author proposed a scheme for collecting data in which sensors are deployed. After that, clustering is performed, and data are saved into a repository. To cluster uncategorized data, the K-means clustering method is used. The proposed scheme, fuzzy-logic-based data aggregation (FLDA), uses fuzzy logic. Afterward, fuzzification and defuzzification are applied to obtain a discrete output to aggregate the most appropriate data, decreasing the volume of duplicate data. The proposed scheme was simulated in a MATLAB MATLAB 2018b environment, and the results showed that FLDA achieved better data persistency, higher network lifetime, and reduced energy utilization. The drawback of the scheme is that it works better under specified assumptions that cannot always be achieved as the density of nodes increases.
By considering the hot-spot or energy hole issue in WSNs, Ssert et al. presented a technique that uses energy economically. The proposed method, two-tier distributed fuzzy-logic-based protocol (TTDFP), is categorized into two tiers. In the primary tier, fuzzy logic is used to select CHs for unequal clustering via the process of the probabilistic model. In the second tier, the routing path is chosen. The cluster head generates the Min value, which is assigned as one. The fuzzy logic is applied if the min value increases and becomes >1. The proposed scheme was simulated with MATLAB, and the results showed that TTDFP achieved a higher ratio of the alive node’s residual energy until the last round. The advantage of this proposed distributed scheme is that the hot-spot problem is resolved. It balances and economically consumes power, which ultimately increases network lifespan. The limitation of the proposed method is that no procedure is initialized to lessen the load on the CH [
57].
The grid clustering method was introduced to efficiently aggregate data from nodes by utilizing an economical amount of energy. The whole area is divided into grids, and a CH is selected for each. The entire network acts as an environment, and the CH works as an agent. The nodes with a short distance and good link quality are more likely to be selected as aggregator nodes. Afterward, the sink node is placed occasionally in areas where a low amount of energy is used. For this purpose, the fruit fly optimization algorithm is used. MATLAB was used for simulation and generating results considering important metrics such as PLR, energy utilization, and throughput. The benefit of this scheme is that it reduces latency and enhances node lifetime by minimizing energy consumption. The drawback of the method is that complications arise, and performance degrades in the case of dense WSN [
58]. To maintain efficient data aggregation in heterogeneous networks, the scheme uses fuzzy logic scheduling, which takes two inputs: the residual energy of a node and the overlapping range of a node and the nodes in its vicinity. The output of the system is a suitable data rate. In the second stage, the binary tree of a CH is created, and the BS is responsible for implementing the dragonfly algorithm to create an aggregated tree. Afterward, high-priority nodes are placed as left and right children. If two nodes have the same priority level, in this case, the node with low priority is considered first. When the tree is completed, it is evaluated based on a fitness function. The fitness function is calculated using Equation (
4) [
23].
This equation checks factors including distance to the sink node, residual energy of
, and the number of CMs. Then, it evaluates the constructed tree based on the abovementioned terms and selects the best tree.
D shows the depth of the present aggregated tree,
n is the total
in the network,
c is the
in a current tree,
d is the distance between
and
is the maximum distance between CH and SN,
is the ultimate energy level of
, the
is the total CM in a cluster
, and
shows the entire CM in the group. The proposed scheme was simulated using NS, performing better than existing schemes. The benefit of this scheme is that it provides better data packet transmission because of a suitable aggregation tree that was not considered in previous methods. The drawback of this technique is that the CH has to bear a higher load that eventually consumes more energy [
59]. This protocol introduces a multipath for aggregated data to transmit crucial healthcare data to medical servers (MS) and reduce delay. The incoming data are divided into normal and emergency data. When biosensors send readings, if the generated data are beyond the normal range, it sets the threshold value as one. This sort of data are termed emergency data and are transmitted to cluster heads from the best routes with the lowest congestion rate. On the other hand, normal data are transferred from ordinary routes. Fuzzy logic is employed to rank the data. The scheme has a lower packet loss rate, and critical data are transmitted to the MS effectively, but the security perspective needs to be addressed [
60]. To resolve the hotspot problem in WBANs, a temperature-aware scheme was presented, which considers the temperature of nodes before selecting the CH. The clustering is performed for data aggregation based on fuzzy logic. The fuzzy logic considers route breakage, residual energy, and nodes having the same neighbors. Similar nodes lie in the same cluster and aggregate data efficiently. The proposed scheme consumes low power while transmitting data to the coordinator, but complexity increases in high-level heterogeneous environments [
61]. To understand the health situation of patients, the K-edge mechanism was introduced in a heterogeneous health-sector environment. In the initial phase, fuzzy logic is used to know the heart condition of patients. Then, a CNN mechanism is employed to determine the respiratory condition of patients. By using multianalysis and Mamdani fuzzy output, the patient’s condition is evaluated. The K-edge implementation provides better results regarding patient condition. The results demonstrated an accuracy of 98.68% for respiratory conditions and was suitable for performance in resource-restricted environments [
62]. In another method, to increase the efficacy of data transmission in the WBAN context, the aggregation node dynamically selects the aggregation frame. The data are classified into seven user priorities (UPs): UP7 has the highest priority, and UP0 has the lowest priority. The data are transferred to queues and sent to the central hub, where they are transmitted to the main server. Queue 0 contains emergency data, which are dispatched without delay. At the same time, aggregation occurs at Queues 1 and 2. For selecting an aggregation frame, the DQN algorithm is used. The hub node offloads the tasks and sends them to the medical server [
63].


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}