

A Comprehensive Overview of IoT-Based Federated Learning: Focusing on Client Selection Methods




Abstract
:1. Introduction
- RS: RS are information filtering systems designed to anticipate user preferences and offer personalized recommendations. Employing FL in RS yields numerous benefits and enhancements, including the delivery of efficient and privacy-preserving personalized recommendations to users across diverse platforms and devices [10].
- IoT applications:
- ➢
- IoV: FL also has the potential to bring about a revolutionary transformation in the automotive industry and the development of intelligent transportation systems [11].
- ➢
- MEC: The incorporation of FL into MEC is anticipated to have a crucial impact in achieving efficient and privacy-preserving intelligent applications at the network’s edge [12].
- ➢
- IIoT: The integration of IIoT with FL has the potential of revolutionizing industries and streamlining industrial operations. IIoT involves a network of interconnected devices, sensors, and equipment in industrial environments, enabling data collection and exchange. On the other hand, FL is a privacy-preserving machine learning approach that facilitates model training across distributed devices without the need to share sensitive raw data [13].
- ➢
- IoHT: The integration of IoHT with FL is a solution to enhance healthcare practices, enabling advancements in remote patient monitoring, disease prediction, and treatment optimization [14].
- ➢
- A thorough SLR is presented that examines the challenges of FL in adopting CS methods that can be used to aid future research and development of CS in FL.
- ➢
- A detailed overview of the CS process, including its abstract implementation and characteristics, is presented that can be used in various domains.
- ➢
- Different CS methods are categorized and explained based on their main characteristics and the challenges they solve. This provides insight into current literature and provides a plan for future investigations on this topic.
2. Background
2.1. Client Selection
- ➢
- Cross-device FL with millions of clients such as smartphones, wearables, and edge device nodes, where each client typically stores local data [49].
- ➢
- Cross-silo FL in which the client is typically a company or organization, with a small number of participants and a huge amount of data, and each client is expected to participate in the entire training process [18].
- (1)
- RQ1: Why and how can adopting an appropriate CS method optimize the overall performance of FL?
- (a)
- RQ1.1: In which aspects should FL be improved?
- (b)
- RQ1.2: How can CS help resolve the FL challenges?
- (2)
- RQ2: From the structural perspective, what are the main pros and cons of different CS methods?
- (a)
- RQ2.1: How can different methods be categorized in different terms?
- (b)
- RQ2.2: What challenges have been addressed with CS methods?
2.2. Related Surveys
- ➢
- Focusing on FL challenges without considering different CS methods: Li et al. [19], Zhang et al. [24], Liu et al. [27], Wen et al. [32], Zhang et al. [36], Nguyen et al. [53], Antunes et al. [54], Campos et al. [55], and Banabilah et al. [38] focus on FL challenges from the perspectives of IoT devices, IoT, privacy applications, 6G communication, privacy protection, intelligent healthcare, healthcare applications, intrusion detection in IoT, and edge computing respectively.
- ➢
- Reviewing FL challenges and introducing CS as a solution without discussing its challenges: Lo et al. [18] examined the development and challenges of FL systems from the software engineering perspective.
- ➢
- Focusing on the challenges of CS methods: Only two papers focus on CS and its importance for FL. In [41], only system and statistical homogeneity challenges are discussed without considering fairness, robustness, and privacy issues. In contrast, the authors in [6] briefly examines the critical challenges of CS methods extracted from current research, compares them to find the root causes of the challenges, and guides future research. However, it is not a comprehensive survey and does not contain data privacy issues or the design architecture of CS methods.
3. Research Methodology
- A.
- Defining research questions.
- B.
- Determine data literacy and keywords.
- C.
- Selecting studies based on inclusion and exclusion criteria.
- The papers explicitly addressed challenges in FL related to CS.
- The papers were published in internationally recognized computer science journals and conferences. These publishers contribute to computer Science applications, and algorithms are used to structure the logic of their programs, perform computations, manipulate data, and control the flow of execution to simplify the CS process.
- The papers were written in English.
- Papers without evaluation results, such as white papers or short papers.
- Papers that provided background information on FL.
- Papers without peer review, such as theses.
- Papers not written in English.
- D.
- Finalizing the source selection.
- E.
- Data extraction from the selected sources
- F.
- Using study quality factor assessment.
- G.
- Analyzing the extracted data.
4. Discussing CS’s Impact on FL Challenges and Its Challenges
4.1. FL Structure and Its Challenges
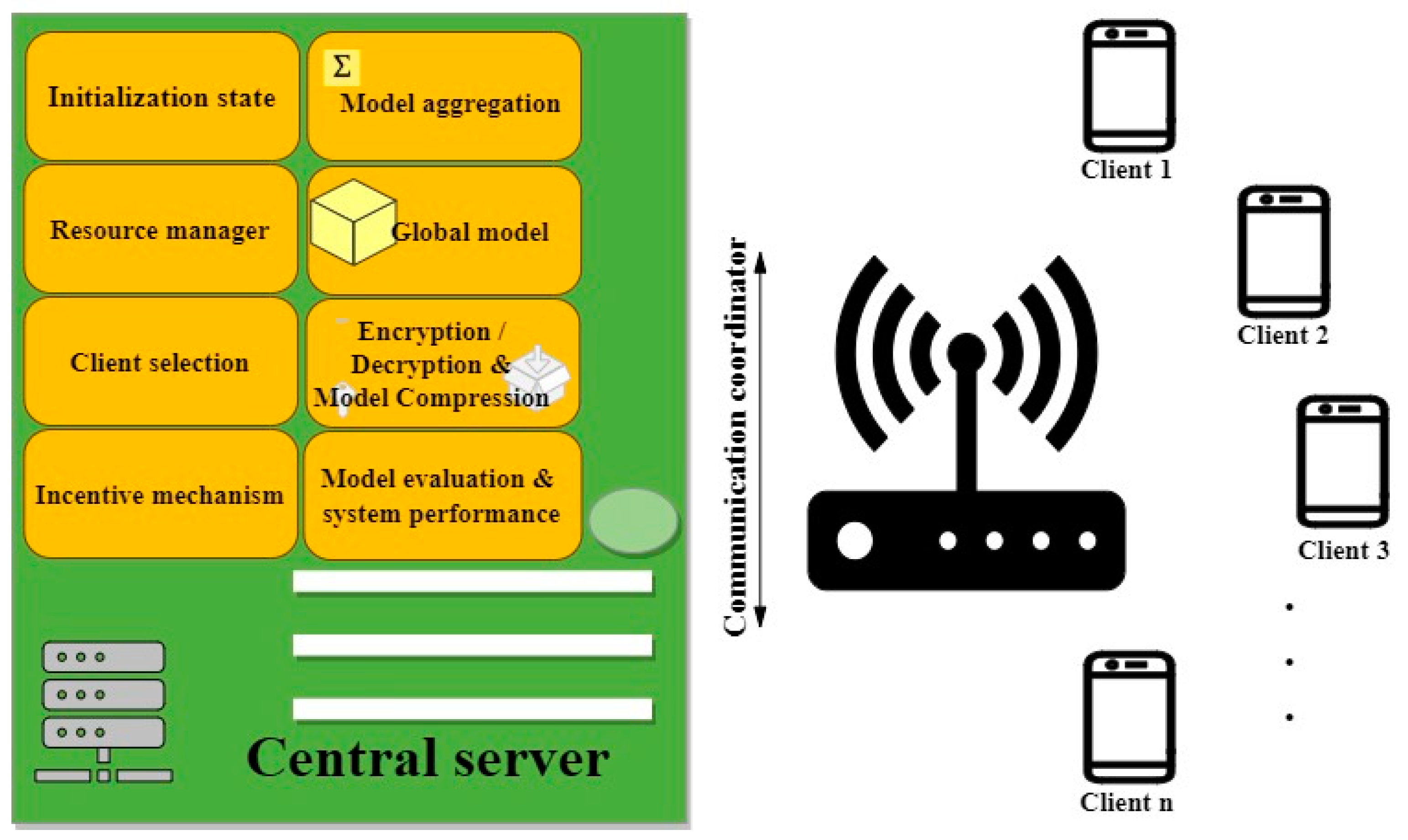
- Central Server. The server is one of the key parts of FL. The server initializes the process by completing a foremost global model using a sample dataset generated by itself or by collecting data from clients [62]. In some FL systems like in [75], clients start the global model. Then, an encrypted and compressed global model is broadcasted to clients based on an examination of the available clients [50,51,63] or based on the participating clients’ performance in the last step [64]. After that, a trained local model can be collected from all clients or only the participating clients accordingly. The communication coordinator is an administrator that provides a channel between the server and multiple clients for communication [37]. It is also possible to collect local models either synchronously or asynchronously [57,66]. In contrast to synchronous, an asynchronous scheme means that clients do not need to wait for each other to synchronize. When the server receives all or part of the updates, it performs model aggregation. After that, clients are notified of the updated global model. In the end, the evaluation part assesses the system performance of the process. This process continues until convergence is reached. In addition to orchestrating the exchange of model parameters, FL also has other parts, especially a resource manager and a CS process [18]. The resource manager is to make the best use of resources. It is the administration system for the optimization of resource consumption and control of the allocated resources of clients. The result of this is reflected in the CS mechanism for selecting suitable clients to conduct model training and reaching desirable system performance [68]. In addition, clients may be motivated to participate through incentive mechanisms [71,72,73].
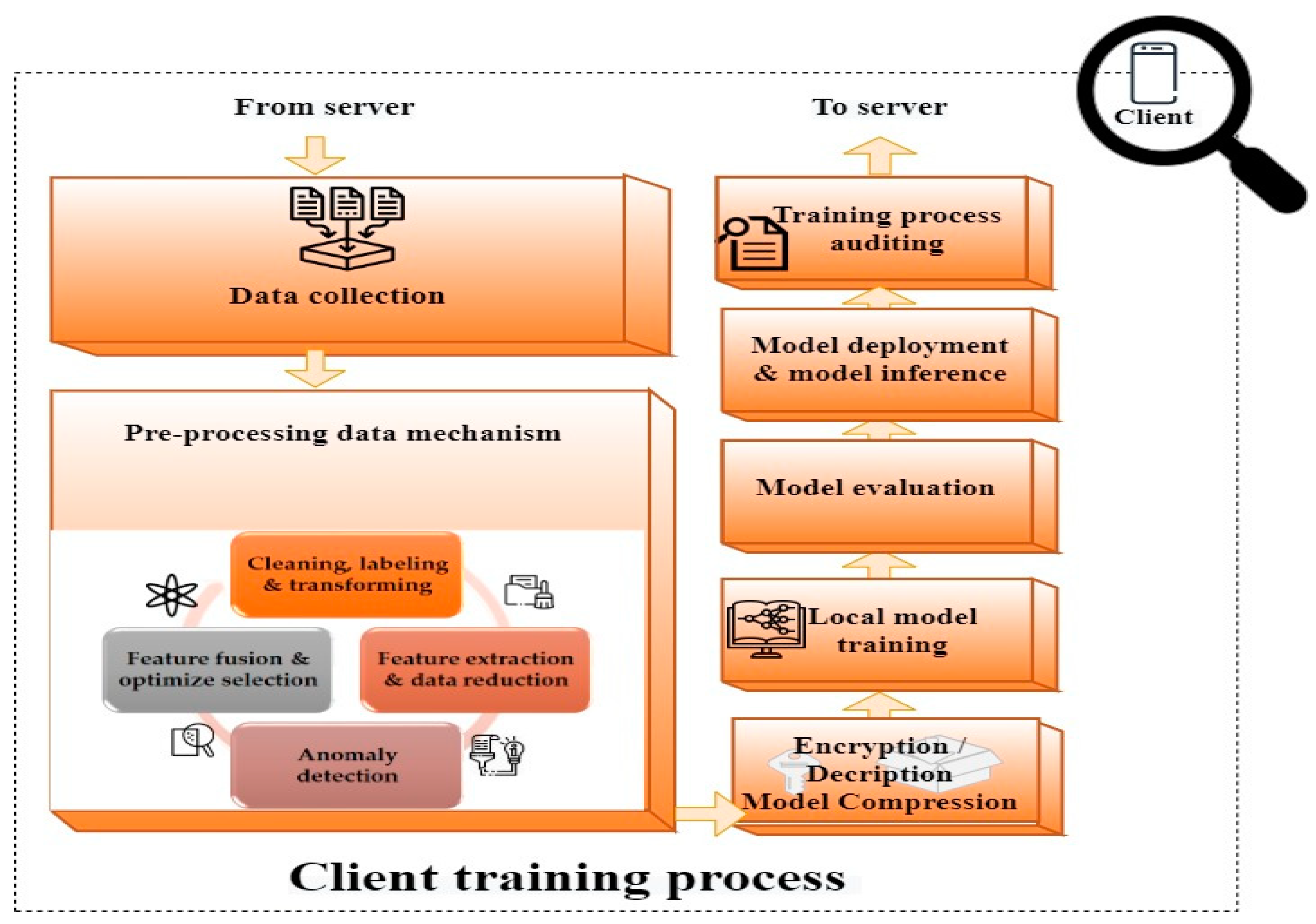
- Clients. As another important part of FL, clients train local models at each iteration using their local data. To begin (see Figure 3), each client gathers and pre-processes its data through various steps, including cleaning, labeling, data augmentation, data transformation, feature extraction, data reduction, anomaly detection, feature fusion, and selection optimization [20]. Then, each client receives the global model and initiates the operations of decryption, decompression, and parameter extraction from the global model. This step is followed by performing local model training by clients. After being trained for multiple rounds [77], the model is evaluated by the client and audited as being complete. Model evaluation is to ensure that the model has reached the expected level of performance. This step is followed by model deployment and model inference. After this step, the model is compressed to acquire a sufficient level of performance and to decrease communication costs [63,72,74]. Encryption is applied to the local model before it is uploaded to secure the process and the data. Then, the local models are sent to the server to aggregate the results [78].
4.1.1. Expensive and Inefficient Communication
4.1.2. Statistical Heterogeneity
4.1.3. Client Heterogeneity
- Expect an inferior portion of the participation.
- There is a need to consider this attribute specifically.
- Tolerate faults in heterogeneous hardware. It is a vital attribute of classical distributed systems to support fault tolerance, including Byzantine formalism failures [88]. Since some remote clients may drop out before completing training, fault tolerance becomes even more critical. For instance, suppose the failed clients have specific data properties. Ignoring such client failures, like in FedAvg [18], may lead to bias. FedAvg is difficult to analyze theoretically in such realistic scenarios and thus lacks convergence guarantees to characterize its behavior.
- Be sufficiently solid to drop clients in the transmission. As there is a risk of dropping clients during FL due to computational capability or poor network connection, the FL process should be solid enough even when encountering this issue [59].
- Asynchronous communication. Due to client variability, they are also more exposed to stragglers [57]. Stragglers mean that some clients with low-level resources are unable to complete their training within the deadline. The use of this scheme, particularly in shared memory systems, is an attractive technique to mitigate stragglers [19,59], although they generally use boundary-delay assumptions to deal with staleness. Li et al. [39] also proposed a FedProx optimization method in FL to cope with heterogeneity, but it lacks formalization. Although asynchronous FL has been demonstrated to be more practical even with its restrictions [59], new solutions to ensure more expected performance are under-explored.
- Active device sampling. Each round of training in federated networks typically involves just a small number of clients. Nevertheless, most of these clients are passive in that round and each round does not aim to control which clients participate.
4.1.4. Data Privacy
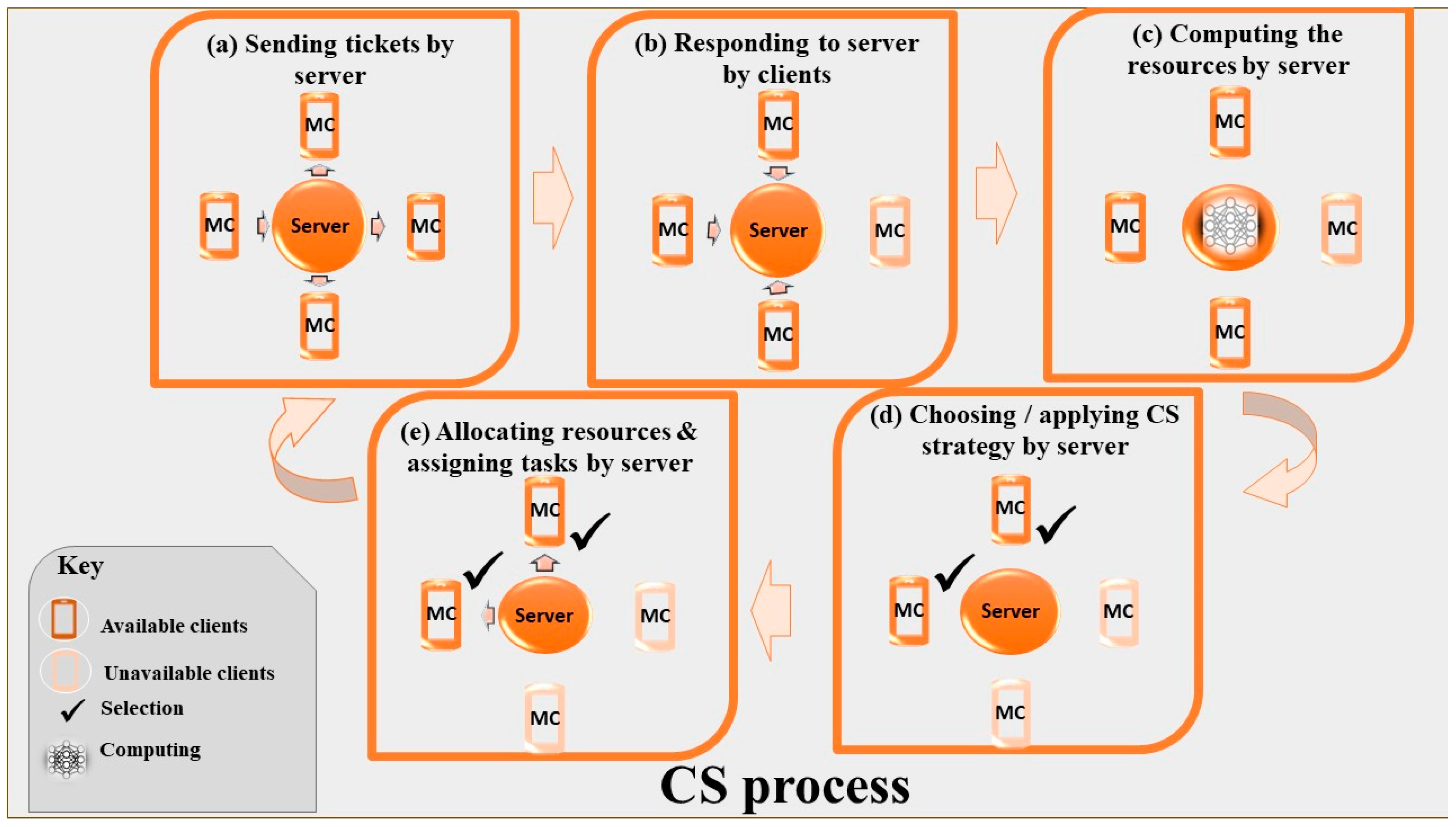
4.2. CS in FL
5. Pros and Cons of Different CS Methods
5.1. CS Methods
- Update compression (quantizing gradient is a solution for efficient communication).
- Over-the-air analysis [63].
5.2. CS Side Effects
- Fairness: Fairness means that every client has an equal chance to be selected for training. When fairness is ignored, the server may prioritize the client with a different dataset size but in a shorter response time. This may significantly affect the training performance. So, clients with insufficient abilities have a lower chance of being selected to participate in the training process, which may lead to bias and low-level model accuracy [1,41]. Fairness boosts the accuracy and speed of convergence of models by enabling clients with various datasets to participate in the FL [34,35,59]. Consequently, all end devices should be involved in the FL process to decrease model bias.
- Trustworthiness: Because the FL server is unaware of the local training procedure, malicious clients can launch attacks and manipulate the training outputs. A primary priority should be recognizing and removing malicious clients from the procedure [6].
- Dynamic environment: This means that because of the existence of deficiencies, including high mobility, poor network conditions, and energy constraints, some clients might not be available to take part in model training [35,49,59]. Moreover, channel fading in wireless networks may result in losing some local model updates. Therefore, a dynamic condition with high-mobility devices and volatility including client population, client data, training status, and biased data [84] significantly impacts the performance of the CS process and FL.
5.3. Overall Evaluation of Different CS Methods
- Clustering methods
- Greedy methods
- Random methods
- MAB methods
6. Limitations and Research Possibilities
- Privacy and Communication: In the FL process, the communication between clients and parameter servers usually occurs over an impaired wireless channel, which introduces some research queries about privacy issues and how the updates can be transferred to a secure channel.
- Trade-off between metric factors: A considerable number of factors to improve model performance were used. However, different factors are not comparable. So, a need exists to balance factors for performance evaluation among various techniques for the same problem. For instance, selecting more clients in each training round boosts model performance and training efficiency but does not guarantee time efficiency, especially in a volatile environment. In the research that was reviewed in the paper, the rate of volatility in that space was unclear. This issue can be a potential research gap for future researchers.
- Asynchronous communication schemes: Regarding analysis approaches, asynchronous communication schemes for local data updates remain an open issue demanding additional examination.
- Communication resource handling: There is space to explore appropriate communication resource methods for allocating resources (same or different bandwidth, energy, and computational capacity) based on the network topology. This strategy can remarkably affect learning performance. This issue becomes essential when many client devices join the FL process. Remarkably, the training rate can be greatly reduced due to different client heterogeneity of computational capacities and data qualities. A favorable answer would be developing additional parts to encourage clients to use high-quality training data.
- Channel characteristics: Analyzing the network requirements impacts the accuracy of federated model training. It is a future examination direction, particularly in wireless communication, when noise, path loss, shadowing, and fading impairments exist.
- Available datasets for clients: The availability of client datasets is needed to obtain suitable training performance. Clients needed to use feature extraction for their local training. In this regard, one of the critical problems is the non-IID matter, potentially causing the local training to be highly divergent. Therefore, some solutions to cope with this matter need to be developed.
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence | MAB | Multi-Armed Bandit |
| AUC | Area Under curve | Macro-Acc | Macro-Accuracy |
| AUROC | Area Under the ROC curve | MEC | Mobile edge computing |
| CEPD | Cumulative effective participation data | Micro-Acc | Micro-Accuracy |
| CFL | Clustered FL | ML | Machine learning |
| CMAB | Combinatorial multiarmed bandit | MUEs | Mobile user equipment |
| CS | Client selection | non-IID | Non-independent and -identical data |
| FedAvg | Federated averaging | ROC | Receiver Operating Characteristic |
| FedCS | Federated client selection | RQs | Research questions |
| FL | Federated Learning | RS | Recommendation systems |
| FN | False Negatives | SGD | Stochastic gradient descent |
| FP | False Positive | THF | 3-way hierarchical |
| GBP- CS | Gradient-based Binary Permutation Algorithm | TN | True Negative |
| IIoT | Industrial Internet of Things | TP | True Positive |
| IoT | Internet of Things | MAB | Multi-Armed Bandit |
| IoV | Internet of Vehicles | WFLN | Wireless FL network |
Appendix A
- ➢
- Model performance metrics
- Accuracy
- Precision
- Recall
- F1-Score
- Micro-Acc
- Macro-Acc
- Micro-F1
- Macro-F1
- AUC
- Convergence speed
- ▪
- Training time/training duration
- ▪
- Training loss
- ▪
- Training round (number of local training epochs)
- ➢
- System performance metrics
- Convergence speed
- ▪
- Execution Time
- ▪
- Iteration count
- Communication efficiency
- Computational efficiency
- System scalability
References
- Huang, T.; Lin, W.; Wu, W.; He, L.; Li, K.; Zomaya, A. An efficiency-boosting client selection scheme for federated learning with fairness guarantee. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1552–1564. [Google Scholar] [CrossRef]
- Asad, M.; Moustafa, A.; Rabhi, F.A.; Aslam, M. THF: 3-Way hierarchical framework for efficient client selection and resource management in federated learning. IEEE Internet Things J. 2021, 9, 11085–11097. [Google Scholar] [CrossRef]
- Ludwig, H.; Baracaldo, N. Federated Learning: A Comprehensive Overview of Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Briggs, C.; Fan, Z.; Andras, P. Federated learning with hierarchical clustering of local updates to improve training on non-IID data. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar]
- Chen, M.; Yang, Z.; Saad, W.; Yin, C.; Poor, H.V.; Cui, S. A Joint learning and communications framework for federated learning over wireless networks. IEEE Trans. Wirel. Commun. 2020, 20, 269–283. [Google Scholar] [CrossRef]
- Soltani, B.; Haghighi, V.; Mahmood, A.; Sheng, Q.Z.; Yao, L. A survey on participant selection for federated learning in mobile networks. In Proceedings of the 17th ACM Workshop on Mobility in the Evolving Internet Architecture, Sydney, NSW, Australia, 21 October 2022; pp. 19–24. [Google Scholar]
- Xu, B.; Xia, W.; Zhang, J.; Quek, T.Q.S.; Zhu, H. Online client scheduling for fast federated learning. IEEE Wirel. Commun. Lett. 2021, 10, 1434–1438. [Google Scholar] [CrossRef]
- Nishio, T.; Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.-Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Ghosh, A.; Hong, J.; Yin, D.; Ramchandran, K. Robust federated learning in a heterogeneous environment. arXiv 2019, arXiv:1906.06629. [Google Scholar]
- Kang, J.; Yu, R.; Huang, X.; Wu, M.; Maharjan, S.; Xie, S.; Zhang, Y. Blockchain for secure and efficient data sharing in ve-hicular edge computing and networks. IEEE Internet Things J. 2018, 6, 4660–4670. [Google Scholar] [CrossRef]
- Ye, D.; Yu, R.; Pan, M.; Han, Z. Federated learning in vehicular edge computing: A selective model aggregation approach. IEEE Access 2020, 8, 23920–23935. [Google Scholar] [CrossRef]
- Li, Z.; He, Y.; Yu, H.; Kang, J.; Li, X.; Xu, Z.; Niyato, D. Data heterogeneity-robust federated learning via group client selection in industrial IoT. IEEE Internet Things J. 2022, 9, 17844–17857. [Google Scholar] [CrossRef]
- Rahman, M.A.; Hossain, M.S.; Islam, M.S.; Alrajeh, N.A.; Rahman, M.A.; Hossain, M.S.; Islam, M.S.; Alrajeh, N.A.; Muhammad, G. Secure and Provenance Enhanced Internet of Health Things Framework: A Blockchain Managed Federated Learning Approach. IEEE Access 2020, 8, 205071–205087. [Google Scholar] [CrossRef]
- Lian, X.; Zhang, C.; Zhang, H.; Hsieh, C.-J.; Zhang, W.; Liu, J. Can decentralized algorithms outperform centralized algo-rithms? a case study for decentralized parallel stochastic gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/f75526659f31040afeb61cb7133e4e6d-Paper.pdf (accessed on 11 August 2023).
- Smith, V.; Forte, S.; Chenxin, M.; Taka, M.; Jordan, M.I.; Jaggi, M. Cocoa: A general framework for communication-efficient distributed optimization. J. Mach. Learn. Res. 2018, 18, 230. [Google Scholar]
- Zhang, X.; Hong, M.; Dhople, S.; Yin, W.; Liu, Y. FedPD: A Federated Learning Framework With Adaptivity to Non-IID Data. IEEE Trans. Signal Process. 2021, 69, 6055–6070. [Google Scholar] [CrossRef]
- Lo, S.K.; Lu, Q.; Wang, C.; Paik, H.-Y.; Zhu, L. A systematic literature review on federated machine learning: From a software engineering perspective. ACM Comput. Surv. (CSUR) 2021, 54, 1–39. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Khajehali, N.; Alizadeh, S. Extract critical factors affecting the length of hospital stay of pneumonia patient by data mining (case study: An Iranian hospital). Artif. Intell. Med. 2017, 83, 2–13. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; He, L.; Lin, W.; Mao, R.; Maple, C.; Jarvis, S.A. SAFA: A Semi-Asynchronous Protocol for Fast Federated Learning With Low Overhead. IEEE Trans. Comput. 2021, 70, 655–668. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Liu, J.K.; Xiang, Y. DeepPAR and DeepDPA: Privacy Preserving and Asynchronous Deep Learning for Industrial IoT. IEEE Trans. Ind. Inform. 2019, 16, 2081–2090. [Google Scholar] [CrossRef]
- Hu, B.; Gao, Y.; Liu, L.; Ma, H. Federated Region-Learning: An Edge Computing Based Framework for Urban Environment Sensing. In Proceedings of the 2018 IEEE global communications conference (Globecom), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar]
- Zhang, T.; Gao, L.; He, C.; Zhang, M.; Krishnamachari, B.; Avestimehr, A.S. Federated Learning for the Internet of Things: Applications, Challenges, and Opportunities. IEEE Internet Things Mag. 2022, 5, 24–29. [Google Scholar] [CrossRef]
- Cao, L. Beyond iid: Non-iid thinking, informatics, and learning. IEEE Intell. Syst. 2022, 37, 5–17. [Google Scholar] [CrossRef]
- Yu, L.; Albelaihi, R.; Sun, X.; Ansari, N.; Devetsikiotis, M. Jointly Optimizing Client Selection and Resource Management in Wireless Federated Learning for Internet of Things. IEEE Internet Things J. 2021, 9, 4385–4395. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, X.; Xiong, Z.; Kang, J.; Wang, X.; Niyato, D. Federated learning for 6G communications: Challenges, methods, and future directions. China Commun. 2020, 17, 105–118. [Google Scholar] [CrossRef]
- Sattler, F.; Mu, K.-R.; Samek, W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3710–3722. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Kone, C.J.; Rush, K.; Kannan, S. Improving federated learning personalization via model agnostic meta-learning. arXiv 2019, arXiv:1909.12488. [Google Scholar]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Client-edge-cloud hierarchical federated learning. In Proceedings of the ICC 2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An Efficient Framework for Clustered Federated Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 19586–19597. [Google Scholar] [CrossRef]
- Wen, J.; Zhang, Z.; Lan, Y.; Cui, Z.; Cai, J.; Zhang, W. A survey on federated learning: Challenges and applications. Int. J. Mach. Learn. Cybern. 2022, 14, 513–535. [Google Scholar] [CrossRef]
- Ji, S.; Jiang, W.; Walid, A.; Li, X. Dynamic Sampling and Selective Masking for Communication-Efficient Federated Learning. IEEE Intell. Syst. 2021, 37, 27–34. [Google Scholar] [CrossRef]
- Lin, W.; Xu, Y.; Liu, B.; Li, D.; Huang, T.; Shi, F. Contribution-based Federated Learning client selection. Int. J. Intell. Syst. 2022, 37, 7235–7260. [Google Scholar] [CrossRef]
- Huang, T.; Lin, W.; Shen, L.; Li, K.; Zomaya, A.Y. Stochastic Client Selection for Federated Learning With Volatile Clients. IEEE Internet Things J. 2022, 9, 20055–20070. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Amiri, M.M.; Gu, D. Federated learning over wireless fading channels. IEEE Trans. Wirel. Commun. 2020, 19, 3546–3557. [Google Scholar] [CrossRef]
- Banabilah, S.; Aloqaily, M.; Alsayed, E.; Malik, N.; Jararweh, Y. Federated learning review: Fundamentals, enabling tech-nologies, and future applications. Inf. Process. Manag. 2022, 59, 103061. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Xu, J.; Wang, H. Client Selection and Bandwidth Allocation in Wireless Federated Learning Networks: A Long-Term Perspective. IEEE Trans. Wirel. Commun. 2020, 20, 1188–1200. [Google Scholar] [CrossRef]
- Fu, L.; Zhang, H.; Gao, G.; Wang, H.; Zhang, M.; Liu, X. Client selection in federated learning: Principles, challenges, and opportunities. arXiv 2022, arXiv:2211.01549. [Google Scholar] [CrossRef]
- Saha, R.; Misra, S.; Chakraborty, A.; Chatterjee, C.; Deb, P.K. Data-centric client selection for federated learning over dis-tributed edge networks. IEEE Trans. Parallel Distrib. Syst. 2022, 34, 675–686. [Google Scholar] [CrossRef]
- Telikani, A.; Rossi, M.; Khajehali, N.; Renzi, M. Pumps-as-Turbines’ (PaTs) performance prediction improvement using evolutionary artificial neural networks. Appl. Energy 2023, 330, 120316. [Google Scholar] [CrossRef]
- Khajehali, N.; Khajehali, Z.; Tarokh, M.J. The prediction of mortality influential variables in an intensive care unit: A case study. Pers. Ubiquitous Comput. 2021, 27, 203–219. [Google Scholar] [CrossRef]
- Li, X.; Qu, Z.; Tang, B.; Lu, Z. FedLGA: Toward System-Heterogeneity of Federated Learning via Local Gradient Approximation. IEEE Trans. Cybern. 2023, 1–14. [Google Scholar] [CrossRef]
- Mothukuri, V.; Khare, P.; Parizi, R.M.; Pouriyeh, S.; Dehghantanha, A.; Srivastava, G. Federated-Learning-Based Anomaly Detection for IoT Security Attacks. IEEE Internet Things J. 2021, 9, 2545–2554. [Google Scholar] [CrossRef]
- Le, J.; Lei, X.; Mu, N.; Zhang, H.; Zeng, K.; Liao, X. Federated Continuous Learning With Broad Network Architecture. IEEE Trans. Cybern. 2021, 51, 3874–3888. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q.; An, D.; Li, D.; Wu, Z. Multistep Multiagent Reinforcement Learning for Optimal Energy Schedule Strategy of Charging Stations in Smart Grid. IEEE Trans. Cybern. 2022, 53, 4292–4305. [Google Scholar] [CrossRef] [PubMed]
- Dennis, D.K.; Li, T.; Smith, V. Heterogeneity for the win: One-shot federated clustering. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 2611–2620. [Google Scholar]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive federated learning in re-source-constrained edge Computing systems. IEEE J. Sel. Areas Commun. 2019, 37, 1205–1221. [Google Scholar] [CrossRef]
- Mills, J.; Hu, J.; Min, G. Communication-Efficient Federated Learning for Wireless Edge Intelligence in IoT. IEEE Internet Things J. 2019, 7, 5986–5994. [Google Scholar] [CrossRef]
- Deng, Y.; Lyu, F.; Ren, J.; Wu, H.; Zhou, Y.; Zhang, Y.; Shen, X. AUCTION: Automated and Quality-Aware Client Selection Framework for Efficient Federated Learning. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 1996–2009. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Pham, Q.-V.; Pathirana, P.N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; Hwang, W.-J. Federated Learning for Smart Healthcare: A Survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Antunes, R.S.; Andre da Costa, C.; Kuderle, A.; Yari, I.A.; Eskofier, B. Federated learning for healthcare: Systematic review and architecture proposal. ACM Trans. Intell. Syst. Technol. TIST 2022, 13, 1–23. [Google Scholar] [CrossRef]
- Campos, E.M.; Saura, P.F.; Gonza, A.; Herna, J.L.; Bernabe, J.B.; Baldini, G.; Skarmeta, A. Evaluating federated learning for intrusion detection on the internet of things: Review and challenges. Comput. Netw. 2022, 203, 108661. [Google Scholar] [CrossRef]
- Xie, C.; Koyejo, S.; Gupta, I. Asynchronous federated optimization. arXiv 2019, arXiv:1903.03934. [Google Scholar]
- Fahmideh, M.; Grundy, J.; Ahmad, A.; Shen, J.; Yan, J.; Mougouei, D.; Wang, P.; Ghose, A.; Gunawardana, A.; Aickelin, U.; et al. Engineering blockchain-based software systems: Foundations, survey, and future directions. ACM Comput. Surv. 2022, 55, 1–44. [Google Scholar] [CrossRef]
- Roy, A.G.; Siddiqui, S.; Po, S.; Navab, N.; Wachinger, C. Braintorrent: A peer-to-peer environment for decentralized federated learning. arXiv 2019, arXiv:1905.06731. [Google Scholar]
- Cortes, C.; Lawrence, N.; Lee, D.; Sugiyama, M.; Garnett, R. Advances in neural information processing systems 28. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Yang, H.H.; Liu, Z.; Quek, T.Q.S.; Poor, H.V. Scheduling Policies for Federated Learning in Wireless Networks. IEEE Trans. Commun. 2019, 68, 317–333. [Google Scholar] [CrossRef]
- Triastcyn, A.; Faltings, B. Federated Generative Privacy. IEEE Intell. Syst. 2020, 35, 50–57. [Google Scholar] [CrossRef]
- Savazzi, S.; Nicoli, M.; Rampa, V. Federated Learning with Cooperating Devices: A Consensus Approach for Massive IoT Networks. IEEE Internet Things J. 2020, 7, 4641–4654. [Google Scholar] [CrossRef]
- Yang, K.; Jiang, T.; Shi, Y.; Ding, Z. Federated Learning via Over-the-Air Computation. IEEE Trans. Wirel. Commun. 2020, 19, 2022–2035. [Google Scholar] [CrossRef]
- Sattler, F.; Wiedemann, S.; Mu, K.-R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3400–3413. [Google Scholar] [CrossRef] [PubMed]
- Song, Z.; Sun, H.; Yang, H.H.; Wang, X.; Zhang, Y.; Quek, T.Q.S. Reputation-Based Federated Learning for Secure Wireless Networks. IEEE Internet Things J. 2021, 9, 1212–1226. [Google Scholar] [CrossRef]
- Chen, Y.; Ning, Y.; Slawski, M.; Rangwala, H. Asynchronous Online Federated Learning for Edge Devices with Non-IID Data. In Proceedings of the 2020 IEEE International Conference on Big Data, Atlanta, GA, USA, 10–13 December 2020; pp. 15–24. [Google Scholar]
- Wei, X.; Li, Q.; Liu, Y.; Yu, H.; Chen, T.; Yang, Q. Multi-Agent Visualization for Explaining Federated Learning. IJCAI 2019, 6572–6574. Available online: https://www.ijcai.org/proceedings/2019/0960.pdf (accessed on 11 August 2023).
- Anh, T.T.; Luong, N.C.; Niyato, D.; Kim, D.I.; Wang, L.-C. Efficient Training Management for Mobile Crowd-Machine Learning: A Deep Reinforcement Learning Approach. IEEE Wirel. Commun. Lett. 2019, 8, 1345–1348. [Google Scholar] [CrossRef]
- Wang, G. Interpret federated learning with shapely values. arXiv 2019, arXiv:1905.04519. [Google Scholar]
- Yao, X.; Huang, T.; Wu, C.; Zhang, R.; Sun, L. Towards Faster and Better Federated Learning: A Feature Fusion Approach. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 175–179. [Google Scholar]
- Sarikaya, Y.; Ercetin, O. Motivating Workers in Federated Learning: A Stackelberg Game Perspective. IEEE Netw. Lett. 2019, 2, 23–27. [Google Scholar] [CrossRef]
- Zhan, Y.; Li, P.; Qu, Z.; Zeng, D.; Guo, S. A Learning-Based Incentive Mechanism for Federated Learning. IEEE Internet Things J. 2020, 7, 6360–6368. [Google Scholar] [CrossRef]
- Zhang, W.; Lu, Q.; Yu, Q.; Li, Z.; Liu, Y.; Lo, S.K.; Chen, S.; Xu, X.; Zhu, L. Blockchain-Based Federated Learning for Device Failure Detection in Industrial IoT. IEEE Internet Things J. 2020, 8, 5926–5937. [Google Scholar] [CrossRef]
- Luping, W.; Wei, W.; Bo, L. Cmfl: Mitigating communication overhead for federated learning. In Proceedings of the IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 954–964. [Google Scholar]
- Bao, X.; Su, C.; Xiong, Y.; Huang, W.; Hu, Y. FL chain: A blockchain for auditable federated learning with trust and in-centive. In Proceedings of the 2019 5th International Conference on Big Data Computing and Communications (BIGCOM), QingDao, China, 9–11 August 2019; pp. 151–159. [Google Scholar]
- Zhao, Y.; Chen, J.; Zhang, J.; Wu, D.; Teng, J.; Yu, S. PDGAN: A Novel Poisoning Defense Method in Federated Learning Using Generative Adversarial Network. In Algorithms and Architectures for Parallel, Processing of the 19th International Conference, ICA3PP 2019 (Proceedings, Part I 19), Melbourne, VIC, Australia, 9–11 December 2019; Springer: Cham, Switzerland, 2020; pp. 595–609. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Hsu, T.-M.H.; Qi, H.; Brown, M. Measuring the effects of non-identical data distribution for federated visual classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]
- Zhan, Y.; Li, P.; Guo, S. Experience-Driven Computational Resource Allocation of Federated Learning by Deep Reinforcement Learning. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), New Orleans, LA, USA, 18–22 May 2020; pp. 234–243. [Google Scholar]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.-L. Block chained on-device federated learning. IEEE Commun. Lett. 2019, 24, 1279–1283. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Blockchain and Federated Learning for Privacy-Preserved Data Sharing in Industrial IoT. IEEE Trans. Ind. Inform. 2019, 16, 4177–4186. [Google Scholar] [CrossRef]
- Weng, J.; Weng, J.; Zhang, J.; Li, M.; Zhang, Y.; Luo, W. DeepChain: Auditable and Privacy-Preserving Deep Learning with Blockchain-based Incentive. IEEE Trans. Dependable Secur. Comput. 2019, 18, 2438–2455. [Google Scholar] [CrossRef]
- Shayan, M.; Fung, C.; Yoon, C.J.; Beschastnikh, I. Biscotti: A ledger for private and secure peer-to-peer machine learning. arXiv 2018, arXiv:1811.09904. [Google Scholar]
- Shi, F.; Hu, C.; Lin, W.; Fan, L.; Huang, T.; Wu, W. VFedCS: Optimizing Client Selection for Volatile Federated Learning. IEEE Internet Things J. 2022, 9, 24995–25010. [Google Scholar] [CrossRef]
- Mohammed, I.; Tabatabai, S.; Al-Fuqaha, A.; El Bouanani, F.; Qadir, J.; Qolomany, B.; Guizani, M. Budgeted Online Selection of Candidate IoT Clients to Participate in Federated Learning. IEEE Internet Things J. 2020, 8, 5938–5952. [Google Scholar] [CrossRef]
- Shi, W.; Zhou, S.; Niu, Z. Device Scheduling with Fast Convergence for Wireless Federated Learning. In Proceedings of the ICC IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Amiri, M.M.; Gu, D.; Kulkarni, S.R.; Poor, H.V. Convergence of update aware device scheduling for federated learning at the wireless edge. IEEE Trans. Wirel. Commun. 2021, 20, 3643–3658. [Google Scholar] [CrossRef]
- Tan, X.; Ng, W.C.; Lim, W.Y.B.; Xiong, Z.; Niyato, D.; Yu, H. Reputation-Aware Federated Learning Client Selection based on Stochastic Integer Programming. IEEE Trans. Big Data 2022, 1–12. [Google Scholar] [CrossRef]
- Long, G.; Xie, M.; Shen, T.; Zhou, T.; Wang, X.; Jiang, J. Multi-center federated learning: Clients clustering for better per-sonalization. World Wide Web 2023, 26, 481–500. [Google Scholar] [CrossRef]
- Wang, S.; Chang, T.-H. Federated Matrix Factorization: Algorithm Design and Application to Data Clustering. IEEE Trans. Signal Process. 2022, 70, 1625–1640. [Google Scholar] [CrossRef]
- Qu, Z.; Duan, R.; Chen, L.; Xu, J.; Lu, Z.; Liu, Y. Context-Aware Online Client Selection for Hierarchical Federated Learning. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 4353–4367. [Google Scholar] [CrossRef]
- Zhu, H.; Zhou, Y.; Qian, H.; Shi, Y.; Chen, X.; Yang, Y. Online Client Selection for Asynchronous Federated Learning With Fairness Consideration. IEEE Trans. Wirel. Commun. 2022, 22, 2493–2506. [Google Scholar] [CrossRef]
- Xia, W.; Quek, T.Q.S.; Guo, K.; Wen, W.; Yang, H.H.; Zhu, H. Multi-Armed Bandit-Based Client Scheduling for Federated Learning. IEEE Trans. Wirel. Commun. 2020, 19, 7108–7123. [Google Scholar] [CrossRef]
- Han, Y.; Li, D.; Qi, H.; Ren, J.; Wang, X. Federated learning-based computation offloading optimization in edge computing-supported internet of things. In Proceedings of the ACM Turing Celebration Conference-China, Chengdu China, 17–19 May 2019; pp. 1–5. [Google Scholar]
- Tan, A.Z.; Yu, H.; Cui, L.; Yang, Q. Towards personalized federated learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–17. [Google Scholar] [CrossRef]
- Nilsson, A.; Smith, S. Evaluating the Performance of Federated Learning. Master’s Thesis, University of Gothenburg, Göteborg, Sweden, 2018. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria/ | References | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [6] | [18] | [19] | [24] | [27] | [32] | [36] | [38] | [41] | [53] | [54] | [55] | This Work | |
| Systematic Literature Review | ✕ | ✓ | ✕ | ✕ | ✕ | ✓ | ✕ | ✕ | ✕ | ✕ | ✓ | ✕ | ✓ |
| Focusing on the CS issue | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ |
| Compare the Pros and Cons of other papers | ✓ | ✕ | ✕ | ✕ | ✕ | ✓ | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ |
| Compare methods of CS | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ |
| Client heterogeneity issues discussion | ✓ | ✓ | ✓ | ✓ | ✕ | ✓ | ✓ | ✓ | ✓ | ✓ | ✕ | ✓ | ✓ |
| Data heterogeneity issues discussion | ✓ | ✓ | ✓ | ✕ | ✕ | ✓ | ✓ | ✓ | ✓ | ✓ | ✕ | ✕ | ✓ |
| Fairness issues discussion | ✓ | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ |
| Dynamicity issues discussion | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ |
| Trustworthiness issues discussion | ✓ | ✕ | ✕ | ✓ | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ |
| Data Privacy issues discussion | ✕ | ✓ | ✓ | ✓ | ✓ | ✓ | ✕ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| CS Categories | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ |
| Designing an architecture for CS | ✕ | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | ✓ |
| Research Question | Refs. No | Research Type |
|---|---|---|
| RQ1.1 | [38,41,55] | Review |
| [18,54,57] | SLR | |
| [8,28,33,34,39,58,59,60] | Experimental research | |
| [6] | Survey | |
| RQ1.2 | [18,61] | SLR |
| [5,8,37,50,51,57,58,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83] | Experimental research | |
| [36] | Survey | |
| [19,41] | Review | |
| RQ2.1 | [6,41,55] | Review |
| [1,2,4,5,7,8,10,13,26,28,31,33,34,35,40,42,49,52,60,62,84,85,86,87,88,89,90,91,92,93] | Experimental research | |
| [6,36] | Survey | |
| RQ2.2 | [18] | SLR |
| [1,2,5,8,13,28,33,34,35,40,49,62,84] | Experimental research | |
| [38] | Review |
| CS Methods | CS Challenges | Ref. No. | Main Characteristics | Applications | Strategy | Evaluation Metrics |
|---|---|---|---|---|---|---|
| Clustering | statistical heterogeneity | [28] | Non-IID data | Mobile/the IoT devices | CFL | Accuracy, F1 score, Micro-Acc, Micro-F1 Macro-Acc, Macro-F1 |
| [89] | Mobile phones/IoTs | Federated SEM | Ac, Convergence speed, Communication round | |||
| [90] | Wireless edge | Federated MF | Accuracy, Convergence speed, Communication round | |||
| [31] | Recommender systems | Iterative FCA | Accuracy | |||
| [13] | Industrial IoT | Gradient-based Binary P-CS | Accuracy, Convergence speed | |||
| [10] | Unbalanced Data | Recommendation systems | 3-step modular solution | Iteration count | ||
| Client Heterogeneity | [49] | Statistical heterogeneity communication cost | Mobile Phones | One-Shot FC, k-FED | Accuracy, Convergence speed | |
| [4] | Computation and communication cost issues | Mobile and IoT devices | FL with HC | Accuracy, Convergence speed, training round | ||
| [2] | IoT systems- wireless devices | THF | Accuracy, Convergence speed | |||
| Greedy Selection | Client Heterogeneity | [40] | Bandwidth allocation issues | Mobile devices | Wireless FL network (WFLN) | Accuracy, Convergence speed |
| [33] | Communication cost issues | Wireless communication | dynamic sampling | Accuracy | ||
| [8] | Computational resources | MEC | Fed CS | Accuracy | ||
| [85] | Convergence time communication computation constraint | IoT devices | Online Hybrid FL | Accuracy | ||
| Random Selection | statistical heterogeneity | [86] | Bandwidth allocation | Wireless FL system | Accuracy, Latency | |
| [42] | Energy consumption, delay, computation cost issues | Edge networks | A data-centric CS, DICE | Accuracy, Training round, Training time | ||
| Client Heterogeneity | [26] | Energy consumption, latency issues | IoT | ELASTIC | Number of selected clients and energy consumption | |
| [5] | Bandwidth allocation issues | IoT networks | FL in fog-aided IoT ALTD | Accuracy, Convergence speed | ||
| [87] | Resource allocation- Convergence issues | MUEs | Scheduling and resource allocation | Accuracy, Convergence speed | ||
| [88] | Model training efficiency, resource constraints | Stochastic integer CS | Accuracy | |||
| Multi-armed bandit-based Selection | Client Heterogeneity | [93] | Training latency, dynamic wireless environment | Wireless networks | A CS based on UCB and queue | Accuracy, Convergence speed |
| [7] | Training latency | Online scheduling scheme | Accuracy, Training latency | |||
| [84] | Convergence issues and Volatility | IoT devices | CE Participation Data | Accuracy, Convergence speed | ||
| statistical heterogeneity | [52] | Data Quality (Mislabeled and non-IID) | Wireless networks | AUCTION | Accuracy, Scalability | |
| [91] | Training performance communication time | Mobile devices | Context-aware Online CS | Accuracy, Convergence speed | ||
| Fairness | [35] | Training efficiency | IoT | (Exp3)-based CS | Accuracy, the communication rounds | |
| [34] | Convergence speed-the training latency | IoT | CEB3 | |||
| [1] | Fairness-guaranteed, RBCS-F | Accuracy, Training time | ||||
| [62] | UCB-GS | Communication and computational cost, Execution time | ||||
| [92] | FLACOS | Accuracy, Convergence speed, Training time |
| CS Strategies | Advantages | Disadvantages |
|---|---|---|
| Random |
|
|
| Greedy |
|
|
| Clustering |
|
|
| MAB |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khajehali, N.; Yan, J.; Chow, Y.-W.; Fahmideh, M. A Comprehensive Overview of IoT-Based Federated Learning: Focusing on Client Selection Methods. Sensors 2023, 23, 7235. https://doi.org/10.3390/s23167235
Khajehali N, Yan J, Chow Y-W, Fahmideh M. A Comprehensive Overview of IoT-Based Federated Learning: Focusing on Client Selection Methods. Sensors. 2023; 23(16):7235. https://doi.org/10.3390/s23167235
Chicago/Turabian StyleKhajehali, Naghmeh, Jun Yan, Yang-Wai Chow, and Mahdi Fahmideh. 2023. "A Comprehensive Overview of IoT-Based Federated Learning: Focusing on Client Selection Methods" Sensors 23, no. 16: 7235. https://doi.org/10.3390/s23167235