
Lightweight Model for Pavement Defect Detection Based on Improved YOLOv7
Abstract
:1. Introduction
2. Related Work
2.1. YOLOv7
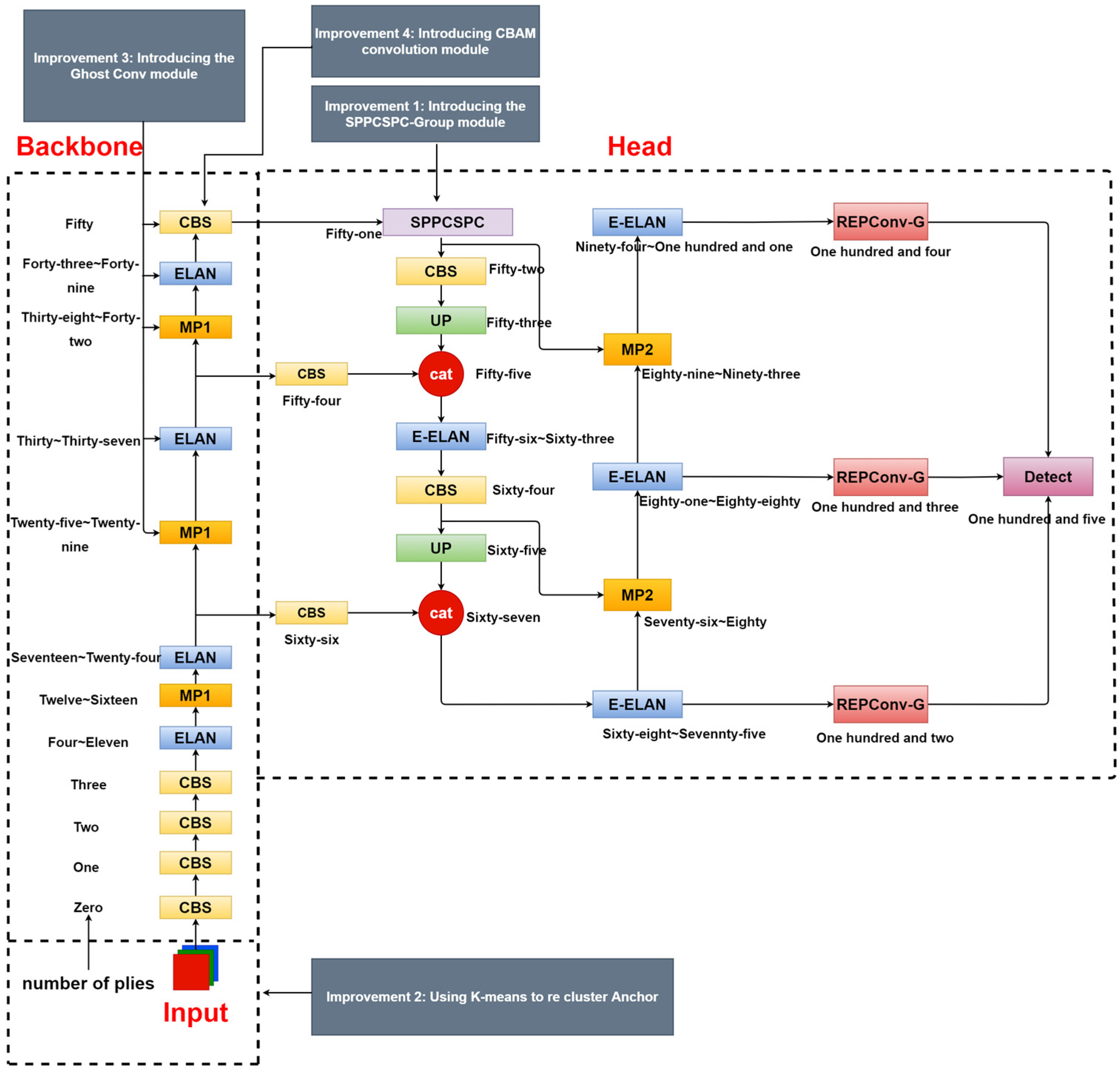
2.2. Improved YOLOv7 Network Model
2.3. SPPCSPC_Group: Group Space Pyramid Pooling Module
2.4. K-Means
2.5. Ghost Conv Module
2.6. CBAM Attention Mechanism
2.6.1. Channel Attention Module
2.6.2. Spatial Attention Module
3. Experiment Materials
3.1. Experiment Environment
3.2. Evaluation Index
3.3. Data Collection and Processing
4. Results and Discussion
4.1. Introduction of SPPCSPC_Group Group Space Pyramid Pooling Module
4.2. Reset a Priori Frame Comparison Experiment
4.3. Effect of Adding GhostConv on the Network with Different Convolutional Layers
4.4. Adding the CBAM Attention Mechanism
4.5. Ablation Experiments
4.6. Comparison Experiments of Different Network Models
4.7. Comparison of the Experiments of the Different Network Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yin, F.; Mei, S. The Ministry of Transport issued the “Statistical Bulletin on the Development of the Transportation Industry in 2021”. Shuidao Port 2022, 43, 346. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Ye, G.; Qu, J.; Tao, J.; Dai, W.; Mao, Y.; Jin, Q. Autonomous surface crack identification of concrete structures based on the YOLOv7 algorithm. J. Build. Eng. 2023, 73, 106688. [Google Scholar] [CrossRef]
- Chen, J.; Liu, H.; Zhang, Y.; Zhang, D.; Ouyang, H.; Chen, X. A Multiscale Lightweight and Efficient Model Based on YOLOv7: Applied to Citrus Orchard. Plants 2022, 11, 3260. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight underwater object detection based on yolo v4 and multi-scale attentional feature fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Li, C.; Wang, Y.; Liu, X. An Improved YOLOv7 Lightweight Detection Algorithm for Obscured Pedestrians. Sensors 2023, 23, 5912. [Google Scholar] [CrossRef]
- Zhou, L.; Wei, S.; Cui, Z.; Fang, J.; Yang, X.; Ding, W. Lira-YOLO: A lightweight model for ship detection in radar images. J. Syst. Eng. Electron. 2020, 31, 950–956. [Google Scholar] [CrossRef]
- Du, F.J.; Jiao, S.J. Improvement of lightweight convolutional neural network model based on YOLO algorithm and its research in pavement defect detection. Sensors 2022, 22, 3537. [Google Scholar] [CrossRef]
- Jiang, J.; Fu, X.; Qin, R.; Wang, X.; Ma, Z. High-speed lightweight ship detection algorithm based on YOLO-v4 for three-channels RGB SAR image. Remote Sens. 2021, 13, 1909. [Google Scholar] [CrossRef]
- Wan, F.; Sun, C.; He, H.; Lei, G.; Xu, L.; Xiao, T. YOLO-LRDD: A lightweight method for road damage detection based on improved YOLOv5s. EURASIP J. Adv. Signal Process. 2022, 2022, 98. [Google Scholar] [CrossRef]
- Fang, W.; Wang, L.; Ren, P. Tinier-YOLO: A Real-Time Object Detection Method for Constrained Environments. IEEE Access 2020, 8, 1935–1944. [Google Scholar] [CrossRef]
- Wang, G.; Ding, H.; Yang, Z.; Li, B.; Wang, Y.; Bao, L. TRC-YOLO: A real-time detection method for lightweight targets based on mobile devices. IET Comput. Vis. 2022, 16, 126–142. [Google Scholar] [CrossRef]
- Xia, Y.; Nguyen, M.; Yan, W.Q. A Real-Time Kiwifruit Detection Based on Improved YOLOv7. In Proceedings of the Image and Vision Computing: 37th International Conference, IVCNZ 2022, Auckland, New Zealand, 24–25 November 2022; Revised Selected Papers. Springer Nature: Cham, Switzerland, 2023; pp. 48–61. [Google Scholar]
- Liu, H.; Fan, Y.; He, H.; Hui, K. Improved YOLOv7-tiny object detection lightweight model. Comput. Eng. Appl. 2023, 59, 166–175. [Google Scholar]
- Duan, B.; Ma, M. Research on Mask Detection Based on Improved YOLOv5 Algorithm. Comput. Eng. Appl. 2023, 1–11. [Google Scholar] [CrossRef]
- Tu, C.; Yi, A.; Yao, T.; He, W. High-precision Garbage Detection Algorithm of Lightweight YOLOv5n. Comput. Eng. Appl. 2023, 59, 187–195. [Google Scholar]
- Ma, D.; Fang, H.; Wang, N.; Zhang, C.; Dong, J.; Hu, H. Automatic Detection and Counting System for Pavement Cracks Based on PCGAN and YOLO-MF. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22166–22178. [Google Scholar] [CrossRef]
- Kaya, Ö.; Çodur, M.Y.; Mustafaraj, E. Automatic Detection of Pedestrian Crosswalk with Faster R-CNN and YOLOv7. Buildings 2023, 13, 1070. [Google Scholar] [CrossRef]
- Que, Y.; Dai, Y.; Ji, X.; Leung, A.K.; Chen, Z.; Tang, Y.; Jiang, Z. Automatic classification of asphalt pavement cracks using a novel integrated generative adversarial networks and improved VGG model. Eng. Struct. 2023, 277, 115406. [Google Scholar] [CrossRef]
- Huang, L.; Yang, Y.; Yang, C.; Yang, W.; Li, Y. FS-YOLOv5: Lightweight Infrared Object Detection Method. Comput. Eng. Appl. 2023, 59, 215–224. [Google Scholar]
- Zhang, R.; Qu, J.; Li, X.; Ling, X.; Zhu, Z.; Hou, B. Lightweight pineapple heart detection algorithm based on improved YOLOv4. J. Agric. Eng. 2023, 39, 135–143. [Google Scholar]
- Wu, C.; Ye, M.; Zhang, J.; Ma, Y. YOLO-LWNet: A lightweight road damage object detection network for mobile terminal devices. Sensors 2023, 23, 3268. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Xin, Z. Efficient Detection Model of Steel Strip Surface Defects Based on YOLO-V7. IEEE Access 2022, 10, 133936–133944. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Batch_Size | mAP% | FPS | Flops/G | Params/M |
|---|---|---|---|---|
| 8 | 90.6 | 79 | 104.8 | 37.21 |
| 16 | 90.7 | 80 | 104.8 | 37.21 |
| 32 | 90.4 | 80 | 104.8 | 37.21 |
| Parameter Settings | Details |
|---|---|
| Batch_size = 16 | Number of batch processes is 16 |
| Epoch = 150 | Training 150 rounds of data |
| Learing_rate = 0.01 | Initial learning rate of 0.01 |
| SGD | Optimizer |
| Weight_decay = 0.0005 | The weight decay coefficient is 0.0005 |
| Tags | Category | Number |
|---|---|---|
| PSB | Broken version | 623 |
| LF | Fractures | 1423 |
| KD | Pothole | 1185 |
| XB | Repair | 605 |
| FJX | Dividing Line | 2626 |
| Model | Layer | mAP% | FPS | Flops/G | Params/M |
|---|---|---|---|---|---|
| SPPCSPC | Layer = 51 | 90.7 | 77 | 104.8 | 37.21 |
| SPPCSPC_Group | Layer = 51 | 91.2 | 78 | 100.3 | 31.51 |
| Algorithm | Dimension Value | mAP% | FPS | Ratio of Prior Box to Target Box | BPR |
|---|---|---|---|---|---|
| K-means | [12,16, 19,36, 40,28] [36,37, 76,55, 72,146] [142,110, 192,243, 459,401] | 90.7 | 77 | 3.67 | 0.9932 |
| K-means (1-iou) | [12,7, 23,9, 21,16] [49,15, 52,41, 127,37] [70,133, 208,95, 322,202] | 91.8 | 79 | 4.2 | 1 |
| Attentional Mechanisms | Layer | mAP% | FPS | Flops/G | Params/M |
|---|---|---|---|---|---|
| Conv | Layer = 50 | 90.7 | 77 | 104.8 | 37.21 |
| CBAM | Layer = 50 | 90.9 | 78 | 105 | 37.34 |
| Attentional Mechanisms | Layer | mAP% | FPS | Flops/G | Params/M |
|---|---|---|---|---|---|
| Conv | Layer = 50 | 90.7 | 77 | 104.8 | 37.21 |
| CBAM | Layer = 50 | 90.9 | 78 | 105 | 37.34 |
| Model | Ghost Conv | K-Means | CBAM | SPPCSPC_Group | mAP% | FPS | Flops/G | Params/M | Size/MB |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv7 | × | × | × | × | 90.7 | 77 | 104.8 | 37.22 | 71.369 |
| YOLOv7+GK | √ | √ | × | × | 90.7 | 68 | 93.6 | 31.37 | 60.281 |
| YOLOv7+GC | √ | × | √ | × | 90.4 | 64 | 94.2 | 32.02 | 61.508 |
| YOLOv7+GS | √ | × | × | √ | 90 | 72 | 89.5 | 26.19 | 50.379 |
| YOLOv7+GKC | √ | √ | √ | × | 90.5 | 72 | 94.2 | 32.02 | 61.508 |
| YOLOv7+GKS | √ | √ | × | √ | 89.4 | 72 | 89.1 | 25.67 | 49.406 |
| YOLOv7+KC | × | √ | √ | × | 90.8 | 73 | 105 | 37.35 | 71.623 |
| YOLOv7+KS | × | √ | × | √ | 91.7 | 79 | 100.3 | 31.52 | 60.494 |
| YOLOv7+CS | × | × | √ | √ | 90.9 | 78 | 100.5 | 31.65 | 60.748 |
| YOLOv7+GKCS | √ | √ | √ | √ | 91 | 80 | 89.7 | 26.32 | 50.633 |
| Data Set | Model | mAP% | FPS | Flops/G | Params/M |
|---|---|---|---|---|---|
| RDD2022 Japan | YOLOv7 | 67.2 | 74 | 104.8 | 37.21 |
| RDD2022 Japan | YOLOv7+GKCS | 70.5 (+3.3) | 78 | 89.7 | 26.32 |
| RDD2022 US | YOLOv7 | 64.3 | 65 | 104.8 | 37.21 |
| RDD2022 US | YOLOv7+GKCS | 66.4 (+2.1) | 74 | 89.7 | 26.32 |
| Model | Backbone Network | mAP% | FPS |
|---|---|---|---|
| Faster R-CNN | Resnext101 | 89 | 40 |
| YOLOv3 | CSPdarknet | 78 | 60 |
| YOLOv4 | CSPdarknet | 85 | 70 |
| YOLOv5 | CSPdarknet | 90 | 72 |
| YOLOv7 | 90.7 | 77 | |
| YOLOv8 | CSPdarknet | 88 | 78 |
| Ours | 91 | 80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, P.; Wang, S.; Chen, J.; Li, W.; Peng, X. Lightweight Model for Pavement Defect Detection Based on Improved YOLOv7. Sensors 2023, 23, 7112. https://doi.org/10.3390/s23167112
Huang P, Wang S, Chen J, Li W, Peng X. Lightweight Model for Pavement Defect Detection Based on Improved YOLOv7. Sensors. 2023; 23(16):7112. https://doi.org/10.3390/s23167112
Chicago/Turabian StyleHuang, Peile, Shenghuai Wang, Jianyu Chen, Weijie Li, and Xing Peng. 2023. "Lightweight Model for Pavement Defect Detection Based on Improved YOLOv7" Sensors 23, no. 16: 7112. https://doi.org/10.3390/s23167112