3.1. System Specifications
The procedure to build a Reinforcement Learning environment in game engines is as follows: defining agents (observation, action), rewards, and selecting algorithms.
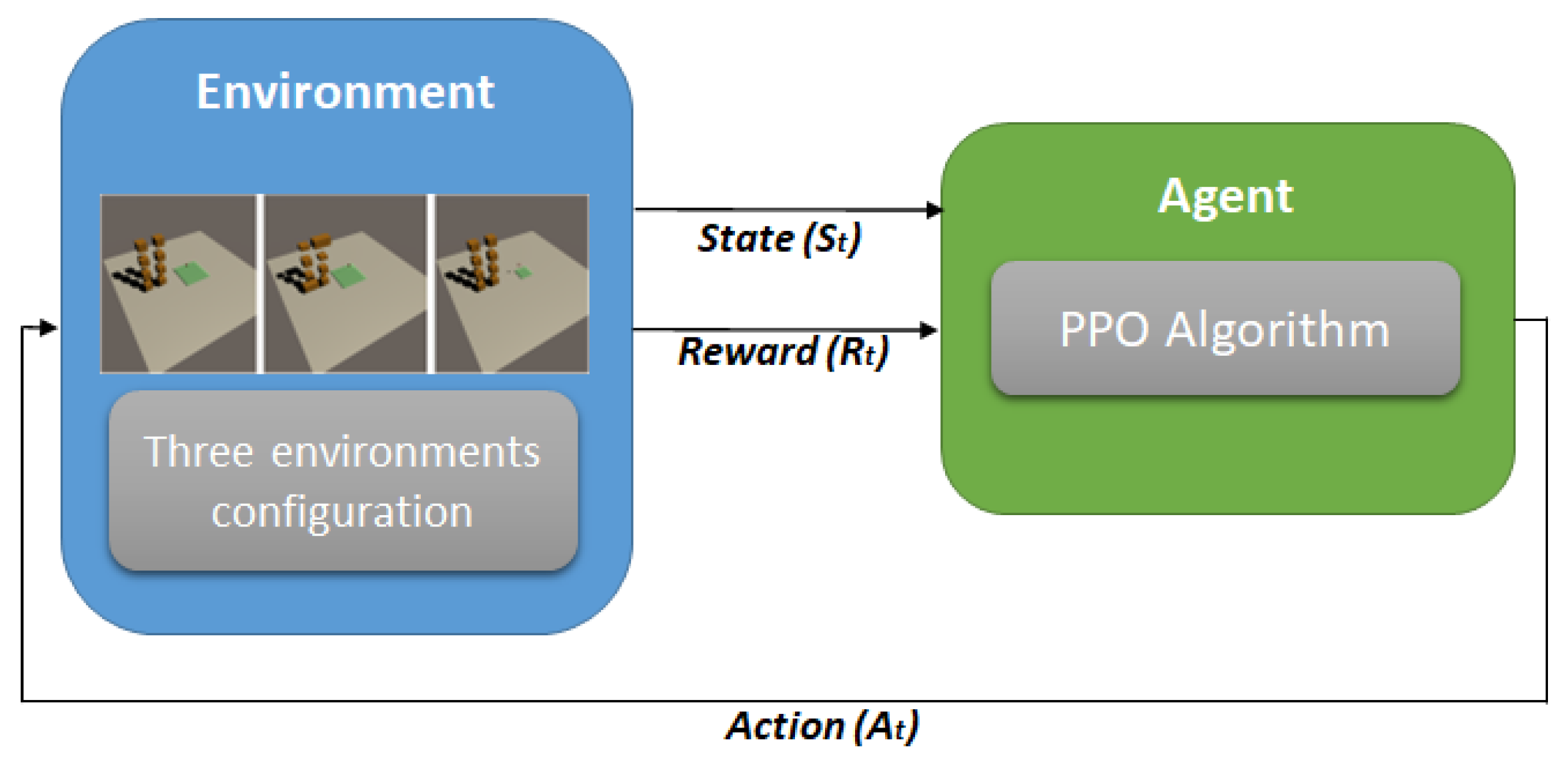
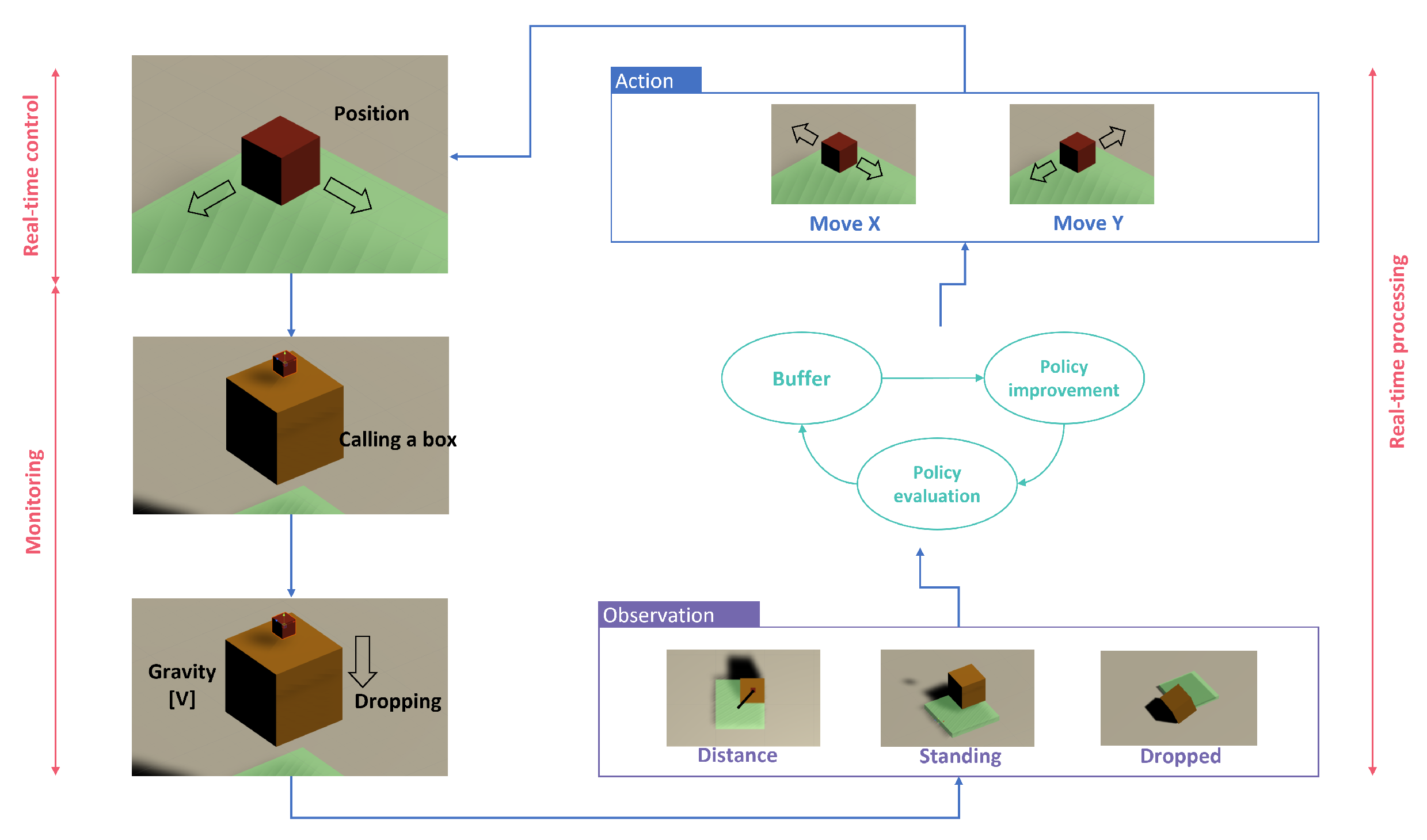
Figure 1 depicts the structure of the DRL concept in the proposed work. It consists of three dynamic environment settings and an agent. The environments are the layout of warehouses in a simplified manner, and the agent is the box that should learn how to load the box into the designated plate, which is the simulation of the space inside the container.
In order to design a Reinforcement Learning environment and an agent, it is recommended to go through the following process:
- 1.
Define goals or specific tasks to be learned.
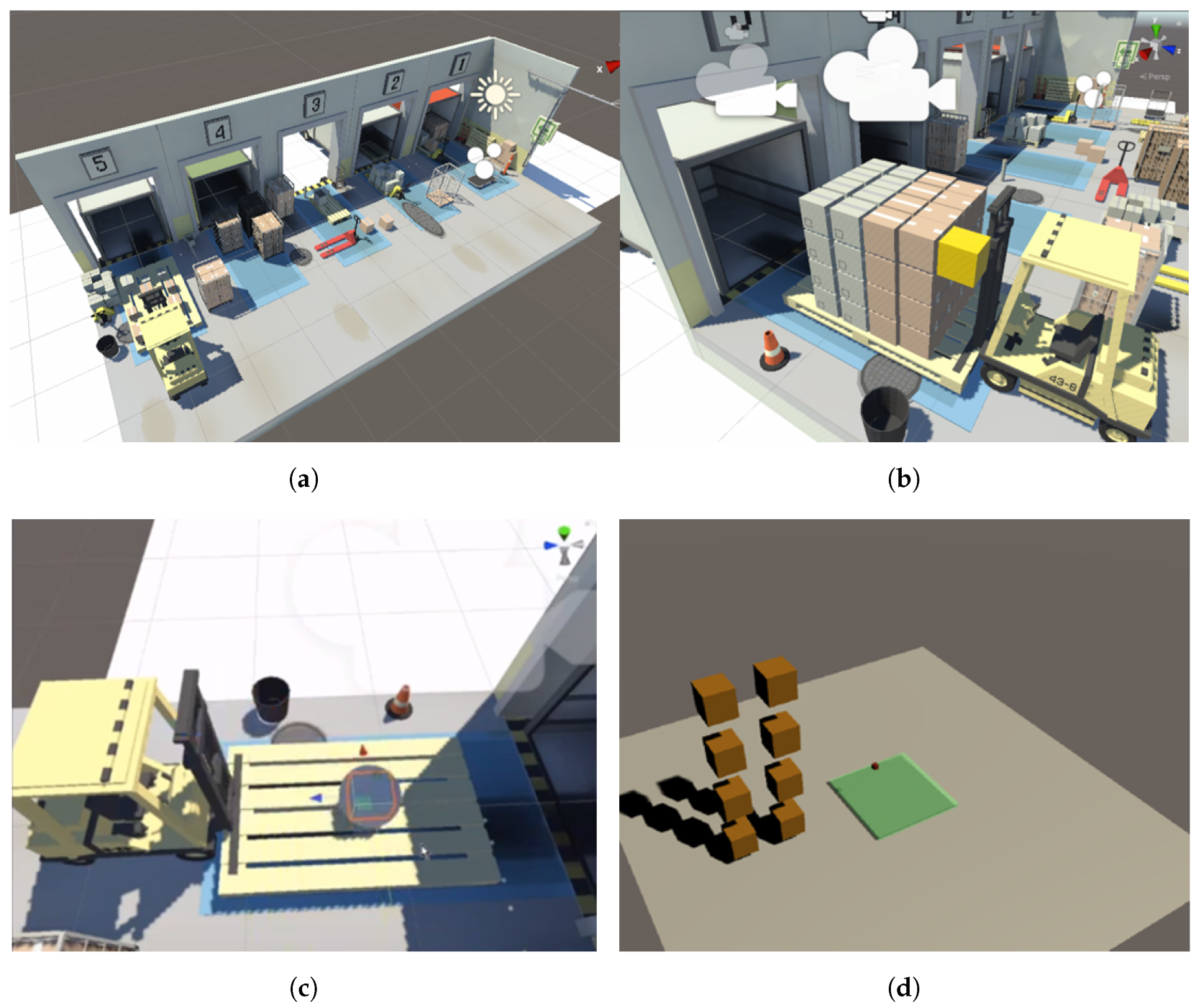
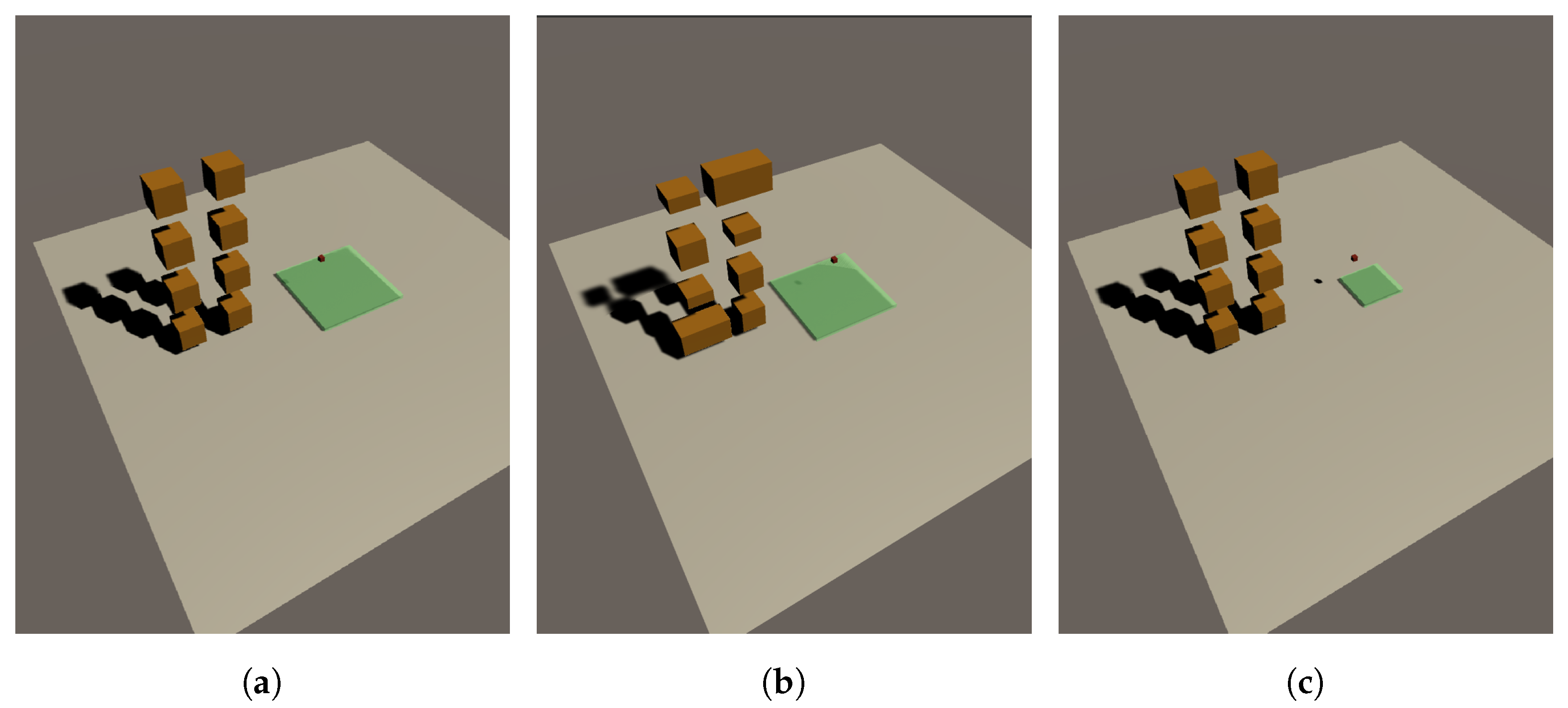
The goal of this study is to train an agent to stack boxes on a designated plate area, with the goal of ensuring that the boxes are centered on the center of the plate. The training process is conducted in a simulated warehouse environment that is designed to be visually similar to a real-world setting. The warehouse contains five slots, but for the purpose of the training, only one slot is used, as all the slots are identical. This allows for more efficient training by eliminating the need to consider variations between slots. To facilitate the observation of the learning process, the training of the boxes is initially conducted in a simplified environment that consists of only eight boxes. This allows for a clearer understanding of the learning dynamics without the added complexity of a larger number of boxes. The proposed work environment settings are shown in
Figure 2.
- 2.
Define agents.
The agent is the one that acts in Reinforcement Learning. The agent may be an actual object or an abstract object inside the Reinforcement Learning environment. In the context of this study, the agent is represented by a small box placed in the center of the plate. Through the process of Reinforcement Learning, the agent will learn to determine the optimal position for placing the real boxes on the plate one by one. Since the agent has to act directly and achieve its goals, an agent script to an actual object was assigned.
- 3.
Define agents’ behavior and observation.
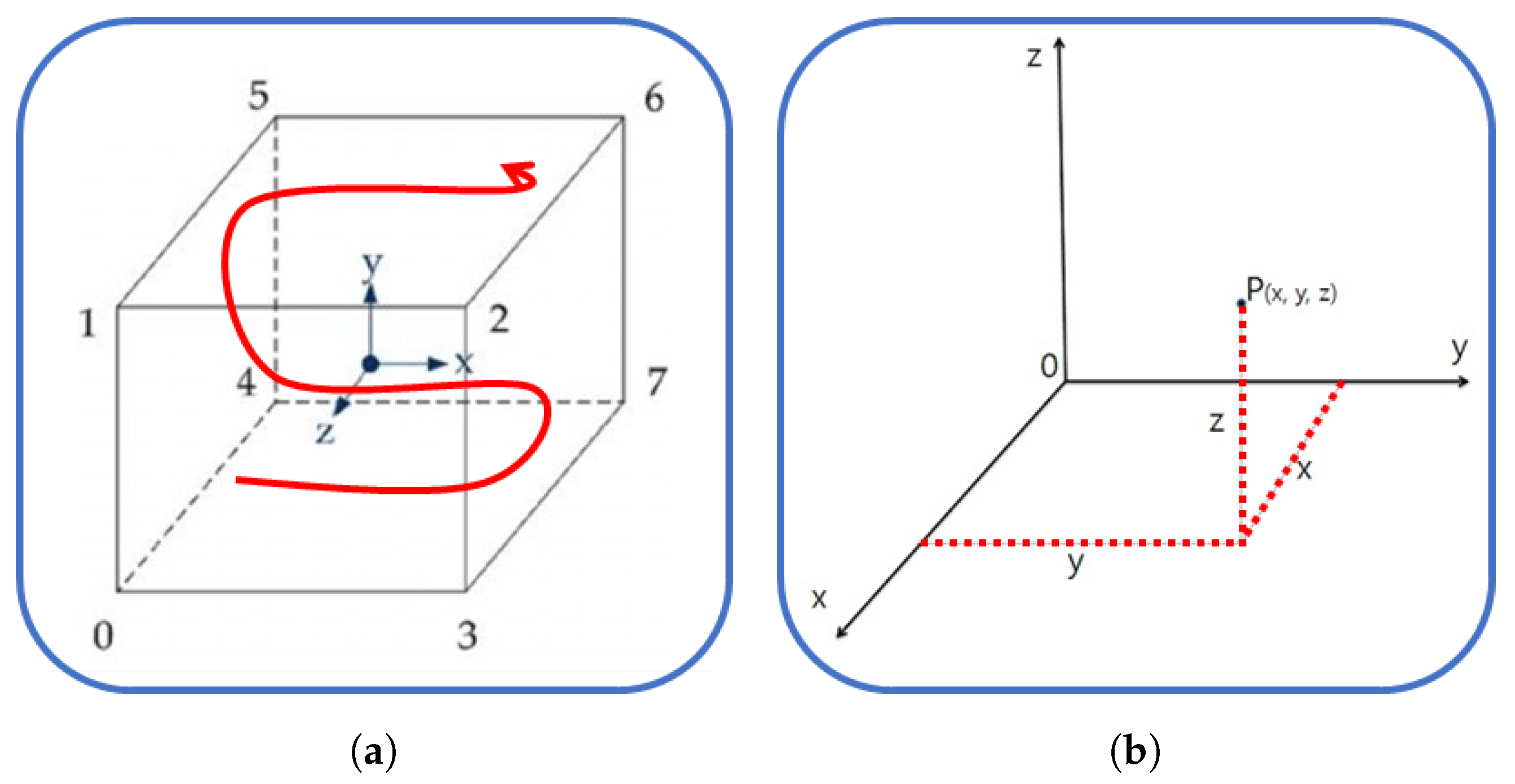
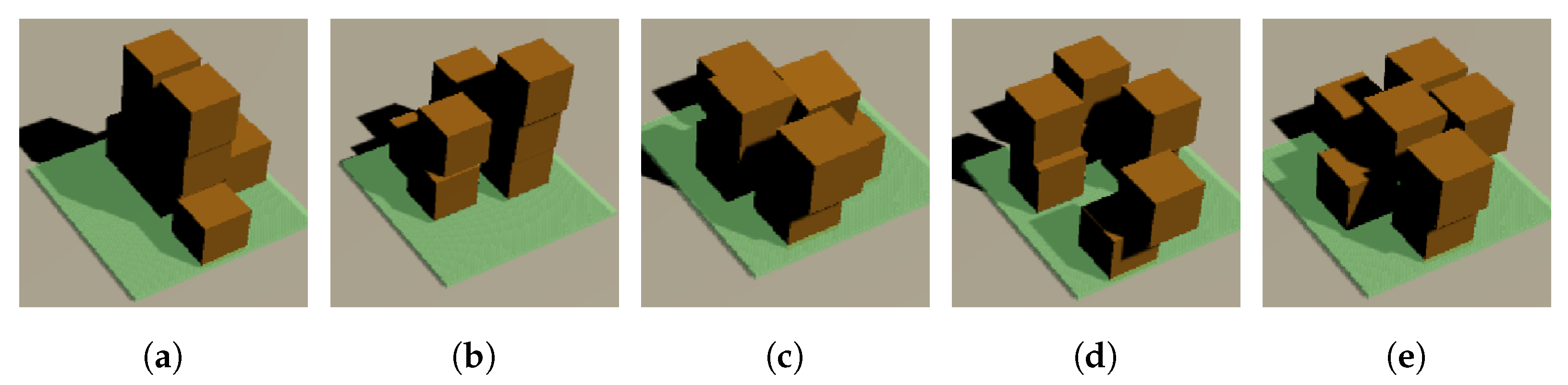
In the learning environment, the agent must define what information and behavior to observe. The Reinforcement Learning model uses observation information as an input of the model and outputs the value of the state or behavior. In this study, the agent generates a box (object which needed to load). Generating a box is the action of the agent. Agent observes the generated box’s positions and how many boxes are stacked. The agent receives rewards if all the layers are stacked. In the initial stages of this research, the agent was programmed to move in three dimensions (x, y, and z axes) during the learning process, as shown in
Figure 3a. However, the complexity of the problem was found to be excessively high (approximately O(6
1000000)), due to the infinite trajectory space. As a result, the agent was subsequently modified to generate movement only on the x and y axes (
Figure 3b), reducing the complexity of the problem (O(4
1000000)).
- 4.
Define the reward.
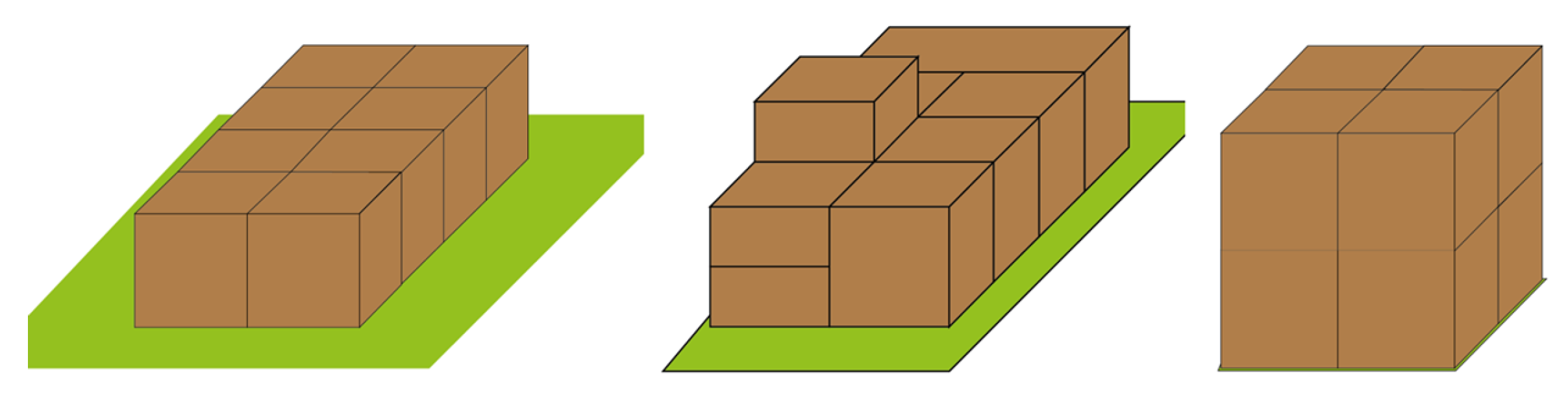
Next, and the most important, the reward for Reinforcement Learning should be defined. No matter how well the environment and agent are designed, the agent cannot learn what the target is unless a reward is given. The reward should be provided when the agent acts and satisfies certain conditions. At this time, the amount of the reward and the timing of reward are important. Determining the informativeness of a reward function is an essential issue [
36,
37]. The agent will get a reward after being able to stack the boxes, and after all the boxes are stacked, an evaluation will be made of which solution is close to the optimal solution, as illustrated in
Figure 4. The reward function used in this study can be seen in Algorithm 1.
| Algorithm 1: Box Stacker Agent Learning |
![Sensors 23 06928 i001]() |
- 5.
Define the conditions of the start and end of the episode.
The initial state and termination conditions must be set at the beginning of the episode. The end of the episode is divided into success and failure in achieving the goal, and rewards for success and failure must also be allocated. At the end of the episode, the episode begins again, and at this time, learning begins again to its initial state. If the initial state (agent location, environment information) is set randomly, learning takes longer, but more general performance can be expected. In this study, the environment consists of a plane for stacking boxes, a thin collider surrounding the plane, and an agent. The agent’s goal is to create a target point within the specified range of the plane and then place a box at that point. If the box collides with a virtual wall or goes out of bounds during the process of placing it, the agent receives punishment, and the episode is terminated. Therefore, the stacking attempts will restart from the first box again. However, if all the boxes are placed without collision, the agent is rewarded for successfully stacking one floor. The agent inputs the information of the changed environment into the observation and then creates a new coordinate to place another box at the target point. This process is repeated until the agent either succeeds in stacking all the boxes or receives punishment for an unsuccessful attempt.
- 6.
Reinforcement learning model (algorithm) selection.
The Reinforcement Learning algorithm is divided into a value-based algorithm and a policy-based algorithm. In this case, if there is a probabilistic element in the environment, it is recommended to use a policy gradient-based algorithm. In general, policy gradient-based algorithms perform better in environments such as robot control. A detailed explanation about algorithms used in this study will be explained in the next subsection.
3.2. Algorithm
The Proximal Policy Optimization (PPO) Algorithm by Schulman et al. is a prominent policy gradient algorithm for solving the optimization problem [
38], and has proven to learn policies more efficiently than Trust Region Policy Optimization (TRPO) [
39]. From past studies, this algorithm achieved better overall performance while also ease of implementation and hyperparameter tuning to achieve even better results. PPO performs each policy update over numerous epochs of stochastic gradient ascent. In the case of ML-Agents, PPO is recommended since it provides more stable results in the environment and has better generalization ability [
40]. Therefore, PPO algorithms are chosen to implement the model in this study.
After initializing the policy parameters,
, it collects a batch of transitions (
st,
at,
rt,
st) from the environment using the current policy. Then, it estimates the expected reward gradient in relation to the parameters of the policy as follows:
where
N is the number of transitions in the batch,
is the probability of taking action
in state
according to the current policy, and
is the advantage function for the
t-th transition. Then, compute the PPO objective function:
where
is the ratio of the new and old policy probabilities and
is a hyperparameter that limits the size of the policy updates. Lastly, perform a gradient ascent step on the PPO objective function:
where
is the learning rate. This update step is repeated until the policy has converged.
3.3. Workflow of Deep Reinforcement Learning
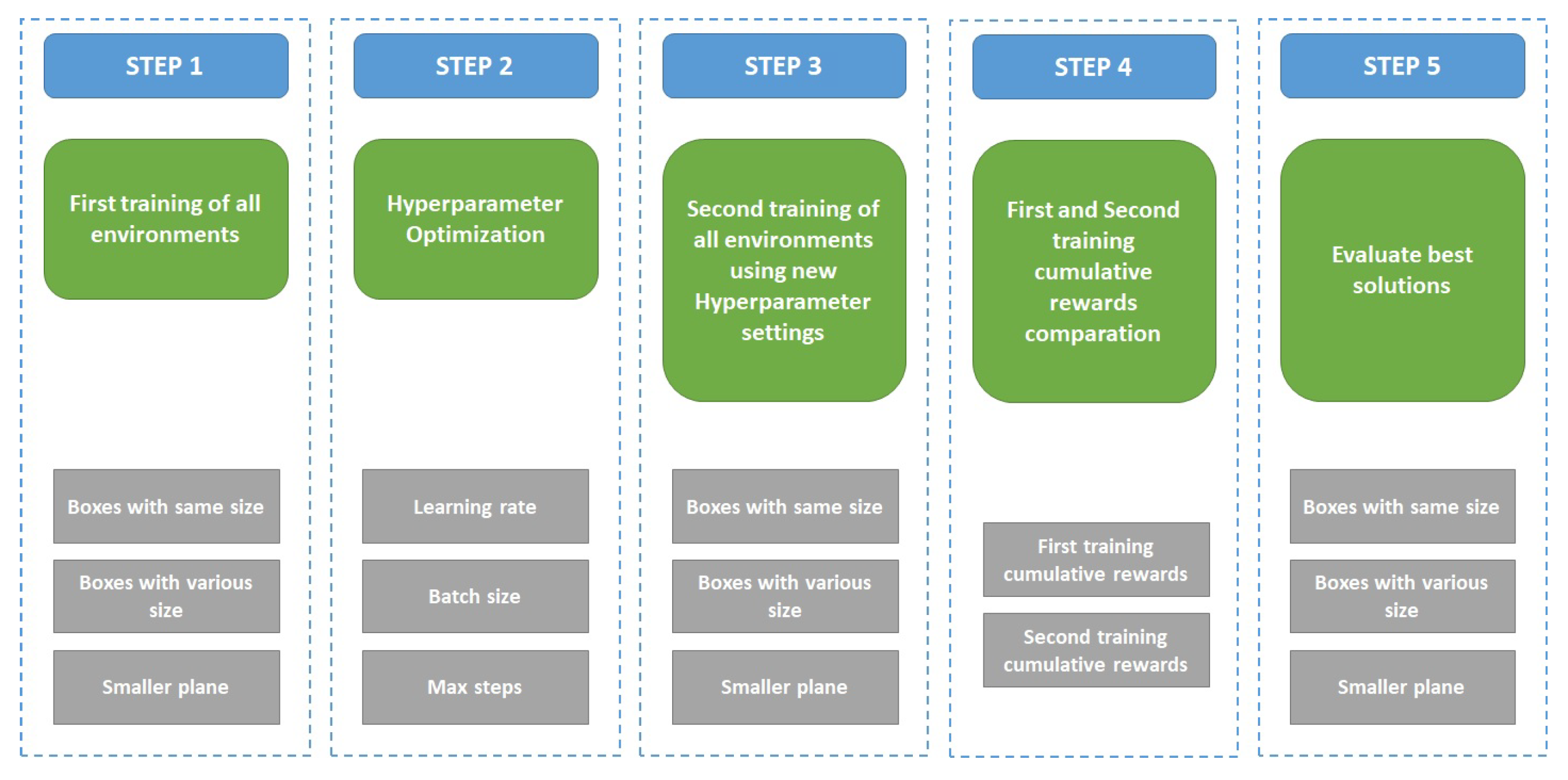
Algorithm 1 outlines the process of training an agent to stack boxes in this study. The training process involves moving the agent, represented by a box pointer, to stack the boxes. If the current box is out of bounds or successfully stacked, the agent receives a reward, and the current box is moved. The training process is terminated when the index for the current box reaches the total number of boxes, at which point the episode is marked as a success or failure depending on whether all the boxes were stacked. The agent receives a positive or negative reward in each case. The training process is terminated when the maximum number of steps is reached.
Basic objects of Reinforcement Learning are a plate to support the dropping boxes, a pointer to call each box during flying over the plate, and boxes waiting for loading on the plate. The agent of the pointer reports observations and rewards after conducting actions generated by the PPO algorithm, as shown in
Figure 5. First, the pointer moves along the X and Y axis. Next, each box is transferred to the position of the point and dropped when gravity is applied to the box. The agent checks if the box stands on the plate or drops out. The reward is a plus value when standing while a minus value when dropping out.
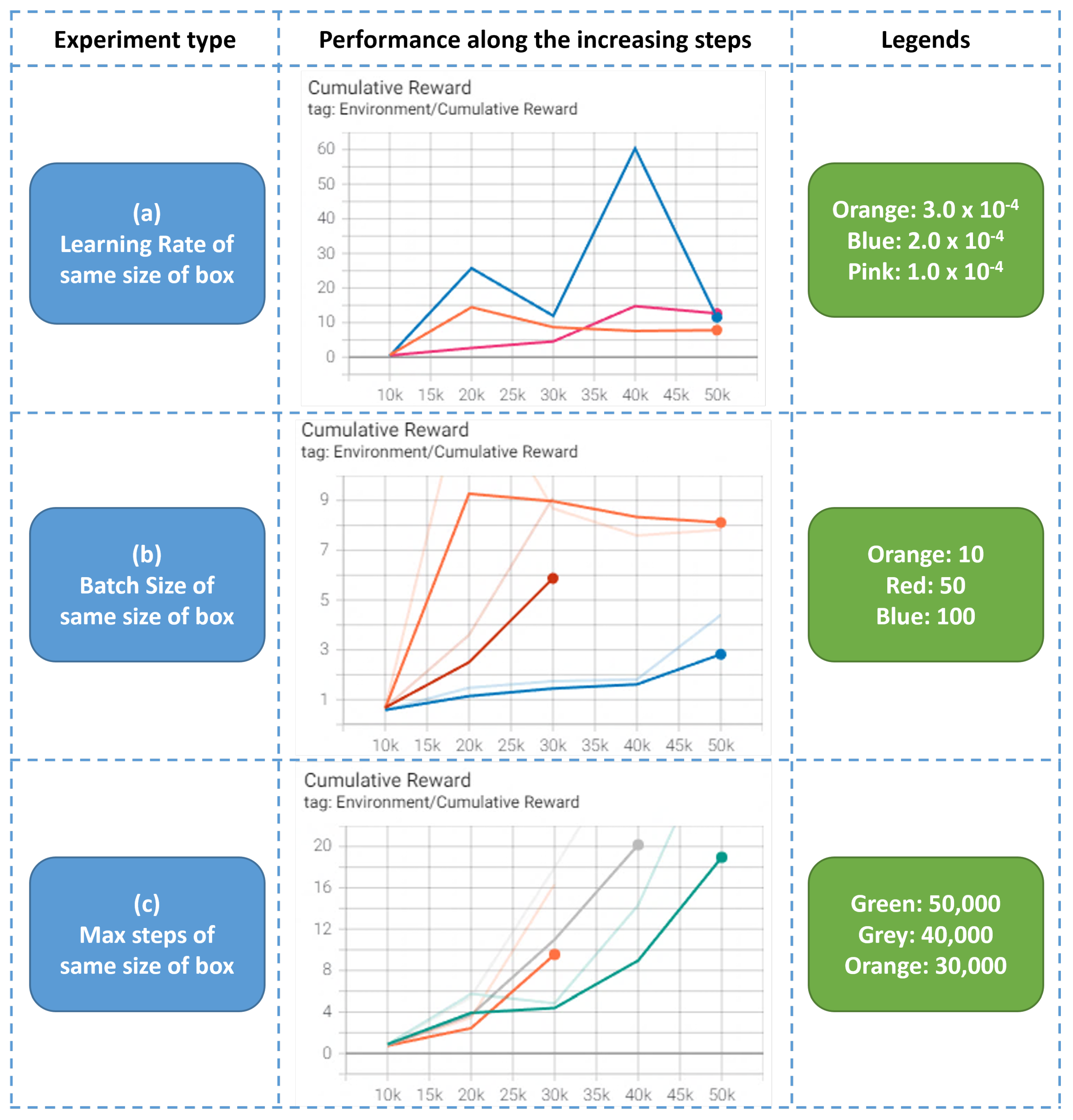
The reward of each agent action is the distance of each box from the center of the plate step by step, as well as the final status of the dropped box. In addition, the PPO algorithm will be used for training, with the following hyperparameter settings, as shown in
Table 1.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}