
An Underwater Image Enhancement Method for a Preprocessing Framework Based on Generative Adversarial Network
 ,
, 
 ,
,
Abstract
:1. Introduction
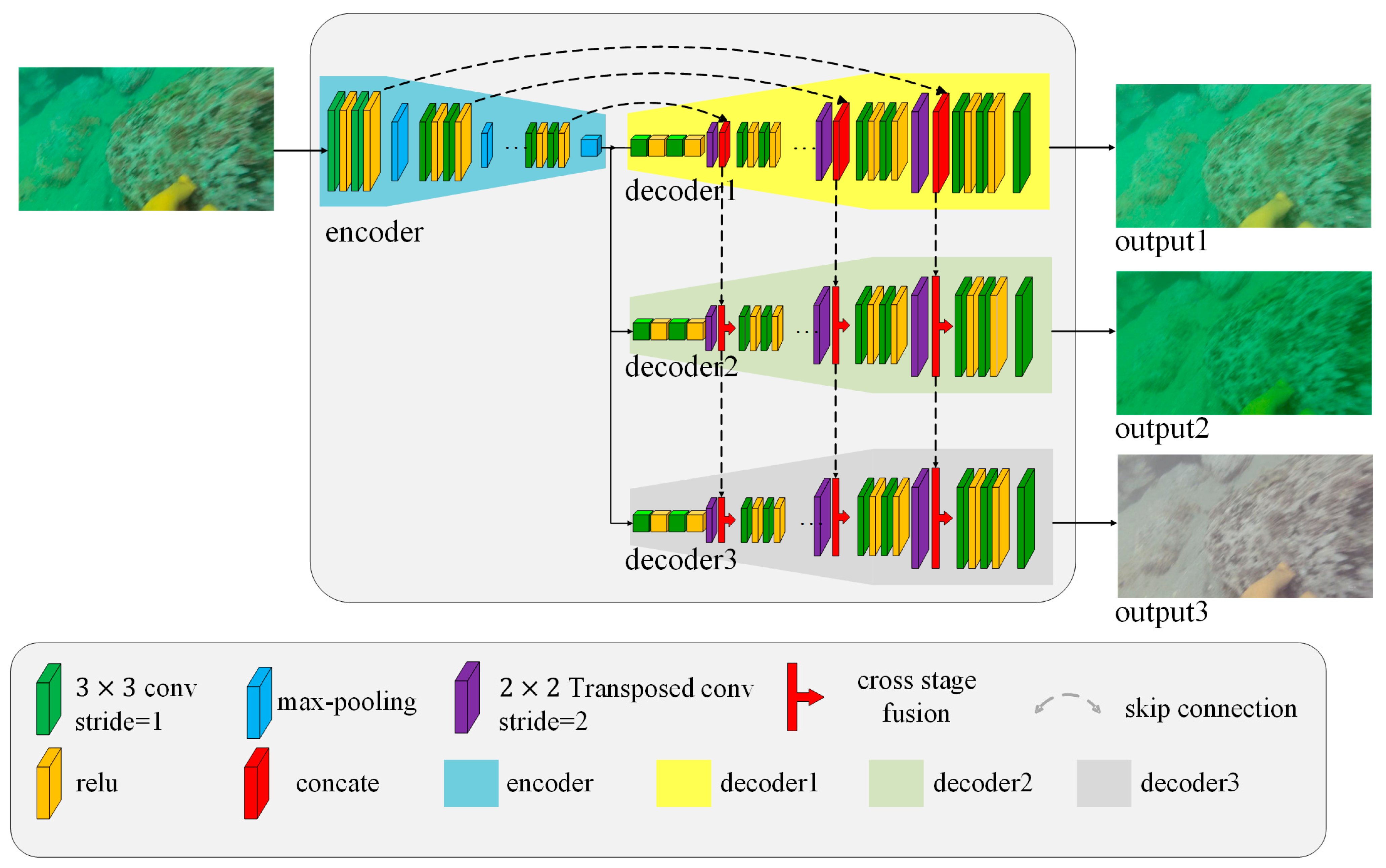
2. Underwater Image Enhancement Network
2.1. Generator
2.2. Discriminator
2.3. Loss Function
2.3.1. Loss Function of the Generator
2.3.2. The Loss Function of the Discriminator
3. Experiment
3.1. Evaluation Indicator
3.2. Experimental Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Drews, P.; Nascimento, E.R.; Botelho, S.S.C.; Campos, M.F.M. Underwater Depth Estimation and Image Restoration Based on Single Images. IEEE Comput. Graph. Appl. 2016, 36, 24–35. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.-T.; Cao, K.; Cosman, P.C. Generalization of the Dark Channel Prior for Single Image Restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef] [PubMed]
- Carlevaris-Bianco, N.; Mohan, A.; Eustice, R.M. Initial results in underwater single image dehazing. In Proceedings of the Oceans 2010 Mts/IEEE Seattle, Seattle, DC, USA, 20–23 September 2010; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Li, C.-Y.; Guo, J.-C.; Cong, R.-M.; Pang, Y.-W.; Wang, B. Underwater Image Enhancement by Dehazing With Minimum Information Loss and Histogram Distribution Prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Guo, J.; Chen, S.; Tang, Y.; Pang, Y.; Wang, J. Underwater image restoration based on minimum information loss principle and optical properties of underwater imaging. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1993–1997. [Google Scholar] [CrossRef]
- Akkaynak, D.; Treibitz, T. A Revised Underwater Image Formation Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6723–6732. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Bekaert, P. Color balance and fusion for underwater image enhancement. IEEE Trans. Image Process. 2018, 27, 379–393. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, X.; Zhuang, P.; Huang, Y.; Liao, Y.; Zhang, X.-P.; Ding, X. A retinex-based enhancing approach for single underwater image. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4572–4576. [Google Scholar] [CrossRef]
- Fu, X.; Fan, Z.; Ling, M.; Huang, Y.; Ding, X. Two-step approach for single underwater image enhancement. In Proceedings of the 2017 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Xiamen, China, 6–9 November 2017; pp. 789–794. [Google Scholar] [CrossRef]
- Fabbri, C.; Islam, J.; Sattar, J. Enhancing Underwater Imagery Using Generative Adversarial Networks. arXiv 2018, arXiv:1801.04011. [Google Scholar]
- Yu, X.; Qu, Y.; Hong, M. Underwater-GAN: Underwater Image Restoration via Conditional Generative Adversarial Network. In Proceedings of the Pattern Recognition and Information Forensics: ICPR 2018 International Workshops, CVAUI, IWCF, and MIPPSNA, Beijing, China, 20–24 August 2018; Springer: Cham, Switzerland, 2018; pp. 66–75. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Guo, C. Emerging From Water: Underwater Image Color Correction Based on Weakly Supervised Color Transfer. IEEE Signal Process. Lett. 2018, 25, 323–327. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Li, N.; Zhang, S.; Yu, Z.; Zheng, H.; Zheng, B. Multi-scale adversarial network for underwater image restoration. Opt. Laser Technol. 2018, 110, 105–113. [Google Scholar] [CrossRef]
- Liu, X.; Gao, Z.; Chen, B.M. MLFcGAN: Multilevel Feature Fusion-Based Conditional GAN for Underwater Image Color Correction. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1488–1492. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised Generative Network to Enable Real-time Color Correction of Monocular Underwater Images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef] [Green Version]
- Islam, J.; Xia, Y.; Sattar, J. Fast Underwater Image Enhancement for Improved Visual Perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Anwar, S.; Li, C.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar]
- Sun, X.; Liu, L.; Li, Q.; Dong, J.; Lima, E.; Yin, R. Deep pixel-to-pixel network for underwater image enhancement and restoration. IET Image Process. 2019, 13, 469–474. [Google Scholar] [CrossRef]
- Hong, L.; Wang, X.; Xiao, Z.; Zhang, G.; Liu, J. WSUIE: Weakly Supervised Underwater Image Enhancement for Improved Visual Perception. IEEE Robot. Autom. Lett. 2021, 6, 8237–8244. [Google Scholar] [CrossRef]
- Wu, S.; Luo, T.; Jiang, G.; Yu, M.; Xu, H.; Zhu, Z.; Song, Y. A Two-Stage Underwater Enhancement Network Based on Structure Decomposition and Characteristics of Underwater Imaging. IEEE J. Ocean. Eng. 2021, 46, 1213–1227. [Google Scholar] [CrossRef]
- Li, Y.; Chen, R. SE–RWNN: An synergistic evolution and randomly wired neural network-based model for adaptive underwater image enhancement. IET Image Process. 2020, 14, 4349–4358. [Google Scholar] [CrossRef]
- Chang, X.; Ren, P.; Xu, P.; Li, Z.; Chen, X.; Hauptmann, A. A Comprehensive Survey of Scene Graphs: Generation and Application. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 45, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Chang, X.; Liu, J.; Luo, M.; Li, Z.; Yao, L.; Hauptmann, A. TN-ZSTAD: Transferable Network for Zero-Shot Temporal Activity Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3848–3861. [Google Scholar] [CrossRef] [PubMed]
- Yan, C.; Chang, X.; Li, Z.; Guan, W.; Ge, Z.; Zhu, L.; Zheng, Q. ZeroNAS: Differentiable Generative Adversarial Networks Search for Zero-Shot Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9733–9740. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Huang, P.Y.; Chang, X.; Hu, J.; Yang, Y.; Hauptmann, A. Video Pivoting Unsupervised Multi-Modal Machine Translation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3918–3932. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Fang, X.; Pan, M.; Yuan, L.; Zhang, Y.; Yuan, M.; Lv, S.; Yu, H. A Marine Organism Detection Framework Based on the Joint Optimization of Image Enhancement and Object Detection. Sensors 2021, 21, 7205. [Google Scholar] [CrossRef] [PubMed]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8877–8886. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR | SSIM | UIQM | UCIQE | ||
|---|---|---|---|---|---|---|
| GT | / | 1.0 | 0.2337 | 0.2524 | ||
| Light | 16.19 | 0.9075 | 0.1404 | 0.2166 | ||
| Sharp | 11.48 | 0.7224 | 0.1467 | 0.2094 | ||
| WB | 31.40 | 0.9613 | 0.1744 | 0.2191 | ||
| Light | Sharp | 11.95 | 0.7609 | 0.1523 | 0.2125 | |
| Light | WB | 24.56 | 0.9587 | 0.1867 | 0.2214 | |
| Sharp | WB | 21.79 | 0.9487 | 0.1899 | 0.2170 | |
| Light | Sharp | WB | 24.12 | 0.9521 | 0.1985 | 0.2263 |
| Method proposed by Zhang et al. in [27] | 17.29 | 0.7648 | 0.1556 | 0.1678 | ||
| ECO-GAN | 32.71 | 0.9783 | 0.1970 | 0.2016 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, X.; Yu, H.; Zhang, Y.; Pan, M.; Li, Z.; Liu, J.; Lv, S. An Underwater Image Enhancement Method for a Preprocessing Framework Based on Generative Adversarial Network. Sensors 2023, 23, 5774. https://doi.org/10.3390/s23135774
Jiang X, Yu H, Zhang Y, Pan M, Li Z, Liu J, Lv S. An Underwater Image Enhancement Method for a Preprocessing Framework Based on Generative Adversarial Network. Sensors. 2023; 23(13):5774. https://doi.org/10.3390/s23135774
Chicago/Turabian StyleJiang, Xiao, Haibin Yu, Yaxin Zhang, Mian Pan, Zhu Li, Jingbiao Liu, and Shuaishuai Lv. 2023. "An Underwater Image Enhancement Method for a Preprocessing Framework Based on Generative Adversarial Network" Sensors 23, no. 13: 5774. https://doi.org/10.3390/s23135774