1. Introduction
Defect inspection is important in the manufacturing industry and is required to ensure consistent product quality and improve the costs and efficiency of the entire manufacturing process. Human visual inspection, however, is time-consuming, labor-intensive, and prone to human errors. In contrast, machine vision inspection using cameras, optics, and inspection software enables fast and robust low-cost inspection. Therefore, it has been increasingly adopted in various manufacturing industries [
1,
2,
3,
4,
5]. For decades, numerous studies on machine vision inspection have been conducted [
6,
7,
8,
9,
10], but traditional inspection techniques still face challenges in dealing with variations in environmental conditions and part appearance.
Recently, inspection algorithms integrating artificial intelligence (AI) techniques have shown promise and improved the accuracy and robustness of defect inspection. These algorithms have been employed in various manufacturing industries, including textile [
11], fabric [
8,
9,
10], and steel surface [
4,
12]. Defect inspection using deep learning algorithms achieved enhanced accuracy and robustness by learning features from the large training dataset. A number of prominent architectures and pre-trained models, such as AlexNet [
13], VGGNet [
14], ResNet [
15], and MobileNet [
16], have emerged, and these are accompanied by various techniques to enhance inspection performance. Wei et al. achieved an inspection accuracy of 98.5% using convolutional neural network (CNN)-based algorithms with image preprocessing, such as noise reduction and binarization, to detect defective products in the textile industry [
17]. Yang et al. used the you only look once (YOLO) v5 object detection algorithm to detect and identify welding defects on steel pipes. The proposed model achieved an accuracy of 97.8%, demonstrating its potential for real-time welding defect detection [
18]. Kim et al. presented a skip-connected convolutional autoencoder for advanced printed circuit board (PCB) inspection. The proposed unsupervised autoencoder model delivered promising performance, with a detection rate of up to 98% in 3900 defect and non-defect images [
19]. Tang et al. proposed a skip autoencoder to improve the accuracy of anomaly detection and address labeling issues. Leveraging a pre-trained feature extractor and skip connections, the proposed method achieved better performance, showing a maximum area under the curve (AUC) of 0.98 [
20]. Upadhyay et al. developed a U-Net-based deep learning framework to detect engine defects. They applied a hybrid motion deblurring method for image sharpening and denoising, combined with a customized generative adversarial network (GAN) model, to remove the blur effect based on classic computer vision techniques. The deep learning framework achieved precisions and recalls of over 90% [
21]. Yoon Jong-Pil et al. presented a defect classification approach based on a convolutional variational autoencoder (CVAE) and deep CNN for metal surface defect inspection. The proposed conditional CVAE achieved a maximum completion of 0.9969 [
22].
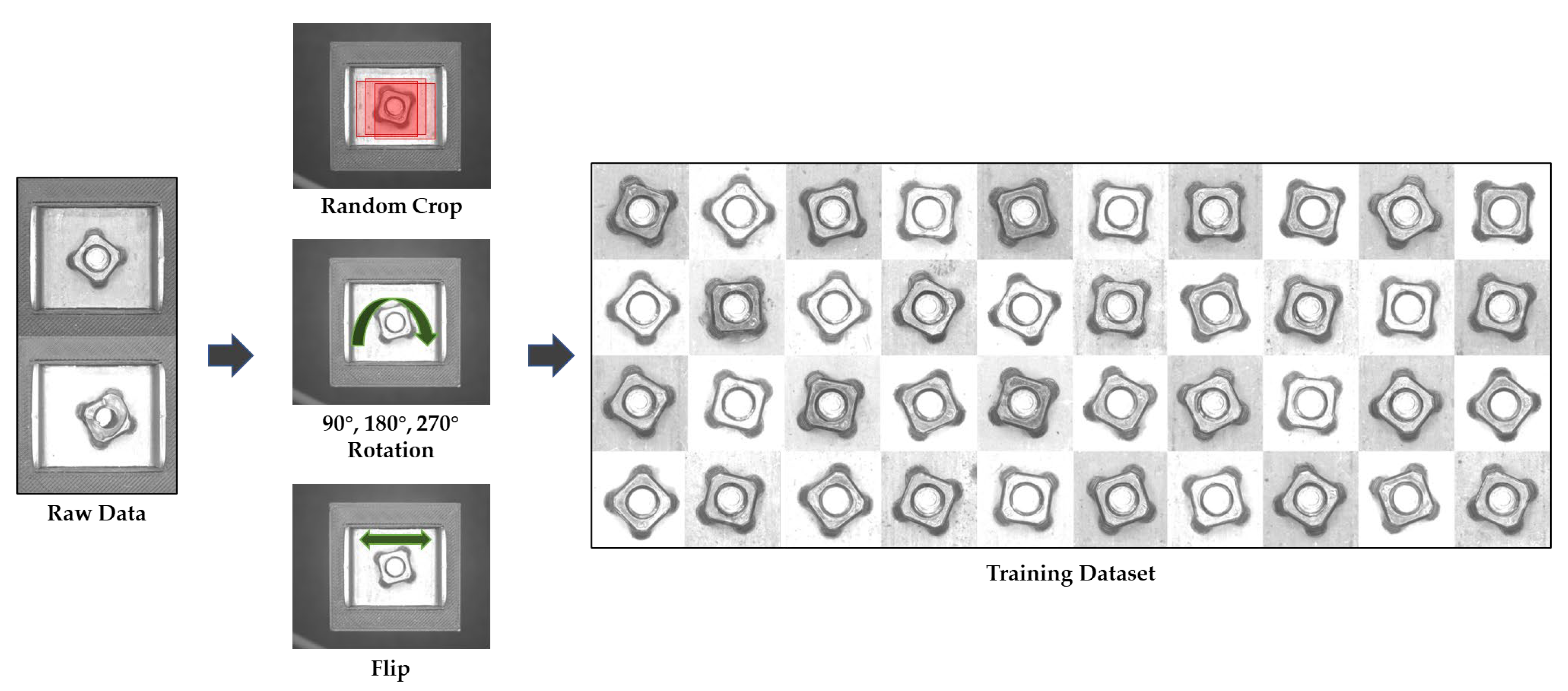
Although AI-based inspection provides superior performance compared to traditional methods, several limitations remain in applying this approach to practical situations. One major challenge is the performance degradation caused by data imbalance. AI-based inspection requires a large training dataset. However, practically, the collected data often suffer from class imbalance, where certain classes have considerably fewer samples than others. In defect inspection, collecting sufficient defective samples is difficult because the defect rate is quite low (usually under 1–5%) in general manufacturing processes. To address this issue, various methods have been proposed, including data augmentation [
23,
24,
25], synthetization [
19,
26], and an adjustment of the weight or loss function of the network [
27]. Wang et al. proposed a novel loss function called ‘mean false error’ together with its improved version called ‘mean squared false error’ for deep network training using imbalanced datasets [
28]. Mao et al. improved data imbalance by extending the training dataset using a GAN model and achieved up to 86.8% accuracy [
29].
One-class classification (OCC), which identifies objects belonging to a specific class given only positive samples of that class, is attracting attention as a solution to this problem [
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40]. Unlike general machine-learning-based classification algorithms, the OCC model aims to learn a classification boundary that separates the target class from other classes in the input space. OCC can thus be utilized effectively to solve data imbalance problems, as it does not require negative samples and can be trained only using positive samples. Shin et al. proposed a one-class support vector machine (SVM) model to detect mechanical defects in electronic devices, achieving up to 93.9% accuracy compared to the multilayer perceptron method [
31]. Ruff et al. proposed a deep support vector data description that extracts the similarity between patterns of general categories and new data. The proposed method achieved up to 99.7% average AUCs on MNIST and CIFAR-10 [
34]. Lee et al. proposed a one-class deep-learning-based fault-detection module for imbalanced industrial time-series data. Using four different networks, i.e., MLP, ResNet, LSTM, and ResNet-LSTM, for prediction, they achieved an excellent fault prediction accuracy of 96% [
36]. Goyal et al. developed a deep robust one-class classification (DROCC) to help address the representation collapse problem. The DROCC achieved an average accuracy of 74.2% using the CIFAR-10 dataset [
37].
The representation collapse problem is a major issue in OCC, and it can arise when the diversity of the training data is insufficient, or the data follow a repetitive pattern. In such cases, the decision boundary is fitted too tightly to the training dataset, leading to a decrease in the generalization performance for new data. In practical applications, the environmental conditions for collecting training and test samples may not be the same, which can lead to false positive errors, resulting in overall performance degradation.
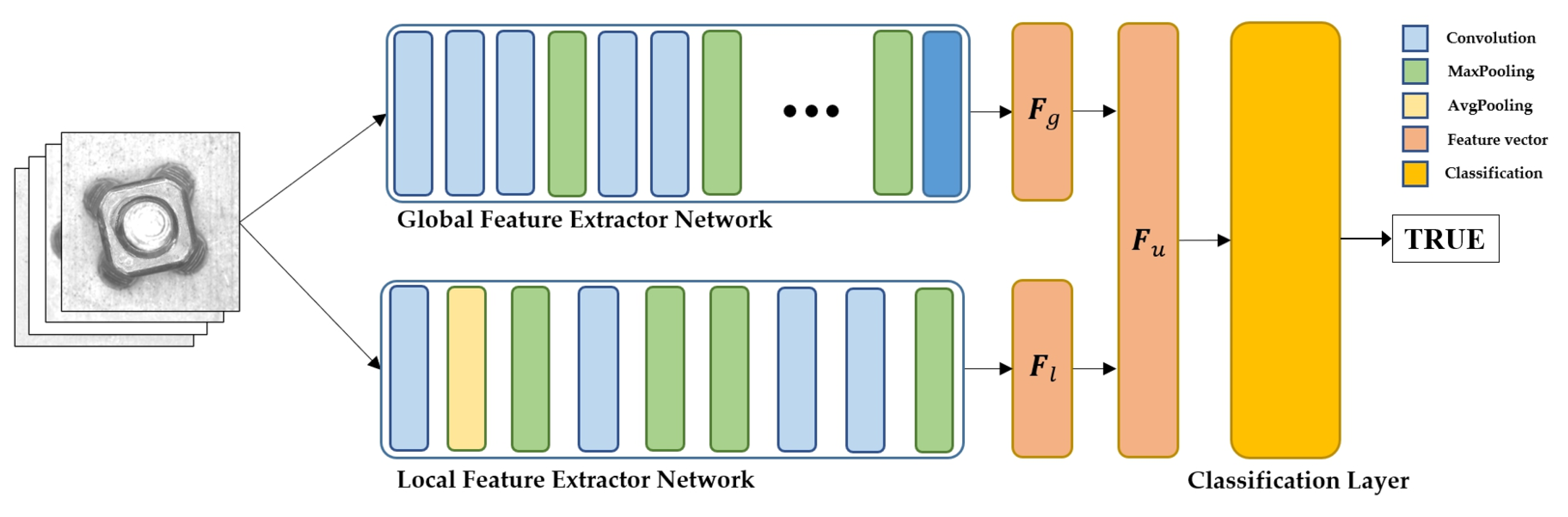
In this paper, we propose a two-stream network OCC model for defect detection that attempts to address the representation collapse problem, which has been a critical issue when applying the OCC model to practical applications. The proposed two-stream network model alleviates the representation collapse problem by introducing two feature extractor networks, i.e., global and local feature extractor networks. The global feature extractor network, which is designed to learn a general feature of the target class, can extract a feature vector that is not affected by variations in environmental conditions. The local feature extractor network is designed to capture features specific to the training dataset, and it extracts the target class-oriented feature vectors. Two feature vectors output from each network are merged and passed through the following classification layer for the final decision. Three types of classification layers, i.e., a one-dimensional (1D) convolution layer, a fully connected layer, and an SVM layer, were tested for the target class classification to determine the optimal classification layer. The proposed two-stream OCC model was verified by using an image dataset obtained from the practical application of automotive airbag bracket inspection. The main contributions of this paper are as follows:
A two-stream network architecture composed of global and local feature extractor networks is proposed to resolve the representation collapse problem of the OCC model.
The classification performances of three types of classification layers, i.e., 1D convolution, fully connected, and SVM layers, are described to elucidate the type that yields the optimal classification performance.
The performance of the proposed OCC model is verified using the practical application of automotive airbag bracket inspection.
4. Discussion
In the manufacturing sector, defect inspection using AI technology has been extensively studied to optimize labor costs and process automation. However, due to the difficulty of collecting data in the field and data imbalances, OCC has recently attracted attention for various applications. OCC is efficient in applications where data are unbalanced, but it has a critical limitation in that the features are compressed in the training data, resulting in false-positive errors. To overcome this limitation, we developed a two-stream network OCC model consisting of local and global feature extractor networks followed by a classification layer. The performance of the proposed model was validated using a practical example of automotive-airbag bracket-welding defect inspection. The image datasets of the airbag bracket collected in two different environments, i.e., a laboratory and a production site, were used for the training and validation of the proposed model. For the dataset collected in the laboratory, our model achieved results of 0.8966, 0.9236, 0.9500, and 0.9366 for the accuracy, precision, recall, and F1 score, respectively. For the production site dataset, the model achieved results of 0.9706, 1.0000, 0.9672, and 0.9833 for the accuracy, precision, recall, and F1 score, respectively.
The inspection performance of the entire model could be affected by not only the performance of the feature extraction layer but also that of the classification layer. Three types of classification layers, 1D convolution, fully connected, and SVM layers, were tested to investigate the effect of the classification layer and to identify the optimal classification presenting the best inspection performance. The 1D convolution layer showed the best accuracy, precision, and F1 score for both laboratory and production site datasets. The fully connected layer yielded slightly better performances than the 1D convolution layer only in terms of recall. In the performance comparison between the laboratory and production site datasets, the SVM layer exhibited a decrease in the accuracy, precision, recall, and F1 score by 9.44%, 0.24%, 8.87%, and 4.58%, respectively, for the production site dataset compared with the laboratory dataset. By contrast, the 1D convolution layer showed an increase of 8.37% in accuracy, 8.54% in precision, 1.77% in recall, and 5.01% in the F1 score for the production site dataset compared to the laboratory dataset. These results indicate that the classification by the 1D convolution layer is more appropriate for alleviating the representation’s collapse than that by other layers.
Compared with the single-stream network model, the two-stream network model showed an increase of up to 7.35% in accuracy, 9.70% in precision, and 3.80% in F1 score, proving that the two-stream model achieved a better performance than the existing single-stream model. In addition, the proposed two-stream model exhibited performance improvements in the production site dataset’s results compared with the laboratory dataset results, with an increase in accuracy of 8.25%, precision of 8.27%, recall of 1.81%, and F1 score of 4.99%, demonstrating that the proposed model maintains the inspection performance for the datasets gathered under different environmental conditions than the training datasets. This finding proves that the two-stream network architecture contributes to reducing the performance degradation caused by representation collapse.
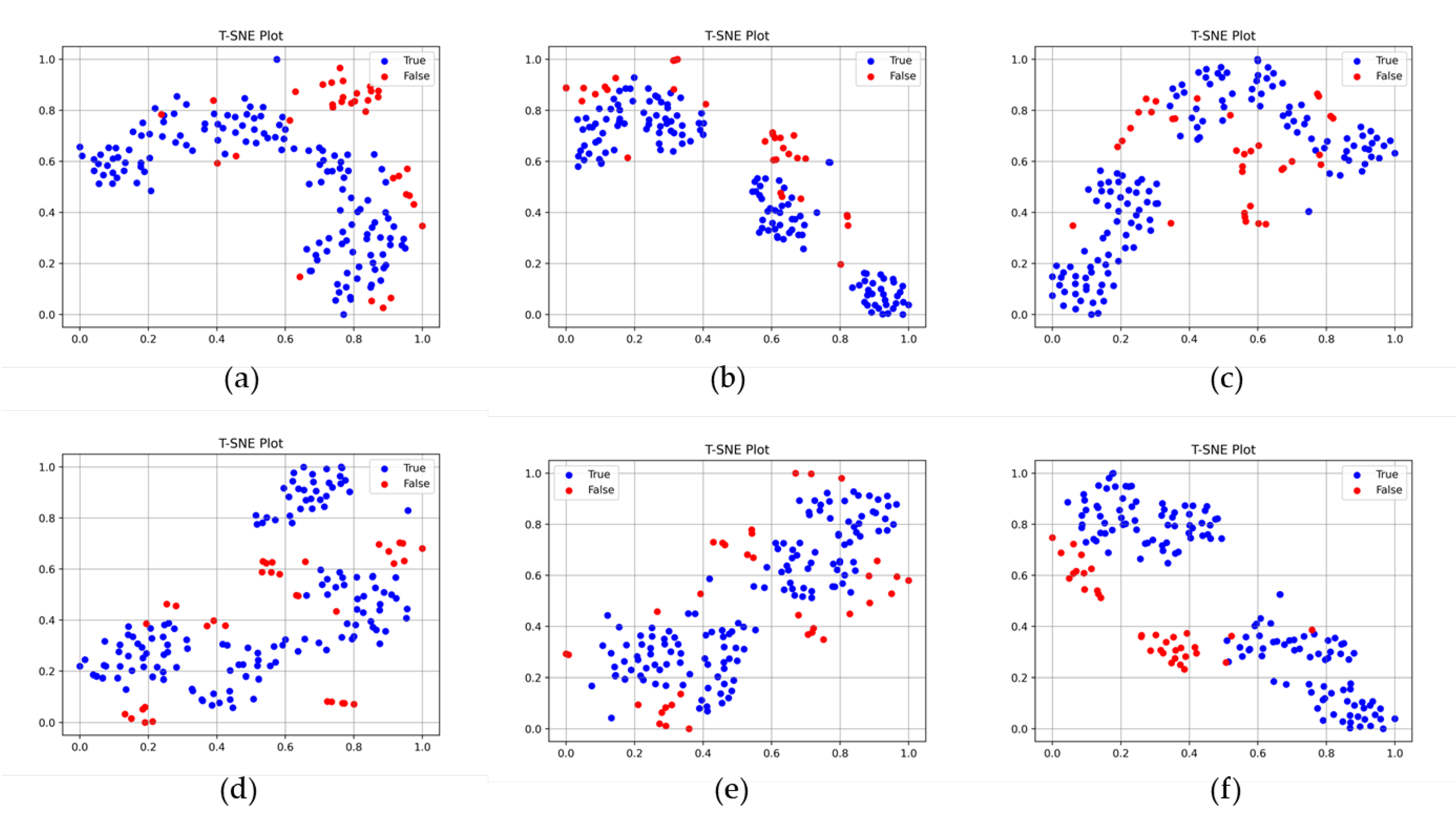
The effect of the two-stream network on performance improvement is clearly presented by the t-SNE plots shown in
Figure 9. In
Figure 9a, the feature vectors produced by the global feature extractor network provide a rough classification of the true and false samples, and there is some overlap observed among certain portions of the samples. The lack of a distinct decision boundary can be attributed to the global feature extractor network’s emphasis on capturing general features. In contrast, the feature vector generated by the local feature extractor network depicted in
Figure 9b exhibits clear differentiation between true and false samples. Nevertheless, determining a single decision boundary is challenging as false samples are divided into two separate clusters. By combining the characteristics of the global and local feature extractor networks, the feature vector generated by the two-stream network depicted in
Figure 9c effectively discriminates between true and false samples using a single decision boundary.
The comparison between the proposed two-stream network model and the previous model confirmed its enhanced classification performance. In the performance comparison with the previous model, the proposed two-stream model showed the best performance for most performance indices, including the accuracy, precision, and F1 score for production site datasets. The improvements in accuracy, precision, and F1 score were up to 65.01%, 10.74%, and 40.05%, respectively. The PaDiM method demonstrated proficient classification performance within the laboratory dataset. However, its performance significantly deteriorated when applied to the production site’s dataset, which has distinct environmental conditions compared to the training dataset. To understand the rationale behind the performance improvement in the proposed two-stream network model, we examined the t-SNE plots presented in
Figure 10. The feature vectors of the previous model did not exhibit clear classification boundaries for true and false samples. In contrast, the feature vectors generated by the proposed model provided the most distinct differentiation between true and false samples. The significance of this enhancement in classification features lies in its ability to alleviate the inherent bias toward true samples, which frequently possess larger datasets in comparison to false samples. The biased predictions of previous models toward true samples had a detrimental impact on precision performance, resulting in its degradation.
The two-stream network OCC model proposed in this study exhibited high classification performance with respect to both the laboratory and production site datasets. However, the validation was not sufficient for verifying the classification performance of negative samples because not enough defective samples were collected at the production site. In future studies, sufficient negative samples must be collected, and the performance of the proposed model should be further validated with those samples.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}