1. Introduction
Landmines have caused great harm to human life and health and greatly hindered the harmonious development of human society [
1]. According to incomplete statistics, more than 110 million landmines are still present in post-war areas. To date, many methods have been developed to detect and remove landmines during war or post-war reconstruction. They can be divided into two categories based on their fundamental principles [
2]. One employs the geophysical differences between certain parts of landmines and their surroundings, including ground-penetrating radar, low-frequency electromagnetic induction, metal detectors, ultrasonic devices, infrared imaging, and other combinations of detection techniques. The other has a wide range of research dimensions based on particular techniques, such as acoustics, biological sensing, and molecular tracking.
With the development of military technologies, scatterable landmines have emerged and are attracted increasing attention, as opposed to landmines covered with vegetation. The scatterable landmines naturally possess the advantages of speed, flexibility, and high mobility. Consequently, large-scale and large-area minefields can be deployed quickly during war. Moreover, aerial minelaying or projection from armored vehicles results in the randomized distribution of landmines in diverse topographies and complex vegetation environments. These pose new challenges for minefield clearance and make the long-distance and rapid detection of scatterable landmines increasingly necessary.
Meanwhile, massive advances in unmanned aerial vehicles (UAVs) have presented enormous potential [
3]. Specifically, UAVs with various on-board electromagnetic sensors have yielded a considerable number of applications, including a rise in low-altitude landmine detection, as they can provide better safety performance and faster measurements than other mine detection platforms. Many investigations aiming at the combination of drones and predominantly ground-penetrating radar (GPR) have been conducted [
4,
5,
6,
7,
8,
9]. The authors in [
4,
6] aimed to achieve a precise and steady flight over the surface, to increase the positioning accuracy and reliability of GPR measurements, while on-board software-defined radio (SDR)-based radars were developed in [
6,
10] to detect landmines. Other customized sensors mounted on drones have also emerged. Among them, synthetic aperture radar (SAR) [
9,
11] and hyper-spectral [
12] imaging techniques have shown unprecedented potential with advanced image processing and computer vision algorithms. In [
11], the authors reported the capability of high-resolution 3D SAR images for the detection of buried hazards, while the hyper-spectral imaging of landmines was highlighted with different signal processing techniques in [
12,
13].
Numerous factors, such as the materials and shapes of the mines, terrain complexity, vegetation humidity, flight altitude, etc., limit the detection of scatterable mines. It is challenging for a single sensor to solve all of the aforementioned issues. It is well known that objects exhibit different features in different spectra, and multispectral remote sensing that obtains and comprehensively exploits different spectra information of the same target by means of photography or scanning is appealing. For instance, a particular spectrum may offer a unique advantage in certain terrains or settings, whereas the proper fusion of multispectral remote sensing might expand the observation range and reveal more information. Multispectral fusion greatly outperforms a single spectrum in pedestrian recognition, especially in challenging situations such as occluded appearances and background clutter [
14]. However, the development of multispectral techniques in the detection of scattered landmines is still in a preliminary exploration stage. Research in this area mainly concentrates on the analysis of different spectral signatures and the simulation of ground environmental influences [
15,
16,
17,
18,
19]. Differences in spectral signatures between soils and landmines are essential for detection, and a study has been performed regarding this [
15]. The utilization of remote sensing thermal infrared technology has led to satisfactory results in PFM-1 minefield detection [
16], and plastic mines such as PFM-1 have higher thermal conductivity when the heat flux is high in the early morning [
18]. In addition, ref. [
17] simulated the influence of environmental forces on the orientation of PFM-1, complicating the minefield environment.
In the past few years, deep learning, based on the cognitive structure of the human brain, has achieved great success in many areas. Compared with the traditional machine learning algorithm (shallow learning), it can extract more abstract features through multi-layer nonlinear transformation. As one of the fundamental visual tasks, object detection based on deep learning has outperformed traditional methods over the last few years. Ideas and implementations based on convolutional neural networks (CNNs) have facilitated the success of deep learning in detection [
20]. Widely acclaimed deep learning models, such as ResNet [
21], regions with CNN features [
22] (R-CNN), Faster R-CNN [
23], etc., show outstanding transferability in mine detection scenes [
19,
24,
25,
26]. Some customized deep learning models also show powerful feature extraction abilities and adaptability in varied scenes [
27,
28]. It is worth noting that different types of data were used in the above studies, such as thermal infrared images, GPR B-scans, and radar signals, but deep learning methods still achieve excellent performance.
The Binghamton University team [
16,
17,
18,
19] is conducting ongoing research into multispectral landmine detection. Comparative experiments indicate that thermal cameras can detect temperature variations between plastic PFM-1 landmines and host geology during the early-morning hours, when the thermal flux is high [
18]. Their preliminary studies in [
16,
17] demonstrate that a thermal camera mounted on a low-cost UAV can successfully detect PFM-1 mines at the elevation of 10 meters above the ground, regardless of their orientations. In 2020, they incorporated an analysis of multispectral and thermal datasets and discovered that different bands are beneficial in different situations [
19]. Furthermore, they employed the Faster R-CNN [
23] model and yielded satisfactory accuracy for a partially or wholly withheld testing set. The employed data only consist of RGB visible images, without fusing other bands for detection, but their solid work gives confidence and inspiration for multispectral detection. In our past work [
29], we combined the detection results of RGB and NIR images and finally achieved excellent performance, demonstrating the advantages of multispectral over monospectral images in detection. In this paper, to further investigate the application of multispectral imaging, we explore in depth a new approach as an extension of the aforementioned work.
Most of the existing research and trials only consider an extremely elementary simulation environment and landmine setting. However, high-quality data from the real environment or diversified and high-fidelity experimental scenes are the foundation for the sufficient generalization of supervised deep learning. Therefore, in this study, we were motivated to set up complex minefield conditions to simulate real scenes and collect raw high-quality multispectral data acquired via a drone with an integrated multispectral camera. One RGB sensor and four monochrome sensors collected data in discrete spectral bands—green, red, red edge, and near-infrared. More specifically, our dataset contains four types of scatterable landmines, four scenes with different ground vegetation, and various flight altitudes. To overcome the labeling issues introduced by the severe occlusion and the tiny size of the landmines and improve the labeling efficiency, we utilize the idea of active learning to ensure the complete and accurate labeling of the dataset. To improve the detection performance for the obtained high-quality multispectral images, we present a detection-driven image fusion framework with YOLOv5 [
30] plugged in. When compared to the original YOLOv5 [
30] benchmark or other fusion detection cascade models, our proposed fusion detection enhances the recall markedly. The RGB and NIR bands are used to demonstrate this in the study. There are 789 pairs of images in our dataset, which are partitioned into training and test sets in an 8:2 ratio. A total of 991 mines are labeled in the test dataset, and a recall rate of 0.848 is achieved when using RGB alone for prediction, while 0.906 is achieved with the fusion of NIR and RGB driven by the landmine detection task. As a plug-and-play module, it can be integrated into most of the current state-of-the-art object detection models.
The rest of the paper is organized as follows.
Section 2 illustrates the details of our dataset, including the instruments and the data processing.
Section 3 introduces the adopted deep learning method and proposed fusion module.
Section 4 presents the experimental results and comparative analysis. Finally, conclusions are drawn in
Section 5.
2. Multispectral Dataset
In order to address the shortage of public multispectral landmine datasets, we constructed a small landmine dataset, including labeled RGB and near-infrared (NIR) image pairs.
2.1. Landmine Samples
In the dataset, 40 mines with five different sizes and materials were selected in total, three of which were anti-personnel mines, while the others were anti-vehicle mines. Their primary materials were metal, and the shell parts contained a small amount of plastic and rubber. The specifications of the four types of mines are given in
Figure 1.
With the exception of the M93 landmine, they are all olive-drab-covered and cylindrical in shape. Specifically, the smallest anti-personnel mine M14 is less than 6 cm in diameter and primarily non-metallic. In comparison, the anti-vehicle M93 Hornet mine possesses a relatively large body size and is plastic-cased with a rubber top. Before the explosion, they are air-delivered and hidden well on the ground or in vegetation, remaining active without being noticed for long periods.
2.2. Equipment
We acquired the multispectral images using the Sequoia multispectral kit. The Sequoia sensor comprises four monochrome cameras with specific narrow-band filters and high-resolution RGB lenses in the NIR and visible domains, respectively, as shown in
Table 1.
The camera is equipped with a “sunlight sensor” that measures sky irradiance. The built-in spectroradiometer has precision of 1.5 nm to measure irradiance of 2048 pixels in the visible and NIR spectral ranges (350–1000 nm). The drone equipped with the multispectral sensor (
Figure 2) can sustain a continuous flight of an hour approximately.
The preparations before take-off include the calibration of the drones and multispectral cameras and radiation correction through the sunshine sensor. The matching sunshine sensor can monitor radiation fluctuations to obtain multispectral images with stable quality under different lighting and natural conditions. The flying height changes according to the host environment and whether sparse, tall plants are present. In this work, the flying heights are fixed at approximately 3 m and 8 m, respectively, to obtain images with a similar ground resolution. During the data acquisition process, the drone cruises at a constant speed with an area overlap rate of 80% to ensure complete coverage of the minefields of the given range. Moreover, the built-in GPS/GNSS of the multispectral camera can determine the device’s location when capturing images, which provides good feasibility to convert the image coordinate system and the geographic coordinate system.
2.3. Experimental Scenes
We conducted data collection experiments and placed dozens of mines on grassland, instead of experimental scenes such as sand land, cement roads, and gravel roads, etc. A more complex environment with vegetation is considered to validate the feasibility of our method. We selected several low-vegetation environments to simulate minefields. As displayed in
Figure 3, mines are easily obscured by wild vegetation. The mines were scattered randomly, with approximately 60% obscured by vegetation; in other words, only part of the mine body was visible. Moreover, a small number of them were entirely covered by ground vegetation, which caused extremely low visibility. In addition, there were many leaves, stones, and plant rhizomes that were similar in color and shape to the mines, which may have caused false alarms.
2.4. Acquisition and Registration
With a constant capturing interval of 2 s, UAVs may complete the minefield cruise in a very short amount of time. Sequoia’s monochrome and RGB cameras are not calibrated throughout production, resulting in a lack of rigorous time synchronization due to the various shutters. As a result, the collected multispectral raw images have a spatio-temporal shift. Thus, in addition to the typical nonlinear intensity differences, there are also spatio-temporal mismatches between the multi-modal data. For instance, the vegetation in the simulated landscape is mostly filled with dense grasses that sway in the wind in different directions. Completely accurate image registration is almost impossible. This can be a significant problem for actual minefield detection, but not for host environments without vegetation. Registration allows image pixels to be aligned for more precise fusion and also eases subsequent labeling. The registered infrared and visible image pair that we obtained is shown in
Figure 4. We also refer to the channel feature of oriented gradients [
31] (CFOG) method to register the multispectral images, which could effectively further improve the precision of the registration result. By comparing the positions of the corresponding landmines, we could directly assess the quality of the registration result.
2.5. Labeling
Supervised learning strongly relies on high-quality labeled data, which usually comes with high costs. Manually labeled data are time-consuming to obtain and sometimes unreliable. Even in the well-known public datasets in the academic community, there are still many instances of mislabeling. In this paper, we labeled our dataset using the following steps: detection equipment assembly, data collection, data cleaning, image alignment, and labeling.
Firstly, random landmine placement and extreme occlusion substantially increase the difficulty of labeling. Moreover, nonsalient objects such as landmines usually blend in easily with their surroundings. In a 1280 × 960 resolution image, the target is estimated to occupy 100 pixels, while, for the smallest mine, M14, it occupies only approximately 10 pixels. It is not feasible to label each image manually. Therefore, during the labeling precess, we referred to the strategy described in [
14]. We compared and labeled images in parallel after aligning the image pairs. Moreover, to accelerate the labeling, we introduced an active learning technique, which is shown in
Figure 5.
In real-world circumstances, it is worth considering how to collect valuable labeled data for a lower cost and subsequently increase the algorithm’s performance. Active learning focuses on reducing the burden of labeling by incorporating human experience into machine learning models. Firstly, the query function determines the candidate set of data to be labeled. Then, professionals with business experience annotate the selected datasets. With continual manual annotation to be added, the model is therefore incrementally updated. The core principle behind active learning is to manually resolve the “hard sample” via human interference. In our situation, the term “hard sample” refers to landmines that are well hidden and difficult to detect. Furthermore, the training results assist in the improvement of the annotation. After three rounds of the iterative process, a dataset with reliable annotations was created.
3. Methods
Existing image fusion algorithms tend to focus on the visual effect of the fused image itself and the pursuit of quantitative evaluation, while ignoring the promotion ability of image fusion as a low-level vision task for the subsequent high-level vision task. In fact, the ideal image fusion method should not only provide rich texture details and accord with human visual perception, but also help to conduct high-quality downstream tasks.
Compared with the traditional architectures, the fusion architecture driven by high-level vision tasks can better conserve semantic information as well as exclude external noise. Liu in [
32] designed a cascade structure to connect the image denoising module with the high-level vision network and jointly trained them to minimize the image reconstruction loss. Under the guidance of semantic information, a denoising network could further improve the visual effect and help to complete the semantic task. Similarly, Guo in [
33] designed a residual network for semantic refinement and jointly trained the “drainage” network and the segmentation network in two stages, which was successfully utilized to overcome the impact of rainwater on sensors during automatic driving. Object detection, as one of the high-level vision tasks, was also used to guide image super-resolution reconstruction. In the research of [
34], the authors built a novel end-to-end super-resolution framework, in which the updating of the super-resolution network was influenced by the detection loss. The proposed task-driven super-resolution algorithm was verified to improve the detection accuracy on the low-resolution image under various scale factors or conditions.
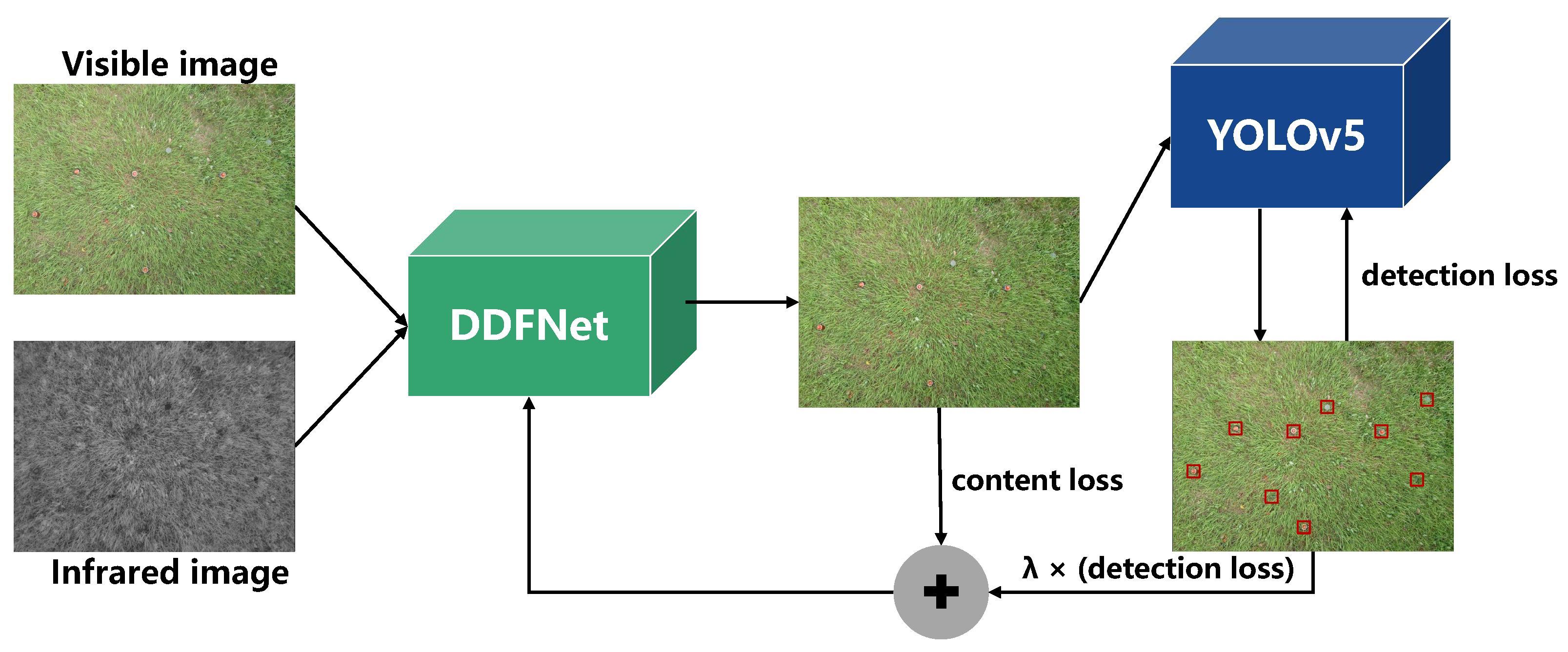
3.1. Detection-Driven Fusion Framework
By focusing on landmine detection, we introduce a joint training framework based on detection-driven fusion (DDF), as shown in
Figure 6, in which we select YOLOv5 [
30] for detection.
The image fusion network is not limited to the preservation of low-level semantic information but is driven by the detection task to gather more valuable high-level semantic information. Meanwhile, the fusion network is partially influenced by the detection result, which can preserve fine-grained details while providing more semantic information for computer perception.
3.2. Fusion Network
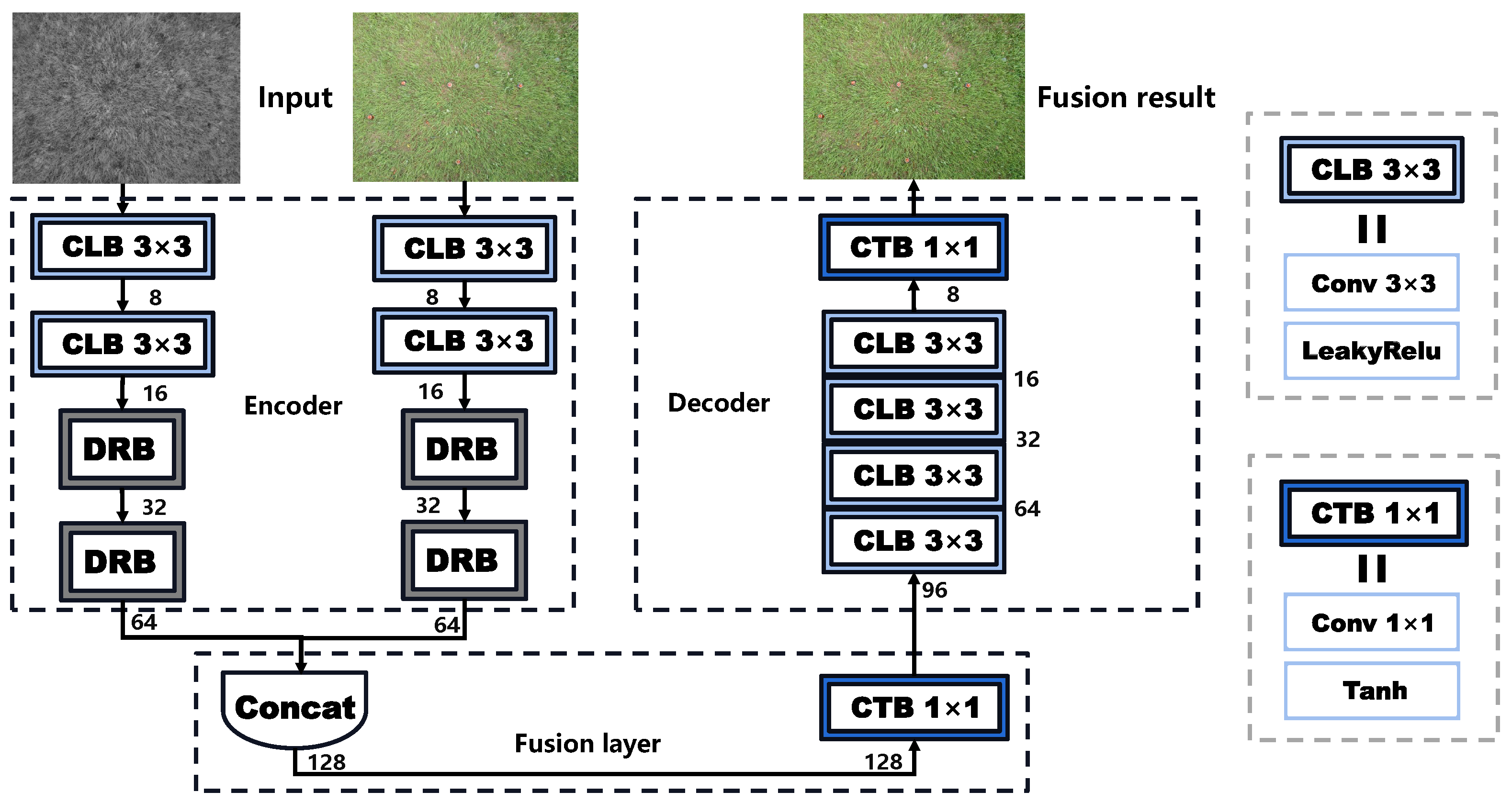
On the basis of auto-encoder, we design a lightweight fusion network (denoted as DDFNet) with two inputs and one output, in which the registered images include the visible image
and the near-infrared image
as the original inputs. The images pass through the encoder, fusion layer, and decoder, respectively, as shown in
Figure 7, where the encoder is used for feature extraction and the decoder for image reconstruction, which can be expressed as follows:
where
and
are the depth features extracted by two different encoders
, respectively.
denotes the fused features of the visible and the infrared images through concatenation, and
is the fused image reconstructed by decoder DE. In
Figure 7, the encoder part is mainly composed of two general convolutional blocks as well as two dense residual blocks (DRB), as shown in
Figure 8, which refers to the combination of the residual and dense blocks from [
35]. The main branch of DRB aggregates shallow and deep semantic information by dense connection as the shortcut branch uses the classic
convolutional layer in the residual block to achieve identity mapping. Next, the output of the main branch and the shortcut are added at the element level to integrate deep features with fine-grained features. Thus, the superposition of two DRBs in the encoder ensures that the abundant semantic features are fully utilized. Then, the fusion layer fuses the rich features extracted from the infrared image and the visible image via concatenation. Finally, the fused features are fed back into the decoder for image reconstruction. With the dimensions of the feature map shrinking, the decoder outputs a three-channel fused image. In general, the design of our fusion network is simple and lightweight, which contributes to a higher fusion speed, and it is easy to facilitate subsequent deployments. Moreover, the introduction of the auto-encoder architecture as well as the DRB makes it possible for the fused image to fully restore the details and semantic information of the source images.
3.3. Loss Function
The design of the loss function starts with two aspects. Firstly, the fusion network needs to fully integrate the complementary information of the source images, such as the salient objects in the infrared image and the texture details in the visible image. For this reason, the content loss
is constructed, which aims to ensure the visual fidelity of the fused image. Secondly, the fused image should effectively promote the detection effect. Therefore, the semantic loss
is introduced to indicate the contribution of the fused image to the detection task. In summary, the joint loss function is designed as follows:
where the joint loss
of the fusion network comprises the content loss
and the semantic loss
, and
is set as the weight of the semantic loss.
Meanwhile, the content loss is composed of three types of loss, image intensity loss (
), texture loss(
) [
35], and structural similarity loss (
), formatted as
where
and
are the hyperparameters to define the weights of texture loss and structural similarity loss, respectively. Image intensity loss
assesses the difference in pixel intensity between a fused image and a source image, which can be more precisely formulated as
where
H and
W are, respectively, the height and width of the fused image
.
stands for the
-norm.
ensures that the fused image maintains the intensity sufficiently, which contributes to the positioning of landmines. The texture loss
is introduced to preserve the details. It can be calculated as
where the absolute value operation is denoted by
and the Sobel gradient operator is denoted by ∇. Although the standard
distance can maintain edges well in image fusion, it cannot effectively remove noise. Moreover, it lacks the capability to determine how structurally similar the images are, and it is highly sensitive to changes in lighting, color, etc., which poses a challenge in maintaining specificity in multispectral images. The Structure Similarity Index Measure (SSIM) proposed by [
36] is used to compare the structural similarity of an image before and after alteration. SSIM is sensitive to local structural changes, as with the human visual system (HVS). More importantly, SSIM can better tolerate the influence of outside information on the source image. The SSIM between two images can be more precisely expressed as follows:
where
and
represent the mean and the covariance of images, respectively, and
,
,
are the parameters used to stabilize the measurement. Therefore, the SSIM loss
can be formulated as
where
and
denote the weights of structural loss between the fused image
and the source image
and
, respectively. Although content loss can maintain information in the fused image and minimize distortion to some extent, it is challenging to measure the promotion impact of the fusion result on high-level vision tasks. As a consequence, we redefine the semantic loss using the standard loss function based on YOLOv5 [
30] to guide the training of the fusion network and ultimately enhance the detection performance.
The object detection task normally requires us to refine the target size as well as identify and categorize the detected item. In particular, the accuracy of the test results depends on three optimization directions:
All targets in the image should be identified, with a low missed and false alarm rate;
The bounding boxes should completely and accurately enclose the target;
The categorization of the detected object should be consistent with its label.
Therefore, the semantic loss (marked
[
30]) is defined by the confidence loss (marked
), the bounding box loss (marked
), and the categorized loss (marked
) as follows:
where
a,
b, and
c are their weights, respectively. The confidence loss generally weighs the most, followed by the bounding box loss and the categorized loss.
3.4. Joint Training Algorithm
There are primarily two approaches to low-level vision model training that is motivated by high-level visual tasks. The first one is to train the low-level vision model under the guidance of the pre-trained high-level vision model, but the training result cannot be effectively fed back to the high-level vision model. The second one is to concurrently train the low-level and high-level vision models in one stage, and this strategy may bring difficulties in maintaining a balance between the performance of vision models at various levels. Therefore, we introduce a joint training method based on an iterative strategy to train our fusion network.
More specifically, we train the fusion and detection networks repeatedly, with the number of iterations set to
n. Firstly, the fusion and the detection network employ the Adaptive Moment Estimation (ADAM) optimizer to maximize each of their individual parameters under the supervision of the joint loss
and the detection loss
, respectively. Secondly, the parameters of the detection model are fixed to generate real-time semantic loss when the fusion network is updated. It should be noted that the hyperparameter
set for the joint loss is dynamically adjusted in an iterative process, which is expressed as follows:
This option is primarily intended to guarantee that, as the fusion network has been trained to a certain extent, the fraction of semantic loss steadily increases, and the visual effect becomes a secondary priority.
During the training process, we adopt the periodic joint training strategy demonstrated in Algorithm 1, which is iterated for 5 rounds.
| Algorithm 1: Multi-stage joint training algorithm. |
![Sensors 23 05693 i001]() |
In the first round, the fusion network only utilizes the content loss for backward propagation, while the semantic loss is set to 0. Then, in the next four rounds, both the content and semantic loss contribute to the updating of the fusion network. In addition, the detection network is trained through the updated fused image in each round.
5. Conclusions
In recent years, the application of deep-learning-based techniques in landmine detection has progressed at a rapid pace. This paper investigates recent advances and suggests some opportunities for future research in this field. Specifically, we propose a UAV-based solution for the detection of scatterable landmines. We establish a dataset of scatterable landmines, including RGB and NIR image pairs collected by a multispectral sensor, with complex scenes covered. In addition, to fully utilize the multispectral potential in detection, we employ a training framework for image fusion, which is task-oriented and allows high-level semantic information to flow back into the fusion network upstream, so as to boost the quality of the fusion image as well as enhance the detection performance purposefully. We have carried out extensive comparative experiments to verify the effectiveness of the fusion and detection methods that we propose. Our attempt at multispectral utilization for landmine detection paves the way for future advancement.
Overall, the obscuration and burial of landmines remain the most challenging problems that we confront. We have focused on the concealment and occlusion of landmines by vegetation when constructing the dataset. However, the simulated settings are still far from the natural minefield environment. The aging, corrosion, and burial of mines in real situations are time-consuming and complex to reproduce. Furthermore, the range of host conditions, such as snow, gravel pavement, and so on, needs to be greatly enlarged. In the future, we will supplement the dataset with more hard samples (primarily obscured by weeds, fallen leaves, sand, snow, and gravel or buried under shallow soils). We expect that the proposed dataset will encourage the development of better landmine detection methods, and our efforts will be of assistance and inspiration to demining organizations.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}