1. Introduction
Recently, infrared images have been widely used in many real-time applications, such as pedestrian segmentation [
1], salient object detection [
2], object fusion tracking [
3], and invisible clothing [
4]. Compared with visible images, infrared images are also able to obtain temperature information of scenes and human bodies. Furthermore, they provide good visual effects in dark environments. Consequently, infrared images can provide new ideas for visible scenes in many different research fields.
Therefore, many researchers have proposed several image-processing algorithms based on infrared images. Most of these algorithms were based on fusing infrared images with visible images. The infrared images usually have the disadvantages of low texture details and more noise, which are the advantages of visible images. Thus, the idea of fusing both visible and infrared images is required to reconstruct a synthesized image containing prominent targets and abundant texture details. Many researchers have used multi-scale transforms to extract and match the features for both images. For example, Chen et al. [
5] applied Laplace’s pyramid for infrared and visible images to obtain high- and low-frequency information, respectively. They applied regularization parameters and hence adjusted the scale of the features to achieve the flexible fusion of the two images. Yang et al. [
6] used a sparse representation based on multi-scale decomposition to fuse out a base layer. This layer improved the accuracy of image integration. Unlike the multi-scale transform that was applied in [
5,
6], Li et al. [
7] decomposed infrared images with visible images based on Latent Low-Rank Representation (LatLRR). The above-mentioned algorithms used traditional methods for infrared- and visible-images fusion. After Luo et al. [
8] obtained infrared images using a Fourier Transform Infrared Spectrometer, they analyzed the changes in image details to grasp the evolution of specific microstructures.
Image-feature extraction has a very important position in all of the above algorithms. Thus, Wang et al. [
9] improved the accuracy of feature extraction based on the ensemble-learning algorithm. Convolution Neural Networks (CNNs) are able to extract features of images very intelligently. Compared with traditional algorithms, CNN has better results in image-feature extraction. For example, Ao et al. [
10] used CNN to extract images of patient-specific organs for local treatment. Fu et al. [
11] proposed the depth-estimation algorithm for extracting simple and complex textures based on CNN. Wang et al. [
12] investigated a multispecies transferable algorithm to improve the prediction accuracy of the CNN model. Zhang et al. [
13] proposed a new classifier applied to an electroencephalogram for the overfitting phenomenon of CNN-model features. Deng et al. [
14] applied CNNs to the field of natural-language processing to solve the challenge of non-action question and answer. Liu et al. [
15] found that the global perception capability of CNNs needs to be improved. Therefore, they combined a Fast Fourier Transform with CNN to improve the performance of the model. Moreover, CNN has derived more novel models in various research areas in the last decade.
Furthermore, with the rapid development of machine learning and CNN, many neural-network-based algorithms have been applied for fusing infrared images and visible images. The Generative Adversarial Network (GAN) is widely used for infrared- and visible-image fusion [
16,
17,
18]. Ma et al. [
16] proposed the FusionGAN model, which is capable of fusing images with different resolutions. The FusionGAN generator first classified the features of infrared images and then fused them with visible images. The discriminator ensured that the fused images had more details of visible images. Additionally, a dual discriminator was added to the GAN for multi-resolution image fusion and was successfully applied for multi-modal medical images [
17]. Ma et al. [
18] presented the Generative Adversarial Network with Multiclassification Constraints (GANMcC)-based fusion model to estimate the distribution functions for both infrared and visible images. They introduced a specific content-loss function to constrain the generator. In addition to the classical GAN models, new customized models for infrared-image fusion have been presented [
19,
20]. Zhang et al. [
19] proposed a low-time-complexity image-fusion CNN based on the Proportional Maintenance of Gradient and Intensity (PMGI) model. Their proposed model is capable of being used for different image-fusion tasks such as fusing visible and infrared images, fusing medical images, fusing multi-exposure images, and fusing multi-focus images [
19]. Most of the existing deep-learning-based algorithms use convolution operation to extract local features but have not combined the network’s multi-scale characteristics and global dependencies, which may result in a disadvantage of target regions and texture details for fusing two types of images. Consequently, Wang et al. [
20] combined the multi-scale transform with a self-encoder and applied an attention mechanism to fuse infrared images more accurately with visible images. They employed dense skip connections in both watermark embedding and watermark extraction to reuse the intermediate features of several layers and scales for fusing images [
20].
The copyright protection of infrared images has captured many researchers’ attention recently. Image steganography is one of the commonly used algorithms to protect the copyright of images. In the literature, many image-steganography algorithms have been proposed to hide information based on pixel-prediction error. Li et al. [
21] presented a reversible data-hiding algorithm that combined both Pixel-Value Ordering (PVO) and Prediction-Error Expansion (PEE). The PVO algorithm performs pixel prediction based on ordering pixels according to their values in an image block. However, their method failed to provide sufficient embedding positions by applying only one bin as the inner region. Ou et al. [
22] extended the PVO method [
21] and proposed PVO-k, where the maximum-value and minimum-value pixels in a block are taken as a unit to hide the watermark and were modified together to keep the PVO invariant. These PVO-based methods [
21,
22] performed splendidly, especially for low embedding capacity. However, a smaller block size should be applied to obtain a high embedding capacity, which causes more degradations in the quality of the watermarked image. Therefore, Wang et al. [
23] improved the performance of the PVO-based methods and proposed a reversible data-hiding method based on dividing the cover image into a dynamic size of image blocks instead of applying same-sized blocks. Weng et al. [
24] discovered that most of the improved PVO-based algorithms are applied to predict the pixels that occupy only a small fraction of the image block. Thus, they proposed a Dynamic Improved PVO (DIPVO) algorithm based on graded local complexity to dynamically hide information. Zhang et al. [
25] proposed the Location-based PVO (LPVO) algorithm to solve the problem of irregular prediction-error distribution of PVO-based algorithms. The LPVO algorithm simultaneously considers the sequential location of pixel values, which makes more pixels available for image steganography.
In this paper, the infrared image is firstly divided into two sets: Dot sets and Cross sets. Secondly, we use the method of Super-Resolution based on deep CNN (SRCNN) [
26] to pre-process half of the original image. This step refers to the image-super-resolution algorithm based on signal preprocessing proposed by Huang et al. [
27]. Then, we apply Smooth Wavelet Transform (SWT) to extract high- and low-frequency sub-bands of the image. Thirdly, the CNN-based Predictor (CNNP) [
28] is employed with a few attention-network layers to improve the accuracy of the pixel prediction. Finally, to make the process of the algorithm reversible, we proposed to train models that can recover the image and extract information simultaneously. The main contributions of this paper are as follows:
Pixels in the same position have better prediction accuracy. Therefore, we employ SRCNN for pre-processing the Cross set of the infrared image to predict the Dot set of the original image, which reduces pixel-prediction errors.
We apply SWT for extracting image-frequency-domain features to improve the prediction performance of the spatial CNN models. Furthermore, we employ the improved CNNP model on the image and frequency-domain features. The features in the spatial and frequency domains improve the accuracy of the training stage.
An attention mechanism is added to the CNNP model. This allows the extracted features to be ranked according to their importance. The attention mechanism will also speed up the model training and improve the performance of the testing stage of the model.
The rest of this paper is organized as follows:
Section 2 summarizes the related works, including the basic idea behind the SRCNN model and the CNNP model.
Section 3 presents the proposed method in detail. The experimental results and performance analysis of the proposed algorithm compared with other algorithms are shown in
Section 4. Finally, the conclusion and some future directions can be found in
Section 5.
2. Related Works
Recently, CNN-based image-steganography algorithms have become a popular research direction. Luo et al. [
29] used DenseNet to extract high-level semantic features of each block instead of low-level features and then hide information by using DCT. Sharma et al. [
30] combined steganography with cryptography, and they used CNN for image steganography and image recovery. Similarly, Hu et al. [
28] proposed a CNN-based Predictor (CNNP). They applied the same structure of the CNN model for image steganography and image recovery, but the training set was different. Hu et al. [
31] improved the structure of the model and introduced the concept of chunking to improve the accuracy of pixel prediction. The CNN-based models presented by Hu et al. [
28] and Hu et al. [
31] were very small and the training process could be run on the CPU. Furthermore, Panchikkil et al. [
32] applied Arnold-transform-based data hiding to improve the performance of image recovery, where each block underwent some complex scrambling processes based on the watermark information required for embedding in the selected block. Their method has two segments: a watermark-embedding segment that hides confidential information in the cover image, and a watermark-extraction segment that recovers the original cover image and extracts the watermark information [
32].
Overall, CNN-based algorithms have excellent performance in image steganography in the spatial domain, but the combination with the traditional frequency-domain transforms should not be neglected. The algorithms based on the spatial domain directly process the pixels in the image, and the frequency domain is a variety of high- or low-frequency sub-bands that are created by an image-transform algorithm. With this in mind this, Liu et al. [
33] combined U-Net with Haar Wavelet Transform (HWT). HWT was applied to extract high- and low-frequency features of the image. Then, the U-Net was used to hide information in the original image. In this paper, the model of Super-Resolution based on deep CNN (SRCNN) [
26] was applied to pre-process the infrared image and combine it with its corresponding SWT sub-bands. Furthermore, we applied the CNNP model [
28] on the image and frequency-domain features. The features in the spatial and frequency domains improved the accuracy of the training step and hence improved the prediction accuracy of the proposed algorithm.
2.1. SRCNN Model
Dong et al. [
26] presented the first machine-learning framework of SRCNN for single-image Super Resolution (SR). In the pre-processing process, they applied bilateral interpolation for upsampling the original image
to the desired size. Bilinear interpolation enables fast and relatively accurate upsampling of images. The image at this Dot set is defined as the interpolated image
. The general structure of the SRCNN model is shown in
Figure 1.
SRCNN aims to recover an interpolated image
from an image
that is mostly similar to a high-definition (HD) image
. The algorithm should ensure that the output result of
: HD image
as close as possible to the interpolated image
. The SRCNN algorithm can be divided into three main steps: patch extraction, nonlinear mapping, and image reconstruction. Intensive patch extraction is a very popular strategy for image recovery. Moreover, feature extraction and representation of the patches in a reasonable way plays a key role in the image-SR algorithm. Thus, the first layer of the SRCNN model is represented in Equation (1) as follows:
where
is a filter for extracting features,
is a parameter for adjusting the bias, and
represents the convolution operation. First,
extracts the features from the interpolated image
. Then, the ReLU activation function is applied to correct the extracted features. Hence, plenty of features can be obtained in the patch-extraction step, whereas in the nonlinear-mapping step, more features are further extracted and then classified. The calculation process is shown in Equation (2) as follows:
where
is a filter for extracting features, and
is a parameter for adjusting the bias. Theoretically, more convolutional layers can be added in this step to improve the performance of the model, but the complexity of the model and the training cost will also be increased. In transform-based algorithms of the frequency domain, the predicted overlapping blocks of SR pixels are usually averaged to generate a good image recovery. In order to improve the image-prediction accuracy of the model, we need to increase the number of convolutional layers to improve the perceptual field of the convolutional kernel. This reduces the error of the model-output results and is also more beneficial for the subsequent information-hiding step. Inspired by traditional algorithms, the SRCNN model incorporates a dialogue layer. Equation (3) shows how this dialogue layer is computed.
Let the parameters to be learned by the SRCNN model be:
. Then, for the set of HD images
and the corresponding interpolated images
, the loss function is defined as the Mean-Square-Error (MSE) function as follows:
The MSE loss function tends to result in high-quality images for the algorithm. The SRCNN model is obtained when the value of the loss function meets the requirements of the model training.
2.2. CNNP Model
The CNNP model [
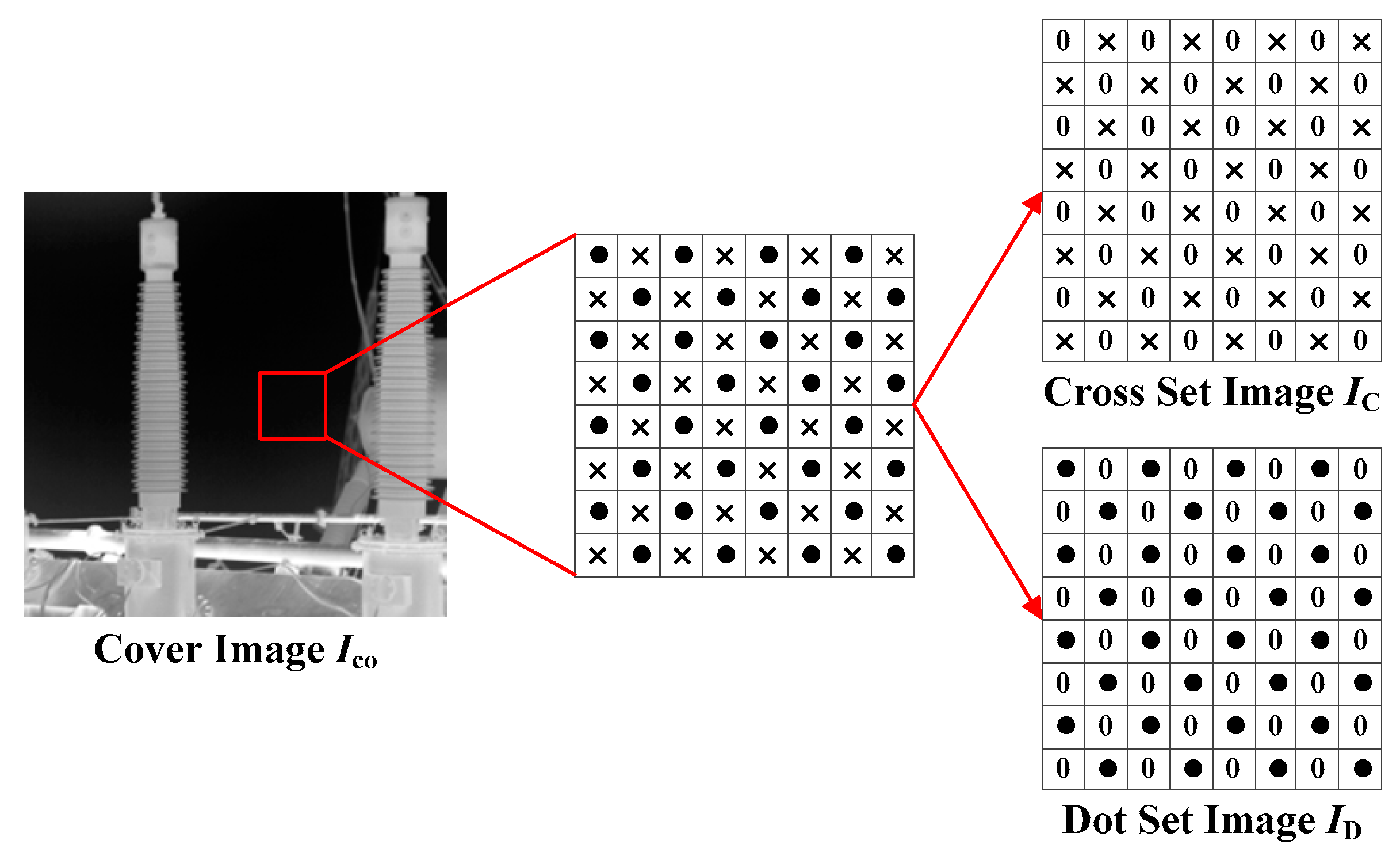
28] is a CNN-based framework for image steganography. The structure of the model is very simple and does not require the GPU server during the model-training phase. Furthermore, it makes full use of the excellent extraction capability of CNN for global features, which makes the watermark capacity exceed many traditional image-steganography algorithms. The CNNP model firstly divides the images into two groups equally, as shown in
Figure 2, which are named the Cross collection and the Dot collection. The algorithm then predicts the Dot collection
by the Cross collection
. Next, the predicted Dot collection
is input into the CNNP model to predict the Cross collection
. Finally, they combine the predicted Cross collection
with the predicted Dot collection
to obtain the full predicted image. The main structure of the CNNP model is shown in
Figure 3.
The model consists of several convolutional blocks. Each convolutional block consists of × convolutional layers, a LeakyReLU activation function, and 3 × 3 convolutional layers. The algorithm applies a two-stage information-hiding approach. Firstly, the error between the Dot collection and predicted Dot collection needs to be calculated, and then the appropriate prediction error (usually 0) is selected for image steganography. The information-hiding process for the Cross-set images is the same as that for the Dot collection . Furthermore, the algorithm flow of CNNP is reversible. In the flow of image recovery, the CNNP model is applied first to recover the Cross collection , and then the Cross collection is input into the model to recover the Dot collection .
3. Proposed Algorithm
The proposed method contains three main aspects: image steganography, image recovery, and information extraction. For the information-hiding process, we firstly divide the input infrared image into two sets: the Cross collection
and the Dot collection
, as shown in
Figure 2. Then, the watermarked Dot collection
is used to predict the Cross collection
. The prediction process is performed by SRCNN and SWT for the Cross collection
and Dot collection
, respectively. The CNNP model for predicting infrared images is also incorporated into the attention layers to improve the accuracy of the prediction. After the full predicted image
is obtained, the watermarking information is embedded into the infrared image. Furthermore, information-extraction and image-recovery processes are then performed simultaneously. The watermarked Cross collection
is first applied to predict the Dot collection
and the watermark is extracted based on the prediction error. The process for recovering the Cross collection
and extracting the information is done in the same way.
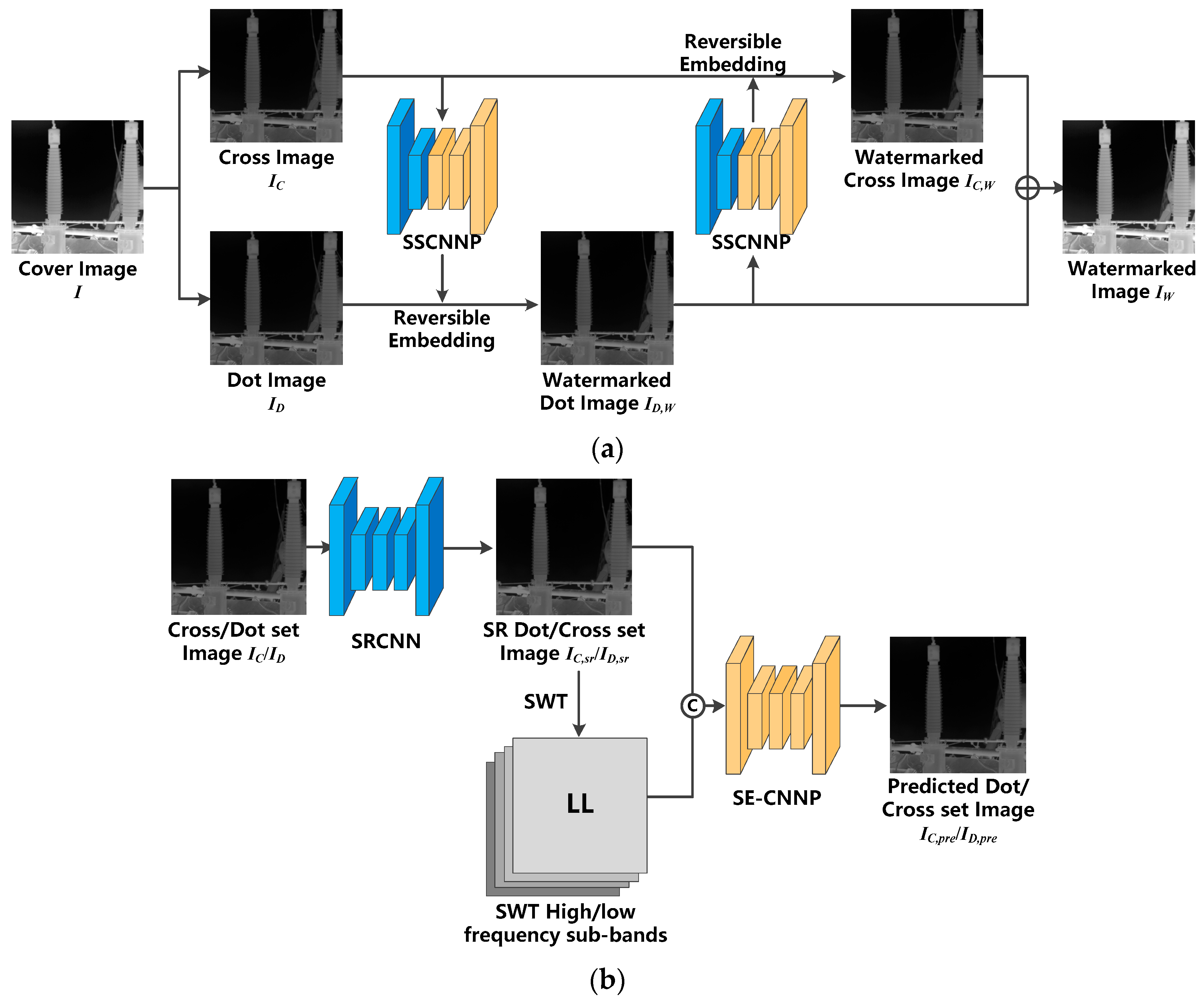
3.1. Image Steganography
In image-steganography step, two CNN-based models are employed: the SRCNN model and the CNNP model. Moreover, SWT is employed to extract the frequency-domain features of the infrared image. The overall structure of the proposed steganography algorithm is shown in Algorithm 1 and
Figure 4a.
Figure 4b indicates the process of SSCNNP (SRCNN followed by CNNP based on the SE layer).
| Algorithm 1: General flow of the algorithm |
1: Image is divided into collections of Cross/Dot .
2: SRCNN preprocesses the .
3: SWT decomposes the result of SRCNN .
4: SE-CNNP predicts the .
5: Reversible hiding or extraction of information.
6: Steps 2~5 for the other half of the image. |
Image steganography can be divided into four main steps: initial image prediction, SWT decomposition, CNNP-based image prediction, and difference-histogram translation. These segments are carefully described in the following subsections.
3.1.1. Initial Image Prediction
Inspired by the SRCNN model for image SR, the initial prediction stage of the image in the proposed method aims to take up as few resources as possible to predict the information of neighboring pixels accurately. Empirically, the CNN model is trained better for input and output images with the same pixel positions. Therefore, if we apply the Cross/Dot
/
collections to predict each other, the prediction error can be reduced. Therefore, the original collections of Cross/Dot
/
are required to be accurately pre-processed before predicting the images. Since the SRCNN model is applied for pre-processing, the Dot/Cross-set images here are denoted by
/
, respectively. As shown in
Figure 1, the SRCNN model receives the original Cross/Dot-set image
/
and outputs the SR collections of Dot/Cross
/
, respectively. Generally, a 9 × 9 convolutional layer first transforms the original Cross/Dot images
/
into 64 feature maps. Then, the model can be applied to more nonlinear scenes by adding nonlinear factors using the ReLu activation function. Finally, two 5 × 5 convolutional layers are applied to extract the features from the image and recover the image as a single-channel infrared image. Moreover, the SRCNN model updates the learning parameters
to reduce the error between the SR Dot/Cross images (
/
) and the original Dot/Cross images (
/
). Finally, the classical MSE function is applied by the loss function
as follows:
3.1.2. SWT Decomposition
CNN model-based algorithms usually extract features from images in the spatial domain. In this paper, we propose to combine an infrared image with its four SWT low-/high-frequency sub-bands inside a tensor and then feed that tensor into the CNNP model for image prediction. In contrast to other wavelet transforms, SWT is a non-downsampling transform, i.e., all sub-bands are equal in size to the original image [
34]. Low-pass and high-pass SWT filters keep all low- and high-frequency components the same size by padding with 0 coefficients in the process of coefficient processing. Taking the SR Dot-set image
as an example, the SWT decomposition can be shown as in the following Equations (6)–(9):
where LL is a low-frequency sub-band, and HL, LH, and HH are high-frequency sub-bands generated by SWT decomposition.
and
are the filters of the SWT transform for different sub-bands. In this paper, the images in the spatial domain and low-/high-frequency features in the frequency domain were jointly used as inputs to the CNNP model to improve the convergence speed and prediction accuracy of the model.
3.1.3. CNNP-Based Image Prediction
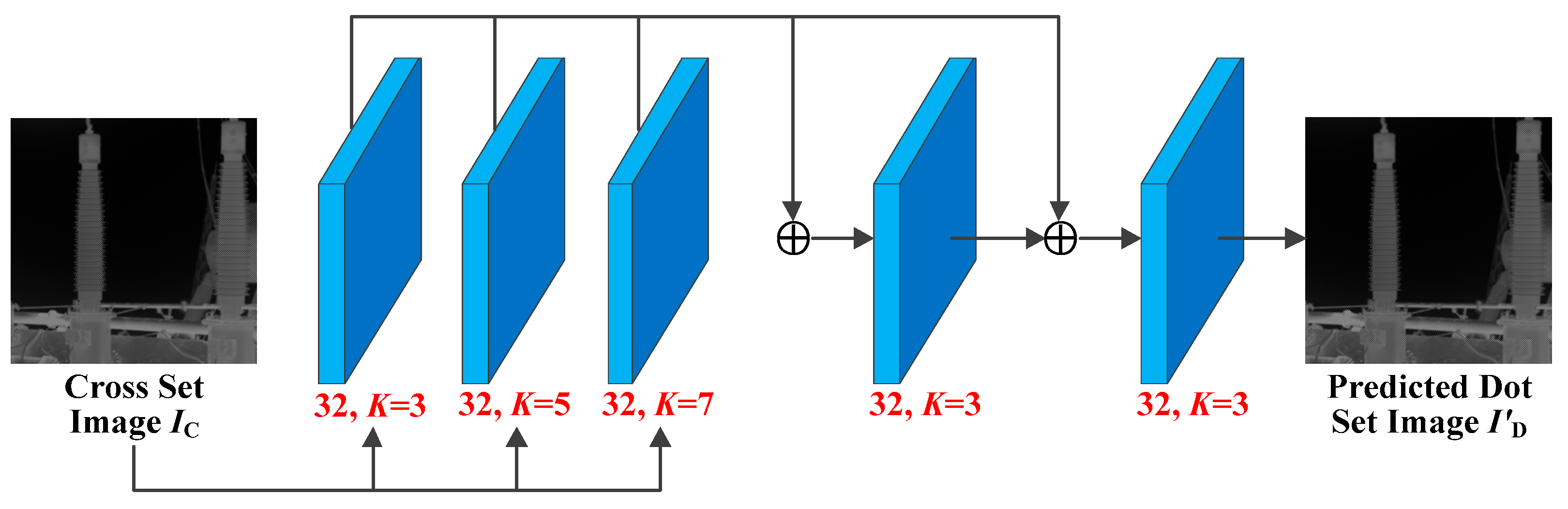
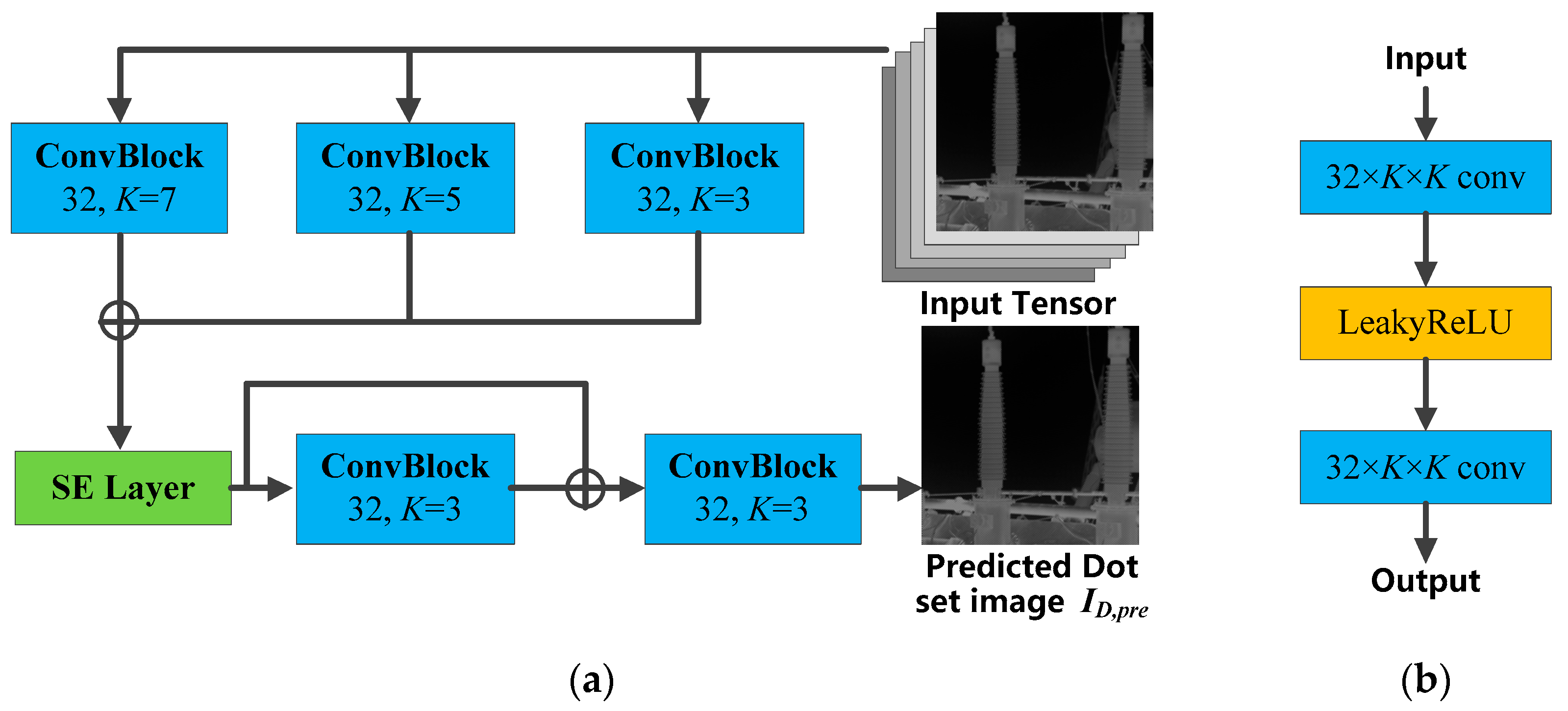
In this paper, we employed a Squeeze-and-Excitation Network (SENet) [
35] to improve the accuracy of the CNNP model. Compared with many CNN-based models that modify the spatial dimension to improve the image-prediction accuracy, SENet instead increases the performance by modeling the relationship of feature channels. Usually, an SE layer takes up few resources and largely improves the convergence speed and performance of the model. In this paper, we modified the CNNP model by applying the SE layer to improve the prediction accuracy of the CNNP model. The structure of the modified CNNP model is shown in
Figure 5.
The input tensor consists of an infrared image and four frequency components of SWT (LL, HL, LH, LL). The SWT sub-bands need to be modified according to the type of infrared image. For example, if the infrared image is the SR collection of Dot
, the Cross-set position of all SWT sub-bands should be set to 0. Consequently, the coefficient of the Dot-set position has to be changed to 0 if the infrared image is the SR collection of Cross
. We first extracted the features of the input tensor by applying 3 × 3, 5 × 5, and 7 × 7 convolutional blocks. Each convolution block consisted of two
×
convolution layers and a LeakyReLU activation function, as shown in
Figure 5b. The LeakyReLU function is an improved version of the classical ReLu activation function, and it has a small slope output for negative inputs. Since the derivative is essentially non-zero, the number of silent neurons is reduced substantially, which allows for gradient-based learning. The LeakyReLU function can solve the problem in which the neurons do not learn if the ReLu function has negative values. However, the training time is increased dramatically. Therefore, we summed up the extracted features and recorded the importance of each feature layer by the SE layer. The SE layer quantifies the importance of the features and visualizes it on the features. Finally, we predicted the final infrared image by using two 3 × 3 convolutional blocks to prevent the CNNP model from gradient disappearance or explosion. One of the convolution blocks was referenced in the form of a residual block, which was connected to the SE layer. By using the SR Dot/Cross (
/
) collections as inputs to the model for training, the loss function
could be defined as in Equation (10) as follows:
where
is the parameter of the CNNP model. Similar to
Section 3.1.1, the CNNP model also uses the MSE function as a loss function. When the loss function
is at a very low value for a long time, it means that the parameters of the model have reached the best case.
3.1.4. Histogram Shifting
Each digital image has its own histogram, including infrared images. The histogram visualizes the number of pixels in the image for each pixel value. Due to its small computational cost and its translation, scaling, and rotation invariance, the image histogram is widely applied in many fields of digital-image processing. In image steganography, histogram shifting is one of the classical reversible information-hiding algorithms [
36,
37,
38]. In this paper, we propose using the histogram-shifting algorithm for reversible image steganography based on the CNNP model to predict the complete final image. Different from traditional histogram-shifting-based algorithms, we selected the prediction error of infrared images to count the histogram.
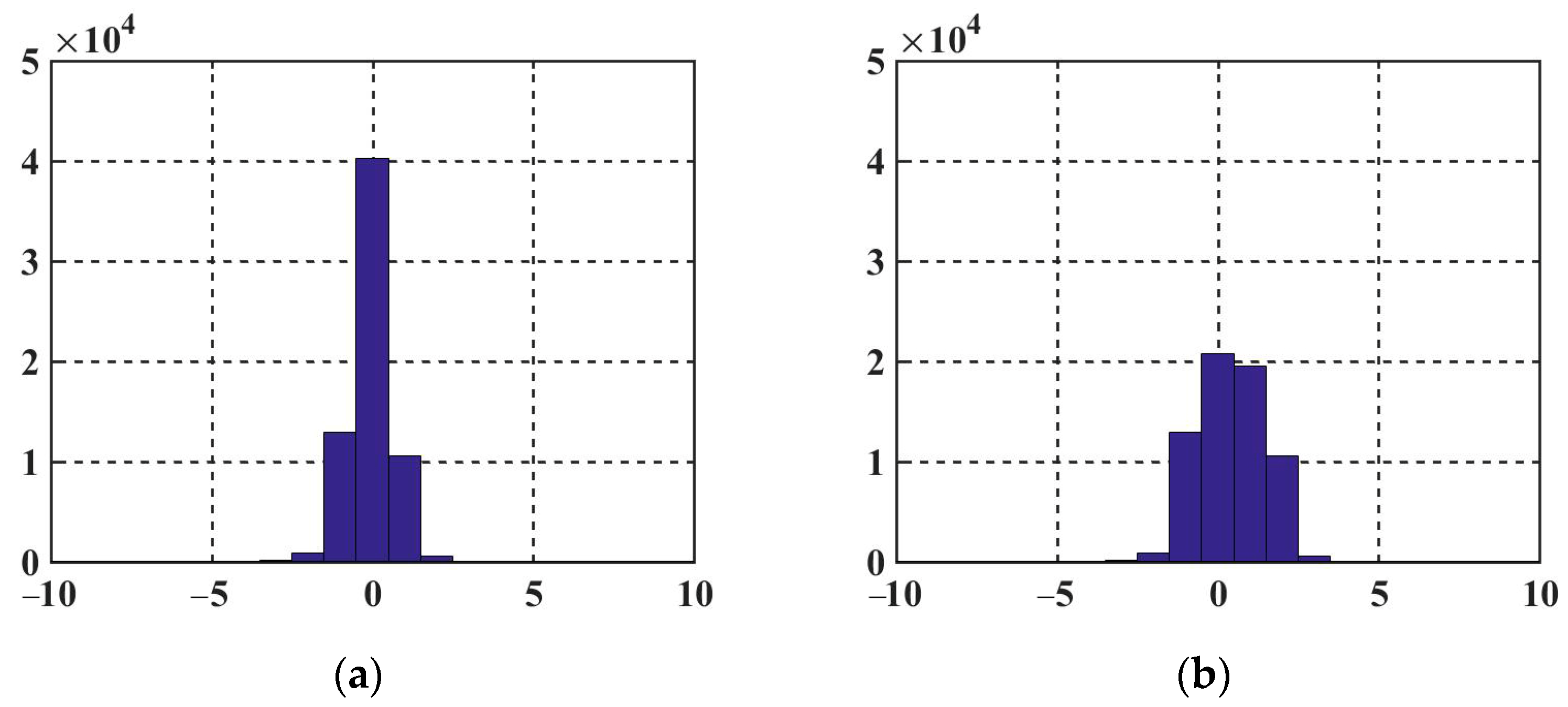
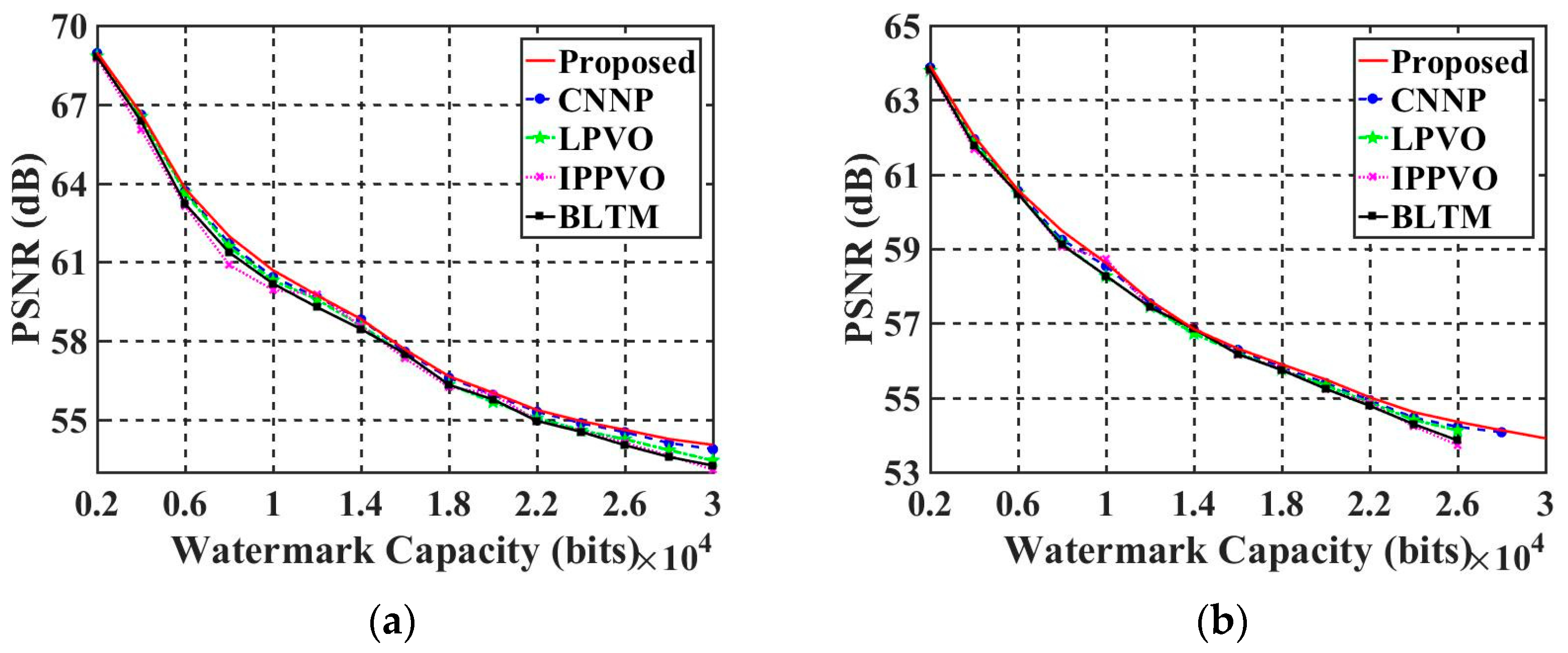
Figure 6a shows a histogram of the prediction error for an infrared image. This image was randomly selected from the test set.
From
Figure 6a, we can see that the proposed SSCNNP model had a good prediction accuracy, where the peaks of the prediction-error histogram were very high at the position 0. This means that we do not need to remember the peak points of the histogram, as in the traditional histogram-shifting algorithm. The peak point of the histogram must be located at level 0 because the prediction error of the algorithm concentrates at 0. The information-hiding algorithm is slightly different depending on the location of the nearest zero point to the peak. For example, in
Figure 6a, the zero value on the right side of the histogram was closest to the peak point (the pixel value between the two points was the lowest), so the equation for the proposed image steganography is shown in Equation (11) as follows:
where
and
are the original and watermarked prediction errors, respectively. The prediction error is the difference between the pixel predicted by the model and the original pixel. The pixel prediction error is inversely proportional to the capacity of information hiding.
i is the index of the pixel.
is the watermarking information to be hidden, and
is watermark’s index. Conversely, if the nearest zero point is located to the left of the peak, the proposed image steganography can be determined as in Equation (12) as follows:
Briefly, the algorithm strives to minimize the number of pixels that are changed with an equal number of watermarks. Furthermore, the positions of these zeros remain unremembered. For example, in
Figure 6b, since the nearest zero point was located to the right of the peak, the watermark-containing histogram had more pixels to the right of 0. Therefore, the direction of the histogram translation could be selected as the right side.
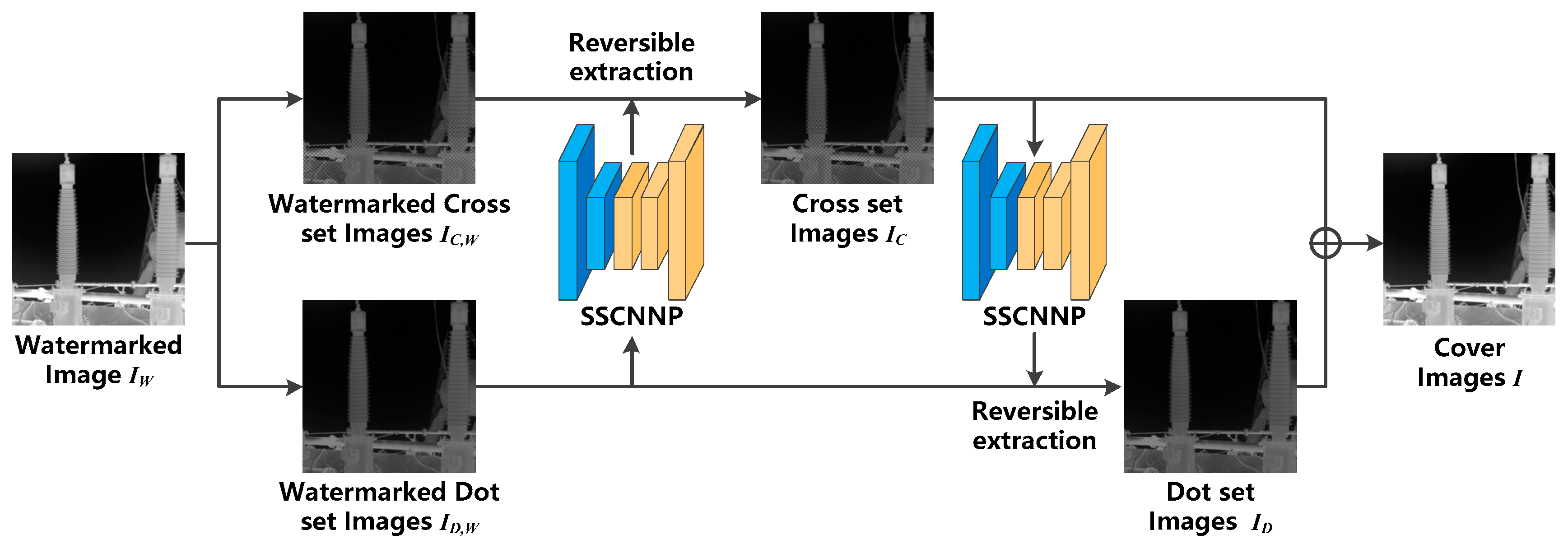
3.2. Image Recovery and Information Extraction
Image recovery and information extraction are performed simultaneously. Furthermore, the information-extraction process is similar to the steps of hiding information. The SRCNN initially predicts the infrared image. Moreover, low-/high-frequency sub-bands of SWT decomposition are fed into the improved CNNP model along with the infrared image itself. For information extraction, the proposed method first uses the watermarked collection of Dot
to predict the collection of Cross
. The result obtained from the prediction and the watermarked collection of Cross
calculates the prediction error to extract the information. While the information is extracted, the collection of Cross
is also recovered. The flow structure of the proposed image recovery and information extraction is shown in
Figure 7.
3.2.1. SRCNN and SWT Pre-Processing
Firstly, SRCNN is applied to pre-process the watermarked collection of Dot/Cross (/). The output of the model is recorded as the watermarked collection of SR Cross/Dot (/, respectively). Secondly, SWT decomposes the watermarked collections of SR Cross/Dot /, and hence one low-frequency sub-band (LL) and three high-frequency sub-bands (HL, LH, and HH) are obtained. The SWT sub-bands together with the watermarked collections of SR Cross/Dot / are fed into the CNNP model to improve the convergence speed and prediction performance of the model.
3.2.2. CNNP Recovery and Extraction
Firstly, the watermarked collections of SR Cross/Dot (
/
) are fed into the improved CNNP model. The addition of the SE layer in the embedding stage allows the CNNP model to obtain a more accurate predicted collection of Cross/Dot (
/
). Secondly, the prediction-error difference between the predicted collections of Cross/Dot (
/
) and the watermarked collections of Cross/Dot (
/
) is calculated. Equation (13) and Equation (14) are the equations for image recovery and watermark extraction when the pixel-prediction error ≥ 0 and ≤ 0, respectively. Based on the difference-histogram translation mentioned in
Section 3.1.4, the formulas for extracting information in both cases are defined as follows:
Next, the same process is applied to predict the collection of Dot by using the watermarked collection of Cross . While the watermark information is extracted from the watermarked collection of Dot , the collection of Cross is also recovered. Finally, the algorithm can obtain both the extracted watermark information and the original infrared image .
5. Conclusions
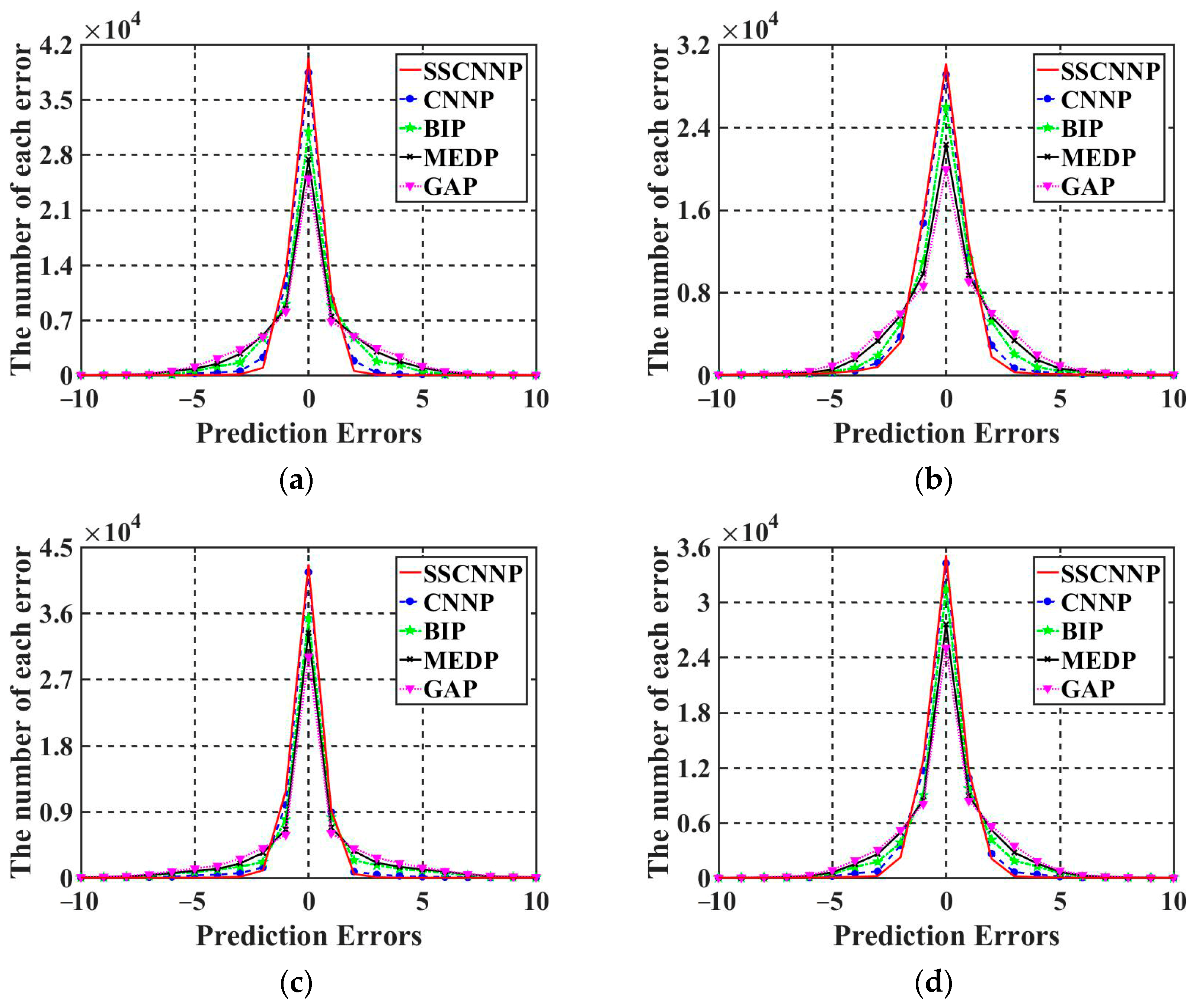
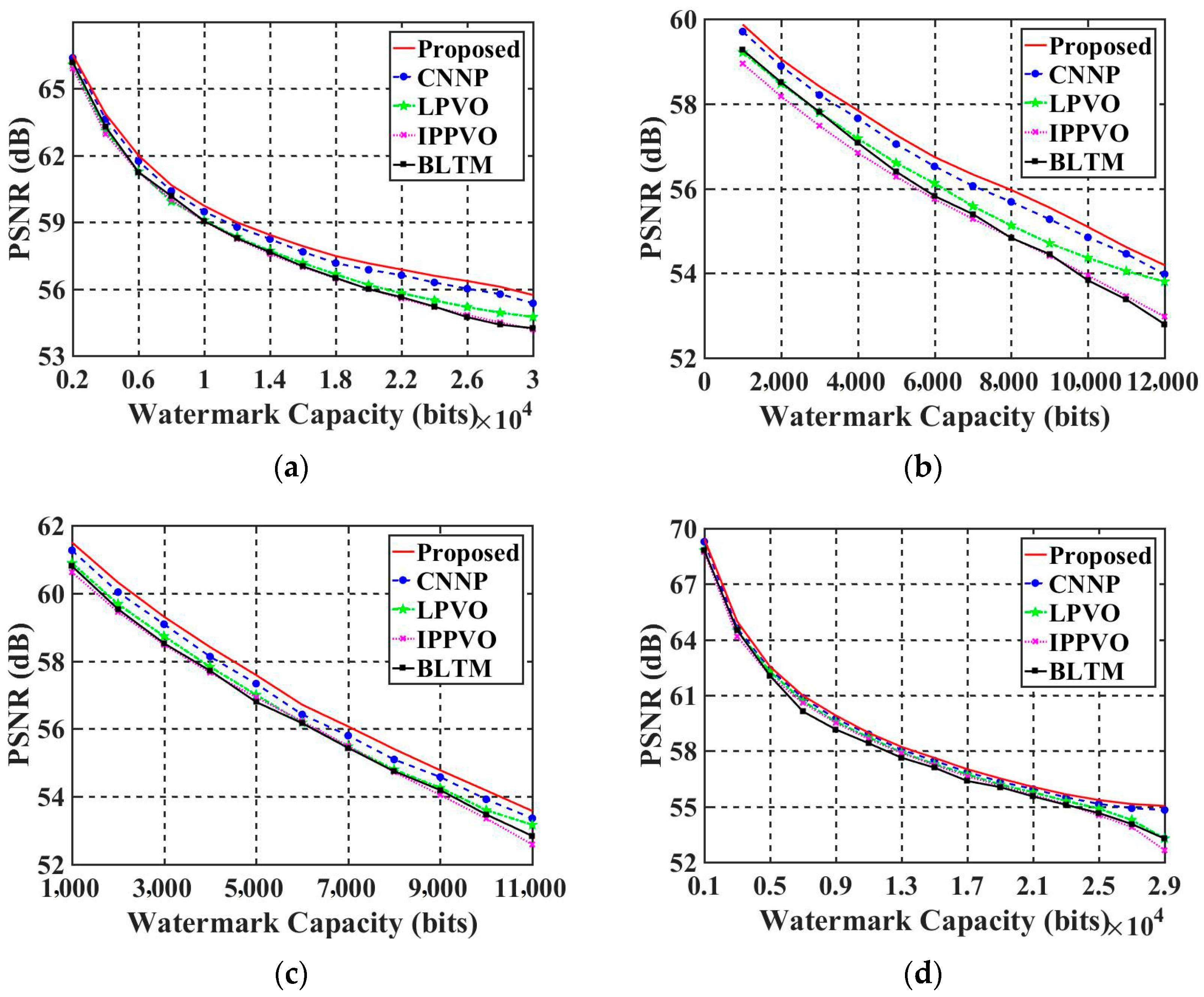
In this paper, a novel steganography algorithm for infrared images is proposed based on the SRCNN and CNNP models. The pre-processing model is the SRCNN model, which is able to predict image pixels more accurately. Furthermore, the proposed model combines the frequency domain of SWT with the spatial domain of the CNNP model to reduce the prediction error. Experiments show that the proposed SSCNNP model had better prediction performance for both classical-prediction-based algorithms and novel-CNNP-based models. Therefore, the imperceptibility and watermark capacity were also improved for infrared images. Moreover, the SRCNN and CNNP models are both lightweight CNN models, and they can be combined with each other in a harmonious way. In future work, we will try to introduce more lightweight CNN models and wavelet transform in the frequency domain to reduce the requirements of hardware equipment and improve the performance of the algorithm at the same time. Moreover, the experimental images should be more abundant and closer to real-time images to ensure the practicality of the algorithm.
However, the infrared applied in this paper was only for the device, so in the future we hope to extend the study to a larger range of infrared images. In addition to image steganography, robust image-watermarking algorithms are also well worth exploring.














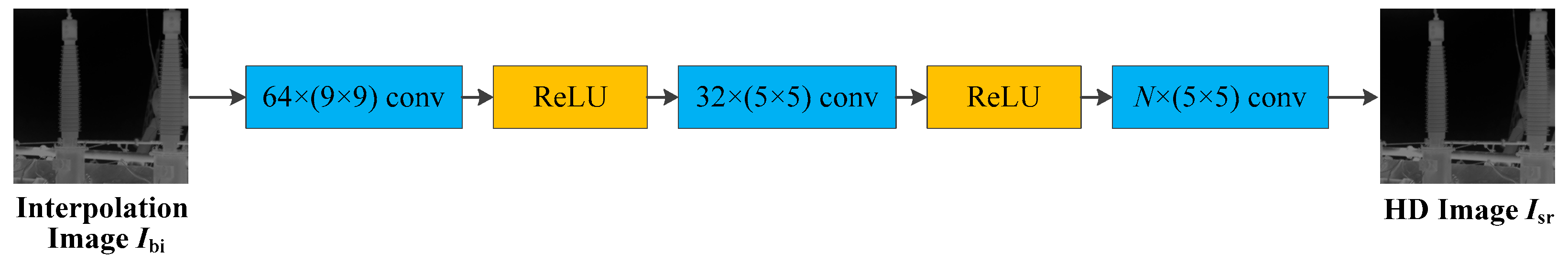{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}