
Deep Learning-Based Anomaly Detection in Video Surveillance: A Survey

Abstract
:1. Introduction
- A comprehensive review of vision-based human activity recognition for video surveillance.
- A description of popular databases used in anomaly detection.
- Analysis of data processing and feature engineering for deep learning models.
- Discussion of recent deep learning models, along with their advantages and disadvantages.
- Identifying existing challenges and future research for anomaly detection in video surveillance.
2. Background Knowledge and Related Works
2.1. Background Knowledge
2.2. Related Works

3. Benchmark Databases
3.1. CASIA Action Database
- Single person action:
- -
- Walk: One subject walking along the road.
- -
- Run: One subject running along the road.
- -
- Bend: One subject bending his/her body while walking.
- -
- Jump: One subject jumping along the road.
- -
- Crouch: One subject crouching once while walking along the road.
- -
- Faint: One subject falling down on the ground while walking along the road.
- -
- Wander: One subject wandering around.
- -
- Punching a car: One subject punching a car.
- Interaction:
- -
- Rob: One subject robing another one.
- -
- Fight: Two subjects fighting with each other.
- -
- Follow: One subject following another till the end.
- -
- Follow and gather: One subject following another and then walking together with the other to the end.
- -
- Meet and part: Two subjects meeting each other and then departing.
- -
- Meet and gather: Two subjects meeting each other and then walking together till the end.
- -
- Overtake: One subject overtaking another.
3.2. Subway Database
3.3. UMN Crowd Abnormality Database
3.4. Anomalous Behavior Database
- Traffic–Train: This video records daily activity on a train. This is a very challenging video, since the lighting conditions change drastically and there is camera jitter. The video includes 19,218 frames of RGB image with a resolution of 288 × 386 and a frame rate of 25 FPS. The anomalous event is the movement of a passenger.
- Belleview: This video includes cars moving through an intersection. Video is recorded in grayscale format at a resolution of 320 × 240, with a frame rate of 10 FPS, and it has 2918 frames in total. The anomalous event is cars entering the thoroughfare from the left or right.
- Boat–Sea: This video describes a passing boat as an abnormal event. The video was recorded in RGB format at a resolution of 720 × 576, with a frame rate of 19 FPS, and it has 450 frames in total.
- Boat–River: This video illustrates a boat passing on a river as an abnormal event. The video was recorded in RGB format at a resolution of 720 × 576, with a frame rate of 5 FPS, and it has 250 frames in total.
- Canoe: This video describes a canoe passing on a river as an abnormal event. The video was recorded in RGB format at a resolution of 320 × 240, with a frame rate of 30 FPS, and it has 1050 frames in total.
- Camouflage: This video illustrates a person walking in camouflage. The right motion is learned as the normal behavior, and the opposite is the abnormal behavior. The video was recorded in RGB format at a resolution of 320 × 240, with a frame rate of 30 FPS, and it has 1629 frames in total.
- Airport-WrongDir: This video records people walking in a line at an airport. The video was recorded in RGB format at a resolution of 300 × 300, with a frame rate of 25 FPS, and it has 2200 frames in total. The anomalous event is people moving in the wrong direction.
3.5. Avenue Database
- Strange actions: behaviors such as running, throwing objects, and loitering.
- Wrong direction: people moving in the wrong direction.
- Abnormal objects: people carrying some strange objects with them, such as a bicycle.
3.6. UCSD Anomaly Detection Database
- The circulation of non-pedestrian entities on the walkways such as bikers, skaters, and small carts.
- Anomalous pedestrian motion patterns, such as people walking across a walkway or in the grass that surrounds it.
3.7. ShanghaiTech Campus Database
- Strange actions: behaviors such as running, robbing, pushing, jumping, jumping over the fence, dropping, throwing objects, and fighting. Below are some sample images.
- Wrong direction: there is the case where people usually follow a normal direction, but someone does the inverse.
- Abnormal objects: this is a case where a person carries a strange object with them, such as a bicycle or baby stroller.
3.8. UCF-Crime Database
3.9. Street Scene Database
4. Preprocessing Data for Video Anomaly Detection
4.1. Segmentation
4.2. Feature Extraction and Selection
- Local representative features use local descriptor algorithms to govern how an input region of an image is locally quantified. They take into account the locality of regions in an image and describe them separately. A HOG (histogram of gradients), as reported in [60,62,63], is a basic technique to extract a local description of the gradient magnitude and orientation of images. A HOG is invariant to photometric transformations but can only be used for human detection at fixed size. Scale-invariant feature transform (SIFT) was used in [64,65] and showed invariance to geometric and photometric transformation, even with 3D projection, but it contains high-dimensional features, which is computer inefficient and unsuitable for real-time applications. The speed-up robust feature (SURF) algorithm [66,67] is an alternative to SIFT that is faster and retains the detection points’ quality. Lastly, the shape-based local feature descriptor in [68,69] demonstrated its robustness to noise by preserving the edge structures of the target subjects. However, it is heavily dependent on silhouette segmentation in its preprocessing step.
- Global representative features use an image descriptor that governs how an input image is globally quantified and returns a feature vector abstractly representing the image contents. The global descriptor in [31,70] encoded the detail information of corners, edges, ridges, and the optical flow as essential features. These features can be easily obtained from the camera depth but they are scene-dependent and have a lack of generic info. Some researchers in [71,72,73] used 3D space–time volume to extract 3D global feature vectors, which were independent of background subtraction. However, these 3D features were highly sensitive to noise and occlusion. The discrete Fourier transform (DFT) was also used in [74,75] to transform spatial features into frequency features, but the inverse process may lose the spatial and temporal information needed to identify the anomalous target subjects.
- The semantic features are obtained from the analysis of human body postures in a video sequence. These features can be transformed into human pose information [76,77] that is robust to interclass variation, but pose accuracy is hard to achieve. The researchers in [78,79] used appearance-based features such as textures and colors to gain contextual information, but this was sensitive to intraclass variations. Three-dimensional semantic features can be obtained from RGD-D cameras [68,80], which provide both geometric and visual information, but this is highly affected by noise and occlusion problems.
5. Deep Learning Methods
5.1. Reconstruction-Based Method
5.2. Multiclass Classifier Method
5.3. Future Frame Prediction Method
5.4. Scoring Method
5.5. Anomaly Score
6. Research Gaps, Challenges, and Future Research
6.1. Research Gaps
6.2. Challenges
6.3. Future Research
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Klette, R. Deep-cascade: Cascading 3d deep neural networks for fast anomaly detection and localization in crowded scenes. IEEE Trans. Image Process. 2017, 26, 1992–2004. [Google Scholar] [CrossRef] [PubMed]
- Medel, J.R.; Savakis, A. Anomaly detection in video using predictive convolutional long short-term memory networks. arXiv 2016, arXiv:1612.00390. [Google Scholar]
- Hu, C.; Chen, Y.; Hu, L.; Peng, X. A novel random forests based class incremental learning method for activity recognition. Pattern Recognit. 2018, 78, 277–290. [Google Scholar] [CrossRef]
- Xiao, Q.; Song, R. Action recognition based on hierarchical dynamic Bayesian network. Multimed. Tools Appl. 2018, 77, 6955–6968. [Google Scholar] [CrossRef]
- Sok, P.; Xiao, T.; Azeze, Y.; Jayaraman, A.; Albert, M.V. Activity recognition for incomplete spinal cord injury subjects using hidden Markov models. IEEE Sens. J. 2018, 18, 6369–6374. [Google Scholar] [CrossRef]
- Abidine, B.M.; Fergani, L.; Fergani, B.; Oussalah, M. The joint use of sequence features combination and modified weighted SVM for improving daily activity recognition. Pattern Anal. Appl. 2018, 21, 119–138. [Google Scholar] [CrossRef]
- Hu, X.; Hu, S.; Huang, Y.; Zhang, H.; Wu, H. Video anomaly detection using deep incremental slow feature analysis network. IET Comput. Vis. 2016, 10, 258–267. [Google Scholar] [CrossRef]
- Ijjina, E.P.; Chalavadi, K.M. Human action recognition in RGB-D videos using motion sequence information and deep learning. Pattern Recognit. 2017, 72, 504–516. [Google Scholar] [CrossRef]
- Tan, T.H.; Gochoo, M.; Huang, S.C.; Liu, Y.H.; Liu, S.H.; Huang, Y.F. Multi-resident activity recognition in a smart home using RGB activity image and DCNN. IEEE Sens. J. 2018, 18, 9718–9727. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Oyedotun, O.K.; Khashman, A. Deep learning in vision-based static hand gesture recognition. Neural Comput. Appl. 2017, 28, 3941–3951. [Google Scholar] [CrossRef]
- Weingaertner, T.; Hassfeld, S.; Dillmann, R. Human motion analysis: A review. In Proceedings of the IEEE Nonrigid and Articulated Motion Workshop, San Juan, PR, USA, 16 June 1997; p. 0090. [Google Scholar]
- Aggarwal, J.K.; Cai, Q. Human motion analysis: A review. Comput. Vis. Image Underst. 1999, 73, 428–440. [Google Scholar] [CrossRef]
- Valera, M.; Velastin, S.A. Intelligent distributed surveillance systems: A review. IEEE Proc. Vision Image Signal Process. 2005, 152, 192–204. [Google Scholar] [CrossRef]
- Ko, T. A survey on behavior analysis in video surveillance for homeland security applications. In Proceedings of the 2008 37th IEEE Applied Imagery Pattern Recognition Workshop, Washington, DC, USA, 15–17 October 2008; pp. 1–8. [Google Scholar]
- Popoola, O.P.; Wang, K. Video-based abnormal human behavior recognition—A review. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 865–878. [Google Scholar] [CrossRef]
- Tsitsoulis, A.; Bourbakis, N. A first stage comparative survey on vision-based human activity recognition. Int. J. Tools 2013, 24, 782783783. [Google Scholar]
- Zabłocki, M.; Gościewska, K.; Frejlichowski, D.; Hofman, R. Intelligent video surveillance systems for public spaces—A survey. J. Theor. Appl. Comput. Sci. 2014, 8, 13–27. [Google Scholar]
- Li, T.; Chang, H.; Wang, M.; Ni, B.; Hong, R.; Yan, S. Crowded scene analysis: A survey. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 367–386. [Google Scholar] [CrossRef]
- Onofri, L.; Soda, P.; Pechenizkiy, M.; Iannello, G. A survey on using domain and contextual knowledge for human activity recognition in video streams. Expert Syst. Appl. 2016, 63, 97–111. [Google Scholar] [CrossRef]
- Herath, S.; Harandi, M.; Porikli, F. Going deeper into action recognition: A survey. Image Vis. Comput. 2017, 60, 4–21. [Google Scholar] [CrossRef]
- Mabrouk, A.B.; Zagrouba, E. Abnormal behavior recognition for intelligent video surveillance systems: A review. Expert Syst. Appl. 2018, 91, 480–491. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Ogunbona, P.; Wan, J.; Escalera, S. RGB-D-based human motion recognition with deep learning: A survey. Comput. Vis. Image Underst. 2018, 171, 118–139. [Google Scholar] [CrossRef]
- Abdallah, Z.S.; Gaber, M.M.; Srinivasan, B.; Krishnaswamy, S. Activity recognition with evolving data streams: A review. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Kiran, B.R.; Thomas, D.M.; Parakkal, R. An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos. J. Imaging 2018, 4, 36. [Google Scholar] [CrossRef]
- Zhang, H.B.; Zhang, Y.X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.X.; Chen, D.S. A comprehensive survey of vision-based human action recognition methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef]
- Raval, R.M.; Prajapati, H.B.; Dabhi, V.K. Survey and analysis of human activity recognition in surveillance videos. Intell. Decis. Technol. 2019, 13, 271–294. [Google Scholar] [CrossRef]
- Dhiman, C.; Vishwakarma, D.K. A review of state-of-the-art techniques for abnormal human activity recognition. Eng. Appl. Artif. Intell. 2019, 77, 21–45. [Google Scholar] [CrossRef]
- Ramachandra, B.; Jones, M.J.; Vatsavai, R.R. A Survey of Single-Scene Video Anomaly Detection. arXiv 2020, arXiv:2004.05993. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Ahmed, M.; Mahmood, A.N.; Hu, J. A survey of network anomaly detection techniques. J. Netw. Comput. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Moustafa, N.; Hu, J.; Slay, J. A holistic review of network anomaly detection systems: A comprehensive survey. J. Netw. Comput. Appl. 2019, 128, 33–55. [Google Scholar] [CrossRef]
- Fernandes, G.; Rodrigues, J.J.; Carvalho, L.F.; Al-Muhtadi, J.F.; Proença, M.L. A comprehensive survey on network anomaly detection. Telecommun. Syst. 2019, 70, 447–489. [Google Scholar] [CrossRef]
- CASIA. CASIA Action Database. 2007. Available online: http://www.cbsr.ia.ac.cn/english/Action/%20Databases/%20EN.asp (accessed on 20 November 2020).
- Adam, A.; Rivlin, E.; Shimshoni, I.; Reinitz, D. Robust real-time unusual event detection using multiple fixed-location monitors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 555–560. [Google Scholar] [CrossRef] [PubMed]
- Mehran, R.; Oyama, A.; Shah, M. Abnormal crowd behavior detection using social force model. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 935–942. [Google Scholar]
- Zaharescu, A.; Wildes, R. Anomalous behaviour detection using spatiotemporal oriented energies, subset inclusion histogram comparison and event-driven processing. In Proceedings of the European Conference on Computer Vision, Heraklion Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 563–576. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 FPS in MATLAB. In Proceedings of the 2013 IEEE international Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Statistical Visual Computing Lab. UCSD Anomaly Data Set. 2014. Available online: http://www.svcl.ucsd.edu/projects/anomaly/ (accessed on 20 November 2020).
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future frame prediction for anomaly detection—A new baseline. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6536–6545. [Google Scholar]
- Ramachandra, B.; Jones, M. Street Scene: A new dataset and evaluation protocol for video anomaly detection. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2569–2578. [Google Scholar]
- Babaee, M.; Dinh, D.T.; Rigoll, G. A deep convolutional neural network for video sequence background subtraction. Pattern Recognit. 2018, 76, 635–649. [Google Scholar] [CrossRef]
- Subudhi, B.N.; Ghosh, S.; Shiu, S.C.; Ghosh, A. Statistical feature bag based background subtraction for local change detection. Inf. Sci. 2016, 366, 31–47. [Google Scholar] [CrossRef]
- Shen, Y.; Hu, W.; Yang, M.; Liu, J.; Wei, B.; Lucey, S.; Chou, C.T. Real-time and robust compressive background subtraction for embedded camera networks. IEEE Trans. Mob. Comput. 2015, 15, 406–418. [Google Scholar] [CrossRef]
- Jiang, S.; Lu, X. WeSamBE: A weight-sample-based method for background subtraction. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2105–2115. [Google Scholar] [CrossRef]
- Sakkos, D.; Liu, H.; Han, J.; Shao, L. End-to-end video background subtraction with 3d convolutional neural networks. Multimed. Tools Appl. 2018, 77, 23023–23041. [Google Scholar] [CrossRef]
- Minematsu, T.; Shimada, A.; Uchiyama, H.; Taniguchi, R.I. Analytics of deep neural network-based background subtraction. J. Imaging 2018, 4, 78. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Del Ser, J.; Baik, S.W.; de Albuquerque, V.H.C. Activity recognition using temporal optical flow convolutional features and multilayer LSTM. IEEE Trans. Ind. Electron. 2018, 66, 9692–9702. [Google Scholar] [CrossRef]
- Ladjailia, A.; Bouchrika, I.; Merouani, H.F.; Harrati, N.; Mahfouf, Z. Human activity recognition via optical flow: Decomposing activities into basic actions. Neural Comput. Appl. 2020, 32, 16387–16400. [Google Scholar] [CrossRef]
- Mliki, H.; Bouhlel, F.; Hammami, M. Human activity recognition from UAV-captured video sequences. Pattern Recognit. 2020, 100, 107140. [Google Scholar] [CrossRef]
- Singh, R.; Dhillon, J.K.; Kushwaha, A.K.S.; Srivastava, R. Depth based enlarged temporal dimension of 3D deep convolutional network for activity recognition. Multimed. Tools Appl. 2019, 78, 30599–30614. [Google Scholar] [CrossRef]
- Liu, L.; Wang, S.; Peng, Y.; Huang, Z.; Liu, M.; Hu, B. Mining intricate temporal rules for recognizing complex activities of daily living under uncertainty. Pattern Recognit. 2016, 60, 1015–1028. [Google Scholar] [CrossRef]
- Sun, B.; Li, Y.; Guosheng, C.; Zhang, J.; Chang, B.; Min, C. Moving target segmentation using Markov random field-based evaluation metric in infrared videos. Opt. Eng. 2018, 57, 013106. [Google Scholar] [CrossRef]
- Lai, Y.; Han, Y.; Wang, Y. Anomaly detection with prototype-guided discriminative latent embeddings. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; pp. 300–309. [Google Scholar]
- Doshi, K.; Yilmaz, Y. Any-shot sequential anomaly detection in surveillance videos. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 934–935. [Google Scholar]
- Cai, R.; Zhang, H.; Liu, W.; Gao, S.; Hao, Z. Appearance-motion memory consistency network for video anomaly detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 938–946. [Google Scholar]
- Kumar, K.S.; Bhavani, R. Human activity recognition in egocentric video using HOG, GiST and color features. Multimed. Tools Appl. 2020, 79, 3543–3559. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, D.; Chen, J.; Ghoneim, A.; Hossain, M.A. A triaxial accelerometer-based human activity recognition via EEMD-based features and game-theory-based feature selection. IEEE Sens. J. 2016, 16, 3198–3207. [Google Scholar] [CrossRef]
- Roy, P.K.; Om, H. Suspicious and violent activity detection of humans using HOG features and SVM classifier in surveillance videos. In Advances in Soft Computing and Machine Learning in Image Processing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 277–294. [Google Scholar]
- Patel, C.I.; Garg, S.; Zaveri, T.; Banerjee, A.; Patel, R. Human action recognition using fusion of features for unconstrained video sequences. Comput. Electr. Eng. 2018, 70, 284–301. [Google Scholar] [CrossRef]
- Jagadeesh, B.; Patil, C.M. Video based human activity detection, recognition and classification of actions using SVM. Trans. Mach. Learn. Artif. Intell. 2018, 6, 22. [Google Scholar]
- Kale, G.V. Human Activity Recognition on Real Time and Offline Dataset. Int. J. Intell. Syst. Appl. Eng. 2019, 7, 60–65. [Google Scholar] [CrossRef]
- Bux, A.; Angelov, P.; Habib, Z. Vision based human activity recognition: A review. In Advances in Computational Intelligence Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 341–371. [Google Scholar]
- Ahad, M.A.R.; Tan, J.K.; Kim, H.; Ishikawa, S. Activity representation by SURF-based templates. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2018, 6, 573–583. [Google Scholar] [CrossRef]
- Patrona, F.; Chatzitofis, A.; Zarpalas, D.; Daras, P. Motion analysis: Action detection, recognition and evaluation based on motion capture data. Pattern Recognit. 2018, 76, 612–622. [Google Scholar] [CrossRef]
- Tang, J.; Cheng, H.; Zhao, Y.; Guo, H. Structured dynamic time warping for continuous hand trajectory gesture recognition. Pattern Recognit. 2018, 80, 21–31. [Google Scholar] [CrossRef]
- Kim, K.; Jalal, A.; Mahmood, M. Vision-based Human Activity recognition system using depth silhouettes: A Smart home system for monitoring the residents. J. Electr. Eng. Technol. 2019, 14, 2567–2573. [Google Scholar] [CrossRef]
- Baumann, F.; Ehlers, A.; Rosenhahn, B.; Liao, J. Recognizing human actions using novel space-time volume binary patterns. Neurocomputing 2016, 173, 54–63. [Google Scholar] [CrossRef]
- Kihl, O.; Picard, D.; Gosselin, P.H. Local polynomial space–time descriptors for action classification. Mach. Vis. Appl. 2016, 27, 351–361. [Google Scholar] [CrossRef]
- Fu, Y.; Zhang, T.; Wang, W. Sparse coding-based space-time video representation for action recognition. Multimed. Tools Appl. 2017, 76, 12645–12658. [Google Scholar] [CrossRef]
- Seyfioğlu, M.S.; Özbayoğlu, A.M.; Gürbüz, S.Z. Deep convolutional autoencoder for radar-based classification of similar aided and unaided human activities. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 1709–1723. [Google Scholar] [CrossRef]
- Shahroudy, A.; Ng, T.T.; Yang, Q.; Wang, G. Multimodal multipart learning for action recognition in depth videos. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2123–2129. [Google Scholar] [CrossRef]
- Li, M.; Zhou, Z.; Liu, X. Multi-person pose estimation using bounding box constraint and LSTM. IEEE Trans. Multimed. 2019, 21, 2653–2663. [Google Scholar] [CrossRef]
- Nishi, K.; Miura, J. Generation of human depth images with body part labels for complex human pose recognition. Pattern Recognit. 2017, 71, 402–413. [Google Scholar] [CrossRef]
- Xu, D.; Yan, Y.; Ricci, E.; Sebe, N. Detecting anomalous events in videos by learning deep representations of appearance and motion. Comput. Vis. Image Underst. 2017, 156, 117–127. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, H.; Zhang, L.; Ruan, X. Combining motion and appearance cues for anomaly detection. Pattern Recognit. 2016, 51, 443–452. [Google Scholar] [CrossRef]
- Ji, X.; Cheng, J.; Feng, W.; Tao, D. Skeleton embedded motion body partition for human action recognition using depth sequences. Signal Process. 2018, 143, 56–68. [Google Scholar] [CrossRef]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]
- Sabokrou, M.; Fathy, M.; Hoseini, M. Video anomaly detection and localisation based on the sparsity and reconstruction error of auto-encoder. Electron. Lett. 2016, 52, 1122–1124. [Google Scholar] [CrossRef]
- Narasimhan, M.G.; Kamath, S. Dynamic video anomaly detection and localization using sparse denoising autoencoders. Multimed. Tools Appl. 2018, 77, 13173–13195. [Google Scholar] [CrossRef]
- Zhao, Y.; Deng, B.; Shen, C.; Liu, Y.; Lu, H.; Hua, X.S. Spatio-temporal autoencoder for video anomaly detection. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1933–1941. [Google Scholar]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Moayed, Z.; Klette, R. Deep-anomaly: Fully convolutional neural network for fast anomaly detection in crowded scenes. Comput. Vis. Image Underst. 2018, 172, 88–97. [Google Scholar] [CrossRef]
- Ribeiro, M.; Lazzaretti, A.E.; Lopes, H.S. A study of deep convolutional auto-encoders for anomaly detection in videos. Pattern Recognit. Lett. 2018, 105, 13–22. [Google Scholar] [CrossRef]
- Sabzalian, B.; Marvi, H.; Ahmadyfard, A. Deep and Sparse features For Anomaly Detection and Localization in video. In Proceedings of the 2019 4th International Conference on Pattern Recognition and Image Analysis (IPRIA), Tehran, Iran, 6–7 March 2019; pp. 173–178. [Google Scholar]
- Landi, F.; Snoek, C.G.; Cucchiara, R. Anomaly Locality in Video Surveillance. arXiv 2019, arXiv:1901.10364. [Google Scholar]
- Zhou, J.T.; Du, J.; Zhu, H.; Peng, X.; Liu, Y.; Goh, R.S.M. Anomalynet: An anomaly detection network for video surveillance. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2537–2550. [Google Scholar] [CrossRef]
- Zhu, Y.; Newsam, S. Motion-aware feature for improved video anomaly detection. arXiv 2019, arXiv:1907.10211. [Google Scholar]
- Lin, S.; Yang, H.; Tang, X.; Shi, T.; Chen, L. Social MIL: Interaction-Aware for Crowd Anomaly Detection. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; van den Hengel, A. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1705–1714. [Google Scholar]
- dos Santos, F.P.; Ribeiro, L.S.; Ponti, M.A. Generalization of feature embeddings transferred from different video anomaly detection domains. J. Vis. Commun. Image Represent. 2019, 60, 407–416. [Google Scholar] [CrossRef]
- Ionescu, R.T.; Khan, F.S.; Georgescu, M.I.; Shao, L. Object-centric auto-encoders and dummy anomalies for abnormal event detection in video. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7842–7851. [Google Scholar]
- Luo, W.; Liu, W.; Lian, D.; Tang, J.; Duan, L.; Peng, X.; Gao, S. Video anomaly detection with sparse coding inspired deep neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1070–1084. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Sun, T.; Jiang, X. Video anomaly detection and localization based on an adaptive intra-frame classification network. IEEE Trans. Multimed. 2019, 22, 394–406. [Google Scholar] [CrossRef]
- Fan, Y.; Wen, G.; Li, D.; Qiu, S.; Levine, M.D.; Xiao, F. Video anomaly detection and localization via Gaussian mixture fully convolutional variational autoencoder. Comput. Vis. Image Underst. 2020, 195, 102920. [Google Scholar] [CrossRef]
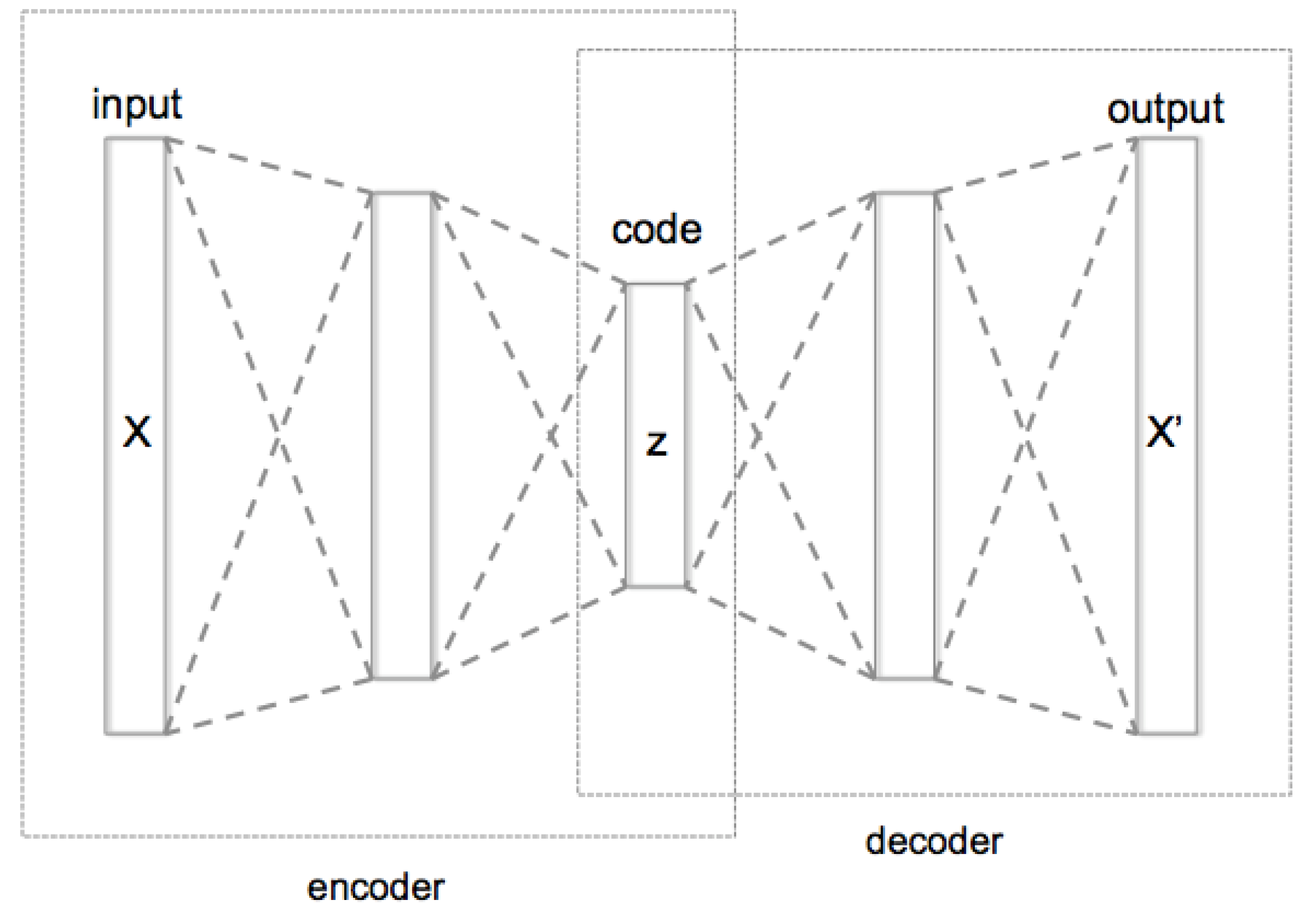
- Wikipedia. Autoencoder—Wikipedia, The Free Encyclopedia. 2023. Available online: http://en.wikipedia.org/w/index.php?title=Autoencoder&oldid=1141727025 (accessed on 4 April 2023).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Aich, A.; Peng, K.C.; Roy-Chowdhury, A.K. Cross-Domain Video Anomaly Detection without Target Domain Adaptation. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 2579–2591. [Google Scholar]
- Yang, Z.; Wu, P.; Liu, J.; Liu, X. Dynamic Local Aggregation Network with Adaptive Clusterer for Anomaly Detection. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part IV. Springer: Berlin/Heidelberg, Germany, 2022; pp. 404–421. [Google Scholar]
- Liu, Y.; Liu, J.; Zhao, M.; Yang, D.; Zhu, X.; Song, L. Learning Appearance-Motion Normality for Video Anomaly Detection. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Zhang, X.; Fang, J.; Yang, B.; Chen, S.; Li, B. Hybrid Attention and Motion Constraint for Anomaly Detection in Crowded Scenes. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 2259–2274. [Google Scholar] [CrossRef]
- Wang, T.; Xu, X.; Shen, F.; Yang, Y. A cognitive memory-augmented network for visual anomaly detection. IEEE/CAA J. Autom. Sin. 2021, 8, 1296–1307. [Google Scholar] [CrossRef]
- Bahrami, M.; Pourahmadi, M.; Vafaei, A.; Shayesteh, M.R. A comparative study between single and multi-frame anomaly detection and localization in recorded video streams. J. Vis. Commun. Image Represent. 2021, 79, 103232. [Google Scholar] [CrossRef]
- Liu, Z.; Nie, Y.; Long, C.; Zhang, Q.; Li, G. A hybrid video anomaly detection framework via memory-augmented flow reconstruction and flow-guided frame prediction. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13588–13597. [Google Scholar]
- Tang, W.; Feng, Y.; Li, J. An autoencoder with a memory module for video anomaly detection. In Proceedings of the 2021 36th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Nanchang, China, 28–30 May 2021; pp. 473–478. [Google Scholar]
- Wu, C.; Shao, S.; Tunc, C.; Satam, P.; Hariri, S. An explainable and efficient deep learning framework for video anomaly detection. Clust. Comput. 2022, 25, 2715–2737. [Google Scholar] [CrossRef]
- Aslam, N.; Rai, P.K.; Kolekar, M.H. A3N: Attention-based adversarial autoencoder network for detecting anomalies in video sequence. J. Vis. Commun. Image Represent. 2022, 87, 103598. [Google Scholar] [CrossRef]
- Borja-Borja, L.F.; Azorín-López, J.; Saval-Calvo, M.; Fuster-Guilló, A.; Sebban, M. Architecture for Automatic Recognition of Group Activities Using Local Motions and Context. IEEE Access 2022, 10, 79874–79889. [Google Scholar] [CrossRef]
- Huang, X.; Hu, Y.; Luo, X.; Han, J.; Zhang, B.; Cao, X. Boosting Variational Inference with Margin Learning for Few-Shot Scene-Adaptive Anomaly Detection. IEEE Trans. Circuits Syst. Video Technol. 2022; early access. [Google Scholar] [CrossRef]
- Li, D.; Nie, X.; Li, X.; Zhang, Y.; Yin, Y. Context-related video anomaly detection via generative adversarial network. Pattern Recognit. Lett. 2022, 156, 183–189. [Google Scholar] [CrossRef]
- Yu, G.; Wang, S.; Cai, Z.; Liu, X.; Xu, C.; Wu, C. Deep anomaly discovery from unlabeled videos via normality advantage and self-paced refinement. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13987–13998. [Google Scholar]
- Zhang, Z.; Zhong, S.h.; Fares, A.; Liu, Y. Detecting abnormality with separated foreground and background: Mutual generative adversarial networks for video abnormal event detection. Comput. Vis. Image Underst. 2022, 219, 103416. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, Y. Anomaly detection with dual-stream memory network. J. Vis. Commun. Image Represent. 2023, 90, 103739. [Google Scholar] [CrossRef]
- Le, V.T.; Kim, Y.G. Attention-based residual autoencoder for video anomaly detection. Appl. Intell. 2023, 53, 3240–3254. [Google Scholar] [CrossRef]
- Deng, H.; Zhang, Z.; Zou, S.; Li, X. Bi-Directional Frame Interpolation for Unsupervised Video Anomaly Detection. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 2634–2643. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965; Volume 1, pp. 281–297. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Cambridge, MA, USA, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Wiskott, L.; Sejnowski, T.J. Slow feature analysis: Unsupervised learning of invariances. Neural Comput. 2002, 14, 715–770. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Wu, P.; Liu, J.; Li, M.; Sun, Y.; Shen, F. Fast sparse coding networks for anomaly detection in videos. Pattern Recognit. 2020, 107, 107515. [Google Scholar] [CrossRef]
- Li, N.; Chang, F.; Liu, C. Spatial-temporal cascade autoencoder for video anomaly detection in crowded scenes. IEEE Trans. Multimed. 2020, 23, 203–215. [Google Scholar] [CrossRef]
- Chang, Y.; Tu, Z.; Xie, W.; Yuan, J. Clustering driven deep autoencoder for video anomaly detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 329–345. [Google Scholar]
- Chang, Y.; Tu, Z.; Xie, W.; Luo, B.; Zhang, S.; Sui, H.; Yuan, J. Video anomaly detection with spatio-temporal dissociation. Pattern Recognit. 2022, 122, 108213. [Google Scholar] [CrossRef]
- Huang, X.; Zhao, C.; Gao, C.; Chen, L.; Wu, Z. Synthetic Pseudo Anomalies for Unsupervised Video Anomaly Detection: A Simple yet Efficient Framework based on Masked Autoencoder. arXiv 2023, arXiv:2303.05112. [Google Scholar]
- Sun, X.; Chen, J.; Shen, X.; Li, H. Transformer with Spatio-Temporal Representation for Video Anomaly Detection. In Proceedings of the Structural, Syntactic, and Statistical Pattern Recognition: Joint IAPR International Workshops, S+ SSPR 2022, Montreal, QC, Canada, 26–27 August 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 213–222. [Google Scholar]
- Guo, L.; Wang, L.; Liu, J.; Zhou, W.; Lu, B. HuAc: Human activity recognition using crowdsourced WiFi signals and skeleton data. Wirel. Commun. Mob. Comput. 2018, 2018, 6163475. [Google Scholar] [CrossRef]
- Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; Carlos Niebles, J. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Pei, Z.; Qi, X.; Zhang, Y.; Ma, M.; Yang, Y.H. Human trajectory prediction in crowded scene using social-affinity Long Short-Term Memory. Pattern Recognit. 2019, 93, 273–282. [Google Scholar] [CrossRef]
- Akila, K.; Chitrakala, S. Highly refined human action recognition model to handle intraclass variability & interclass similarity. Multimed. Tools Appl. 2019, 78, 20877–20894. [Google Scholar]
- Wateosot, C.; Suvonvorn, N. Group activity recognition with an interaction force based on low-level features. IEEJ Trans. Electr. Electron. Eng. 2019, 14, 1061–1073. [Google Scholar] [CrossRef]
- Jalal, A.; Kim, Y.H.; Kim, Y.J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Carreira, J.; Noland, E.; Hillier, C.; Zisserman, A. A short note on the kinetics-700 human action dataset. arXiv 2019, arXiv:1907.06987. [Google Scholar]
- Xu, C.; Chai, D.; He, J.; Zhang, X.; Duan, S. InnoHAR: A deep neural network for complex human activity recognition. IEEE Access 2019, 7, 9893–9902. [Google Scholar] [CrossRef]
- Salaken, S.M.; Khosravi, A.; Nguyen, T.; Nahavandi, S. Seeded transfer learning for regression problems with deep learning. Expert Syst. Appl. 2019, 115, 565–577. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.N.; Thai, C.H.; Luu, A.T.; Nguyen-Xuan, H.; Lee, J. NURBS-based postbuckling analysis of functionally graded carbon nanotube-reinforced composite shells. Comput. Methods Appl. Mech. Eng. 2019, 347, 983–1003. [Google Scholar] [CrossRef]
- Goyal, R.; Kahou, S.E.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “Something Something” Video Database for Learning and Evaluating Visual Common Sense. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 1, p. 5. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type | Year | Reference |
|---|---|---|---|
| Convolutional Long Short-Term Memory | RB + Future Frame Prediction | 2016 | [4] |
| 2D Convolutional Autoencoder | RB | 2016 | [81] |
| Sparse Autoencoder | Reconstruction based | 2016 | [82] |
| Slow Feature Analysis + Deep Neural Network | Scoring | 2016 | [9] |
| Sparse Denoise Autoencoder | Multiclass Classification | 2017 | [83] |
| Autoencoder + Cascade Deep CNN | Multiclass Classification | 2017 | [3] |
| Spatiotemporal Autoencoder | RB + Future Frame Prediction | 2017 | [84] |
| Pretrained DNN + Gaussian classifier | Multiclass Classification | 2018 | [85] |
| Autoencoder + Low level features | Reconstruction based | 2018 | [86] |
| Multiple Instance Learning | Scoring | 2018 | [2] |
| Low-level Features + Autoencoder | Reconstruction based | 2018 | [86] |
| Frame predict using GANs | Future Frame Prediction | 2018 | [43] |
| Combination of traditional and deep features | Scoring | 2019 | [87] |
| Localization feature extraction | Scoring | 2019 | [88] |
| AnomalyNet | Reconstruction based | 2019 | [89] |
| Optical Flow + Multiple Instance Learning | Scoring | 2019 | [90] |
| Social Force Maps + Multiple Instance Learning | Scoring | 2019 | [91] |
| Attention module + Autoencoder | Reconstruction based | 2019 | [92] |
| Component Analysis + Transfer Learning | Multiclass Classification | 2019 | [93] |
| Object detection using SSD + Autoencoder | Multiclass Classification | 2019 | [94] |
| Sparse coding Deep neural network | Scoring | 2019 | [95] |
| Adaptive Intra-Frame Classification Network | Classification | 2019 | [96] |
| Autoencoder + Gaussian Mixture Model | Scoring | 2020 | [97] |
| Method | Ped 1 | Ped 2 | Avenue | ShanghaiTech | Year | Reference |
|---|---|---|---|---|---|---|
| Cognitive memory-augmented network (CMAN) | - | 96.2 | - | - | 2021 | [104] |
| Single and multi-frame anomaly detection | - | 97.5 | 87.2 | - | 2021 | [105] |
| Multi-Level Memory modules in an Autoencoder with Skip Connections (ML-MemAE-SC) | - | 99.3 | 91.1 | 76.2 | 2021 | [106] |
| Autoencoder with a Memory Module (AMM) | - | 97.2 | 87.9 | 70.2 | 2021 | [107] |
| Explanation for Anomaly Detection | 73.1 | 80.1 | - | - | 2021 | [108] |
| Attention-based adversarial autoencoder (A3N) | 90.7 | 97.7 | 89.4 | 86.9 | 2022 | [109] |
| Group Activities for AD | 84.4 | 95.0 | 82.3 | - | 2022 | [110] |
| Variational Anomaly Detection Network (VADNet) | - | 96.8 | 87.3 | 75.2 | 2022 | [111] |
| Context-related video anomaly detection | - | 96.3 | 87.1 | 73.6 | 2022 | [112] |
| Localization based Reconstruction (LBR) | 81.1 | 97.2 | 92.8 | 72.6 | 2022 | [113] |
| Foreground–Background Separation Mutual Generative Adversarial Network (FSM-GAN) | - | 98.1 | 80.1 | 73.5 | 2022 | [114] |
| Dual-stream memory network | - | 98.3 | 88.6 | 75.7 | 2023 | [115] |
| Attention-based residual autoencoder | - | 97.4 | 86.7 | 73.6 | 2023 | [116] |
| Bi-directional Frame Interpolation | - | 98.9 | 89.7 | 75.0 | 2023 | [117] |
| Zero-shot Cross-domain Video Anomaly Detection (zxVAD) | 78.6 | 95.8 | 83.2 | - | 2023 | [100] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duong, H.-T.; Le, V.-T.; Hoang, V.T. Deep Learning-Based Anomaly Detection in Video Surveillance: A Survey. Sensors 2023, 23, 5024. https://doi.org/10.3390/s23115024
Duong H-T, Le V-T, Hoang VT. Deep Learning-Based Anomaly Detection in Video Surveillance: A Survey. Sensors. 2023; 23(11):5024. https://doi.org/10.3390/s23115024
Chicago/Turabian StyleDuong, Huu-Thanh, Viet-Tuan Le, and Vinh Truong Hoang. 2023. "Deep Learning-Based Anomaly Detection in Video Surveillance: A Survey" Sensors 23, no. 11: 5024. https://doi.org/10.3390/s23115024