



From Lab to Real World: Assessing the Effectiveness of Human Activity Recognition and Optimization through Personalization

Abstract
:1. Introduction
- We discuss the lack of research performed and evaluated on RW data and argue why the community should make the shift towards RW scenarios. We acknowledge and discuss the lack of publicly available RW data for activity recognition.
- To bridge the gap, we designed and performed longitudinal, unobserved RW HAR data collection from wrist-worn devices. We discuss challenges, such as recall bias and label quality, that are part of RW data collection and the steps we have taken to overcome these challenges. As a result, we have collected diverse accelerometer sensor data from 18 participants with different activities. This dataset fully reflects RW scenarios in the daily life of people.
- We trained and evaluated general models on this RW dataset, using different amounts of data. We discuss the amount of data needed to achieve satisfying results. We additionally identify challenges such as different approaches to labeling between subjects, (unintentional) mislabeling, and unknown watch placement (dominant vs. non-dominant arm).
- We investigated the potential of personalization on RW data and discuss whether and when it is of great value to perform personalization.
- We evaluated the predictive performance of models trained with data collected in a controlled environment on RW data and vice versa. We show that models trained on data in a controlled environment perform poorly when evaluated on RW data.
- We investigated the potential of personalizing models trained on data collected in controlled environments with RW data and show that their performance can be greatly improved with only few RW data.
2. Related Work
2.1. HAR Machine Learning Techniques
2.2. Har Personalization of Models
2.3. HAR in Real-World Scenarios
3. Datasets
3.1. Idlab Dataset
3.1.1. Equipment and Devices
3.1.2. Preliminary Data Collection and Supporting Classifier
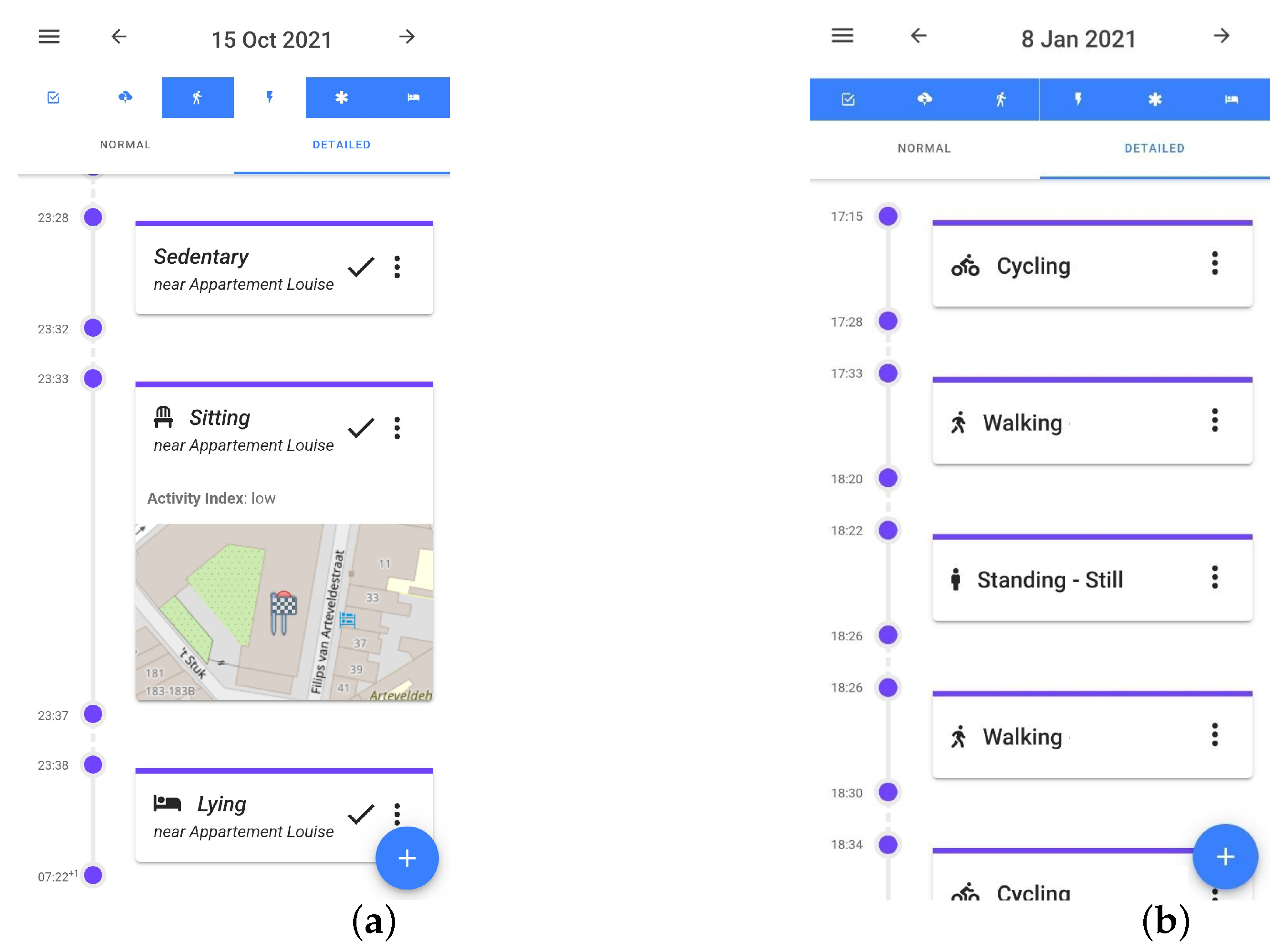
3.1.3. Idlab Real-World Dataset Collection
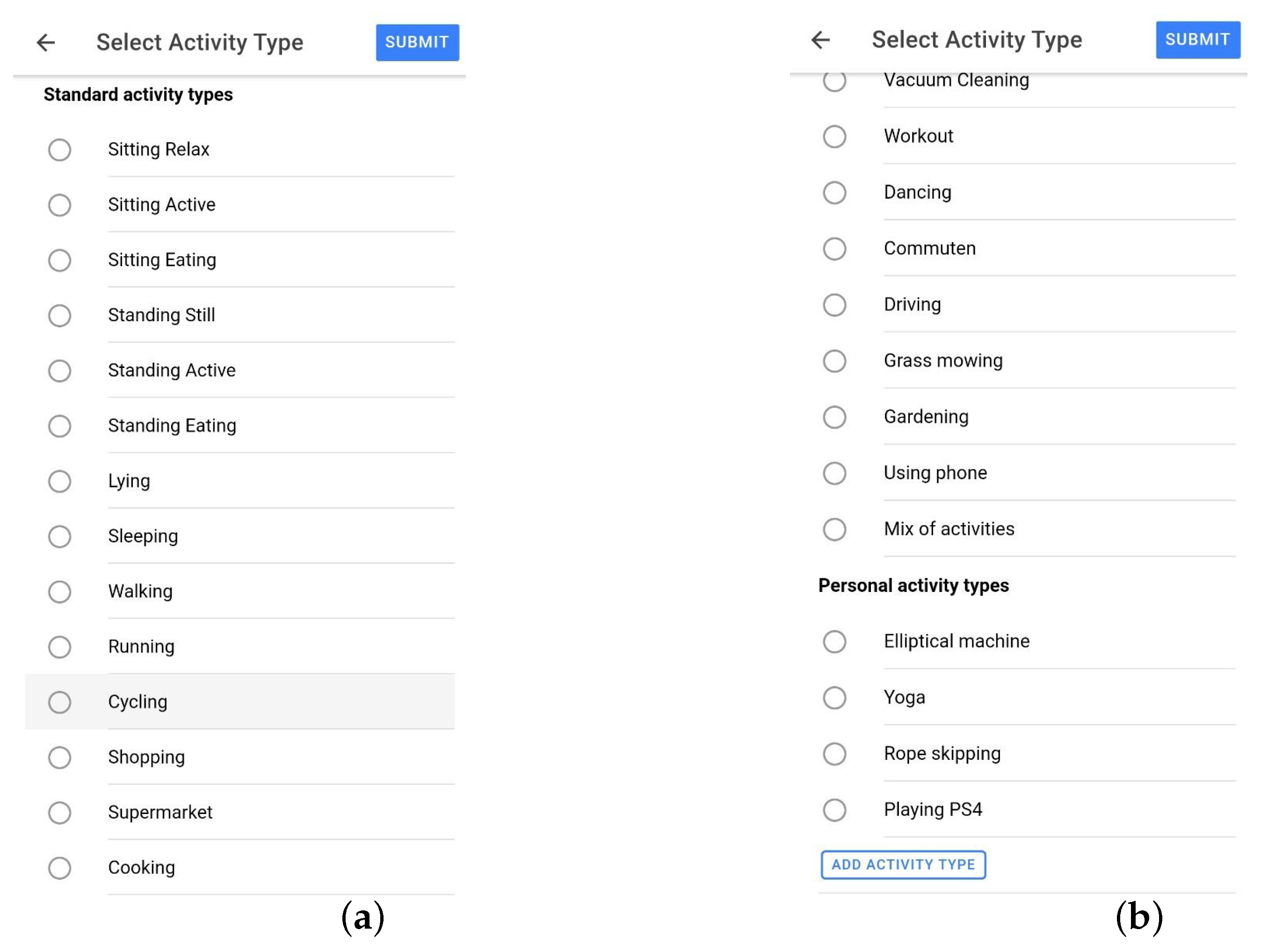
3.1.4. Activities
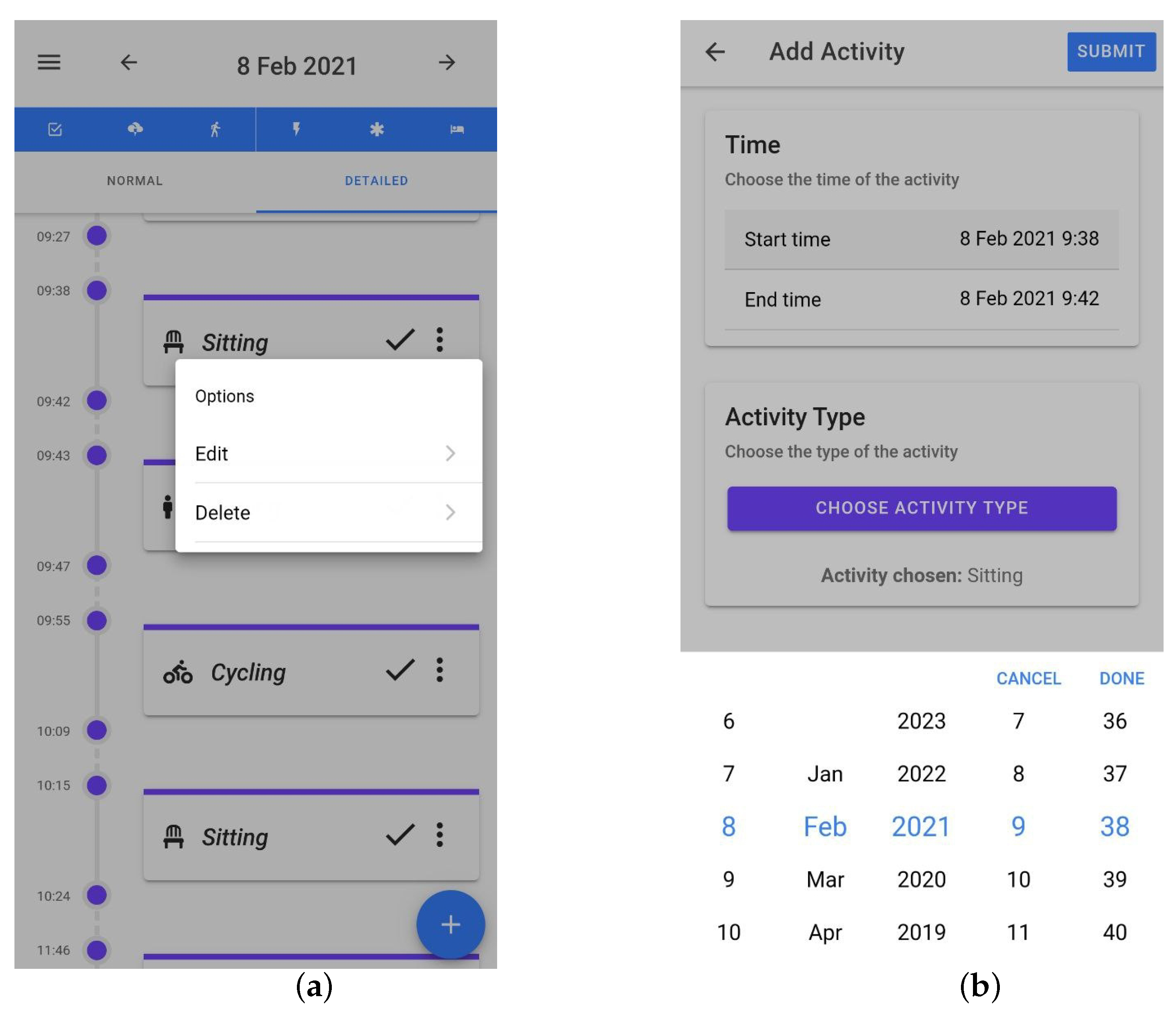
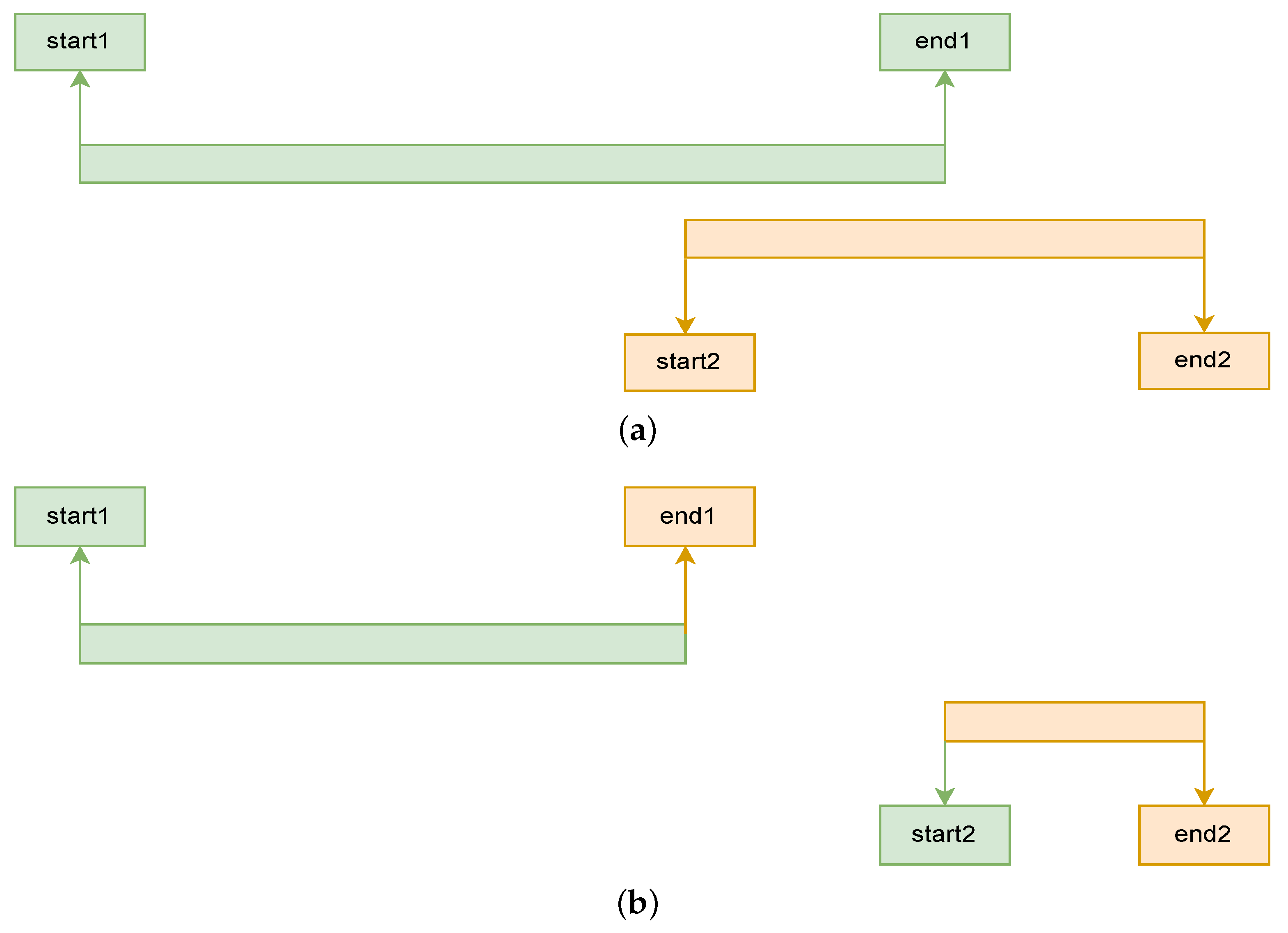
3.1.5. Correcting Overlapping Labels
3.1.6. Final Dataset
3.2. MHEALTH Dataset
4. Methodology
4.1. General Models—Real-World IDLab Dataset
4.1.1. Processing the Sensor Data
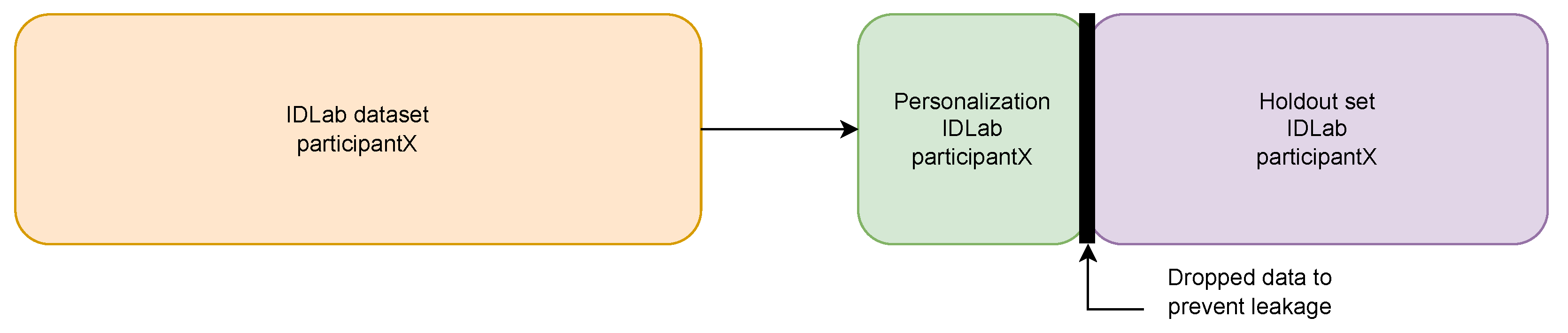
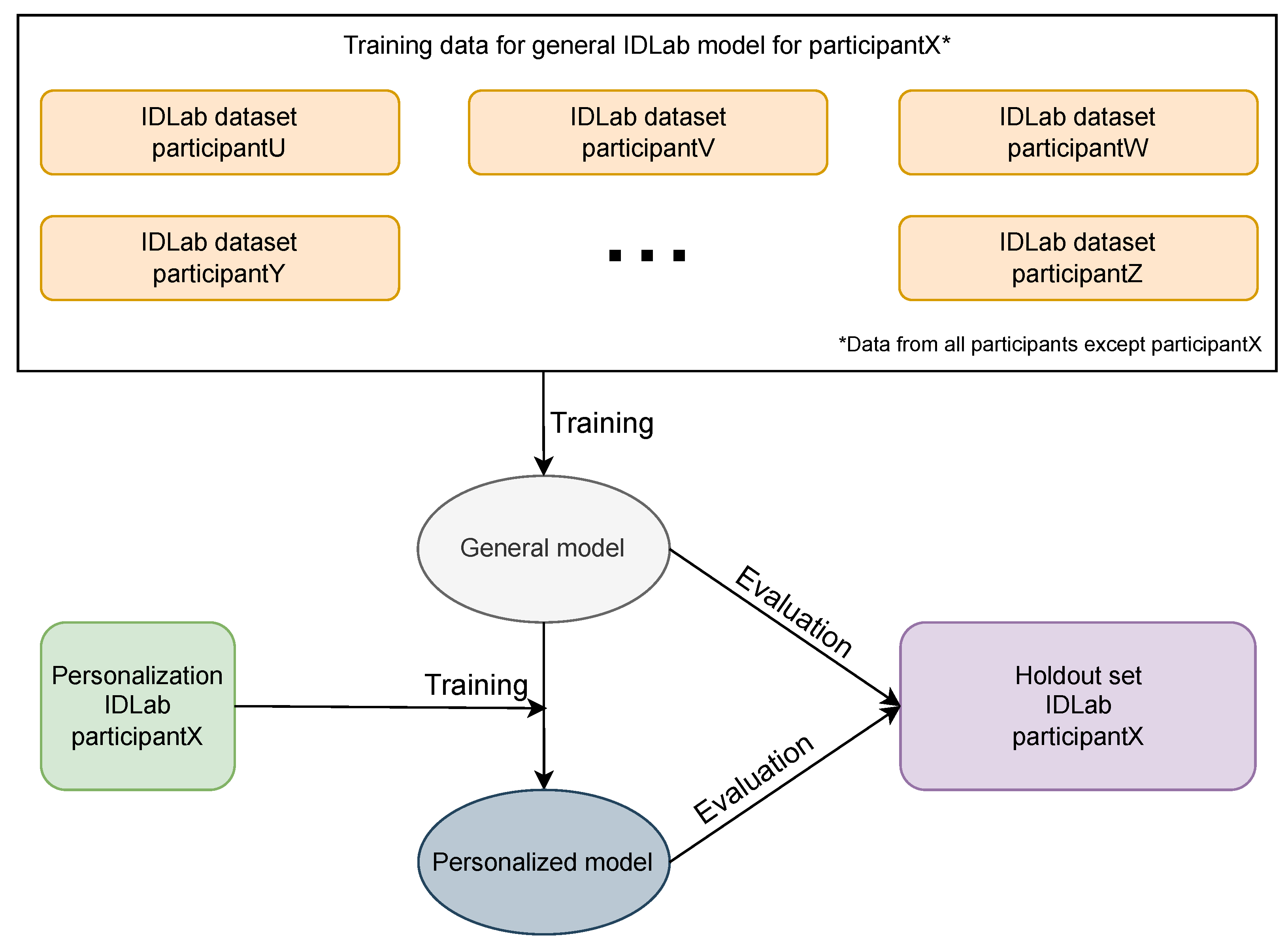
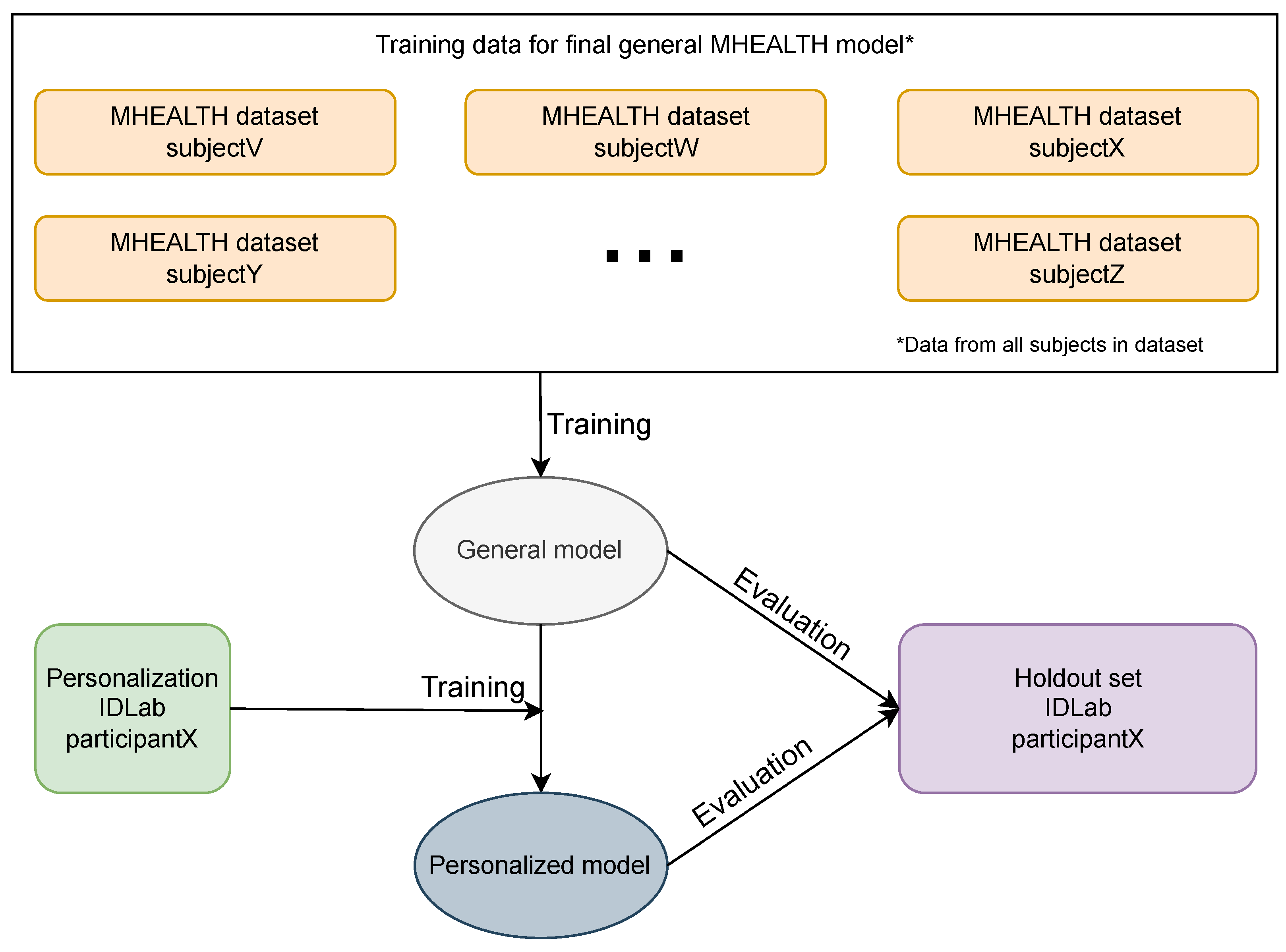
4.1.2. Personalization and Hold-Out Test Set
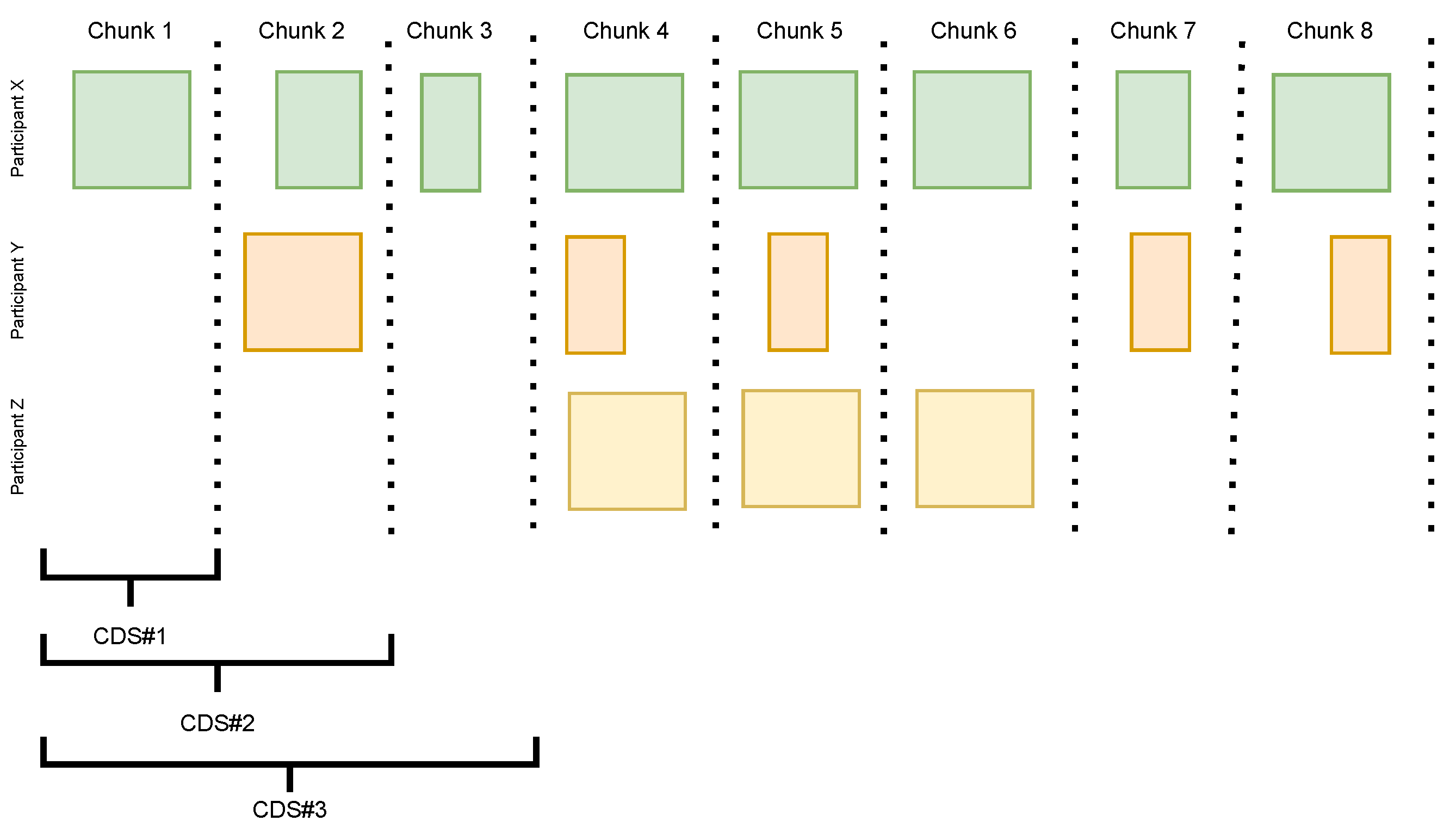
4.1.3. Splitting Data in Time-Ordered Chunks
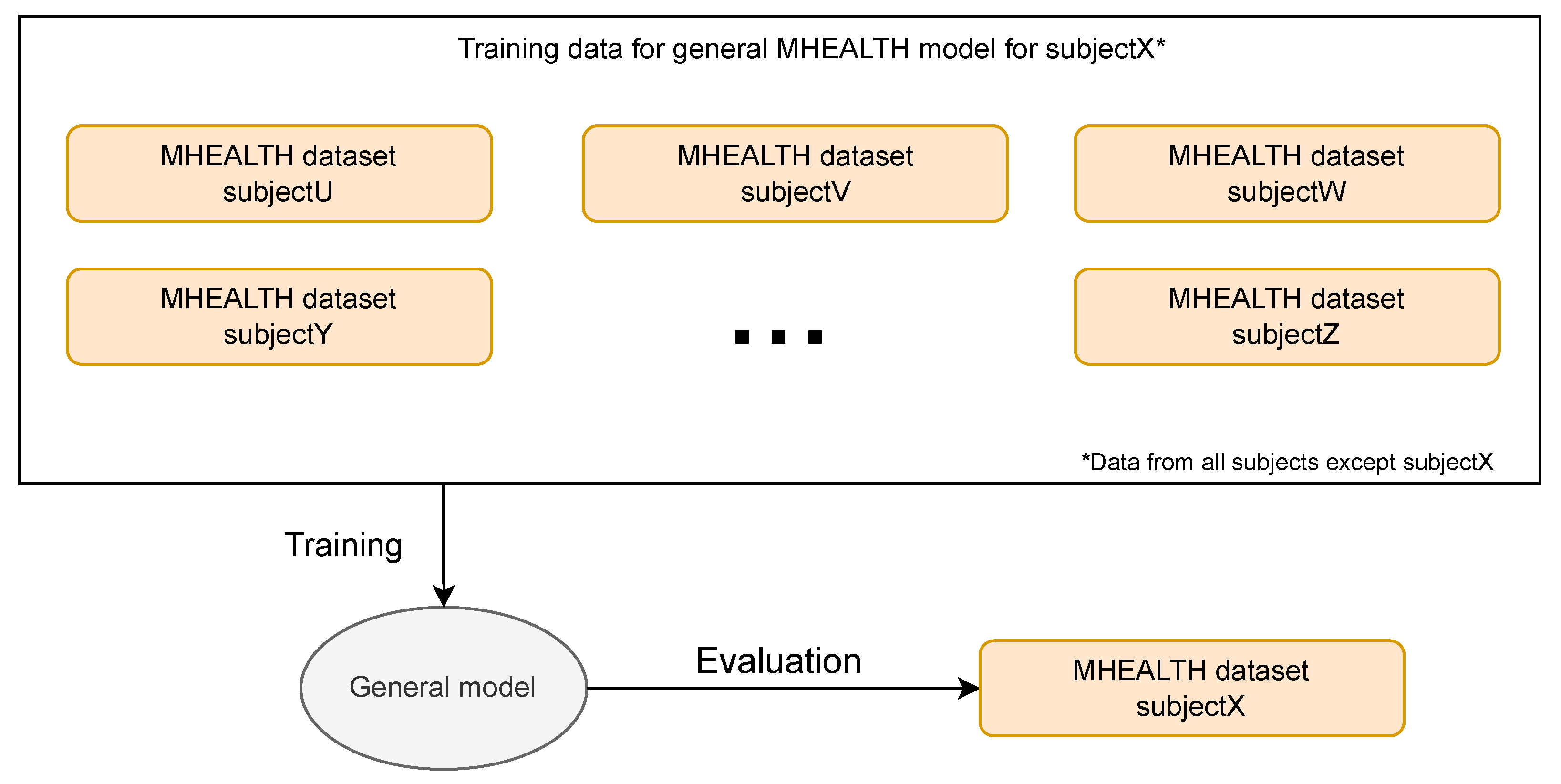
4.1.4. General Models
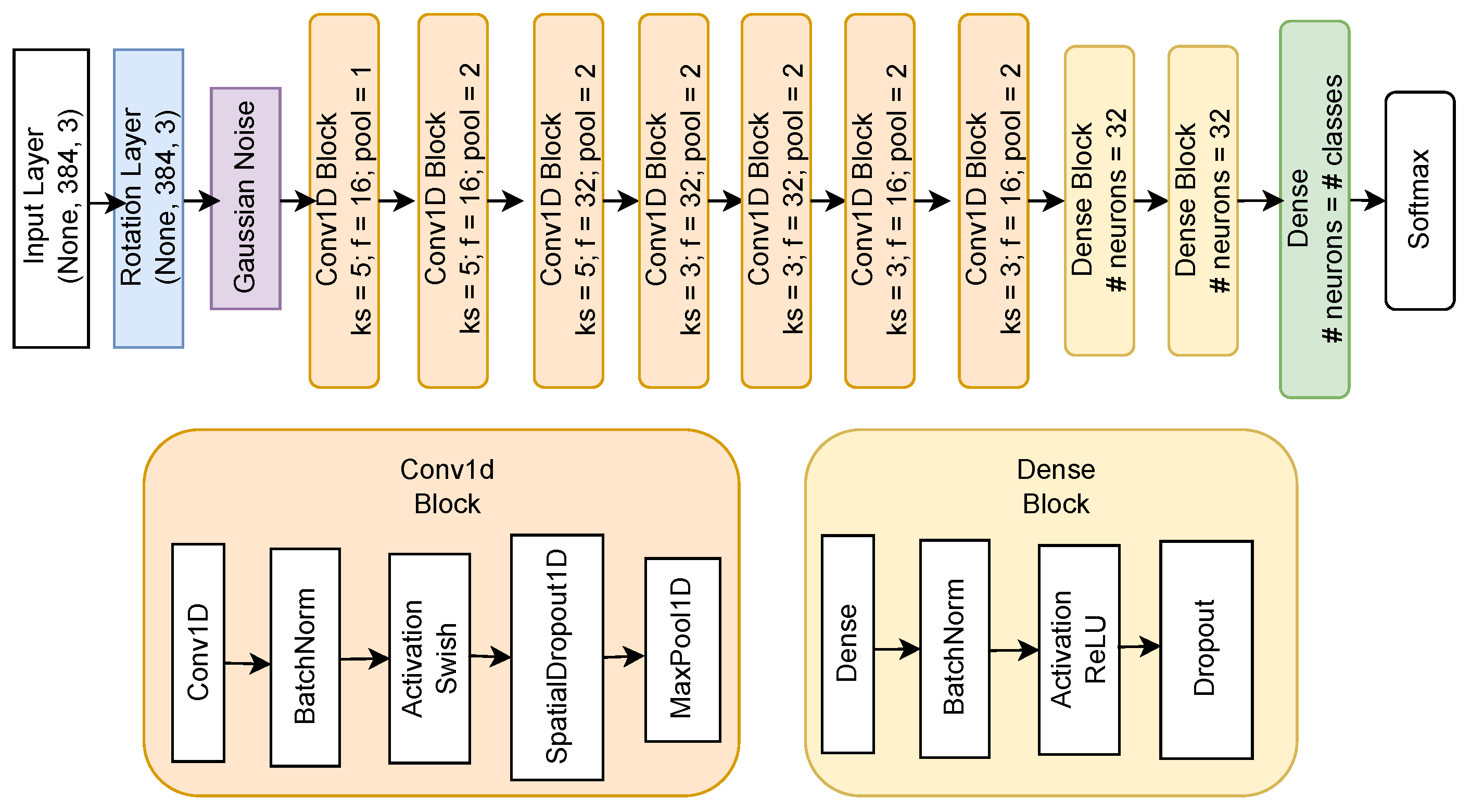
4.1.5. Architecture
4.2. General Models—Controlled MHEALTH Dataset
4.3. Personalization
5. Experiments and Results
- Can we use a single wrist-worn accelerometer for HAR in the real world?
- How does the predictive performance of the general models improve with the increase in the amount of training data?
- How much personal data do we need for the improvement of a general model (not trained on the same person)?
- How much data do we need for the general model to generalize so well that it makes little sense to personalize?
- How well do models trained on data collected in controlled environments perform in RW scenarios?
- Can the personalization of models trained on data collected in controlled environments with RW data lead to satisfying performance?
5.1. Evaluation Metrics
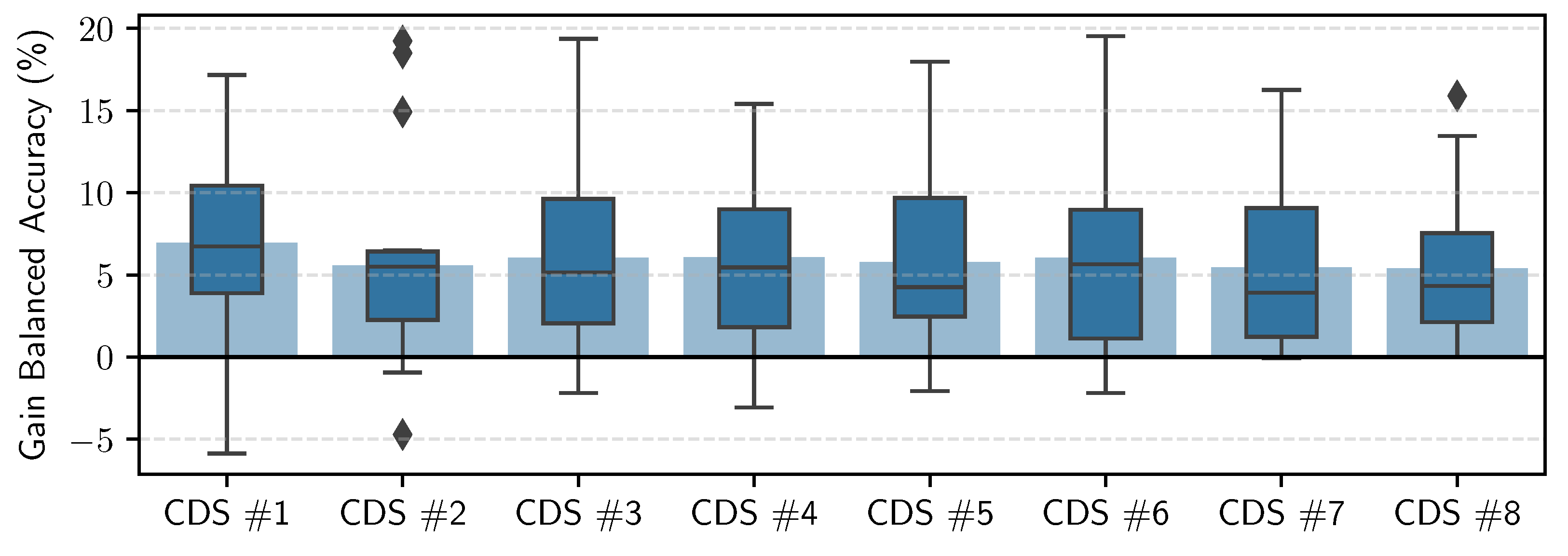
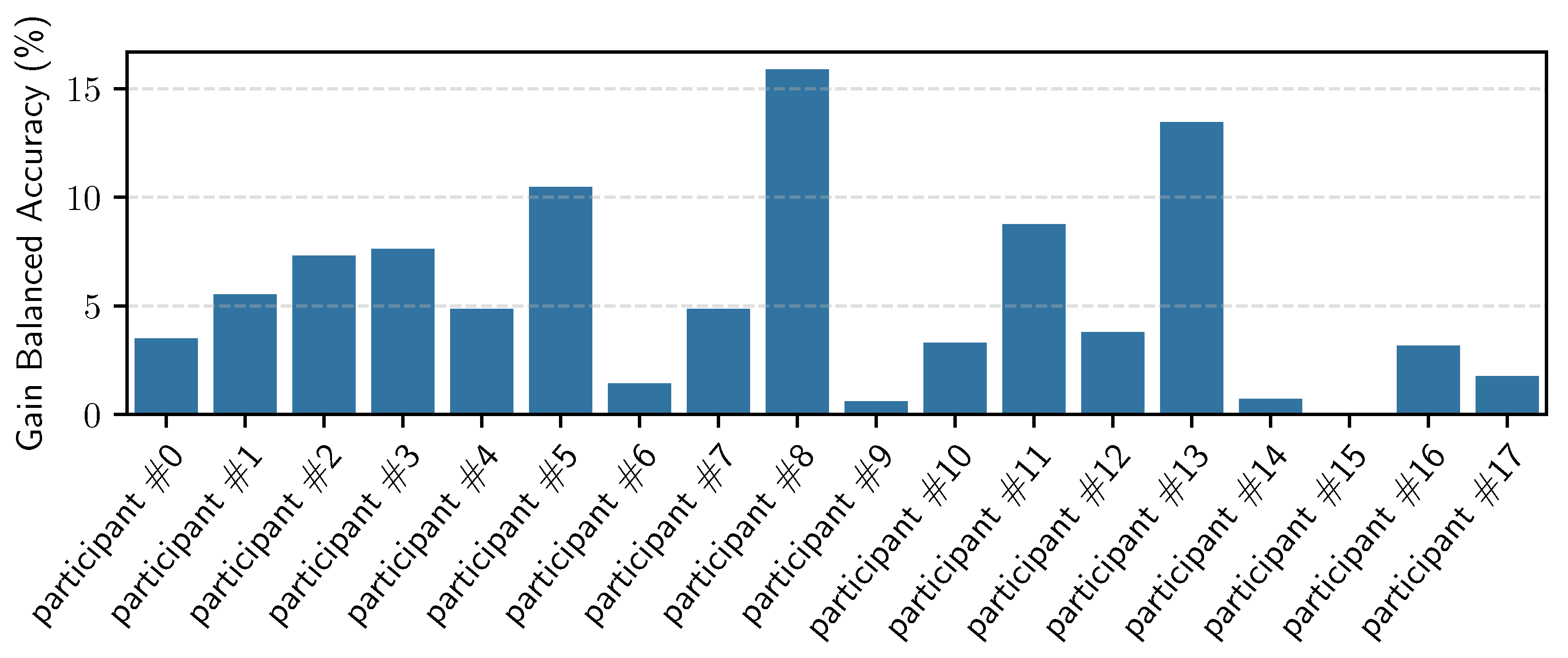
5.2. General Models—RW IDLab Dataset
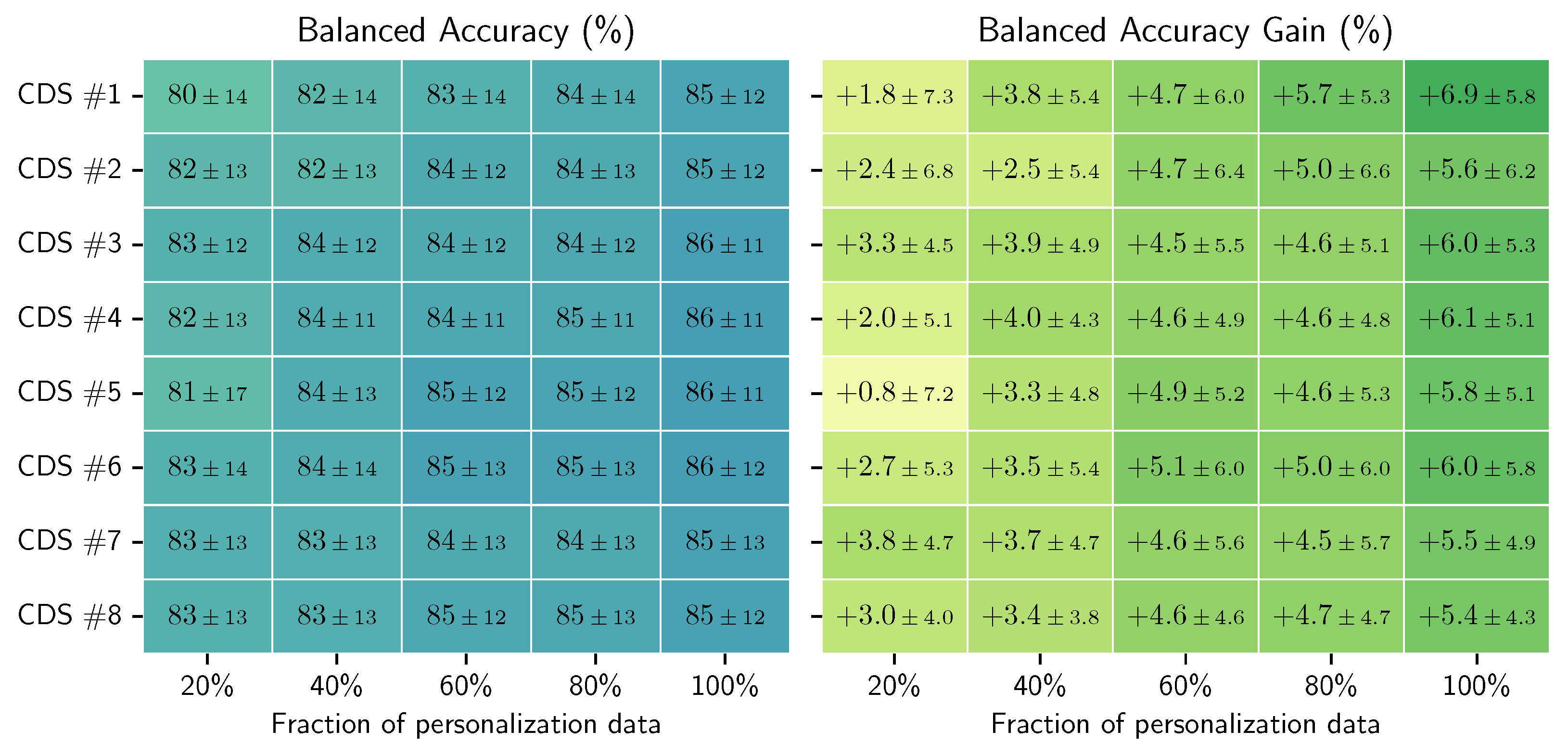
5.3. Personalization of the General RW Models
5.4. General Models—Controlled MHEALTH Dataset
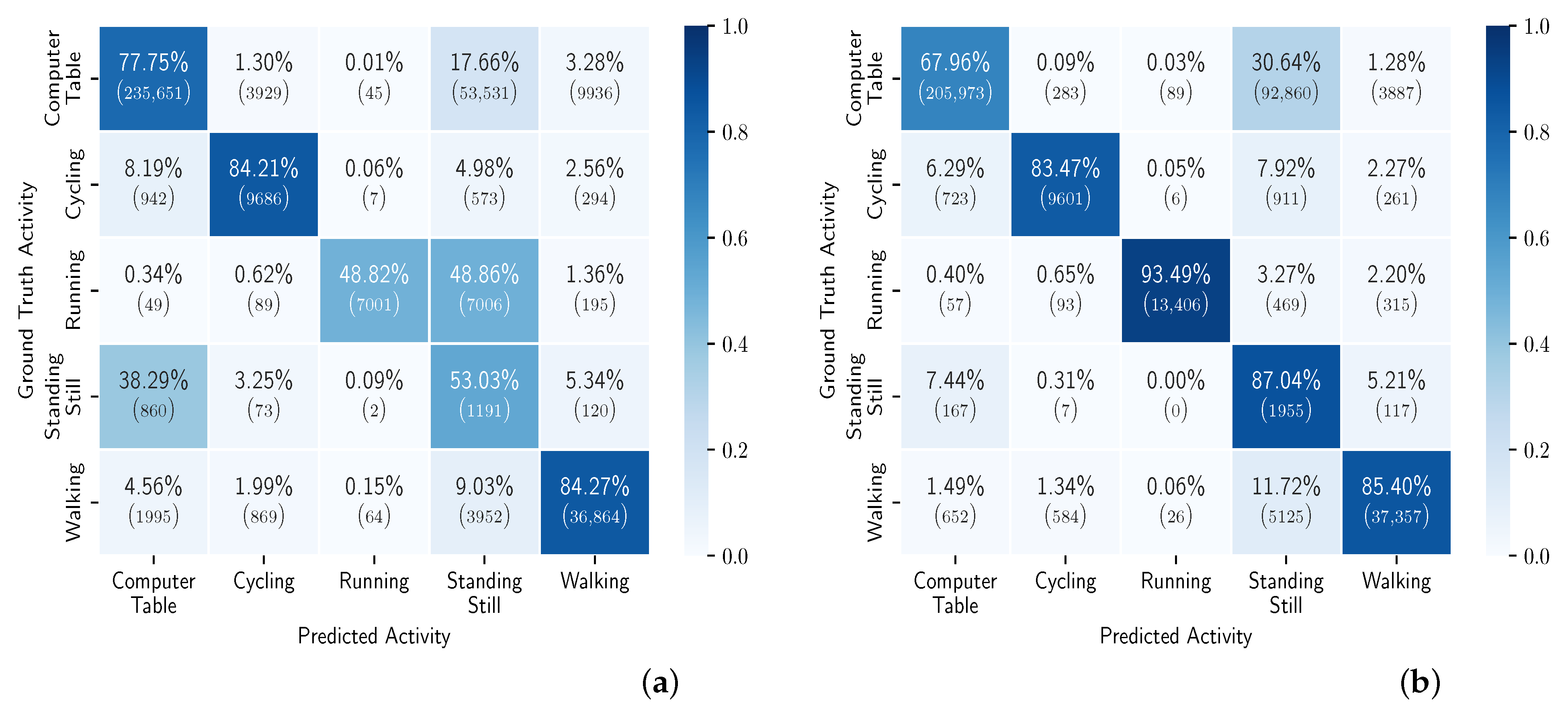
5.5. RW Data Versus Controlled Environment Data
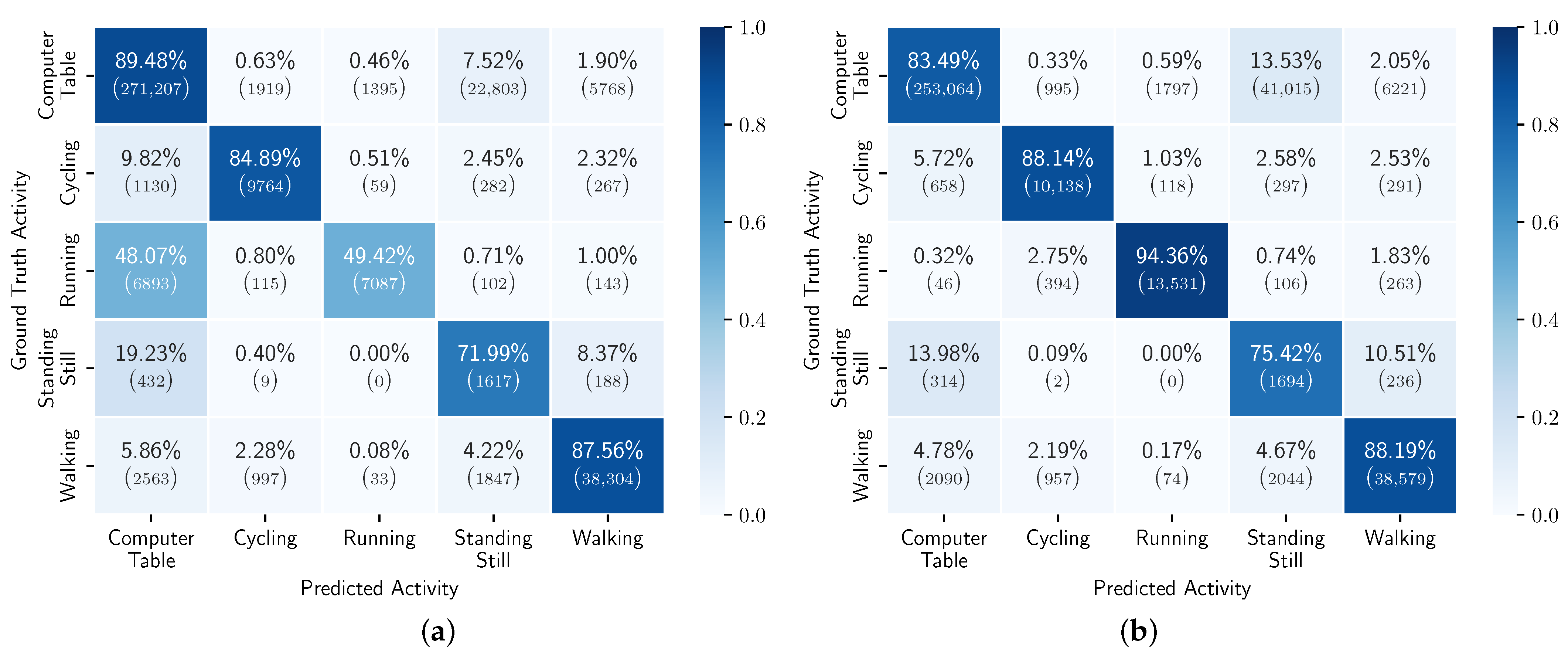
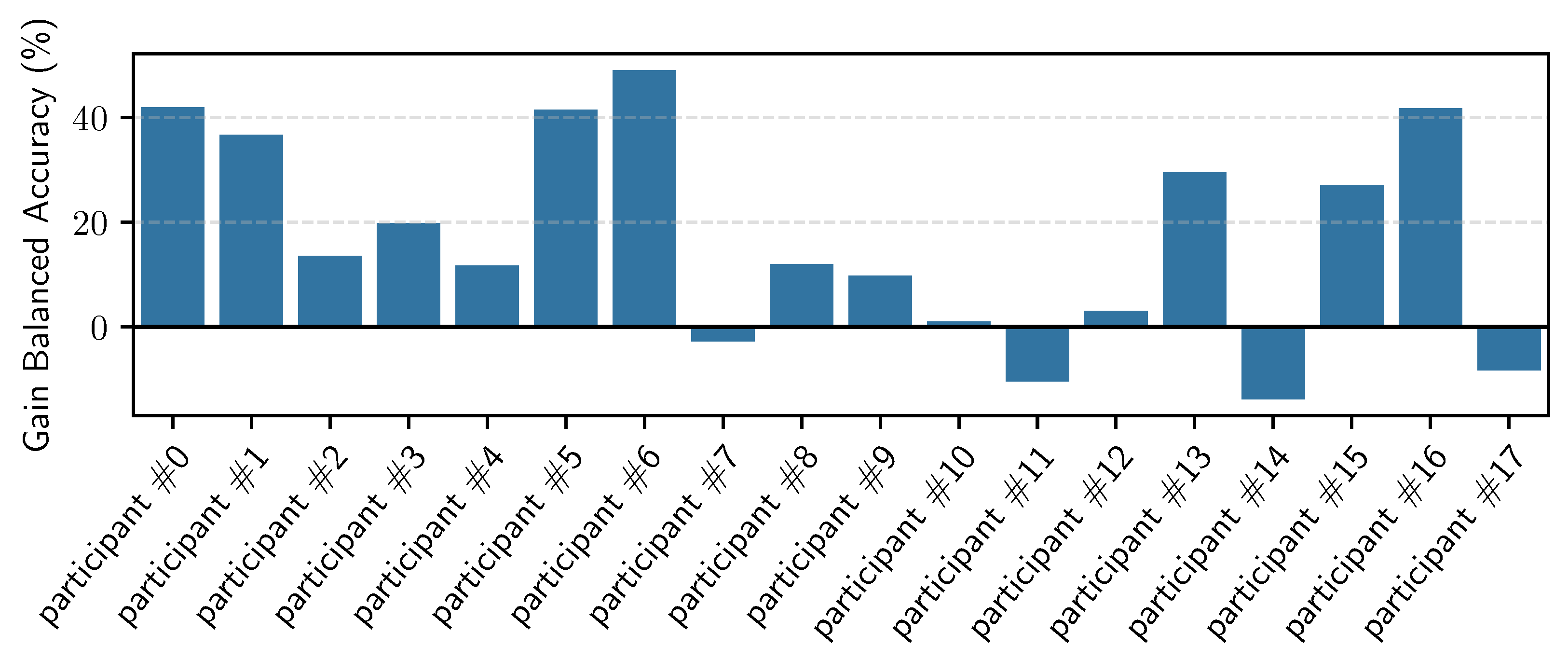
5.6. Personalizing MHEALTH Models with RW Data
6. Discussion
- Can we use a single wrist-worn accelerometer for HAR in the real world?
- How does the predictive performance of the general models improve with the increase in the amount of training data?
- How much personal data do we need for the improvement of a general model (not trained on this person)?
- How much data do we need for the general model to generalize so well so that it makes little sense to personalize?
- How well do models trained on data collected in controlled environments perform in RW scenarios?
- Can the personalization of models trained on data collected in controlled environments with RW data lead to a satisfying performance?
- Can personalization be used to learn new activities, that is, activities that were not present in the training of the general model but are present in the user-specific dataset?
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. CNN Model Architecture

Appendix B. Results of the General Models per CDS and MHEALTH for Each Participant

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.63 | 0.29 | 0.86 | 0.58 |
| CDS #2 | 0.71 | 0.34 | 0.90 | 0.40 |
| CDS #3 | 0.77 | 0.34 | 0.72 | 0.57 |
| CDS #4 | 0.80 | 0.32 | 0.69 | 0.55 |
| CDS #5 | 0.80 | 0.32 | 0.63 | 0.60 |
| CDS #6 | 0.80 | 0.33 | 0.71 | 0.55 |
| CDS #7 | 0.77 | 0.37 | 0.52 | 0.80 |
| CDS #8 | 0.76 | 0.30 | 0.54 | 0.80 |
| MHEALTH | 0.38 | 0.13 | 0.22 | 2.69 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.79 | 0.54 | 0.81 | 0.58 |
| CDS #2 | 0.81 | 0.57 | 0.89 | 0.35 |
| CDS #3 | 0.83 | 0.56 | 0.81 | 0.42 |
| CDS #4 | 0.81 | 0.56 | 0.80 | 0.44 |
| CDS #5 | 0.82 | 0.56 | 0.81 | 0.38 |
| CDS #6 | 0.85 | 0.56 | 0.80 | 0.46 |
| CDS #7 | 0.83 | 0.57 | 0.83 | 0.32 |
| CDS #8 | 0.82 | 0.56 | 0.81 | 0.40 |
| MHEALTH | 0.52 | 0.29 | 0.36 | 2.44 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.85 | 0.36 | 0.82 | 0.56 |
| CDS #2 | 0.89 | 0.37 | 0.87 | 0.39 |
| CDS #3 | 0.84 | 0.36 | 0.82 | 0.44 |
| CDS #4 | 0.84 | 0.44 | 0.80 | 0.50 |
| CDS #5 | 0.83 | 0.44 | 0.80 | 0.51 |
| CDS #6 | 0.81 | 0.43 | 0.76 | 0.59 |
| CDS #7 | 0.85 | 0.45 | 0.83 | 0.41 |
| CDS #8 | 0.86 | 0.45 | 0.83 | 0.37 |
| MHEALTH | 0.86 | 0.23 | 0.86 | 0.37 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.81 | 0.49 | 0.76 | 0.70 |
| CDS #2 | 0.82 | 0.52 | 0.80 | 0.49 |
| CDS #3 | 0.80 | 0.51 | 0.76 | 0.56 |
| CDS #4 | 0.80 | 0.50 | 0.74 | 0.59 |
| CDS #5 | 0.81 | 0.52 | 0.76 | 0.51 |
| CDS #6 | 0.80 | 0.52 | 0.77 | 0.51 |
| CDS #7 | 0.83 | 0.53 | 0.81 | 0.43 |
| CDS #8 | 0.81 | 0.52 | 0.78 | 0.46 |
| MHEALTH | 0.70 | 0.39 | 0.80 | 0.56 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.50 | 0.41 | 0.68 | 0.98 |
| CDS #2 | 0.52 | 0.42 | 0.74 | 0.79 |
| CDS #3 | 0.50 | 0.43 | 0.67 | 0.78 |
| CDS #4 | 0.49 | 0.41 | 0.59 | 0.90 |
| CDS #5 | 0.49 | 0.41 | 0.63 | 0.83 |
| CDS #6 | 0.48 | 0.42 | 0.63 | 0.76 |
| CDS #7 | 0.49 | 0.42 | 0.66 | 0.70 |
| CDS #8 | 0.51 | 0.42 | 0.68 | 0.69 |
| MHEALTH | 0.30 | 0.25 | 0.49 | 1.83 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.77 | 0.33 | 0.64 | 0.99 |
| CDS #2 | 0.81 | 0.43 | 0.77 | 0.60 |
| CDS #3 | 0.79 | 0.51 | 0.70 | 0.66 |
| CDS #4 | 0.78 | 0.46 | 0.64 | 0.75 |
| CDS #5 | 0.78 | 0.51 | 0.66 | 0.67 |
| CDS #6 | 0.78 | 0.43 | 0.68 | 0.65 |
| CDS #7 | 0.78 | 0.55 | 0.69 | 0.62 |
| CDS #8 | 0.78 | 0.45 | 0.67 | 0.61 |
| MHEALTH | 0.39 | 0.13 | 0.26 | 3.53 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.75 | 0.31 | 0.67 | 0.70 |
| CDS #2 | 0.82 | 0.39 | 0.79 | 0.46 |
| CDS #3 | 0.76 | 0.35 | 0.63 | 0.65 |
| CDS #4 | 0.78 | 0.36 | 0.68 | 0.60 |
| CDS #5 | 0.78 | 0.36 | 0.67 | 0.61 |
| CDS #6 | 0.78 | 0.36 | 0.64 | 0.73 |
| CDS #7 | 0.79 | 0.45 | 0.66 | 0.61 |
| CDS #8 | 0.79 | 0.36 | 0.66 | 0.61 |
| MHEALTH | 0.15 | 0.11 | 0.10 | 4.55 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.73 | 0.48 | 0.88 | 0.44 |
| CDS #2 | 0.63 | 0.44 | 0.59 | 0.81 |
| CDS #3 | 0.55 | 0.37 | 0.35 | 1.10 |
| CDS #4 | 0.62 | 0.41 | 0.51 | 0.91 |
| CDS #5 | 0.54 | 0.38 | 0.33 | 1.05 |
| CDS #6 | 0.54 | 0.36 | 0.34 | 1.11 |
| CDS #7 | 0.52 | 0.31 | 0.28 | 1.20 |
| CDS #8 | 0.58 | 0.38 | 0.41 | 1.02 |
| MHEALTH | 0.39 | 0.12 | 0.21 | 3.87 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.84 | 0.36 | 0.80 | 0.62 |
| CDS #2 | 0.80 | 0.35 | 0.84 | 0.44 |
| CDS #3 | 0.83 | 0.36 | 0.81 | 0.47 |
| CDS #4 | 0.81 | 0.36 | 0.77 | 0.53 |
| CDS #5 | 0.82 | 0.36 | 0.80 | 0.44 |
| CDS #6 | 0.77 | 0.43 | 0.79 | 0.49 |
| CDS #7 | 0.83 | 0.45 | 0.86 | 0.41 |
| CDS #8 | 0.79 | 0.44 | 0.81 | 0.40 |
| MHEALTH | 0.88 | 0.31 | 0.88 | 0.51 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.90 | 0.56 | 0.94 | 0.23 |
| CDS #2 | 0.91 | 0.56 | 0.95 | 0.20 |
| CDS #3 | 0.92 | 0.57 | 0.95 | 0.21 |
| CDS #4 | 0.92 | 0.57 | 0.94 | 0.21 |
| CDS #5 | 0.91 | 0.57 | 0.94 | 0.22 |
| CDS #6 | 0.93 | 0.57 | 0.95 | 0.21 |
| CDS #7 | 0.92 | 0.57 | 0.95 | 0.21 |
| CDS #8 | 0.92 | 0.57 | 0.94 | 0.21 |
| MHEALTH | 0.81 | 0.60 | 0.90 | 0.29 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.90 | 0.53 | 0.90 | 0.43 |
| CDS #2 | 0.93 | 0.55 | 0.93 | 0.39 |
| CDS #3 | 0.92 | 0.55 | 0.92 | 0.33 |
| CDS #4 | 0.93 | 0.55 | 0.93 | 0.32 |
| CDS #5 | 0.92 | 0.54 | 0.92 | 0.31 |
| CDS #6 | 0.92 | 0.54 | 0.92 | 0.35 |
| CDS #7 | 0.92 | 0.55 | 0.92 | 0.31 |
| CDS #8 | 0.92 | 0.54 | 0.92 | 0.34 |
| MHEALTH | 0.91 | 0.67 | 0.92 | 0.37 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.79 | 0.48 | 0.93 | 0.30 |
| CDS #2 | 0.76 | 0.47 | 0.92 | 0.26 |
| CDS #3 | 0.93 | 0.50 | 0.95 | 0.19 |
| CDS #4 | 0.94 | 0.51 | 0.95 | 0.18 |
| CDS #5 | 0.92 | 0.51 | 0.95 | 0.23 |
| CDS #6 | 0.91 | 0.63 | 0.95 | 0.20 |
| CDS #7 | 0.81 | 0.60 | 0.94 | 0.21 |
| CDS #8 | 0.86 | 0.49 | 0.94 | 0.22 |
| MHEALTH | 0.89 | 0.49 | 0.84 | 0.70 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.96 | 0.49 | 0.96 | 0.22 |
| CDS #2 | 0.91 | 0.47 | 0.91 | 0.29 |
| CDS #3 | 0.93 | 0.38 | 0.93 | 0.25 |
| CDS #4 | 0.92 | 0.47 | 0.92 | 0.27 |
| CDS #5 | 0.92 | 0.47 | 0.92 | 0.30 |
| CDS #6 | 0.90 | 0.47 | 0.91 | 0.31 |
| CDS #7 | 0.93 | 0.48 | 0.93 | 0.26 |
| CDS #8 | 0.90 | 0.47 | 0.90 | 0.32 |
| MHEALTH | 0.70 | 0.39 | 0.70 | 1.70 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.83 | 0.69 | 0.87 | 0.63 |
| CDS #2 | 0.72 | 0.58 | 0.79 | 0.54 |
| CDS #3 | 0.75 | 0.66 | 0.72 | 0.69 |
| CDS #4 | 0.69 | 0.62 | 0.76 | 0.63 |
| CDS #5 | 0.74 | 0.66 | 0.80 | 0.47 |
| CDS #6 | 0.72 | 0.65 | 0.78 | 0.55 |
| CDS #7 | 0.69 | 0.63 | 0.77 | 0.60 |
| CDS #8 | 0.70 | 0.63 | 0.78 | 0.55 |
| MHEALTH | 0.66 | 0.44 | 0.68 | 0.98 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.53 | 0.55 | 0.66 | 1.87 |
| CDS #2 | 0.74 | 0.75 | 0.89 | 0.51 |
| CDS #3 | 0.76 | 0.76 | 0.89 | 0.38 |
| CDS #4 | 0.77 | 0.77 | 0.89 | 0.32 |
| CDS #5 | 0.85 | 0.80 | 0.91 | 0.25 |
| CDS #6 | 0.94 | 0.83 | 0.93 | 0.25 |
| CDS #7 | 0.92 | 0.83 | 0.93 | 0.20 |
| CDS #8 | 0.93 | 0.83 | 0.92 | 0.23 |
| MHEALTH | 0.93 | 0.83 | 0.93 | 0.24 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.93 | 0.64 | 0.93 | 0.21 |
| CDS #2 | 0.99 | 0.66 | 0.99 | 0.10 |
| CDS #3 | 1.00 | 1.00 | 1.00 | 0.03 |
| CDS #4 | 1.00 | 1.00 | 1.00 | 0.03 |
| CDS #5 | 1.00 | 1.00 | 1.00 | 0.02 |
| CDS #6 | 1.00 | 1.00 | 1.00 | 0.03 |
| CDS #7 | 1.00 | 1.00 | 1.00 | 0.02 |
| CDS #8 | 1.00 | 1.00 | 1.00 | 0.05 |
| MHEALTH | 0.73 | 0.41 | 0.76 | 0.42 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.76 | 0.34 | 0.88 | 0.53 |
| CDS #2 | 0.72 | 0.30 | 0.55 | 0.85 |
| CDS #3 | 0.73 | 0.32 | 0.63 | 0.61 |
| CDS #4 | 0.74 | 0.42 | 0.73 | 0.56 |
| CDS #5 | 0.72 | 0.39 | 0.62 | 0.69 |
| CDS #6 | 0.72 | 0.39 | 0.61 | 0.69 |
| CDS #7 | 0.70 | 0.40 | 0.66 | 0.60 |
| CDS #8 | 0.71 | 0.40 | 0.64 | 0.64 |
| MHEALTH | 0.23 | 0.07 | 0.07 | 4.02 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | 0.82 | 0.59 | 0.84 | 0.56 |
| CDS #2 | 0.80 | 0.57 | 0.89 | 0.45 |
| CDS #3 | 0.76 | 0.53 | 0.81 | 0.51 |
| CDS #4 | 0.76 | 0.42 | 0.75 | 0.64 |
| CDS #5 | 0.79 | 0.45 | 0.76 | 0.66 |
| CDS #6 | 0.80 | 0.58 | 0.86 | 0.45 |
| CDS #7 | 0.77 | 0.54 | 0.81 | 0.45 |
| CDS #8 | 0.78 | 0.57 | 0.85 | 0.42 |
| MHEALTH | 0.77 | 0.39 | 0.66 | 0.74 |
References
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Bouchabou, D.; Nguyen, S.M.; Lohr, C.; LeDuc, B.; Kanellos, I. A Survey of Human Activity Recognition in Smart Homes Based on IoT Sensors Algorithms: Taxonomies, Challenges, and Opportunities with Deep Learning. Sensors 2021, 21, 6037. [Google Scholar] [CrossRef] [PubMed]
- Steenwinckel, B.; De Brouwer, M.; Stojchevska, M.; De Turck, F.; Van Hoecke, S.; Ongenae, F. TALK: Tracking Activities by Linking Knowledge. Eng. Appl. Artif. Intell. 2023, 122, 106076. [Google Scholar] [CrossRef]
- Attal, F.; Mohammed, S.; Dedabrishvili, M.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. Physical Human Activity Recognition Using Wearable Sensors. Sensors 2015, 15, 31314–31338. [Google Scholar] [CrossRef] [PubMed]
- Scheurer, S.; Tedesco, S.; Brown, K.N.; O’Flynn, B. Human activity recognition for emergency first responders via body-worn inertial sensors. In Proceedings of the 2017 IEEE 14th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Eindhoven, The Netherlands, 9–12 May 2017; pp. 5–8. [Google Scholar] [CrossRef]
- Yen, C.T.; Liao, J.X.; Huang, Y.K. Human daily activity recognition performed using wearable inertial sensors combined with deep learning algorithms. IEEE Access 2020, 8, 174105–174114. [Google Scholar] [CrossRef]
- Ha, S.; Choi, S. Convolutional neural networks for human activity recognition using multiple accelerometer and gyroscope sensors. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; Volume 2016, pp. 381–388. [Google Scholar] [CrossRef]
- Yang, J.B.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. IJCAI 2015, 15, 3995–4001. [Google Scholar]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN Architecture for Human Activity Recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Mihoub, A. A Deep Learning-Based Framework for Human Activity Recognition in Smart Homes. Mob. Inf. Syst. 2021, 2021. [Google Scholar] [CrossRef]
- Oyedotun, O.K.; Khashman, A. Deep learning in vision-based static hand gesture recognition. Neural Comput. Appl. 2017, 28, 1–11. [Google Scholar] [CrossRef]
- Neethu, P.S.; Suguna, R.; Sathish, D. An efficient method for human hand gesture detection and recognition using deep learning convolutional neural networks. Soft Comput. 2020, 24, 15239–15248. [Google Scholar] [CrossRef]
- Kim, J.H.; Hong, G.S.; Kim, B.G.; Dogra, D.P. deepGesture: Deep learning-based gesture recognition scheme using motion sensors. Displays 2018, 55, 38–45. [Google Scholar] [CrossRef]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS), IEEE, Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar] [CrossRef]
- Weiss, G.M.; Yoneda, K.; Hayajneh, T. Smartphone and Smartwatch-Based Biometrics Using Activities of Daily Living. IEEE Access 2019, 7, 133190–133202. [Google Scholar] [CrossRef]
- Zhang, M.; Sawchuk, A.A. USC-HAD: A daily activity dataset for ubiquitous activity recognition using wearable sensors. In Proceedings of the, Pittsburgh, Pennsylvania, 5–8 September 2012; pp. 1036–1043. [Google Scholar]
- Mannini, A.; Intille, S.S. Classifier Personalization for Activity Recognition Using Wrist Accelerometers. IEEE J. Biomed. Health Inform. 2019, 23, 1585–1594. [Google Scholar] [CrossRef] [PubMed]
- Siirtola, P.; Röning, J. Incremental learning to personalize human activity recognition models: The importance of human AI collaboration. Sensors 2019, 19, 5151. [Google Scholar] [CrossRef] [PubMed]
- Mazankiewicz, A.; Berges, M. Incremental Real-Time Personalization in Human Activity Recognition Using Domain Adaptive Batch Normalization. Proc. Acm Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–20. [Google Scholar] [CrossRef]
- Rokni, S.A.; Nourollahi, M.; Ghasemzadeh, H. Personalized Human Activity Recognition Using Convolutional Neural Networks. Proc. Aaai Conf. Artif. Intell. 2018, 31, 1. [Google Scholar] [CrossRef]
- Zhuang, Z.; Xue, Y. Sport-related human activity detection and recognition using a smartwatch. Sensors 2019, 19, 5001. [Google Scholar] [CrossRef]
- Hsu, Y.L.; Yang, S.C.; Chang, H.C.; Lai, H.C. Human Daily and Sport Activity Recognition Using a Wearable Inertial Sensor Network. IEEE Access 2018, 6, 31715–31728. [Google Scholar] [CrossRef]
- Casale, P.; Pujol, O.; Radeva, P. Human activity recognition from accelerometer data using a wearable device. In Pattern Recognition and Image Analysis: 5th Iberian Conference, IbPRIA 2011, Proceedings 5, Las Palmas de Gran Canaria, Spain, 8–10 June 2011; Springer: Berlin Heidelberg, Germany, 2011; Volume 6669, pp. 289–296. [Google Scholar] [CrossRef]
- Alessandrini, M.; Biagetti, G.; Crippa, P.; Falaschetti, L.; Turchetti, C. Recurrent neural network for human activity recognition in embedded systems using ppg and accelerometer data. Electronics 2021, 10, 1715. [Google Scholar] [CrossRef]
- Challa, S.K.; Kumar, A.; Semwal, V.B. A multibranch CNN-BiLSTM model for human activity recognition using wearable sensor data. Vis. Comput. 2021, 38, 4095–4109. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Cruciani, F.; Vafeiadis, A.; Nugent, C.; Cleland, I.; McCullagh, P.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R. Comparing CNN and human crafted features for human activity recognition. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Leicester, UK, 19–23 August 2019. [Google Scholar] [CrossRef]
- Matic, N.; Guyon, I.; Denker, J.; Vapnik, V. Writer-adaptation for on-line handwritten character recognition. In Proceedings of the 2nd International Conference on Document Analysis and Recognition (ICDAR’93), Tsukuba, Japan, 20–22 October 1993; pp. 187–191. [Google Scholar] [CrossRef]
- Siirtola, P.; Röning, J. Context-aware incremental learning-based method for personalized human activity recognition. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 213–239. [Google Scholar] [CrossRef]
- Cruciani, F.; Nugent, C.D.; Quero, J.M.; Cleland, I.; McCullagh, P.; Synnes, K.; Hallberg, J. Personalizing activity recognition with a clustering based semi-population approach. IEEE Access 2020, 8, 207794–207804. [Google Scholar] [CrossRef]
- Amrani, H.; Micucci, D.; Napoletano, P. Personalized models in human activity recognition using deep learning. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), IEEE, Milan, Italy, 10–15 January 2020; pp. 9682–9688. [Google Scholar] [CrossRef]
- Ferrari, A.; Micucci, D.; Mobilio, M.; Napoletano, P. Deep learning and model personalization in sensor-based human activity recognition. J. Reliab. Intell. Environ. 2022, 1–13. [Google Scholar] [CrossRef]
- Vaizman, Y.; Ellis, K.; Lanckriet, G. Recognizing detailed human context in the wild from smartphones and smartwatches. IEEE Pervasive Comput. 2017, 16, 62–74. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep Learning in Human Activity Recognition withWearable Sensors: A Review on Advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. ESANN 2013, 3, 3. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; IEEE: Washington, DC, USA; pp. 108–109. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; Volume 2015, pp. 168–172. [Google Scholar] [CrossRef]
- Banos, O.; Garcia, R.; Holgado-Terriza, J.A.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid: A novel framework for agile development of mobile health applications. In Ambient Assisted Living and Daily Activities, Proceedings of the 6th International Work-Conference, IWAAL 2014, Belfast, UK, 2–5 December 2014, Proceedings 6; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; Volume 8868, pp. 91–98. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q.V. Swish: A Self-Gated Activation Function. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Workshop Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–932. [Google Scholar] [CrossRef]
- Bengio, Y.; Bastien, F.; Bergeron, A.; Boulanger-Lewandowski, N.; Breuel, T.; Chherawala, Y.; Cisse, M.; Côté, M.; Erhan, D.; Eustache, J.; et al. Deep learners benefit more from out-of-distribution examples. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 164–172. [Google Scholar]

















| Dataset | #S | Devices | #Activities | Labeling Procedure | Env. and Exec. |
|---|---|---|---|---|---|
| OPPORTUNITY | 12 | body, object, and ambient sensors | 13 actions, 17 gestures, 5 activities | VR/VI | C and P |
| UCI-HAR | 30 | smartphones | 8 activities | OE | C and P |
| PAMAP2 | 9 | body sensors | 12 activities | OE | C and P |
| WISDM | 51 | smartphones, smartwatches | 18 activities | OE | C and P |
| UTD-MHAD | 8 | camera, body sensors | 27 actions | VR/VI | C and P |
| USC-HAD | 14 | body sensor | 12 activities | OE | C and P |
| MHEALTH | 10 | body sensors | 12 activities | OE | C and P |
| ExtraSensory | 60 | smartphones, smartwatches | 103 activities (51 after cleaning) | SR | UC and F |
| IDLab | 18 | smartphones, smartwatches | 26 activities | SR | UC and F |
| Activity | Labeled Duration | Sensor Duration | Number of Labels |
|---|---|---|---|
| Computer Table | 23 days 8 h 56 m 38 s | 18 days 15 h 22 m 10 s | 579 |
| Walking | 3 days 7 h 42 m 30 s | 2 days 15 h 05 m 00 s | 328 |
| Running | 1 day 4 h 53 m 42 s | 21 h 17 m 15 s | 122 |
| Cycling | 1 day 1 h 20 m 03 s | 18 h 08 m 30 s | 59 |
| Standing Still | 6 h 23 m 41 s | 4 h 25 m 35 s | 55 |
| Personalization Set | Hold-Out Set | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Participant | Computer Table | Cycling | Running | Standing Still | Walking | Computer Table | Cycling | Running | Standing Still | Walking |
| 0 | 1195 | 0 | 0 | 49 | 99 | 28,689 | 0 | 0 | 113 | 965 |
| 1 | 1197 | 97 | 99 | 47 | 0 | 39,462 | 2367 | 1021 | 100 | 0 |
| 2 | 1194 | 0 | 0 | 0 | 99 | 7716 | 0 | 0 | 0 | 2880 |
| 3 | 1186 | 97 | 0 | 0 | 99 | 33,412 | 1446 | 0 | 0 | 8533 |
| 4 | 1197 | 99 | 99 | 0 | 95 | 9954 | 1541 | 118 | 0 | 516 |
| 5 | 1194 | 99 | 0 | 0 | 96 | 45,472 | 274 | 0 | 0 | 2094 |
| 6 | 1194 | 0 | 0 | 47 | 99 | 32,827 | 0 | 0 | 1115 | 3382 |
| 7 | 1190 | 99 | 0 | 47 | 98 | 22,447 | 1106 | 0 | 55 | 4383 |
| 8 | 1196 | 99 | 0 | 0 | 0 | 6386 | 468 | 0 | 0 | 0 |
| 9 | 0 | 97 | 99 | 0 | 99 | 0 | 171 | 4036 | 0 | 2427 |
| 10 | 0 | 94 | 99 | 0 | 99 | 0 | 344 | 643 | 0 | 166 |
| 11 | 0 | 98 | 0 | 48 | 98 | 0 | 288 | 0 | 140 | 3539 |
| 12 | 0 | 0 | 99 | 0 | 99 | 0 | 0 | 273 | 0 | 264 |
| 13 | 1195 | 99 | 99 | 0 | 98 | 5062 | 172 | 1176 | 0 | 1775 |
| 14 | 1199 | 97 | 99 | 49 | 98 | 15,206 | 2998 | 6998 | 569 | 10,140 |
| 15 | 0 | 0 | 99 | 0 | 95 | 0 | 0 | 75 | 0 | 61 |
| 16 | 1194 | 0 | 0 | 49 | 99 | 41,695 | 0 | 0 | 154 | 1638 |
| 17 | 1195 | 96 | 0 | 0 | 99 | 14,764 | 327 | 0 | 0 | 981 |
| CDS | Computer Table | Cycling | Running | Standing Still | Walking |
|---|---|---|---|---|---|
| #1 | 18,508 | 1290 | 2469 | 546 | 5253 |
| #2 | 31,349 | 2079 | 3083 | 738 | 13,789 |
| #3 | 34,010 | 2830 | 4301 | 1420 | 21,607 |
| #4 | 54,447 | 3898 | 7509 | 1786 | 24,899 |
| #5 | 127,397 | 4733 | 10,169 | 1951 | 31,159 |
| #6 | 195,769 | 6227 | 11,077 | 2111 | 34,586 |
| #7 | 275,343 | 11,525 | 13,677 | 2250 | 40,461 |
| #8 | 318,618 | 12,673 | 15,132 | 2582 | 45,313 |
| CDS | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| #1 | ||||
| #2 | ||||
| #3 | ||||
| #4 | ||||
| #5 | ||||
| #6 | ||||
| #7 | ||||
| #8 |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | ||||
| CDS #2 | ||||
| CDS #3 | ||||
| CDS #4 | ||||
| CDS #5 | ||||
| CDS #6 | ||||
| CDS #7 | ||||
| CDS #8 | ||||
| MHEALTH |
| Training Data | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| CDS #1 | ||||
| CDS #2 | ||||
| CDS #3 | ||||
| CDS #4 | ||||
| CDS #5 | ||||
| CDS #6 | ||||
| CDS #7 | ||||
| CDS #8 | ||||
| MHEALTH |
| Fraction Personalization | Balanced Accuracy | F1-Macro | F1-Micro | Logloss |
|---|---|---|---|---|
| 0% | ||||
| 20% | ||||
| 40% | ||||
| 60% | ||||
| 80% | ||||
| 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stojchevska, M.; De Brouwer, M.; Courteaux, M.; Ongenae, F.; Van Hoecke, S. From Lab to Real World: Assessing the Effectiveness of Human Activity Recognition and Optimization through Personalization. Sensors 2023, 23, 4606. https://doi.org/10.3390/s23104606
Stojchevska M, De Brouwer M, Courteaux M, Ongenae F, Van Hoecke S. From Lab to Real World: Assessing the Effectiveness of Human Activity Recognition and Optimization through Personalization. Sensors. 2023; 23(10):4606. https://doi.org/10.3390/s23104606
Chicago/Turabian StyleStojchevska, Marija, Mathias De Brouwer, Martijn Courteaux, Femke Ongenae, and Sofie Van Hoecke. 2023. "From Lab to Real World: Assessing the Effectiveness of Human Activity Recognition and Optimization through Personalization" Sensors 23, no. 10: 4606. https://doi.org/10.3390/s23104606