1. Introduction
In the past decade, solar PV energy, as a clean energy source, has gained considerable attention and has been developed greatly worldwide due to the increasing problems of environmental pollution and the energy crisis [
1]. Currently, as a key renewable energy generation technology, PV power generation has achieved rapid development and has become a clean, low-carbon form of energy with great price competitiveness in many countries. The International Energy Agency (IEA) reports that from 2010 to 2021, global PV capacity increased from 17 GWdc to 172 GWdc, and by 2021, global PV installations increased by 19% annually, with the total cumulative installed PV capacity reaching at least 939 GWdc [
2]. In particular, China’s solar energy consumption is expected to reach 33.0 Mtoe by 2023 [
3]. However, the optimization, improvement and operating costs of PV power plants limit the long-term healthy development of the entire PV industry, of which PV cell defect detection has become a prominent problem.
In fact, the production, processing and application of PV cell modules will produce various types of defects. As shown in
Figure 1, contamination during the manufacturing process for PV cells can result in issues including dark cells, broken grids, fractures, lobes and chipped corners; in addition, PV cells may have hot spots and short circuits in operation [
4]. Various defects in PV cells can lead to lower photovoltaic conversion efficiency and reduced service life and can even short circuit boards, which pose safety hazard risks [
5]. As a result, PV cell defect detection research offers a crucial assurance for raising the caliber of PV products while lowering production costs.
To detect defects on the surface of PV cells, researchers have proposed methods such as electrical characterization [
6], electroluminescence imaging [
7,
8,
9], infrared (IR) imaging [
10], etc. EL imaging is frequently utilized in solar cell surface detection studies because it is rapid, non-destructive, simpler and more practical to integrate into actual manufacturing processes [
11]. EL imaging is mainly based on the electroluminescence principle of silicon materials for detection. By adding forward bias to a crystalline silicon cell module, the module will emit light of a certain wavelength, and a charge-coupled device image sensor can capture the light in this wavelength range and image it [
12]. In order to improve the quality and efficiency of PV defect detection and promote the sustainable development of the PV industry and new energy applications, the use of cutting-edge computer technology to automatically perform the intelligent detection of defects is a necessary technical means. With the gradual deepening and improvement of image analysis technology and deep learning technology, the combination of computer vision technology and surface defect detection is becoming more and more closely applied.
In many fields, including computer vision and speech recognition [
13], deep learning has achieved considerable success since it was first introduced by Hinton’s research team [
14]. Deep learning methods far outperform traditional image processing algorithms in terms of accuracy and performance for tasks such as target detection and image recognition. In 2012, deep learning techniques made a large impact in machine vision, are widely used in various industrial scenarios and have become the mainstream methods for defect detection, e.g., AlexNet [
15], VGG [
16], GoogLeNet [
17], ResNet [
18], DenseNet [
19], MobileNet [
20], YOLO [
21], etc. Defect detection methods based on deep learning technology with high accuracy and no damage can satisfy the needs of industrial application sites.
Deep learning methods have steadily been applied to industrial defect detection studies in recent years, and many scholars have studied the automatic detection of PV cell defects based on EL imaging methods. Deitsch et al. [
22] proposed two deep-learning-based methods for the automatic detection of PV cell defects with convolutional neural networks (CNNs) and SVMs; the results showed that CNN classifier detection has higher accuracy. Rahman et al. [
23] proposed CNN architecture and CNN integration; integrated learning not only improves accuracy but also reduces the risk of relying on a single model. However, when the CNN level is too deep, using BP propagation to modify the parameters will change the parameters near the input layer more slowly. Using the gradient descent algorithm will easily make the training results converge to the local minimum instead of the global minimum, and the pooling layer will lose a lot of valuable information and ignore the correlation between the local and the whole. A deep-learning-based defect diagnosis model was proposed, and a Hessian-matrix-based defect feature extraction method and a multi-scale line detector-based defect feature enhancement method were used to improve the performance, achieving a classification accuracy of 93% [
24]. Akram et al. [
25] proposed a new method for identifying EL image defects using an optical CNN structure, combining data enhancement and regularization strategies to expand the training dataset; the model achieved a classification accuracy of 93.02% and consumed less computational power and time. Huang et al. [
26] proposed a multi-round PSOPruner to automatically search for the optimal DCNN pruning scheme, which deployed the PSO algorithm as a search engine while employing a multi-round trick to speed up and simplify the search process. Wang et al. [
27] proposed a lightweight dual-stream defect detection network (DDDN) with a classification accuracy of 88.26%, accelerated using a field-programmable gate array (FPGA) based on a developed dual-stream parallel computing architecture (DPCA). Researchers have continued to improve on a single deep learning model to optimize the training process and reduce computational consumption time; however, model training relies on a large number of training datasets to ensure a balanced distribution of different types of data. In recent years, migration learning has shown satisfactory results with limited training datasets and on smaller, more practical datasets. Demirci et al. [
28] proposed a defect detection model based on migration learning. It showed good results in processing EL images with simple backgrounds; however, the accuracy decreased significantly in complex backgrounds. Tang et al. [
29] proposed an evolutionary algorithm which combines traditional image processing techniques, deep learning, migration learning and deep clustering; this fine-tuned model can detect new defects with high accuracy. Fan et al. [
30] proposed a migration learning and ResNet-based microcrack detection method, which combines feature fusion and incorporates a self-attention mechanism to aggregate low-level features and deep semantic strong features to significantly improve defect detection.
In summary, deep learning techniques have achieved good results in the detection of defects in PV cells but can only basically satisfy the requirements of practical industrial scenarios; moreover, two difficulties in the existing research still need to be further addressed: (1) It is difficult to collect data from the actual application scenarios of PV cells, especially samples with defects, and there are flaws of small and unbalanced datasets; (2) traditional detection models and existing models based on the accuracy and efficiency of defect detection cannot fully achieve the practical requirements.
To solve the above problems, this paper proposes a deep-learning-based solution for the automatic defect detection of PV modules based on electroluminescent images, with the following key contributions.
(1) Adopting data augmentation and weight class to mitigate the effects of small data volume and data imbalance on the model performance, respectively.
(2) The fusion network based on ResNet152–Xception enhances the model’s feature extraction capability. Hybrid pooling is introduced to avoid the defects of traditional single pooling.
(3) Embedded CA to effectively improve the classification accuracy of the model.
(4) We experimented on two global public datasets to validate the model from the perspective of dichotomous and multiclassification tasks, respectively. In addition, to the best of our knowledge, this is the first time that the model has been applied to a dataset with no defects and nine defect types in studying the PV defect identification problem.
The rest of this paper is organized as follows. The models and methods used for the experiments are given in
Section 2. The experimental steps and details are given in
Section 3. The results obtained from the experiments are reported and discussed in
Section 4. Finally, conclusions and future work are given in
Section 5.
2. Methodology
Data are the basis of deep learning method research, and solving the small sample problem and imbalance problem is the most critical research point in PV cell defect recognition. Data enhancement techniques are widely used in the field of industrial defect surface detection; however, defect forms designed for a specific scene are difficult to generalize to other scenes and cannot fundamentally solve the problem. Therefore, the introduction of a migration learning model to achieve PV cell defect recognition enhances the feature extraction ability of the model to achieve a better classification effect on the one hand; on the other hand, the weights are directly loaded into the new model to reduce the cost of deep neural network training.
ResNet is optimized in terms of network structure, utilizing residual blocks to ensure good network performance even in deeper networks. In addition to the network depth problem, how to extend the neural network without increasing the computational cost is a key issue. Inception sets differently sized convolution kernels in each layer of the model and performs dimensionality reduction with 1 × 1 convolution. Xception improves on Inception by mapping spatial correlations for each output channel separately and then performs 1 × 1 convolution to obtain cross-channel correlations, separating the relationships on the channels from the spatial relationships for identification. Therefore, we chose to fuse the features of the two neural network models, ResNet and Xception, to combine the feature representations extracted from the deeper network level by ResNet and from the wider network level by Xception, enhancing the information extraction capability for yet defective regions.
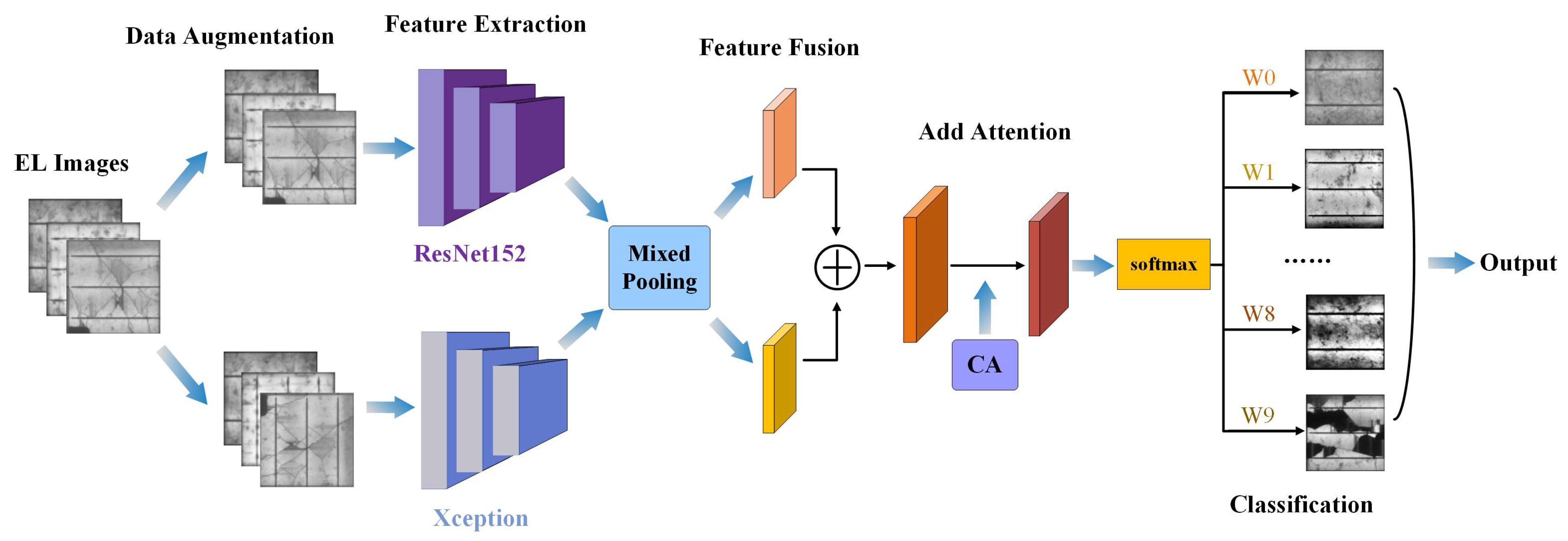
Figure 2 shows the overall framework diagram of our experiment design. First, the images input to the training set were augmented with data enhancement method; second, the preprocessed data were input to ResNet152 and Xception pre-training models to extract features, and the features are pooled using hybrid pooling method; then the hybrid pooled features were combined along the spatial dimension to complete the feature fusion; subsequently, the features are fused with CA, and the location information is embedded into the channel attention; finally, Classweight is introduced in the classification layer to weight the classification probabilities of different categories, and the maximum probability is selected to input the classification prediction results.
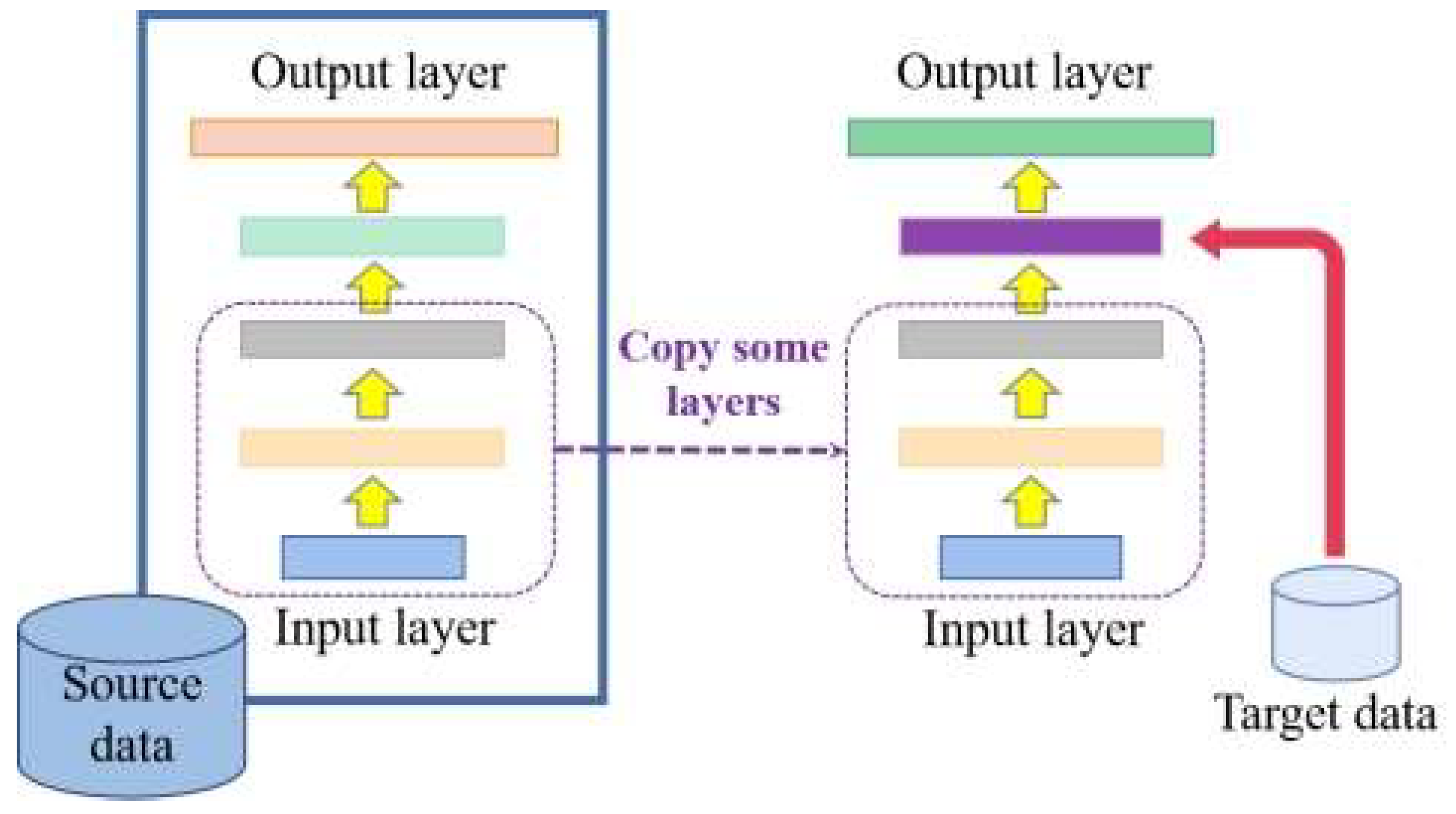
2.1. Transfer Learning
Transfer learning [
31] exploits the correlation between data to transfer the knowledge learned by the model on the source domain,
Ds, and source task,
Ts, to the target domain,
Dt, and target task,
Tt, and to enhance the prediction of the target task learning function
ft(·) with the knowledge of
Ds and
Ts in the case that
Ds ≠ Dt or
Ts ≠ Tt. The domain consists of the feature space
X and the probability distribution
P(X), which generates these data, and the task consists of the labeling space
Y and the learning function
f(·).In this paper, we introduce a model-based learning approach in migration learning, where the parameters of the already trained model are migrated to the new model to help with training. The first n layers of the model are frozen and are not involved in training, and only the last few layers of parameters are trained after copying the weights, thus reducing the training time cost. The model-based migration learning model is shown in
Figure 3.
2.2. ResNet152 Model
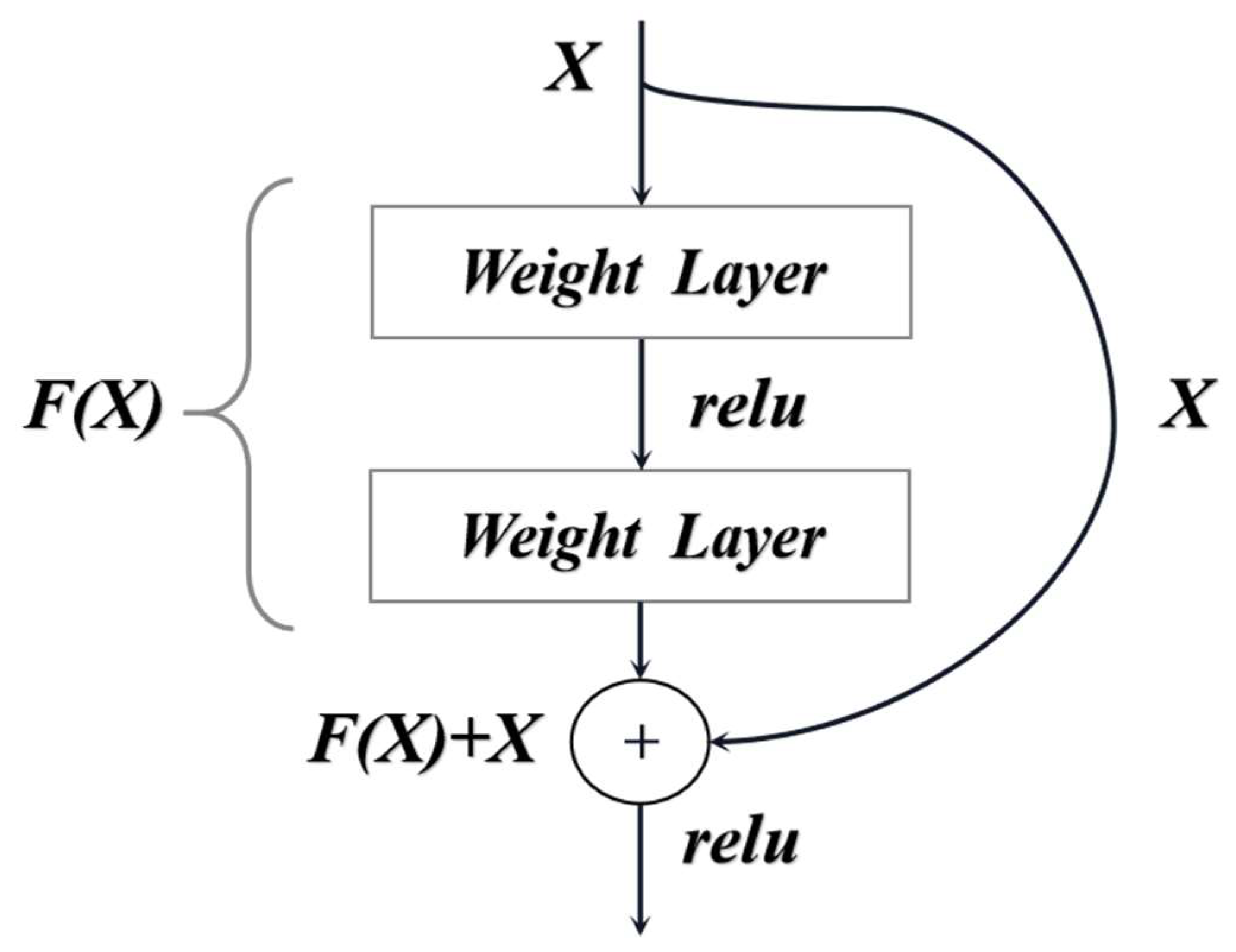
Deep residual networks (such as ResNet) solve the degradation problem caused by increasing the number of network layers in neural networks by stacking residual structures and effectively using the information of multiple layers in the network [
18]. ResNet forms a residual unit by partially convolving layers and a short connection and then by stacking the residual units to form a residual network, which only needs to learn the residual function during the training process without adding additional parameters and computational complexity. The residual unit is shown in
Figure 4, where
X denotes the input of the residual block;
F(X) denotes the mapping result of
X after two layers of weights; relu is the modified linear unit; and the output of the residual block is
F(X) +
X.
The ResNet152 model used in this study was a ResNet network with 152 layers, which is 8 times deeper than VGG-19, but with a lower complexity and better ability to extract features [
32]. The ResNet152 network uses a three-layer convolutional structure to form one residual network cell, with four feature extraction layers, Conv2_x, Conv3_x, Conv4_x and Conv5_x, corresponding to 3, 8, 36 and 3 residual network cells, respectively, plus the input convolutional layer Conv1 and the fully connected convolutional layer FC, for a total of 152 convolutional layers.
2.3. Xception Model
Google has proposed an improved Xception (Extreme Inception) to Inception v3, the ultimate Inception [
33]. Depthwise separable convolution is used to replace the convolution operation in the original Inception v3. The problem of incomplete separation of channel correlation and spatial correlation is effectively solved, and the model is improved while maintaining the same number of parameters as InceptionV3.
The Xception network consists of 14 modules, including 36 convolutional layers, of which except for the first 2 convolutional layers and the convolutional layers connected by residuals, all adopt depth-separable convolution, and the basic network is constructed by stacking depth-separable convolution. The introduction of depth-separable convolution can effectively reduce the number of parameters to reduce the complexity of operations; moreover, the linear residual connection is used in all modules except the first and the last module, which can effectively solve the degradation problem caused by the network being too deep. The output of GlobalAveragePooling in the last module, i.e., a one-dimensional vector of length 2048, was used in this study.
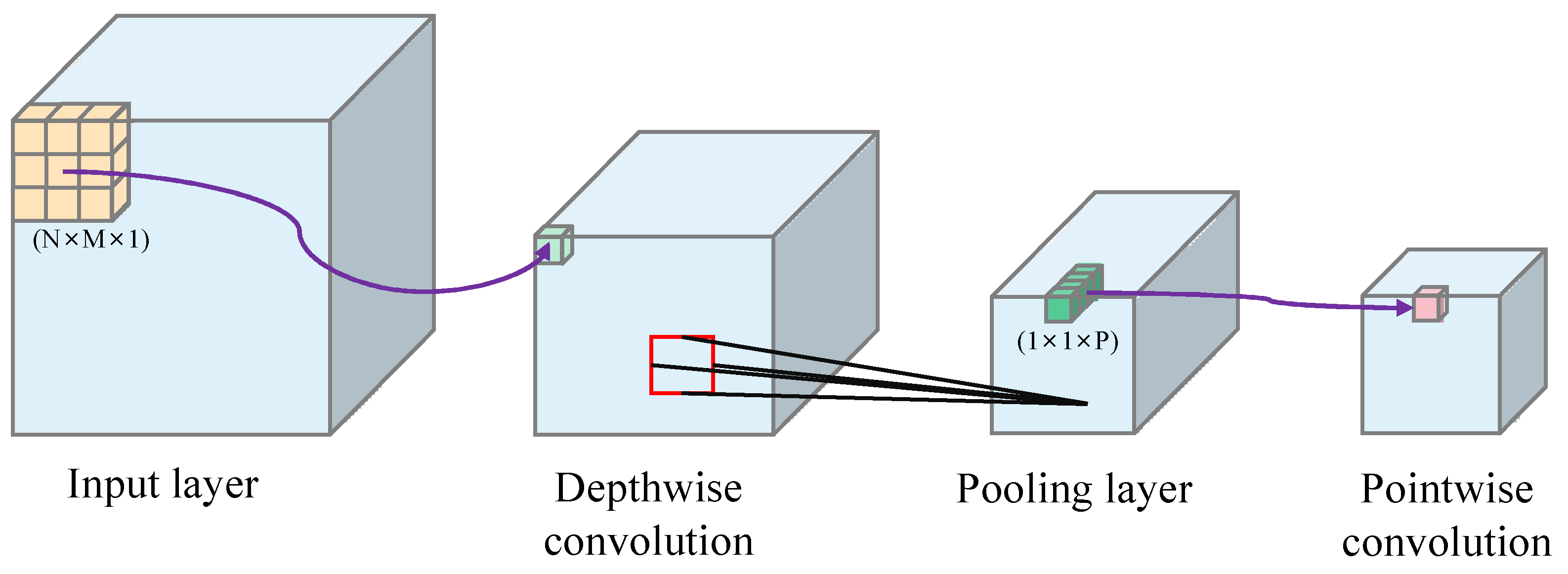
The structure is shown in
Figure 5. (1) Depthwise convolution convolves each input feature channel individually, assuming that the number of input feature maps is S and the convolution kernel size is k × k so that each input feature map will correspond to a separate k × k convolution kernel for convolution and output S feature maps; (2) pointwise convolution uses a standard convolution of 1 × 1 to correlate the feature channels between correlation output features.
2.4. CA
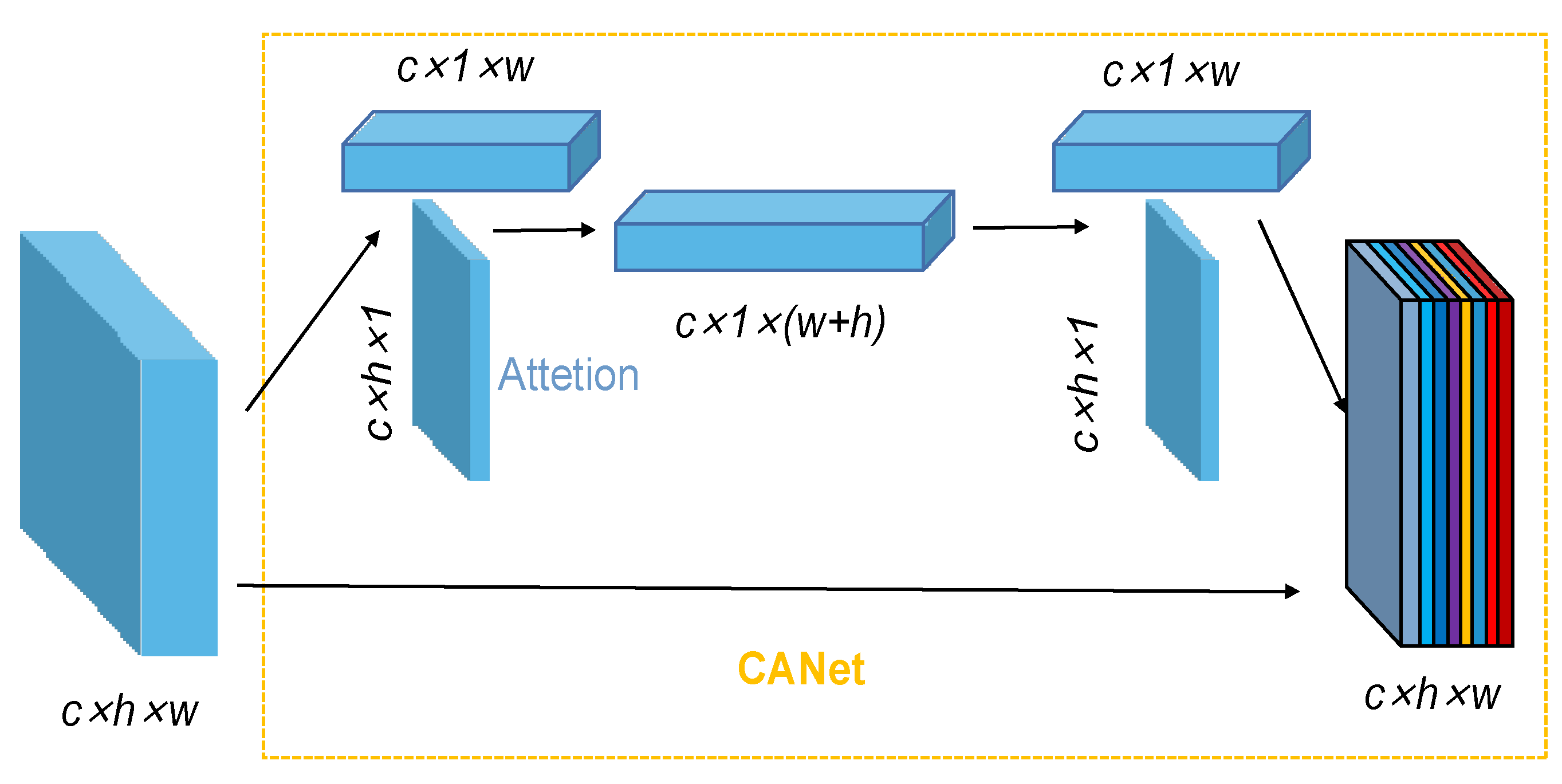
In image feature extraction, attention mechanisms can enhance feature selection. Position-based attention mechanisms act in two ways: one is by large-scale kernel convolution, such as squeeze excitation (SE) and the convolutional block attention module (CBAM); two is to decompose feature images, such as CA.
Compared with the large-scale kernel convolution operation to obtain spatial information, decomposing the feature image can make full use of the captured location information so that the region of interest and the relationship between channels can be accurately and effectively captured. The overall flow of the CA mechanism module is shown in
Figure 6, which decomposes the feature image into two one-dimensional codes through a two-dimensional global pool operation to effectively capture the location information and channel relationship; the specific location of the target is analyzed, and the related feature values are output.
The CA structure obtains accurate location information by two-dimensional encoding, which includes two steps of coordinate information embedding and coordinate attention generation, and can effectively enhance the performance of the deep network. The CA mechanism is processed by first encoding each channel along the horizontal and vertical directions; the calculation process is as follows:
In Equation (1),
H is the height of the feature map, and
W is its width;
is the feature map of the
cth channel. A pair of direction-aware feature maps of
c × 1 ×
w and
c × 1 ×
h in size is obtained as:
In Equation (2),
is the output of the
cth channel with height
h;
is the output of the
cth channel with width
w. The global perceptual field is obtained after the above transformation, and precise position information can be obtained. After combining the operations and using the 1 × 1 convolutional transform function
to transform them:
In Equation (3),
is the output of all channels with height
h;
is the output of all channels with width
w;
is the continued combination operation along the spatial dimension;
δ is the nonlinear activation function; and
f is the intermediate feature mapping, which encodes the spatial information in the horizontal and vertical directions. After decomposing into
and
along the horizontal and vertical dimensions and using the 1 × 1 convolutional transform functions
and
to transform
and
into tensors with the same number of channels, respectively, the calculation process is:
In Equation (4),
σ is the sigmoid activation function. After expanding the output
and
as the dimensional weights of vertical and horizontal attention, the output feature image is:
In Equation (5), and are expanded by and as the dimensional weights of vertical and horizontal attention; is the feature map of the cth channel; and is the output attention-weighted image.
2.5. Feature Fusion
To improve the feature extraction ability of the network and to enrich the feature expression, this study fused ResNet and Xception. Firstly, the outputs of ResNet and Xception networks were mixed pooling compared with the traditional pooling; mixed pooling introduces pooling selection coefficients during the training process, which in turn, determines the pooling method and changes the rules of pooling adjustment randomly. This method is better than the traditional single pooling method and is also beneficial in the prevention of overfitting to a certain extent. Then the features after hybrid pooling are combined along the spatial dimension, and finally, the fused features are pooled global averages to complete feature fusion. The feature fusion implementation process is shown in Equations (6) and (7).
In Equation (6), is the output feature map; GAP is the global average pooling; is the output of the ResNet network after hybrid pooling, which indicates the output of the Xception network after hybrid pooling; and indicates the combination operation of and along the spatial dimension.
In Equation (7), denotes the mixed pooling output value of the rectangular region, , associated with the kth feature map; λ is a random value of 0 or 1, indicating the choice of using maximum pooling or average pooling; denotes the element located at in the rectangular region, , in the kth feature map; and denotes the number of elements in the rectangular region, .
3. Dataset Introduction
In this study, the two global public datasets of EL images used for the experiments were from the field of photovoltaic power generation. Dataset 1 [
34] was a sample of 2624 PV cell images obtained from 44 PV modules with different degrees of defects, of which 18 modules were monocrystalline and 26 were polycrystalline; in addition, all samples were normalized by normalizing the size and view angle to 8-bit grayscale images of 300 × 300 pixels [
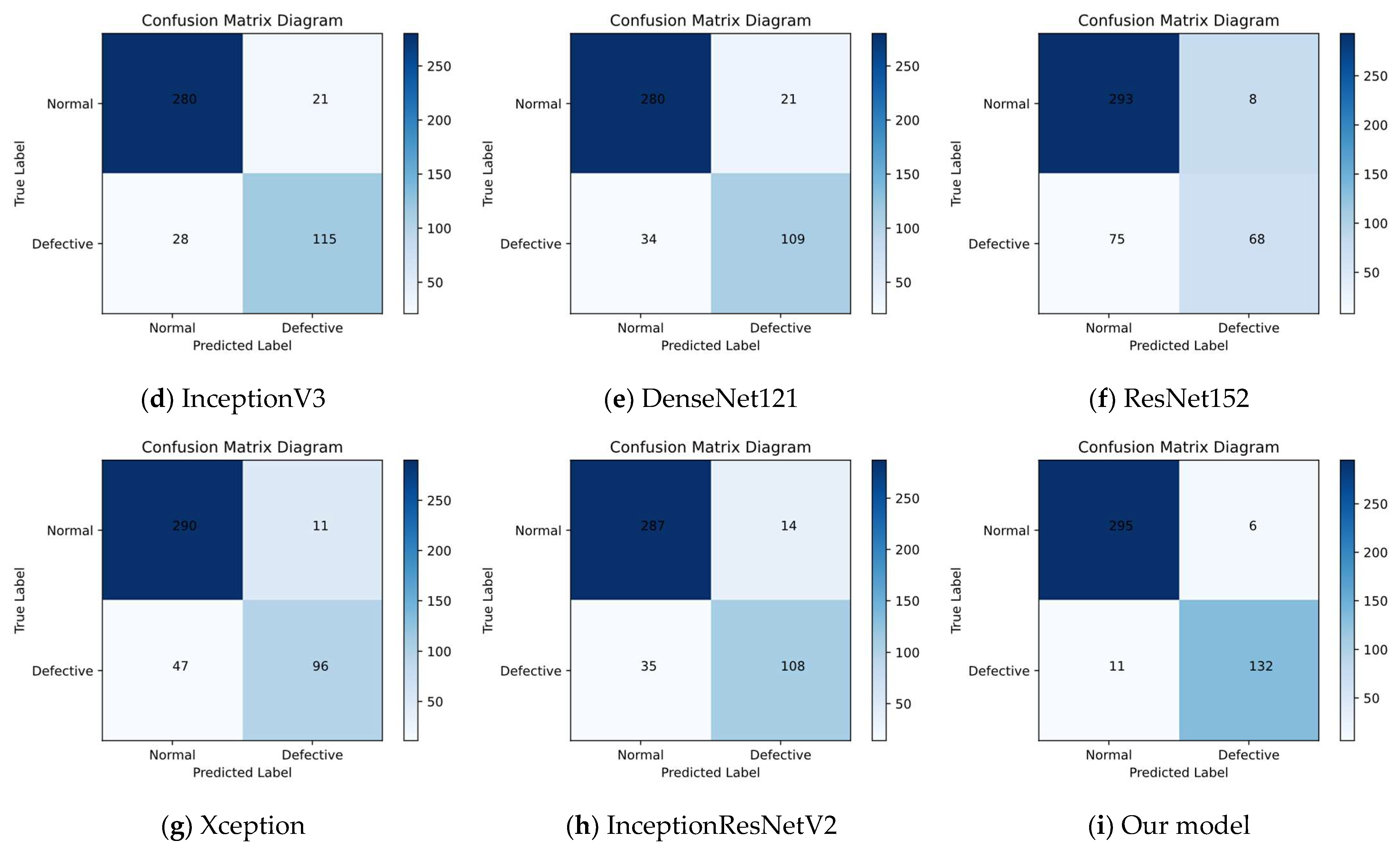
35]. The critical detail of whether a PV cell is defective or not exhibited uncertainty due to the possible noise and unknown defect type of PV cells. Therefore, the image samples in the dataset were expertly labeled as “0%”, “33%”, “67%”, and “100%”, as four probabilities of the occurrence of PV cell defects. In order to check the performance of the model in identifying the presence of defects on the PV cell surface, we only selected two types of data, “0%” (without defects) and “100%” (with defects), to complete the experiment.
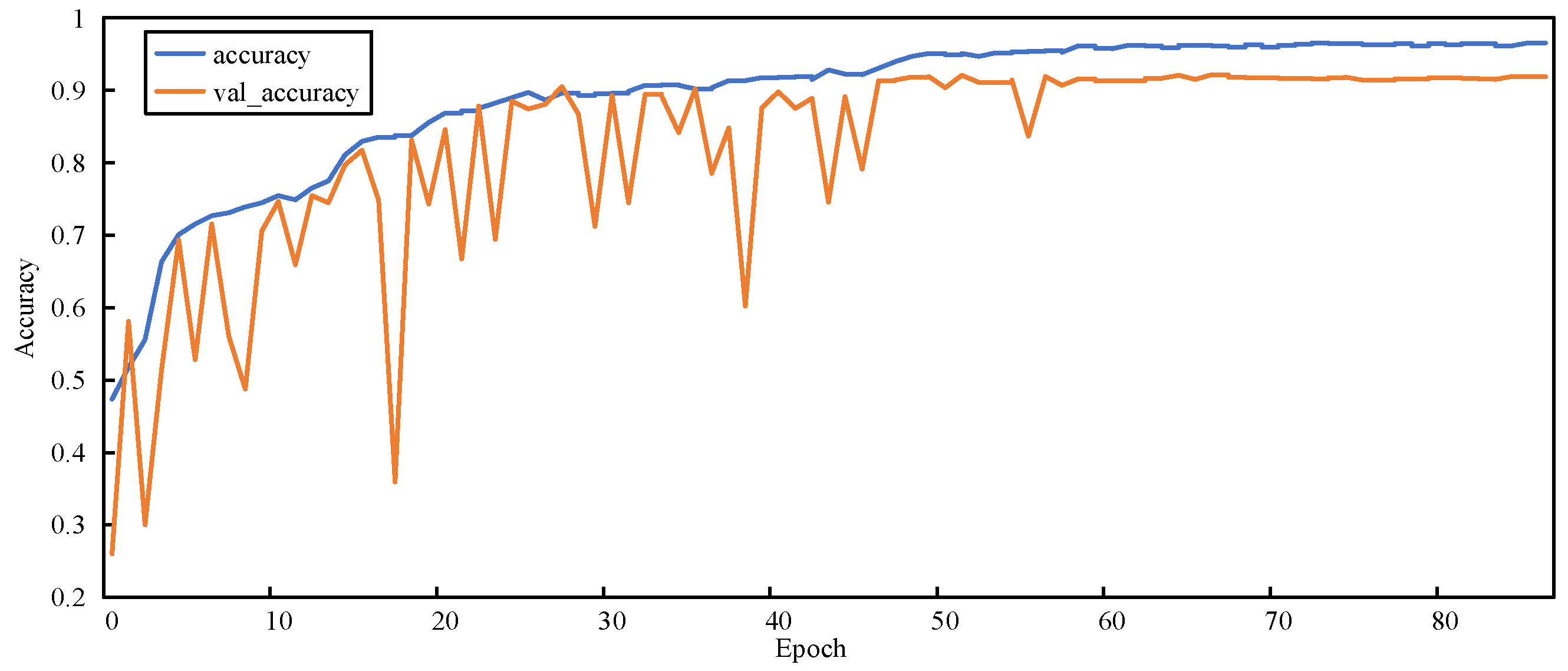
Figure 7 shows the number of samples of these two types.
Dataset 2 [
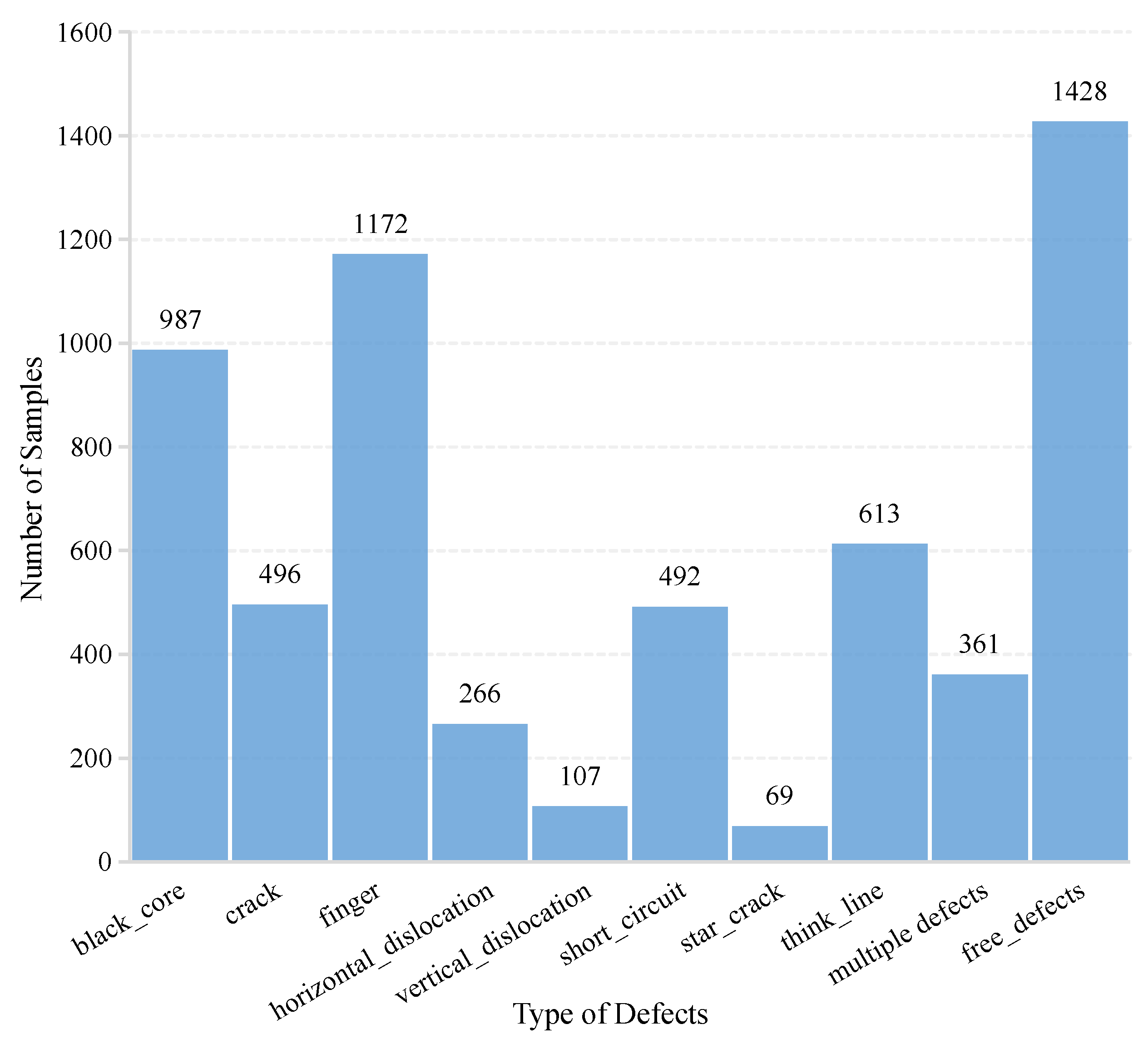
36] was a high-resolution image sample of PV cell defects collected from actual industrial manufacturing, which was jointly published publicly by the Hebei University of Technology and Beijing University of Aeronautics and Astronautics. Compared with dataset 1, this dataset had higher resolution and more diverse and comprehensive types of anomalies, such as different types of defects including cracks (linear and stellate), broken grids, black cores, unaligned, thick lines, etc.
Figure 8 shows the defects in dataset 2. In addition, any distortion issues in the images have been addressed, which helped to fully validate the model proposed in this paper.
Therefore, based on the detection of the presence or absence of defects by the model, we further validated the performance of the model in identifying different types of defects on the PV cell surface on dataset 2.
Figure 9 shows the number of samples with “no defects”, and the nine defect types in dataset 2.
According to the distribution of category samples in dataset 1 and dataset 2, two problems can be found: (1) the number of samples in different categories is unbalanced, with large disparities; (2) the number of images trained based on deep learning is relatively small. Therefore, in order to balance the distribution of samples within different categories and to make full use of the value of limited data, we adopted data enhancement and category weighting strategies.
3.1. Data Enhancement
Large-scale datasets are an important prerequisite for the successful application of deep learning techniques. Therefore, in this study, a series of stochastic changes was applied to the training set using a data enhancement strategy to improve the generalization ability of the employed deep learning model and to avoid overfitting problems. First, all images were normalized in order to improve the speed and possibly the accuracy of gradient descent for optimal solutions. Second, to obtain more images with different defect patterns, all the images were row–row swapped, randomly flipped vertically and flipped horizontally. We did not use random cropping and panning because some key regions that affect the model judgment would be cropped or panned, resulting in the model’s failure to learn the features during training. Furthermore, the blurring process reduced the influence of dark areas in EL images, and we randomly chose from Gaussian blur, motion blur and center blur. Finally, image brightness, contrast and saturation enhancement techniques were applied to the original EL images to produce new images with different and useful information.
3.2. Category Weights
As mentioned in the previous section, the dataset in this paper had the problem of data imbalance, and to address this problem, this study used type weights to weight the categories; the weight balance formula is shown in
Section 3.1. Each sample was given a different weight value according to the number of samples in its category, and the category with a small number of samples is weighted more, i.e., the loss of sample misclassification is greater, which acts on the loss function during the training process, thus making the model pay more attention to the category with a small number of samples.
where
is the weight of category
;
is the total number of samples in the dataset;
is the number of categories; and
is the total number of samples in category
.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
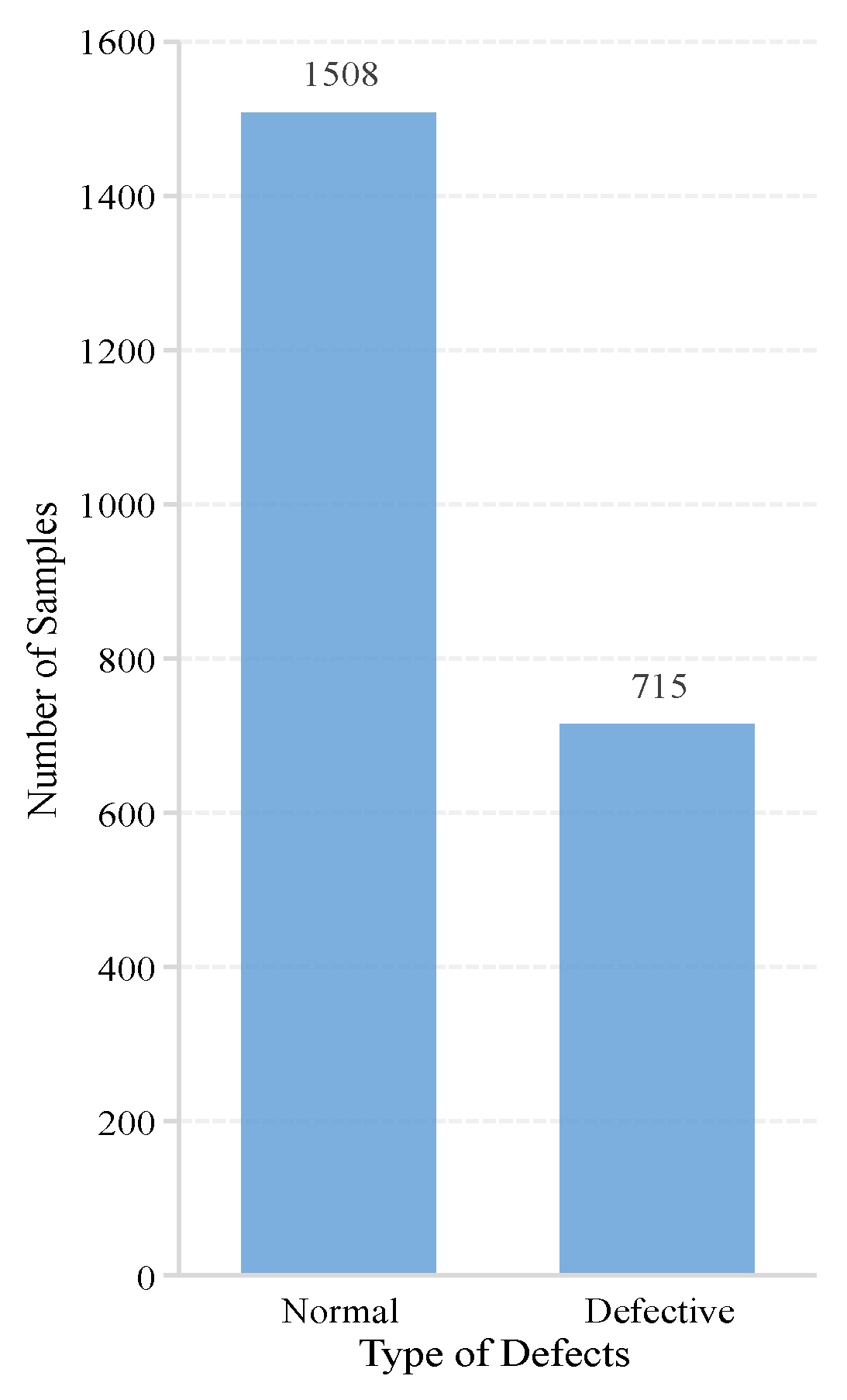{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}