1. Introduction
In the field of aviation, foreign object debris (FOD) refers to any substance that is not part of the aircraft and is presented on the airport runways, which could potentially cause damage and may seriously threaten flight safety [
1]. FOD mainly includes metal pieces, screws, tire debris, small stones, plastic pipe, and junk, which are hard to find. During aircraft takeoff and landing, FOD could be sucked into the aircraft by the aircraft engine, possibly causing aircraft engine failure. In addition, FOD may puncture the tires of the landing gear of the aircraft. For example, in 2000, the flight crash at Charles De Gaulle Airport in France was caused by a metal strip that fell on the airport runway. In this accident, 113 people lost their lives. It was the most serious air disaster caused by FOD [
2]. Since then, FOD detection has been listed as a prime safety measure in the airport. Traditional FOD detection usually adopts a manual screening method, which has poor reliability and low efficiency, and cannot meet the high-safety and fast-throughput requirements of airports. Therefore, many domestic and international airports are actively studying and developing automatic FOD detection systems to reduce FOD risks.
To date, several FOD detection systems have been applied in airports. For example, the Tarsier Radar system developed in the United Kingdom (UK) uses a 94.5 GHz FMCW radar [
3]; the FODetect system, developed in Israel, consists of a millimeter wave radar and an optical camera [
4]; the FODFinder system developed in the United States (US) contains a millimeter wave radar, GPS, and optical cameras [
5]; and the iFerret system developed in Singapore [
6] uses optical cameras. These systems are radar-based detection systems, optical-camera-based detection systems, and multi-sensor fusion detection systems. In radar-based detection systems, FOD detection is implemented based on the characteristics of radar returns [
7]. The results of radar-based detection systems are favorable for detection of FOD with sizes larger than 5 cm × 5 cm, but poor for objects with smaller size or weak radar returns such as nuts and rubbers [
8]. Even though FOD images could be obtained via optical cameras, these images are not employed to detect FOD. If the characteristics of FOD in optical images are utilized to complete FOD detection, then it is of great significance in preventing FOD damage and increasing the utilization rate of airport runways. Although iFerret uses optical images for FOD detection, the detection results are poor for objects smaller than 5 cm × 5 cm.
The advantages of optical-camera-based detection systems are that they can acquire rich information about the environment and can use computer vision technology to detect objects. In recent years, many methods detecting FOD by virtue of optical images have been proposed, which are performed based on traditional computer vision or deep learning. A typical traditional method is to design a segmentation model to find the possible FOD region. For example, an improved region growth algorithm was proposed by Zheng et al. [
9] to identify the FOD region on airport runways. A FOD detection algorithm based on image change detection was designed by Xu et al. [
10] and Chen et al. [
11]. Zhang et al. [
12] presented a detection algorithm based on the weighted fuzzy morphology, detecting image edge while reducing noises. An alternative traditional method of detecting FOD focuses on the novel feature descriptors and effective detectors. Hu et al. [
13] developed a FOD detection and classification method based on extreme learning machine and several visual features, in which the color, the histograms of oriented gradient (HOG), and the scale-invariant feature transform (SIFT) are extracted and integrated to represent FOD. Aiming at FOD detection, Niu et al. [
14] proposed a method combining support vector machine (SVM) and Gabor wavelet, in which Gabor wavelet is adopted to extract effective features to describe FOD, and then SVM is used to classify FOD. Although the above methods are simple, easy to understand, and fast in calculation, their accuracy is limited due to the diversity of FOD type and the interference of airport road surfaces, such as tire marks, marker lines, splice joints, and holes.
In recent years, for computer vision, such as image classification, image segmentation, and object detection, deep-learning-based methods have been widely used [
15,
16,
17]. Inspired by this, many scholars have introduced deep-learning-based methods into FOD detection. Deep-learning-based methods extract high-level semantic information through continuous down-sampling operations, representing the objects more abstractly and accurately. Cao et al. [
18] improved the region-based convolutional neural networks for FOD detection. Li et al. [
19] and Gao et al. [
20] applied YOLOv3 and DeepLabv3+ in FOD detection, respectively. Deep-learning-based methods can automatically extract the features of FOD to reduce human intervention, but they require a huge dataset to learn. Indeed, the reliance on the large variety of unexpected FOD makes it extremely difficult to collect anomalous images for training. Moreover, most neural networks used in object detection or semantic segmentation are designed to detect typical generic objects, such as pedestrians, and they may provide inferior results of FOD detection tasks where a small area is occupied by FOD on the airfield pavement image.
There are also object detection methods based on random forest framework [
21,
22,
23,
24]. Typically, this kind of method firstly construct corresponding pixel-level representations with handcraft features. Then, with the obtained features, random forest can be trained to model the distribution of features patterns and inference the class of pixels in the feature space. Shotton et al. [
21] proposed semantic texton forests to serve as efficient texton codebooks for image categorization and semantic segmentation. The splitting nodes in semantic texton forests use the raw value of a single pixel, the sum, difference, and absolute difference of a pair of pixels in d × d image patches. To improve the performance of semantic segmentation, Schroff et al. [
22] combined the global features, local features, and context-rich information in the splitting nodes of random forest. Being applied in human pose estimation in the depth images by Shotton et al. [
23,
24], random forest takes the depth comparison between a pair of pixels as the splitting criteria. In random forest, using the simple comparison between a pair of pixels on local image patches for a feature representation has been one of the most popular representation learning methods. It has constraints of using only two points in fixed-size image patches and fixed weights. This does not fully consider the spatial coherence between adjacent pixels, which reflects the structure properties of the object surface and element correlation of the image, similar to the macroscopic observation of human vision.
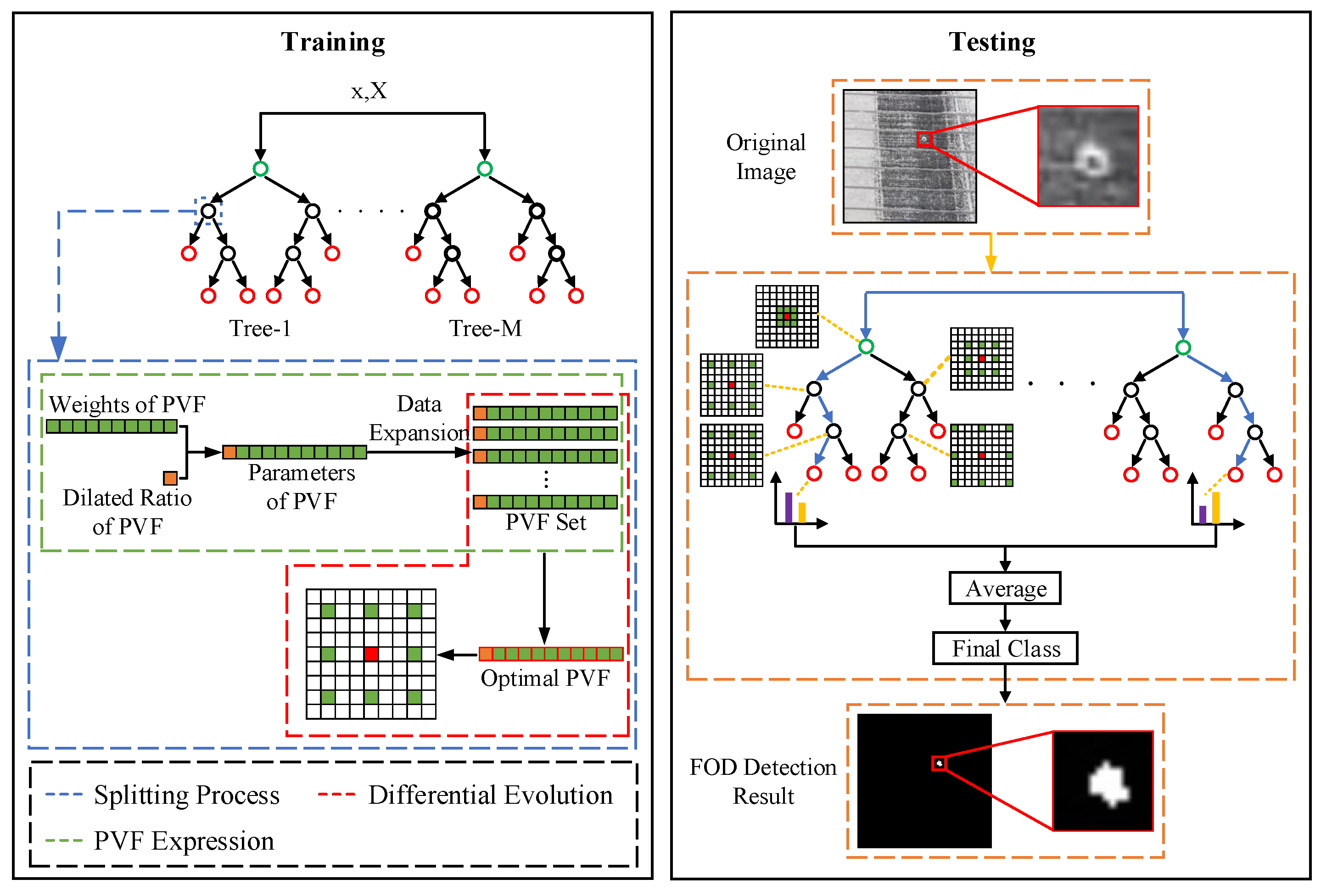
In this paper, we present a new FOD detection framework based on random forest to detect small-scale FOD with complex background and noise in airfield pavement images. In this way, the FOD detection problem is described as a pixel-wise classification problem. There are two categories, namely foreground and background. The foreground refers to pixels belonging to FOD and the background refers to pixels belonging to airfield pavement. The pixel visual feature (PVF) is firstly designed to reflect the state of pixels and the spatial coherence between pixels. Compared with using several points in fixed-size image patches and fixed weights in random forest, PVF is able to learn weights and size of receptive field by differential evolution algorithm. Then, the random forest employs the learned PVF and calculates the probability of each pixel for each class. Finally, the effectiveness of the proposed method is verified on the FOD dataset collected from airport and annotated at the pixel level. For the capability of the generalization and robustness of random forest [
25] and the global optimization ability of differential evolution algorithm [
26], FOD could be detected accurately.
The rest of this paper is organized as follows. The overall detection framework is described in
Section 2, including the learning process of PVF using differential evolution algorithm, and the training and testing of random forest. In
Section 3, the proposed FOD detection system used in this paper is introduced. In
Section 4, the effectiveness of the proposed detection method is verified on the FOD dataset. Comparative experiments between this method and other methods are also introduced in this section.
Section 5 and
Section 6 provide the discussion and conclusions of this paper, respectively.
3. FOD Detection System
The FOD detection system in this work is a solution for cost-effective and simple detection of FOD (
Figure 4). The system could be installed along both sides of the airport runway. The system is composed of two modules, the FOD-detecting sensors and data processing center. In detail, the FOD-detecting sensors consist of several optical cameras fixed on the pan-tilt, which can provide up, down, left, right, and other azimuth control. The installation cost could be acceptable because the FOD detection sensors can use the power of the runway edge lights. The data processing center receives the optical images captured by the optical cameras, and FOD detection is conducted in this module by the proposed method, providing the information of the detected FOD (such as image and location). According to the information of FOD, the procedures of alarm and clear processing are performed.
Referring to the runway standard of Shahe Airport, the length and width of the runway are 1800 m and 45 m, respectively. The area of the airport runway covered by an optical camera is approximately (200 × 23) . Therefore, to cover 1800 m of the runway distance, 9 cameras need to be installed. Because one image cannot cover this area, the runway is divided into multiple circular regions. The optical camera focuses on the ring and captures the pavement images along the route. The rotation angle of pan-tilt contains the vertical and horizontal angle. For the same circular region, the vertical angle and the focal length remain unchanged. With the horizontal angle continuing to change, the circular region is scanned by the optical camera. For different circular regions, the vertical angle and the focal length are different. In order to detect nuts with 5 mm in diameter (the smallest FOD sample), the minimum physical size of a pixel is 1 mm.
4. Experiments and Analysis
The
Section 4.1 introduces the FOD dataset. The evaluation criteria are presented in
Section 4.2, and the influence of different parameters is studied in
Section 4.3. The effectiveness of the proposed PVF and the differential evolution algorithm is verified in
Section 4.4. The comparative experiments of the proposed method with the original random forest [
16] and other deep learning methods (Faster R-CNN [
30] and Deeplabv3+) [
31] are described in
Section 4.5.
4.1. Dataset
The Federal Aviation Administration (FAA) of the United States and the Civil Aviation Administration of China (CDDC) published their advisory circulars, Technical Standards for Airport Foreign Object Debris (FOD) Detection Equipment [
1] and the Information Announcement of Airport Runway Foreign Object Debris Equipment [
32], respectively, formulating the standards of FOD detection system. Based on the two documents, FOD samples were prepared, including real FOD collected from the airfield pavement and standard samples made by factories. Real FOD samples include nuts, screws, steel balls, gaskets, rubber blocks, and stones, which are major targets for FOD detection, as shown in
Figure 5a–f. Standard samples contain spheres and cylinders made of metal, marble, glass, and plastic, as shown in
Figure 5g,h. The size of FOD samples is smaller than 5 cm × 5 cm.
The FOD dataset was collected by our research group at Shahe Airport in Beijing, China. These images only include the runway pavement, not the sky, grass, or other regions. The FOD dataset contains 1800 RGB images (with a resolution of 1920 × 1080). The dataset is made up of 14 different object categories. Six categories consist of real FOD samples, including nuts, screws, steel balls, gaskets, rubber blocks, and stones. The other 8 categories contain standard FOD samples, including metal spheres, marble spheres, glass spheres, plastic spheres, metal cylinders, marble cylinders, glass cylinders, and plastic cylinders. A single image contains 0 or multiple FODs and there are a 4375 annotation instances. The number of different FOD in the dataset varies from 250 to 350. The area of the FOD samples in the images is less than 15 × 15 pixels on average. Here 70% of the FOD dataset is used as training data, and the other 30% the testing data. To achieve the diversity of FOD dataset, different runway surface disturbances and FOD samples are collected. Runway surface disturbances include tire marks, marker lines, splice joints, holes, and others (
Figure 6). The original images were labeled as FOD and ground by labelme software, as shown in
Figure 7. The RGB images were used for visual interpretation. The pixel-precise ground truths were manually checked by 5 operators, who would vote for determination in terms of controversial image region.
In this paper, for introducing real-world variations and increasing the number of FOD in dataset, the dataset is augmented using two strategies. First of all, we use generative adversarial networks (GANs) [
33] to generate high-quality airfield pavement images. The generated images drawn from the generator net after training are shown in
Figure 8a. Second, inspired by recent success of synthetic object detection datasets [
34] and the fact that many airfield pavement images do not have FOD, a cut-and-paste strategy to synthetically insert FOD into airfield pavement images for data augmentation is employed. As shown in
Figure 8b, we first cut numerous FOD objects from the original FOD dataset, and generate synthetic airfield pavement images by inserting FOD in the original images. In this paper, OFOD is used to represent the original FOD dataset and SFOD is used to represent the set of the synthetic FOD dataset and the original FOD dataset.
4.2. Evaluation Criteria
To evaluate the performance of the proposed FOD detection method, two benchmark metrics, i.e., precision and recall, are employed. In this study, the proposed FOD detection method acts directly on pixels and infers the category of each pixel. There are mainly two results, FOD and background, of which FOD is denoted by 1 and background by 0. To illustrate the calculation methods of the 2 metrics, 3 types of detection results are defined: (1) is the number of pixels correctly detected as FOD; (2) is the number of pixels incorrectly detected as FOD; and (3) is the number of pixels incorrectly detected as background.
According to
,
, and
, precision and recall are calculated by Equations (15) and (16).
Precision indicates the proportion of real FOD pixels in the FOD pixels predicted by the detection method.
Recall indicates the proportion of FOD pixels predicted correctly by the detection method in the real FOD pixels.
4.3. Experimental Setup
The influence of different parameters of the proposed method on FOD detection results is demonstrated in this section. According to the experimental results, the experimental setup is described. The parameters come from two parts, differential evolution algorithm and decision trees. The parameters affecting the evolutionary process include the population size, the maximum number of iterations, the scaling factor, and the crossover rate. The parameters of the decision trees include the number of decision trees and the maximum depth of decision trees.
The detection process including training and testing is repeated five times and the training and testing dataset are reselected for each detection process. All the reported results are averaged over the five experiments. The experimental method is control variable method. First, all parameters are set to their default value, indicated by green marks in
Figure 9 and
Figure 10, respectively. Then, in each experiment, only a parameter value is changed while fixing the remaining five parameters’ values. Using the method, we compared and analyzed the impact of the main parameters on the performance of the proposed method.
Figure 9a shows the performance of the proposed method when the population size changes. The performance is improved with respect to the population size. However, when the population size is greater than 50, its impact on the detection performance becomes negligible and can even be ignored.
Figure 9b uncovers the influence of the maximum number of iterations. When the maximum number of iterations is less than 200, the performance is significantly improved, yet when the number of iterations is more than 200, the improvement of the performance is not obvious.
Figure 9c presents influence of the scaling factor. It can be observed that the detection performance deteriorates with the enlargement of scaling factor.
Figure 9d displays the influence of the crossover rate. It can be seen that the procedure is sensitive to the crossover rate, and the crossover rate with 0.6 performs the best.
Figure 10a shows the relations between detection performance and the maximum depth of decision trees. It can be observed that the maximum depth of decision trees is nearly proportional to the performance when the maximum depth is less than 22. The improvement is not obvious when the maximum depth is greater than 22. The possible explanations that a large number of the maximum depth leads to over-fitting.
Figure 10b shows the relations between detection performance and the number of decision trees. It can be observed that the performance becomes better when the number of decision trees increases, though eventually they would level out. In detail, when the number of decision trees is less than 7, precision can be increased by about 7% by adding a decision tree. However, when the number of decision trees is greater than 7, precision can only be increased by about 1% by adding a decision tree. This proves that when the number of decision trees exceeds a certain value, increase in the number of decision trees only has a limited improvement effect on the performance.
The experimental results reveal that compared with the number of decision trees, the maximum depth of decision trees has a greater impact on the performance of the proposed method. The reason may be that the depth of decision trees directly affects the classification ability of the proposed method, while the number of decision trees merely affects the robustness of the proposed method to the noise of the data.
Based on the above experiments, the following parameters are used unless stated otherwise. The population size is set as 50, the maximum number of iterations 200, the scaling factor 0.1, and the crossover rate 0.6. In consideration of the increased computational complexity and memory usage resulted from the increased maximum depth and number of decision trees, the maximum depth of decision trees is set as 20 and the number of decision trees 10. The conditions for generating leaf nodes are that the probability of being a class is 0.99% and the amount of the remaining data is 0.01% of the total training data.
4.4. Validity of the Proposed Method
This section demonstrates the effectiveness of the proposed PVF and the differential evolution algorithm compared with the typical convolution kernel and random generation in
Table 1. The performance of the random forest based on PVF outperforms the random forest based on 3 × 3 convolution kernel and the former has smaller number of nodes. The analysis shows that the PVF, learned by differential evolution algorithm, outperforms that learned through random generation. In terms of the spatial information, the detection result with PVF integrating the spatial information is better than that of without integrating the spatial information. It can be concluded that the random forest based on the proposed PVF and the differential evolution algorithm can learn more optimal representations.
4.5. Comparative Experiments
This section compares the proposed method with the original random forest and deep learning methods (Deeplabv3+ and Faster R-CNN) on FOD dataset using a machine with Intel i9-9940 CPU with 3.30 GHz, 32 GB RAM, and NVIDIA GeForce RTX 2080 Ti GPU.
The proposed method and the original random forest were trained on the OFOD dataset, which includes only the original FOD data and is defined in
Section 4.1. The precision and recall of the original random forest are about 76.18% and 92.93%, respectively. The detection precision of the proposed method is about 17.69% higher than that of the original random forest.
Figure 11 present the qualitative results of the proposed method and the original random forest. In
Figure 11, the image in the first row contains a piece of rubber block, the second row a gravel, and the third row a white cylinder made of plastic. According to
Figure 11, the original random forest raised many false alarms in the regions with airfield pavement disturbances, such as tire marks and holes. This proves that the proposed method can better suppress the interference and noise on the airfield pavement and segment foreign objects from the airfield pavement than the original random forest.
Table 2 and
Figure 12 show the comparison of the proposed method with Deeplabv3+, trained on the SFOD dataset. In
Figure 12, there is a nut in the first row, a gasket in the second row, and a screw and a steel ball in the third row. Compared with Deeplabv3+, the precision of the proposed method is increased by 0.91% and the recall 3.06%. The results in
Table 2 demonstrate that the proposed method has a better detection effect on small-scale FOD than Deeplabv3+. The Precision-Recall (PR) curves of the two methods are shown in
Figure 13. The results in
Figure 12 demonstrate that the proposed method and Deeplabv3+ are all robust to the interference and noise of airfield pavement. The detailed images in
Figure 12 show the FOD edge detection results of the two methods. Deeplabv3+ records many omission errors and false alarms in FOD edge detection. In conclusion, compared with Deeplabv3+, the proposed method performs better in control of omission errors and false alarms, and in the display of FOD edge details.
We discuss the possible explanations for why the precision of the deep learning method is limited compared with the proposed method. Some FOD is quite small, such as screws, nuts, and steel balls that fall from the aircraft. Additionally, since cameras are generally installed with a large view from a long distance, the pixels of FOD in image are less than 15 × 15 pixels on average. Therefore, the task of FOD detection is essentially small objects detection. Although deep learning methods are widely used, the problem of small-scale FOD detection is still not fully resolved [
35]. First, small objects often reveal extremely limited appearance information, which increases difficulty in learning discriminative features. Second, with the continuous decline of the resolution of feature map in deep neural networks, the area of small objects is also gradually decreasing and even the spatial information on the feature map is lost. Finally, since deep learning methods often predict pixel-level labels on a low-resolution feature map, e.g., 1/16-th of the input for Deeplabv3+, or 28 × 28 mask for Mask-RCNN [
36], boundary recovery has been a challenge for deep neural networks in image segmentation [
37].
Table 3 and
Figure 14 show the comparison of the proposed method with Faster R-CNN, trained on the SFOD dataset. In
Figure 14, there is a nut and a rubber block in the first column, a copper pillar in the second column, and a metal sphere in the third column. To compare the performance of two methods, the mean average precision (mAP) is calculated. The proposed method achieves 93.47% mAP and is higher 3.3% than Faster R-CNN, which means that the proposed method is effective and robust for small-scale FOD detection. This is because the proposed method classifies pixels by learning their optimal representations without down-sampling, which retains all information of FOD. However, Faster R-CNN extracts high-level feature representations by continuous down-sampling operations, damaging the information of small-scale FOD, whose poor-quality appearance and structure also increase the difficulty of learning rich features [
38].
5. Discussion
In this study, the current research on FOD detection method is investigated. It can be found that there are shortcomings in existing detection algorithms based on optical images, i.e., the poor result on small FOD and not considering interference of airport road surface. Consequently, an object detection method for small FOD under complex background is proposed. Random forest and differential evolution are introduced into FOD detection tasks. The concept of PVF is proposed, which learns the optimal feature to replace the manual design process. The process of learning the optimal PVF is combined with finding the optimal decision boundary to split data in nodes, which are divided into two classes: FOD pixel data and non-FOD pixel data. In this way, the problem of FOD detection is transformed into the problem of pixel classification, achieving pixel-level FOD detection. In the process of decision tree construction, the optimal splitting results are scored by the information entropy and the differential evolution.
For random forest, it is necessary to provide features of the data to use for segmentation in the process of decision tree construction. Inspired by the use of convolutional kernels to learn features in deep neural networks, the convolutional kernels are introduced to learn the state and spatial correlation of pixels. According to the experimental results in
Section 4.4, due to the diversity of FOD type and the interference of airport road surface, the PVF of pixels cannot be calculated by 3 × 3 convolution filters with random weights and fixed receptive field. In the proposed method, the weights and the size of receptive field are able to learned using differential evolution at the same time, so as to distinguish between FOD pixels and background pixels accurately. By comparison, the detection accuracy of the proposed method for FOD is better than that of other methods.
The FOD dataset is collected to verify the effectiveness of the method. Although the types of FOD are unknown in advance, we selected many object categories based on guidance from related research by FAA and CDDC. Currently, the FOD dataset has included 14 object categories and 4375 annotation instances. Varying object categories ensures the complexity of the FOD dataset. However, there is still a limitation. The FOD dataset does not consider the variability of the real world, which includes different light and weather conditions. In future research, we will continue to expand the FOD dataset from two aspects: collecting different FOD samples and collecting images under different light and weather conditions to ensure accurate simulation of airport environments.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}