
Method to Minimize the Errors of AI: Quantifying and Exploiting Uncertainty of Deep Learning in Brain Tumor Segmentation


Abstract
:1. Introduction
2. Materials and Methods
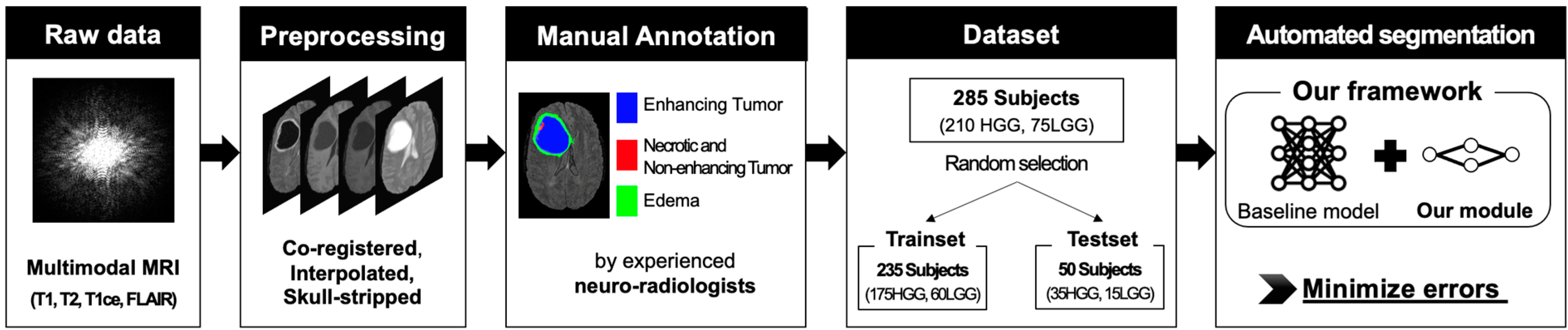
2.1. Dataset
2.2. Baseline Model
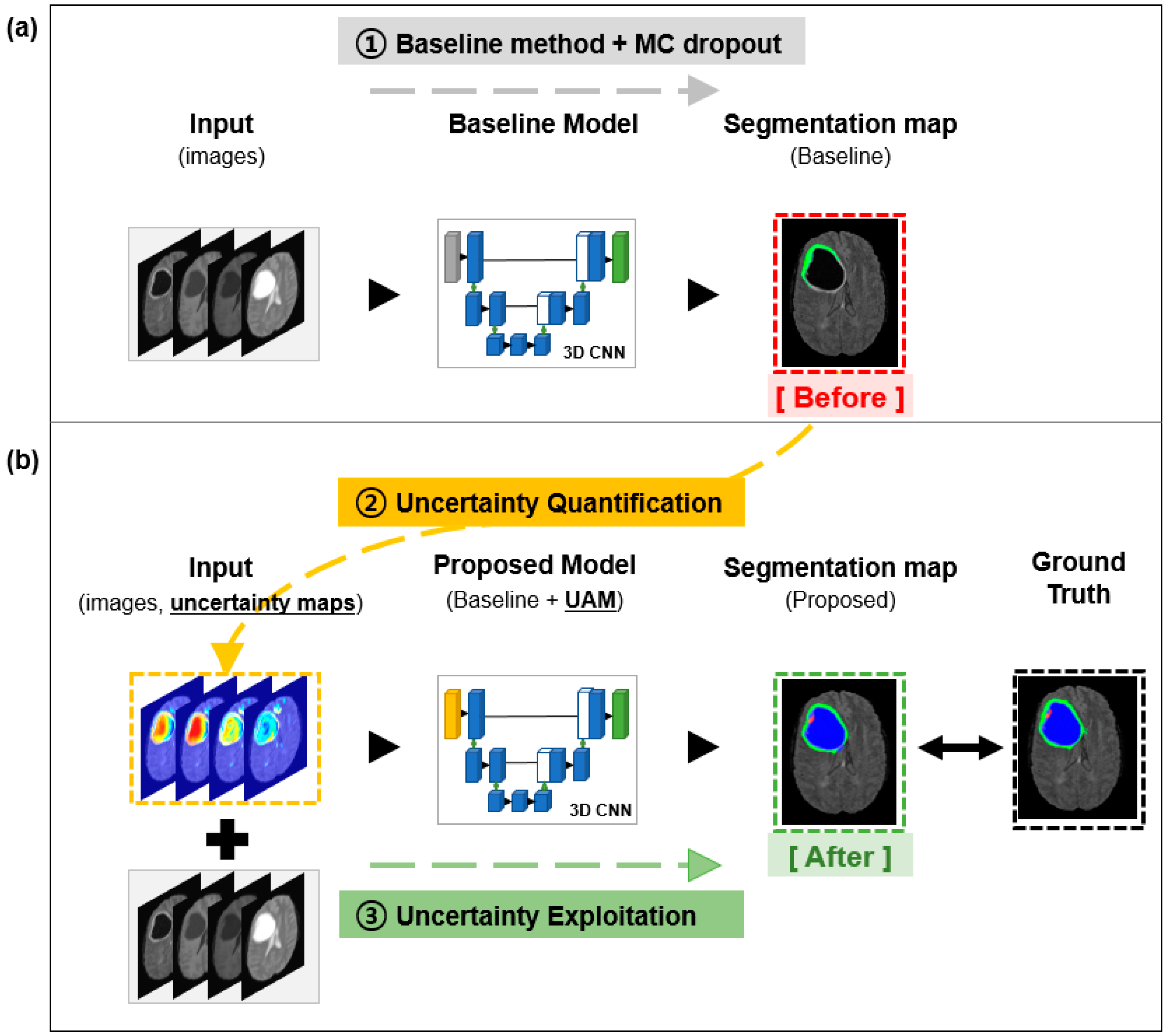
2.3. Uncertainty Quantification
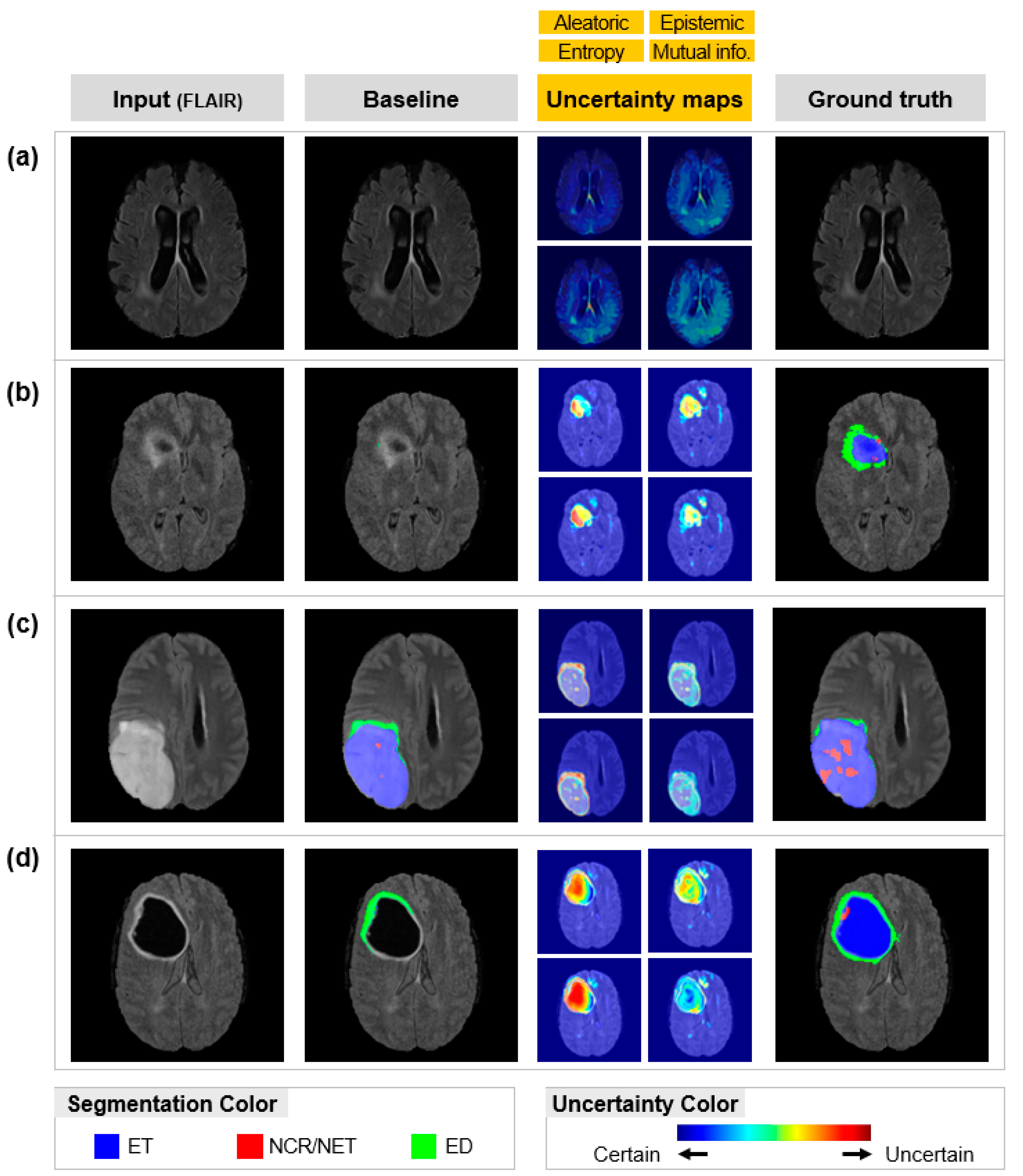
2.3.1. Aleatoric Uncertainty
2.3.2. Epistemic Uncertainty
2.3.3. Entropy
2.3.4. Mutual Information
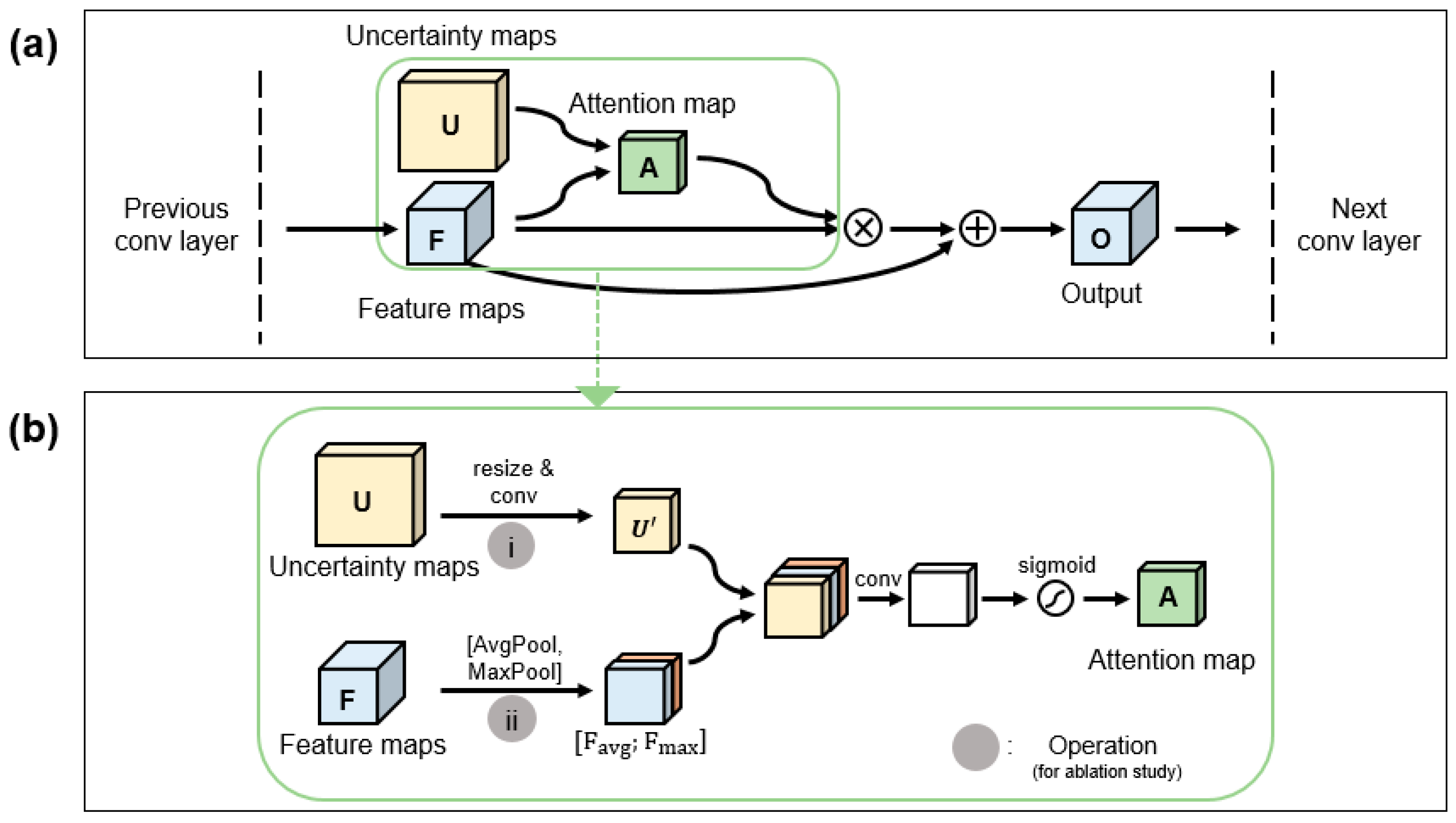
2.4. Uncertainty Exploitation
2.5. Model Training
3. Results
3.1. Uncertainty Quantification
3.2. Uncertainty Exploitation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bakas, S.; Reyes, M.; Jakab, A.; Bauer, S.; Rempfler, M.; Crimi, A.; Shinohara, R.T.; Berger, C.; Ha, S.M.; Rozycki, M.; et al. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv 2018, arXiv:1811.02629. [Google Scholar]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2014, 34, 1993–2024. [Google Scholar] [CrossRef] [PubMed]
- Wee, C.W.; Sung, W.; Kang, H.-C.; Cho, K.H.; Han, T.J.; Jeong, B.-K.; Jeong, J.-U.; Kim, H.; Kim, I.A.; Kim, J.H.; et al. Evaluation of variability in target volume delineation for newly diagnosed glioblastoma: A multi-institutional study from the Korean Radiation Oncology Group. Radiat. Oncol. 2015, 10, 137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing The Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Magadza, T.; Viriri, S. Deep Learning for Brain Tumor Segmentation: A Survey of State-of-the-Art. J. Imaging 2021, 7, 19. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Chen, L.; Tong, L.; Zhou, F.; Jiang, Z.; Zhang, Q.; Zhang, X.; Jin, Y.; Zhou, H. Deep learning based brain tumor segmentation: A survey. arXiv 2020, arXiv:2007.09479. [Google Scholar]
- Kim, S.; Cho, S.; Cho, K.; Seo, J.; Nam, Y.; Park, J.; Kim, K.; Kim, D.; Hwang, J.; Yun, J.; et al. An Open Medical Platform to Share Source Code and Various Pre-Trained Weights for Models to Use in Deep Learning Research. Korean J. Radiol. 2021, 22, 2073. [Google Scholar] [CrossRef]
- Jiang, R.; Jiang, S.; Song, S.; Wei, X.; Deng, K.; Zhang, Z.; Xue, Y. Laplacian-Regularized Mean Apparent Propagator-MRI in Evaluating Corticospinal Tract Injury in Patients with Brain Glioma. Korean J. Radiol. 2021, 22, 759–769. [Google Scholar] [CrossRef]
- Park, J.E.; Kickingereder, P.; Kim, H.S. Radiomics and Deep Learning from Research to Clinical Workflow: Neuro-Oncologic Imaging. Korean J. Radiol. 2020, 21, 1126. [Google Scholar] [CrossRef]
- Chen, C.; Liu, X.; Ding, M.; Zheng, J.; Li, J. 3D Dilated Multi-fiber Network for Real-Time Brain Tumor Segmentation in MRI. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 184–192. [Google Scholar]
- Myronenko, A. 3D MRI Brain Tumor Segmentation Using Autoencoder Regularization. In Proceedings of the International MICCAI Brainlesion Workshop, Granada, Spain, 16–20 September 2018; pp. 311–320. [Google Scholar]
- Isensee, F.; Kickingereder, P.; Wick, W.; Bendszus, M.; Maier-Hein, K.H. No New-Net. In Proceedings of the International MICCAI Brainlesion Workshop, Granada, Spain, 16–20 September 2018; pp. 234–244. [Google Scholar]
- McKinley, R.; Meier, R.; Wiest, R. Ensembles of Densely-Connected CNNs with Label-Uncertainty for Brain Tumor Segmentation. In Proceedings of the International MICCAI Brainlesion Workshop, Granada, Spain, 16–20 September 2018; pp. 456–465. [Google Scholar]
- Nair, T.; Precup, D.; Arnold, D.L.; Arbel, T. Exploring uncertainty measures in deep networks for Multiple sclerosis lesion detection and segmentation. Med. Image Anal. 2020, 59, 101557. [Google Scholar] [CrossRef]
- Natekar, P.; Kori, A.; Krishnamurthi, G. Demystifying Brain Tumor Segmentation Networks: Interpretability and Uncertainty Analysis. Front. Comput. Neurosci. 2020, 14, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shin, D.; Kim, Y.; Oh, C.; An, H.; Park, J.; Kim, J.; Lee, J. Deep reinforcement learning-designed radiofrequency waveform in MRI. Nat. Mach. Intell. 2021, 3, 985–994. [Google Scholar] [CrossRef]
- An, H.; Shin, H.-G.; Ji, S.; Jung, W.; Oh, S.; Shin, D.; Park, J.; Lee, J. DeepResp: Deep learning solution for respiration-induced B0 fluctuation artifacts in multi-slice GRE. NeuroImage 2020, 224, 117432. [Google Scholar] [CrossRef] [PubMed]
- Jung, W.; Yoon, J.; Ji, S.; Choi, J.Y.; Kim, J.M.; Nam, Y.; Kim, E.Y.; Lee, J. Exploring linearity of deep neural network trained QSM: QSMnet+. NeuroImage 2020, 211, 116619. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Lee, D.; Choi, J.Y.; Shin, D.; Shin, H.; Lee, J. Artificial neural network for myelin water imaging. Magn. Reson. Med. 2019, 83, 1875–1883. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwon, Y.; Won, J.H.; Kim, B.J.; Paik, M.C. Uncertainty quantification using Bayesian neural networks in classification: Appl1ication to biomedical image segmentation. Comput. Stat. Data Anal. 2020, 142, 106816. [Google Scholar] [CrossRef]
- Shi, W.; Zhuang, X.; Wolz, R.; Simon, D.; Tung, K.; Wang, H.; Ourselin, S.; Edwards, P.; Razavi, R.; Rueckert, D. A Multi-image Graph Cut Approach for Cardiac Image Segmentation and Uncertainty Estimation. In Proceedings of the International Workshop on Statistical Atlases and Computational Models of the Heart, Toronto, ON, Canada, 22 September 2011; pp. 178–187. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the International Conference on Machine Learning PMLR, Barcelona, Spain, 9 December 2016; pp. 1050–1059. [Google Scholar]
- Kiureghian, A.; Ditlevsen, O. Aleatory or epistemic? Does it matter? Struct. Saf. 2009, 31, 105–112. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? arXiv 2017, arXiv:1703.04977. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Swizerland, 2017; pp. 240–248. [Google Scholar]
- Joe, B.N.; Fukui, M.B.; Meltzer, C.C.; Huang, Q.-S.; Day, R.S.; Greer, P.J.; Bozik, M.E. Brain Tumor Volume Measurement: Comparison of Manual and Semiautomated Methods. Radiology 1999, 212, 811–816. [Google Scholar] [CrossRef]
- Grossman, S.A.; Wharam, M.; Sheidler, V.; Kleinberg, L.; Zeltzman, M.; Yue, N.; Piantadosi, S. Phase II study of continuous infusion carmustine and cisplatin followed by cranial irradiation in adults with newly diagnosed high-grade astrocytoma. J. Clin. Oncol. 1997, 15, 2596–2603. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
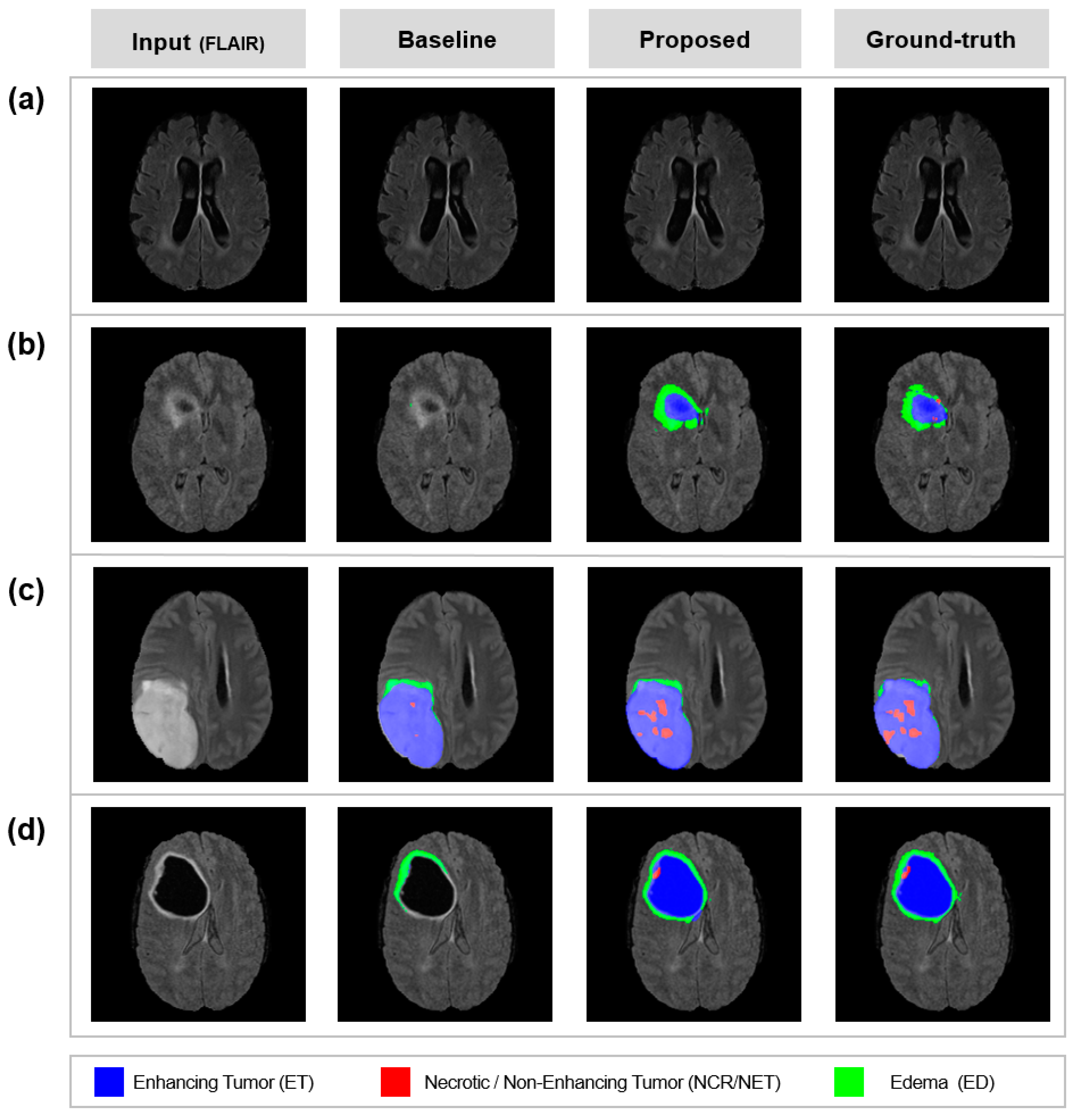{kind=link}
| Model | MFNet | MFNet + UAM (Proposed) | DMFNet | DMFNet + UAM (Proposed) | |
|---|---|---|---|---|---|
| DSC (%) | ET | 79.91 | 82.56 | 80.12 | 83.27 |
| TC | 84.61 | 84.93 | 84.54 | 85.12 | |
| WT | 90.43 | 89.56 | 90.62 | 90.28 | |
| Params (M) | 3.19 | 3.20 | 3.88 | 3.89 | |
| FLOPs (G) | 20.61 | 20.81 | 27.04 | 27.28 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Shin, D.; Oh, S.-H.; Kim, H. Method to Minimize the Errors of AI: Quantifying and Exploiting Uncertainty of Deep Learning in Brain Tumor Segmentation. Sensors 2022, 22, 2406. https://doi.org/10.3390/s22062406
Lee J, Shin D, Oh S-H, Kim H. Method to Minimize the Errors of AI: Quantifying and Exploiting Uncertainty of Deep Learning in Brain Tumor Segmentation. Sensors. 2022; 22(6):2406. https://doi.org/10.3390/s22062406
Chicago/Turabian StyleLee, Joohyun, Dongmyung Shin, Se-Hong Oh, and Haejin Kim. 2022. "Method to Minimize the Errors of AI: Quantifying and Exploiting Uncertainty of Deep Learning in Brain Tumor Segmentation" Sensors 22, no. 6: 2406. https://doi.org/10.3390/s22062406