1. Introduction
DNA and RNA sequencing is an important tool in biological and medical research. DNA sequencing is essential in genomics, RNA sequencing is essential in transcriptomics. Considerable progress has been made since the first method for identifying nucleotides in DNA strands was proposed in 1977 [
1]. The development of new technologies and sensors has led to the creation of increasingly better generations of sequencers, with regard to quality of results, volume of genetic material able to be sequenced in each trial, time savings, and cost efficiency [
2].
Current progress in sequencing is being achieved thanks to new algorithms. Nanopore sequencing, a third-generation sequencing method, available since 2010, has as its key feature the ability to generate very long reads, tens or hundreds of times longer than other competitive solutions [
3,
4]. One of the most popular providers of devices based on this type of technology is Oxford Nanopore Technologies (ONT) [
5]. Nanopore sequencing became a very popular sequencing technique after ONT launched its first MinION device [
6].
The ONT nanopore sequencing process is based on measuring ionic current in the nanopore when DNA/RNA strand is passed through it. The currents’ values are then translated to the sequence of bases, a task known as basecalling. It can be expressed as the function described in Equation (
1) and is a sequence-to-sequence processing task. A schematic illustration of sequencing and basecalling is presented in
Figure 1.
Basecalling is an essential step, mainly responsible for the output of the sequencer and the bases it reads. The software tools identifying bases from ionic current measurements are called basecallers. After the analysis of numerous published solutions, we devised their division into four categories based on two main factors:
algorithms in use: Hidden Markov Models (HMM) vs. various deep learning models (including Recurrent or Convolutional Neural Networks);
input data type: raw current signal data vs. events data (obtained through segmentation of raw current signal data).
The earliest solutions, such as Nanocall created by David et al. [
7], or the first official ONT basecaller, Metrichor [
8], used HMM models together with the Viterbi algorithm to decode the most probable sequence of k-mers that emitted observed events data sequence. Soon, deep learning models started to generate a lot of interest and began to be applied to other solutions. DeepNano, proposed by Boža et al. [
9], and another ONT basecaller, Nanonet, were based on Recurrent Neural Networks and achieved better accuracy scores than previous ones, progressing from around 60% to approximately 80% [
4]. However, they operated on event data, the processing of which began to be considered error-prone, creating inaccuracies which could then be propagated in the second stages of a pipeline, i.e., processing of events and deriving base sequences. Most later developments switched instead to single stage end-to-end processing of raw data. One of the first such tools used for this was BasecRAWller, proposed by Stoiber et al. [
10], which changed basic statistical event detection on raw data to segmentation after RNN feature extraction. The next full end-to-end basecallers were Chiron [
11], which used combinations of CNNs, RNNs, and CTC decoder. The current official ONT basecaller is called Guppy [
12], which is closed-sourced and therefore its implementation details are not precisely known. The Mauler basecaller, proposed by Abbaszadegan [
13], implemented a new approach using deep learning encoder–decoder with the attention model. Even more recent tools are URNano, based on U-net and proposed by Zhang et al. [
14], and Causalcall [
15], using TCN, which is a model gaining in popularity. Mentioned tools have increased the accuracy of single strand reads basecalling to over 90–95%. The latest state-of-the-art in terms of pure accuracy is Bonito [
16], a research algorithm developed by ONT, and Heron, proposed by Boža et al., which can reach over 95% accuracy on some datasets [
17]. Despite surpassing Guppy v3.3 by a large margin regarding accuracy, higher scores come at the cost of lower processing speed, which is most probably the reason why Guppy is still the official ONT basecaller. Nevertheless, all accuracy scores reached by nanopore basecallers are still lower than the over 99% scores of competitive short-read sequencers, like Illumina.
As for new conceptions in this field, both Abbaszadegan’s [
13] and Zhang et al.’s [
14] works mention that, apart from the direct use of raw data, the processing of its segmentation might be beneficial, providing more information to the model.
In this paper, we propose a novel basecaller called Ravvent, which performs joint sequence-to-sequence processing of raw and event data. Its name combines the words
raw and
event, relating to combination of raw and event data types. It is built as an encoder–decoder architecture of recurrent deep neural network. Our solution has an attention model and uses twin encoders for processing both input data types. It has been tested to verify how such joint processing influences the basecalling and its quality, and if this approach has potential in carrying out this task. The general idea of joint processing of different types of data is known in literature and presented, for example in Xiao’s et al. [
18] and Chen’s et al. work [
19]. However, to our knowledge, it has never been applied and examined as an approach to basecalling task.
Our paper is divided into five sections.
Section 2 presents Materials and Methods used for developing and testing the proposed solution. Firstly, the data preprocessing pipeline, as well as datasets used—both simulated and real-life—are presented. Afterwards, an overview of the encoder–decoder models used in the developed tool is described, followed by details of its implementation. In
Section 3, we show and discuss the results of the experiments conducted. Core ones are the tests focused on accuracy on simulated and real datasets, presented in
Section 3.1 and
Section 3.2, together with the speed analysis in
Section 3.3. We also present an analysis of applied attention mechanism behaviour in
Section 3.4. Our results were primarily compared to the Guppy v3.3.0 basecaller [
20]. In
Section 4, we discuss and summarize the results, comparing them with the initial hypothesis, indicating areas for future improvement and further research. We show that the joint processing of raw and event data reaches higher basecalling read accuracy than just using raw data and much higher accuracy than only carrying out event data processing.
2. Materials and Methods
2.1. Data Preprocessing
Sequences (time series) of raw current signal values, which are the plain output of the nanopore sequencers, were the primary data for basecalling. They were saved into fast5 files, a variant of Hierarchical Data Format 5 (HDF5), which enables an efficient data storage organised in a similar way to a file system [
21]. For both training and evaluating a basecaller, the correct sequence of base symbols corresponding to raw sequences was required, serving as ground truth data. It included reference sequences for bases, stored in fasta files, and alignment data mapping each nucleotide base to a range of raw values. We used data sources described in
Section 2.2 that already offered such alignment data, but in general, additional tools should be utilized to perform such mapping, e.g., Tombo [
22] with its re-squiggle algorithm.
Time series with ground truth aligned data cannot be used directly for constructing a basecaller’s input data, since it is not available in typical sequencer output. We therefore propose the data preparation pipeline presented in
Figure 2.
Raw signal values were used to detect events with an algorithm used in earlier versions of official ONT basecallers, specifically open-source Scrappie [
23]. The algorithm is based on sliding window t-statistics and was applied in our solution with window length set between 6 and 9, and other parameters were set to default. Event detection provides segmentation of raw data into events, described by ranges of raw data values, but in contrast to ground truth alignment mapping, it does not use reference base sequence information, and such events are not guaranteed to correspond to bases. The event detection process itself tends to be error-prone, but it may still provide valuable information, in addition to plain raw data. In our algorithm, events have 5 features: (1) mean, (2) standard deviation, (3) length of raw data range, (4) difference of means between the previous and current event, and (5) mean squared.
Using raw and event data, together with ground truth aligned sequences, actual data samples were then created by gathering a maximal number of consecutive events where the corresponding number of raw data values included within them was not greater than the parameter . The next sample then started from the event being positions after the initial event of the previous sample, enabling consecutive samples to overlap. parameter acted as a sampling stride. Base sequence samples consisted of bases which corresponding raw values in the ground truth alignment data were included in the input raw samples.
Samples were then randomly shuffled and split into test, validation, and training datasets of sizes defined as fractions of the whole dataset. The next processing step was scaling, performed with standarization. Six separate scalers were used: 1 for raw data and 5 for each event data feature. Afterwards, raw and event data were padded and truncated to defined and lengths.
Base sequences were put between [START] and [END] symbols, to mark out sequence spans, and then tokenized—each symbol being transformed to an integer token. This mapping dictionary consisted of 7 tokens: 4 nucleotides symbols, start, end, and padding symbols.
Finally, samples of raw, event, and reference token sequences were gathered into batches of size 128, forming data packages ready for processing by the model. During training, the model’s parameters were updated according to gradients computed after processing each batch.
All data used in our work was processed with defined parameters:
and
. These details, together with batch size, are marked on schematic examples of data samples in the
Figure 3. The value of
was selected by us, with the assumption to cover wide enough span of raw data points and be short enough for performant RNN processing.
was then set to a minimal number of events, always including all raw data points selected for a sample, based on the training part of real data.
was adjusted depending on a conducted analysis. For read accuracy evaluation, it was set to 6.
2.2. Datasets
2.2.1. Simulated Sequences
Even though computerized data banks, especially those being a part of INSDC (International Nucleotide Sequence Database Collaboration), such as NCBI GenBank [
24], are popular and actively used, full datasets containing raw output data files straight from ONT sequences are much less common and more difficult to obtain.
As a consequence, special simulators have been developed in order to instantly provide easily accessible and available raw electrical current signals data.
DeepSimulator was the first such tool, initially proposed in 2018 and updated in 2020 to provide better results [
25,
26]. Its core component is a pore model in the signal generation module, which uses BiLSTM-extended Deep Canonical Time Warping deep learning strategy. The simulator provides multiple parameters for tuning signal filtering and applied Gaussian noise to make it highly similar to real life data. Another recent tool is NanosigSim, proposed in 2020, which uses a processing pipeline similar to DeepSimulator, but operates on a BiGRU neural network instead of BiLSTM [
27]. In their paper, the authors demonstrate that NanosigSim might offer slightly greater similarity to real raw sequences. However, since the differences are insignificant and DeepSimulator software is much better documented and used more widely, it was therefore used for data generation for simulated datasets described further. It was run in context-dependent mode with default filter and noise parameters.
To analyse the basecaller using data differing in complexity, 5 datasets were prepared. As a measure of DNA complexity, we used the linguistic sequence complexity introduced by Trifonov [
28], in a variant proposed by Orlov et al. [
29], with vocabulary restricted to words of size 6. Each dataset was based on two sequences of the same length, with one of them being used only for the training part, while the other was split into validation and test sets by
and
fractions, respectively. Their details are presented in
Table 1.
The complexity of the datasets was proportional to the number of 6-mers appearing in the source base sequences.
K-mers of length 6 were used, since 5–6 nucleotides are said to fit in a nanopore during single measurements, and should thus ensure that a reduction in the number of all 6-mers appearing results in a roughly proportional reduction of the complexity of raw current signal sequences in the context of the ability to learn and generalize from them. Basic 6-mers were chosen from a list composed of random permutation of all 6-mers, always starting from the first one—for example, Dataset 2 includes all 3 basic 6-mers of Dataset 1 plus 9 others. Each sequence in a dataset was a random variation with repetition of basic 6-mers, of defined length. A plot of all 6-mers appearing in the function of number of basic 6-mers, used for defining datasets’ characteristics, is presented in
Figure 4. Lengths of sequences in datasets were set to roughly respect the proportion between the numbers of all 6-mers appearing across different datasets, especially with higher ids, in order to obtain fairer results from model trainings (by providing it with more data in the case of more complex datasets). Dataset 5, since it uses all of the 6-mers, represents not reduced and fully random bases sequences.
2.2.2. Real-Life Sequences
Apart from the computerized bio-data banks mentioned earlier, data suitable for preparing new basecalling solutions is often publicly available as a supporting resource for articles on this topic. The dataset prepared and originally used for the development of the Chiron basecaller is one of the most popular pre-prepared datasets used in many other works [
11,
30]. The full dataset is split into training and evaluation parts, each of them consisting of 2000 reads of the
Escherichia coli (
E. coli) genome and 2000 reads of the
Lambda phage genome. Our basecaller was trained on
Lambda phage part, with evaluation part split by
and
into validation and test datasets, respectively. The same splitting was applied to
E. coli dataset and its test part was additionally used for model evaluation.
2.3. Encoder–Decoder Models
Model architecture used in our proposed basecaller originates from the field of natural language processing translation, because basecalling is a sequence-to-sequence translation. We used encoder–decoder architecture of recurrent neural networks, initially proposed by Cho et al. [
31] and Sutskever et al. [
32]. We extended the model with an attention mechanism, which has been proven to greatly improve its translation capabilities, especially when dealing with longer sequences. We used multiplicative attention based on the one proposed by Luong et al. [
33].
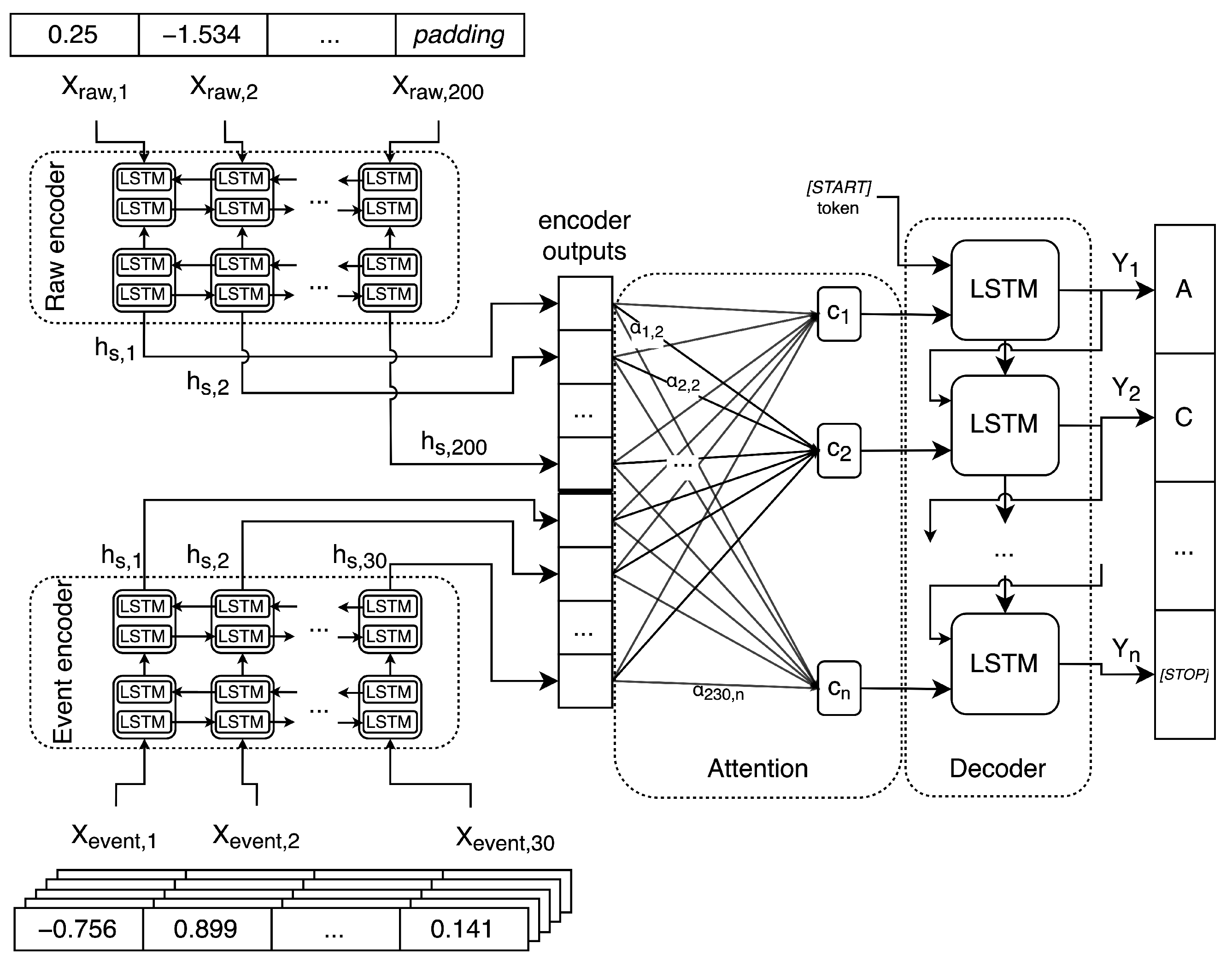
Figure 5 presents a general overview of the model structure. While processing raw data, the model consumes only raw data samples and passes them to raw encoder. Then, its output is used by attention mechanism and decoder, finally producing predicted bases sequence. Event data processing differs only in the two first steps, using event data samples and event decoder. For full joint processing, both data type samples and encoders are used in parallel. Then, their outputs are concatenated and passed to the attention mechanism and the decoder. Part of our architecture is described by Equations (
2)–(
4).
The encoder consumes an input sequence of length S—in this case, it is a sequence of raw or event data—and for each element of the sequence it produces an output, while passing information about its state for processing of next elements.
Decoder is provided with a [START] token to begin the decoding process. Then, at each time step, it produces output () and state information.
An attention layer is used, queried by the decoder’s state over all encoder outputs (). It is also provided with an input mask to explicitly ignore any encoder outputs corresponding to input padding. Prediction of the base at each time step is made using a beam search or greedy search decoding.
The attention layer first calculates attention weights
(Equation (
2)) using specific score function (Equation (
3)), with
as a weight matrix shared over all time steps. Then, it computes a context vector
c (Equation (
4)), which is used in the decoder for the prediction of the probabilities of output sequence tokens at a certain time step. Therefore, attention allows the decoder to focus with different strengths on different parts of the input, which is applicable and needed in longer sequences of data processed by the basecaller.
Joint type is based on processing and encoding raw and event input data in parallel, using twin encoders, as shown in
Figure 5. The outputs of these encoders are then concatenated on the first axis for each sample in a batch. The rest of the processing is executed in the same way as for raw and event components.
Both encoder and decoder are based on generalized Recurrent Neural Networks (RNNs). We applied one of the most popular type—i.e., Long-Short Term Memory (LSTM) network, with its bidirectional variant used in encoder (BiLSTM). Its output, to be used in attention mechanism, is the concatenation of LSTM cells’ outputs in both directions at the same step. During training, all models’ gradients were clipped by norm.
2.4. Loss and Accuracy Metrics
As a loss function, cross-entropy was used, being called over a sequence of the logits token predictions and a tokenized ground truth base sequence. It also respected masking on the ground truth sequence and did not take into account its padding. Loss was calculated on each data batch and averaged across all of the batches afterwards. It was monitored on training and validation datasets and logged after each computational epoch.
Two methods of accuracy measurements were used: subset [
34] and read accuracy [
35]. The first one, also called exact match accuracy, calculates a fraction of bases symbols identified exactly, also in the right position in the sequence. It was applied on the data samples. Read accuracy is a more significant method—it measures the identity of a whole predicted bases sequence relative to a reference once. To obtain the whole sequence, predicted samples are merged using pairwise Needleman–Wunsch algorithm. Using a minimap2 (v2.17) tool [
36,
37], we aligned basecalled reads to the reference bases sequence. Each read’s accuracy was defined as the number of matching bases in its alignment divided by the total alignment length including insertions and deletions, a.k.a. the ‘BLAST identity’ [
35,
38]. Accuracy from multiple reads was averaged using lengths of aligned blocks as weights.
2.5. Implementation
Implementation of our basecaller was done in Python using
tensorflow and
keras deep learning libraries [
39]. The official
tensorflow tutorial was used as a template for baseline code implementation [
40]. For all inner RNNs (two encoders and a decoder), latent dimensions were set to 128. Encoders used 2 stacked BiLSTM layers, the decoder used 1 layer of LSTM. Gradients were clipped to ensure their L2-norm was less than 1. Scheduled sampling teacher forcing was applied during training, with a sampling ratio of
. Core implementation files consisted of nearly 1500 lines of code (LOC) in total. The processing pipeline was tested on small data samples, focusing largely on the correct shapes of tensors passed between consecutive processing steps.
The software is publicly available on the project’s repository homepage [
41], and a version used in analysis is presented on commit
7ab517e. The detailed block diagram of Ravvent basecaller with selected network is presented in
Figure 6.
3. Results
3.1. Basecalling Accuracy on Simulated Data
To analyse the behavior of our models on simulated datasets with different complexity, they were subjected to training and evaluation—the training took 100 epochs and applied
was equal to 1. A plot of read accuracy for each model using test datasets is presented in
Figure 7, together with read accuracy of the ONT Guppy v3.3.0 basecaller subjected to the same evaluation sequences.
It can be seen that for the least complex datasets, accuracy scores for all types of own models are mostly above 90%—similar to the ONT Guppy that reaches around 92%, though performing at the same level for every dataset type. Interestingly, results on Dataset 1 of all own models are lower than on the two next, more complex, datasets. However, it is most probably due to minimap2 tool not being adapted for that simple sequence. The event model gave the lowest accuracy for every dataset, but the gap between it and the other two increases dramatically for the more complex datasets, which confirms that plain event data is less usable for good quality of basecalling task. Joint and raw models’ accuracy also decreased with increasing complexity of datasets, but it did not drop below , staying at a level competitive with Guppy. The joint model performed the best for all datasets, with an average gain of 1p.p over the plain raw model.
3.2. Basecalling Accuracy on Real Data
In addition to analysing simulated datasets, models were tested on real datasets. Their training was executed for 40 epochs on
Phage Lambda dataset,
was equal to 6, due to its considerable size. Read accuracy achieved by each model variant and the ONT Guppy are listed in
Table 2. They include scores achieved on
Phage Lambda and
E. coli datasets with Ravvent decoder’s beam width set to 5 and 1 (greedy search decoding).
A bigger beam width resulted in better performance—on average p.p. for all models, but only p.p. for better performing raw and joint models. However, speed of basecalling with bigger beam width was approximately slower than with simpler greedy search decoding.
Joint model again performed the best in all tested cases, reaching on average p.p. higher accuracy than the raw one. With bigger beam width, this advantage reached p.p. The event model provided much lower and unsatisfactory scores.
Similar results of models trained on Phage Lambda on E. coli dataset confirmed that over-fitting to a specific organism type sequences did not take place.
The Guppy basecaller’s accuracy on real data is at approximately the same level as its accuracy on simulated datasets, which indicates its consistent performance and well-learnt ability to generalize over different datasets.
3.3. Basecalling Speed Analysis
Apart from the accuracy assessment, the speed of basecalling is also a relevant aspect to consider. To analyse the performance of the Ravvent, we run its trained models on the evaluation part of the
Phage Lambda dataset 10 times, measuring and averaging the time it took to process all sequences. It was run with beam width set to 1. The final speed rate values were calculated by dividing the number of bases and the number of signal measurements in the sequences their processing time. The same process was conducted using Guppy v3.3.0. We run experiments on 4-core CPU machine (Intel family 6, model 61), with and without GPU NVIDIA GeForce GTX 1080 Ti enabled. Obtained results are presented in
Table 3. Additionally, we attached speed rates declared in papers testing other basecallers, including Chiron and BasecRAWller from [
11], Osprey and Bonito 0.3 from [
17], and DeepNano-blitz 96 from [
17], with approximate values scaled proportionally to the 4 CPU cores used by us. Since values in the referenced papers were not given for all units nor environment configurations that we examined, we filled the missing values with NA symbol.
The results confirm that the use of joint raw and event data processing impacts the basecalling speed, which is then
smaller than in raw only case and around
smaller than in event only case. Guppy’s speed on CPU only is
higher than Ravvent with joint model, but with GPU it reaches
. Chiron and BasecRAWller are the tools with the lowest speed, the reason is most probably the fact that they were developed as one of the earliest tools based on neural networks. On the contrary, DeepNano-blitz and Osprey have been published very recently and are deeply optimised to reach one of the highest speeds currently available. Bonito [
16], as the newest ONT developed tool, is also able to process sequences with much higher speed. At this stage of the development, Ravvent has not been optimised regarding speed in most of its implementation. While it is very unlikely to reach processing rates of the fastest mentioned tools, some improvements in the speed through implementation changes are achievable, including parallelization or more efficient tensors usage.
3.4. Attention Mechanism
To review how the attention mechanism implemented performed, all types of trained models were run on suitable input data sequences and attention weights applied by models during such predictions were plotted in the form of a heat map—examples of which are presented in
Figure 8. Points on the charts’ images indicated which encoder outputs (corresponding to the input sequence) were attended to for prediction of each base in the output sequence. The brighter the color, the bigger the weight assigned to a specific encoder output.
It can be seen that for both event and raw types, the points representing higher weights form a diagonal line on the plot. On event one, it is much more condensed, i.e., for single output base id there are usually 3 encoder outputs attended to. In the case of raw data, each predicted output base is largely based on a wider span of consecutive encoder outputs. As one of the characteristics of raw nanopore data is that a current is measured multiple times per each nucleotide and neighbouring nucleotides influence these measurements, it is assumed that correct identification of a base symbol requires the model to understand wider dependencies between raw data points. Attention weights plots indicate that our model demonstrates this property.
On the right-hand sides of both first plots, correct masking on the padding of the input data can also be observed as blank vertical zones.
As for the joint data, its attention weight plot corresponds to the way in which twin encoder outputs are processed in the model, i.e., concatenation. Therefore, there exist two distinguishable parts in the plot, representing separate raw and event plots, which are concatenated. This therefore confirms that such a model utilises information jointly from parts of raw and event data—for each predicted output base there are encoder outputs attended to in both parts.
4. Discussion
In this paper, we proposed a novel approach to basecalling, using joint raw and event data processing, and presented implementation of our own basecaller using this technique. The Ravvent basecaller is based on an encoder–decoder model with an attention mechanism. After evaluating it on simulated and real-life datasets, we confirmed that this approach shows potential for further exploration and development, since in all of the cases analysed it achieved accuracy scores that were higher than when processing only raw data, currently the most popular method.
We confirmed that plain event data processing is indeed much more erroneous, which was the reason for seeking new solutions based on raw data processing a few years back, one of the first ones being BasecRAWller [
10]. However, when processed jointly with raw data, it appears to provide additional information that models can leverage to perform better.
Even though in terms of both accuracy scores and basecalling speed our basecaller achieved lower result values than state-of-the-art solutions, we find the presented approach promising, since other analysed tools are based only on raw data processing, while we proved that joint data types processing can result in increase of basecaller’s accuracy. We acknowledge that our model’s architecture was simpler than the ones of other tools, which is one of the reasons why we see a prospect of having its performance and results quality further increased—with code optimisation and especially with architecture development, including adjustments to RNN layers. Moreover, official ONT basecaller presumably has access to a large number of data sources, which undoubtedly enables it to learn and perform better. Our solution, for less complex (regarding appearing 6-mers) simulated datasets, performed considerably better than Guppy, which may additionally indicate the importance of amounts of training data, in which case the official solution has much greater training potential.
By proving that the joint processing performs better in terms of basecalling accuracy, we identify a practical value in such confirmation, which can be used as a clue for creating or developing basecallers with more complex architecture, optimised from the core to compete with the best available basecallers, by leveraging joint processing.
Lastly, in the neural machine translation field, more advanced versions of encoder–decoder models are currently gaining popularity, including transformer, which utilises a self-attention mechanism. Applying a joint processing approach to such model architecture might well boost its performance and provide more data for analysis of the approach itself.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}